

TPU被低估了。
看完谷歌最新发布的第8代TPU,我终于理解马斯克说这句话的含义了。
确实,谷歌专为Agent时代打造的第8代TPU,亮点显而易见:
一是在「训推分离」这条路上,谷歌比英伟达走得更彻底——
直接推出了两款物理上完全不同的芯片。
面向训练的TPU 8t:整体计算性能是上一代产品Ironwood的近三倍,能将模型训练周期从数月缩短至数周。
面向推理的TPU 8i:在成本不变的情况下,能让服务能力翻倍。

二是在能效上,谷歌继续发力——
采用第四代液冷技术,第8代TPU每瓦性能比上一代Ironwood提升了近两倍。
性能和能耗两个问题一解决,Agent的大规模落地才算真正有了可能。
也正因此,这次第8代TPU一发布,就在引发了不小的讨论:
这才是真正能带来变革的硬件升级。
市场的反应也来得很直接。
就在第8代TPU亮相发布会后,Alphabet股价盘中最高涨幅2.2%,显示出资本市场对这一方向的初步认可。
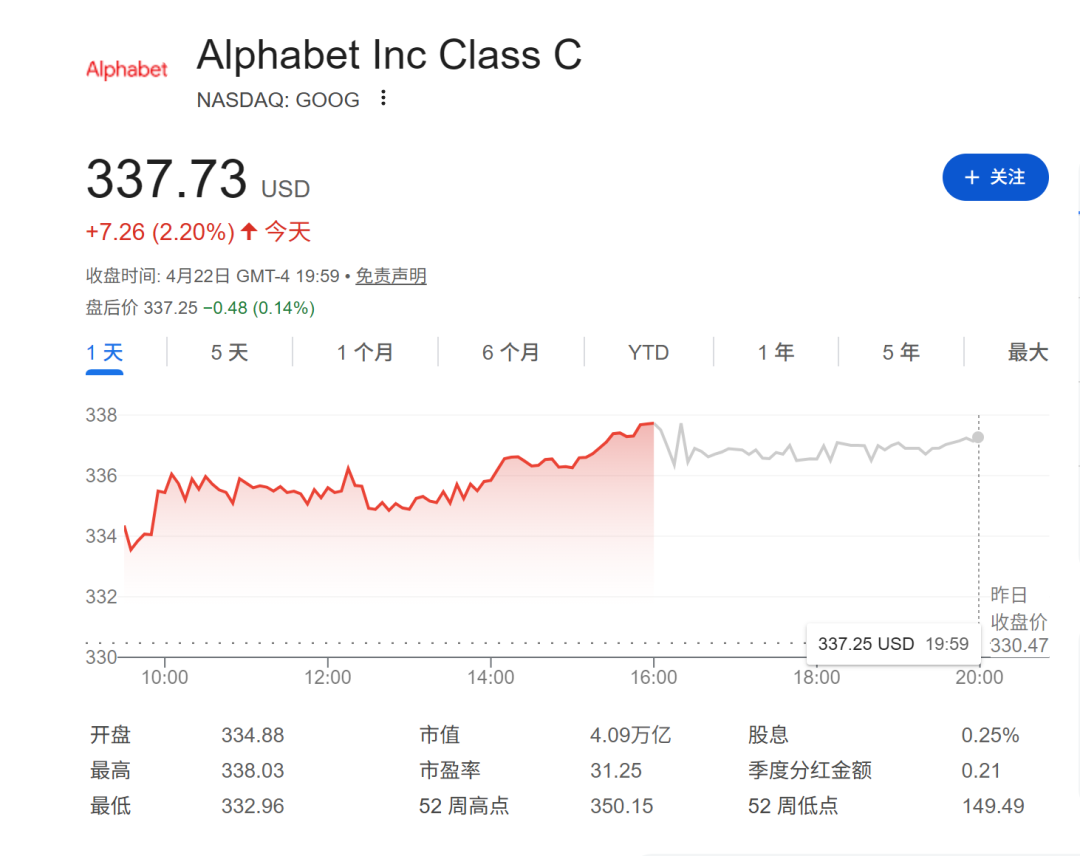
预计这两款芯片将在今年晚些时候正式上市。
Gemini参与设计、谷歌放出两款芯片细节
值得一提的是,谷歌第8代TPU背后还有Gemini的手笔。
