

英伟达Rubin进入量产,下一代Feynman进一步推升算力硬件需求,服务器架构从训练主导转向训推兼顾,从GPU主导转向GPU LPU架构,并推出存储机柜、CPU机柜、LPX机柜等,实现系统方案的进一步优化。谷歌/AWS/Meta等厂商的ASIC亦在加速迭代。算力芯片需求持续强劲增长,先进制程、先进存储、先进封装、PCB、光通信等仍是硬件需求增量、技术创新最显著的环节,台积电、三星、英特尔等开发并扩产2nm先进制程,HBM演进到HBM4并衍生出定制芯片,CoPoS、CoWoP等先进封装形式涌现,CPU、传统存储的供需也逐步紧俏。

算力催动存储需求高增长,涨价周期被显著拉长
随着AI训练、推理需求的持续膨胀,存储已成为算力增长的主要瓶颈,HBM/DDR、SSD、HDD陆续成为服务器的最紧缺物料。除了HBM、DDR外,产业内还在开发AI SSD、CMX、HBF、SRAM等存储器(或方案),以满足AI训练和推理过程中数据吞吐的高要求。
1、内存仍然是AI算力核心卡口,HBM需求持续高景气
随着英伟达GPU的发布周期固定在每年一次,算力提升对内存容量和带宽提出了接近每年翻倍的高要求;根据TrendForce数据,GPU的计算能力在过去20年间增长了60000倍,但同期DRAM内存带宽仅提高了100倍——“内存墙”仍将长期存在,通过HBM路线实现低功耗高带宽趋势明确。以位元计算,目前HBM占整个DRAM市场比重仍在个位数,渗透率存在较大提升空间;TrendForce预计2026年HBM出货量将超过300亿Gb。
DRAM产能供给紧缺趋势不变,SK海力士等龙头厂商加速扩产。从供给端看,HBM供应仍然紧缺,相应持续挤占DRAM产能,25Q4-26Q1 DRAM厂商现货报价加速攀升;部分美国与国内厂商已经开始和晶圆厂签订2-3年的长期合同进行锁价。