



最深的瓶颈依然是“数据鸿沟”
6月22日,“物理AI概念股”天娱数科再次涨停,此时距离它澄清相关概念已有一段日子。
但就在这两天,港股“物理AI第一股”深圳多光谱AI公司海清智元在港交所挂牌,掀起了市场的巨大兴趣,因为它超额认购近7200倍,开盘涨幅超过300%,市值一度突破200亿港元。
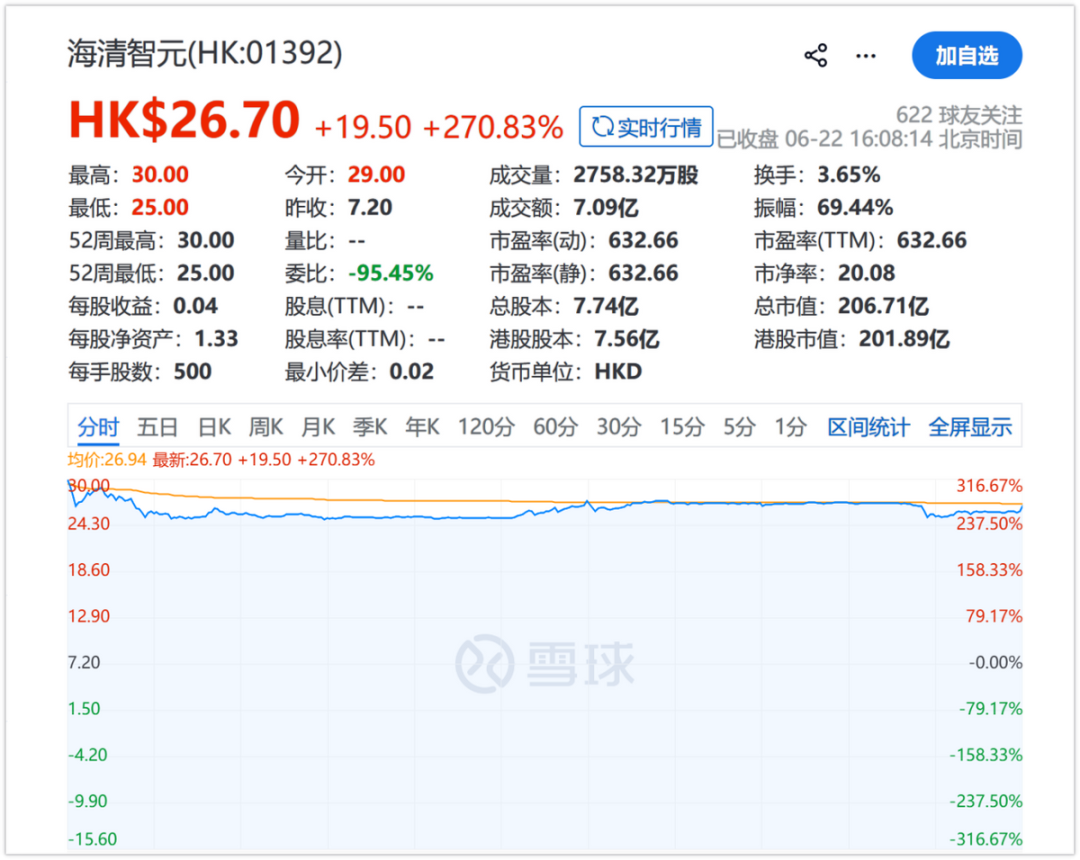
在市场看来,物理AI显然是个长期概念——从实际来说,确实如此,但资本市场给予的短期关注度总是过高的。
这一轮物理AI热潮源自英伟达在6月初开源了Cosmos 3世界模型,并发布与宇树合作的人形机器人参考平台。毕竟是“下一个50万亿美元的市场机会”,从资本市场到产业界,所有人都在试图理解它到底是什么——以及更重要的是,哪些要素决定了它能不能真正跑通。
从底层逻辑来看,大模型时代的AI学会了读文、生图、写代码,但这些能力始终飘在数字空间里。物理AI想要做的事情,是让AI像人类一样理解物理世界的规律——重力、摩擦力、刚性、柔度、碰撞——然后在这个世界里行动。它不仅仅是让机器人动起来,而是让机器人在真实环境中能看懂、能预测、能操作、能适应。
这件事的难度,远超大模型的参数竞赛。所以物理AI真正的要素可能是“原子化”的——和发展物理世界AI有关的一切,都是未来物理AI的潜力股。于是,也就有了现在的市场情况。
而问题在于,物理AI并不是某一个单一技术的突破,它需要几个核心要素同步进化:第一,足够逼真且规模宏大的物理交互数据来训练模型;第二,能够精确模拟物理世界,并且将模拟与真实差距缩到最小的仿真引擎;第三,能够从真实世界采集高质量感知数据的硬件终端。这三个要素构成了一个闭环:数据驱动模型,模型指导仿真,仿真正反馈到硬件执行,硬件再产生新的数据。
正因为如此,天娱数科这些早已做出澄清的企业,依然会留在资本的视野中。比起物理AI这个概念,它手握的真正对AI发展有价值的资源,才是关键。

