


当你在聊天框输入一句“帮我写一份活动方案”,几秒钟后就能得到排版工整、逻辑清晰的回复,你很少会追问:AI到底是怎么读懂我的问题的?藏在这顺畅交互背后,一个最基础却最容易被忽略的单元就是AI Token。它是大语言模型拆解人类语言的最小积木,是计算AI算力成本的最小单位,如今更被视作AI时代的“新电力”,成为产业和金融领域共同关注的标的。
2026年3月,国家数据局对Token给出了更为正式的定义:Token是大模型处理信息的最小计量单位,是模型输入输出的计量基础;也是大模型厂商销售套餐的计费单位,是可定价、可交易、可结算的数字商品。这一定义将Token从纯技术概念扩展到了经济商品层面,为后续的Token金融化奠定了制度基础。
目前,围绕Token的生产、计价、交易和消费,正在形成一套新型资源配置方式,被学界称为“词元经济”。词元经济并非简单的商业模式创新,而是数字经济向智能经济跃迁过程中的结构性变革。随着“人工智能 ”行动加快推进,数字经济正加速向以大模型为代表的智能经济跃迁,以词元(Token)为核心计量单位的Token新经济正在加速形成。Token作为信息生成单元和算力消耗单元的统一尺度,正在重塑产业的价值生成与分配逻辑。这意味着Token不仅是一种计量工具,更是连接算力、数据和应用这三大AI经济支柱的纽带,是理解未来AI产业价值链的钥匙。
什么是Token?
它不是加密货币,也不止是“单词”
很多人第一次听到Token会联想到区块链的虚拟代币,或是简单把它等同于“单词”,这其实是两个最常见的认知误区。Token,中文官方译名“词元”,是大语言模型(LLM)处理文本、代码、图像等多模态信息的最小独立单位,是人类语言转换为机器可识别数字的中间载体,也是模型计费和处理的基本单位,是可定价、可交易、可结算的数字商品。它并非严格对应一个汉字或英文单词,而是模型根据词表进行的一种“语义切片”。简单来说,人类说的话、写的文字对计算机来说只是一堆杂乱的字符,无法直接计算语义,Token化就是把连续的文本切割成一个个小单元,再把每个单元映射为一个唯一的数字ID,让模型可以通过计算这些数字的关联,理解人类语言的含义,再生成符合逻辑的回复。当你向AI提问时,问题中的每一个词语、标点甚至部分笔画都会被拆解成多个Token;当AI生成答案时,每一个输出的字符同样以Token为单位计量。
Token的切割粒度不是固定的:它可以是一个字、一个字符,也可以是一个单词的一部分,甚至是一整个常用词。在英文中,1个Token约等于4个字符(约0.75个单词);在中文中,由于分词复杂性,1个汉字通常对应1-2个Tokens。比如输入“你好ChatGPT”,中文的“你”“好”会被拆分为两个Token,英文的“ChatGPT”会被拆分为“Chat”“GPT”两个Token,最终一共得到四个Token,每个对应一个独立的数字ID送入模型计算。这个切割转换的过程被称作Tokenization(分词/Token化),是所有大语言模型运行的基础——没有Token化,AI就无法理解人类语言的语义和逻辑关系。
我们可以做一个通俗的类比:如果把生成一段AI回复比作盖一栋房子,人类的提示词/指令(Prompt)就是一堆堆没分拣的建材,Token就是分拣打包好、可以直接递给工人的标准砖,模型就是盖房子的工人,工人一次只能搬运固定数量的砖,这就是我们常说的“Token上下文窗口限制”。
