

2026年6月1日,国内首个集齐 1M 超长上下文、原生多模态与顶级 Coding/Agent 三大能力的模型——MiniMax M3 正式发布!这不仅是一款性能比肩国际顶尖的“全能选手”,更是目前同级别中唯一的开源模型。
并行科技 MaaS 平台已第一时间完成 M3 接入,以海量算力破除门槛,让顶尖大模型“开箱即用”。告别算力焦虑,一键开启您的普惠智算之旅!⬇️
https://www.paratera.com/mass.html
M3 是 MiniMax 面向 Agentic Engineering 场景打造的新一代模型能力升级,能够更好地完成复杂任务拆解、代码生成、工程协作、文档理解和多模态信息处理。
01
架构革新:MSA稀疏注意力
MiniMax M3采用了全新的 MiniMax Sparse Attention (MSA) 架构。不同于传统的全注意力机制(计算复杂度随长度平方级增长),MSA 通过更精确的 KV 分块,配合算子层优化,实现了极高的计算效率。
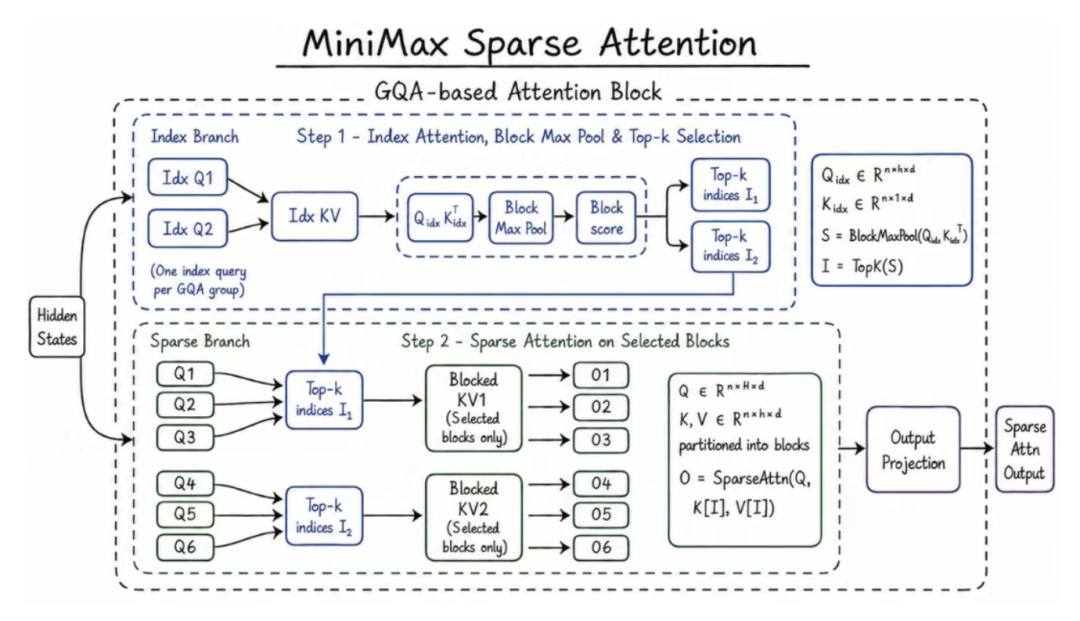
性能收益:
成本降低:在 100 万上下文下,每 token 计算量仅为上代模型的 1/20。
速度飞跃:Prefilling 阶段加速 9 倍,Decoding 阶段加速 15 倍。
硬件友好:比开源的 Flash-Sparse-Attention 快 4 倍以上,真正实现了“长上下文”的普惠。
02
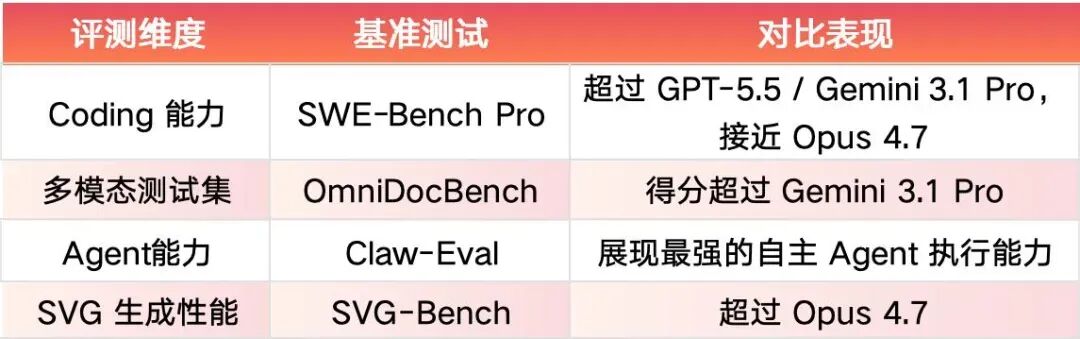
