

1 MoE稀疏化趋势下,计算效率提升成为关键
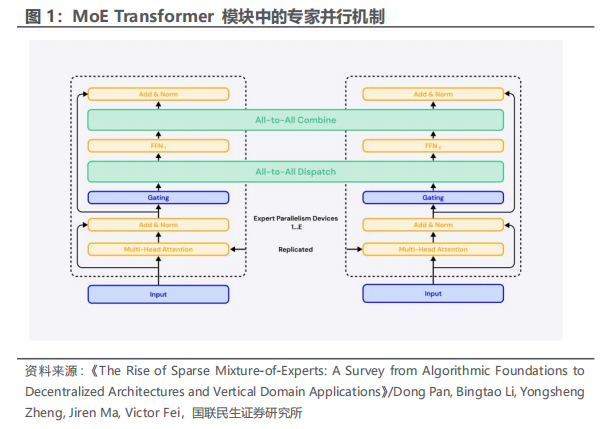
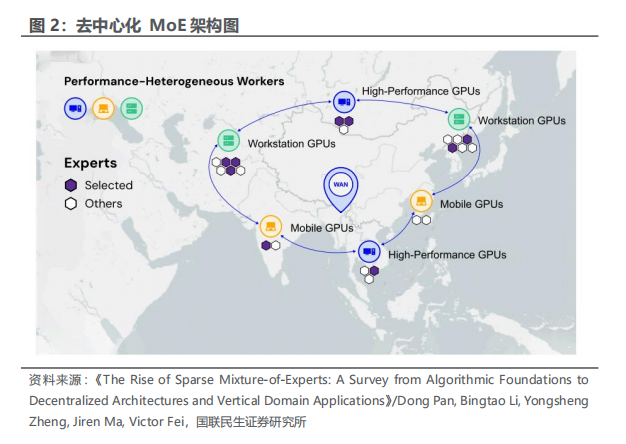
全球头部大模型迈向万亿参数和长上下文,训练和推理必须依赖专家并行、数据并行、流水线并行和张量并行等多种策略,并部署于高性能GPU集群和高速RDMA网络之上。根据论文《The Rise of Sparse Mixture-of-Experts: A Survey from Algorithmic Foundations to Decentralized Architectures and Vertical Domain Applications》,我们可以看到在MoE技术路线下,未来算力基础设施发展的一些趋势。
MoE推动算力需求从单卡能力转向集群级系统能力。随着MoE模型参数规模持续扩大,部分新一代MoE模型已经迈向万亿参数,并支持128K以上长上下文。由于模型规模和上下文长度显著提升,单张GPU已难以承载完整模型训练和推理,模型必须被拆分到多GPU、多节点集群中运行。
2 Agentic AI计算效率为先,CPU迎来价值重估
2.1 评价计算效率的核心指标:单位Token成本
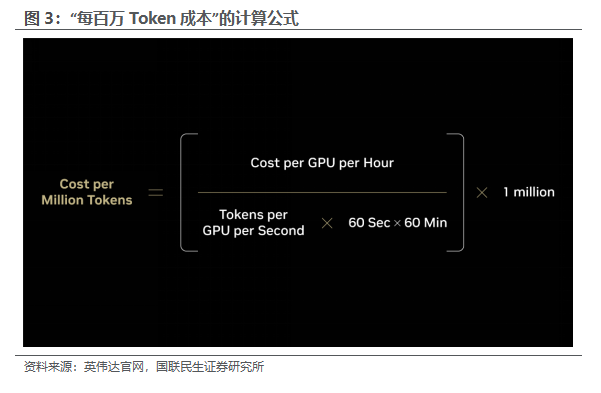
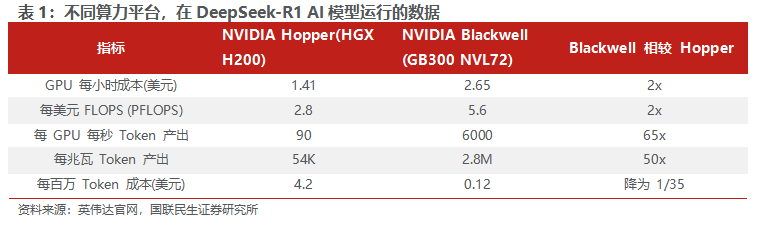
根据英伟达官网的数据,基于DeepSeek-R1 AI 模型,仅从算力成本来看,NVIDIA Blackwell平台的成本约为 NVIDIA Hopper 的2倍,但Blackwell 每瓦的Token产出量是Hopper的50倍以上,每百万 Token 的成本降低至其1/35左右。
2.2 提升整体计算效率趋势下,CPU迎来价值重估
在Agentic AI时代,CPU-GPU协同失效制约落地效率。当前智能体部署面临“堆卡低效”的困境,佐治亚理工学院相关论文《A CPU-Centric Perspective on Agentic AI》通过对五大典型智能体负载的实证测试,揭示传统“CPU搬运、GPU推理”分工模式存在协同瓶颈。
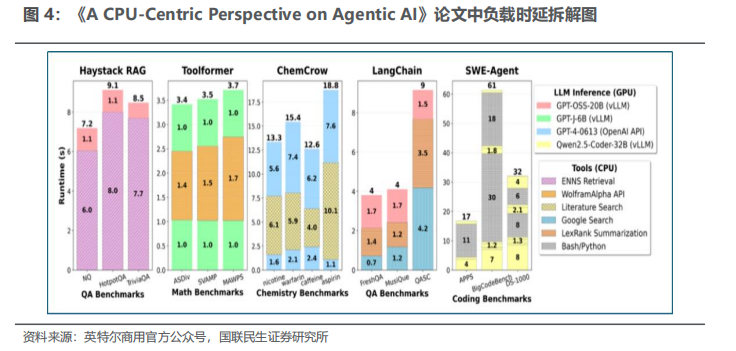
