

6月19日,智谱港股股价继续大涨,盘中一度上涨41%,收盘报2410港元/股,市值突破一万亿港元。自6月12日GLM-5.2发布以来,智谱五个交易日内股价从1097港元涨至2410港元,累计上涨约120%。
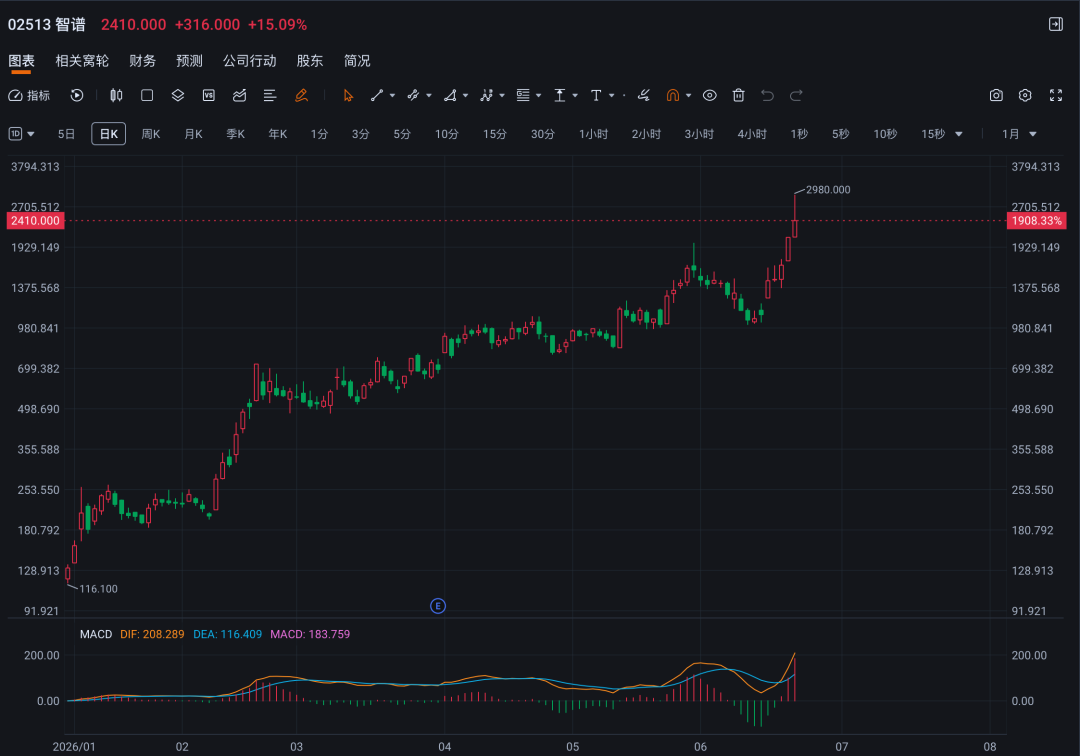
从传统财务指标看,这一估值几乎难以解释。以约7.24亿元年收入计算,万亿港元市值对应的市销率高达千倍以上,远高于全球主要AI公司和A股AI芯片龙头的估值水平。更何况,智谱还将在2026年7月迎来基石投资者股份解禁,潜在抛压并不低。
但资本市场给出的答案似乎是另一套逻辑:智谱当前被交易的,并不是静态收入,而是中国大模型进入全球前沿竞争区间后的期权价值。
GLM-5.2的发布,使国产开源模型首次在编程、智能体和长上下文等高价值场景中逼近海外顶级闭源模型;与此同时,美国前沿闭源模型的全球可获得性出现不确定性,进一步放大了开源模型在成本、部署和供应连续性上的优势。
换言之,智谱股价暴涨的直接催化剂是GLM-5.2,但市场真正交易的,是中国AI公司从“低价追赶者”向“前沿能力、成本结构和商业化落地并重”的全球竞争者转换的可能性。
GLM-5.2引爆资本市场
GLM-5.2发布的核心意义在于,它让国产开源模型第一次明确进入了此前主要由海外闭源实验室主导的前沿能力区间。
根据智谱发布数据,GLM-5.2参数规模753B,采用MoE(混合专家)架构,支持1M token稳定上下文窗口,以MIT协议完全开源。在FrontierSWE编程基准上,GLM-5.2得分74.4,Anthropic的Opus 4.8为75.1,差距约1个百分点,同时超过GPT-5.5的72.6。在PostTrainBench(测试Agent训练小模型能力)基准中,GLM-5.2以34.3分排名第二,仅次于Opus 4.8的37.2,高于GPT-5.5的28.4。
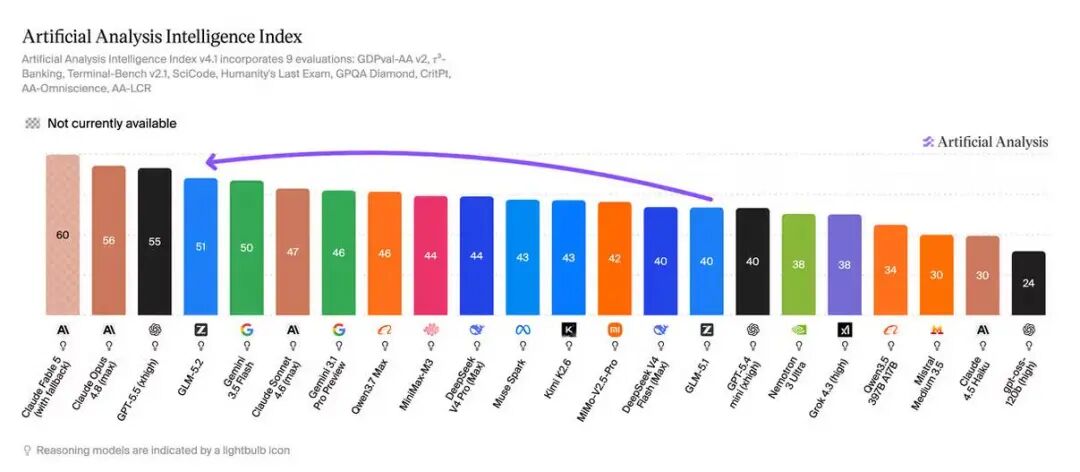
Artificial Analysis在其智能指数v4.1中将GLM-5.2评定为51分,领先MiniMax-M3(44分)、DeepSeek V4 Pro(44分)和Kimi K2.6(43分),同时将其置于GPT-5.5与Opus 4.8之间,成为迄今排名最高的开源模型。
这些排名真正指向的,是模型竞争维度的变化。
