

2026年,计算机板块正迎来基本面修复与AI范式转移的共振拐点,模型能力迭代未见上限,Claw类应用渗透率快速提升,国内算力需求陡增,AI infra走进新阶段。下半年建议关注:1)AI产业建议从需求维度出发,关注涨价、缺货的算力方向、提效的infra与云产业、部分景气度高的应用方向。2)非AI产业的投资建议关注政策催化下的数币2.0、智驾以及商业航天等政策催化机会。
海外模型三足鼎立,商业化战略分层
海外大模型格局已基本集中于OpenAI、Anthropic和Google,三者在底层模型的迭代方向上已呈现出一定程度的分层:
OpenAI:战略重心向B端商业化倾斜,加速构建系统级Agent生态。过去OpenAI更追求AGI,但面对另外两家竞对尤其是Anthropic在ARR与估值的反超,已逐步向B端适配倾斜。其中,GPT-5.5深化长周期复杂任务执行能力为基础,更试图借助全面升级的Codex实现对终端操作系统的底层接管与自动化调度。同时,原生推理视觉模型GPT Image 2的推出,也标志着其在多模态领域全面补齐短板。
Anthropic:巩固B端壁垒,冲击模型智能上界。凭借早期在代码及合规方面的布局,Anthropic已成功在金融、医疗等高门槛企业级市场建立用户粘性与商业化壁垒。在确立B端基本盘后,Anthropic也开始探索智能边界。顶级模型Mythos在网络漏洞挖掘等复杂场景中展现出颠覆性能力,验证了模型能力的加速突破,更通过极高的溢价策略证明了顶尖智能的价值。
Google:依托生态壁垒,实现全矩阵布局。谷歌凭借底层算力基础设施与YouTube等高质量视频数据生态,始终保持着最完善的模型矩阵。从通用基座Gemini、视频模型Veo、图像模型Nano Banana,到端侧小模型Gemma及世界模型Genie,谷歌已完成全赛道的覆盖。通过算力统筹与技术降本,谷歌有望凭借性价比优势,加速AI能力在千行百业基础设施中的全面渗透。
OpenAI: GPT系列逐步优化B端场景应用,Image-2补齐多模态能力。
OpenAI 4月24日发布最新旗舰模型GPT-5.5。作为全新旗舰模型,GPT-5.5在推理精度、复杂任务规划及系统级自治能力上实现了对当前行业基准的全面超越。在衡量复杂命令行与代码流的Terminal-Bench 2.0测试中,GPT-5.5准确率达到82.7%,相较前代GPT-5.4提升超7个百分点,大幅领先Claude Opus 4.7的69.4%;在评估真实专业知识工作流的GDPval测试中,GPT-5.5亦取得84.9%的成绩,超越了垂直行业专家基线。此外,在考验模型独立操作真实计算机环境的OSWorld-Verified评测中,其准确率达到78.7%,标志着其在跨应用协同操作能力上亦已追平Opus 4.7。
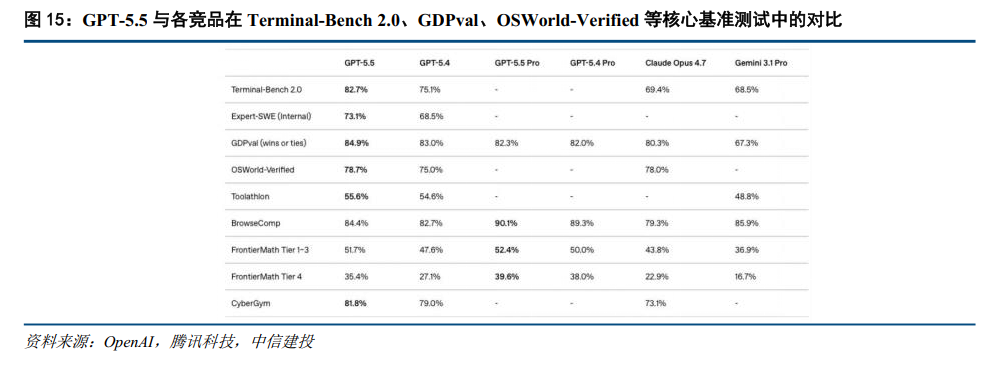
