

这不是新瓶装旧酒,而是从底层逻辑上,重新定义了数据治理的玩法。

破局革新:AI数据治理提智提效

极致提效:效率的“乘法”,而非“加法”
极致提效:效率的“乘法”,而非“加法”
元数据补全,效率提升6倍;数据标准构建,提升7倍;标准落标,提升6倍;数据模型设计,提升7倍。这是什么概念?原来一个资深专家,一天最多处理50个字段的元数据对标。现在,同样的工作量,单字段处理时间从10分钟降到了秒级。
对话即治理:从”反复的菜单查找“到”对话即执行“
对话即治理:从”反复的菜单查找“到”对话即执行“
大家现在用AI工具,基本上是“你提问,它回答;你下指令,它执行”的模式,这已经很方便了。
但睿治Agent的“对话即治理”,不只是“你问我答”。它基于Agent的感知-决策-执行能力,能够实现从问题发现、到分析、到修复的全流程智能闭环。更关键的是——它会告诉你它为什么这么做。
做过数据治理项目的同学应该都有这个体会:你跟客户汇报,说“我们给这个字段补了这个业务描述”,客户会问你:依据是什么?你说“我们把这个字段落标到了这个数据标准”,客户问:凭什么?这种灵魂拷问,以前只能靠人来回答,有时候确实很难自圆其说。
现在,睿治Agent在执行每一个任务的时候,都会明确告知:我根据什么规则、基于什么知识模型、做出了这个判断。所有操作留痕,支持回溯。这个透明度,直接建立了和客户之间的信任。
知识可沉淀:从“个人经验”到“组织智能”
知识可沉淀:从“个人经验”到“组织智能”
在数据治理项目上,经常遇到一种情况:一个很厉害的数据治理专家,在这家公司干了三五年,把数据摸得非常熟,治理成果也做得很好。然后有一天,他离职了。下一个接手的人,从零开始,之前所有的经验和成果,几乎全废了。这种损失,是没有办法用金钱来衡量的。
睿治Agent要解决的,就是这个问题。所有在平台上构建的标准、采集的元数据、落地的规则,全部沉淀在系统里。换人不换脑,经验不随人走。而且更重要的是——Agent学会了专家的经验之后,新人一上来,就站在专家的肩膀上。治理门槛,从“需要五年经验”降到了“具备基本知识就能上手”。