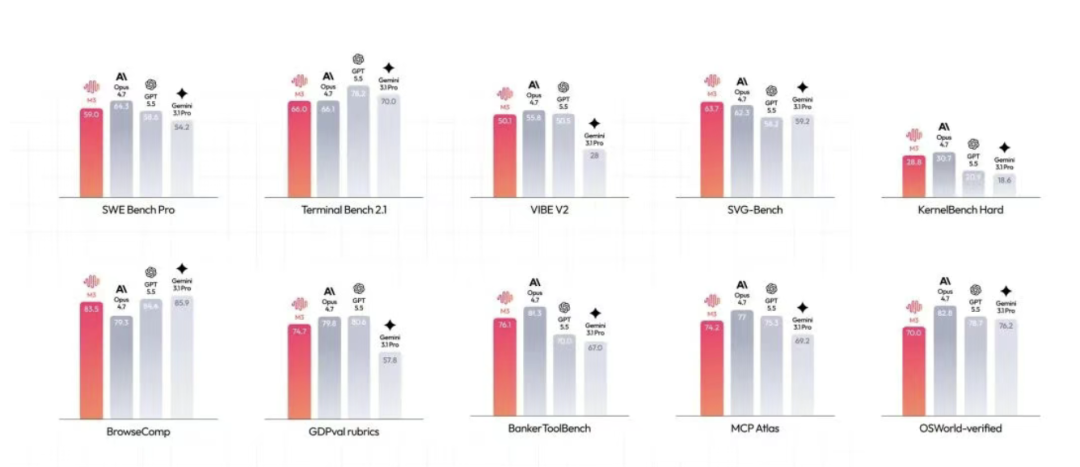
能力越级:比肩国际顶尖模型
在多项国际权威评测中,M3 展现出了比肩甚至超越海外闭源模型的实力:
03
实战表现:从“写代码”到“做科研”
M3 不仅在 Benchmark 上跑分高,更在复杂的真实任务中表现出色:
独立复现顶会论文:M3 成功独立复现了 ICLR 2025 Outstanding Paper Award 获奖论文,自主运行 12 小时,产出 18 次 commit 与 23 张实验图表,并跑通核心实验。

自主优化 CUDA 算子:在没有参考代码的情况下,M3 自主优化了 NVIDIA Hopper 架构的 FP8 GEMM kernel,将硬件峰值利用率从 7.6% 提升至 71.3%(实现相较于原始版本的 9.4× 加速)。
自我迭代训练:在 PostTrainBench 任务中,M3 自主完成了数据合成、训练、评测的全流程,最终得分(0.37)略低于 Opus 4.7(0.42)和 GPT-5.5(0.39),但明显领先其他模型。
MiniMax M3现已上线并行科技MaaS平台,把模型能力从“更强”推进到“更能干活”。并行科技提供灵活的按需调用与本地私有化部署,以海量GPU资源免去前期投入,实现极致性价比;7×24小时专业技术服务团队全程护航,让应用落地无后顾之忧。
立即登录并行科技MaaS平台,一起探索 M3 在 Coding、Agent、办公、多模态和复杂任务场景中的更多可能!

 VIP复盘网
VIP复盘网