长上下文与复杂任务执行能力大幅跃升,自我优化潜力显现。从案例测试看,GPT-5.5自主拆解、多步推理及自我代码审查与纠错能力较强。在面对前端应用开发、3D引擎渲染(如WebGL/Three.js应用重构)及高难度数学证明(如在纯数学领域协作发现拉姆齐数的新证明路径)等复杂任务展现出较好的表现。在超长上下文处理方面,GPT-5.5支持400K-1M上下文,在MRCR v2(512K到1M长度)测试中准确率高达74.0%,显著优于Claude Opus 4.7的32.2%。此外,OpenAI在技术披露中指出,GPT-5.5驱动的Codex系统已能够分析底层数据中心的生产流量日志,并自主编写负载均衡启发式分区算法,使系统Token生成速度提升逾20%,已反应模型自我优化潜力。
商业化路径逐步清晰,高Token效率 Agent能力突破助力B端部署。在定价策略上,GPT-5.5 API输入与输出定价分别为5美元与30美元每百万Token。虽然绝对单价较前代翻倍,但得益于极高的Token利用效率,其完成单次复杂任务的实际Token消耗量显著减少,整体系统运行成本反而具备优势——据Artificial Analysis的智能指数,GPT5.5在成绩最高的同时,其成本仅为同类前沿编码模型的一半;在内部benchmark测试中,GPT-5.5较GPT-5.4在相同表现下消耗Token数同样更低。此外,GPT-5.5的Agent能力同样得到了大幅突破,在官方测试中,GPT-5.5可以在真实终端环境中连续运行接近10小时,完成从任务拆解、执行到调试交付的完整流程,有望更好助力B端场景落地。
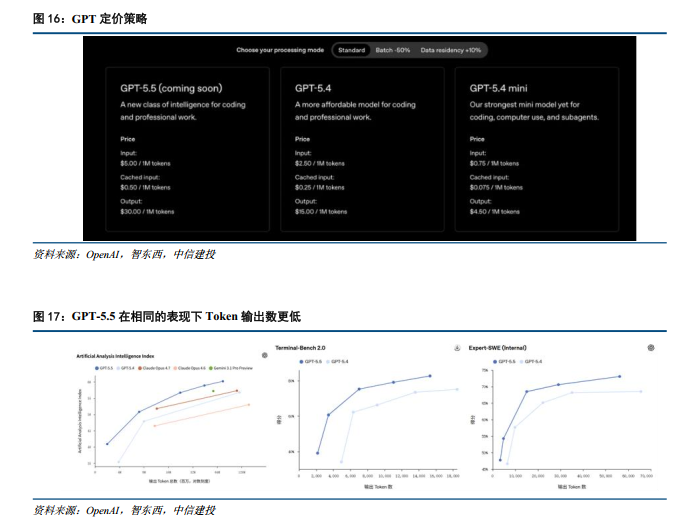
Image 2重塑视觉生成范式,原生推理架构建立断层式技术优势。OpenAI 4月21日推出全新视觉基座模型GPT Image 2,上线即以创纪录的241分优势绝对登顶Text-to-Image Arena等核心榜单。在底层架构上,该模型打破传统扩散模型路径依赖,首次引入原生推理机制,使模型在渲染前具备自主检索、推演布局与内容自检能力。核心指标方面,其彻底攻克多语种密集文本渲染难题,准确率推升至99%,并具备生成复杂几何证明图解、长文本精确排版及最高3840像素动态分辨率重构的极强工程水准。

Anthropic:Claude系列持续迭代,Mythos探索智能上界。
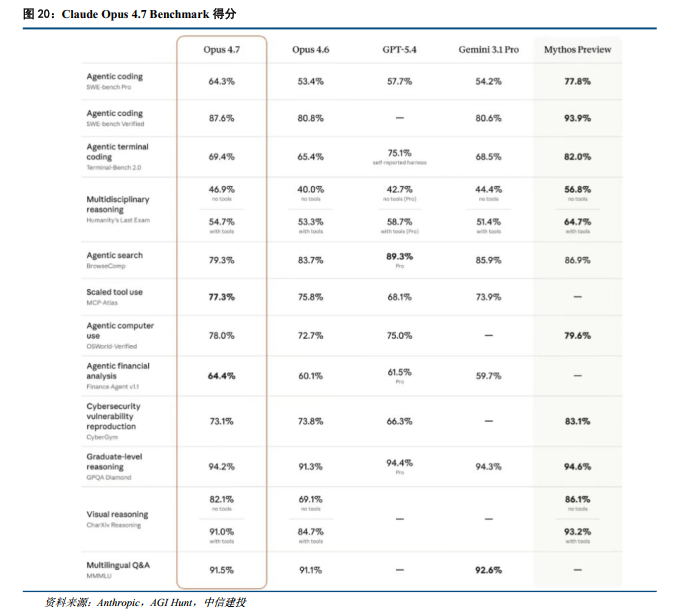
Opus 4.7实现视觉与Agent自主能力的跃升,高价值垂类场景有望突破。4月16日,Anthropic发布最新商业级旗舰模型Claude Opus 4.7。在核心能力上,Opus 4.7在多项复杂工程与知识工作基准中取得突破,其SWE-bench Pro得分从前代的53.4%跃升至64.3%(超越GPT-5.4的57.7%,亦高于后续发布GPT-5.5的58.6%)。在Agent领域,模型不仅在Finance Agent evaluation中实现SOTA,更在衡量金融、法律等高实际经济价值知识工作能力的第三方评测基准GDPval-AA中达到业界顶尖水平。此外,模型视觉感知能力实现代际飞跃,支持最高2576像素长边的图像(约375万像素,分辨率达前代3倍),XBOW视觉敏锐度基准得分从54.5%飙升至98.5%,为依赖精细视觉细节的多模态应用如界面重构、复杂图表解析等打开了空间。