过去,国产大模型更多是在通用对话、中文语料、价格效率等维度上形成优势;而GLM-5.2进入的编程与Agent能力区间,恰恰是当前大模型厂商商业化最清晰、客户付费意愿最强的方向。企业客户并不会单纯为模型“会聊天”支付高溢价,但会为代码生成、流程自动化、长文档处理和复杂任务执行带来的效率提升付费。
AI研究机构Proximal评价称,GLM-5.2是"第一个真正缩小了Anthropic/OpenAI与其他模型提供商之间巨大技术鸿沟的模型"。
也正因为GLM-5.2进入的是编程和智能体这类高价值能力区间,它引发的讨论很快超出了普通用户圈层,转向一个更具产业意义的问题:中国大模型距离全球最前沿闭源模型究竟还有多远。
6月18日,特斯拉创始人马斯克在社交平台回复网友有关“你目前对中国达到Fable级别的预计时间表是什么?GLM-5.2 无疑缩短了差距”问题时表示,“或许(2027年)一季度。”
之后,清华大学教授、智谱AI创始人唐杰回复马斯克:“用不了这么久。(Won’t take that long)。”
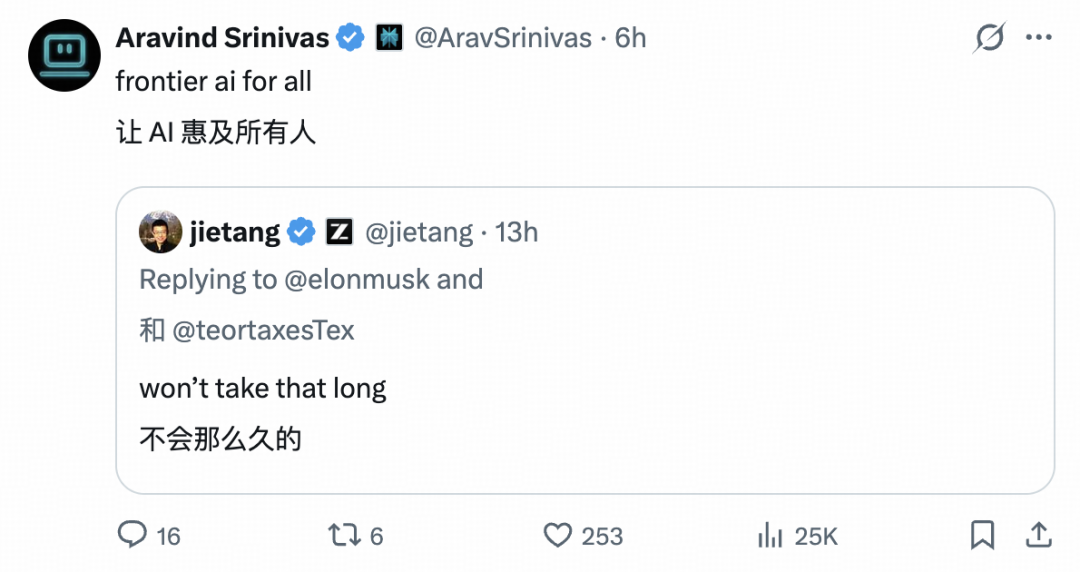
马斯克似乎不甘示弱,在下方回复:“单看各项跑分基准测试,或许是这样;但如果以实际落地实用价值来评判,就算明年一季度追上,也已经相当厉害了。Anthropic 的思路是对的,他们全力打磨具备真实实用价值的智能能力——这类能力在跑分榜单上体现不出来,但实实在在能转化成营收。”
唐杰则回复:专注就是我们唯一需要的东西,尤其是要聚焦于智能的本质究竟是什么……
这也解释了为什么这次模型发布会迅速外溢到资本市场。智谱被讨论的重点,不再只是国产模型能否降低调用成本,而是能否在智能体编程、长程复杂任务和企业工作流自动化等关键场景中,进入全球头部模型的同一张竞争表。
美国开源模型知名研究员Nathan Lambert评论称:“智谱GLM-5.2在当下在智能体能力超过了谷歌Gemini,这是一份极具分量的成就”,这意味着曾经垄断全球模型头部能力的谷歌、OpenAI、Anthropic“御三家”铁三角,第一次出现了来自中国的模型企业。
而对于长期处于追赶叙事的中国AI来说,在智能体时代首次出现了持平全球顶尖闭源模型的国产开源模型,无论对于智谱本身,还是对于资本市场,都是一剂强心针。
中国模型,从性价比平替到掌握定价权