虽然谷歌没有透露Gemini具体参与了哪些环节,但博客里可是给它署了名(Co-designed)。
而凝聚「人机智慧」的第8代TPU,这次分别朝着训练和推理两个方向极致开卷——
最终也诞生了8t和8i两款芯片。
笑死,网友还脑洞大开想到了一句如何区分它们的口诀:
横屏用于训练,竖屏用于推理。

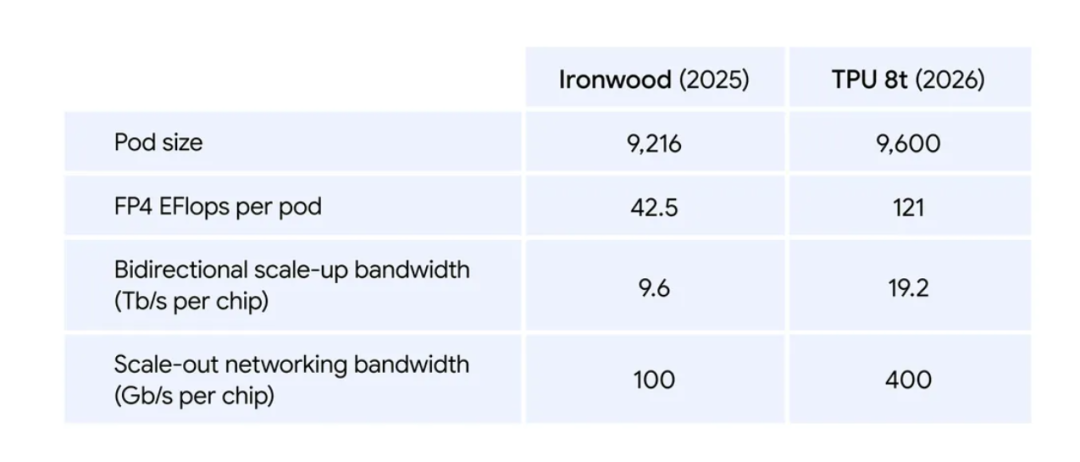
先看右手边专攻训练的8t。
对比上一代Ironwood,8t直接把「规模、效率、稳定性」三件事一起拉满了:
规模:单个超级芯片组可扩展至9600个芯片 2PB共享高带宽内存,芯片间带宽翻倍,总算力达到121 ExaFlops,支持模型直接运行在统一超大内存池中。
利用率:存储访问速度提升10倍,配合TPUDirect数据直连,让算力不再空转,尽可能把资源吃满。
扩展性:基于Virgo网络 JAX Pathways,实现近乎线性扩展,单一逻辑集群可延伸至百万级芯片规模。
稳定性:通过实时遥测、自动绕过故障链路(ICI)、光路交换(OCS)等机制,在超大规模下仍能维持运行连续性,有效吞吐目标最高可达97%。
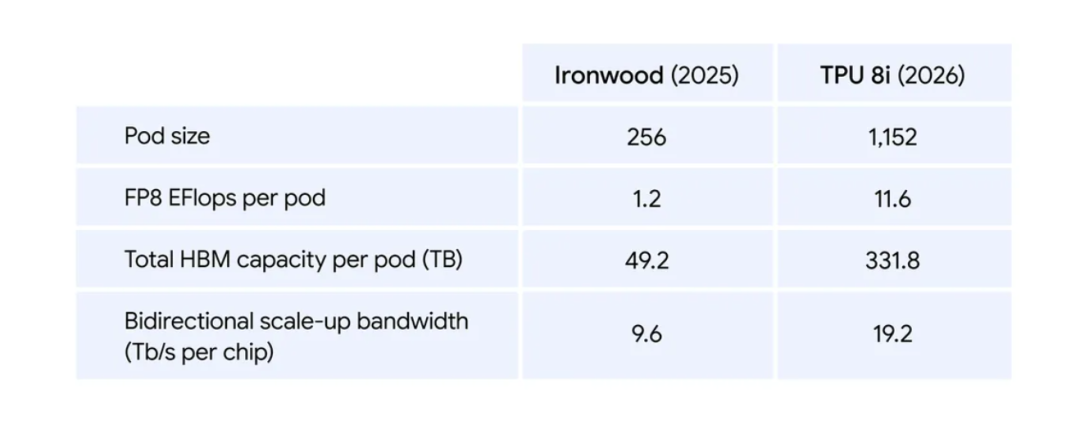