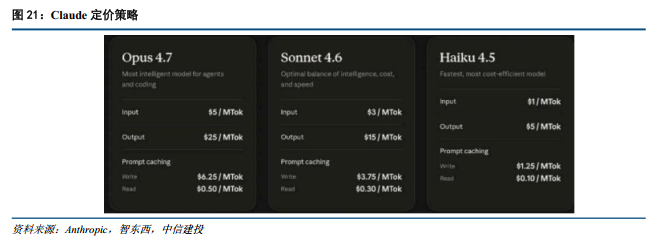
加码企业级长周期任务,精细化Token控制优化商用ROI。定价方面,Opus 4.7维持了前代Opus模型每百万Token 5美元/25美元的输入/输出价格。为匹配日益复杂的B端工作流,Opus 4.7引入了“自我验证”机制,能够在长周期任务交付前自主审阅与纠错。同时,Opus 4.7推出了针对深层代码审查的ultrareview功能,并将支持无间断执行的Auto Mode下放至MAX用户。据Notion团队反馈,接入Opus 4.7后其整体性能提升14%,工具调用出错率下降约三分之一。为应对新Tokenizer(相同的输入内容,token数量会比以前多出约0% 到35%)及新增的xhigh推理档位带来的潜在Token消耗增长,Anthropic同步开放了任务预算功能,允许企业在长任务中精细化管理Token支出,进一步完善了B端商业化的成本可控性。
Mythos编程能力跃升突破,展现颠覆性网络安全漏洞挖掘能力。区别于常规商业迭代,Anthropic于4月7日官宣了未向公众开放的顶级模型Claude Mythos Preview。据悉,该模型参数规模或达到10T,且在以编程能力为代表的基准测试中呈现出突破式跃升。其中,SWE-bench Verified得分高达93.9%(较Opus 4.6提升13.1%,亦高于Opus 4.7的87.6%),SWE-bench Pro得分达77.8%(高于Opus 4.6的53.4%和Opus 4.7的64.3%),Terminal-Bench 2.0亦达到82.0%(高于Opus 4.6的65.4%和Opus 4.7的69.4%)。更为关键的是,Mythos展现出极强的自主漏洞挖掘能力,在几周内成功挖出数千个高危0day漏洞,包括隐藏27年之久的OpenBSD远程崩溃漏洞及16年前的FFmpeg边界漏洞,其以美元计价的漏洞发现效率据测算达前代模型的10倍。
成立Project Glasswing联盟,极高定价印证顶尖算力的极高商业价值。鉴于Mythos带来的系统级网络安全风险,美财政部与美联储甚至举办针对系统性金融风险的紧急会议,而Anthropic亦选择暂缓向公众开放,转而联合AWS、微软、谷歌等12家核心大厂及40余家关键基础设施组织成立Project Glasswing联盟,旨在为防御方争取6-18个月的安全加固窗口期。在定价侧,Mythos Preview向受邀机构开出了每百万Token 25美元/125美元的输入/输出的极高价格,达到Opus 4.6/4.7的5倍,持续验证了模型智能上界突破带来的价格上行趋势。

Google:模型矩阵丰富,全面布局各类场景。
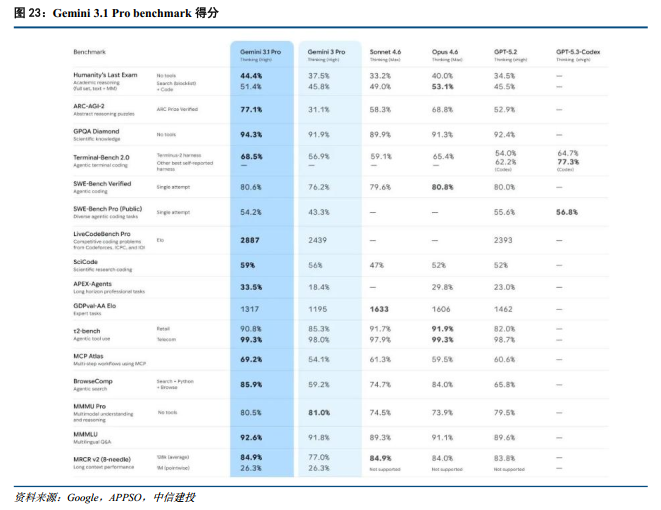
