

6 月 2 日,COMPUTEX 2026 开展首日,美格智能宣布正式发布自研 MEIGINE AI 神经网络推理引擎(MEIG Intelligent Neural Engine)。该引擎专为端侧大模型部署而生,通过全格式兼容、异构计算调度与跨平台适配三大核心能力,让广大客户无需等待漫长的平台适配,大幅降低资源和模型限制,为智能终端提供“全、通、快、稳、广”的推理加速体验,助力端侧AI从“能跑”迈向“快跑”。
最强生态:全面兼容 GGUF,无缝接入顶级生态
MEIGINE 最为显著的优势在于全面兼容 GGUF 模型格式,并接入顶级开源生态,模型开源后 MEIGINE 第一时间即可在端侧稳定运行。区别于简单的“格式兼容”,导入的模型会经过端侧专项调优,实现“拿来就用,用就快”的零门槛部署体验。目前, MEIGINE 已稳定支持 Qwen、Llama 全系列模型,覆盖 0.6B 到 7B 参数规模,让开发者无需为端侧适配耗费额外精力。

一跑全通:一套模型文件,多平台通用
面对端侧芯片平台多元化的行业现实,MEIGINE 提出“一次部署,全平台通用”的解决方案。同一套 GGUF 模型文件,无需重复适配即可在高通、紫光展锐等不同芯片平台上稳定运行,告别“一平台一模型”的碎片化困境。这一能力大幅降低了开发者的适配成本,让端侧 AI 应用真正实现跨平台快速迁移与规模化复制。
高效部署:更快解码速度与更强内存优化
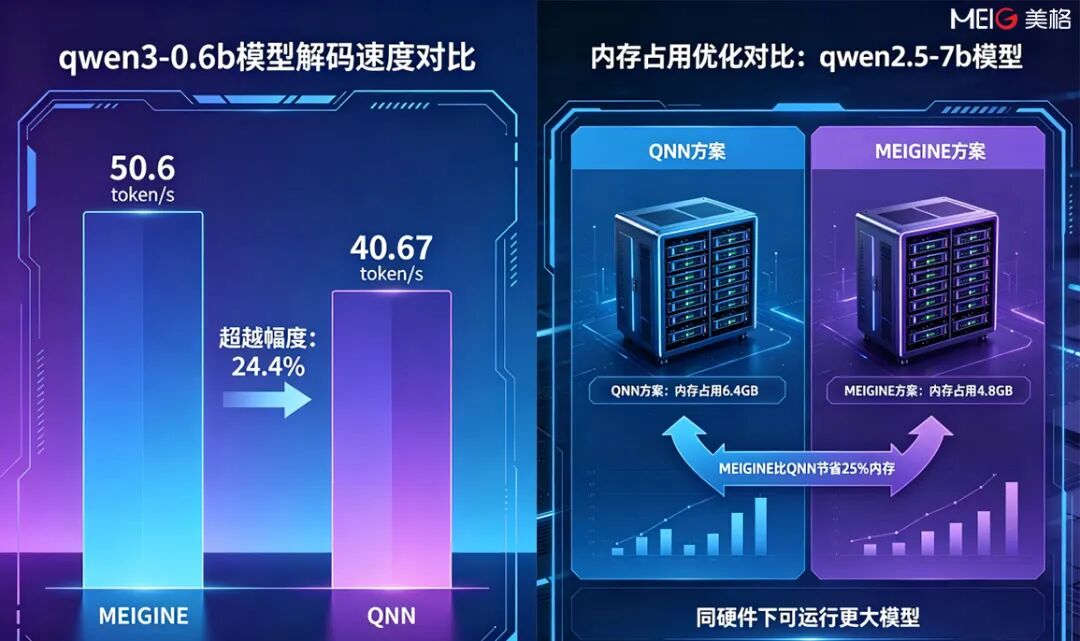
在模型解码速度方面,美格智能基于 SNM970(Q-8550 平台)进行了 MEIGINE 方案与 QNN 方案的部署对比。以 Qwen3-0.6B 为例,MEIGINE 解码速度高达 50.6 token/s,超越 QNN 的 40.67 token/s,让小模型在端侧实现无压力实时交互。在内存占用方面,以 Qwen2.5-7B 为例,MEIGINE 仅需 4.8GB 内存,较 QNN 的 6.4GB 节省 25%,同样的硬件可部署更大参数模型,显著降低端侧AI落地门槛。
异构协同:CPU/GPU/NPU 智能调度,解放 CPU 算力瓶颈
针对端侧推理中 CPU 负载过高的行业痛点, MEIGINE 自研异构调度引擎,将计算负载智能分配至 CPU、GPU、NPU 协同处理,打破传统方案对 CPU 的过度依赖,通过精细化算力调度与底层优化,实现整机功耗的大幅降低。
同样基于 SNM970(Q-8550 平台),以 Qwen2.5-3B 模型为例,MEIGINE 的 CPU 占用为 9%,相较 QNN 的 38% 降幅高达 76%;在 Qwen2.5-7B 模型下,MEIGINE 的 CPU 占用仅为 8%,较 QNN 的 20% 降低 60%。更低的 CPU 占用意味着设备不烫不卡,整机流畅运行,为长时间 AI 交互提供坚实的能效保障。

