


摘 要
GPU不再是算力竞逐的核心,超节点规模将是算力世界的决胜场。超节点,即物理上由多台设备组成,逻辑上以一台机器学习、思考、推理,即通过Scale-up而获得远超Scale-out的卡间互联带宽。因此,超大规模的超节点是大模型训练最理想的工具。当前,全球大厂均已先后布局超节点产品,英伟达已展出其72卡、144卡、576卡的超节点路径,华为也亮相384卡、8192卡、15488卡的超节点方案。超节点将成为算力的主流形态,意味着在未来,算力需求方的采购,将以超节点为单位,而不是GPU卡。
我们认为,超节点时代,以下方向将有显著投资机会:
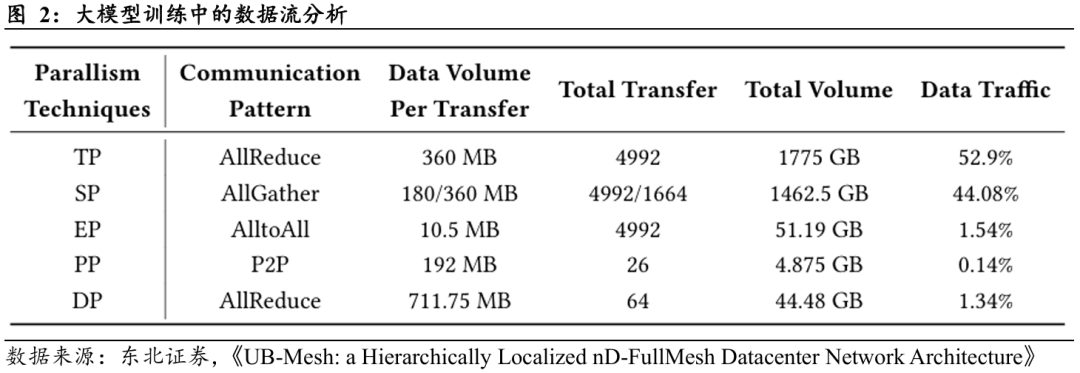
1、超节点时代,同等卡数规模集群,超节点形态的集群将使得先进制程需求倍增!超节点相比于传统AI算力集群,使用了数十倍数量的Scale-up switch芯片,其Scale-up switch芯片数量与集群GPU数量比之相近甚至超过。而Scale-up switch往往采用与GPU同等先进制程工艺,将消耗同等规模的先进制程产能。在以往市场对“算力需求-先进制程产能”的关系分析中,往往只关注了GPU本身的需求量对先进制程产能的带动,而忽视了switch芯片。超节点形态下,同等数量的GPU将叠加巨量的Scale-up switch芯片,促成先进制程需求的翻倍增长。意味着,超节点时代,先进制程的增长斜率将倍增!台积电与中芯国际等具备先进工艺能力的厂商,有望充分受益。
2、超节点Scale-up switch需求大增,交换机、交换芯片较Scale-out有近40倍的需求空间。以华为Atlas 950超节点(8192卡)为例,据相关公开资料,其使用了9000 颗LRS(低维交换芯片)与500 颗HRS(高维交换芯片),Scale-up交换机价值量占整个超节点价值量超过6%(东北电子团队测算)。
3、中国特色的超节点机会:以规模换性能,以能源换性能。由于工艺制程限制,国产芯片单卡算力将长期落后于海外芯片,而Scale-out下系统性能受到集群规模限制,一味增加集群卡数并不能实现系统性能的持续提升,即国产算力无法通过数倍于海外集群卡数的Scale-out集群达到接近海外集群的性能。但超节点打破了规模限制,能够实现“三个臭皮匠,顶个诸葛亮”的功效。中国超节点,通过以规模换性能,以能源换性能,可以通过更多的卡数和更高的能耗实现与海外超节点同等的算力。以华为和英伟达相关对标超节点产品做比较,在同等算力条件下,2025年,国产超节点卡数规模是海外超节点的3.2倍,而到2027年,该比值将提升至8.5倍;同等算力下,国产超节点的能耗是海外超节点的2~3倍。中国超节点各环节中,与量有关的环节,如GPU、交换芯片、先进制程等,将呈现比海外算力更高的增长潜能;与能源有关系的环节,如电源、液冷,将较海外算力有更陡峭的增长斜率。