模型能力的进步直接赋予了智谱乃至中国大模型第一次拿到的东西——定价权。
尽管GLM-5.2的输入/输出token价格较Opus 4.8低约72%至82%。但摩根大通在报告中指出,与GLM-5.1相比,GLM-5.2实际上是一次涨价:GLM-5.1采用分档计费,部分用量可享受较低费率;GLM-5.2统一适用较高定价层,客户实际支付的混合单价因此上升。由于性能提升主要来自强化学习与后训练优化,而非大规模扩张模型体量,成本基础基本稳定,这一调整有望推动Z.ai毛利率改善。
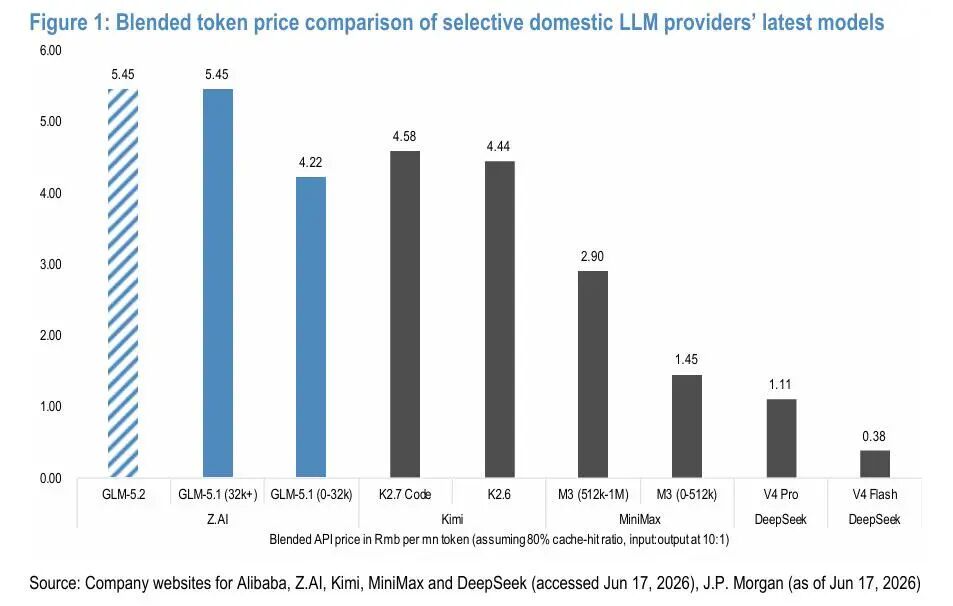
摩根大通据此得出结论:"成熟智能压缩定价,但GLM-5.2显示前沿升级能够实现相反效果。"
该行认为,AI模型定价正在呈现结构性分化:基础对话、简单摘要、标准代码辅助等已商品化能力将持续面临价格压缩,DeepSeek是这一力量的最典型代表;而能够解锁新工作流、提升任务完成率的前沿能力——尤其在编程、Agent、企业工作流自动化和长上下文任务场景——在客户"为完成任务而非为token付费"的逻辑下,仍可维持甚至提高定价。
更关键的是,智谱的高性价比叙事并不只来自模型价格,还来自其对国产算力生态的适配能力。外部供应约束强化了中国模型企业对自主算力体系的依赖,也倒逼智谱长期处于国产模型算力适配的第一梯队。GLM-5.2上线首日,即完成与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞等国产算力平台的全适配。
此前发布的国产大模型DeepSeek V4也已完成该类国产算力生态的全栈适配。这意味着,智谱、DeepSeek等中国大模型企业正在形成一条不同于海外闭源模型的竞争路径:以开源或开放生态降低使用门槛,以国产算力适配增强交付确定性,并以更低成本切入全球AI应用市场。
瑞银半导体团队最新的研究也给出了类似的观点:中国模型的 API 均价不到美国同类的 20%,训练成本不到 10%,但毛利率却和 Anthropic、OpenAI 基本持平,都在 20% 到 40% 之间。
这一区别很重要。如果低价只是补贴,那么价格优势最终会随着融资能力和资本开支压力而消失;但如果低价来自模型架构、推理效率、算力适配和能源成本的系统性优化,那么它就可能转化为长期竞争力。资本市场真正关注的,也正是智谱能否把这种成本优势从技术层面的“便宜”,变成商业层面的“高毛利、可放量、可持续”。
