

【新智元导读】摩尔线程 AI 算力本(MTT AIBOOK)是专为 AI 学习与开发者打造的个人智算平台。它搭载自研智能 SoC 芯片「长江」,提供 50TOPS 异构 AI 算力,支持混合精度计算。运行基于 Linux 内核的 MT AIOS 操作系统,具备多系统兼容能力,并预置完整 AI 开发环境与工具链。产品内置智能体「小麦」及丰富 AI 应用,提供开箱即用的一站式 AI 体验。「本地写代码 小规模调试」→「云端一键调用大规模算力训练」→「模型回传本地部署」的闭环体验,才是 MTT AIBOOK 真正的杀手锏。
最近电脑圈什么最火?那必须是「AI PC」。
甚至可以说,现在是个笔记本厂商,不在发布会上提两句「AI」,出门都不好意思跟人打招呼。
但是咱们有一说一,市面上绝大多数所谓的「AI PC」,其实还是那个熟悉的配方:装个 Windows,塞个稍微强点的 NPU,然后告诉你「嘿,我们可以离线跑个美颜滤镜哦」。这就很没劲。
对于咱们这种动不动就要跑个模型、调个参,或者想在本地搓个 AI 应用的开发者(或者准开发者)来说,这种「AI PC」就像是给法拉利装了个自行车的辅助轮——看着挺花哨,真跑起来还是得靠那两条用久了发烫的 x86「腿」。
直到前段时间,我们终于拿到了摩尔线程发售的 MTT AIBOOK。
这玩意儿挺奇怪,因为它居然不预装 Windows(但它也能跑),而是预装了一个基于 Linux 的 MT AIOS。
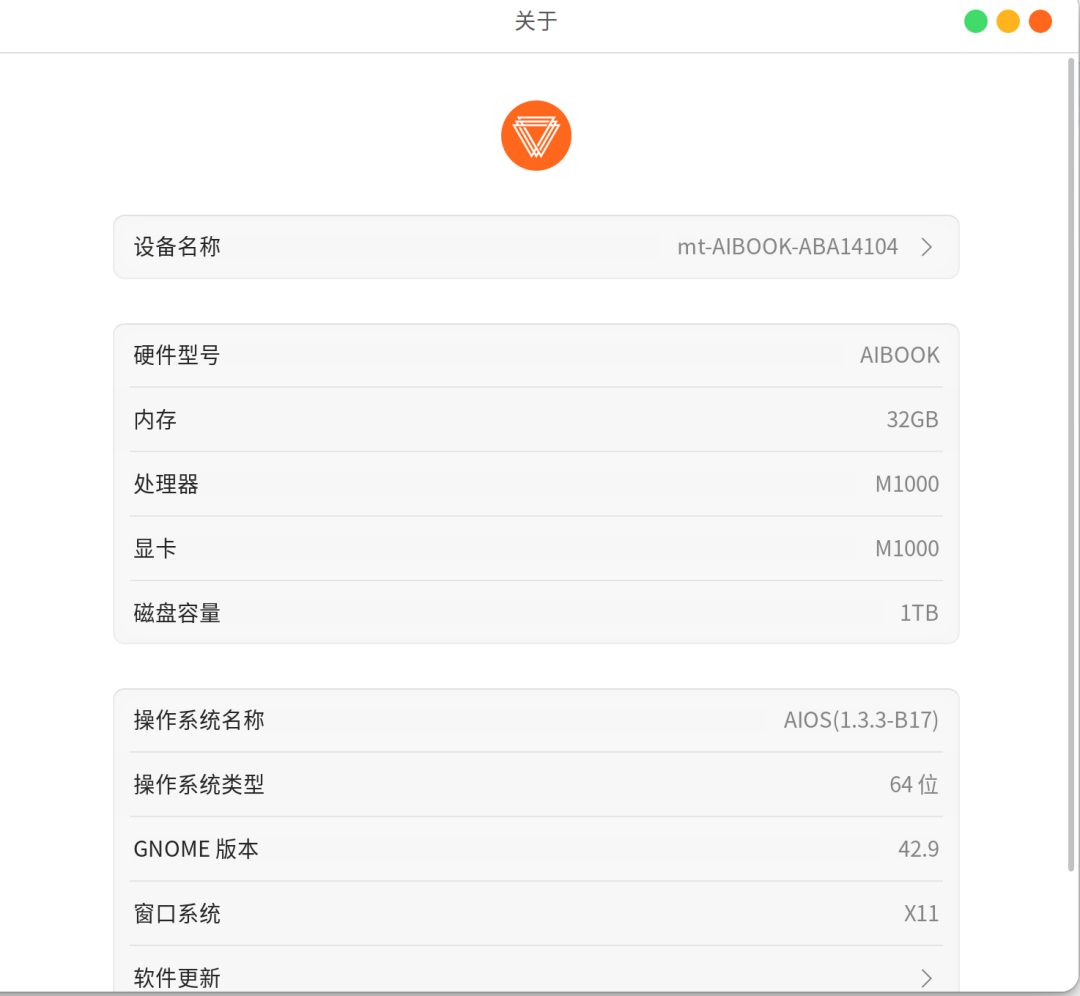
官方管它叫「个人智算平台」,说它是专门为 AI 开发者、学生党准备的「第一站」。
起初我们也就是抱着「试试看国产 GPU 到底能不能打」的心态,把它当成备用机扔进了背包。
结果没想到,一周下来,这台本子居然成了我桌面上开机率最高的设备。
甚至有点,回不去的感觉。
今天,咱们就抛开那些花里胡哨的词藻,实打实地聊聊:这台塞进了国产「长江」SoC 芯片的 MTT AIBOOK,到底是噱头,还是真家伙?