根据Trendforce援引The Bell报道,SK海力士计划通过清州DRAM工厂M15X和利川M16的扩产,在26H2将其DRAM晶圆产量提高到60万片/月,和三星的DRAM晶圆产能处于同一水平。具体来看,M15X在投产初期将保持在10000片/月的DRAM晶圆,到26Q4将爬坡至5万片/月。
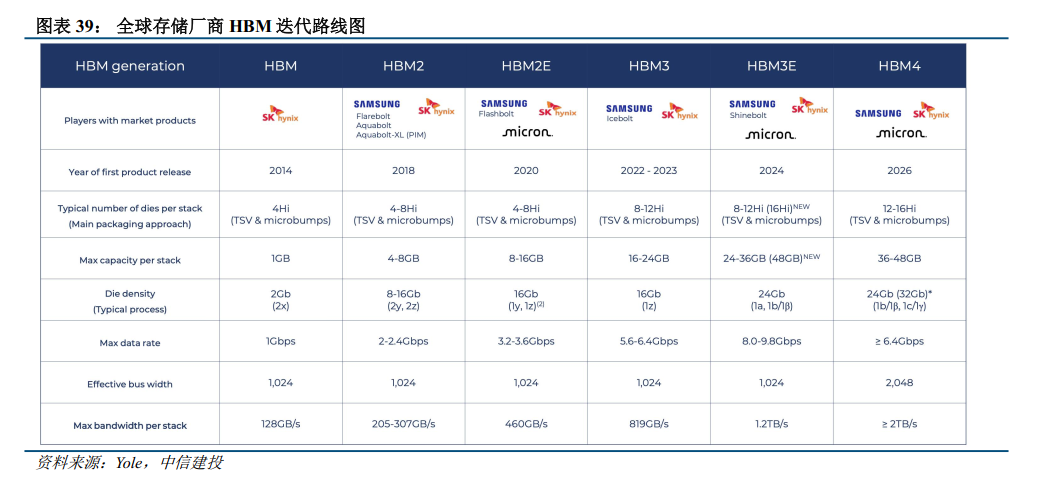
HBM迭代周期随之显著缩短,HBM4开始大规模商用。2025年下半年,英伟达量产的GB300搭载的是12层24GB的HBM3e,2026年英伟达将发布的Rubin系列和AMD将发布的MI400系列均将搭载HBM4/4e。其中英伟达计划在26Q1完成HBM4的最终资格测试。从更新周期来看,JEDEC于2025年4月正式发布了JESD 270-4高带宽存储器(HBM4)标准,(接口宽度从HBM3/HBM3e的1024位翻倍至2048位;堆栈通道数从16个增加到32个,支持24Gb或32Gb芯片的4到16层堆栈配置),较HBM3规范发布晚约三年,计划落地时间较HBM3落地时点亦在三年左右。根据EETimes的预测,HBM的迭代周期从前期的每四年一代提高并稳定到每两年到两年半一代。
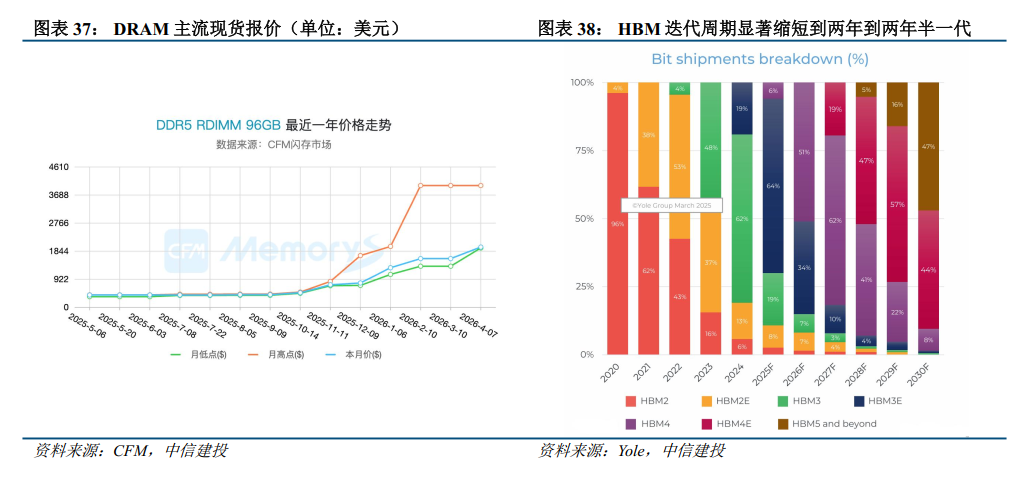
全球龙头存储厂商竞逐HBM4,SK海力士仍居领先地位,三星美光加速追赶。根据Trendforce预测,2025年SK海力士将以59%的HBM出货量保持行业领先地位,而三星和美光将各占20%左右份额。从时点上看,SK海力士于2025年3月交付了全球首批12层HBM4样品、6月小批量出货,计划10月快速进入量产;美光也在25Q2向主要客户交付了HBM4样品;三星的HBM4样品25Q2交付给英伟达,当前进入最终的预生产(PP)阶段。预计2026年,领先的GPGPU如Rubin将大范围采用HBM4,Yole预计2026年HBM4渗透率将达到51%。