人机协同:从“三人团队”到“1人 Agent”
人机协同:从“三人团队”到“1人 Agent”
传统做数据治理项目,标配是资深业务专家、业务骨干、技术开发,至少三个人。而且,这三个人里面,最贵的那个——资深专家,往往是整个项目的瓶颈。他不在,事情推不动。
有了睿治Agent之后呢?理想的配置是:1名“治理专员”,负责审核和决策;所有的执行工作,由大脑统一指挥Agent来完成。在亿信华辰已落地的项目里,原来三个人的工作量,1人加Agent团队就可以胜任。
光有大模型还不够,得有“数据治理大脑”
光有大模型还不够,得有“数据治理大脑”
有些同学可能会想:上面这些事情,我接个OpenAI的API是不是也能干?但要重点说明一个事情:通用大模型确实很强,但它不懂数据治理的行业逻辑。你让它去判断一个金融数据字段该对应哪个监管标准,它可能根本没有这方面的训练数据。

睿治Agent的核心,是一个AI原生的“数据治理大脑”。这个大脑里面,沉淀了:各行业的数据治理经验、国家及行业的政策法规标准、大量真实项目的实践积累、以及针对不同场景的产品最佳实践方案。它懂业务、懂治理、能规划、能教学——这四个词说起来很抽象,用下面的一个场景让大家感受一下:
想象一个新人治理专员,第一天上班,完全不知道从哪里开始。以前他要去找老专家问,老专家不一定有空,就算有空,那套经验也不一定能完整传给他。现在,他打开治理大脑,问一句:「我们这是个金融项目,数据治理应该从哪里入手?」大脑会告诉他完整路径,告诉他每一步为什么,甚至告诉他某条元数据为什么推荐对标这个标准。
从摸着石头过河,到有地图导航——这就是“能规划”加“能教学”的实际意思。这个数据治理大脑,是实现一切革新的前提。

场景实践:Agent驱动的治理变革
睿治Agent数据治理平台是彻底的架构重构,而非简单的AI叠加。采用"Data AI"深度融合,内置智能体开发平台,将AI能力内化为治理流程的一部分。睿治Agent在实际的治理工作里,打造了多个场景Agent。
