

又放新大招了,将图像生成常用的“扩散技术”引入语言模型,12秒能生成1万tokens。
什么概念?不仅比Gemini 2.0 Flash-Lite更快。
甚至需要不得不在演示过程中放慢视频的速度,才能看清生成过程。
这是Google DeepMind推出Gemini Diffusion:不同于以往大多数语言模型“从左到右”预测文本的生成方式,而是通过逐步优化噪声来学习生成输出。

传统的自回归模型是根据已生成的词序列逐步预测下一个词,每次只能生成一个词或一个token,这种顺序过程很慢,并且会限制输出的质量和一致性。
而扩散模型的特点则是通过逐步细化噪声学习生成,这种特点会大大提高生成速度,并且减少训练的不确定性。
Gemini Diffusion就是利用了扩散模型这一优势,将文本生成速度提升至2000token/秒。
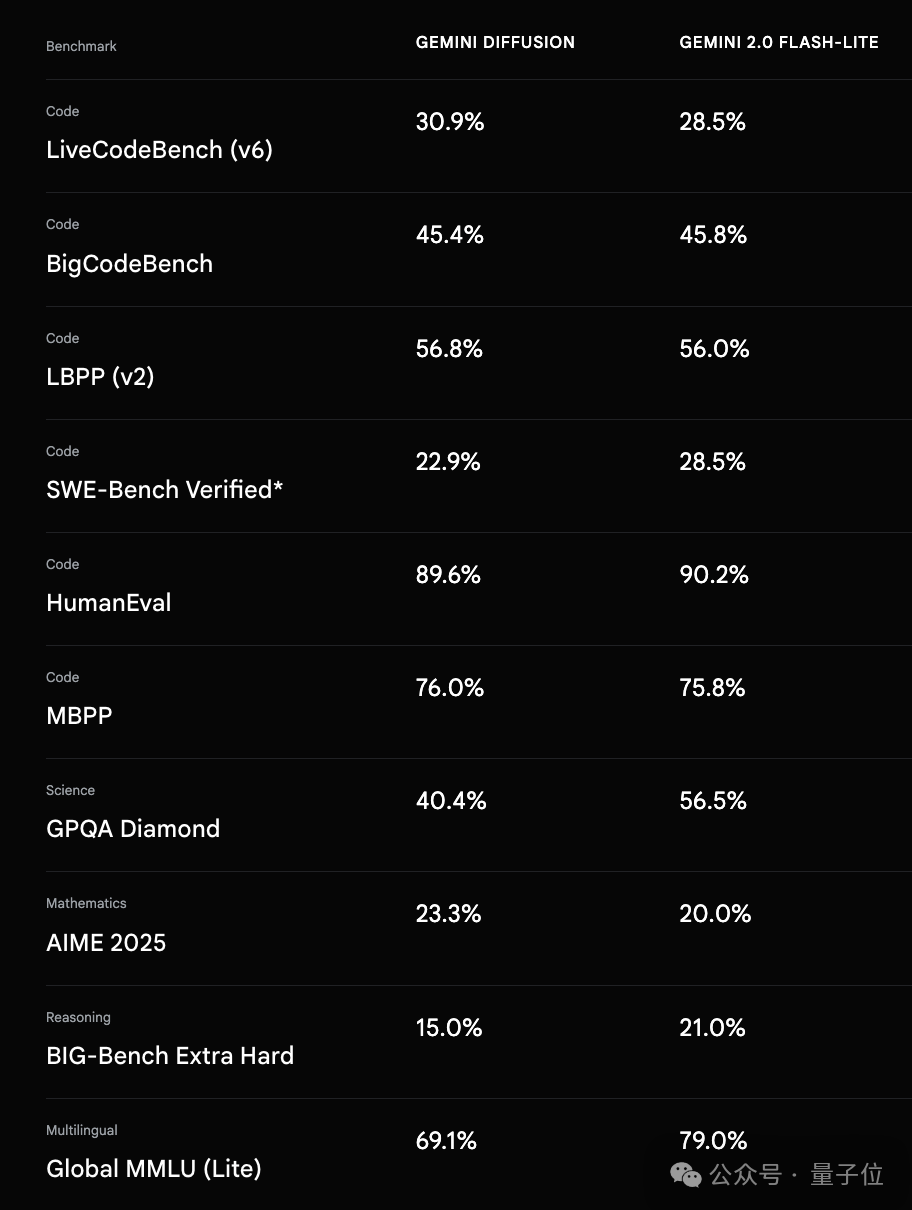
官方给出了Gemini Diffusion的基准测试结果,结果显示Gemini Diffusion的表现可与更大的模型(Gemini 2.0 Flash-Lite)相媲美,甚至速度更快。
Gemini Diffusion目前是一个实验性演示,官方设置了访问候补名单,感兴趣的朋友可以戳文末链接申请体验~
Gemini Diffusion每秒能生成2000个token
消除“从左到右”文本生成需求
与以往大多数基于自回归的语言模型不同,Gemini Diffusion在语言模型中引入了“扩散”技术,它不是直接预测文本,而是通过逐步细化噪声来学习生成输出。
这种技术能够让模型在生成过程中快速迭代,并在生成过程中进行错误纠正。
这种优势有助于模型在编辑等任务中表现出色,包括在数学和代码环境中也能表现良好。
有一位团队研究员展示了一个代码示例,在这个示例中,Gemini Diffusion模型以2000 个token/秒的速度生成,这其中包括toke化、预填充、安全过滤器等开销。
在生成过程中进行非因果推理
虽然Gemini Diffusion在生成速度上比迄今为止最快的模型还要快得多,但速度却不是它的唯一优势。
它能够一次生成整个标记块,这意味着对于用户的提示,它能比自回归模型做出更连贯的响应。
在迭代细化中能够纠正生成过程中的错误以获得更一致的输出。
研究员还通过举例说明,与仅限于一次生成一个token的自回归模型不同,扩散可以在生成过程中进行非因果推理。
“(√(81) * (2/3))^2 (15 - 3) / (2^2)) 等于多少?先给出答案,然后再推导出答案。”
对于基于自回归思想的模型来说,这是一个非常难的问题,例如,GPT-4o就无法解决此问题,因为它们必须严格自回归生成文本,无法跳过中间token,在生成答案之前对其进行推理。
但扩散模型的生成过程不依赖于严格的时序因果关系,而是通过并行或迭代式去噪实现数据生成,可以进行非因果推理以得出正确答案(答案:39)。以下是研究员提供的演示视频。
One More Thing
实际上,自回归确实不是LLM的唯一路径。
此前,人大高瓴人工智能研究院、蚂蚁也提出了类似研究,LLaDA是基于扩散模型的双向模型。
语言模型逐步引入扩散技术,在未来,我们是否可以期待更多混合模型的出现呢?

 VIP复盘网
VIP复盘网