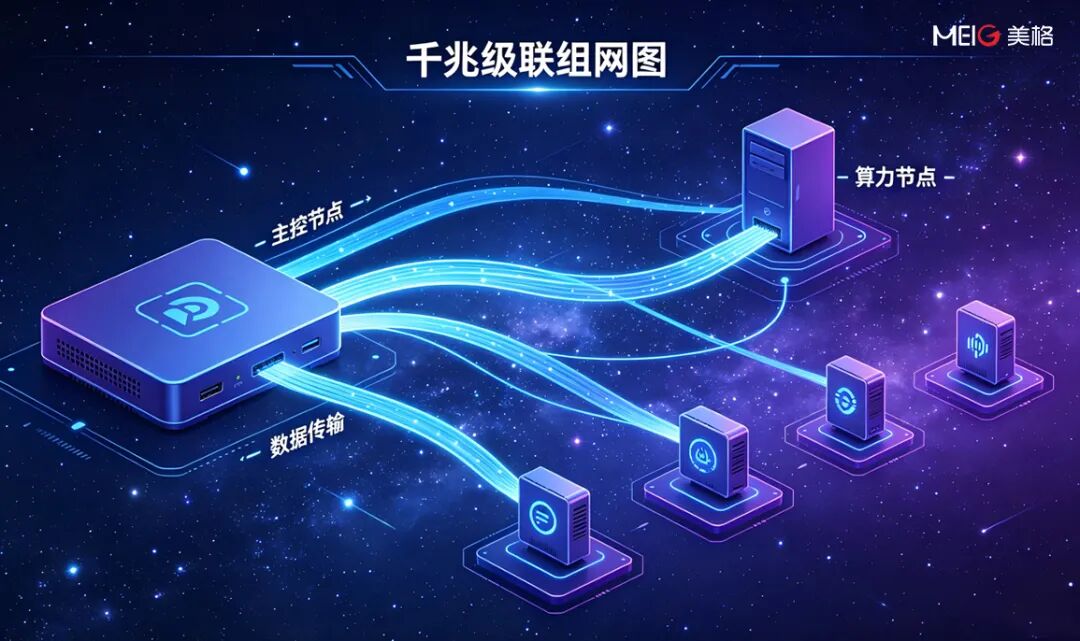
无限扩展:千兆级集群互联,算力叠加突破单设备边界
面向更大参数模型与更复杂推理场景的未来需求,美格智能已跑通验证通过千兆级网线设备构建推理集群的技术方案。该方案可实现规模化算力叠加,通过网线连接设备即可突破单设备算力上限,为 7B 以上更大模型的端侧部署预留充足的扩展空间。
美格智能研究院院长李书杰表示:
“MEIGINE 的发布,是美格智能从‘连接’向‘算力 算法 连接’全栈能力跃迁的重要里程碑。端侧 AI 的下半场,不仅需要高算力硬件,更需要高效的推理引擎释放硬件潜能。”
未来,美格智能将持续深耕端侧 AI 与 Agent 核心技术,以 MEIGINE 为基座,携手产业链合作伙伴,推动大模型在具身机器人、智能座舱、低空经济等场景的规模化落地,为万物智联时代注入强劲的智算动能。

 VIP复盘网
VIP复盘网