从技术上看,SK海力士的HBM4拥有2048个I/O终端,带宽翻倍,引脚速度在6.4Gbps以上。美光目前交付HBM4样品超过2.8 TBps带宽和超过11 Gbps引脚速度,计划在2027年同时推出标准版和定制版的HBM4e。三星同样计划于2027年推出HBM4e产品,目标引脚速度超过13Gbps,目标最大吞吐量3.25TB/s,较当前HBM3e快2倍以上。
远期看,英伟达等厂商计划自研Base Die,将存算架构进一步整合。除传统晶圆厂外,为了进一步提高传输速率,AI算力芯片厂商也开始协同进行HBM设计。2025年8月,英伟达宣布计划自研HBM内存Base Die,采用3nm工艺,预计于2027年下半年开始小规模试产。英伟达此次自研HBM内存Base Die的计划,旨在优化AI芯片的内存带宽与能效匹配度;未来英伟达的HBM内存有望采用内存原厂DRAM Die与英伟达Base Die的组合模式,标志着其在高性能计算存储架构领域的垂直整合进一步深化。
2、为解决HBM高成本低容量的问题,HBF应运而生
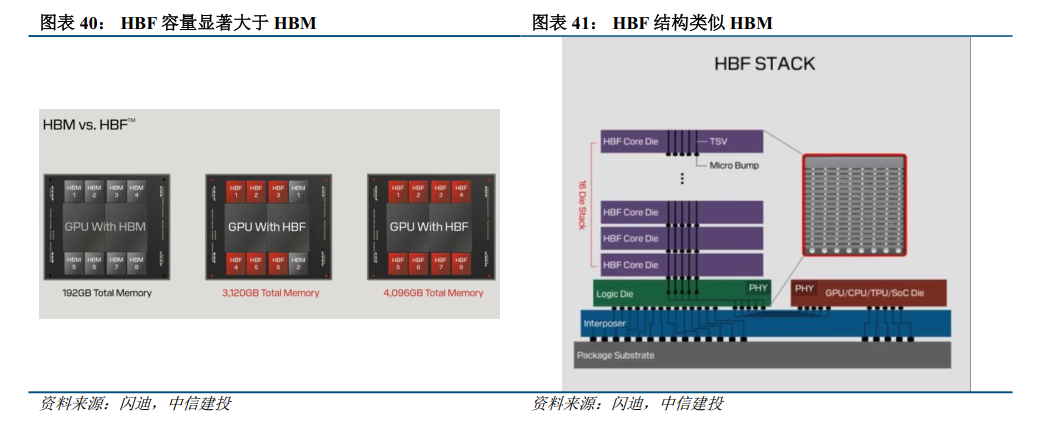
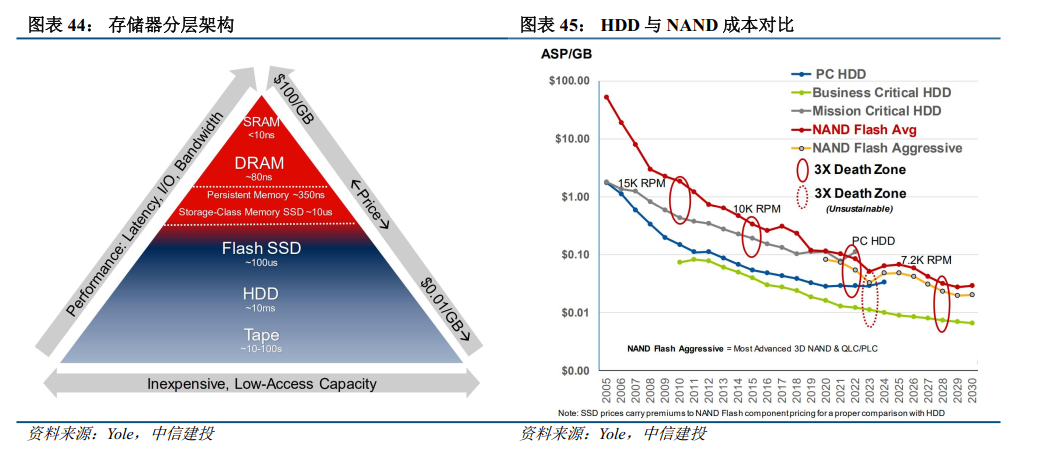
HBM带宽大、延迟低,但容量低、成本高。随着AI大模型参数规模向万亿级迈进,推理部署环节的市场规模和应用场景变得极为广阔,但传统的存储体系正面临严峻的“内存墙”困境。HBM虽能提供极致的带宽和纳秒级访问延迟,但其容量有限(单堆栈通常为16-64GB),且成本高昂,难以线性扩展。