

1. 先进封装:超越摩尔定律,助力芯片性能突破
1.1. 半导体封装所属集成电路后道工艺,封装工艺持续优化
所属集成电路产业链后道,起着安防、固定、密封、保护芯片,以及确 保电路性能和热保护等作用。封装测试环节所属集成电路产业链后道,主要是指 安装集成电路的外壳的过程,包括将制备合格的芯片、元件等装配到载体上,采 用适当的连接技术形成电气连接并构成有效组件。常规封装主要是用引线框架承 载芯片的封装形式,具有四大功能:①芯片机械支撑和环境保护、②接通电源、 ③引出信号线和接地线、④芯片热通路。先进封装引脚以面阵列引出,承载芯片大 都采用高性能多层基板,在原有四大功能的基础上,更肩负了提高芯片规模、扩展 芯片功能和提高可靠性的作用。
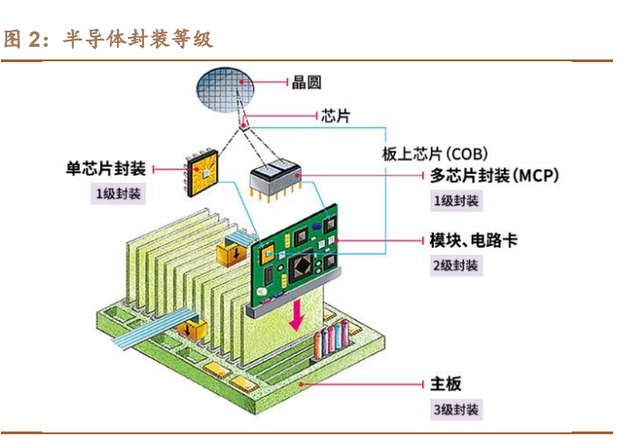
电子封装技术覆盖四个等级,集成电路的封装主要是指其中的一级封装和二 级封装,即芯片级封装和外联 PCB 板。 零级封装(切割晶圆):从晶圆片上切割得到芯片。 一级封装(芯片级封装):将芯片固定在封装基板或引线框架上,将芯片的焊 盘与封装基板或引线框架内的引脚互连,并对芯片和互连进行保护性包封。 二级封装(外联 PCB 板):将一级封装和其他电子元件安装在 PCB(硬质线 路板),得到电子系统的插卡、插板或主板。 三级封装:将附带芯片和模块的电路板安装到系统板,组装完整的电子产品。
半导体封装由三要素决定:封装体的内部结构(一级封装)、外部结构和贴装 方法(二级封装),目前最常用的类型是“凸点-球栅阵列(BGA)-表面贴装工艺”。 半导体封装包括半导体芯片、装在芯片的载体(封装 PCB、引线框架等)和封装 所需的塑封料。直到上世纪末 80 年代,普遍采用的内部连接方式都是引线框架 (WB),即用金线将芯片焊盘连接到载体焊盘,而随着封装尺寸减小,封装内金 属线所占的体积相对增加,为解决该问题,凸点(Bump)工艺应运而生。外部连 接方式也已从引线框架改为锡球,因为引线框架和内部导线存在同样的缺点。过 去采用的是“导线-引线框架-PCB 通孔插装”,如今最常用的是“凸点-球栅阵列 (BGA)-表面贴装工艺”。
从封装工艺进步以提升封装效率为主线。通孔插装时期,封装体引脚数<64, 封装密度≤10 引脚/cm² ;表面贴装时期,引脚变为引线,引线数量为 3-300 根, 封装密度变为≤10-50 引脚/cm² ;球栅阵列时期,以焊球代替引线,芯片与系统 的距离缩短,安装密度达到 40-60 引脚/cm² 。目前,全球集成电路封装技术以面 积阵列技术为主,即 BGA、CSP 等,随 WLP、TSV 和 SiP 等技术规模化推广, 封装体的封装效率或进一步提升。
传统封装的技术迭代使得封装体尺寸更小,引脚间距更近,实际提升了封装 体与 PCB 的互联性能(二级封装);进入先进封装时期,必须满足提升 I/O 数的 客观需求。近几十年来 I/O 增速仅为晶体管密度增速的一半,I/O 已经成为先进芯 片性能的命脉。随着处理器和高性能芯片的计算能力不断提升,对数据的传输能 力提出更高要求,需要更多 I/O 引脚以支持更高的数据带宽。从技术迭代来看, ①BGA、CSP 等技术支持在相对更小的封装面积内容纳更多引脚;②如 Fan-Out 晶圆级封装通过重布线提升 I/O 的数量和密度;③应用 TSV 和凸点等技术的 2.5D/3D 封装通过堆叠的方式进一步提升 I/O 密度和数量。
1.2. 四大要素助力先进封装提质增效、系统集成
先进封装是“超越摩尔定律”的重要途径。集成电路沿着两条技术路线发展, 一方面是“摩尔定律”:每隔 18-24 个月,随晶体管尺寸微缩,集成电路容纳的元 器件数量约增加一倍;而另一方面则是“超越摩尔定律”:以多样化的封装方式提 升系统性能。2015 年以后,集成电路制程发展进入瓶颈,芯片特征尺寸已接近物 理尺寸极限,晶圆代工成本和研发成本大幅增长,集成电路行业进入“后摩尔时 代”。通过先进封装技术提升芯片整体性能或成为集成电路行业技术发展趋势。
与传统封装相比,先进封装具有小型化、轻薄化、高密度、低功耗、功能集 成的优势。传统封装形态上主要是 2D 平面结构,芯片之间缺乏高速互联的硬件 支持;而先进封装能够支持多芯异构集成,具有 2.5D/3D 结构,且芯片之间能实 现高速互联。先进封装较传统封装,尺寸更加轻薄的同时,兼顾更高的性能,能实 现更高内存带宽,提升数据的传输效率。
先进封装在 AI、高性能计算、数据中心等新兴应用蓬勃发展,市场规模快速 提升。据 Yole 分析,先进封装技术在特定领域需求强劲,比如 FO(扇出型)封 装在手机、汽车、网络等领域会有巨大的增量空间;2.5D/3D 封装在 AI、HPC、 数据中心等领域也有巨大增量空间。根据 Frost & Sullivan 预测,2021-2025 年 中国先进封装市场规模复合增速达到 29.91%,预计 2025 年中国先进封装市场规 模为 1136.60 亿元。根据《2022 年中国集成电路封测行业发展白皮书》中的数据, 全球范围内,预计 2025 年晶圆级封装、倒装、3D 堆叠等先进封装市场规模累计 达到约 460 亿美元。
《基于 SiP 技术的微系统》提出先进封装的四个关键要素:Bump(凸块)、 RDL(重布线)、Wafer(晶圆)和 TSV(硅通孔):Bump 联通芯片与外部的电 路,并能缓解应力;Wafer 充当集成电路的载体;RDL 联通 XY 平面的电路;TSV 则贯通 z 轴方向上的电路。前三种技术广泛运用于 2D/2.5D/3D 封装,TSV 则主 要运用于 2.5D/3D 封装。随着技术发展,凸块尺寸逐渐缩小,晶圆片则越来越大, RDL 和 TSV 向着尺寸更小,排布更密集发展。
1.2.1. 倒装(Flip Chip)与凸块(Bump)
倒装技术(FC)通过平面排列的 Bump 将芯片的有缘电路朝下键合到基板、 衬底或电路板上来实现电信号联通。与传统引线键合(WB)相同,倒装是一种实 现芯片与基板电气连接的互连技术,不过 WB 的芯片焊盘都在芯片四周,因此 I/O 密度受限于引线间距,而 FC 可以在芯片的整个面上排布 Bump 与基板互连,极 大提高 I/O 数,缩短互连路径,减薄封装厚度。性能提升方面,倒装的电阻和寄生 电容/电感更低,具有更好的频率特性和更低功耗,封装电性能极大提升;此外, Bump 可向基板导热,具有更低热阻和散热性能。
凸块(Bump)制造技术是倒装等工艺演化的基础工程,凸块可用来代替引线 直接联通芯片和基板的电信号。凸块制作的材质主要有金、铜、铜镍金、锡等, 应用场景各不相同。凸块间距尺寸(Bump Pitch)越小,意味着凸块密度越大, 封装集成度越高,相对工艺难度越大。AnandTech 披露数据显示,台积电凸块间 距已推进到 10μm 以下;根据未来半导体公众号,通富微电、华天科技等国内厂 商先进工艺向 40μm 推进。当凸块间距超过 20μm,内部互连技术采用基于热压 键合(TCB)的微凸块连接技术;而未来 HCB(混合铜对铜连接)则能实现更小 凸块间距(10μm 以下)和更高的凸块密度,并带动带宽和功耗双双提升。
