


新智元报道
新智元报道
【新智元导读】2025年底,AI战局继续扑朔迷离,卖铲子的英伟达似乎也想要下场挖矿了。12月15日英伟达对外宣布Nemotron 3家族(Nano/Super/Ultra),Nano先发布,Super/Ultra规划在2026年上半年。
长久以来,全世界都习惯默认AI领域遵循一种分工:英伟达和其他。
其他包括:OpenAI、Meta、谷歌、DeepSeek、xAI等等。
分工的原则也很简单:卖铲子和用铲子的。

最近谷歌靠着TPU,具备了和英伟达掰一掰手腕的能力。但短期内依然难以撼动英伟达
只要金矿还在,无论谁挖到了金子,卖铲子的人永远稳赚不赔。
这种商业模式让英伟达的市值一度冲破天际,成为全球最赚钱的科技公司之一。
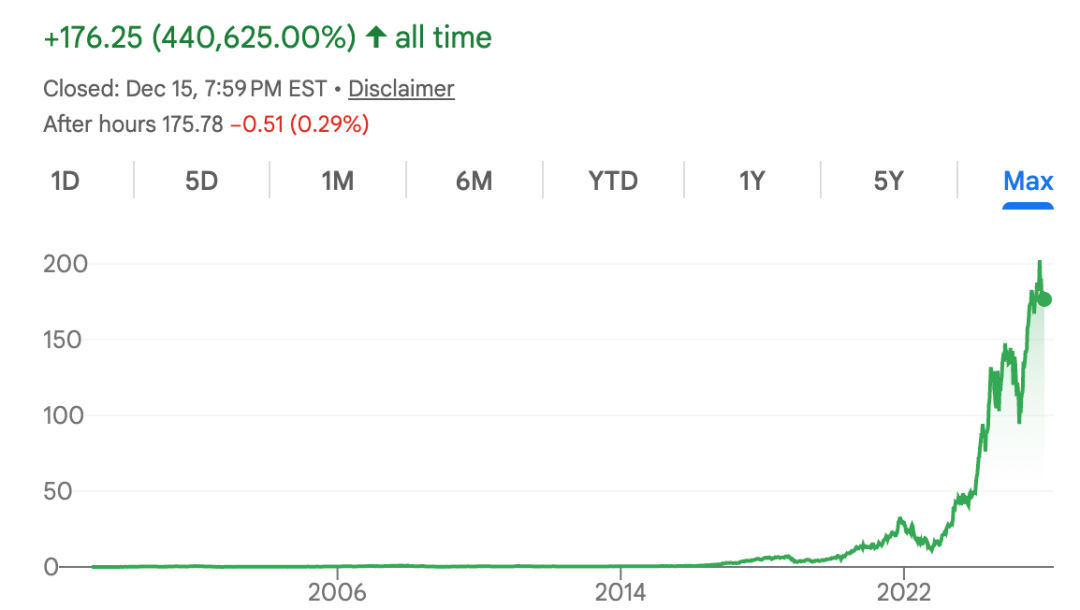
然而,2025年底,英伟达似乎不再满足于这种状态,它想亲自下场挖矿。
英伟达正式发布了全新的开源模型家族——Nemotron 3。

这不仅仅是一次例行的产品更新,更像是一次精心策划的战略突袭。
英伟达不再满足于仅仅提供硬件底座,它亲自下场了,而且一出手就是颠覆性的「王炸」:
Mamba架构、MoE(混合专家模型)、混合架构、100万Context(上下文窗口)。
Nemotron 3系列开源模型涵盖Nano、Super和Ultra三种规格。
Nemotron 3是英伟达对OpenAI或Meta开源的一次简单模仿吗?还是黄仁勋的玩票之举?