Gemini 3.1 Pro核心推理能力升级,稳固全模态与复杂任务解决优势。谷歌于2月20日发布新一代旗舰模型Gemini 3.1 Pro。在衡量前沿抽象推理能力的ARC-AGI-2测试中,该模型以77.1%的准确率大幅领先竞品,相较Gemini 3.0 Pro的31.1%实现翻倍跃升。在代码与Agent领域,其LiveCodeBench Pro得分达2887,并在评估第三方任务执行能力的MCP Atlas测试中以69.2%的成绩领先。此外,Gemini 3.1 Pro在3D空间推理与复杂图形生成方面取得突破,仅需文本指令即可快速生成高质量、带交互的SVG动态图形,且原生支持百万Token超长上下文,MRCR v2大海捞针准确率达84.9%,进一步巩固了其在复杂逻辑推理与全模态输入领域的头部地位。
从应用案例看,Gemini 3.1 Pro自然语言编程与应用生成能力较强。通过Vibe Coding范式,用户不仅能生成动态可视化图表,更能在数分钟内定制专属高级应用软件,显著降低复杂工作流的开发门槛。定价方面,Gemini 3.1 Pro API维持了与上代一致的平价策略,百万Token输入与输出分别为2美元和12美元,展现出较高的性价比优势。目前该模型已全面接入Google AI Studio、Vertex AI及面向消费者的Gemini App和NotebookLM,全面服务用户各类需求。
模型布局全面:多模态、端侧小模型与世界模型构建护城河。除Gemini系列外,谷歌全面布局模型矩阵。图像生成领域发布Nano Banana 2,以极低算力成本提供旗舰级画质,并在复杂文本渲染与高保真度上实现突破;视频生成领域更新Veo 3.1,大幅增强对音频与叙事逻辑的精细化控制,并支持最长148秒的连贯视频延展,进一步打通AI影视制作工作流;端侧与开源领域推出Gemma 4系列并全面切入Apache 2.0协议,其26B MoE与31B Dense版本性能比肩千亿级闭源模型,极小参数版本原生支持边缘设备完全离线运行,有望打开端侧AI的商业空间;世界模型领域推出Genie 3,率先落地生成式交互环境,从底层颠覆传统游戏化编码至渲染的开发逻辑,提前卡位游戏、工业等场景AI需求。
国内模型崛起,多模态场景反超
通用模型:进入密集发布期,迭代加速
国产大模型步入密集爆发期,能力高位收敛,全线挺进全球第一梯队。据Artificial Analysis统计,今年以来,国内头部厂商如阿里、DeepSeek、Kimi、MiniMax、小米、智谱等的模型迭代速度显著加快,并在多模态输入、长上下文窗口、长周期复杂任务执行、代码能力上补齐短板。同时,通过压缩方式、注意力机制等底层架构方面的创新,国产模型在SWE-Bench Pro、GDPval等核心基准上追平甚至反超GPT-5.4与Claude Opus 4.6等海外头部模型的同时,亦展现出相当程度的Token性价比。能力 性价比有望构成国产模型在AI商业化落地下半场中的技术壁垒。