1.2.2. RDL(重布线层)
RDL(Re-distributed layer,重布线层)通过在芯片表面沉积金属层和相应 的介电层,形成金属导线,可将 I/O 端口重新排布到更宽敞的区域。RDL 可形成 表面阵列布局,因此放置芯片的方式能紧凑且高效,并减少器件的整体占地面积, 极大提高封装效率。目前 RDL 已经是先进封装异质集成的基础,广泛应用于晶圆 级扇出封装、扇出基板上芯片、扇出层叠封装和 2.5D/3D 封装集成等。
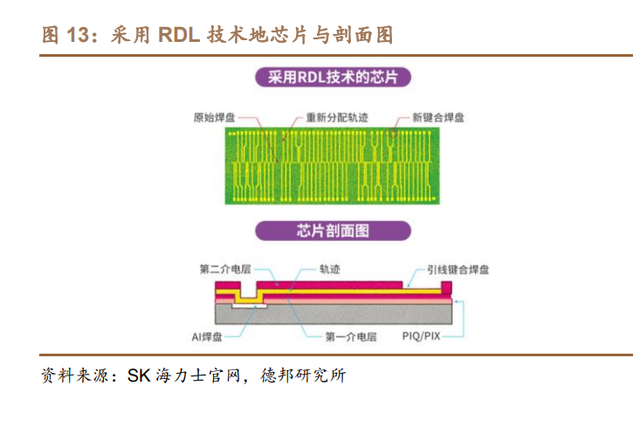
头部厂商RDL技术的线宽和间距向1/1μm突破。RDL采用线宽和间距(L/S) 来度量,线宽和间距分别是指金属布线的宽度和它们之间的距离。根据未来半导 体和与非网,如今 4 层 RDL 已经成熟,良率达到 99%,约 85%封装需求可通过 4 层 RDL 满足,未来 RDL 有望从 4 层增加到 8 层以上。头部封装厂商的 RDL L/S 将从 2023/2024 年的 2/2μm 发展到 2025/2026 的 1/1μm,再跨入到 2027 年以后 的 0.5/0.5μm;国内企业长电科技、通富微电等已突破 5 层,L/S 达 2μm。
1.2.3. WLP(晶圆级封装)
晶圆级封装(WLP)与传统封装流程不同,采用先封装测试,后切割的方式, 得到几乎裸片尺寸的封装面积。传统技术先在裸片切割,后进行封装,封装后至 少增加原芯片 20%的体积;而 WLP 封装则是先封装测试,后切割,封装完成后 近乎等同于裸晶的原尺寸,明显缩小封装面积。性能方面,WLP 具有较小的寄生 电阻、电容、电感,从而具有较佳的电性表现。从制造方面,WLP 为芯片制造、 封装、测试等流程实现晶圆级集成铺平道路,大大减少中间环节,使得一个器件 从硅片到客户交付的制造流程效率更高,周期更短。
以是否扩展封装面积以容纳更多 I/O 数,WLP 可分为扇入型和扇出型。 扇入型(Fan-In):芯片尺寸和封装尺寸一致,封装凸球位于芯片尺寸范围内, 在 I/O 数量较小时可以使用这类技术。而伴随着 IC 信号 I/O 数的增加,且部分组 件对于封装后尺寸以及信号输出脚位位置的调整需求,芯片尺寸已经无法容纳足 够 I/O 接口,因此变化衍生出扇出型 WLP(FOWLP)。 扇出型(Fan-Out):芯片经过切割后先被埋入环氧树脂塑料(EMC)等材料 中,形成一个塑料模压重组晶圆,再对其进行晶圆级工艺加工,使 I/O 数量和密度 大幅提升,不再受芯片尺寸限制。此外扇出型封装在面积扩展的同时,还可以加 入其他有源/无源器件,形成系统级封装(SiP)。
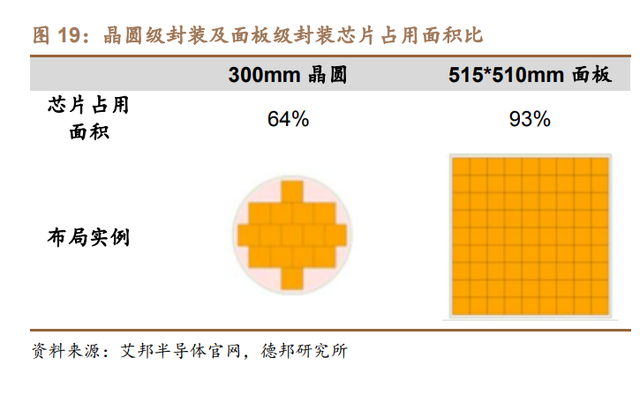
晶圆级封装的技术发展分两个维度:①异构集成;②面板级封装。 ①异构集成:包括多芯片封装、封装中的无源组件集成、封装上的封装等, 随着 TSV、集成无缘器件(IPD)、扇出等封装技术的引入,WLP 产品的集成方案 广泛应用。比如从 2012 年起,台积电陆续推出的晶圆级集成扇出(InFO)、封装 上封装(InFO-PoP)等,显著提升封装性能。 ②扇出面板级封装(FOPLP):过去 WLP 一直用直径为 200mm 或 300mm 的晶圆片或重构晶圆片生产,这些规格可以利用现有的大型工厂和设备基础设施 进行加工。但是由于最后的封装体是矩形的,因此圆形硅片不能提供最高的加工 效率和最有效的面密度。因此考虑将面板扩展到矩形而非圆形,再进行进行晶圆 级加工,将有效降低成本。据 Yole 报告,FOWLP 的面积利用率小于 85%,而 FOPLP(扇出型面板级封装)的面积使用率超过 95%。当放置的芯片数增加,成 本也会下降,据 Yole 测算,圆片晶圆从 200mm 过渡到 300mm,节省成本约 25%; 而从 300mm 圆片晶圆过度到板级晶圆,则能节约 66%成本。
1.2.4. 2.5D/3D 封装与 TSV 技术
2.5D 封装通过添置一层高密度中阶层提供芯片之间的电气连接,极大提升封 装性能。结构上,2.5D 封装的多个芯片并排放置在中阶层(Interposer)顶部,通 过芯片的微凸块(μBump)和中阶层的布线实现互连。中阶层类型包括硅、玻璃 或有机基板,一般通过 TSV(硅通孔技术)实现上下的互连,再通过凸球(C4) 焊接到传统 2D 的封装基板上。相比 PCB 级封装,2.5D 封装内的互连线更细更 短,各种元件堆叠得更加紧密,因此具有更高带宽,而且因为元件靠的近、线路 短,延迟几乎可以忽略 。此外,2.5D 封装结构在与堆叠内存模块(特别是高带宽 内存)相结合后能进一步提高整体性能。 3D 封装可以容纳多个不同制程的异构裸片,可兼顾高性能和低成本。相比于 2.5D 封装将芯片集成在中阶层上,3D 封装则是直接在芯片上打孔(TSV)和布线 (RDL),并通过微凸块等技术彼此互连,电气连接上下层芯片。3D 封装可以容 纳多个异构裸片,如逻辑、存储器、模拟、射频和微机电系统 (MEMS),其中高 速逻辑可以采用先进制程节点,而模拟逻辑可以采用较早的制程节点。这为系统 级芯片(SoC) 集成提供了一个替代方案,使得开发人员不必为了在单个封装中集 成更多功能而不得不采用成本昂贵的新的制程节点,也能节省漫长开发周期带来 的额外成本。因此 3D 封装有望同时实现高性能和低成本。
基于 TSV 工艺的 2.5D/3D 封装具有远超过往堆叠封装的性能、功耗、密度和 外形尺寸。与传统引线键合的系统级封装 SiP 相比,TSV 优势包括:①提高电性 能:相比引线键合,TSV 通过垂直互连极大缩短互连线长度,减少传输延迟和损 失,降低电容和电感,实现芯片间的低功耗、高速通讯。②高密度集成:TSV 技 术能减少封装的几何尺寸和重量,满足多功能和小型化的需求。③多种功能集成: TSV 互连的方式可以使不同的功能芯片(如射频、存储、逻辑、数字和 MEMS 等) 集成到一起,实现多功能。④降低制造成本:虽然目前 TSV 技术工艺成本较高, 但是可以在元器件总体水平上降低制造成本。
2. CoWoS 和 HBM:相辅相成,AI 芯片的绝佳搭档
2.1. CoWoS:AI 时代的先进封装版本答案
2.1.1. AI GPU 强需求,先进封装进入算力时代大赛道
算力作为人工智能发展的动力,需求随大模型推出爆炸式提升。2024 年 5 月, IDC 预测全球 2024 年将生成 159.2 ZB(Zettabyte,十万亿亿字节)数据,2028 年将增加一倍以上,达到 384.6 ZB,复合增长率为 24.4%。此外,据《中国算力 发展指数白皮书(2023 年)》,随着新推出的大语言所使用的数据量和参数规模呈 现“指数级”增长,智能算力需求爆发式增加。以 GPT 大模型为例,GPT-3 模型 参数约 1746 亿个,训练一次需要的总算力约 3640PF-days,即以每秒一千万亿 次计算,需要运算 3640 天。2023 年推出的 GPT-4 参数数量可能扩大到 1.8 万亿 个,是 GPT-3 的 10 倍,训练算力需求上升到 GPT-3 的 68 倍,在 2.5 万个 A100 上需要 90-100 天。