最深的瓶颈依然是“数据鸿沟”
如果一定要给物理AI找出一项最紧迫的制约因素,那不会是算力,不会是算法——而是数据。
英伟达机器人业务负责人Spencer在GTC大会后的交流中提到一个判断:“机器人领域目前最大的挑战,是依然无法捕获每一种长尾场景。”
我们知道,大模型之所以能够在语言和图像上取得突破,很大程度上得益于互联网上积累了海量的文本和图片数据。但物理AI需要的数据,是机器人在真实环境中抓取物体、搬运箱子、插拔线缆、躲避障碍的行为数据。这些数据不存在于互联网上,也无法靠爬虫抓取。
它们需要被“制造”出来。
制造数据有两种方式。一种是在真实世界中让人类远程操控机器人,一条一条地采集示范数据。这种方式成本极高、效率极低,而且很难覆盖足够多的场景。
另一种是在虚拟世界里进行仿真,用计算机生成大量合成数据。成本低、规模大,但面临一个核心难题:仿真世界与真实世界之间的差距。

这就是物理AI领域最深刻的矛盾——Sim-to-Real Gap。仿真器里模拟得再完美的抓取动作,放到真实世界中可能因为摩擦力参数偏差一丁点就抓不住。而英伟达的Cosmos 3世界模型,恰恰是冲着这个矛盾去的。
Cosmos 3被英伟达定义为“世界模型”,它的核心能力,是在时序维度上感知、预测并生成物理世界的后续状态,也就是“接下来会发生什么”。
它既可以被当作一个世界推理器来使用,理解场景并做出判断;也可以作为仿真器,在闭环中测试机器人策略;甚至可以直接为不同的机器人本体生成动作指令。
这四种功能的并列,标志着Cosmos不是一个单一环节的工具,而是整个物理AI开发流程的基础设施层。它的位置,介于数据生成和模型训练之间——或者说,它本身就是一座通往“虚拟与真实融合”的桥梁。
但即便是Cosmos,也并非万能。英伟达坦诚,“高精度操作任务所需的物理精度,目前的世界模型尚未完全达到”。例如电子产品的精密装配,所需要的精确到微米的物理仿真,世界模型还做不到。
在这个层面上,Cosmos必须依赖Omniverse——基于传统物理引擎的精确仿真器——来提供“物理锚点”。于是出现了一种共生结构:Omniverse提供精度,Cosmos提供广度;前者生成小而准的数据,后者生成大而多样的数据。
这个共生关系,恰恰也揭示了一个深层现实:物理AI的数据难题,短期内没有单一解法。数据鸿沟的填补,需要仿真精度和数据规模的双重突破,而这两件事目前没有一家公司能够同时做到最好。

感知革命的起点:
从“看得见”到“看得懂”
如果说数据是物理AI的“燃料”,那么感知硬件就是物理AI的“眼睛”。
过去几年,计算机视觉的主流是2D图像识别——给一张照片,识别里面有没有人、有没有车。但物理AI需要的感知能力完全是另一个维度:它需要理解物体的三维形态、空间位置、表面纹理、材质属性,甚至还需要在光线不足或表面纹理缺失的情况下保持精度。
而这,就让一些端侧模组企业,拿到了物理AI这块金字招牌——它们不一定是这么认为的,但市场是这么认为的。其中就包括天娱数科的参股公司,芯明。
6月16日,芯明在张江大会上发布了R216g 3D视觉AI模组,它正是这种需求的产物。

这款产品专为人形机器人、灵巧手和协作臂设计,采用主动式散斑技术,在工件纹理性较差或者光线不足的环境下,依然能输出亚毫米级的深度数据。更关键的是,模组内置自研空间智能芯片,提供3.5 TOPS端侧算力,可以在模组内部实时运行物体识别和姿态判断,不需要把数据传回主机处理。
这种“感算一体”的架构,反映了物理AI对感知硬件的核心要求:低延迟、低功耗、高鲁棒性。因为机器人在抓取动作中,从看到目标到发出指令的时间窗口是以毫秒计算的,不可能把每一帧深度数据都上传到云端去做推理。端侧算力越强,系统响应越快,机器人失败的概率就越低。
前文提到的“物理AI第一股”海清智元的多光谱AI,则代表了感知技术另一个维度的进化。多光谱——紫外、红外、可见光的融合——让AI不仅能“看到”物体的形状,还能“感知”到物体的材料成分、温度变化和隐藏缺陷。这种能力用在消防、工业安全、能源巡检等场景中,相当于给物理AI加了一个“隐性维度”的感知通道。
芯明和海清智元,一个做3D视觉,一个做多光谱融合,它们都在关注物理AI时代的感知革命,后者正在从2D走向3D,从单一谱段走向多光谱融合,从纯算法走向“算法 芯片 光学”的系统级集成。这个软硬一体的感知体系,必然会被市场赋予很多想象力。