拿到真机的第一眼,这台 AIBOOK 居然有点「反差萌」。
按照常理,主打「硬核开发」的本子,通常都长得像块砖,恨不得把散热孔开到屏幕上。
但 MTT AIBOOK 拿在手里,居然有点轻薄本的意思。
全金属机身,0.15mm 的 CNC 切割工艺,摸上去那种冷峻的磨砂感,「果味」十足。

A 面没有任何花哨的 RGB 灯带,甚至 Logo 都做得非常克制。

这种「谦逊」的设计语言,我个人是非常吃的。
毕竟对于开发者来说,我们不需要电脑在咖啡馆里像迪厅球一样闪瞎别人的眼,我们需要的是它在跑代码的时候别掉链子。
掀开屏幕,一块 14 英寸的 2.8K OLED 屏映入眼帘。
120Hz 高刷,100% DCI-P3 色域。
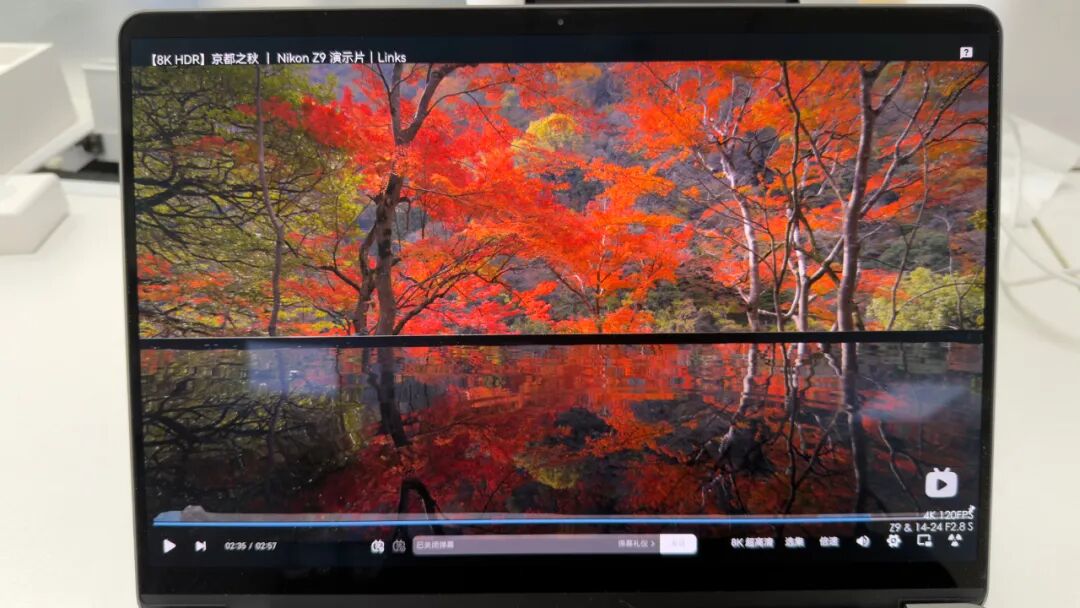
有一说一,这块屏幕的素质用来跑终端代码属于是「暴殄天物」,但用来回看刚生成的 AI 绘图,那个色彩表现力确实顶。
但真正的「硬菜」,在开机之后。
按下电源键,没有熟悉的「田字格」Logo,而是直接进入了 MT AIOS 的桌面。
懂行的朋友都知道,Linux 才是 AI 开发的「快乐老家」。
无论是 PyTorch 这些框架,还是各种开源的大模型,在 Linux 下的兼容性和效率永远是第一梯队。
以前我们在 Windows 上做开发,要么得忍受 WSL(Windows Subsystem for Linux)偶尔的各种怪异 Bug,要么就得自己折腾双系统,把引导分区搞炸那是家常便饭。
MTT AIBOOK 的逻辑非常简单粗暴:既然大家都要用 Linux,那我直接给你原生 Linux。
不仅如此,它还解决了开发者最大的噩梦——环境配置。
如果你是计算机专业的学生,或者刚入行的 AI「炼丹师」,你一定经历过这种绝望:
为了跑通一个 GitHub 上的开源项目,你花了两天时间装 CUDA、配 cuDNN、换 Python 版本、解决各种依赖冲突……最后代码还没跑,人已经麻了。这就是传说中的「环境配置火葬场」。
而这台 AIBOOK,出厂就预置了 MUSA(Meta-computing Unified System Architecture) 全套开发环境。