这种成本优势在智能体时代会被进一步放大。与聊天机器人时代不同,智能体执行任务往往需要多轮规划、工具调用、代码生成、结果校验和反复修正,token消耗会呈指数级上升。因此,当企业从试用AI转向大规模部署AI时,模型单价和推理成本会从一个技术指标,变成直接影响预算和ROI的经营指标。
据报道,Uber 今年头四个月就烧光了全年的 AI 预算,之后给员工的单个工具定了每月 1500 美元的天花板;沃尔玛限制内部智能体的用量;亚马逊干脆关掉了鼓励员工多用 AI 的内部排行榜;连微软都在考虑用 DeepSeek 的微调版替换 Copilot 里更贵的 OpenAI 和 Anthropic 模型。
当企业采购逻辑从“选最强的”转向“选够用且成本可控的”,智谱等国产模型的性能提升与成本优势,就不再只是技术讨论中的变量,而开始成为影响全球AI商业化竞争格局的关键因素。
智谱的财报也从需求侧印证了这一趋势:2025年,公司API调用量增长超过60倍;2026年,在API价格年内累计上涨83%的前提下,调用量不降反增,继续增长约400%。这说明,在高价值应用场景中,客户对模型能力和任务完成效率的需求,已经开始抵消单纯价格上涨带来的抑制效应。
开源优势厚积薄发,闭源风险摆上台面
如果说GLM-5.2的性能突破解释了智谱为什么能被重新评估,那么闭源模型可获得性的不确定性,则进一步放大了开源模型的战略价值。
对企业客户而言,模型采购并不是一次性工具选择,而是要嵌入研发、客服、办公、数据分析乃至核心业务流程。一旦底层模型的访问权限受到政策、地区、合规或供应链因素影响,企业面临的就不只是成本问题,而是业务连续性问题。
6月12日,美国商务部长卢特尼克援引《出口管理条例》第744.22(b)条款,以上述模型存在被外国军事情报机构利用的"不可接受风险"为由,要求Anthropic在向全球任何外国人提供相关访问权限前须取得商务部许可证,否则将面临刑事及民事处罚。东方证券研报援引媒体报道称,亚马逊研究人员成功突破Mythos模型安全限制,并发现Fable 5在特定提示引导下能够挖掘出至少四款软件中的安全漏洞,这被认为是触发监管介入的关键。Anthropic随即关闭两款模型的全球访问权限,并公开表示政府回应"不成比例",警告若同等标准扩展至全行业,所有前沿模型新部署可能实质上陷入停滞。
