


架构代号 | 中文代号 | 年份 | 工艺制程 | 晶体管数 | 代表型号 |
特斯拉 | 2008 | 90nm | 约6.84亿 | G80 | |
Fermi | 费米 | 2010 | 40/28nm | 30亿 | Quadro 7000 |
Kepler | 开普勒 | 2012 | 28nm | 71亿 | K80、K40M |
Maxwell | 麦克斯韦 | 2014 | 28nm | 80亿 | M5000、M4000 |
Pascal | 帕斯卡 | 2016 | 16nm | 153亿 | P100、GTX1080、P6000 |
Volta | 伏特 | 2017 | 12nm | 211亿 | V100、TiTan V |
Turing | 图灵 | 2018 | 12nm | 186亿 | T4、GTX2080Ti |
Ampere | 安培 | 2020 | 7nm | 283亿 | A100、A30、GTX3090 |
Hopper | 赫柏 | 2022 | 5nm | 800亿 | H100、H200 |
Ada Lovelace | 阿达·洛夫莱斯 | 2022 | 5nm (台积电 4N) | 760亿 | L40、L40S、RTX 4090 |
Blackwell | 布莱克威尔 | 2024 | 5nm,台积电 4NP | 2080亿 | B100、B200、RTX 5090 |
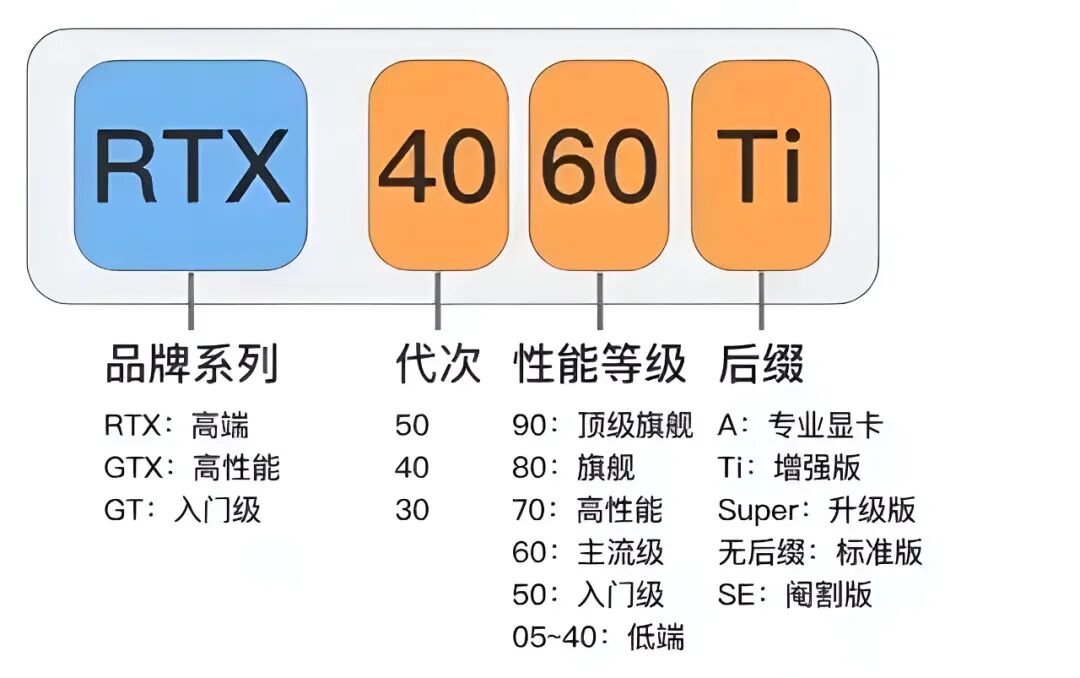
(1)代表产品:
RTX 30 系列(Ampere架构)、RTX 40 系列 (Ada Lovelace架构) 、RTX 50系列(最新Blackwell架构)三大系列。
比如:RTX 5090:旗舰级显卡,拥有32GB GDDR7显存、10752个CUDA核心,AI算力达2375 TOPS,定位高端游戏与专业创作,适合追求极致性能的用户。
RTX 30 | RTX 40 | RTX 50 | |
Ampere | Ada Lovelace | Blackwell | |
2、 RTX A系列/Quadro--专业图形与工程计算
RTX A系列,原Quadro,其特定是更精确的色彩显示,专业软件认证,多屏高分辨率支持(最高32个4K),是设计师的"精密仪器"。
(1)定位:专为创作者、工程师定制。工作站显卡专注于稳定性、精准度与专业软件兼容性,是影视特效、建筑设计、CAD绘图、科研仿真的理想搭档。
(2)代表产品:RTX A6000、RTX A5000(Ampere架构)、RTX 6000 Ada(Ada架构)。
(3)与GeForce区别:专业驱动(稳定性优先),双精度计算能力更强,专业领域的用户首选A系列,不建议使用消费级GeForce RTX显卡替代,尽管后者性能不差,但稳定性与兼容性无法保证。
3、边缘计算&智驾系列
(1)Jetson 系列:AI边缘专业
英伟达Jetson系列是面向边缘计算和嵌入式AI应用的高性能计算平台,可在设备端直接完成感知、推理与决策,无需依赖云端传输,实现低延迟、高实时性的本地化AI处理。旨在为机器人、自动驾驶、工业自动化、智能安防等领域提供本地化AI算力支持。