Python、VS Code、Jupyter Notebook、PyTorch……这些吃饭的家伙什儿,开箱即用。

这就好比你去买房,以前是毛坯房,你得自己刷墙铺地砖;
现在摩尔线程直接给了你一套精装房,拎包入住,你只需要关心「我要写什么代码」,而不是「为什么 pip install 又报错了」。
光说不练假把式。
既然官方号称这台机器有 50 TOPS 的异构 AI 算力,那我们必须得给它上点强度。
我们选择了目前 AI 绘画圈最硬核、最能体现算力调度的工具——ComfyUI。
熟悉 AI 绘画的朋友都知道,ComfyUI 这玩意儿虽然功能强大(节点式工作流简直是极客浪漫),但它的安装门槛极其劝退。
而且,它默认是深度绑定英伟达显卡和 CUDA 生态的。
在一台国产 GPU 的笔记本上跑 ComfyUI?这听起来就像是在 PS4 上跑 Xbox 的《光环》一样离谱。
但实测下来的过程,居然顺滑得让我有点怀疑人生。

按照官方给的【初级】教程,整个部署过程不仅不需要我重新编译 PyTorch,甚至都不需要我对着终端敲那行看着就头疼的:
git clone
摩尔线程显然是做了大量的底层适配工作。
他们提供了一个「特制版」的压缩包,里面已经把适配国产架构的 Torch 库和加速接口都打包好了。
操作步骤简单到令人难以置信:
下载 AIBOOK 专版的 ComfyUI 压缩包。
解压。
打开终端,敲一行:
python main.py --gpu-only --force-fp16
完了。
真的,就这么简单。当看到终端里跳出 Starting server 的字样,浏览器自动弹出熟悉的节点界面时,我承认我有点感动。
这不仅仅是省事,这代表了摩尔线程的工程师在底层做了大量的「脏活累活」,把异构计算的天然屏障给抹平了。
为了测试性能,我没有用那种几十 MB 的小模型,而是直接上了 SDXL Lightning—— 这可是目前文生图领域的高质量代表。
我加载了一个官方提供的 .json 工作流文件。
如果是没接触过 ComfyUI 的小白,可能会被满屏的连线吓到。
但在 AIBOOK 上,这种节点化的操作反而显得非常直观:
左边是 Checkpoints 加载器,我选好了下载好的
sdxl_lightning_4step.safetensors。中间是 CLIP 文本编码器,这里就是输入提示词的地方。
右边是 KSampler(采样器)和 VAE 解码。
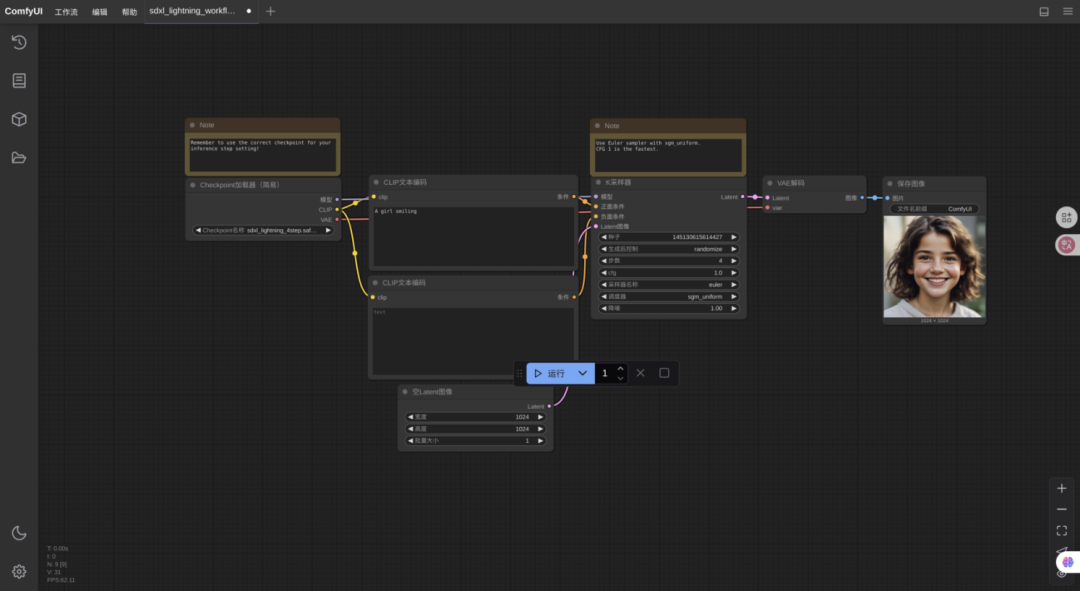
我试着输入了一段简洁的提示词:
Anime style, 1 girl with long pink hair, cherry blossom background,
studio ghibli aesthetic, soft lighting, intricate details Masterpiece,
best quality, 4k
然后,深吸一口气,点击运行。
此时,我能明显听到机身内部的双涡轮风扇开始介入,声音有点像飞机起飞前的滑行声——这声音对极客来说,就是「算力正在燃烧」的悦耳音符。
屏幕上的绿色进度条在各个节点之间快速跳动。
K采样器上的进度条仅仅走了几秒钟,一张可爱的小女孩图片就出现在了最右侧的预览框里。
在这个过程中,所有的计算都在本地。
这意味着什么?
意味着我不需要把我的提示词(可能包含一些私人的创意)上传到云端;
意味着即使我现在拔掉网线,我依然可以坐在公园的长椅上,利用这颗「长江」SoC,源源不断地生成我的创意。
当然,肯定有硬核老哥会说:「你这也就是跑个推理,只有 50 TOPS 算力,我想训练个大模型岂不是要等到天荒地老?」
这就问到点子上了。
笔记本毕竟是笔记本,受限于功耗和体积,它不可能塞进一张数据中心级别的计算卡。
但 MTT AIBOOK 的聪明之处在于,它从来没想过单打独斗。
它有一个核心理念叫——「端云一体」。
为了体验这个功能,我按照【高级】教程,尝试了一次经典的深度学习实战:CIFAR-10 图像分类训练。
简单科普下,CIFAR-10 是 CV(计算机视觉)界的「Hello World」级数据集,包含 60000 张 32x32 的彩色图片,分成了飞机、汽车、鸟、猫等 10 个类别。

我们要做的,就是从零开始构建一个卷积神经网络(CNN),教电脑学会认图。