这一监管动向同样引发其他AI实验室的高度关注。据知情人士透露,OpenAI首席战略官Jason Kwon已通知员工,公司正在评估该政策动向的影响,并形容当前局面是"一个快速演变、存在大量未知因素的情况"。OpenAI总法律顾问Che Chang则在内部消息中提醒员工,在共同面对监管不确定性时,"不应尝试协调回应,反垄断规则在此适用"。
过去,闭源模型的主要风险更多被理解为价格较高、黑箱程度较强、企业数据治理复杂;而现在,访问权限本身也可能成为风险变量。对于全球开发者和企业客户而言,一个模型再强,如果无法稳定、持续、可预期地获得服务,其商业价值也会被打折。
有行业人士对观察者网表示:此次事件对产业链的影响体现在两个层面:其一,依赖闭源前沿模型的企业和开发者面临业务连续性风险,对替代方案的需求上升;其二,具备开放权重和本地部署条件的开源模型在可控性上具有天然优势,GLM-5.2恰在这一节点提供了性能接近前沿、成本显著更低的替代选项。
市场上对于开源模型的商业模式一直存在质疑,认为存在赔本赚吆喝,叫好不叫座的情形,在智谱2025年财报发布期间,智谱CEO张鹏就曾对此回应称:“开源生态是流量漏斗,凭借着模型高速迭代和原生推理优化的壁垒,我们可以实现API付费,私有化商业授权,Coding Plan订阅等多维度商业化闭环”。
这套逻辑能否跑通,关键取决于两个前提:一是开源模型本身必须足够强,能够吸引开发者和企业真实使用;二是模型厂商必须在推理效率、部署体验和产品化能力上形成壁垒,避免开源流量只停留在社区声量,无法沉淀为收入。GLM-5.2的意义正在于,它为第一个前提提供了更强的技术证明,也为后续API和企业级产品转化打开了更大的想象空间。
而随着本次美国闭源模型的风波,智谱和中国开源模型对于全球AI业界的价值出现了进一步提升,这也对于智谱未来的商业转化产生了巨大的潜在收益。
智谱被重估,资本市场也在重估AI主线
智谱的重估,也反映出资本市场对大模型公司偏好的变化。
早期AI投资更看重模型参数、全模态能力、C端应用想象和全球化用户增长;但随着Anthropic式的B端收入曲线被验证,市场开始更重视编程、智能体和企业工作流这些更容易转化为收入的场景。
在这个背景下,智谱和MiniMax这两家相隔一天上市的大模型公司,上市后的走势分化就具有了更强的参照意义。