在AI的竞技场上,架构就是命运。
过去几年,Transformer架构如日中天,它是ChatGPT的灵魂,是Llama的基石,是所有大模型的底层。
但随着模型参数的膨胀和应用场景的深入,Transformer的瓶颈也日益凸显:推理成本高、显存占用大、处理超长文本时效率低下。
英伟达这次推出的Nemotron 3家族,并非单纯的Transformer模型,而是一个集众家之长的「混血王子」。
它极其大胆地融合了Mamba(状态空间模型)、Transformer(注意力机制)和MoE(混合专家模型)三大顶尖技术。
其中,Nemotron 3 Nano通过突破性的混合专家架构,吞吐量比Nemotron 2 Nano提升4倍。
Nemotron凭借先进的强化学习技术,通过大规模并发多环境后训练实现了卓越的准确性。
NVIDIA率先发布了一套最先进的开源模型、训练数据集以及强化学习环境和库,用于构建高精度、高效率的专用AI智能体。

Nemotron 3并非单指一个模型,而是一个完整的家族矩阵,旨在覆盖从端侧设备到云端超级计算机的全场景需求。
根据英伟达的规划,这个家族主要包含三位成员,每一位都身负不同的战略使命:
参数规模:总参数量30B(300亿),但推理时激活参数仅为3B(30亿)左右。
核心定位:它是家族中的先锋,主打高效推理和边缘计算。在消费级显卡甚至高端笔记本上就能流畅运行。
技术亮点:它是目前市面上最强的「小钢炮」,利用混合架构实现了极致的吞吐量,专门针对需要快速响应的Agent(智能体)任务设计。
战略意义:Nano的存在是为了证明「混合架构」的可行性,并迅速占领开发者桌面和端侧设备市场。
参数规模:约100B(1000亿),激活参数约10B。
核心定位:面向企业级应用和多智能体(Multi-Agent)协作的中枢。它需要在性能与成本之间找到完美的平衡点。
技术跃迁:预计将引入更高级的Latent MoE技术,专为复杂的企业工作流设计。