GPU 是用量最多的 AI 芯片,供应商英伟达一枝独秀。AI 芯片是人工智能产 业的关键硬件之一,从狭义上讲,特指为加速 AI 算法而特别设计的芯片。从技术 架构分类,AI 芯片可分为 GPU、FPGA、ASIC 以及类脑芯片,其中 GPU 芯片主 要用于处理图形、图像方面的数据运算,因架构中融合了大量高效的运算单元和 快速内存,拥有卓越的浮点运算性能和并行处理速度,尤其适合解决 AI 算法方面 的问题。2022 年中国 AI 芯片市场中 GPU 的市场份额最大,占比达 89%。在独 立 GPU 市场上,主要由英伟达、AMD 和英特尔三家占据,据 JPR 数据,23 年 Q1,英伟达、AMD 和英特尔的市场份额占比分别为 84%、12%和 4%。24 年 Q1, 英伟达 GPU 出货份额上升至 88%。
众多高级 GPU 芯片借助台积电 CoWoS 封装集成。英伟达畅销 GPU:A100、 A30、A800、H100、H800、H200 和 GH200 等均采用台积电 CoWoS-S 封装工 艺。据 DigTimes 报道到 2024 年底英伟达能消耗台积电一半的预计产能。AMD GPU:Instinct MI100、Instinct MI200/ MI250X、Instinct MI300 也采用台积电 CoWoS 封装。除此之外,Broadcom、Google TPU、Amazon Trainium、NEC Aurora、Fujitsu A64FX、Xillinx FPGA、Intel Spring Crest 和 Habana Labs Gaudi 产品也使用了 CoWoS 技术。
2.1.2. 台积电 CoWoS 性能优异,AI 芯片应用匹配度高
CoW oS 的 2.5D 封装结构颠覆传统。2012 年 CoWoS(Chip on Wafer On Substrate)登台亮相,结构上由 CoW 和 oS 组合而来:借助微凸块(μBumps) 技术,先将芯片通过 CoW (Chip on Wafer)的封装制程连接至硅中介层(Silicon Interposer),再利用 C4(铜凸块)技术,将 CoW 与封装基板(Package Substrate) 连接,整合成为 CoWoS。其中硅中阶层先由 TSV 技术形成联通上下的通孔,再 使用 RDL 形成高密度布线,因此信号可以经由硅中阶层高速传输,相比过去芯片 间引线键合,大大提高了互连密度和数据的传输带宽。CoWoS 的核心就是将不同 的芯片堆叠在同一个硅中阶层以实现多芯片高性能互联。
CoWoS 非常适合需要大量并行技术、处理大量数据向量以及需要高内存带 宽的应用场景。在高性能计算领域,CoWoS 封装具备整合多个处理器芯片、高速 缓存和内存于同一封装中的能力,从而实现卓越的计算性能和数据吞吐量,这一 特性在数据中心、超级计算机和人工智能应用领域具有突出的重要性。从技术来 看,CoWoS 能最大程度发挥 HBM 以及 Chiplet 等先进技术的潜能。CoWoS 与 HBM 相互成就,内存与处理单元的物理距离更近,且中介层助力互联性能提升, 从而实现更高、更快的传输。CoWoS 与 Chiplet 的结合能提高系统级性能和功效。 与传统的 SiP 相比,CoWoS 技术能在封装中支持更多数量的晶体管。
CoWoS 已迭代多代,以增加中介层尺寸和内存容量(HBM)为主线。2011 年第一代 CoWoS 被 Xilinx(赛灵思)的高端 FPGA“7V2000T”采用,封装体中 配备四个 28 纳米 CMOS工艺的 FPGA逻辑芯片,硅中介层的最大尺寸为 775mm2。 2016 年第三代 CoWoS 首次组合 HBM 和逻辑芯片,随后 HBM 安装的数量持续 增长且 HBM 不断升级。第六代 CoWoS 的硅中介层尺寸达 3400mm2,配备 HBM 数量达到 12 个。但是随着硅中介层的面积增加从 12 英寸的晶圆能获得的中阶层 数量也将减少。在 12 英寸的晶圆中,晶圆边缘的所有中阶层都会有缺陷,若每个 中阶层为正方形(58mm*58mm),则最多能从 12 英寸晶圆中得到 9 个中阶层。
除搭载①硅中介层的 CoWoS-S,台积电还研发出两类搭载其他中阶层材料 的技术:②CoWoS-R(RDL 有机材料);③CoWoS-L(RDL Chiplet 硅桥)。 CoWoS-S(中介层是硅衬底):2011 年开发的第一个 CoWoS 技术,利用硅 片作为微芯片的桥梁,芯片互连密度相比其他两种方案最高的。 CoWoS-R(中介层由 RDL 有机材料构成):出于成本考虑采用 RDL 有机 转接板作为中介层,但是该方式的芯片互联密度较低,适用于需要降低封装成本 并且具有一定性能需求的应用。 CoWoS-L(中介层由 RDL Chiplet 硅桥构成):将小“硅桥(LSI)”安装在 有机转接板中,即仅在芯片链接部分使用硅片,从而实现高密度芯片互连,综合 利用 RDL 和硅互连(LSI)的优点实现更高效的封装,生产成本和综合性能介于 CoWoS-S 和 CoWoS-R 之间。
台积电已打造先进封装产品矩阵 3D Fabric,包括先进 2D 封装 InFO、2.5D 封装 CoWoS 以及前段 3D 整合芯片系统 SoIC 。 InFO:集成扇出型晶圆级封装是一种晶圆级系统集成技术平台,具有高密度 RDL(再分布层)和 TIV(通过 InFO 通孔)以实现高密度互连和高性能。 SoIC:前段 3D 芯片堆叠技术,用于重新集成从 SoC 划分的小芯片,最终的 集成芯片在系统性能方面优于原始 SoC,并且还提供了集成其他系统功能的灵活性。相较 2.5D 封装方案,SoIC 的凸块密度更高,传输速度更快,功耗更低。
三星和英特尔也将先进封装技术作为发展重点,都已完成 2.5D/3D 封装部署。 三星I-Cube:作为异质整合技术,I-Cube可将一个或多个逻辑芯片(如CPU、 GPU 等)和多个存储芯片(如 HBM)整合连接在中介层顶部。I-Cube 封装技术 可与台积电 CoWoS 封装制程相抗衡,该项技术已投入使用。 英特尔 EMIB:全称“Embedded Multi-Die Interconnect Bridge”,是英特尔 在 2.5D IC 上的尝试。结构上看,没有引入额外的硅中介层,而是只在两枚裸片 边缘连接处加入了一条硅桥接层(Silicon Bridge),并重新定制化裸片边缘的 I/O 引脚以配合桥接标准。
2.1.1. CoWoS 供不应求,传统封装大厂加速入局相关工艺端