① Jetson AGX Thor,Blackwell架构,算力高达2070 TFLOPS(FP4精度),支持万亿参数级生成式AI模型。内存:128GB大容量显存,可运行复杂多模态模型。功耗是40-130W,适用于人形机器人、手术机器人、边缘生成式AI等高端场景。
② Jetson AGX Orin:算力200-275 TOPS(INT8),支持多传感器融合与复杂AI任务。内存是32GB/64GB LPDDR5,满足高带宽数据处理需求。功耗约15-60W,适用于高端机器人、工业自动化、城市安防等领域。
③ Jetson Orin Nano,算力是20-40 TOPS,低功耗、低成本入门级选择。内存约4GB/8GB LPDDR5,适合小型机器人、无人机导航、便携式设备。功耗约7-15W,体积小巧,便于集成。
(2)DRIVE 系列:自动驾驶大脑
① DRIVE PX2:早期平台,采用Pascal架构GPU和双Tegra处理器,算力达8TFLOPS,支持12路摄像头输入,用于高精度地图绘制和深度学习模型训练,特斯拉Hardware 2.0曾采用此平台。
② DRIVE AGX Orin:2019年推出,采用Ampere架构,单芯片算力达254TOPS,集成12核ARM Hercules CPU和2048个CUDA核心,符合ISO 26262 ASIL-D安全标准,广泛应用于L3-L4级自动驾驶车型。
③ DRIVE Thor:2022年发布,基于Blackwell架构和ARM Neoverse V3 CPU,单颗算力达2000TOPS(INT8),集成Transformer引擎,支持自动驾驶、智能座舱、自动泊车等多场景功能,预计2025年量产上车。
4、AI训练&IDC系列:英伟达的王牌
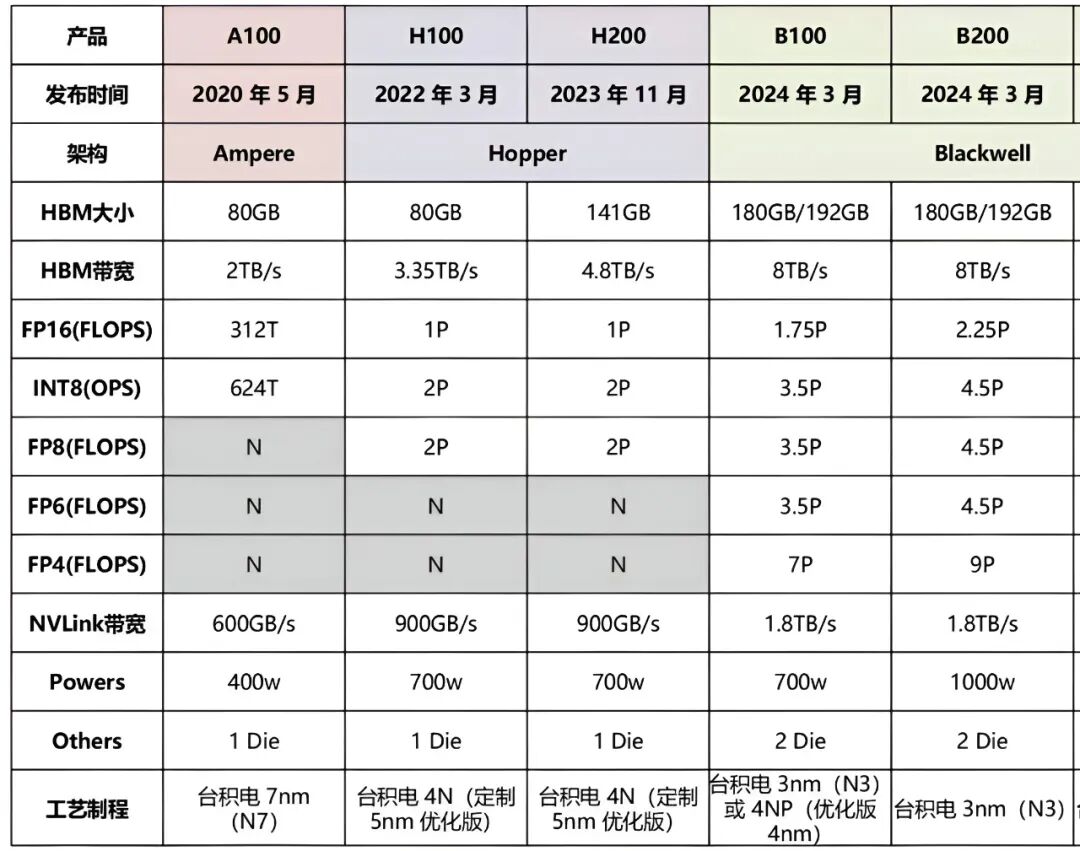
(1)A 系列(Ampere 架构):曾经的AI之王
A 系列是Ampere 架构,采用多流处理器(SM)设计,集成更多CUDA核心、Tensor核心和RT核心,支持FP32、TF32、BFloat16、FP16、INT8等多种精度计算;配备HBM2e显存,带宽可达1.6TB/s至2.04TB/s,支持大容量显存(40GB至80GB)。
1)A100:2020年旗舰AI训练卡
① CUDA核心数6912,Tensor核心432,标配显存40GB/80GB HBM2e,FP32算力19.5TFLOPS,TF32算力156TFLOPS,适用于深度学习训练、科学计算、GPT-3训练、企业AI集群。
2) A30/A40:中端推理选择
A40:适合图形与AI混合任务。FP32算力23TFLOPS,显存48GB GDDR6,集成RT核心,支持实时光线追踪,适合计算与图形融合场景,如多物理场仿真、AI模型推理部署。 A30:为推理优化;显存24GB HBM2,FP64算力可达10.3TFLOPS,支持稀疏化加速,性价比高,适用于中小型科研任务和轻量AI模型训练。
3)A800:中国市场特供版
性能与A100相近,但NVLink带宽限制为400GB/s,适用于国内合规场景的AI训练和推理。
(2)H系列(Hopper架构):AI训练旗舰
2022年3月23日的GTC大会上,英伟达宣布推出采用Hopper架构的新一代加速计算平台,并发布了其首款基于Hopper架构的GPU——NVIDIA H100。
H系列是针对数据中心和高性能计算领域推出的高端GPU产品线,主要面向大规模AI训练、推理及科学计算等应用场景。