每一次AI交互都是Token的消耗过程,这个过程中的Token可分为三类:
输入Token:用户提问、上下文、历史对话编码生成,消耗较少;
推理 Token:模型内部运算、关联、生成的算力消耗,隐性核心成本;
输出 Token:AI 回答生成,消耗最多、定价最高。
Token的发展历程:
从NLP实验性技术到AI产业的计费单位
Token化的概念并不是AI大模型时代才出现的,它已经在自然语言处理领域发展了近半个世纪:
1. 萌芽期(1950-1990):统计NLP的基础工具
NLP(Natural Language Processing),中文译为自然语言处理,是人工智能的核心分支之一,它研究让计算机理解、解析、生成人类语言(文字、语音)的理论与技术,打通人类自然语言和机器语言的壁垒,也是大模型、Prompt、Token 技术的底层基础。最早的分词技术诞生于机器翻译研究初期,当时研究者为了让计算机处理文本,尝试将连续文本切割为最小语义单元,最初的Token就是单词本身,英文按空格分词,中文按字分词。但受限于语料和计算能力,此时的Token化只是实验室中的基础技术,没有大规模落地。
2. 成长期(1990-2017):统计分词与子词分词的突破
随着统计自然语言处理的发展,研究者发现直接按词/字分词存在很大问题:按词分词会导致词汇表过大,生僻词无法处理;按字分词又会丢失大量语义信息。2000年之后,字节对编码(BPE:Byte Pair Encoding)等子词分词技术逐渐普及,这种方法可以根据语料的出现频率,自动将常见词合并为单个Token,将生僻词拆分为多个子词Token,兼顾了词汇表大小和语义完整性,这也是当前所有主流大模型都在用的分词方法。
3. 爆发期(2018年至今):大模型让Token成为产业计费单位
2018年BERT模型(Bidirectional Encoder Representations from Transformers:是 Google 于 2018 年提出的双向预训练语言模型,只使用 Transformer 的 Encoder(编码器),核心是双向上下文理解与预训练 微调范式,被视为现代 NLP 的里程碑)诞生,2020年OpenAI推出GPT-3,第一次将大模型开放API服务,为了方便计算调用者的算力成本,OpenAI选择按照输入Token数量和输出Token数量计费,Token从此从一个纯技术概念,变成了AI产业的“流通货币”——所有开发者调用大模型API都要按Token付费,用户使用AI服务的成本直接和Token消耗挂钩,Token也正式从技术底层走到了产业前台。
Token市场的发展现状
(一)市场规模及价格的变化
1.Token调用量的爆发式增长
Token市场目前最显著的特征是需求端的指数级爆发。据国家数据局披露,中国日均Token调用量已从2024年初的约1000亿,跃升至2025年底的100万亿,到2026年3月进一步突破140万亿(即1.4 × 10^15个Token),两年间增长超过1000倍,成为增长最快的数字经济赛道。按中文每字符约消耗1.5个Token折算,相当于每日处理约93万亿个汉字的信息量。