在上市初期,智谱一度因为业务模式偏B端,重资产研发等标签相对不被看好,而MiniMax则凭借其全球化布局和全模态优势更受到资本青睐。
但随着Anthropic跑通面向企业客户的AI商业化模式,并在营收曲线上出现指数级增长,市场开始重新理解智谱的价值。偏B端、重研发、强模型、重编程和智能体能力,这些曾经压低市场想象空间的标签,反而开始变成智谱对标Anthropic式路径的核心依据。
这种重新定价,也与大模型行业自身的演进节奏有关。大模型竞争大致经历了从聊天机器人、推理模型到智能体的阶段转换:聊天机器人解决的是人机交互入口,推理模型提升的是复杂问题求解能力,而智能体真正指向的是软件工程、办公流程、企业协作和业务自动化。
在这个过程中,智谱的GLM架构承担的是国产大模型在基础模型路线上的探索;而GLM-5.2在编程和智能体能力上的突破,则让智谱第一次更明确地站到了全球高价值模型能力竞争的牌桌上。
对中国AI而言,这不仅是一次单点模型升级,也是在智能体时代争夺产业入口的一次关键卡位。
对于智谱来说,万亿港元市值既是资本市场的期待,也是一张更高难度的考卷。
首先是算力约束。作为国内最缺算力的模型公司之一,智谱在面对API和Coding Plan爆发式增长时,长期处于算力紧张状态。GLM-5.2完成国产算力平台适配,只是解决了“能不能适配”的问题,接下来还要回答“能不能稳定、大规模、低延迟交付”的问题。对于模型公司而言,算力不仅决定下一代模型训练速度,也直接决定商业化收入的承接能力。
其次是增长兑现。API调用量和订阅产品增长可以证明需求存在,但资本市场最终仍会追问这些需求能否沉淀为稳定收入、可持续毛利和高留存客户。尤其在模型价格快速变化、开源竞争持续加剧的背景下,智谱需要证明自己不仅能获得流量,也能形成可重复的商业闭环。
第三是模型迭代压力。在全球前沿模型迭代速度不断加快的背景下,一次GLM-5.2的突破并不足以支撑长期估值。智谱需要持续证明,它的模型能力提升不是单点爆发,而是一条可延续的技术曲线。
智谱的万亿市值不是终点,而是一次提前支付的市场预期。如果模型能力、成本优势、开源生态和B端商业化能够继续相互强化,智谱此次重估就可能成为中国大模型公司从追赶者进入全球竞争者阶段的标志性时刻;反之,当前市值中包含的技术领先、收入增长和国产算力替代预期,也会成为后续市场反复检验的压力来源。

 VIP复盘网
VIP复盘网