场景一:元数据Agent——告别资产“裸奔”
场景一:元数据Agent——告别资产“裸奔”
痛点:你有10万张表,一张表没有业务描述,业务人员看不懂,AI也读不懂。工程师花2小时翻文档、问业务,才勉强补上3个字段。按这个速度,把10万张表补完,项目早就黄了。
以往怎么干的?要么派人去各个业务系统,蹲守在业务人员旁边一个一个问;要么就是维护一下技术属性了事,业务属性和管理属性长期缺失。
业务人员不补没关系,人还能猜,凑合着出报表。但到了AI时代,这套逻辑彻底行不通了。缺少业务描述,AI的理解准确率会大打折扣——它能猜,但猜错的代价,你承担不起。
元数据Agent怎么做?它基于表结构、数据内容、所属业务系统等上下文信息,自动补全中文名称、业务描述、业务标签等关键元数据属性。这个过程,我们叫做:资产“自动穿衣”。原来10分钟才能补一个字段,现在降到秒级,而且有推荐依据,可以一键导出给客户确认。
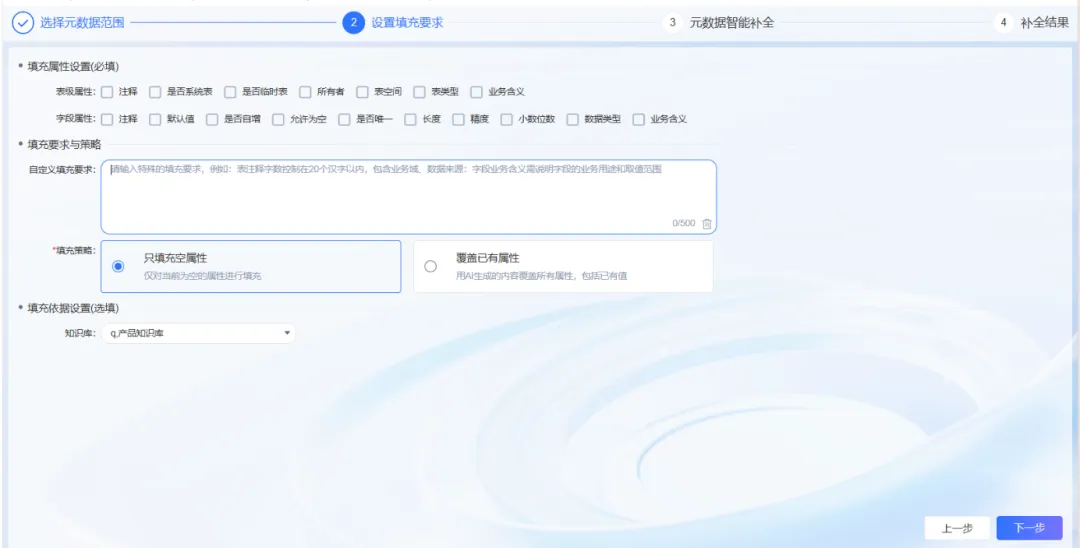
元数据的问题解决了。但光有数据,没有统一的语言,各个系统还是会各说各话——这就是第二个场景要干的事。
场景二:数据标准Agent——构建企业的数据语言
场景二:数据标准Agent——构建企业的数据语言
痛点:同一个“客户ID”,CRM叫cust_id,财务叫client_no,数据仓库里叫c_id。业务要拉一张客户全景表,三个团队吵了一周,谁也不肯改。这还不是最糟的。更糟的是:你花了3个月,好不容易梳理出200条数据标准,但没有系统能自动落标。传统方式靠机械的字符匹配,落标率不到1%。项目一结束,无人维护,新表又回到“无标”状态。
问题还在于——如果是对AI来说,一个客户叫三个名字,它会直接把三个名字当成三个不同的客户实体。你的数据分析,从源头就已经错了。
数据标准Agent怎么做?两个核心能力:智能建标和智能落标。
建标阶段,它会识别企业数据字典,参考国标、行标素材,智能推荐可能存在的数据标准,用户确认后一键入库。标准的建设效率和客观性,都大幅提升。