1) H100:当前AI训练的顶流
① 架构:Hopper,专为Transformer优化,采用4nm工艺,集成800亿晶体管。
2)H200:是H100的推理增强版
① 核心升级:搭载HBM3e内存,延续Hopper架构,进一步优化硬件设计,推理性能较H100提升约2倍,更适合生成式AI和科学计算场景。
② 使用场景:LLM推理部署、推荐系统、科学计算、边缘AI推理加速。
3)H800:中国市场的特供版
(3)B系列--AI推理与超算集群芯片
英伟达B系列芯片均基于Blackwell架构,是面向大规模AI计算集群的新一代产品,涵盖面向全球通用市场的B200、B300,
1) B200:AI推理的霸主
2024年3月发布,由两个Blackwell GPU和一个Grace CPU组合而成,采用双4nm设计,晶体管数量达2080亿个。
配备192GB高速HBM3e显存,单GPU AI性能达20 PFLOPS,是前代H100性能的5倍,处理相关AI任务速度快30倍,能耗成本较前代降低25倍,适配超大规模AI模型训练与推理,支持第五代NVLink,单向带宽达1.8TB/s,支持多GPU互联扩展,可构建大规模计算集群。
2) B300:B200的升级款
同样是Blackwell架构,但在B200基础上进行了优化和升级,性能较B200提升50%,采用台积电4NP工艺。显存升级为288GB 12层堆叠HBM3E,虽带宽保持8TB/s,但更大显存适配OpenAI o1/o3等推理大模型。
其配套的GB300 HGX TDP达1.2KW,还支持NVLink NVL72技术,最多72个GPU可超低延迟协同工作,且仅提供参考板,组件可由客户自行采购,灵活性更高。
(4)GB系列--高性能计算超级芯片
将两个B200 GPU与一个基于Arm的Grace CPU进行配对,再通过900GB/s的超低功耗NVLink连接在一起,可以组成GB200超级芯片。
英伟达GB系列是其针对高性能计算(HPC)和人工智能(AI)训练/推理场景推出的高端计算平台,主要包括GB200和GB300两个型号。GB200于2024年3月在GTC大会上正式发布,同年第四季度开始小批量出货;GB300:于2025年3月在Computex 2025上首次公开亮相。
GB200单芯片FP4算力达20 PFlops,GB300进一步提升至30 PFlops;整机柜(NVL72)算力可达数百PFlops,支持万亿参数规模模型训练。 B200 GPU单颗芯片的功耗1000W,一颗Grace CPU和两颗Blackwell GPU组成的超级芯片GB200的功耗达到了2700W。

1、架构&技术亮点
141GB HBM3e显存:相比H100的80GB HBM3,容量提升76%,支持超大规模模型(如千亿参数级LLM)的完整加载,减少模型分块和数据交换开销;显存带宽达到4.8TB/s,较H100提升43%,确保海量数据快速读写,显著加速训练和推理过程。
HBM3e采用堆叠式设计,将多个存储层叠加,实现更高带宽和更低能耗,数据传输速度可达每秒1.15TB。
(2)强大的FP8计算能力
