

【新智元导读】除了英特尔和AMD,现在我们终于可以选择国产笔记本电脑显卡了!这款显卡的背后,饱含着中国工程师们日夜攻坚的汗水与泪水。
等等,是不是起猛了?
我们好像真的见证了历史:市面上第一台真正基于国产GPU的AI笔记本,诞生了!
它叫MTT AIBOOK。
除了搭载首款国产全功能显卡,它最大的必杀技在于——这是一台彻头彻尾为AI而生的便携式AI PC。
搞过AI开发的都知道,环境配置是「劝退第一关」。
MTT AIBOOK主打一个开箱即用:Python、VS Code、Jupyter、PyTorch全家桶全部预装到位。
这种「保姆级」服务,彻底终结了「环境没配好,头发先掉光」的玄学。
不管是技术小白还是专业大牛,都能将精力全花在创意与算法上,而不是浪费在解决command not found这种琐事上。
更硬核的是,它还打破了系统壁垒——Linux、Windows、安卓三大生态全部奉上:
原生Linux:基于Linux底层的MT AIOS,为AI开发提供最纯粹、高效的环境。
GPU虚拟化(Windows云桌面):利用GPU虚拟化技术,无需重启即可流畅运行Windows系统。码代码、写PPT,顺便打开Steam开一局,无缝切换。
安卓容器:通过安卓容器,甚至连移动端生态也一并「吞」下。挂个手游、刷个短视频,电脑上全搞定。
AI 游戏 办公,这一台就够了!
它的背后,正是摩尔线程全栈自研的MUSA统一系统架构。

算力之争,软硬同等重要。
英伟达之所以难以撼动,核心在于其深耕二十年的CUDA生态。
对此,摩尔线程给出的答案就是——MUSA:
全名Meta-computing Unified System Architecture,元计算统一系统架构。

这绝非对CUDA的简单模仿,而是从指令集、编程模型到运行库的全栈自研。
MUSA不仅仅是芯片,而是一个从底层硬件到上层生态的完整系统,主要包含三个层级:
最底层: 摩尔线程全功能GPU(Universal GPU),内置四大引擎,能够处理各种行业、不同精度和类型的数据。
中间层: 夸娥智算集群。基于全功能GPU搭建的硬件系统,支持从单机到万卡、甚至十万卡超大规模集群。
最上层: MUSA全套软件栈。包含加速库、调试工具、应用案例以及AI训练和推理的整体系统框架。
MUSA 5.0软件栈在本次大会上全面升级,它涵盖了AI计算、图形渲染、物理仿真、超高清视频编解码等全场景的开发工具。

在AI框架层面,MUSA深度适配了PyTorch、PaddlePaddle,并新增了对Jax、TensorFlow以及TileLang的支持。

MUSA 5.0在性能层面实现了极致优化。
在计算方面,芯片设计的集成效率极大提升,HGEMM(半精度通用矩阵乘法)算子效率达到98%;
在通讯方面,效率发挥至97%。这些提升让开发者能更充分地利用MUSA GPU的算力。