落标阶段,不再是机械的字符匹配,而是基于语义理解加知识库,智能为每一条元数据推荐最符合的标准,做到“应落尽落”。
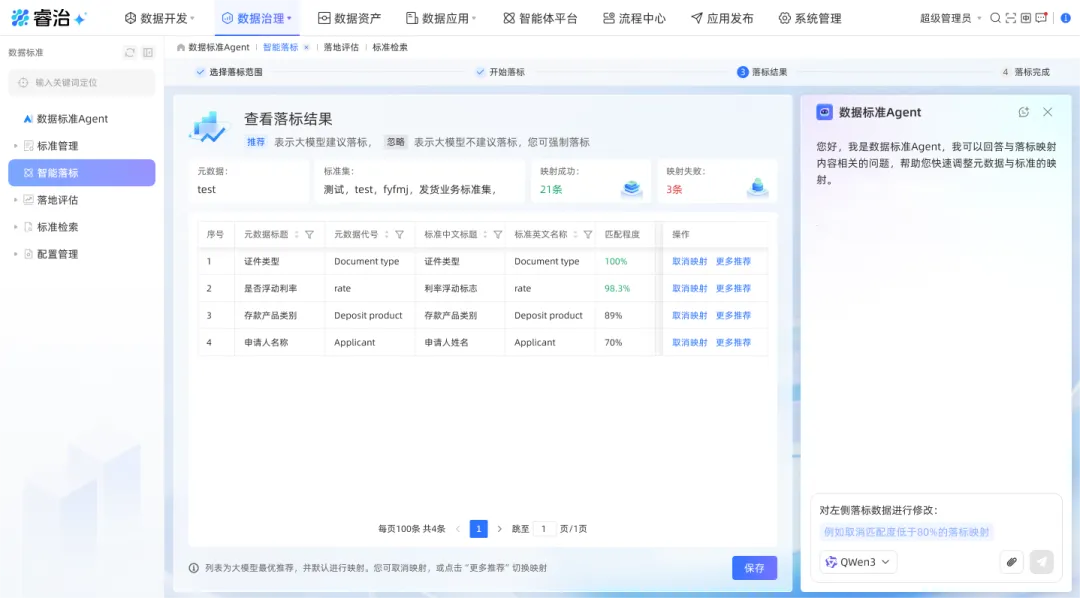
语言统一了,但数据质量没有保障,一切都是白搭——质量问题,是下一个场景的核心。
场景三:数据质量Agent——从“事后灭火”到“主动体检”
场景三:数据质量Agent——从“事后灭火”到“主动体检”
痛点:系统上线半年没发现问题。直到年中汇报,财务口径和销售口径对不上,才查出是某字段空值率突然飙到40%。事后灭火,业务已经受损。
而且,很多项目的质量规则只能覆盖最基础的空值、唯一性检查。那些字段之间的勾稽逻辑关系,根本没办法用人工去建规则——因为这需要同时懂数据逻辑和业务流程的复合型人才,很多企业里这样的人,一个都没有。
数据质量Agent怎么做?两个核心能力。
第一,智能体检:Agent自动探查数据现状,覆盖完整性、准确性、一致性等6大类规则,生成全面的健康检查报告。相当于给你的数据请了一个7×24小时的体检医生,提前发现“亚健康”状态。
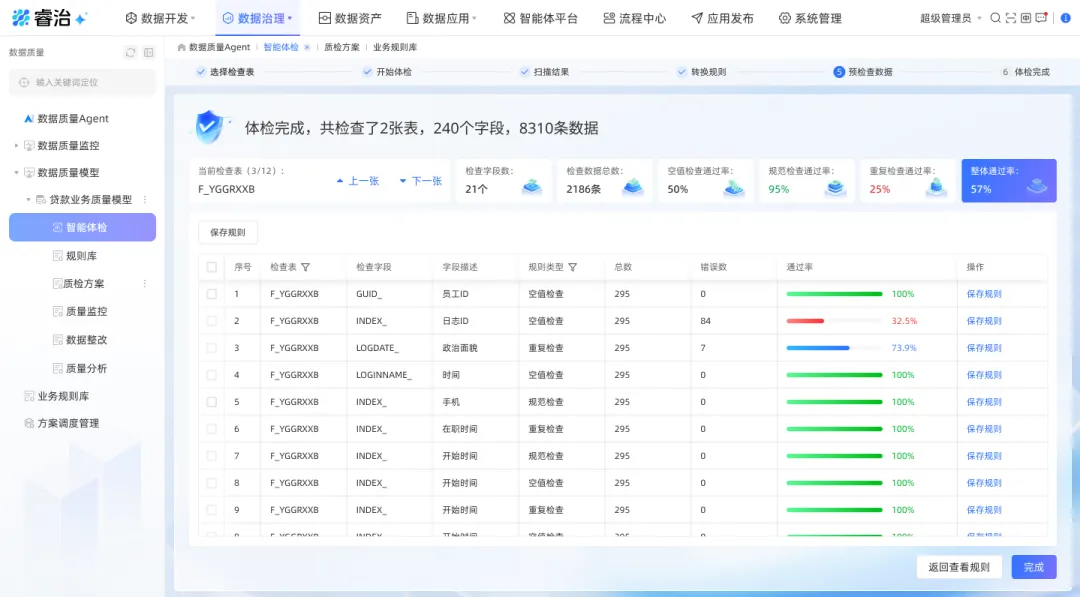
第二,规则智能生成:你有监管类的业务规则文档?直接上传给Agent,它自动解析,找到对应需要检查的表和字段,生成可执行的技术规则。
质量问题有了抓手。但数据从哪里来、建模怎么做,这个环节的效率一直是个老大难——资深架构师不够用,新人根本上不了手。第四个场景,解决这个问题。
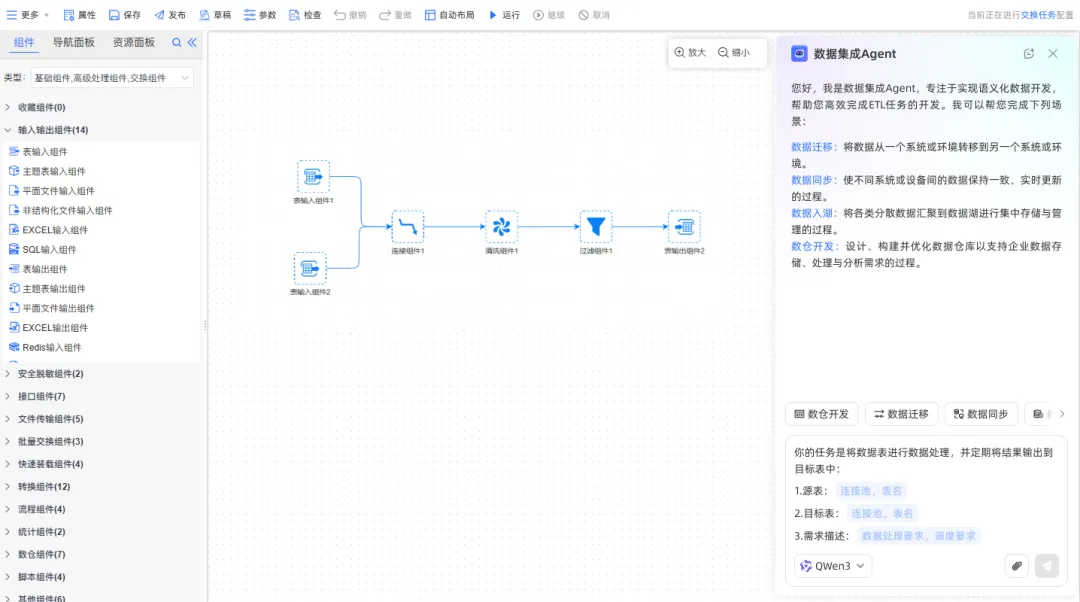
场景四:数据模型Agent 数据集成Agent——从“画图”到“对话”
场景四:数据模型Agent 数据集成Agent——从“画图”到“对话”
痛点:建模工具按钮上百个,资深架构师拖拽连线一整天,才画出一个简单模型。换一个新人?一周都搞不懂界面。业务说“加个字段”,底层ETL要改十几个地方,上线又延期。
两个Agent怎么做?