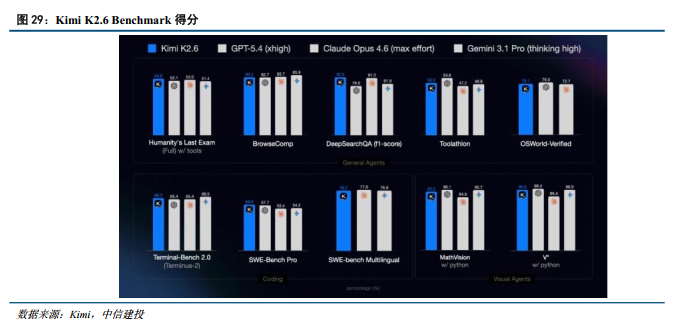
Kimi:4月20日发布并开源K2.6模型,带来代码执行与集群能力的全面跃升。在单体Agent能力上,模型以58.6的得分登顶SWE-Bench Pro榜首;在集群协同上,K2.6架构原生支持高达300个子Agent并行完成4000个协作步骤,并支持长达5天的持续自主运行。依托官方自研的M3 Max大模型推理引擎,K2.6深度重构了核心线程拓扑结构,使其峰值吞吐量从1.23 MT/s大幅跃升133%至2.86MT/s。此外,其在前端UI全栈自建水平上展现出显著优势,在专门创建的前端开发设计基准测评Kimi Design Bench上的胜率大幅领先Gemini 3.1 Pro。
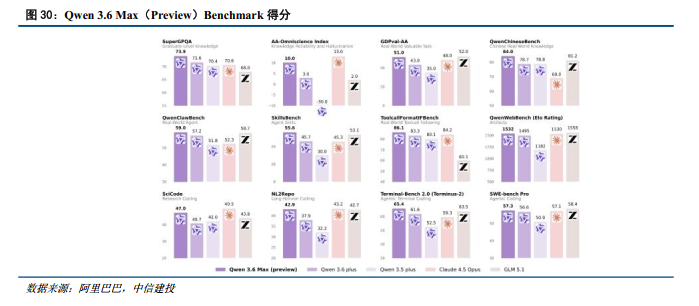
阿里巴巴:4月20日通义千问发布新一代旗舰模型早期预览版Qwen3.6-Max-Preview,重点提升了智能体编程能力(和前代相比,SkillsBench 9.9、SciCode 10.8、NL2Repo 5.0、Terminal-Bench 2.0 3.8)、世界知识储备(和前代相比,SuperGPQA 2.3、QwenChineseBench 5.3)与指令遵循(和前代相比,ToolcallFormatIFBench 2.8)表现。在权威第三方评测Artificial Analysis最新榜单中,该模型综合性能登顶国产模型榜首,超过GLM5.1、MiniMax-M2.7等模型。在工程化部署侧,阿里云百炼API同步首发了preserve_thinking功能,允许在消息流中保留前序轮次的思维内容,专门针对复杂的智能体多步连续执行任务进行了底层状态维护与可靠性增强。
小米:4月23日,小米正式发布MiMo-V2.5系列基座大模型。其中MiMo-V2.5-Pro专为长难Agent任务打造,具备1M超长上下文窗口,在通用智能体能力、复杂软件工程以及长程任务等维度上已能与Claude Opus 4.6、GPT-5.4等全球顶尖Agent模型相媲美。据官方测试,MiMo-V2.5-Pro在从零构建SysY编译器及模拟电路EDA(FVF-LDO)设计等重度测试中表现优异,综合实力逼近全球顶尖闭源模型。此外,该系列在全模态感知实现全线跨越的同时,重点对Token使用效率进行了深度优化。在达到相同Agent基准榜单ClawEval分数情况下,MiMo-V2.5-Pro相比Kimi K2.6节省了42% Token,MiMo-V2.5相比Muse Spark节省了50% Token;配合夜间专属优惠及不区分上下文窗口的API统一定价策略,大幅优化了企业级客户的商业化调用成本。

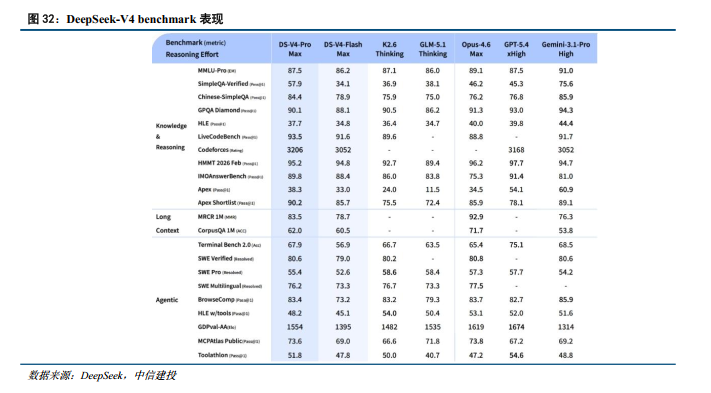