这次,我没有在本地死磕,而是利用 AIBOOK 预置的工具,直接连接到了 AutoDL 算力平台。
这里必须提一句,摩尔线程和 AutoDL 有深度合作,甚至在专区里你可以直接租用到搭载摩尔线程全功能 GPU 的云端实例。
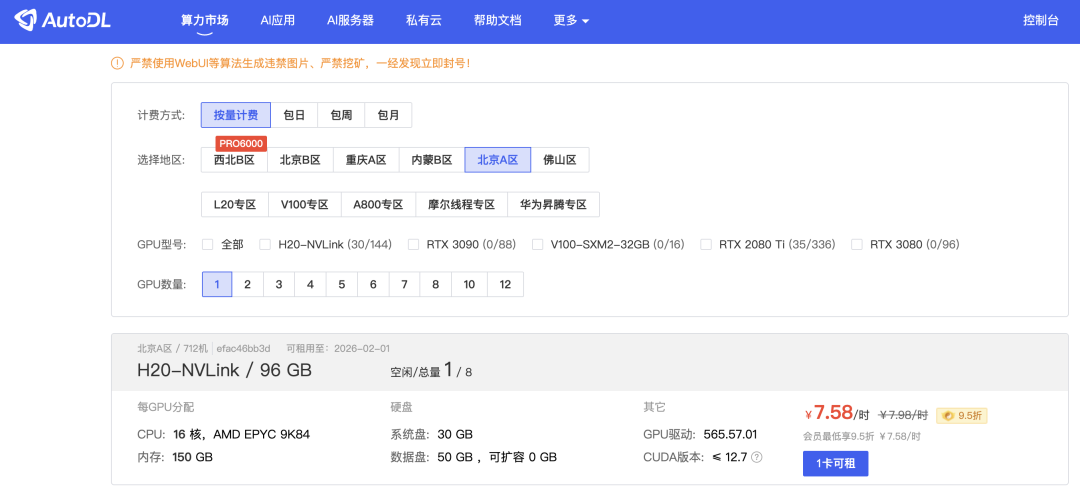
操作体验极其丝滑:
我在 AIBOOK 的本地终端里写好了代码,然后通过 SSH 连接到云端实例。
这时候,神奇的事情发生了。
我在本地 Linux 环境下写的代码,几乎不需要任何修改,就可以直接在云端的摩尔线程 GPU 上运行。
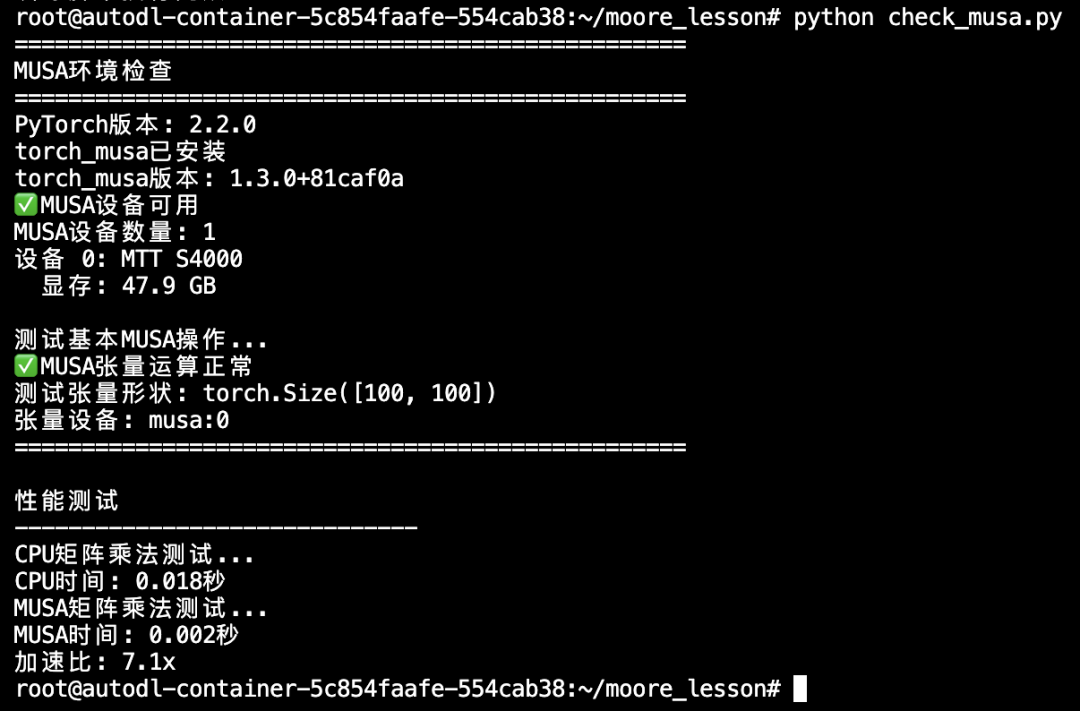
在终端里,我先输入了一行检查指令:
python check_musa.py
屏幕返回:
设备 0:MTT S4000
显存:47.9 GB
这是国产显卡在 PyTorch 框架下发出的「我在」的声音。
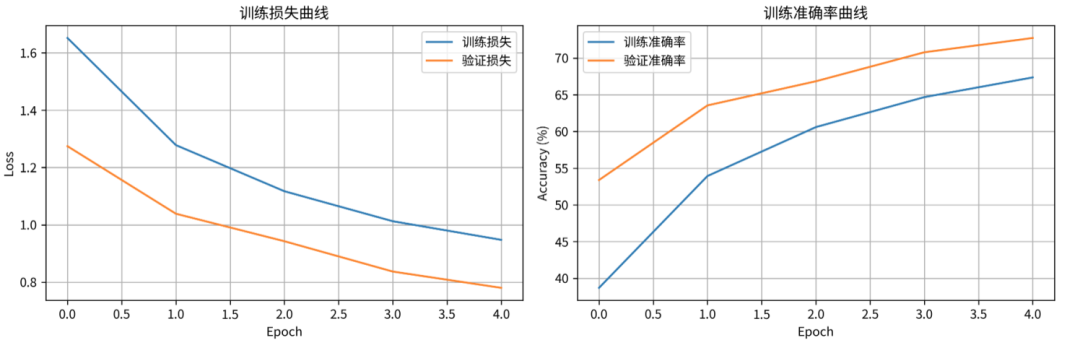
接着,开始训练:
python train_cifar10.py --model simple_resnet --epochs 10
终端里的进度条开始飞快滚动:
随着训练轮数(Epoch)的增加,准确率肉眼可见地提升。

重点是,整个过程中,我使用的是标准的 PyTorch 语法,没有去写什么晦涩难懂的专有算子。
这就是 MUSA 架构最大的护城河——兼容性。它让开发者可以几乎无痛地从 CUDA 生态迁移过来。
这种「本地写代码 小规模调试」→「云端一键调用大规模算力训练」→「模型回传本地部署」的闭环体验,才是 MTT AIBOOK 真正的杀手锏。
它不再是一个孤立的硬件,而是一个通往庞大算力海洋的入口。
测到这儿,肯定有朋友要问了:
「这电脑好是好,但我总不能天天写代码吧?我要是用飞书开个会,或者想打把《空洞骑士》放松一下,难道还要再买台电脑?」
这就是 MTT AIBOOK 最机智的地方。
它虽然是 Linux 核心,但它非常清楚现阶段打工人的痛点。
所以,它搞出了一个「一本三用」的方案:
Host OS:原生的 MT AIOS(Linux),用来干正经事,写代码、跑模型。