与此同时,传统SSD虽然容量大、成本低,但带宽严重不足(如NVMe PCIe 4.0 SSD仅约7GB/s),无法满足大模型推理时对海量权重数据和键值缓存(KV Cache)的高速读取需求。在AI推理场景中,数据访问模式呈现出“读多写少”的特点,且需要单次加载的模型容量极高——例如运行405B参数的Llama 3.1模型时,仅权重存储就需要数百GB空间。HBM很快会被KV缓存占满,而依赖远端SSD或向量重计算又会引入显著延迟。
正是在这一供需失衡的背景下,HBF(High Band Flash,高带宽闪存)应运而生。HBF旨在填补HBM与SSD之间的巨大空白,以接近HBM的带宽和成本水平,提供其8至16倍的超大容量。SK海力士的仿真测试表明,在H3混合架构中引入HBF后,原本需要32颗GPU才能完成的工作负载,仅需2颗GPU即可实现,能效比提升最高达2.69倍。HBF的出现,不仅有望破解推理阶段的存储瓶颈,更可能从根本上改变AI算力集群的经济模型,成为衔接HBM与SSD的新一代核心存储方案。
HBF通过封装创新、3D堆叠和分布式控制,在容量、带宽和成本三个维度上实现了独特的再平衡,成为AI推理场景的理想存储载体。HBF是一种基于3D NAND闪存的高带宽堆叠存储技术,其设计理念借鉴了HBM的垂直堆叠架构,但将存储介质从易失性的DRAM替换为非易失性的NAND闪存。在物理结构上,HBF通过硅通孔(TSV)或CMOS直接键合阵列(CBA)工艺,将多层高性能NAND闪存芯片垂直堆叠起来,并通过逻辑芯片与中介层连接至GPU或处理器,形成密集互连的存储结构。单堆叠可达16层die,首代产品即可实现512GB的容量和1.6TB/s的读取带宽——这一带宽水平已接近HBM3e的性能,而容量则是同等物理空间下HBM的8至16倍。与传统SSD依赖单控制器串行调度不同,HBF采用分布式控制结构,每一组NAND die可独立并行访问,结合优化的控制器算法,将NAND固有延迟从毫秒级压缩至约5微秒级,匹配AI推理场景对高带宽读的需求。