而专攻推理的8i,则完全是另一套思路,核心就三个字:
低延迟。
为此,谷歌几乎是从底层把整套推理栈重做了一遍:
内存:直接对「内存墙」下手,把288GB高带宽内存 384MB片上SRAM塞进芯片里(容量是上一代的3倍),让模型的活跃数据尽量都留在芯片上,减少来回搬运带来的等待。
系统效率:引入自研的Axion CPU架构,把每台服务器的CPU主机数量翻倍,再通过NUMA做隔离优化,让整套系统在协同时更高效。
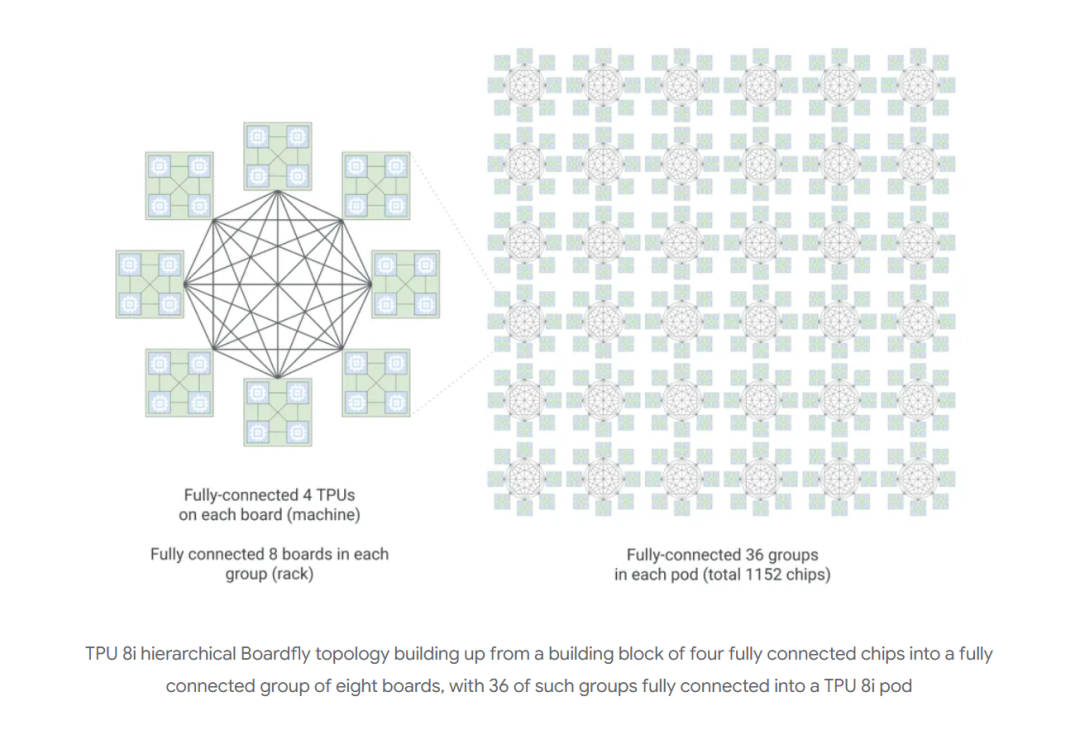
模型适配:针对当下主流的MoE混合专家模型,把互连带宽提升到19.2 Tb/s,再用新的Boardfly架构把网络「路径长度」砍掉一半以上,让多专家协同时不再拖慢整体速度。
延迟控制:新增片上集体加速引擎(CAE),把原本需要跨芯片完成的全局操作搬回芯片内部,整体延迟最高可降低到原来的1/5。
这一套下来,效果也很直接——
每美元性能提升约80%,在相同成本下,服务能力接近翻倍。
至于为什么决定训推分离?在谷歌看来这事儿很简单——
智能体时代对延迟和吞吐的要求截然不同,训练要的是「快」,推理要的是「稳」。
实践已经证明,一块芯片无法同时做好两件事。
既然如此,那为何不尝试分开做呢?