台积电 CoWoS 产能预计不断上调,2024 年底或达到每月 4 万片。据 TrendForce 报道称,预估到 2024 年底,台积电 CoWoS 产能将达到每月 4 万片, 较 2023 年总产能提升超 150%;AnandTech 披露,2024 年 5 月台积电宣布计划 以超过 60%的 CAGR 扩大 CoWoS 产能,截至 2026 年台积电目标将 CoWoS 产 能扩张到 2023 年 4 倍水平以上。 除先进封装巨头全栈式生产 CoWoS,传统封装厂商仍有机会分一杯羹。据 集微网,将 CoWoS 生产拆分成两个部分是可行的。其中,一种方案是台积电完 成晶圆和中介层生产,即 CoWoS 的“CoW”部分,然后交由自家(比如空余 InFO 产能)或别家封装厂完成“oS”部分;另一种方案是联电生产硅中介层,即“Co” 部分,再送往安靠或日月光完成“WoS”部分。但是生产 CoWoS 涉及诸多工艺 的 know-how,产业链分工背景下,提升工艺良率需要两部分厂商通力合作。合作 制造 CoWoS 的方式得到的成品价格或远高于台积电。
2.2. HBM:AI 芯片的最佳显存方案,市场需求高涨
2.2.1. HBM 缓解内存墙问题,满足 AI 高性能动态存储需求
“存”与“算”失调,内存墙问题亟待解决。绝大多数现代计算机都是基于 冯·诺依曼结构建造的。该结构需要 CPU 从存储器取出指令和数据进行相应的计 算。这种“存算分离”结构导致“内存墙”产生:与内存的整体存储容量相比,处 理器与内存之间的数据交换量太小。在高性能计算、数据中心、人工智能(AI)应 用中,顶级高算力芯片的数据吞吐量峰值在数百 TB/s 级别,但主流 DRAM 内存 或显存带宽一般为几 GB/s 到几十 GB/s 量级,与 TB/s 量级有较大差距,DRAM 内存带宽成为制约计算机性能发展的重要瓶颈。而且当数据频繁搬运,在存储、 计算之间来回转移时,还会导致严重的功耗损失:据英特尔的研究表明,当半导 体工艺达到 7nm 时,数据搬运功耗高达 35pJ/bit,占总功耗的 63.7%。 打破内存墙或推动数据科学实现创新:根据《AI and Memory Wall》(Amir Gholami et al.),每当 GPU 内存容量增加时,数据科学家便有机会设计更新模型。
HBM(High Bandwidth Memory)即高宽带存储器,结构上包括多层 DRAM 芯片和一层基本逻辑芯片。参考《高带宽存储器的技术演进和测试挑战》(陈煜海 等),HBM 上部分由多层 DRAM 堆叠组成,不同 DRAM 芯片之间以及 DRAM 和 逻辑芯片之间利用 TSV(硅通孔)和微凸块(Micro bump)实现通道连接。每个 DRAM 芯片可通过多达 8 条通道与外部相连,每个通道可单独访问 1 组 DRAM 阵列,通道间访存相互独立。逻辑芯片可控制 DRAM 芯片,并提供与控制器芯片 连接的接口,主要包括测试逻辑模块和物理层(PHY)接口模块,其中 PHY 接口 通过中间介质层与 CPU/图形处理器(GPU)/片上系统(SoC)直接高速连通, 直接存取(DA)端口提供 HBM 中多层 DRAM 芯片的测试通道。中间介质层通过 微凸块连接到封装基板,从而形成 2.5D 的 SiP 系统。 JEDEC 发布 HBM1 行业标准,多层 DRAM 提升存储容量,多通道数提升访 存性能。国际电子元件工业联合会(JEDEC)发布的第一个 HBM 标准 JESD235 定义了具有 1024bit 接口和单引脚 1Gbit/s 数据速率的 HBM1 存储芯片,该芯片 堆叠了 2 个或 4 个 DRAM,在基本逻辑芯片上,每个 DRAM 芯片具有 2 个 128bit 通道,共有 8 个阵列(B0~B7),最多支持 8 个 128bit 通道(CH0~CH7), 总带宽为 128 GB/s。每个通道实质上是具有 2n(n 代表总线位宽)预取架构的 128 bit DDR 存储器接口,主要包括 128 bit 数据、8 bit 行命令地址和 6 bit 列命 令地址、源同步时钟、校验、数据屏蔽等信号,还包括复位、IEEE 1500 测试端 口和电源、地等公共信号。访存的读、写操作过程基本与 DDR 存储器芯片相同。 HBM1 芯片具备半独立的行、列命令接口,支持读、写命令与其他命令并行执行, 增加了命令接口带宽,提高了访存性能。
较传统 DDR,HBM 高带宽性质打破内存墙,满足 AI 高性能动态存储需求。 1)高速及带宽:虽然 HBM2E 和 HBM3 单引脚最大 I/O 速度不如 GDDR5, 但 HBM 的堆栈方式可以通过更多的 I/O 数量提供远高于 GDDR5 存储器的总带 宽。如 HBM2(1024)带宽可以达到 307 GB/s,而 GDDR5 存储器(32)的带 宽仅为 28 GB/s。 2)低功耗: 由于采用了 TSV 和微凸块技术,DRAM 裸片与处理器间实现了 较短的信号传输路径以及较低的单引脚 I/O 速度和 I/O 电压,使 HBM 具备更好 的内存功耗能效特性,相比传统 GDDR5 存储器,HBM2 的单引脚 I/O 带宽功耗 比数值降低 42%。 3)小体积:HBM 将原本在 PCB 板上的 DDR 内存颗粒和 CPU 芯片一起 全部集成到 SiP 里,因此 HBM 在节省产品空间方面也更具优势,相比于 GDDR5 存储器,HBM2 能节省 94%的芯片面积。
HBM 与先进封装相辅相成。对于 GDDR,32 个引脚只需要铜线相连即可, 不需要单独做微缩处理;而 HBM 引脚数多达 1024 个,在 PCB 板上直接通过铜 线连接并非易事。CoWoS 等 2.5D 先进封装技术通过在 HBM 与 PCB 板之间添加 中介层,以支持 HBM 的高引脚数和短走线长度需要,能够实现 PCB 及封装基板 上无法实现的密集互连。2012 年,台积电开发出可实现异构封装的 CoWoS,2014 年 AMD 与 SK 海力士合作开发 TSV(Through Silicon Via)HBM 产品,采用 HBM 的产品开始正式发布。
2.2.2. 从 HBM1 到 HBM3E 性能倍增,三大厂竞争亦越演愈烈
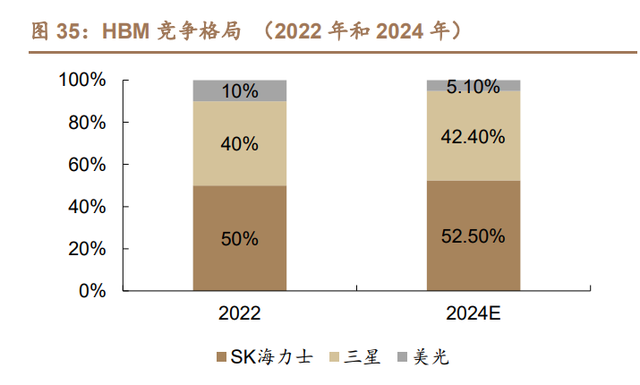
HBM 三大制造商 SK 海力士官网、三星和美光间竞争愈演愈烈。最早由 SK 海力士官网量产 HBM1,HBM2 则是三星拔得头筹。当英伟达 GPU 引爆市场时, SK 海力士官网也凭借率先量产 HBM3 而大获成功。美光最初开发 HMC(混合内 存立方体),而随着 JEDEC 正式认证 HBM 标准,美光在 2018 年放弃 HMC,并 在大幅落后韩国两家制造商后开始 HBM 的开发。据 TrendForce 预测,2024 年 SK 海力士官网可能获得全球市场 52.5%的份额,其次是三星(42.4%)和美光 (5.1%)。
三大制造商新设 HBM 工厂或于 2025 年完工。SK 海力士官网于 2023 年开 始在其工厂 M15 生产 HBM,M16 预计 2025 年实现产能扩张,到 2025 年其在建 的 M15X 工厂将生产 HBM3E 和 HBM4。三星于 2023 年在显示器工厂开始生产HBM,2024 年现有厂房预计接近满产,新厂房 P4L 规划于 2025 年完工。美光或 跳过 HBM3,计划直接参与 HBM3E 的竞争,其 Boise 厂区预期于 2025 年完工 并陆续移机,并计划于 2026 年量产。根据 TrendForce,尽管三大原厂的新厂将 于 2025 年完工,但部分厂房后续的量产时程尚未有明确规划,需依赖 2024 年的 获利,才得以持续扩大采购机台。