由于基于NAND闪存,HBF具备非易失特性,无需像HBM那样持续刷新供电,静态功耗仅为HBM的64%至80%。当然,HBF也存在先天短板:NAND的写入耐久性有限(约10万次擦写),访问延迟(微秒级)远高于DRAM的纳秒级,因此业界主流设计思路是将HBF用于只读数据或低频写入的键值缓存,而将频繁读写的动态数据留在HBM中。
目前,全球存储巨头已围绕HBF形成技术竞赛格局,标准化与量产进程正在加速推进:
闪迪是HBF概念的率先提出者,2025年2月在投资者日上正式介绍HBF技术,依托自家BiCS 3D NAND和CBA工艺构建核心架构,采用16层核心芯片堆叠。闪迪计划于2026年下半年交付首批HBF模块样品,目标2027年初推出首批集成HBF的AI推理服务器。
SK海力士是当前HBF研发最为积极的厂商之一,2025年8月与闪迪签署谅解备忘录,共同推进HBF技术标准化;同年10月在OCP全球峰会上正式发布包含HBF技术的“AIN B”系列存储器,并举办“HBF之夜”活动推动生态合作。SK海力士还提出了创新的H3混合架构(Hybrid HBM HBF),将HBM与HBF并列部署于GPU两侧,通过双存储层级协同工作,并已完成早期测试验证。公司目标在2026年推出第一代HBF样品,2027年实现量产。
三星电子虽态度相对审慎,但已启动HBF产品的早期概念设计工作,并依托其在逻辑代工领域的4nm至2nm工艺优势,探索自研控制逻辑与下一代NAND方案的能效优化。三星计划在2027年底至2028年初将HBF集成到英伟达、AMD及谷歌的实际产品中。