对后来者而言,横亘在面前的不仅是算力高墙,更是英伟达构筑二十载的软件护城河。
全球数百万开发者早已习惯了CUDA的语言体系,海量的存量代码不仅是技术资产,更是牢不可破的生态闭环。
为了在这块铁板上撕开缺口,摩尔线程祭出了关键的战略棋子——MUSIFY。
在业界,它被形象地称为「跨界翻译官」。
其核心逻辑简单而直接:通过自动化移植工具,将原本绑定在国际主流平台上的C 源代码,转化为MUSA架构的C 源代码,让开发者以最小成本将国际主流GPU平台应用移植至MUSA GPU,最终运行在全功能GPU上。
这是一场效率与成本的赛跑。
MUSIFY的出现,试图让开发者以近乎「零成本」的代价实现应用迁移。
它不仅将开发者从枯燥的底层代码重写中解放出来,更在国产GPU生态的荒原上,迅速平整出一条通往商业落地的快车道。
MUSIFY能实现代码「一键搬家」,根源在于MUSA架构在设计之初就选择了与CUDA底层逻辑兼容。
它不仅是个翻译工具,更是MUSA架构兼容能力的具体体现。
这种「原生适配」让开发者几乎不用重写代码,就能顺滑地换上国产GPU,把迁移门槛降到了最低。
靠着这种极低的切换成本,摩尔线程精准接住了英伟达溢出的生态红利,成了打破封锁、抢占市场的利刃。
为了满足更广泛和前沿的开发需求,MUSA 5.0推出了面向AI和渲染融合的全功能编程语言——muLang。
它让开发者通过一套指令集即可完成3D图形和AI计算场景的编程。
此外,面向未来的量子计算领域,摩尔线程推出了MUSA-Q框架,让经典计算框架与量子框架结合,更好赋能量子计算应用。
同时,为了满足高端开发者对精细化控制的需求,摩尔线程还将在明年开放MTX,允许开发者利用汇编语言精准操控GPU资源。
MUSA的理念是统一性、开放性与完整性。
中国工程院院士郑纬民在演讲中指出:「真正决定主权AI成败的,在于是否有足够多的开发者愿意长期在这套栈上写代码。」
摩尔线程显然深谙此道。
大会上,摩尔线程宣布了一项庞大的开源计划:逐步开源计算加速库(MATE、MUTLASS)、通信库(MT DeepEP)以及系统管理框架。
这意味着,摩尔线程正在将底层的核心能力开放给社区,邀请全球开发者共同打磨MUSA生态。
如果说芯片是算力的心脏,那么架构就是芯片的灵魂。
英伟达之所以强大,在于其Hopper、Blackwell等架构的持续演进。
摩尔线程深知,要想在牌桌上拥有话语权,必须拥有自主可控且具备持续迭代能力的底层架构。
摩尔线程保持着一年一代架构的迭代速度:
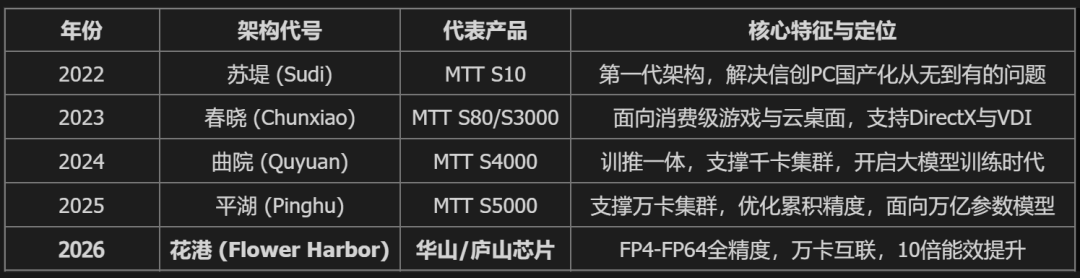
摩尔线程架构演进历程
如今,摩尔线程正式揭晓了其第五代全功能GPU架构——「花港」。
这是一次从指令集到计算单元的深度重构。
根据官方披露的数据,基于新一代指令集架构及MUSA处理器架构,「花港」在算力密度上实现了50%的提升,而计算能效更是实现了惊人的10倍跃升。