数据模型Agent支持语义建模:用自然语言描述需求,Agent自动生成符合3范式的概念、逻辑、物理模型,并自动关联已有的数据标准。你把DDL语句、SQL脚本、设计文档丢给它,它能反向解析,帮你生成完整的模型层级。
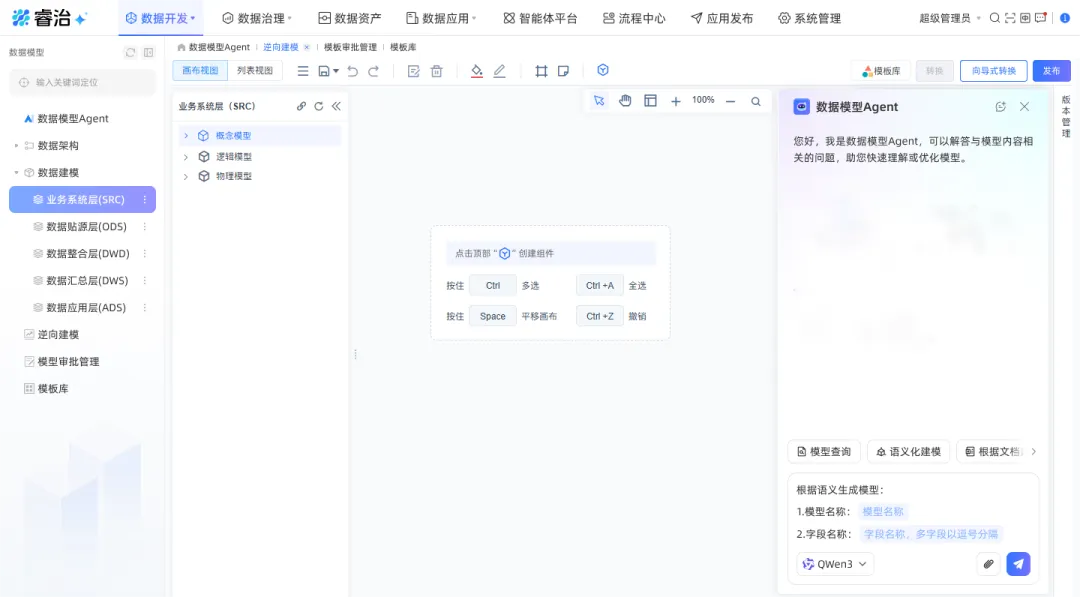
数据集成Agent实现自动数据开发:你告诉它“把A库的表迁移到B库”,它自动生成ETL任务和调度。不需要手动拖组件,不需要写SQL,上线时间大幅缩短。
开发效率的问题解决了。最后一个场景,是这几年越来越被重视的一块——数据安全合规。这块如果出问题,代价是最大的。
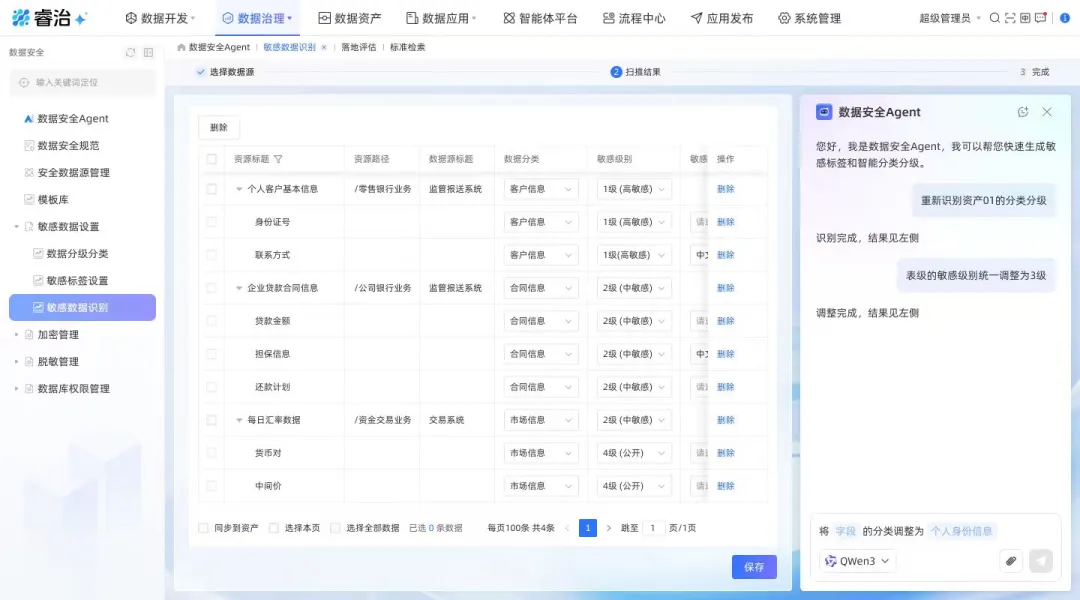
场景五:数据安全Agent——让安全合规有据可依
场景五:数据安全Agent——让安全合规有据可依
痛点:几百张表里,哪些有身份证号、手机号?安全团队手动翻了三天,才覆盖20%。漏掉一个敏感字段,就可能面临合规处罚。
而且分类分级标准本身也是个难题:照搬国标太粗,不落地;自己摸索缺依据,审计时经不起推敲。再加上安全专家一旦离职,谁也搞不清楚当时的分级逻辑,整套体系形同虚设。
更可怕的是:AI一句话查询,就能把未脱敏的身份证号、手机号全部查出来。
数据安全Agent怎么做?你把需要参考的国标,或者企业内部的分类分级制度文件,直接上传给它。它智能理解文件内容,结合已盘点的数据资产,帮你构建符合企业自身的分类分级标准,并自动推荐敏感数据的策略标签——身份证号、手机号、姓名等,全部精准识别。整个过程,纳入了大量行业最佳实践和合规知识库,确保不因设计缺陷导致合规漏洞。

案例应用:金融企业的真实数字

这是某大型金融集团的智能数据管理平台项目。这家企业的体量不小:十余个业务系统,超过20万张数据表,建立了1500条左右的数据标准。
他们之前的困境:
标准是有的,但落标全靠人工。三个人花了四个月,才覆盖了不到30%,而且还不允许漏——意思是要全部遍历完,才能提交结果。效率低到让人绝望。非监管类的数据质量,完全没有抓手。技术团队去问业务人员“我们该做哪些质量检查”,业务人员也说不清楚。最终,质量规则只能覆盖空值和重复,复杂的字段间逻辑关系,根本建不起来。
用了睿治Agent之后:
元数据智能落标方面:针对十几万条元数据,对照1000多条数据标准,一期验收的落标准确率达到了80%以上;整体落标覆盖率从30%提升到了70%;单字段处理时间,从原来的10分钟,降至秒级。
数据质量体检方面:接入资产管理系统的40多张表,10分钟之内,推荐了600多条规则。这600多条规则里,包含了大量复杂的字段间勾稽逻辑关系。这类规则,以往根本建不出来。客户初步的规则采纳率在40%左右。
做完这两个场景之后,我们发现客户衡量价值的方式,和我们预期的不太一样——他们不是在问「准确率多少」,他们在问「你帮我多建了多少以前建不出来的东西」。
具体来说:元数据落标,客户当然要看准确率,但他们更看重的是覆盖率——应落尽落,在质量不降低的前提下,同步提升广度。
数据质量体检,客户的逻辑是:推荐了600条,哪怕我只采纳了10条,那这10条,以前可能要花两三个月才能建出来,或者因为缺乏复合型人才,根本就建不出来。规则能建出来这件事本身,就已经是价值。
以前,人要同时扮演规则制定者、执行者、核查者、知识传承者这几个角色。现在,执行层面的工作交给睿治Agent,人只需要做一件事:审核和决策。
这是从“人治”到“智治”的真正变化。
治理的成果,不再存在某一个人的脑子里,而是沉淀在系统里、积累在大脑里,形成企业真正的核心数据资产。无论人员怎么更迭,治理能力都在,而且在持续生长。这是我们认为AI时代数据治理应该有的样子。

 VIP复盘网
VIP复盘网