需要特别指出的是,2024年初的1000亿调用量更多体现的是早期“问一句、答一句”的文本交互场景,消耗量尚可控制和估算。进入2025年下半年,随着多模态AI、AI编程、智能体(Agent)等应用场景的成熟,Token消耗结构发生了质变。摩根大通预测,中国AI推理Token消耗量将从2025年的约10千万亿增长至2030年的约3900千万亿,五年增幅约370倍。IDC(国际数据中心)预测则更为激进,全球年度Token消耗量将由2025年0.0005 Peta Token(即5 × 10^11 Token)升至2030年15万Peta Token,年复合增长率达3418%。全球活跃智能体数量也将从2026年快速增长至2031年的约3.5亿个,年复合增长率达135.3%。
Token未来核心的增长引擎在AI Agent,即从“人用AI”到“AI用AI”的转变。传统的人类对话单次消耗Token约几百个,但Agent通常是多步骤任务,单次消耗可达几十万个。如果一个企业部署1000个Agent,每个Agent每日消耗100万个Token,那么一家企业一年的Token消耗量就将达到3650亿个,相当于一个中等国家人类对话的总消耗。随着AI的发展,Agent的应用在企业当中越来越普遍,金融投研、制造排产、政务合规、医疗病历结构化等等,很多企业的AI项目都进入了常态化调用。运营商Token套餐的普及,以及手机、车载、家居等轻量化模型和场景的应用,也使得AI融入到了普通人的日常生活当中。
截至2026年,Token已经成为AI行业的通用计量单位:所有主流大模型服务商都采用按Token计费的模式,Token的单位价格、上下文窗口的Token容量,已经成为衡量大模型成本和能力的核心指标之一。Token已经成为AI产业最基础的“大宗商品”:所有AI应用都需要采购Token,它的价格直接决定AI产品的成本,影响整个AI产业的景气度,价格波动也越来越大,产业端对风险管理工具的需求越来越迫切。
2.Token市场规模的跃迁与价格竞争的激烈
2025年,全球已有多家头部大模型公司跨越了商业化临界点。OpenAI的年度经常性收入(ARR)在2025年已达到120亿美元,是全球大模型商业化最成熟的标杆。在国内,尽管公开披露的具体ARR数据有限,但各大云服务商已将Token列为核心付费产品线。Token已成为AI时代核心生产要素与价值载体,围绕Token的商业模式已经成熟,其影响正在延伸到芯片、云服务、应用开发乃至基础设施投资等各个领域。2026年,AI Agent规模化落地推动Token调用量结构性增长,Token应用正从“尝鲜”走向“规模变现”阶段。
Token定价在过去两年也经历了一个完整的“U形周期”。
第一阶段(2024年末至2025年中期):价格战白热化。 某头部平台率先发起价格战,将百万Token价格从行业均价约50元压降至0.3元,引发连锁反应。阿里云、字节跳动、月之暗面相继宣布大幅降价,部分轻量模型的API价格一度跌入每百万词元不足一元的区间,推理算力的毛利率随之跌至负数。这场“流血竞争”在短期内激发了大量中小开发者和初创企业接入AI能力,但行业整体盈利能力受到严峻挑战。
第二阶段(2025年下半年起):价格回归理性。 随着Token调用量持续爆棚,算力成本压力逐渐传导至API定价端。2026年3月,中国云计算市场迎来标志性价格重构,腾讯云、阿里云、百度智能云三大头部厂商在约一周内相继发布调价公告,正式上调AI算力服务及大模型相关产品价格。以腾讯混元HY2.0 Instruct为例,输入单价从0.0008元/千Token上调至0.004505元/千Token,涨幅高达463%。