在半导体工艺制程逼近物理极限的当下,单纯依赖工艺红利已难以为继,架构的优化成为了提升性能的关键。
摩尔线程的技术团队通过对计算单元的精细化设计,在单位面积内塞进了更多的算力,这直接回应了数据中心对于高密度算力的渴求。
· 精度革命:从FP64到FP4的全栈支持
在AI大模型时代,计算精度的选择至关重要。
英伟达在Blackwell架构中引入了FP4精度,而摩尔线程的「花港」架构同样敏锐地捕捉到了这一趋势。
「花港」实现了从FP4到FP64的全精度端到端计算支持。
特别是在低精度计算方面,新增了MTFP6、MTFP4以及混合低精度加速技术。
这已深入到了微架构层面。
在「华山」芯片的研发中,摩尔线程针对Attention算子中的SIMT(单指令多线程)部分进行了革新性升级,原生支持矩阵Rowmax计算,大幅提升了混合精度下的吞吐量。
更值得一提的是TCE-PAIR技术,在Tensor Core(张量核心)的设计中,创造性地让两个TCE(张量计算引擎)共享数据,减少了数据的重复调用,极大地提升了内部引擎的效率。
· 异步编程:榨干每一滴算力
在高性能计算中,最大的浪费往往来自于「等待」。
「花港」架构引入了新一代异步编程模型。
通过全面优化任务与资源调度机制,新的模型支持高效线程同步、线程束特化以及常驻核函数。
简单来说,这就像是一个经验丰富的交通指挥官,能够实时感知每一个计算单元的状态,将任务无缝地填入每一个空闲的间隙。
与那些只做GPGPU(通用计算GPU)的厂商不同,摩尔线程始终坚持「全功能」路线。
在张建中看来,未来的数字世界是物理与虚拟的深度融合。
因此,「花港」架构在图形渲染方面也进行了大刀阔斧的革新。
它集成了一种全新的AI生成式渲染架构(AGR),这是摩尔线程首创的技术,利用AI技术来加速图形渲染流水线。
同时,新二代的硬件光线追踪加速引擎被引入,使其能够完美支持DirectX 12 Ultimate标准。
这意味着,基于「花港」架构的GPU,不仅能跑大模型,还能流畅运行《黑神话:悟空》这样的3A大作。
· 华山:为「AI工厂」而生
AI旗舰GPU「华山」芯片,性能已介乎英伟达Hopper架构GPU(以H200为代表)和Blackwell架构GPU(以B200为代表)之间!
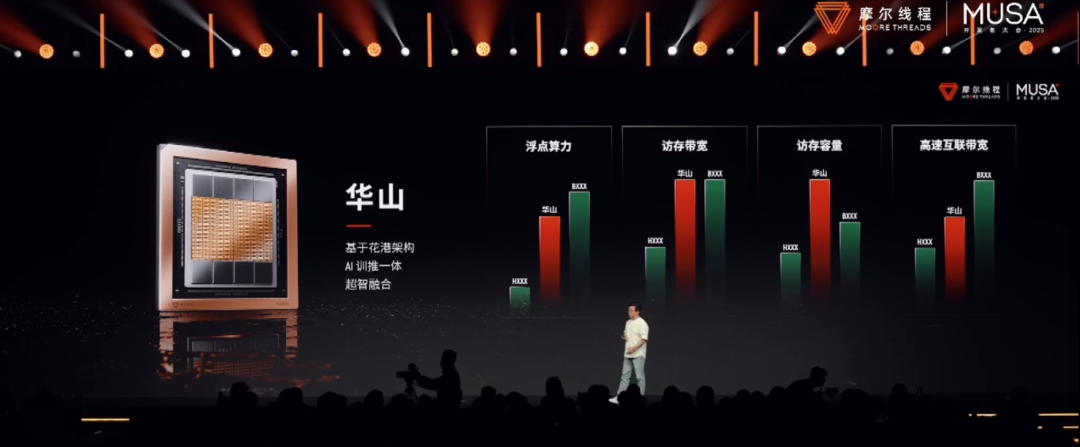
「华山」芯片专注于AI训推一体及高性能计算。
如果说「花港」是蓝图,那么「华山」就是摩尔线程为建设「AI工厂」打造的基石。
它的核心使命是解决大模型训练中的算力与通信瓶颈。
在算力层面,「华山」集成了新一代Tensor Core,支持FP4至FP64的全精度计算,特别是在低精度训练推理场景下,利用MTFP8和MTFP4的优势,加速Transformer模型中的Attention计算。
在通信层面,「华山」集成了ACE 2.0(异步通信引擎)。
这是一个摩尔线程的独创技术,旨在让通信与计算完全并行处理。
在ACE 2.0中,每一个计算单元内部都设计了一个小型的ACE,使得通信的颗粒度更细,效率更高。
此外,配合新一代Scale-up系统,单个超节点可以支持高达1024个GPU的直接互联,这为构建万卡甚至十万卡集群提供了强大的物理基础。
· 庐山:重塑国产图形巅峰
「庐山」芯片则主攻高性能图形渲染。