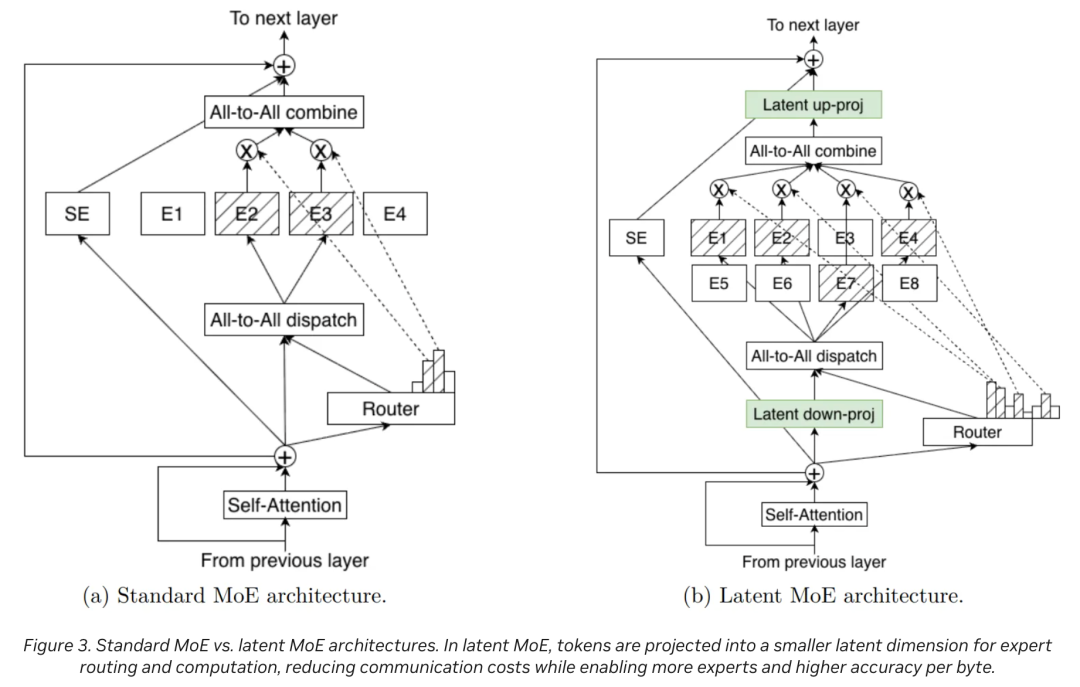
参数规模:约500B(5000亿),激活参数约50B。
核心定位:家族的旗舰,处理最复杂的推理、科研和深度规划任务。
野心:直接对标GPT-5级别的闭源模型,旨在成为开源界的推理天花板。它将展示英伟达在超大规模集群上的训练能力。
Nemotron 3 Nano它不仅仅是一个模型,更是一个技术验证平台,证明了「Mamba MoE」在小参数下也能爆发出惊人的战斗力。
要理解Nemotron 3的革命性,首先得聊聊Mamba。
为什么英伟达要在一个主流模型中引入这个相对「小众」的架构?
在LLM(大语言模型)的世界里,Transformer是绝对的霸主,但它有一个致命的弱点:
随着输入内容的变长,它的计算量和内存消耗呈平方级爆炸式增长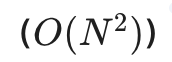 。
。
想象一下,你读一本书。
如果你是Transformer,读第一页时很轻松;读到第一千页时,为了理解当前的句子,你必须同时在脑海里复盘前999页的每一个字与当前字的关系(注意力机制)。
这需要巨大的「脑容量」(显存)。当上下文达到10万、100万字时,任何现有的GPU都会被瞬间撑爆。
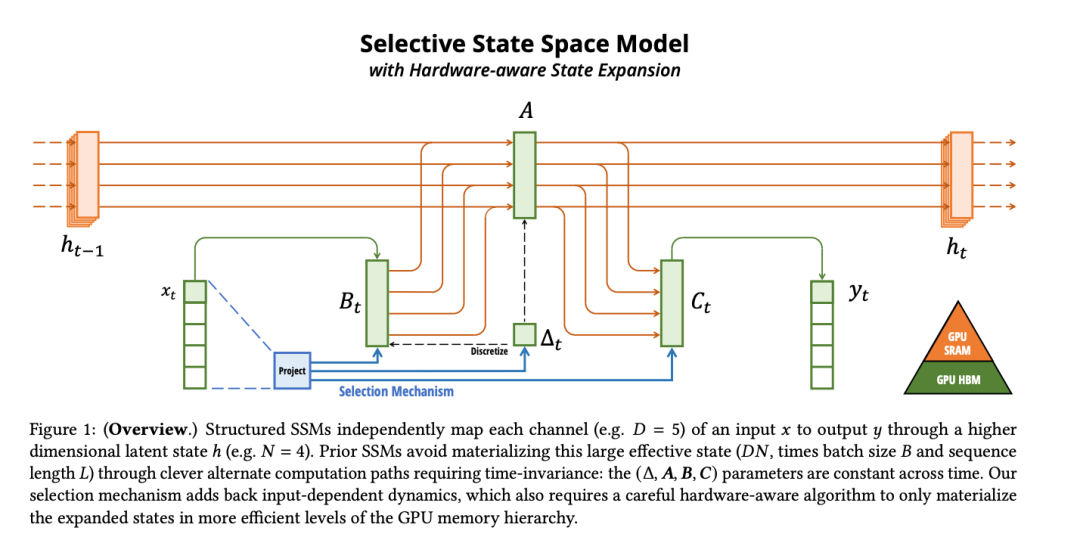
Mamba则不同。它基于SSM(状态空间模型,State Space Models),本质上更像是一个拥有超强短期记忆的循环神经网络。
它阅读的方式更像人类:读过去的内容会被「消化」进一个固定大小的记忆状态(State)中,不需要时刻回头翻看每一个字。