H200 配备了 16,896 个 CUDA 核心和 528 个第四代 Tensor Core,支持 FP8/FP16/FP32/BF16/FP64 等多种精度计算。值得注意的是,H200 的 Tensor Core 在 FP8 精度下可提供高达3,958 TFLOPS的算力,这一数值是 H100 的 2 倍,是 A100 的约 3 倍。此外,H200 还配备了 142 个 RT Core,支持光线追踪技术,为科学可视化等应用提供硬件加速。
(3)第4代NVLink与能效比
支持NVLink 4.0互联技术,提供900GB/s的GPU间互联带宽,8路配置的HGX H200提供超过32 petaflops的FP8计算能力,可构建大规模GPU集群,实现低延迟、高带宽的多卡协同计算,满足超大规模AI任务需求。
2. 与H100的对比
H200 与 H100基于相同的 Hopper 架构,均采用台积电4N(5纳米)制程,拥有相同数量的 CUDA 核心和 Tensor Core。
两者的主要差异在于内存系统:H200 将内存从 80GB HBM3 升级到 141GB HBM3e,带宽从 3.35TB/s 提升到 4.8TB/s。这一升级使得 H200 在处理大模型时具有显著优势,特别是在模型参数超过 80GB 的场景下,H200 能够避免模型分片带来的性能损失。
特性 | H200 | H100 | 提升幅度 |
显存容量 | 141GB HBM3e | 80GB HBM3 | 76% |
显存带宽 | 4.8TB/s | 3.35TB/s | 43% |
LLM推理速度 | 1.7-1.9倍 | 基准 | 70%-90% |
HPC性能 | 比CPU快110倍 | 比CPU快110倍 | 能效提升50% |
功耗效率 | 50%提升 | 基准 | 显著降低TCO |
三、产业链相关标的
(1)芯片制造与封装
① 台积电:独家代工英伟达4nm/5nm先进制程芯片,Blackwell系列唯一供应商,2023年占台积电营收10.11%,已超苹果成为第一大客户
② 中芯国际:国内规模最大、技术最先进的集成电路晶圆代工企业,部分中低端GPU及AI推理芯片代工
③ 长电科技:中国大陆唯一通过H20封装认证企业,负责B100芯片50%封装订单,采用XDFOI技术实现3D堆叠
④ 通富微电:英伟达GPU扇出型先进封装合作伙伴,适配Chiplet技术
(2)核心材料
PCB/覆铜板:
① 胜宏科技:英伟达显卡PCB全球市占率50%,独家供应GB300五阶HDI板(良率95%)。
② 沪电股份:北美AI服务器PCB市占率80%,40层高多层板订单排产至2026年,毛利率>20%
③ 生益科技:高频高速覆铜板供应商,M9材料核心供应商,单价溢价60%
④ 景旺电子、⑤ 深南电路:英伟达合格PCB供应商,高端服务器板卡核心供应商
电子元器件:
① 铂科新材:英伟达GPU电感软磁粉芯独家供应商,全球市占率超35%,直接提升芯片性能
② 和林微纳:GPU芯片测试探针核心供应商,精度达2μm,需求量与GPU产能呈线性关系
③ 华海诚科:HBM封装用环氧塑封料供应商,适配GB300芯片需求
④ 江海股份:超级电容供应商,GB300电源系统核心组件
高速互连与光模块:
① 中际旭创:英伟达800G/1.6T光模块独家供应商,全球市占率>50%,单台Quantum交换机配套价值36万美元
② 天孚通信:英伟达800G光引擎独家供应商,良率99.5%,CPO技术核心合作伙伴
③ 新易盛:800G LPO光模块通过英伟达认证,1.6T产品已获认证,泰国工厂规避关税