此外,主控芯片方面,HBF需要配套极高吞吐能力的控制器来驾驭其超高带宽,闪迪、SK海力士等厂商均在研发专用的分布式控制架构,确保NAND阵列的并行访问效率。行业标准方面,三大厂商已就HBF标准化展开合作,闪迪与SK海力士、三星正共同推动HBF成为行业通用标准,目标在2027年完成产业级标准落地。
3、AI服务器挤兑传统应用需求,传统存储缺货涨价,涨价周期显著拉长
复盘存储器历史,存储器周期大致4-5年,上行、下行周期大致2年上下。上轮周期起始于20Q1,21Q3存储器价格见顶,此后价格持续下滑,至2023Q2持续7个季度。本轮周期,存储器23Q3开始涨价,期间24Q2-24Q4因库存问题,价格有所回落。24Q4-25Q3,除了HBM,DRAM和NAND价格涨跌更多来自库存周期,直到25Q4,北美云厂商对于2026年的需求展望大幅提升,内存条、eSSD缺货涨价,存储随着产能被服务器占用,传统应用(手机、电脑等)开始缺存储器,涨价蔓延至非AI领域的存储器。
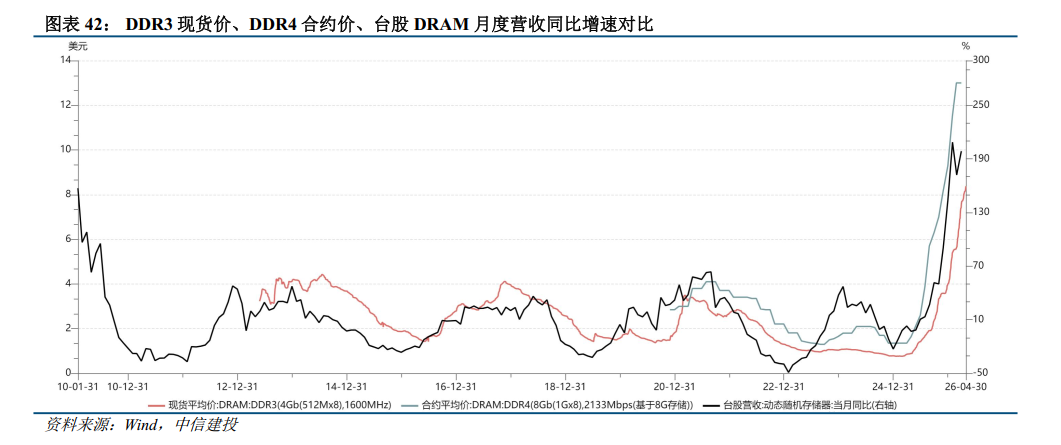
需求侧,对于DRAM而言,单GPU配置的HBM、DDR规格和容量提升,2023年以来需求跟随GPU持续强劲增长;对于NAND而言,推理侧的爆发和QLC NAND成本的下降加强了对高速率、低延迟SSD对HDD的优势,SSD需求跟随token爆发。
催动本轮存储上行的核心因素是AI,特别是推理需求的爆发。大模型训练阶段的存储需求主要来自预训练数据集和checkpoint(模型状态快照),原始数据集规模约10-30TB,而checkpoint存储量与模型参数量线性相关(如6000亿参数模型每个checkpoint约7TB,100个总计约700TB),这些数据主要存储在SSD和HDD中,因HBM容量不足而需从HBM经DRAM逐步offload至SSD。