从市场表现来看,2024 年上半年 HBM3 为主流,三星 HBM3 通过验证后开 始急转直追。据 TrendForce 在 2024 年 3 月 13 日的报道,截至当时 HBM3 为 2024 年的市场主流。在 HBM3 的产品竞争中,SK 海力士官网的市占率超 9 成。 2024 年 Q1,三星 HBM3 产品陆续通过 AMD MI300 系列验证,市占率急转直追。 美光没有加入 HBM3 供应竞争。 HBM3e 将集中在 2024 年下半年出货。2024 年 5 月 20 日 TrendForce 指出, HBM3e 将在今年成为市场主流,出货量集中在下半年。目前,SK 海力士官网仍 然是主要供应商,与美光一起,都使用 1beta nm 制程,并且都已开始向英伟达供 货。三星使用 1alpha nm 制程,预计将在第二季度完成认证,于年中开始交付。 HBM4 有望 2026 年上市。据 TrendForce,HBM4 预计规划于 2026 年推出。 随着客户对运算效能要求的提升,在堆栈的层数上,HBM4 除了现有的 12 层外, 也将再往 16 层发展。HBM4 12 层产品将于 2026 年推出;而 16 层产品则预计于 2027 年问世。此外,受到规格更往高速发展带动,将首次看到 HBM 最底层的逻 辑芯片采用 12nm 制程 wafer,该部分将由晶圆代工厂提供,使得单颗 HBM 产品 需要结合晶圆代工厂与存储器厂的合作。
2.2.3. HBM 单位价格远高于传统存储器,AI 服务器需求猛增有望拉动出货
主流 GPU 芯片的 HBM 用量提升。英伟达 A100 芯片内存分 40GB 和 80GB 两个版本,分别采用 5 颗 HBM2 或 HBM2E;H100PCIe 版本内存 80GB,使用 5 颗 HBM2E;H200 内存 141GB,使用 6 颗 HBM3E;最新发布的 B100 和 B200 内存达到 192GB,使用 8 颗 HBM3E。
价:根据微细加工研究所及 Yole 测算数据,HBM 价格远高于传统 DRAM。 1)单位 GB 价格:无论是各类 HBM 还是常规 DRAM,通常在刚上市时单位 GB 的价格最高,随后价格呈现减少趋势。但是 DRAM 和 HBM 在单位 GB 的价 格会相差 20 倍以上。在 2019 年普通 DRAM 单位 GB 的价格为 0.49 美元,而 HBM2 却是 11.4 美元,高出 23 倍;HBM2E 刚上市时价格为 13.6 美元,高出 28 倍;HBM4 预计上市时价格达到 14.7 美元,高出近 30 倍。 2)HBM 平均价格远高于 DDR 成本:对比 HBM 的平均价格,HBM2 最高价 格为 73 美元,HBM2E 为 157 美元,HBM3 为 233 美元,HBM3E 为 372 美元, HBM4 则达到 560 美元。此外,DRAM 制造商采用 1z 节点工艺生产的 16GB DDR5 DRAM 成本最高为 3-4 美元,而 2024 年 SK 海力士官网发布的 HBM3E 价 格却达到 361 美元,高出约 90-120 倍。
量:AI 服务器出货量高涨,HBM 渗透率大幅提升。 据 IDC 统计,2023 年全球 AI 服务器市场规模预计为 211 亿美元,2025 年 将达到 317.9 亿美元,2023-2025 年 CAGR 为 22.7%。出货量方面,根据 TrendForce 数据,2023 年 AI 服务器出货量近 120 万台,占据服务器总出货量的 近 9%,年增长达 38.4%。TrendForce 预计 2026 年,AI 服务器出货量为 237 万 台,占比达 15%,2024-2026 年复合年增长率约 25.50%。 据 TrendForce 预测,2023-2024 年,产能方面,HBM 占 DRAM 总产能分别 是 2%和 5%,到 2025 年占比有望超过 10%;产值方面,2024 年起 HBM 占比 DRAM 总产值预估可超过 20%,到 2025 年有机会超过 30%。TrendForce 认为 2024 年 HBM 需求增长率接近 200%,2025 年可望将再翻倍。
目前市场上主流的 AI 服务器配置 8 个 GPU 芯片,每个 GPU 芯片配备多个 HBM 芯片,结构上 HBM 芯片中又包含堆叠的 HBM 颗粒,因此可以根据 AI 服务 器出货量推算 GPU 用量个数、HBM 芯片用量个数及 HBM 颗粒的需求量,并由 此测算制备 HBM 芯片所需的晶圆产能需求。根据 TrendForce 集邦咨询资深研究 副总吴雅婷,在同制程同容量下,HBM 颗粒较 DDR5 尺寸大 35%-45%,DDR5面积约 70mm²,HBM 颗粒尺寸约 100mm²,那么每个 12 英寸晶圆除去边角料可 切割约 640 颗;此外 TrendForce 估计 HBM 良率约 50-60%,则每片晶圆切割约 300 个 HBM 颗粒。我们测算得到制造 HBM 颗粒的晶圆产能需求,2023 年约 10.52 万片/月,2024 年约 19.55 万片/月。
3. 本土先进封装产业链:厚积薄发、加速成长
3.1. 刻不容缓:海外高性能芯片管制加强,AI 芯片自主可控大势所趋
美国对高性能芯片出口限制不断加强,英伟达先进芯片供应受阻。 第一阶段,切断 A100 及性能更优的芯片供应:2022 年 10 月 7 日,美国商 务部文件提出对先进计算集成电路的出口限制规则 ECCN 3A090 和 4A090,当 时英伟达热卖的 A100 芯片精准落入限制范围。 后续:为应对出口管制,禁令发布一个月后,英伟达推出替代版 A800。对于 随后推出的 H100,英伟达也如法炮制推出替代版 H800,以避免贸易限制。 第二阶段,扩大管治范围,替代版供应也受限:2023 年 10 月 17 日,美国商 务部发布新的管制规则,如果芯片超过 ECCN 3A090 中标定的两个参数, 3A090.a(“总处理性能”)和 3A090.b(“性能密度”)之一,出口就会受到限制。 新规则实际扩大了管制范围,A800 和 H800 也被纳入出口管制范围。此外英伟达 其他产品也受到了影响,包括推理领域的 L40、L40S 和消费领域的 RTX4090。 后续:2023 年 11 月 16 日,英伟达又推出特供中国的 GPU 芯片:H20、L20、 L2,以及针对消费市场的平替 RTX 4090D。