论文地址:https://arxiv.org/pdf/2312.00752
Mamba的核心优势:
线性复杂度(O(N)):
无论书有多厚,Mamba的推理消耗几乎是恒定的。读1万字和读100万字,对显存的压力几乎一样。 推理速度极快:
因为不需要计算庞大的KVCache(键值缓存)注意力矩阵,Mamba的生成速度(吞吐量)极高。 无限上下文的潜力:
理论上,Mamba可以处理极长的序列而不会撑爆显存。
然而,Mamba也有短板。
在处理极其复杂的逻辑推理、或者需要「回头看」精准定位某个信息点(Copying/Recall任务)时,它的表现不如Transformer的Attention机制精准。
因为信息在被压缩进「状态」时,难免会有损耗。
英伟达的解法:成年人不做选择,我全都要。
Nemotron 3采用了Hybrid Mamba-Transformer(混合Mamba-Transformer)架构。
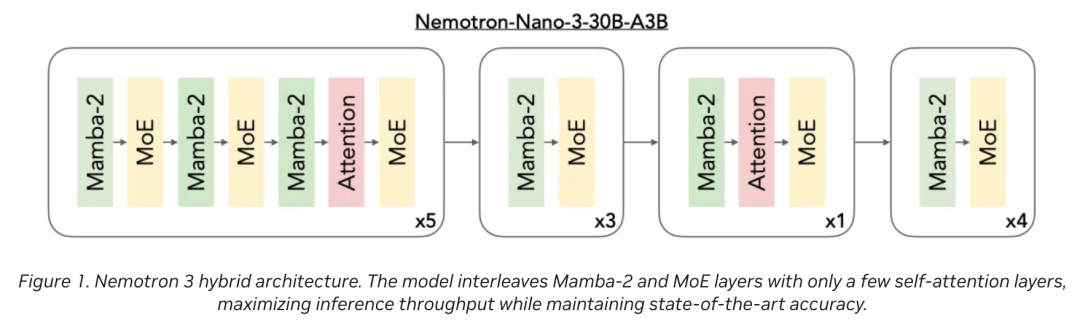
这是一个聪明的设计:
Mamba层(主力):负责处理海量的上下文信息,构建长期的记忆流,保证模型「读得快、记得多、省显存」。这构成了模型的主干。
Transformer层(辅助):在关键节点插入Attention层,负责「精准打击」,处理需要高度逻辑推理和细节回调的任务。

这种设计让Nemotron 3 Nano拥有了100万token(1M)的超长上下文窗口,同时推理速度比同尺寸的纯Transformer模型快了4倍。
如果说Mamba解决了「长」的问题,那么MoE(Mixture of Experts,混合专家)就解决了「大」的问题。
传统的稠密模型(Dense Model)像是一个全能通才,不管你问什么问题(是写诗还是算数),它都要调动大脑里所有的神经元来思考。
这非常浪费算力。
MoE架构则像是一个「专家团」。
在Nemotron 3 Nano这个30B的模型里,住着128个不同的「专家」(Experts)。
这是英伟达硬件霸权的直接体现。

