

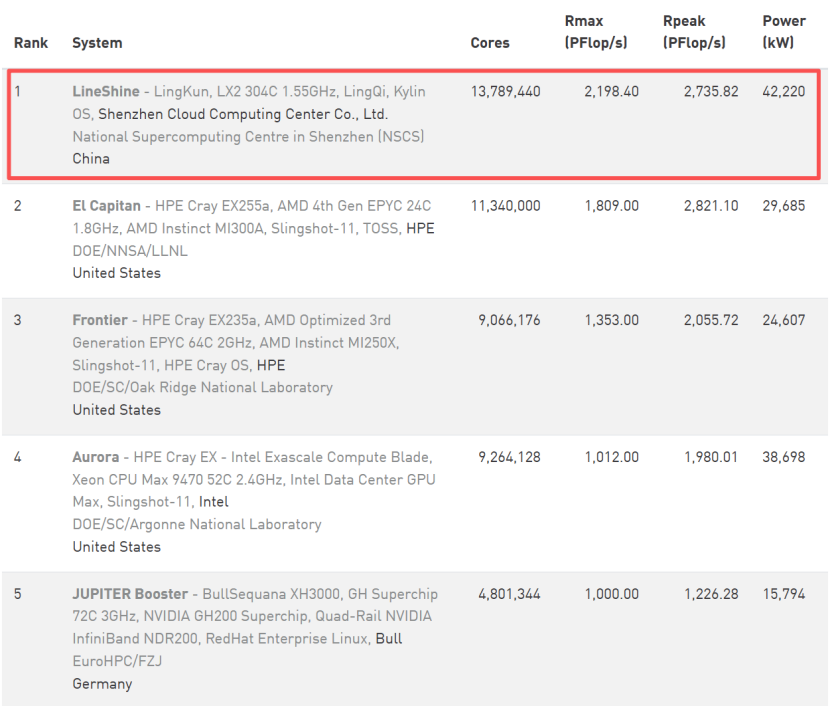
全国产自主研制的“灵晟”超级计算机登顶全球超算TOP500(2026年6月)
这一“计算”与“存储”的响炮,传递出一个强烈的信号:在AI算力遭遇地缘政治“玻璃天花板”的今天,中国算力正在放弃单纯追逐单点算力神话的路径,转而向系统能力要效率,向存力和网络要红利。