英伟达 H20 为目前可在中国销售的最高性能产品。基于 FP16 Tensor Core 的浮点计算能力(FP16 Tensor Core FLOPs),理论上 H100 比 H20 的速度快 6.68 倍。虽然 H20 性能大减,但在国产 AI 芯片供应不足的情况下,中国互联网厂商或 许也不得不采购 H20 芯片。SemiAnlaysis 预测英伟达有望在 2025 财年交付超过 100 万个 H20 芯片,预计每个芯片售价为 1.2-1.3 万美元。H20 应用 CoWoS 封 装技术。
中国智能算力市场需求旺盛。根据中国信息通信研究院发布的《中国综合算 力指数(2023 年)》,截至 2023 年 6 月底,中国算力产业保持高速增长,达到 197EFLOPS,智能算力规模占比整体算力规模的比例提高到 25.4%,智能算力规 模同比增长 45%,比算力规模整体增速高 15%。自 2018 年 6 月到 2023 年 6 月, 中国算力总规模年均增速近 30%,数据中心机架数量年复合增长率超过 30%。 供需不平衡背景下,国内必须发展相关产业链: 华为昇腾:提供峰值达 256T FLOPS(Floating Point Operations per Second) 半精度浮点计算能力、32GB 的 HBM、1200GB/s 内存带宽、多加速器间 100G RoCE v2 高速网络。昇腾 910B 性能对标英伟达 A100,采用先进的达芬奇架构, 支持深度学习、推理等 AI 计算任务,半精度(FP16)计算能力高达 320 TFLOPS, 整数精度 (INT8) 计算能力达到 640 TOPS,同时功耗为 310W。 寒武纪:思元 290(MLU290)芯片是寒武纪首款云端训练智能芯片,采用了 7nm 工艺,在 4 位和 8 位定点运算下,理论峰值性分别高达 1024TOPS、 512TOPS。思元 370(MLU370)芯片是寒武纪首款采用 Chiplet(芯粒)技术的 人工智能芯片,是寒武纪第二代云端推理产品思元 270 算力的 2 倍。 海光信息:海光 DCU 属于 GPGPU(通用图形处理器,General-Purpose Graphics Processing Unit),能够支持全精度模型训练,实现 LLaMa、GPT、Bloom、 ChatGLM、悟道、紫东太初等为代表的大模型的全面应用,与国内包括文心一言 等大模型全面适配,达到国内领先水平。
在中美竞争背景下,先进 EUV 光刻机的禁令为国产芯片制程迭代带来巨大 阻力。先进封装为超越摩尔定律另辟蹊径,有望助力国产半导体产业“弯道超车”。 光刻机禁令更进一步:2019 年 ASML 的 EUV 光刻设备被禁止向中国出售。 2024 年最先进的 DUV 光刻机 NXT:2050i 和 NXT:2100i 的出货许可证也被荷 兰政府吊销,这两种型号的光刻设备可广泛应用于 40nm 以下的工艺容量,对应 28nm、14nm、10nm、7nm 制程工艺。随着禁令生效,几乎堵死国产芯片先进制 程的提高。 集成工艺助力芯片能跨越 1-2 个工艺节点:先进封装通过多颗芯粒和基板的 2.5D/3D 集成,突破单芯片光刻面积的限制和成品率随面积下降的问题,成为进 一步提升芯片性能的可行路径。而且,集成芯片技术是一条不单纯依赖尺寸微缩 路线提升芯片性能的重要途径,在短期内难以突破自主 EUV 光刻机和先进节点制 造工艺的情况下,可以提供一条利用自主低世代集成电路工艺实现跨越 1-2 个工 艺节点的高端芯片性能的技术路线。
3.2. 提前布局:国产封装大厂打开成长空间
封测产业是中国集成电路最具国际竞争力的环节。纵观全球半导体产业发展 历程,经历了由美国向日本、向韩国和中国台湾地区及中国大陆的几轮产业转移, 而封装产业则是产业转移的桥头堡。据芯思想研究院发布的统计数据,2023 年全 球半导体委外封测(OSAT)营收前十大企业合计占比 77.65%份额,其中,中国 台湾有 5 家(日月光、力成科技、京元电、南茂科技、颀邦科技),市占率累计 37.73%;中国大陆有 4 家(长电科技、通富微电、天水华天、智路封测),市占率 累计 25.83%;美国有 1 家(安靠科技),市占率 14.09%。
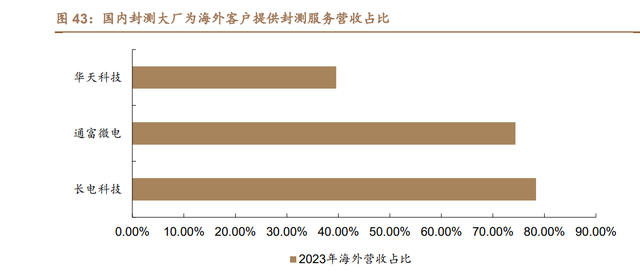
布局海外市场是国内封测大厂重点战略。先进封装上市企业中,布局国内、 国外的企业数量较为均衡。华天科技、甬矽电子等企业重点布局国内市场,长电 科技和通富微电等企业积极布局海外市场。根据各公司披露数据,2023 年长电科 技海外业务营收 232.49亿元,占比总营收 78.38%;通富微电海外业务营收165.60 亿元,占比总营收 74.36%。此外国内第二大封测厂通富微电已与 AMD 形成“合 资 合作”联合模式,成为 AMD 最大的封装测试供应商,为 AMD AI PC 芯片及 工作训练推理用 AI 加速器提供封测服务,目前通富微电已进入全球先进半导体供 应链,并获得 CPU、GPU、APU 等封装及测试的订单。
本土封装龙头企业积极推进先进封装技术。以长电科技为代表的几家国内封 测龙头通过并购重组国际先进封装测试企业,消化吸收并自主研发先进封装技术, 在先进封装领域不断发力,现已具备较强的市场竞争力。此外,以多种封装技术 服务多种集成电路产品、多种应用领域的综合性集成电路封测企业仍是市场发展 的主要力量,除了长电科技、通富微电、华天科技三巨头之外,也涌现出甬矽电 子、利普芯、华宇电子等一批成长型企业。
本土 HBM 稳步推进。据 Trendforce 报道,国内存储厂商武汉新芯(XMC) 和长鑫存储(CXMT)正处于 HBM 制造的早期阶段,目标 2026 年量产,主要是 为了应对未来人工智能(AI)和高性能计算(HPC)领域的应用需求。其中武汉 新芯正在针对 HBM 建造月产能 3000 片晶圆的 12 英寸工厂,长鑫存储则与封装 和测试厂通富微电合作开发了 HBM 样品,并向潜在的客户展示。
3.3. 未来可期:本土先进封装相关设备/材料有望受益
3.3.1. 先进封装工艺流程提出更高要求
先进封装工艺对于传统的半导体封测设备提出更高要求。 传统封装中封测设备主要对应引线键合工艺中的八大工序:背面减薄、晶圆 切割、贴片、固化、引线键合、模塑密封、切筋成型、FT 测试。按照工艺流程, 传统封测需要的设备包括:减薄机/贴膜机、晶圆安装机/划片机/清洗设备、贴片机、 固化设备、引线键合机、塑封机、切筋成型机以及分选机和测试机。 先进封装要求更高:据全景财经,①随着芯片堆叠层数增加,为保证芯片体 积较小,对于减薄设备精度提出要求。②在异构集成设计中,制造小芯片需要更 多切割和贴合,使得划片机、贴片机的用量和精度提升。③异构集成中需要对每 个裸片进行测试,系统集成后还需要整体测试,也增加了测试设备需求。
先进封装中芯片级封装工艺及设备需求:a)装片工艺:把芯片从晶圆上取下, 安装到引线框架、多层基板或载体上,使用装片机(DB)。b)键合工艺:用引线键合 或倒装芯片方法完成芯片上焊盘和引线框架、多层基板或载体上引脚的连接,使 用引线键合机或倒装芯片键合机。 先进封装中塑封及后序工艺及设备需求:主要把安装好和键合好的芯片用塑 封料进行包封,然后再固化、打印、切割、测试、编带包装等工艺过程,所需设备 包括塑封压机、固化炉、装片机、切割机等。