DeepSeek:4月24日,DeepSeek-V4正式发布,包含Pro(总参数1.6T,激活49B)与Flash(总参数284B,激活13B)两个版本,原生支持1M上下文长度。在公开测评集表现上,DeepSeek-V4确立开源新标杆,紧逼顶尖闭源模型。在知识与推理维度,V4-Pro在MMLU-Pro测试中得分达87.5%,在编程竞赛基准Codeforces中获得3206的Rating评分,不仅大幅领先开源竞品,更比肩甚至局部超越了GPT-5.4(3168分)与Gemini 3.1 Pro(3052)。在长文本领域,其MRCR 1M(百万上下文多海捞针)准确率达83.5%。在Agent复杂任务基准中,V4-Pro在SWE Verified(80.6%)、Terminal Bench 2.0(67.9%)以及贴近真实商业场景的GDPval-AA(1554分)评测中,展现出极强的端到端执行与工具调用能力,稳居全球第一梯队。
核心技术方面,DeepSeek-V4主要实现了CSA、HCA与mHC三项关键技术创新,大幅压缩KV Cache节省Token计算量的同时,保证了模型训练的稳定性。此外,在后训练阶段,V4放弃了传统的RLHF,转而采用多教师同策略蒸馏与生成式奖励模型,有效避免了传统强化学习导致的对齐税(对齐带来的模型降智)及模型通用能力退化现象,实现了模型多维能力的高度均一化。
多模态模型:工程化产物,国内产品后来居上
字节跳动与MiniMax原生多模态矩阵布局完整。作为国内最早在多模态领域完整布局的厂商,字节跳动与MiniMax持续深化其全模态产品矩阵。其中,字节跳动于2月12日正式更新Seed2.0与Seedance2.0,前者深度融合LLM与Agent功能,在视觉推理与动态场景理解等测试中达到SOTA水平;后者则依托原生统一架构,实现音、画、文本的深度协同生成,支持多镜头长叙事与原生级声音画同步,在动作一致性与物理规律遵循上展现出极高的工业级标准。MiniMax通过视频模型Hailuo、语音模型Speech及音乐模型Music 2.6构建了完整的多模态布局。其中,Hailuo 2.3在肢体动作呈现与人物微表情方面实现显著提升;Speech 2.6将端到端延迟降低至250毫秒内,并提供高保真的Fluent LoRA音色复刻;Music 2.6则在乐理结构理解与指令控制上取得突破,全面支持BPM、Key及段落结构的精细化编排;三者协同配合,极大降低了复杂多模态内容的创作门槛。
大厂全面补齐多模态能力。国内其他大厂通用在多模态发展浪潮下加速补齐能力版图。其中,智谱AI联合华为开源了首个基于国产算力底座(昇腾800T A2 昇思MindSpore)训练的多模态SOTA模型GLM-Image,采用自回归 扩散解码器架构,在复杂文字渲染(CVTG-2K)榜单取得开源第一,验证了国产全栈算力在多模态大规模训练上的可行性。阿里巴巴ATH创新事业部推出原生多模态视频生成模型HappyHorse,不仅实现电影级的叙事质感与极强的指令遵循,更以720P低至0.44元/秒的价格彰显极致性价比。