它的出现,是对「国产GPU性能羸弱」这一刻板印象的有力回击。
根据官方数据,「庐山」的图形性能实现了全面跨越:AI计算性能较前代S80提升64倍,几何处理性能提升16倍,光线追踪性能提升50倍,运行3A游戏的性能提升了15倍。
而S80的3A游戏性能已不容小觑:
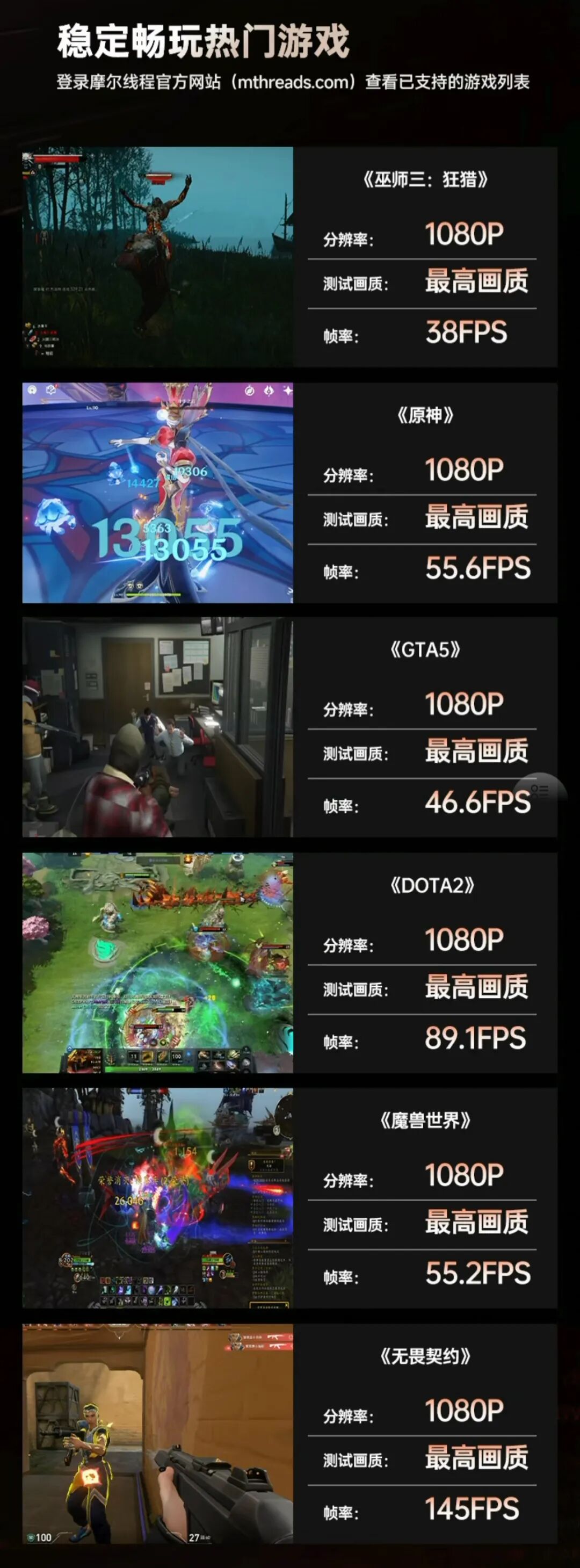
上下滑动查看
「庐山」不仅是一张显卡,更是一个生产力工具。
它集成了AI生成式渲染、UniTE统一渲染架构及全新硬件光追引擎。
在工业软件国产化的大潮中,CAD、CAE等专业软件对GPU的几何处理能力和稳定性有着极高要求。
「庐山」的出现,填补了国产高性能专业显卡的空白,为建筑设计、影视后期、工业仿真等领域提供了自主可控的选择。
单卡性能的提升固然重要,但在大模型时代,真正的决胜点在于集群。
如何让成千上万张显卡像一个大脑一样协同工作,是摆在所有GPU厂商面前的一道天堑。
摩尔线程给出的答案是——「夸娥」(KUAE)万卡智算集群。

「夸娥」取自中国神话「愚公移山」中背负太行、王屋二山的大力神,寓意着摩尔线程要背负起中国算力的重任。
这是一个全栈式的智算解决方案,单集群可部署超过1000个计算节点,每节点集成8颗自研OAM模组化GPU。
发布会上披露的数据显示,「夸娥」集群在工程化能力上已经达到了国际主流水平:
浮点运算能力:达到10 Exa-Flops。
训练效率:在Dense大模型上,训练算力利用率(MFU)达到60%;在MoE(混合专家)模型上达到40%。
扩展性:训练线性扩展效率达95%。