数据的“资产化”与隐形的底座
在数据和感知之间,还需要一层连接——把真实世界采集到的信息,转化为可以供模型训练和仿真使用的结构化数据。这是物理AI产业链中容易被忽视但不可或缺的一环。而“求贤若渴”的市场,又把目光放在了天娱数科的数据优势上。
天娱数科拥有Behavision空间智能MaaS平台。根据公开信息,公司已累计沉淀超过150万条3D数据以及超过518万条多模态数据,其中10项核心数据集已经在北京国际大数据交易所完成数据资产登记。平台的核心能力架构是ABC:Assets(数据)、Behavior(行为)、Client(接口),覆盖了从数据采集、标注到输出适配的全流程。
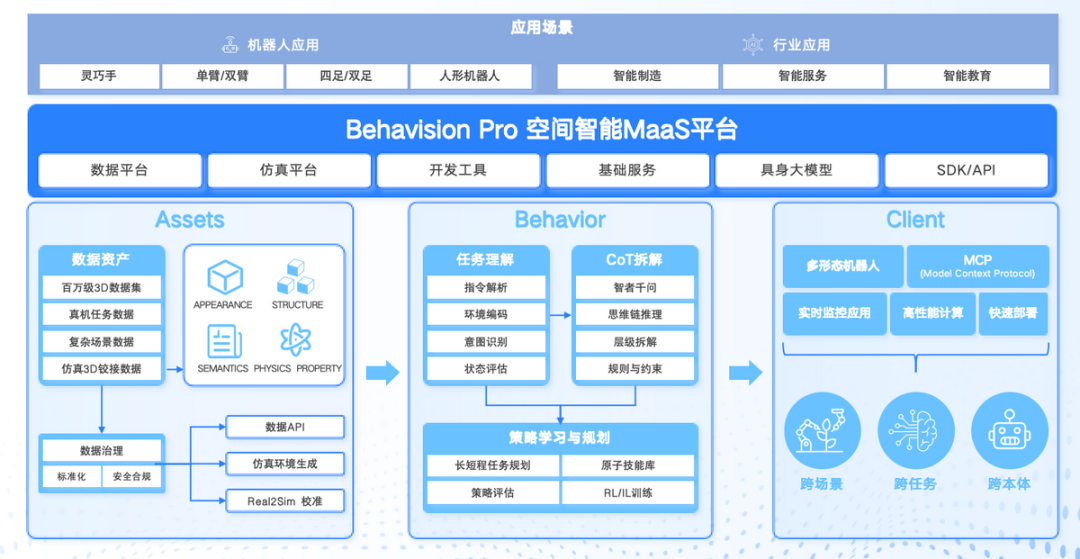
天娱数科首席数据官吴邦毅此前在今年的人形机器人生态大会上提到一个行业共识:“具身智能需要大量任务级、过程级物理交互数据,而行业普遍存在数据碎片化、孤岛化、标注难、复用率低等问题。”天娱数科的策略是,把自己沉淀下来的多模态数据通过资产登记的方式确权,然后通过平台向行业输出。
这个模式并不卖硬件,不卖模型,而是卖“数据服务”。它在物理AI产业链中的位置,类似于一个“数据炼油厂”——从各种真实场景中采集数据,清洗、标注、结构化,然后以标准化的形式提供给下游的机器人公司、自动驾驶公司和仿真平台。
目前这个方向的商业化还处在很早期。天娱数科自己也澄清过,“没有物理AI业务”,没有形成相关业务收入。但从产业发展规律来看,物理AI要规模化落地,高质量的数据供给是必不可少的基础设施。当机器人公司数量增多、场景变多、路测规模扩大时,“数据荒”只会越来越严重,而提前卡住数据生产和确权身位的公司,就有了供给侧的主动权——至少,在市场看来是这样。
长远来看,不必急于用当下的收入来评价这个方向的估值。反而是过早限制物理AI的想象力,并将其圈定于“概念股”,既看小了物理AI的真实潜力,也会影响这些企业长坡厚雪的发展预期。
物理AI是一个长坡厚雪的赛道,数据基础设施的建设周期领先于应用爆发周期。这个逻辑在新能源和自动驾驶时代已经被验证过。

 VIP复盘网
VIP复盘网