至少在第8代TPU身上,谷歌已经看到了这种分离带来的实际利益。
不过,谷歌之所以敢走这条分离的路,背后也确实离不开它对全栈的掌控能力。
背后是全栈协同优化
一个可能容易被忽略的细节是:
以前谷歌的TPU可能搭配的是通用的、第三方的CPU,比如英特尔或AMD的x86架构CPU。
但从这一代开始,TPU终于和谷歌自己设计的CPU(Axion)搭档了。
这意味着,谷歌可以按照AI任务的实际需求,去定制CPU和TPU之间的配合方式,从而榨干每一瓦电的性能。

而说到AI发展的最大瓶颈之一的「电」,谷歌这次也下了不少功夫。
一方面,它不再只盯着芯片本身,而是把优化范围直接拉到整条链路——
从CPU、TPU,到网络,再到整个数据中心,全部围绕「省电」重做一遍。
比如把网络连接直接塞进计算芯片里,减少节点之间的数据搬运。
再配合统一的电源管理,根据实时负载动态调功,把电优先分给最关键的计算环节。
另一方面,连数据中心也不再是被动承载,而是和TPU一起协同设计,供电、调度、散热全部重新打磨。
再加上第四代液冷,把原本风冷顶不住的功率密度撑起来,让算力可以在更高能效区间稳定运行。

这些优化叠加起来,效果也很直接:
8t和8i的每瓦性能,相比上一代直接提升接近2倍。
而一旦放到数据中心层面来看,单位电力能提供的算力,五年也已经提升了6倍。
更关键的是,谷歌目前也把这套全栈能力打包交给开发者使用了。
无需再折腾复杂的适配和环境搭建,8t和8i原生支持像PyTorch、JAX、vLLM这些主流框架,同时提供裸机访问,开发者可以直接用到真实硬件性能。
再配合MaxText、Tunix等开源工具,从模型训练到上线部署的路径也被进一步打通。
也难怪谷歌敢喊出,要做「面向Agent时代的基础设施」这样的口号。
至少从现在的布局来看,它已经在往这个方向铺路了。
One More Thing
随着谷歌第8代TPU发布,网友们也是集体看起了老黄的热闹(doge)。
你说巧不巧,老黄前一阵刚好在一档播客中回应了主持人的犀利提问:
世界上排名前三的AI模型中有两个——Claude和Gemini,都是在TPU上训练的。这对英伟达未来意味着什么?
而老黄当时只留下了引人无限遐想的几个字:
TPU没有威胁。
在老黄看来,专为AI设计的TPU只是在某个赛道上取得突破,而英伟达做的是All。
有大量应用场景是TPU无法覆盖的。英伟达把CUDA打造成一个出色的张量处理单元,但它也能处理数据处理、计算、AI等的整个生命周期。我们的市场机会更广,覆盖面更大。因为我们支持世界上所有类型的应用,你可以在任何地方建立英伟达系统,并确信它会有客户需求。这是一个完全不同的概念。
就是说,英伟达卖的从来不是某一颗芯片,而是一整套加速计算体系——
从CUDA生态,到覆盖AI、数据处理、科学计算在内的全场景能力。
从这个角度而言,AI只是当下其中最火的一块。
不过,随着AI本身开始吞噬越来越多的算力需求,TPU的重要性似乎也正在被重新估值。
别的不说,至少马斯克已经表明了自己的态度。


 VIP复盘网
VIP复盘网