与此同时,国际市场价格同样呈现分化格局。OpenAI于2026年4月发布的GPT-5.5,标准版API输入定价为5美元/百万Token,输出定价为30美元/百万Token,较GPT-5.4整体贵了一倍;其Pro版本输入价格为30美元/百万Token,输出价格高达180美元/百万Token。这一定价水平约为国内头部模型的数十倍,反映了不同市场定位下的差异化定价策略。
阿里云百炼近期发布的Qwen3.7-Max则提供了较为克制的定价:输入6元/百万Token、输出18元/百万Token。跨平台横向对比来看,同样业务场景、几乎相同的模型效果,选择DeepSeek-V3相比GPT-4o,年度API成本可相差9倍之多。
第三阶段:运营商入局,开启规模化套餐时代。2026年5月17日,中国电信率先推出系列试商用Token套餐,从9.9元1000万Token的“轻享版”,到299.9元1.5亿Token的“旗舰版”,以分级定价满足不同需求。这是运营商首次尝试为AI时代的计量单元Token分级分层定价,被视为运营商从“流量经营”迈向“Token经营”的标志性突破。运营商的入局意义远超一般商业事件。它标志着Token已从互联网公司的技术产品进化为电信运营商的基础业务,进而暗示了Token未来可能获得类似短信、数据流量这样的“公共服务属性”地位。同时,三大运营商掌握着全国性的结算体系和庞大的个人与政企客户网络,其入场将极大加速Token的普惠化进程。
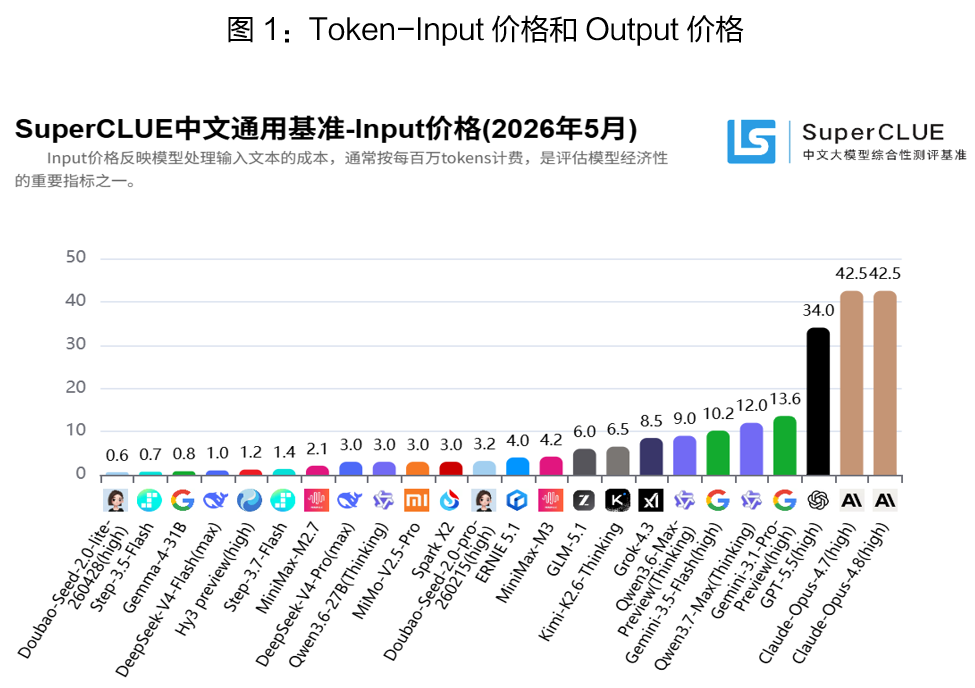
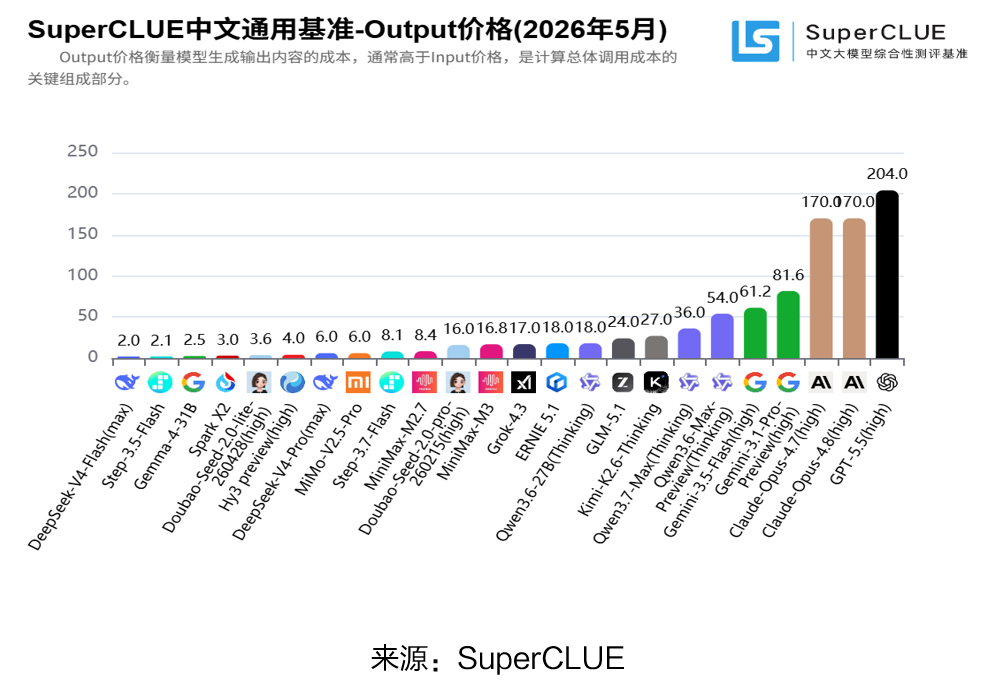
(二)Token的服务商及用户
1. 国际头部服务商
在国际市场,Token服务商呈现出“一超多强”的格局。OpenAI以其庞大的模型矩阵和先发优势占据最大份额,截至2025年ARR已达120亿美元。其产品线从GPT-4.1-nano(0.10-0.40美元/百万Token)到高端推理模型o3/o4-mini(1.10-8美元/百万Token),覆盖了从轻量推理到复杂逻辑的全场景需求。
Anthropic凭借Claude系列模型在编程和企业级应用领域建立起差异化竞争优势,2026年一季度ARR首次超过OpenAI,API定价策略调整83%后调用量仍增长约400%,呈现出显著的“量价齐升”趋势。Google Gemini与xAI Grok则分别依托各自的生态优势参与竞争。
据2026年5月统计,全球已有11家以上具备生产级能力的大模型供应商,每百万输出Token的价格区间从最低0.08美元到最高25美元不等,差价高达300倍。这一巨大价差本身就是一个市场信号——Token远未形成统一的商品定价,而更像是一个高度分化的差异化服务市场。
2. 国内的头部服务商
当前国内Token市场呈现出鲜明的“分层式寡头垄断”特征。在高端前沿模型领域,市场集中度极高;而在中低端及开源市场,则呈现出激烈的垄断竞争态势。目前Token服务市场呈现“云厂商 模型厂商”双轨并行的格局,主力军主要分为三大阵营:
首先是互联网科技巨头。以阿里的通义千问、百度的文心一言、腾讯的混元以及字节的豆包为代表,它们掌握着顶尖的模型能力与庞大的云基础设施,实际上掌握了Token经济的定价中枢。
其次是电信运营商。2026年5月,中国电信、中国移动、中国联通陆续官宣售卖“Token套餐”,将Token与话费、宽带融合打包。这种举措极大地降低了C端用户的使用门槛,让Token像手机流量一样触手可及。
最后是专业的算力与云服务商。包括各类第三方聚合平台(OpenRouter, 百度千帆等)和垂直领域的模型厂商(DeepSeek, 月之暗面(Kimi), 智谱AI等),它们主打的就是高性价比,为开发者和中小企业提供了差异化的替代方案。
随着市场的发展,Token的分销模式在快速兴起,第三方聚合平台、分销商成为Token市场的一个重要群体。分销商等批量采购AI厂商API额度并加价转售给终端用户,形成“上游模型供应商→中游代理平台→下游终端用户”的三方生态格局。这标志着Token市场正在从简单的API直销模式升级为多层级的渠道分销体系,为Token现货市场的成熟提供了更具流动性的交易基础。
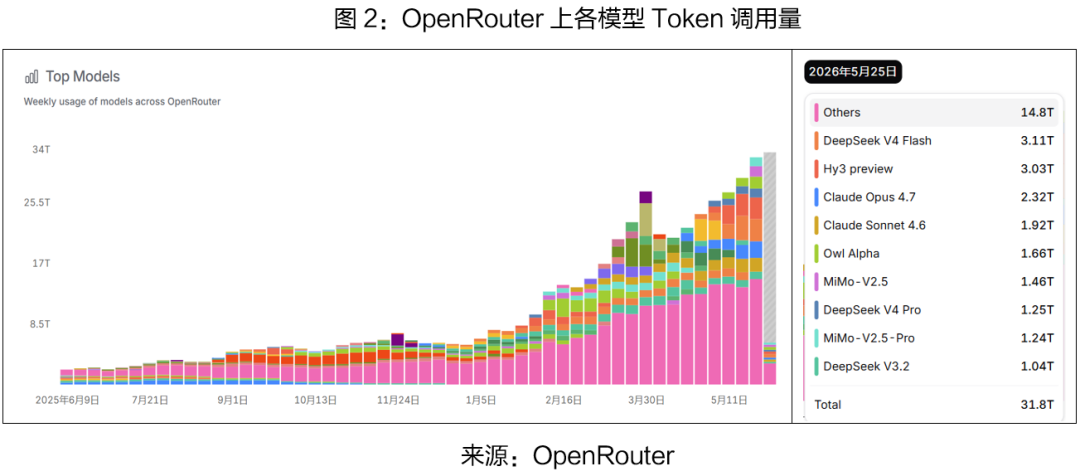
3. Token的核心应用群体
Token的应用群体已经覆盖了几乎所有AI相关的开发者和企业,包括:
AI应用开发商、算力中介与集成商等:SaaS应用、AI聊天机器人、AI内容生成平台、Agent等,几乎所有to C的AI产品都是批量采购大模型Token服务,再进行二次封装后卖给终端用户,Token是其最核心的成本项。
大模型微调与训练企业:在预训练模型基础上做行业微调,需要消耗大量输入Token处理训练数据,Token消耗量直接决定微调成本。另外要将AI用于代码生成、客服、内容创作的企业,也需大规模采购Token包以控制预算。
科研机构与高校:开展大模型相关的算法研究、实验测试,按需采购Token额度,比自建大模型成本低很多。
终端个人用户:很多产品对免费用户限制Token消耗量,付费会员可以解锁更高的Token额度,个人用户也已经成为Token消费的主要群体之一。
Token的定价逻辑与核心影响因素
当前Token的定价并非单一费率,而是呈现出多层次结构,有几种不同的定价模式:
按量付费模式(Pay-as-you-go) 。这是最常见的定价模式,用户根据实际输入和输出的Token数量付费。计算方式为:总费用 = 输入Token数 × 输入单价 输出Token数 × 输出单价。由于输出Token的算力消耗远高于输入Token的编码过程,输出价格通常是输入价格的2到6倍。
分级套餐模式。 运营商和部分云服务商推出分级套餐。中国电信的Token套餐从9.9元/1000万Token到299.9元/1.5亿Token,豆包则从68元/月到500元/月不等。分级套餐的主要优势在于降低个人和中小企业的接入门槛,同时也为云服务商提供了稳定的月度经常性收入(MRR)。
订阅制模式。 这类模式按时间周期(通常为月或年)收费,提供固定额度或无限的Token调用。OpenAI的ChatGPT Plus和豆包三档订阅均属此类。订阅制降低了用户的心理账户门槛,尤其适合个人用户和长期高频使用者。