先进封装工艺可视为晶圆制造和封测前后道制程中出现的中道交叉区域。先 进封装除了在传统封测环节上升级,还要求在晶圆划片前融入封装工艺步骤,具 体包括应用晶圆研磨薄化、线路重排(RDL)、凸块制作(Bumping)及三维硅通 孔(TSV)等工艺技术。上述先进封装工艺技术涉及与晶圆制造相似的光刻、显 影、刻蚀、剥离等工序步骤,从而使得晶圆制造与封测前后道制程中出现中道交 叉区域。目前,带有倒装芯片(FC)结构的封装、晶圆级封装(WLP)、系统级封 装(SiP)、2.5D 封装、3D 封装等均被认为属于先进封装范畴,上述先进封装大 量使用 Bumping、RDL、TSV 等工艺技术。
晶圆级工艺催生前道设备需求。据《先进封装关键工艺设备面临的机遇和挑 战》(王志越等)总结,晶圆级封装(WLP)的工艺在晶圆上进行的关键技术包括: 重新布线技术、凸点制造技术、硅通孔互连技术、扇出技术、以及晶圆减薄技术和 晶圆划片技术。其它先进封装形式如 BGA、CSP、3D 封装和 SiP 所涉及的晶圆工艺主要是晶圆减薄技术和晶圆划片技术。晶圆级封装催生了掩膜设备、涂胶设 备、溅射台、光刻机、刻蚀机等前道设备需求。
Bumping 工艺以凸块替代传统封装中的金线键合,涉及前道光刻、刻蚀、沉 积工艺等相关设备。以常用的电镀 Bump(凸块)工艺为例,制备流程包括:晶 圆、溅射 UBM(凸块下金属化层)、涂敷光刻胶、曝光显影、电镀铜及焊料金属 层、去胶、去除种金层、回流焊。制备过程中涉及到的设备包括:涂胶机、溅射 台、光刻机、印刷机、电镀线、回流焊炉、植球机;涉及材料包括:金属材料、电 镀液、光刻胶、剥离液、焊料等。
据《集成电路先进封装材料》,RDL 制备工艺包括电镀铜 RDL、大马士革 RDL 以及金属蒸镀 金属剥离 RDL。RDL 工艺涉及的设备:涂布设备、清洗设备、显 影设备、刻蚀设备、沉积设备、剥膜设备等。RDL 工艺涉及的材料:金属材料、 聚酰亚胺(PI)、光刻胶、湿化学品、电镀液、剥离液等。 电镀铜 RDL:工艺简单,适合制作线宽/间距(L/S)在 5/5μm 以上的 RDL 结构,且电镀铜层具有良好的导电性、导热性和机械延展性。缺点是当多层叠加 时,交叉线路层不平整,容易引起线条变形,造成线条间电容/电感变异。 大马士革 RDL:当 RDL 的线宽和线距为 2/2μm 甚至低于 1/1μm 时,受限于钝化层材料(如聚酰亚胺)的分辨率及电镀种子黏附层的腐蚀工艺等,电镀方 式不再是最佳的工艺选择。利用前道晶圆制造中大马士革工艺原理的 RDL 工艺应 运而生,基于该工艺的各金属层厚度更均匀。 金属蒸镀 金属剥离 RDL(Metal Lift Off. MLO):该工艺对工艺设备与材料 要求较低,并且比电镀铜的应力大,是一种低成本的高密度 RDL 制作工艺。
据合明科技,TSV 是 3D 集成的关键技术,其填充效果直接关系到芯片的可 靠性。TSV 制作工艺难度较大,包括打孔、沉积、电镀、CMP、减薄等诸多环节。 1)孔成型:主要方式包括激光打孔、干法刻蚀、湿法刻蚀等。基于深硅刻蚀 (Bosch 工艺)的方法目前最广泛应用。 2)沉积绝缘层:TSV 孔内绝缘层用于实现硅衬底和孔内传输通道的绝缘,防 止 TSV 通孔之间的漏电和串扰。 3)沉积阻挡层/种子层:在 2.5D TSV 中介层工艺中,一般使用铜为 TSV 通 孔内部金属互连材料。 4)电镀填充工艺:TSV 深孔刻蚀的填充技术是 3D 集成的关键,关系到后续 器件的电学性能和可靠性。 5)CMP(化学机械抛光)工艺和背面露出工艺:CMP 技术用于去除硅表面 的二氧化硅介质层、阻挡层和种子层;TSV 背面露出技术也是 2.5D TSV 转接基 板的关键工艺。6)晶圆减薄:晶圆表面平坦化后,还需要使用晶圆背面的减薄使 TSV 露出。
TSV 的制备工艺分为三类:Via First、Via Middle 和 Via Last。TSV 可以在 IC 制造的开始制作(Via-First),也可以在 IC 制造过程中制作(Via-Middle),也可以 在 IC 制造完成之后制作(Via-Last)。 Via First 工艺流程:TSV 制备-CMP(化学机械平坦化)-FEOL(IC 前道工 序)-Thinning(减薄)-BEOL(IC 后道工序); Via Middle 工艺流程:FEOL- TSV 制备-CMP-Thinning-BEOL; Via Last 工艺流程:FEOL-BEOL-Thinning-TSV 制备-CMP。
3.3.2. 建议关注配套设备国产厂商:
先进封装对于固晶机、晶圆减薄机、晶圆划片机和键合机等后道设备提出更 高要求。 固晶机:也称装片机(Die Bonder),用于集成电路(IC)、功率 IC、晶体管等 产品的后道封装,是封测的芯片贴装(Die attach)环节中最关键、最核心的设备。 用于将芯片从晶圆蓝膜上取出连接到框架(LEADFRAM)或基板上。主流机器都采 用全自动上下料,将自动识别、自动点胶、工作平台自动到位、自动装载芯片集成 在一起,形成高度自动化设备。 新益昌:国内固晶机头部企业,产品已从传统 LED 扩展到半导体和 MiniLED 市场。公司半导体固晶机具有较强的市场竞争力及较高的产品知名度,封测业务 涵盖 MEMS、模拟、数模混合、分立器件等领域,为包括华为、长电、华天科技、 通富微、固锝电子、扬杰科技、韶华科技等知名公司在内的庞大优质客户群体提 供定制化服务。
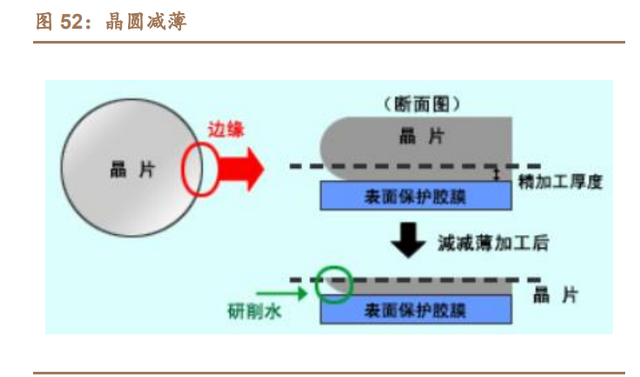
晶圆减薄机:根据《先进封装关键工艺设备面临的机遇和挑战》(王志越等), 随着先进封装尤其 3D 封装的要求越来越苛刻,晶圆减薄工艺越来越重要。国际 上,把芯片和晶圆的厚度分为 3 个等级:常规的厚芯片和晶圆:300~1000μm;薄芯 片和晶圆:100~300μm;超薄芯片和晶圆:50~100μm 及以下。超薄芯片和晶圆又 分为三级,即 50~100μm;10~50μm 和小于 10μm。晶圆减薄目前应用需减薄到 大约 50μm,而在将来需减薄到约 25μm 以下。需要薄芯片和晶圆的主要目的在 于减小形状因子、提高封装密度、减小热阻、提高柔性和可靠性,以及提高成品率。 随晶圆厚度越小,晶圆减薄机的重要性逐渐增加。 华海清科:公司开发的 VersatiIe-GP300 减薄抛光一体机适用于先进封装和 前道晶圆制造的背面减薄工艺,满足 3D IC 对超精密磨削、CMP 及清洗的一体化 工艺需求,在客户端验证顺利。2023 年已推出 VersatiIe-GP300 量产机台,并新 开发双重智能 TTV(总厚度偏差)控制系统,突破传统减薄机的精度限制,稳定 实现 12 英寸晶圆片内磨削 TTV< 0.8μm 达到了国内领先和国际先进水平。
