

广和通要闻
近日,广和通AI研究院在具身智能领域取得关键进展:基于自研FiboVLA框架与端侧推理优化技术,团队在多个主流VLA模型上实现平均2.6倍推理加速,并完成GR00T N1.5在边缘侧高算力主控平台的部署。相关成果已通过LIBERO仿真基准数据集与桌面双臂真机环境验证,为具身智能模型在机器人端侧高效运行提供工程支撑。

参数规模激增,机器人在端侧的实时推理成瓶颈
VLA(视觉-语言-动作模型)是具身智能的重要方向。它把视觉输入、语言指令和动作生成连接起来,让机器人能够根据环境和任务要求生成动作。
随着VLA能力提升,模型参数规模和推理成本也随之增加。对于机器人而言,推理速度直接影响动作响应、任务衔接和运行流畅度。
机器人还受到算力、功耗、散热和系统资源限制。如何让复杂VLA模型在端侧高算力主控上稳定、高效运行,成为具身智能落地必须解决的问题。

FiboVLA:压缩视觉Token,优化推理链路
针对VLA模型端侧推理负载高的问题,广和通AI研究院采用自研FiboVLA压缩框架,从模型语义层进行Token级优化。
在VLA推理过程中,视觉和语言信息中存在大量冗余表征。FiboVLA通过精细化视觉Token筛选与压缩,剔除低价值信息,保留与任务理解、环境判断和动作生成强相关的关键内容。
该框架减少了推理过程中的无效计算,在保持模型决策精度、跨模态理解能力和动作生成能力的前提下,大幅降低计算负载。
同时,团队结合推理链路调度与端侧推理引擎优化,进一步提升模型在机器人端侧运行的效率。经验证,该框架不依赖特定模型架构,已在多个主流前沿VLA模型上验证有效,推理吞吐提升2.6倍,端到端时延得到有效压缩。

打通“大模型 小终端”最后一公里
此次突破的核心价值,让原本对算力要求较高的VLA大模型,能够进入机器人端侧系统运行。
基于FiboVLA框架与端侧推理优化技术,广和通AI研究院成功将GR00T N1.5部署至边缘侧高算力主控平台,并完成运行验证。
在LIBERO仿真基准数据集中,该框架保证了推理加速后的任务效果;在真实物理环境中,也在桌面双臂机器人场景中完成GR00T N1.5真机运行验证。
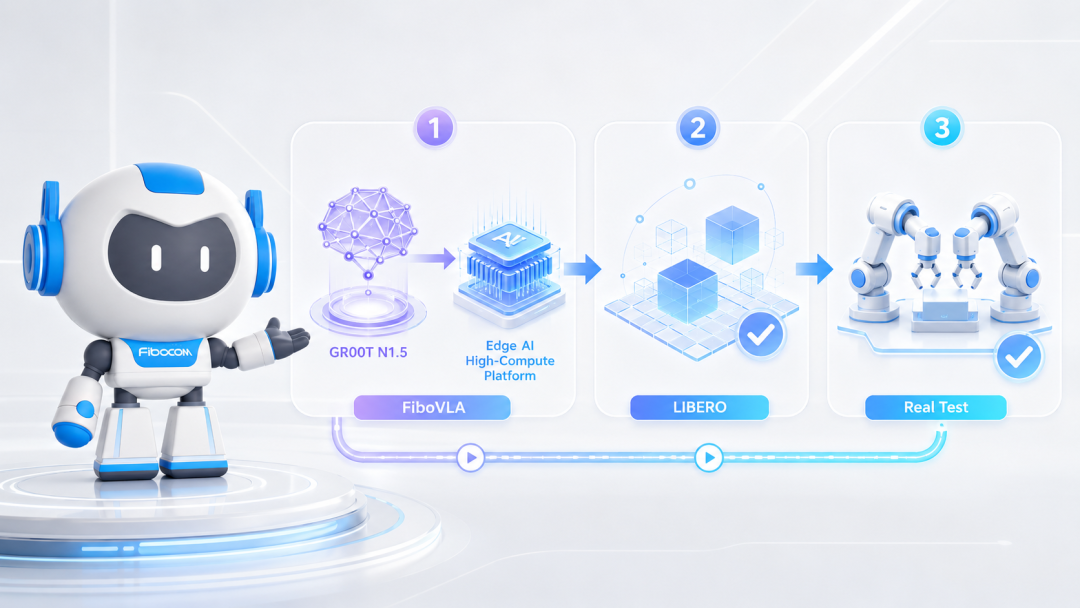
这意味着,机器人可以在端侧更快完成感知、决策与动作生成,形成低延迟、连续化的推理闭环。这不仅是模型速度提升,也是在真实机器人平台上完成了一次工程验证。
从推理加速,走向机器人“本能”
面向具身智能加速发展的产业趋势,广和通将持续结合无线通信、边缘算力、AI工具链与Fibot平台能力,帮助机器人和各类智能终端获得更高效、更稳定的本地智能,为具身智能进入真实系统运行提供工程基础。

 VIP复盘网
VIP复盘网