DeepSeek则在最新技术论文中提出多模态理解新思路,针对多模态模型普遍存在的指代鸿沟(模型难以精准指出画面的中的物体)问题,DeepSeek首创将边界框与空间坐标点作为视觉原语离散化,并直接嵌入大语言模型的思维链中,实现了跨模态的精准空间锚定。底层计算层面,该模型依托284B参数/13B激活的MoE主干与自研ViT,创新性引入压缩稀疏注意力机制(CSA),将视觉Token经过空间级联压缩,实现高达7056倍的极端压缩率(单张756×756图片仅占用81个KV Cache条目)。在后训练阶段,团队通过先专家、后通用的在线策略蒸馏及针对性设计的GRPO强化学习机制,使模型在拓扑推理及细粒度计数等基准测试中,对GPT-5.4与Claude Sonnet 4.6等顶尖闭源模型形成断层式领先。
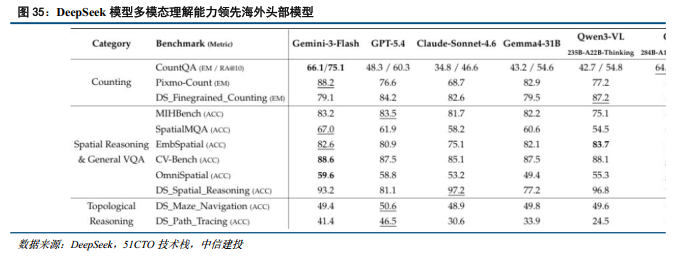
多模态赛道竞争白热化,国内视频生成模型实现霸榜反超。据LlmArena排行榜数据,在图像生成与编辑领域,美国头部大厂暂处领先,OpenAI的GPT-Image-2与谷歌的Gemini 3.1系列包揽了双榜单的前五名,而国内模型如Qwen-image 2.0(文生图第9名)与字节Seedream 4.5(图像编辑第10名)亦成功跻身全球Top 10阵列,保持着极强的追赶态势。而在视频生成与编辑领域,国产模型已实现对海外巨头的反超。字节跳动的Seedance 2.0与阿里的HappyHorse 1.0凭借原生多模态架构的优势,强势包揽了文生视频、图生视频以及视频编辑三大核心榜单的全球冠亚军,将谷歌Veo 3.1、OpenAI Sora 2 Pro及xAI的Grok均压制在其后;此外,快手Kling系列在视频编辑榜单中亦稳居前列(第4与第6名)。

大模型能力增强提升渗透率,推动Token指数级增长
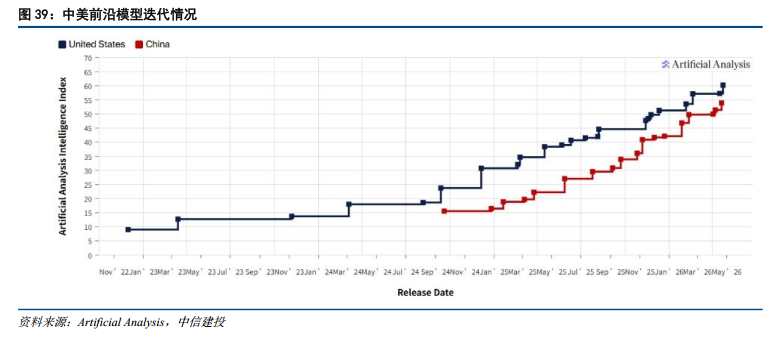
全球大模型智能水平呈陡峭上升,中美双模型能力差距持续缩小。正如2.1和2,2中提及的,中美大厂模型均快速迭代,对应模型能力加速跃升。参考Artificial Analysis大模型智能指数,自2022年底以来,美国模型智能指数持续增长,且呈现加速趋势,重大能力迭代的时间窗口持续缩短。同时,国内大模型则自2023年下半年起加速,在短时间内大幅缩小了与美国头部模型的差距。随着时间推移,中国开源模型能力有望持续逼近海外头部模型能力。
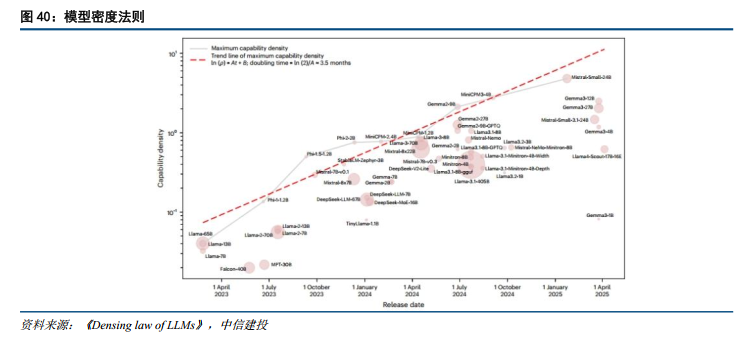
模型密度法则显现,算力向能力转化的效率步入指数级爆发阶段。模型能力跃升不仅依赖算力堆叠,底层算法效率的突破同样推动模型智能上界突破。清华大学团队最新研究揭示,大模型领域已呈现出显著的密度法则(Densing Law),即模型能力密度随时间呈指数级增长,开源大模型的最大能力密度约每3.5个月即可实现翻倍。此外,自ChatGPT发布以来,受资本密集投入与高质量数据工程驱动,模型能力密度的增长斜率较此前大幅提升约50%。这意味着,在同等参数规模及算力消耗下,模型性能上限正以前所未有的速度被打破。算法效率的极速提升不仅实质性优化了端侧部署与推理成本,更为下游大规模调用Agent工作流及执行复杂长周期任务提供了充足的底层支撑。