2)吞吐量提升遭遇双重瓶颈:系统效率上限一方面受GPU显存容量限制——批大小提升到一定阈值后KV Cache占用显存过高,吞吐量进入饱和区间;另一方面受CPU调度瓶颈限制——多核CPU常出现核心未完全占满时吞吐量提前饱和的情况,批大小从64提升到128时,LangChain负载的CPU端摘要任务时延可从2.9秒上升到6.3秒,核心超分导致上下文切换开销大幅增加。
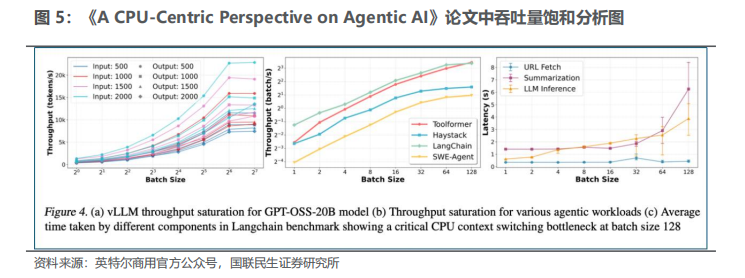
3)能耗结构失衡:大批次场景下CPU能耗占比显著提升,批大小为128的LangChain负载中,CPU动态能耗占总动态能耗比例可达44%,单纯依赖CPU多进程并行提升吞吐量会拉低整体投资回报率。
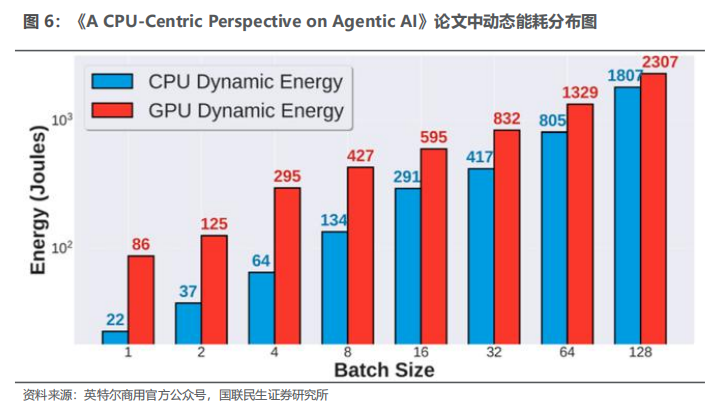
由此可见,推理的关键指标不再是峰值算力,而是单位Token成本、并发吞吐、功耗等。在提升整体计算效率的过程中,CPU至关重要:CPU不仅可以承接长尾和批量推理,而且可以提升整体调度效率,其最为典型的案例即是英伟达的Vera芯片。
2.3 巨头率先发力:英伟达Vera芯片致力于创造更高的数据中心Token营收
在NVIDIA Rubin平台中,GPU执行 Transformer时代的工作负载,CPU编排数据与控制流。
Vera是英伟达面向AI工厂场景推出的新一代专用CPU,基于Grace CPU的高带宽、高能效设计基础,完成了角色定位的核心升级。相比前代产品仅承担辅助调度功能,Vera已成为支撑GPU高效运行的核心数据处理单元,专门针对AI工厂的全流程工作负载完成优化。产品完全兼容Arm v9.2架构,主流Linux发行版、AI框架与编译平台无需修改即可直接运行,同时原生支持跨CPU-GPU边界的机密计算。
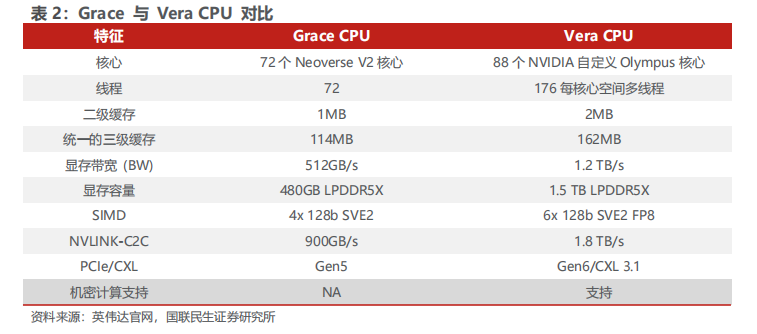
第二代可扩展一致性结构(SCF)有效消除数据的传输瓶颈,保障AI工作负载的线性扩展能力。该架构可将所有核心连接至共享三级缓存与内存子系统,负载下可维持超过90%的峰值内存带宽,消除核心与内存控制器之间数据的传输瓶颈,确保编排、数据处理类工作负载的性能随核心数量线性增长,可持续向GPU供给训练与推理所需的全量数据。
3 ARM CPU迎来重要机遇:兼具性能与生态的系统性壁垒