推理阶段的存储需求则主要来自KV Cache、RAG等,其规模比原始数据大1000倍左右(取决于向量维度),随着思维链发展和用户上下文增长,单次提问token数激增至上万,KV Cache需长期存储在SSD中,当用户30分钟未交互时自动从HBM存入SSD,后续提问时再加载回HBM。推理阶段的KV Cache存储策略采用精确匹配(用户历史对话)和向量空间模糊匹配(多用户共享问题),通过共享相同问题的KV Cache和将长期未使用数据转存至HDD来优化存储,而训练阶段的存储需求则随模型参数量增加而等比例上升。
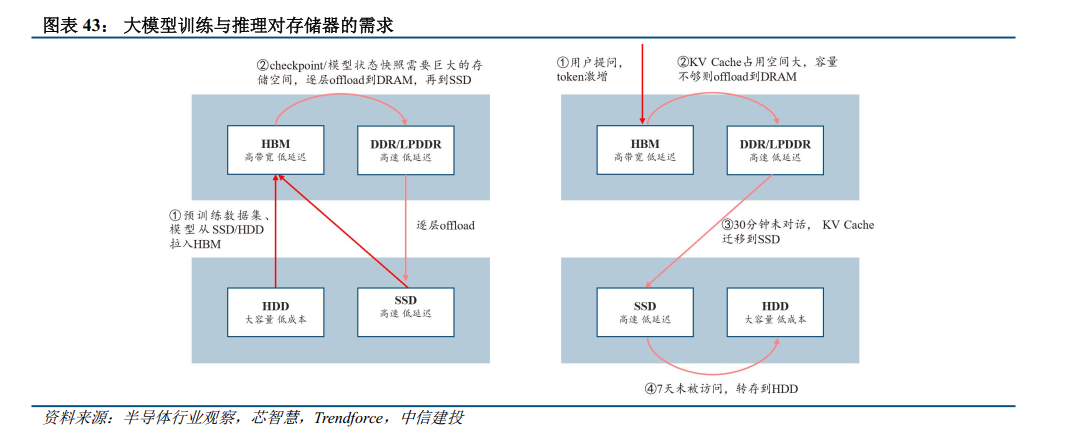
其次是HDD(机械硬盘)供应短缺,eSSD需求爆发。SSD相比HDD的核心优势在于显著的读写速度和低延迟特性,SSD的读写速度可达十几GB级别,而HDD仅约几百兆,这使其在AI推理、高频数据访问等场景中具有明显优势。HDD被SSD替代的主要原因是AI应用爆发式增长,尤其是数据中心对高性能存储的刚性需求,同时HDD产能面临严重瓶颈,HDD厂商因行业处于"夕阳产业"状态普遍不愿扩产,而是致力于优化成本和增加单盘容量,导致HDD供应紧张。在AI应用推动下,大量新增存储需求从HDD转向SSD,特别是数据中心企业级存储中,HDD与SSD的容量比正从1:5-1:6向1:1转变,预计2026年将出现QLC SSD替代HDD的爆发式增长。
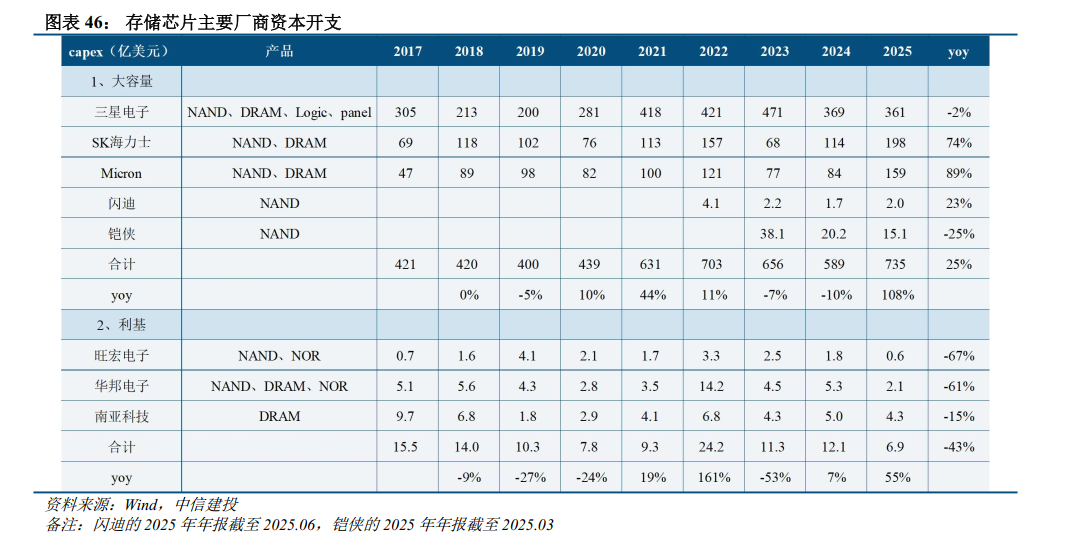
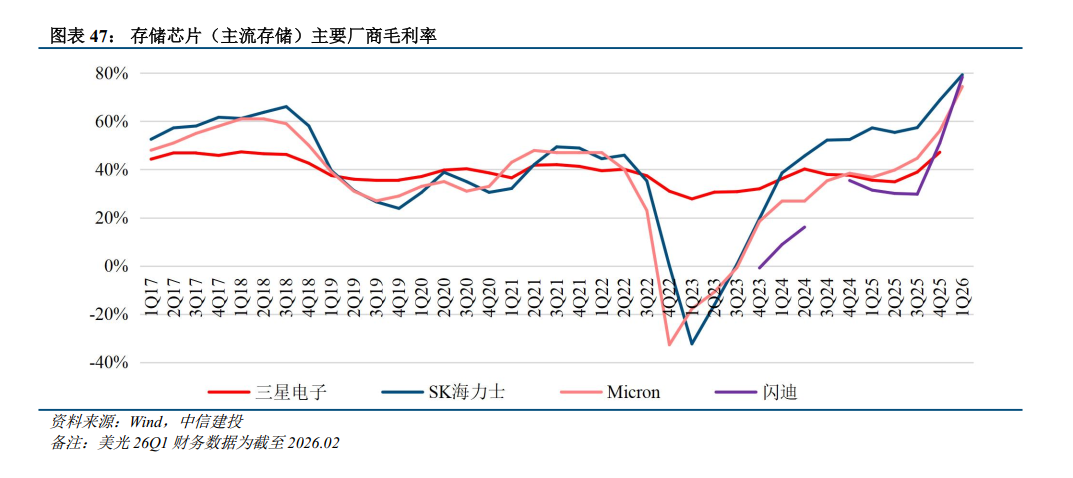
供给侧,存储IDM资本开支计划谨慎,且产能释放速度较慢。2023-2025年,大容量、小容量存储厂商资本开支维持低增长或者负增长状态,其中SK海力士资本开支增长较大,主要用于扩产前两年开始持续紧缺的HBM、DRAM。存储厂商的扩产意愿与供需缺口和盈利水平相关,目前各家DRAM和NAND的毛利率水平接近80%,存储厂商扩产动作开始变得频繁,但是存储器的扩产周期从购买设备到产能释放需要2年以上,因此新增的资本开支难以体现在2026年的供给上,预计产能释放的高峰期在2027年下半年及以后。