4、国内超节点,未来几年将以柜内全铜、柜间全光的连接方案为主流。无论是华为昇腾超节点还是阿里磐久超节点,其未来一两代架构均采用柜内全铜、柜间全光的连接方案,我们认为是国内芯片工艺制程相对落后,对正交背板和CPO的诉求不强。在EUV光刻机突破前,国产超节点可能持续采用该方案。因此,在连接环节的选择上,我们认为:国内看铜,海外看光&PCB。
我们认为,超节点就是大模型的“光刻机”。从重要性看,大模型的训练和推理离不开高算力、高性能的超节点基础设施,正如先进制程离不开高性能光刻机。从价值量看,一台1980i DUV/低数值孔径EUV光刻机售价约1亿美金,而上万卡规模的超节点售价预计也将超过1亿美金。超节点将是中国算力突围的一次革命性机会,在国产算力拥有万卡规模等级的超节点后(如26H2,华为Atlas950),国产大模型将真正拥有了训练利器,有望极大提升国产大模型训练效率。我们看好在明年国产大模型与中国AI资本开支双双爆发,国产算力开启繁荣增长。
风险提示:晶圆厂扩产不及预期、国内AI资本开支不及预期

单卡时代落幕,全球主流算力竞逐超节点
大模型参数规模持续扩张,分布式训练成为必然选择。随着Transformer架构的广泛应用,模型参数量呈指数级增长,对算力、内存与通信带宽的需求迅速攀升。单颗GPU在计算与存储维度均已无法独立支撑超大规模模型训练,多GPU并行的分布式架构成为唯一可行路径。
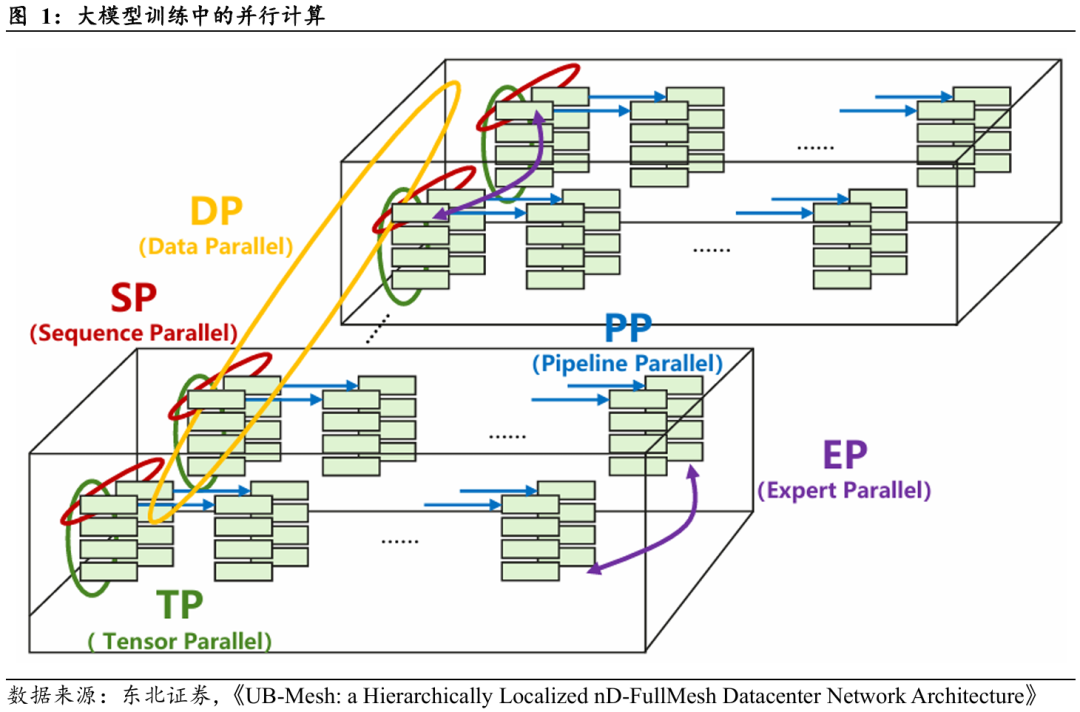
分布式训练对通信系统提出前所未有的挑战。与传统数据中心以请求响应为主的零散通信不同,大模型训练依托于特定的分布式训练算法(如数据并行、张量并行、流水线并行等),形成高强度、周期性且同步性极高的“集合通信”负载。这类通信在带宽与时延维度均处于极限状态,成为系统扩展性的关键瓶颈。为了协同数千乃至上万颗GPU,训练过程必须依赖几类对通信带宽和延迟极其敏感的运算:
Ø All-Reduce(全归约): 在数据并行中,所有GPU必须在每一步迭代后同步海量的梯度数据。对于万亿参数模型,一次All-Reduce的通信量可达TB级别,对通信带宽提出极致挑战。
Ø All-to-All(全交换): 在混合专家(MoE)和部分张量并行中,每个GPU需要向集群中所有其他GPU发送不同的数据(如Tokens或权重分片),形成高并发的全互联通信,极易造成网络瞬时拥塞。
Ø All-Gather / Reduce-Scatter(全收集/归约-分散):在ZeRO优化或张量并行中,GPU需频繁收集参数分片以重组完整权重(All-Gather),或在规约后再分散梯度(Reduce-Scatter)。此类操作高度依赖带宽效率,是模型训练主要通信负载。