晶圆划片机:据《先进封装关键工艺设备面临的机遇和挑战》(王志越等), 基本无损地把整个晶圆划切成单个的集成电路芯片后才能进行装片和引线键合等 工艺。由于划片的对象是成本昂贵的晶圆,划片设备必须具有高精度和高可靠性。 先进 3D 叠层封装要求晶圆及芯片的厚度越来越薄,甚至到了 50μm 以下。超薄晶 圆对机械应力和热应力非常敏感,要求划片过程应力越小越好。 光力科技:全球排名前三的半导体切割划片装备企业,并同时拥有切割划片 量产设备、核心零部件——空气主轴和刀片等耗材,可以为客户提供个性化的划 切整体解决方案。公司在半导体后道封装领域布局精密加工设备、高性能高精度 空气主轴等核心零部件和耗材。经过多年努力,公司已与日月光、嘉盛半导体、长 电科技、通富微电、华天科技等国内外封测头部企业建立了稳定的合作关系。
混合键合机:据未来半导体公众号,混合键合是堆叠芯片之间获得更密集互 连的方法,将介电键合 (SiOx) 与嵌入式金属 (Cu) 结合起来形成互连形成电介 质-电介质和金属-金属键,使用紧密嵌入电介质中的微小铜焊盘可提供比铜微凸块 多 1,000 倍的 I/O 连接。据拓荆科技 2023 年报,混合键合设备可以提供键合面 小于 1μm 互连间距,相比先进封装领域目前成熟的微凸点技术(Micro Bump) 可实现 40-50μm 互连间距,混合键和设备可以使芯片间通信速度达到业界更高 水平,从而提高系统性能。 拓荆科技:2023 年,公司首台晶圆对晶圆键合产品 Dione 300 顺利通过客户 验证,并获得复购订单,复购的设备再次通过验证,实现了产业化应用,成为国产首台应用于量产的混合键合设备,目前该设备的性能和产能指标均已达到国际领 先水平。此外,2023 年公司推出的芯片对晶圆混合键合前表面预处理产品 Propus 发货至客户端验证,并在当年即通过客户端验证,实现了产业化应用,成为国产 首台应用于量产的同类型产品。
先进封装受益材料包括 PSPI、临时键合胶、环氧塑封、电镀液、硅中介板。 PSPI(光敏聚酰亚胺):封装光刻胶 PSPI 是一种光敏性聚酰亚胺材料,兼 具光刻胶的图案化和树脂薄膜的应力缓冲、介电层等功能,主要应用于晶圆级封 装(WLP)中的凸块(Bumping)制造工艺中,使用时先涂覆在晶圆表面,再经 过曝光显影、固化等工艺,可得到图案化的薄膜。 鼎龙股份:2023 年 11 月,鼎龙(仙桃)半导体材料产业园投产,这标志着 全球第二条、国内首条千吨级半导体显示光刻胶 PSPI 生产线正式投用,率先打 破了这款材料长期被国外企业垄断的局面。
临时键合胶:临时键合胶作为超薄晶圆减薄、拿持的核心材料,可将器件晶 圆临时固定在承载载体上,从而为超薄器件晶圆提供足够的机械支撑,防止器件 晶圆在后续工艺制程中发生翘曲和破片,最后临时键合胶可通过光、热和力等解 键合方式完成超薄晶圆的释放。临时键合胶主要用于 2.5D/3D 封装。 飞凯材料:针对目前半导体制造中临时键合工艺的应用,公司开发出包含键 合胶、光敏胶、清洗液的整套临时键合解决方案,该方案支持热拆解、机械拆解以 及激光拆解。飞凯材料提供的临时键合方案对基材有很好的吸附力,使用温度高达 350°C,同时耐 Fan-out、TSV 工艺中的有机溶剂、酸、碱等化学药水,具有很好的 稳定性和安全性。
电镀液:主要由加速剂、抑制剂及整平剂组成,通过不同组分相互作用,能 够实现从下到上的填充效果以及改善镀层晶粒、外观及平整度,是芯片制造和封 装的核心原材料。后端封装的电镀是指在芯片封装过程中,在三维硅通孔、重布 线、凸块工艺中进行金属化薄膜沉积的过程,随着集成电路中互连层数、先进封 装中对 RDL 和铜柱结构使用的增加,铜互连材料需求将持续增长。 艾森股份:在电镀液及配套试剂方面,公司在持续夯实传统封装国内龙头地 位的基础上,逐步在先进封装以及晶圆 28nm、14nm 先进制程取得突破。在先 进封装领域,公司先进封装用电镀铜基液(高纯硫酸铜)已在华天科技正式供应; 先进封装用电镀锡银添加剂已通过长电科技的认证,尚待终端客户认证通过;先 进封装用电镀铜添加剂已完成测试认证,现处于批次稳定性验证。2023 年度,公 司电镀液及配套试剂销售收入为 1.79 亿元,同比增长 21.80%,表现出良好的增 长势头。
安集科技:在电镀液及添加剂产品板块,公司完成应用于集成电路制造及先 进封装领域的电镀液及添加剂产品系列平台的搭建,并且在自有技术持续开发的 基础上,通过国际技术合作等形式,进一步拓展和强化了平台建设,包括技术平 台及规模化生产能力平台,从而提升了公司在此领域的一站式交付能力。公司先 进封装用电镀液及添加剂已有多款产品实现量产销售,产品包括铜、镍、镍铁、锡 银等电镀液及添加剂,应用于凸点、重布线层(RDL)等技术。 天承科技:公司自主研发并掌握了 PCB、封装载板、光伏、显示屏、集成电 路等相关的沉铜、电镀产品制备及应用等多项核心技术,主要产品包括水平沉铜专用化学品、电镀专用化学品、铜面处理专用化学品、垂直沉铜专用化学品、SAP 孔金属化专用化学品(ABF 载板除胶沉铜)、其他专用化学品等,应用于沉铜、电 镀、棕化、粗化、退膜、微蚀、化学沉锡等多个生产环节。23 年公司研发的 RDL、 bumping、TGV、TSV 等部分先进封装电镀液产品已推向下游测试验证。 上海新阳:公司开发的电镀液及添加剂是实现互联技术的关键工艺材料,公 司产品包括大马士革铜互连、TSV、Bumping 电镀液及配套添加剂。经过多年开 发、技术储备以及与客户紧密的联系,24H1 报告期内公司电镀液添加剂相关产品 销售规模快速提升,相比去年同期增长超 80%,新品研发验证工作顺利推进。
环氧塑封材料:应用于集成电路、分立器件等半导体的封装,90%以上的集 成电路均采用环氧塑封料作为包封材料,环氧塑封料已成为半导体产业发展的关 键支撑产业。随着 Chiplet、HBM 等先进封装技术和工艺的不断发展,对于封装 材料提出了更高的要求,先进封装中的 QFN/BGA、FOWLP/FOPLP 等因其不对 称封装形式而增加了对环氧塑封料的翘曲控制要求,同时要求环氧塑封料在经过 更严苛的可靠性考核后仍不出现任何分层且保持芯片的电性能良好。 华海诚科:公司专注于向客户提供更有竞争力的环氧塑封料与电子胶黏剂产 品,构建了可应用于传统封装(包括 DIP、TO、SOT、SOP 等)与先进封装 (QFN/BGA、SiP、FC、FOWLP 等)的全面产品体系,可满足下游客户日益提 升的性能需求。公司已与长电科技、通富微电、华天科技、银河微电、扬杰科技等 业内领先及主要企业建立了稳固的合作伙伴关系。 联瑞新材:公司产品作为性能优异的无机非金属粉体填料,具有高纯度、高 填充、高耐热、高绝缘、低线性膨胀系数、导热性好、介电损耗低等优良特性,其 中球形硅微粉则因其高填充、高流动、低磨损、低应力的特性大量用于高端半导 体器件封装,特别是精确控制粗大粒子的球形硅微粉,还可用于窄间隙封装的环 氧塑封料。 24H1 报告期内,公司聚焦高端芯片(AI、5G、HPC 等)封装、异构 集成先进封装(Chiplet、HBM)等下游应用领域的先进技术,持续推出多种性能 优异的产品,加强高性能功能性粉体材料研究开发。

 VIP复盘网
VIP复盘网