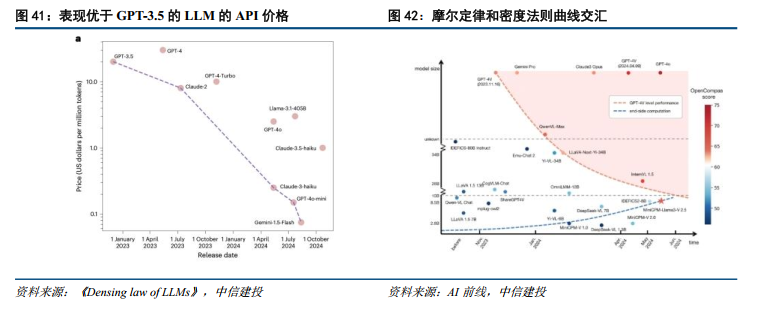
1)模型推理成本将呈断崖式下降趋势,为AI高频调用提供基础。模型能力密度快速上升,达到特定智能所需的实际参数量呈现指数级缩减。反映在商业端,同等性能大模型的API调用价格呈现出比模型能力更陡峭的下降斜率(但智能上界模型则价格或将提升)。实证数据显示,跑赢GPT-3.5性能基准的模型 API 价格约每 2.5个月即可实现折半。例如,Gemini-1.5-Flash每百万Token定价较2022年底已累计暴降逾266倍。
2)密度法则 摩尔定律共振,算力普惠向端侧延伸。密度法则反映了软件算法层面的效率迭代,而摩尔定律(同价位芯片算力约2年翻倍)则框定了硬件的物理进步。两者叠加产生的乘数效应,使得在同等价格消费级端侧芯片上,能流畅运行的模型规模加速提升,约每88天即可实现翻倍,为当前AI PC、AI手机及IoT设备在本地低功耗跑通高阶大模型提供了坚实的底层技术可行性。
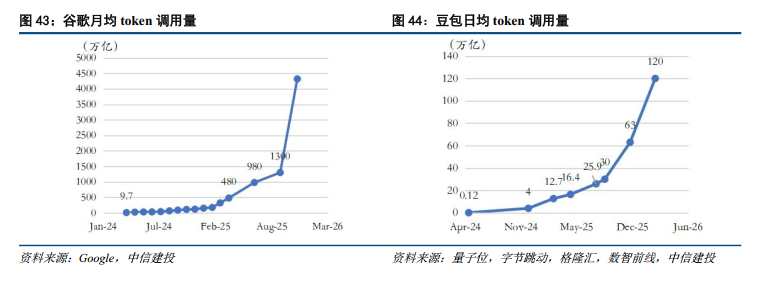
全球大模型应用Token调用量陡峭上行。过去的几年里,AI应用token消耗量加速上行,主要系模型能力的持续提升拓宽了多模态处理与长文本能力边界,同时Agent工作流的普及使得单次指令转化为模型内数十次复杂循环调用。以谷歌为例,2024年4月谷歌月token消耗量仅9.7万亿,一年后的2025年4月即提升50x至480万亿,同年7月和10月更是分别达到980和1300万亿; 2025年12月,谷歌第一方模型在通过客户直接API调用部分,每分钟消耗量已突破100亿Token,折合月度总量高达4320万亿Token。微软此前也披露,Azure AI基础设施在2025年一季度处理了超100万亿Token,较2025年同期暴增5倍,其中仅3月单月的Token调用量即高达50万亿。国内字节豆包的日均token调用量增长同样陡峭,2024年5月首次披露时仅1200亿,2025年12月已达到50万亿,较2025年5月的16.4万亿增长超过200%;2026年3月,豆包大模型日均tokens使用量更是突破120万亿,较2025年12月的63万亿在三个月翻了一倍。整体而言,全行业的Token消耗飙升标志着AI应用正从低频的单次辅助交互向高频复杂工作流发展。

(1)宏观经济下行风险:计算机行业下游涉及千行百业,宏观经济下行压力下,行业IT支出不及预期将直接影响计算机行业需求;
(2)应收账款坏账风险:计算机多数公司业务以项目制签单为主,需要通过验收后能够收到回款,下游客户付款周期拉长可能导致应收账款坏账增加,并可能进一步导致资产减值损失;
(3)行业竞争加剧:计算机行业需求较为确定,但供给端竞争加剧或将导致行业格局发生变化;
(4)国际环境变化影响:目前国际形势动荡,对于海外收入占比较高公司可能形成影响,此外美国不断对中国科技施压,导致供应链安全风险。

 VIP复盘网
VIP复盘网