这些数字的背后,是摩尔线程对网络拓扑、存储系统、散热供电以及调度软件的极致优化。
在万卡规模下,任何一个微小的延迟或故障都会被无限放大。
摩尔线程通过3D全互联拓扑,实现了亚微秒级的通信延迟,确保了数据在数万个计算核心之间的高速流转。
· 零中断容错:给训练装上「保险丝」
在大模型训练中,最令人崩溃的莫过于训练中断。
为了解决这一痛点,摩尔线程推出了「夸娥万卡训练容错系统」。
这套系统的目标是将ETTR(有效训练时间比率)提升至99%。
它支持训练异常的在线诊断,能够实时捕捉无响应、慢节点等问题。
更具创新性的是其「零中断」能力:当发生故障时,系统通过DP(数据并行)组级故障隔离机制,仅隔离受影响节点所在的组,其余组别继续训练。备机接入后,仅需重建对应链路,全程无需整体训练中断。
这就像是在高速行驶的列车上更换轮胎,保证了列车始终全速前进。
算力的价值在于应用。
在MDC 2025的展区里,我们看到了全功能GPU在各个行业的真实落地。这不再是PPT上的愿景,而是正在发生的产业变革。
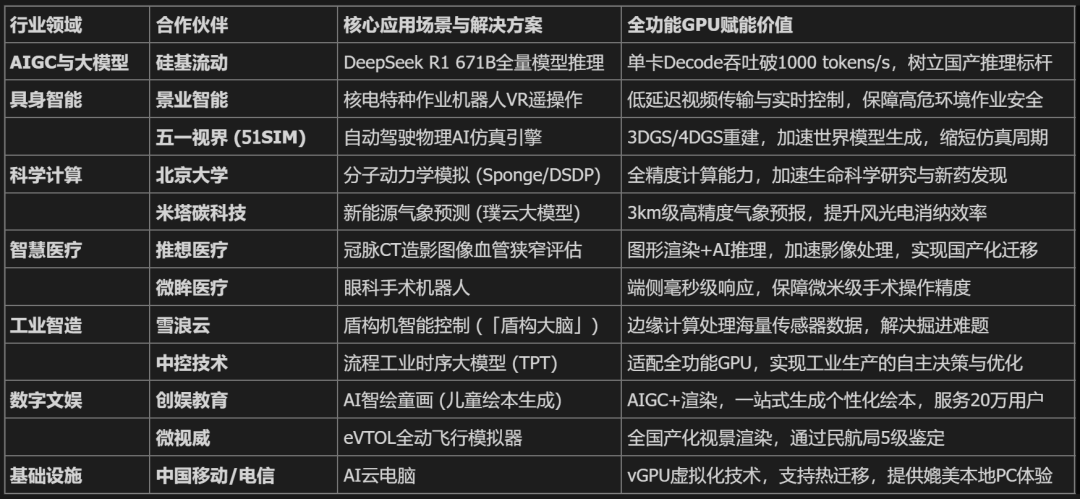
摩尔线程全功能GPU行业应用案例全景
· DeepSeek实战:国产算力的试金石
任何技术指标都不如实战数据来得有说服力。
摩尔线程联合硅基流动,在当前最火热的开源大模型DeepSeek上进行了验证。
在训练侧,摩尔线程完整复现了DeepSeek V3的FP8训练流程。自研的FP8 GEMM算力利用率高达90%,并突破了FP8累加精度不足的业界难题。
在推理侧,基于摩尔线程MTT S5000智算卡,运行DeepSeek R1 671B全量模型,实现了单卡Prefill吞吐突破4000 tokens/s,Decode吞吐突破1000 tokens/s。

这一成绩树立了国产GPU推理性能的新标杆,证明了国产芯片完全有能力承载最前沿、最复杂的AI模型。
· 具身智能:从云端到指尖
在具身智能领域,摩尔线程展示了「云-边-端」的全栈布局。
在端侧,发布的「长江」智能SoC芯片集成了CPU、GPU、NPU等多种核心,提供50 TOPS的异构算力。

搭载「长江」芯片的MTT E300模组,被植入到机器狗、物流无人机中,使其具备了边缘侧的智能感知与决策能力。
摩尔线程还推出了MT Lambda具身智能仿真训练平台,整合了物理引擎(AlphaCore)、渲染引擎和AI引擎。

这使得机器人可以在虚拟世界中进行大规模的强化学习训练,极大地缩短了Sim-to-Real(从仿真到现实)的差距。
从「苏堤」的杨柳依依,到「花港」的鱼翔浅底,摩尔线程用一个个充满中国式浪漫的名字,书写了一段硬核的科技突围史。
这注定是一条孤独而艰难的道路。
在英伟达万亿市值的阴影下,摩尔线程像是一个无畏的攀登者,在悬崖峭壁间开辟出一条属于中国自己的路。
他们面对的,不仅仅是技术上的难题,更是生态的荒漠、市场的质疑以及地缘政治的寒风。
但他们坚持下来了。
因为他们深知,在智能时代,算力就是国力,芯片就是疆土。
MDC 2025不仅展示了技术,更展示了一种决心,一种不甘受制于人、敢于在核心领域亮剑的决心。
摩尔线程的万卡集群,就像是在比特的洪流中筑起的一座大坝,它不仅蓄积了中国AI产业发展的势能,更将源源不断地输出智能的电力,点亮千行百业的未来。
在这场关乎国运的科技长征中,没有捷径可走。
摩尔线程的每一步,都是在为中国科技的自立自强夯实地基。
正如张建中在演讲最后所说的那样,他们的愿景是「为美好世界加速」。
正在加速的,不仅是计算的速度,更是中国迈向科技强国的步伐。

 VIP复盘网
VIP复盘网