安卓容器:直接在桌面运行安卓 App。我试了下,不仅能刷小红书,甚至能通过应用汇下载各种手游。摸鱼神器 get ✅。
Windows 虚拟机:这才是绝杀。

这台机器利用了 KVM 虚拟化技术,支持运行一个完整的 Windows 11。
注意,这不是像 Parallels Desktop 那种简单的模拟,它是支持 GPU 虚拟化的。
实际场景是这样的:
我在 Linux 下刚刚训练完一个模型,把它封装成了一个 .exe 的应用。
但我不知道这玩意儿在客户的 Windows 电脑上能不能跑。
这时候,我不需要到处借电脑,直接在 Dock 栏进入虚拟机,几秒钟后,一个全屏的 Windows 界面就出来了。
我在里面测试软件、写个 PPT、甚至打开 Steam 玩了一会儿游戏,确认无误后,三指一划,又回到了 Linux 继续改代码。
开发在 Linux,办公/测试/娱乐在 Windows/安卓。
这种「精神分裂」般的使用体验,在习惯之后,竟然觉得意外的合理。
它完美解决了开发者「既要又要」的贪婪需求。
用了这一周,我一直在思考一个问题:
在 2026 年,我们到底需要一台什么样的 AI 电脑?
是算力强到能当暖气片?还是薄到能切菜?
摩尔线程用 MTT AIBOOK 给出的答案是:我们需要一个能让更多人低门槛进入 AI 世界的工具。
说实话,这台电脑绝非完美。
它的生态相比于沉淀了几十年的 Wintel 联盟还有差距,它的软件库可能还不如 Ubuntu 社区那么浩如烟海。
但它做对了一件至关重要的事情——它把「国产算力」这四个字,从遥远的数据中心机房,搬到了每一个普通学生、普通开发者的书桌上。
对于摩尔线程来说,这不仅仅是在卖硬件,这是在「播种」。
他们希望未来的开发者,人生的第一行 AI 代码,是在 MUSA 架构上敲下的;
他们希望未来的 AI 应用,是原生生长在国产算力平台上的。
这台 MTT AIBOOK,就像是一张通往未来 AI 时代的「入场券」。
它不是目前市面上性能最狂暴的笔记本,但它是目前最懂中国开发者痛点的「个人智算平台」。
如果 AI 的星星之火需要干柴,那这台算力本,就是那块最顺手的打火石。

 VIP复盘网
VIP复盘网