破除“算力迷信”
“灵晟”登顶振奋人心,但背后仍有严峻的挑战。“算力的本质是产出智能,而不是消耗电力。” 这是当前行业专家在万卡级超大规模集群时代遭遇瓶颈后的共识。
正如中国农业大学信息中心计算中心主任劳凤丹教授所指出,未来的考核指标必须从单纯的算力大小,转变为“每瓦特电力能产出多少Token(词元)”。如果GPU因为等待数据而空转,那么再高的峰值FLOPS也只是纸面富贵。
既然单点算力的提升遇到了物理极限,破局之道就在于系统优化。这也正是中科曙光ParaStor存储系统夺冠的意义所在,它证明了“以存提算”的可行性。
这场“计算 存储” 的双料突破,并非单点技术的偶然超越,而是中国算力跳出传统芯片内卷、以系统能力破解长期行业瓶颈的必然结果。想要理解这一轮范式升级,需要先复盘传统算力体系的底层缺陷。
中科曙光分布式存储总工程师袁清波提到,这并非依赖外部通用组件的“拼接式集成”,而是源于底层系统设计方法论的根本转变。ParaStor F9000的本质突破,在于它让存储具备了“参与计算路径优化”的能力。通过端到端数据路径优化降低了跨节点访问的抖动,确保在万卡规模下,数据能像血液一样稳定、高速地输送到计算单元。
从全球竞争格局来看,高端存储正在从传统企业IT基础设施,快速转向AI与科学计算驱动的新一代算力基础设施核心环节。这个阶段的竞争不再只是单一硬件性能,而是系统工程能力,包括存算网协同设计、大规模并发处理能力以及在真实业务负载下的长期稳定性。
过去十年,AI的发展遵循着Scaling Law(扩展定律),即算力投入与模型能力呈正相关。这导致了行业陷入了一种“唯芯片论”的焦虑——似乎谁拥有了最先进的GPU,谁就拥有了未来。但随着AI训练进入万卡时代,AI基础设施首先需要解决的,是实现机器层面的高效稳定运行。
中科曙光此次展示的AI基础设施方案,是在长期工程实践基础上形成的系统化能力体系:通过“算-存-网”协同夯实机器层基础能力,通过“电力-算力”循环提升规模化运行效率,并以开放计算为支撑推动“系统-生态-应用”融合演进,将机器、能源与产业贯通为一个持续发展的整体。
在这一轮“系统级”的角逐中,中国立足于自主可控的全栈技术,通过极致的系统工程优化,去解决“数据如何流动”“电力如何转化”“异构算力如何协同”等根本性问题。最后获得国际榜单上认可的,不再是某一家企业的技术成果,更是中国在AI时代重塑基础设施规则、寻找差异化发展道路的决心体现。
重构下一代算力底座
通过软件定义和系统级优化,提升单比特数据的访问效率,实际上等同于降低了对高端计算芯片的绝对依赖。“看到学不来”正是系统工程能力带来的护城河。
长期以来,行业算力体系呈现二元割裂格局:超算依托CPU架构,擅长FP64高精度物理规则计算,服务传统科学计算;智算依托GPU/NPU架构,擅长低精度矩阵运算,适配AI模型训练推理。但在AI for Science、全自动科研、世界模型研发等新兴场景,要求高精度科学计算与智能化算力深度融合,传统分离式架构已无法匹配AI Agent自主运行、全流程智能科研的全新需求。这就需要“超智融合”。
“讲到超智融合,全球唯一有能力把超算的计算能力和智算的计算能力融合起来的就只有美国和中国,其他任何一个第三方的国家都不具备这种系统能力。中国要在这一波浪潮里找到自己的定位需要树立一个标杆。”上海交通大学信息办主任林新华提到,未来需要重构重建,面向AI agent去设计整个的超算架构。
而在超算架构中,数据搬运的能耗和延迟就有可能远远超过了计算本身的成本。架构层面的重构需求,正在落地为真实的市场变革与工程实践。
“从全球市场看,高端存储长期由少数国际厂商主导,但这一格局正在被AI驱动的基础设施重构所改变。我们看到的变化是:客户关注点正在从品牌与生态惯性,逐步转向真实负载下的系统效率与TCO。”中科曙光北京公司副总裁何振说。
自国家超算互联网核心节点建设启动以来,ParaStor F9000已投入实际生产环境,并持续迭代优化。目前,该系统已在数万卡集群中稳定运行超过一年,在大模型训练、科学计算与数据分析等关键场景中提供支撑。在典型应用中,该系统联合龙讯旷腾MatPL软件,依托scaleX万卡超集群,完成414.7亿原子规模液态水分子动力学模拟计算,刷新了该领域世界纪录。

中科曙光提供的三套scaleX万卡超集群在国家超算互联网核心节点运行
世界级纪录的背后并非单一硬件的功劳,而是中国厂商系统重塑了数据流动的路径。为了解决万卡集群中“数据搬运”的痛点,底层架构正在经历深度重构:比如中科曙光此次在ISC现场展示的scaleFabric原生类IB高速互联网络,RDMA专属数据通道可消除万卡并发时的网络拥塞;ParaStor F9000分布式全闪存储,利用自研技术实现GPU直通,让存储从被动搬运转变为主动参与计算路径优化;借助scaleX40箱式超节点的无线缆正交架构,形成高密度算力单元,满足万亿参数大模型的训练与推理需求。中科曙光通过一套“算-存-网”全链路协同优化的底层架构为大规模AI训练与科学计算提供了坚实的基础支撑。
“我们期待未来出现更优越的算力,尤其是更具成本效益和更高效率的算力。在此过程中,不仅仅是算力技术本身要发展,让算力发挥最大效能的环境同样重要,二者相辅相成。”广州国家实验室生物信息中心主任、研究员李义学说。
中国在存储和网络领域建立起系统级的优势道路不是直接堆砌GPU,未来的胜者也未必是拥有最快芯片的国家,而是那个能让数据流动得最高效、最智能的国家。这,就是中国算力给出的“系统级答案”。

 VIP复盘网
VIP复盘网