④ 源杰科技:25G/100G EML光芯片通过英伟达认证,国产替代加速
⑤ 博创科技、⑥光迅科技:英伟达光通信供应商,800G模块量产能力
(3)其他关键上游
EDA软件:
新思科技(Synopsys.US)获英伟达20亿美元投资(持股2.6%),英伟达芯片设计核心工具链供应商
HBM内存:
SK海力士、三星电子、美光科技垄断供应,SK海力士占HBM3E市场60%,HBM4单价约560美元
电源管理:
① 杰华特、② 晶丰明源:DrMOS芯片供应商,GB300电源系统核心
2、中游系统集成与制造
(1)服务器ODM/OEM厂商
① 工业富联:英伟达AI服务器全球最大代工厂,独占H100/H800模组90%份额,GB300液冷服务器独家代工,订单排至2026年,占数据中心业务40%
② 浪潮信息:国内AI服务器市占率超50%,H20芯片服务器独家供应商,2025年交付量预增200%
③ 华勤技术:英伟达AI服务器的重要ODM供应商,新晋GB300服务器ODM,Jetson Thor平台代工合作伙伴
④紫光股份:新华三品牌搭载英伟达GPU的AI服务器供应商,服务政企客户
⑤ 中科曙光:高性能计算服务器供应商,英伟达GPU战略合作伙伴
(2)散热与电源系统
① 英维克:GB300液冷方案核心供应商,冷板式市占率>50%,单套价值20万元,2025年订单增300%
② 高澜股份:浸没式液冷技术领先,GPU散热市占率超40%,适配GB300高功耗需求
③ 麦格米特:英伟达数据中心电源独家供应商,定制570kW HVDC电源(效率96%)
④ 中恒电气: 英伟达AI数据中心电源解决方案的核心供应商,通过工业富联等渠道间接进入英伟达产业链
(3) 其他中游配套(代理/分销)
① 鸿博股份:通过子公司运营北京AI创新赋能中心,提供英伟达算力服务,MiniMax智算合作伙伴
② 神州数码:英伟达中国区核心分销商,负责GPU、服务器销售及技术支持
③ 中电港:英伟达国内授权分销商,AI开发板等产品销售与服务
④ 弘信电子全资子公司安联通是英伟达中国区精英级(Elite)合作伙伴,拥有英伟达H20、H200等高端芯片的全牌照销售资格,负责英伟达芯片在国内的分销、解决方案集成及本土化服务
3、下游应用标的
(1) 智驾
① 德赛西威:基于英伟达DRIVE平台开发L4级自动驾驶域控制器,相关营收占比超40%
② 比亚迪(002594.SZ)、广汽集团(601238.SH):采用英伟达DRIVE Orin芯片的智能驾驶车型量产
③ 阿尔特:英伟达自动驾驶技术解决方案提供商,合作开发L2 至L4级系统
(2)智能制造
① 奥比中光:3D视觉传感器集成至Isaac Sim平台,2025年Q1获英伟达1.8亿元订单
② 均胜电子:工业机器人视觉系统供应商,基于英伟达Jetson平台开发
③ 天准科技:智能制造视觉检测设备提供商,搭载英伟达GPU加速
(3)AI服务与计算
① 光环新网、② 数据港:运营搭载英伟达GPU的AI算力中心,提供IaaS服务
③ 润建股份:通信网络与算力服务提供商,与英伟达合作建设边缘数据中心
④ 欧陆通:AI服务器电源领域的国内龙头,与英伟达存在深度合作关系。
⑤ 鸿博股份:通过全资子公司英博数科,与英伟达合作开展智算服务器算力资源及配套服务,参与建设英伟达北京AI创新赋能中心。


 VIP复盘网
VIP复盘网