混合模式。 许多服务商同时提供上述多种计费方式,让用户根据实际需求选择最经济的方案。例如,企业客户可将大规模稳定训练任务的API调用安排到专用实例上,以获取更优惠的“包年包月”折扣;而突发性推理调用则选用按量付费模式,实现成本弹性的双重优化。
Token的定价模式多样,而且不同厂商价格差异也很大,其核心影响因素有三个:
(1)算力的成本
GPU价格直接决定Token成本,这是Token定价最底层的制约因素:H100/A800 等高端卡租金占比超 60%,当GPU稀缺且价格高企时,大模型的增量训练和推理成本同步上升,必然推动Token价格上行。
(2)大模型本身的训练与推理成本
模型能力决定Token的价值溢价,模型越大,参数越多,上下文窗口越长,训练阶段投入的成本越高,推理单Token消耗的算力越多,定价也就越高。像一些旗舰模型,推理能力强,定价就比较高,而一些轻量模型,推理能力弱,定价也就偏低,比如GPT-4o的输入价格是每百万Token5美元,输出15美元,而GPT-3.5-turbo输入价格仅为每百万Token0.5美元,输出1.5美元,价差接近10倍,本质就是模型推理成本的差异。
(3)市场供需关系与竞争格局变化
AI行业爆发式增长时,GPU算力供不应求,大模型厂商的推理成本上涨,Token价格也会随之上涨;当算力产能释放后,Token价格也会逐步下行,2024年以来全球GPU产能逐步释放,主流大模型的Token价格已经下降了30%左右。另外模型效率的提升、稀疏化、蒸馏技术普及,使得同等算力能产出更多 Token,会长期推动Token价格下行。另外,新入场的厂商为了争夺市场份额,通常会定比头部厂商更低的价格,吸引开发者迁移。比如国内很多二线大模型,Token定价仅为头部厂商的1/2到1/3,核心就是通过低价抢占市场,也会导致市场价格的变化。
Token期货化的标的选择
随着AI Token需求的规模化,价格波动越来越大,产业端已经出现了对冲Token价格波动的需求。Token已经具备了可计量、可交易、价格波动等几大适合期货交易的特性。结合“词元经济”的诞生,我们认为Token也具备了一些推出期货交易的基础。有消息称上期所正在研究Token期货,我们非常期待。
算力租赁和Token是算力期货化的两种不同路径。以算力租赁价格指数为标的进行期货交易,其本质是以算力供给成本作为定价核心,这一设计更偏算力供给侧,核心在于硬件层面。Token则是锚定算力的需求端,更偏向于服务下游AI应用开发商、SaaS服务商、终端开发者的需求。两条路径都是中美在算力金融化领域博弈的关键。如果条件具备,我们认为不管是算力供应端还是需求端,都有推出期货交易的必要,不过从目前国内的政策导向及资源禀赋来看,开发算力租赁价格指数相比于Token价格指数会相对容易一些。
首先从政策端来看,工信部推进“1 M N”算力互联互通体系,要求“统一标识、统一标准、统一规则”,不仅是算力标准化的保障,也为价格标准化提供了政策背书。其次,算力租赁以长约加少量现货为主,交易主体为数据中心、云厂商、AI 企业,市场集中度相对较高,成交价格、规格、时长、用量可留痕、可追溯,且计价维度相对比较清晰,主流计价单位为元 / 卡时(GPU 小时)、元 / 核时、元 / TOPS,虽未完全统一,但属于 “同一物理量的不同口径”,可通过折算系数标准化。第三,算力租赁的成本结构相对透明,包括硬件折旧、电力、带宽、运维、机房折旧等,定价的锚点比较清晰,且价格波动驱动相对易把控。