Nemotron 3 Super/Ultra将采用NVFP4格式进行训练和推理。

论文链接:https://arxiv.org/html/2509.25149v1
Blackwell专属:這是英伟达下一代GPU架构Blackwell的原生支持格式。
极致压缩:相比现在的FP16(16位浮点)或BF16,NVFP4将模型体积压缩了3.5倍。
精度无损:许多人担心4-bit精度会让模型变笨。
英伟达利用特殊的两级缩放(Two-levelScaling)技术,结合块级(Block-level)和张量级(Tensor-level)的缩放因子,在4-bit这种极低精度下,依然保持了模型的高性能。
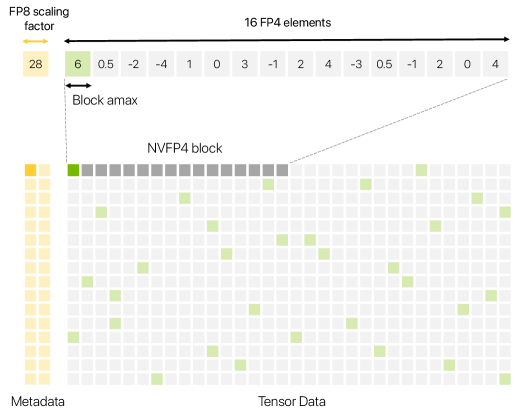
这意味着什么?
这意味着,未来的500B巨型模型(Ultra),可能只需要现在100B模型的显存就能跑起来。
但这有一个前提:你必须用英伟达的Blackwell显卡。
这是一个极其隐蔽但致命的「软硬件锁定」策略。
英伟达正在通过数据格式,为自己的硬件挖一条深深的护城河。
此外,英伟达还推出了「NeMo Gym」强化学习实验室,并罕见地开源了训练数据,旨在为开发者提供构建AI智能体的完整工具链。
为什么英伟达这个在这个星球上最赚钱的芯片公司,还要费尽心机去搞一个开源模型?
甚至不惜投入巨大的资源去研发Mamba这种非主流架构?
过去,英伟达是单纯的「卖铲子」。
不管你用PyTorch还是TensorFlow,不管你跑Llama还是GPT,只要你买H100/H200/GB200,黄仁勋就开心。
但现在,市场变了。
危机正在逼近:
竞争对手崛起:
AMD的ROCm正在追赶;谷歌的TPU在自家生态里极其便宜且强大,甚至能做到比英伟达便宜一半;各大云厂商(AWS、Azure)都在自研推理芯片。 模型架构分化:
如果未来的模型不再依赖CUDA优化,或者专门针对TPU优化,英伟达的护城河就会变浅。
发布Nemotron 3,英伟达实际上是想要定义下一代AI的标准。
推广Mamba架构:Mamba架构虽然好,但对硬件优化要求极高(需要高效的并行扫描算法)。
谁最懂如何在GPU上跑Mamba?
当然是英伟达。通过开源高性能的Mamba模型,英伟达在诱导开发者使用这种架构。