Arm的核心竞争优势已从传统能效领先,升级为兼具性能与生态的系统性壁垒。性能较同级别x86 CPU实现两位数领先,同时保持显著的TCO优势;每瓦性能是AI时代的核心成本指标之一,Arm可在不提升功耗与散热需求的前提下实现更高算力吞吐量,解决当前AI数据中心普遍面临的电力约束痛点。生态层面,根据ARM官方公众号、Futurum,Arm全球开发者规模超2200万,是全球最大的开放计算生态之一,软件栈与AI框架适配成熟,开发者一次优化即可实现全场景部署,架构切换成本高,形成了持续强化的复利式竞争护城河。
Arm AGI CPU是基于Arm Neoverse平台打造的全新量产级芯片,旨在为AI基础设施提供核心算力支撑。Arm AGI CPU能够在数千核心并行的持续高负载下,为每个任务提供高性能表现,且满足现代数据中心功耗与散热的严格要求。从运行频率到内存及I/O架构,Arm AGI CPU的每一处设计都经过专门优化,在高密度机架部署场景下,支持大规模并行、高性能的代理式AI工作负载。目前Arm AGI CPU已有多个重要客户,包括Cerebras、Cloudflare、Oracle、F5、Meta、OpenAI、Positron、Rebellions、SAP、SK 电讯和 Verda等。
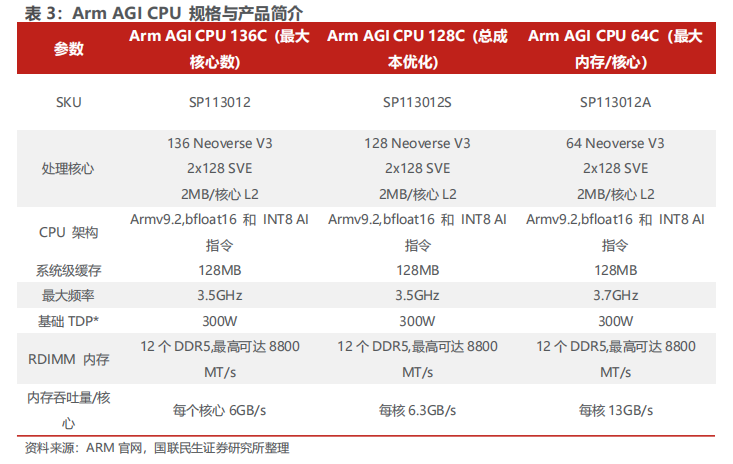
Arm AGI CPU 可实现单机架性能较高:Arm AGI CPU 具备业界领先的内存带宽,使每个机架能够支持更多高效执行的线程;高性能、高能效的单线程 Arm Neoverse V3处理器核心性能出众,每个 Arm 线程可处理更多任务;更多可用线程与更高单线程处理能力相互叠加,最终实现单机架性能的大幅提升。Meta 作为 Arm AGI CPU 的早期合作伙伴与客户,参与该 CPU 的联合开发,旨在为 Meta 全系应用优化吉瓦级规模基础设施,并与 Meta 自研的 MTIA 加速器协同运行。
4 投资建议
AI基础设施正进入推理效率竞争阶段,MoE稀疏化、Agentic AI等趋势推动算力需求转向系统级效率优化,ARM CPU兼具性能与生态的系统性壁垒,将迎来重要的发展机遇。建议重点关注:1)国产算力:浪潮信息、寒武纪等。2)CPU:海光信息、中国长城、龙芯中科、禾盛新材、广合科技等。
5 风险提示
MoE工程化落地不及预期风险。MoE涉及路由、专家并行、负载均衡和通信优化等复杂问题,若通信开销或调度效率问题难以解决,可能影响其降本增效效果。
AI推理需求增长不及预期风险。若下游AI应用商业化、Agentic AI落地或企业推理需求增长低于预期,相关算力基础设施和CPU价值重估进程可能放缓。

 VIP复盘网
VIP复盘网