但其核心难点也有几个方面。一是标准化不足,需要设定算力折算基准,将所有算力都折算为标准算力单位;二是公开报价跟实际成交价之间可能差距较大,要有识别清洗机制;三是区域间报价差距较大;四是高端算力集中在少数企业,容易形成垄断,需要建立防操控机制。
相比之下,Token价格指数的编制可能会更难一点。从计量单位的角度看,相对容易统一,基本都为“元/百万Token”,难点在于Token的质量差异难以统一,从当前产业结构来看,不同模型 Token 质量差异很大(能力、速度、稳定性)。在算力市场中,同一型号的H100芯片在物理性能上是可比的,尽管在不同部署环境中存在性能方差,但这种方差可通过归一化框架进行系统性修正。然而,不同大模型之间的Token质量差异是质的差异,而非量的差异,标准化框架几乎无法用统一的修正因子进行校准——因为“更聪明10%”本身就是一个主观性极强的概念。而且模型性能和API定价之间也没有简单的线性关系,价格不能直接映射质量。不同模型擅长不同类型任务,如在代码生成任务中,Claude的表现可能优于GPT-5.5,但在创意写作中可能相反。所以Token指数会面临“同价不同质”的困扰。一个模型的高价可能反映了其卓越能力,也可能反映了其定价策略失误。一个模型的低价可能是性价比优势,也可能是模型能力较弱。因此对于不同模型的Token难以有效区分其“质量价格”差异。
另外,大模型技术迭代速度非常快,每隔6-12个月就会有性能更强的新模型推出,新模型单位Token的价值比旧模型更高,这也可能使得指数的基准需要不断调整,很难保持长期稳定性,而作为期货标的的指数,稳定性是核心要求,这就形成了一定的矛盾。
当然,这并不意味着Token不能作为期货标的,我们需要将其标准化后再作为标的使用。可以做一个算力锚定的Token指数。 锚定某主流模型的核心指标,将达到指定性能基准的模型产出的1个推理Token定义为1个标准Token,然后把不同模型、不同厂商的Token按照模型性能折算为统一的“标准等效Token”,在此基础上,可编制“标准推理Token指数”(Standard Inference Token Index, SITI)。虽然这种方案也并没有从根本上解决异质性的问题,但总体而言其更具底层定价逻辑的稳定性,不易受具体模型定价策略变动的影响,适合成为长期金融产品的锚定基准。
结语:Token, AI时代的新大宗商品
Token已经从AI模型处理信息的最小计量单位,演进为可定价、可交易、可结算的数字商品,并正在成为AI经济的核心价值载体。两年间增长超千倍的爆发式增长背后,一个涵盖上游算力、中游模型、下游应用的完整Token经济生态正在加速形成。
Token期货的探索则代表着Token从数字商品到金融资产的关键一跃。然而,Token价格指数的编制面临底层资产的异质性、定价模式的多层性、模型迭代差异等多重挑战,这些挑战远大于GPU算力指数所面临的标准化难度。
在金融化进程中,Token期货是一条与美国算力期货不同的道路,二者展现了不同的战略视角,一边是锚定需求端,另一边则是锚定供给端。Token经济的未来,既取决于技术的进步,也取决于制度的设计。当算力成为继“石油美元”之后的下一个金融锚点时,不管是算力租赁还是Token,都将成为大国数字经济竞争的核心领域。

 VIP复盘网
VIP复盘网