一旦生态形成,大家会发现:只有在英伟达的GPU上,Mamba才能跑得这么快。这就在算法层面锁死了硬件选择。
NVFP4的锁定:这是一个更露骨的阳谋。
Nemotron 3 Super/Ultra使用NVFP4格式。这是一种只有Blackwell GPU原生支持的格式。
如果你想用最高效、最先进的开源模型?请购买Blackwell显卡。
英伟达不再满足于你用它的卡,它要你用它的架构、它的数据格式、它的软件栈。
它要让整个AI生态长在它的硅基底座上。
Nemotron 3的发布,标志着AI行业进入了一个新的阶段。
英伟达正在构筑一个闭环的开放生态。听起来很矛盾?不,这正是高明之处。
从战术上看,这是一款极其优秀的模型。它快、准、省,解决了企业部署AI的痛点,特别是对于那些想做Agent、想处理长文档的公司来说,Nemotron 3 Nano似乎也是一个不错的答案。
从战略上看,这是英伟达构建「AI帝国」最关键的一块拼图。
硬件:Blackwell GPU NVLink NVFP4。
软件:CUDA NeMo TensorRT。
模型:Nemotron(Mamba MoE)。
应用:NIMs(Nvidia Inference Microservices)。
它开放模型权重,让谁都能用;但它封闭最佳体验,只有在英伟达的全栈生态里,你才能获得那4倍的加速、那极致的压缩、那丝滑的部署体验。
对于开发者来说,这是一场盛宴。有了更强的开源工具,能做更酷的事情。
对于竞争对手来说,这是一场噩梦。追赶英伟达的难度,从单纯造出芯片,变成了要造出芯片、还要适配架构、还要优化软件、还要提供模型……这是一场全维度的战争。
Nemotron 3就像是黄仁勋扔进AI湖面的一颗石子,涟漪才刚刚开始扩散。
2026年,当500B参数的Nemotron Ultra带着Latent MoE和NVFP4降临时,那或许才是AI大战真正的「诺曼底」时刻。
不过,想要做好大模型并不是容易的事情。
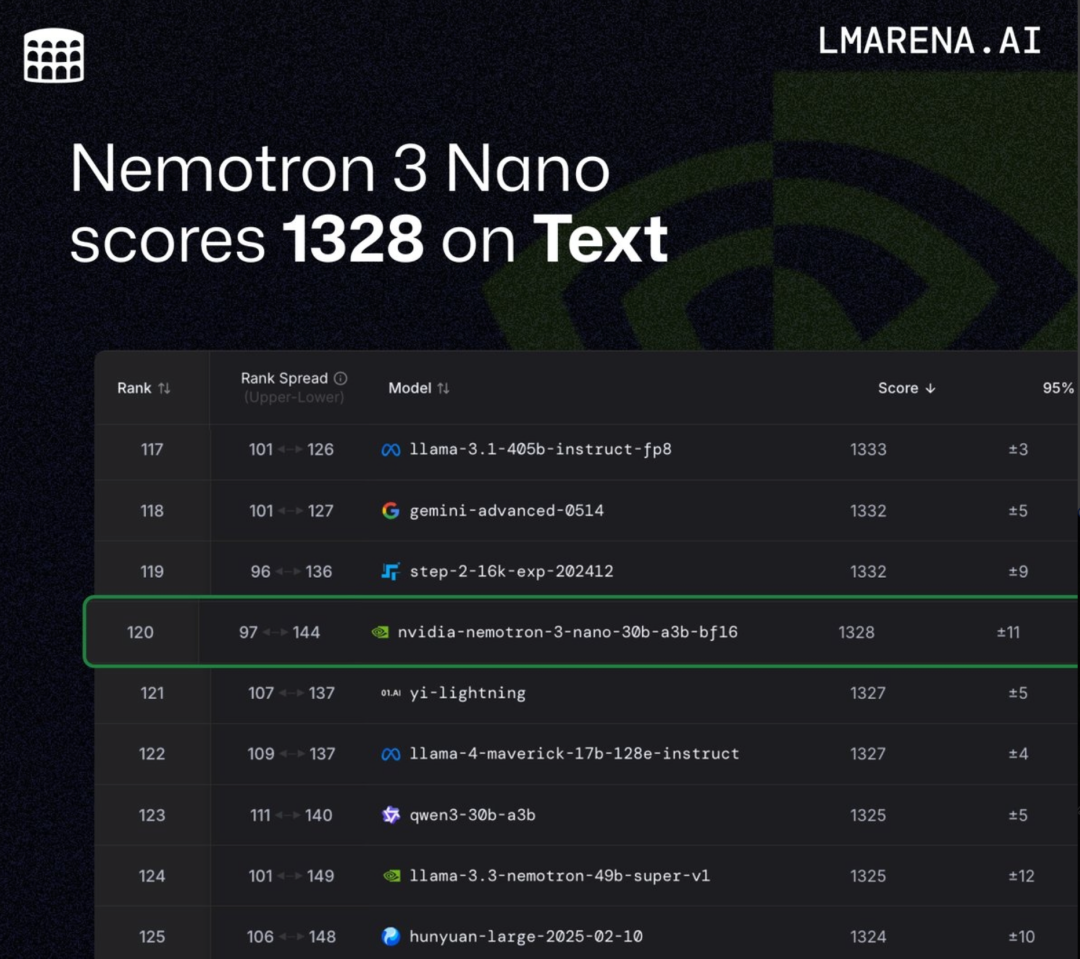
英伟达最新Nemotron 3在开源榜单中排名已经出来了。
Nemotron 3 Nano(30B-A3B)目前在文本排行榜上排名第120位,得分为1328分,在开源模型中排名第47位。

 VIP复盘网
VIP复盘网