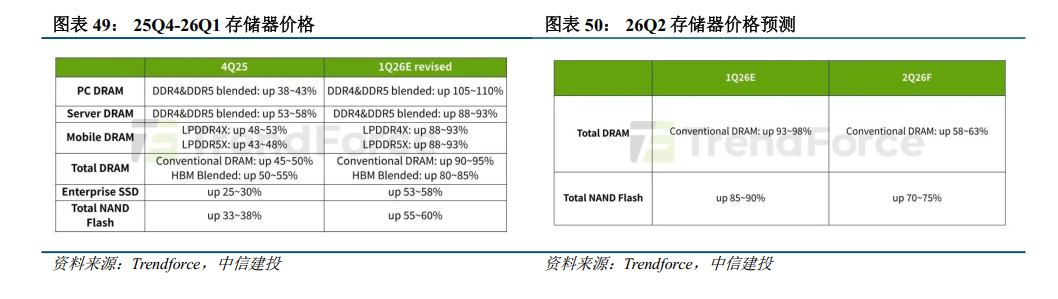
我们预计2026-2027年HBM、DRAM、NAND甚至小容量存储均会出现不同程度的供给紧缺,本轮存储涨价周期将不同于以往,涨价时间和涨价幅度将远超预期。供需缺口将催化价格大幅度上涨,根据Trendforce预测, DRAM 26Q2 的合约价在26Q1上涨93-96%的基础上继续上涨58-63%,NAND 26Q2的合约价在26Q1上涨85-90%的基础上继续上涨70-75%。
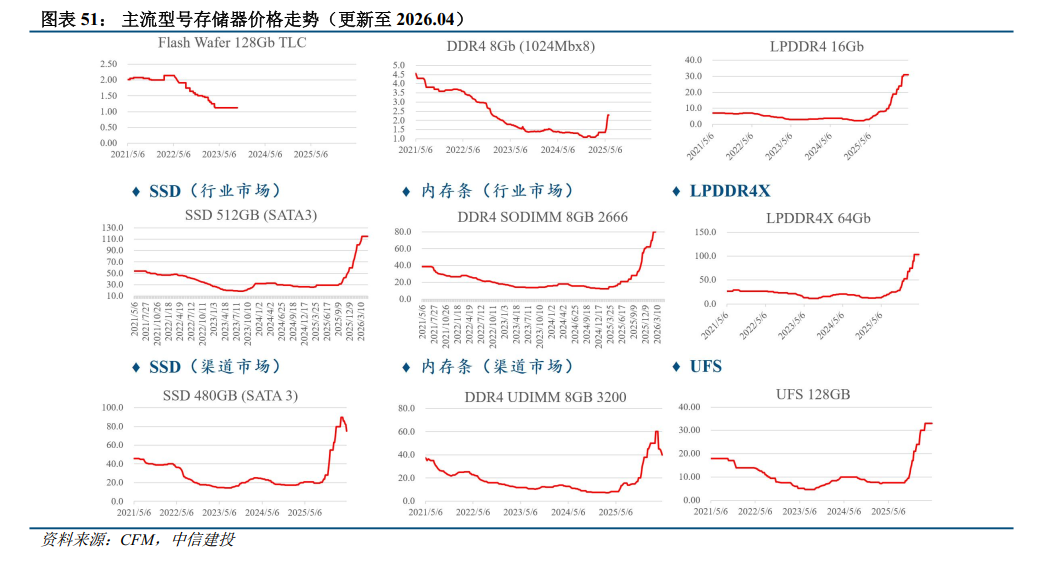
2026年,DRAM市场规模将增长至4570亿美元,同比 121%,预计NAND市场规模将增长至1420亿美元,同比 103%, NAND、DRAM的单GB价格均有大幅度提升。从 市场结构看,服务器在存储市场的占比有望进一步提升,成为存储器的第一大应用。

1、未来中美贸易摩擦可能进一步加剧,存在美国政府将设置进出口限制条件或其他贸易壁垒风险;2、AI上游基础设施投入了大量资金做研发和建设,端侧尚未有杀手级应用和刚性需求出现,存在AI应用不及预期风险;3、宏观环境的不利因素将可能使得全球经济增速放缓,居民收入、购买力及消费意愿将受到影响,存在下游需求不及预期风险;4、大宗商品价格仍未企稳,不排除继续上涨的可能,存在原材料成本提高的风险; 5、全球政治局势复杂,主要经济体争端激化,国际贸易环境不确定性增大,可能使得全球经济增速放缓,从而影响市场需求结构,存在国际政治经济形势风险。

 VIP复盘网
VIP复盘网