Ø Point-to-Point(点对点): 在流水线并行中,各阶段(Stage)GPU需传递激活值。该操作对延迟极度敏感,任何微小时延均会造成“流水线气泡”,导致算力利用率显著下降。
传统Scale-out架构的结构性瓶颈:通信路径成为算力扩展的核心约束。大模型训练过程高频、海量的通信需求,使得集群在扩展至千卡乃至万卡级别时,传统的Scale-out架构(通过外部网络连接大量独立服务器)以CPU和PCIe总线为中心的通信路径成为性能的致命短板。
Ø 通信绕行导致延迟与带宽受限:传统的Scale-out架构以CPU和PCIe总线为中心,计算节点间需经由GPU—CPU—网卡(NIC)的多级路径完成数据传输。该“绕路式”通信不仅延迟高、带宽受限,更受制于CPU I/O与PCIe总线性能上限。
Ø 算力利用率显著下滑:当通信延迟成为主要瓶颈后,大量GPU需等待数据同步,导致有效算力被闲置。集群的实际算力利用率(MFU, Machine Fraction Utilization)显著低于理论峰值,训练效率随规模扩展反而下降。
Ø 能耗与系统复杂度急剧上升:随着集群规模放大,CPU数量、互联设备及能耗同步增加,通信与管理成本非线性上升,进一步削弱系统的整体经济性。
超节点Scale-up架构以高速互联重构算力体系。超节点是通过高速互联技术重构的新一代计算架构,为突破上述瓶颈,超节点通过高速互联技术对计算架构进行了系统性重构,其本质是将物理上分离的多个计算单元融合成一个逻辑上统一、性能极致的“超级计算节点”。其核心在于,通过NVLink、CXL等高速互联协议,将数十乃至数百个加速器(GPU/NPU)紧密耦合,构建一个高带宽(TB/s级)、低延迟(纳秒级)的直接通信域(Scale-up Domain)。
Ø 硬件层面: 该域内的GPU间通信(如 All-Reduce)得以绕过传统的CPU与PCIe总线,实现GPU-to-GPU的直接数据交换,从根本上消除了数据传输瓶颈。
Ø 软件层面: 超节点借助用户态集合通信库(如NCCL)直接调度硬件,绕过操作系统内核繁复的协议栈,进一步将通信开销降至最低。
如下图所示,图中底部标注为HBD(Scale-up)的部分代表纵向扩展架构。在该层级内,多个GPU与CPU通过专用的HB Switch(高速互联交换机)高密度互连,构建出一个高带宽、低延迟的紧耦合计算域。图中顶部标注为Scale-out的部分则对应横向扩展架构,多个HBD(Scale-up)单元通过Leaf(叶)交换机与Spine(主干)交换机组成的Fat-Tree或类似网络拓扑进行互联。
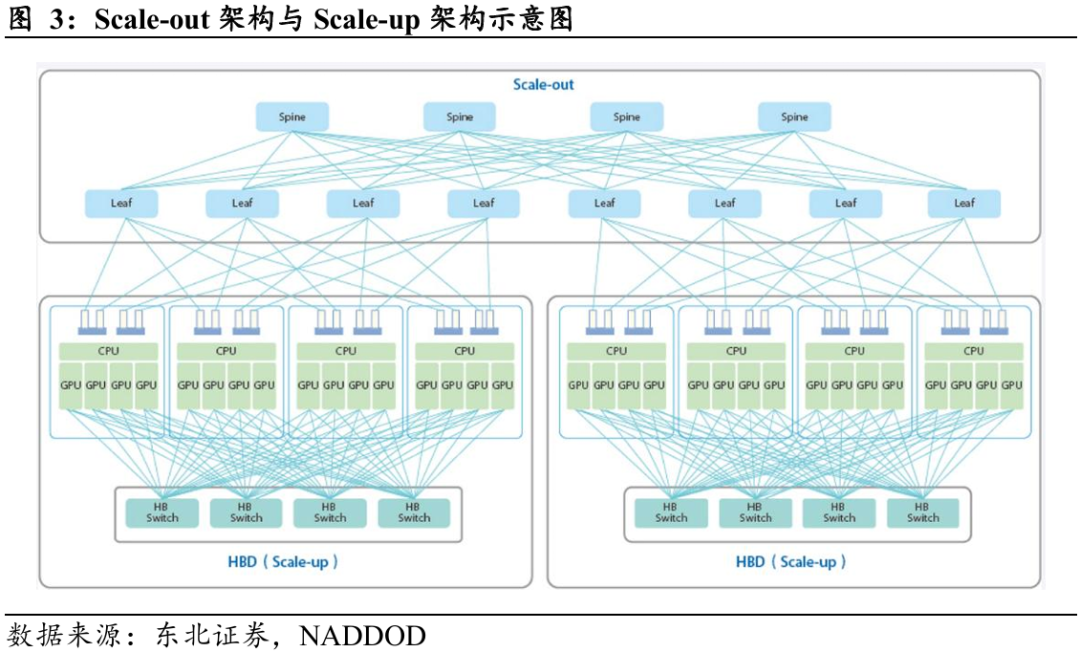
超节点核心价值在于突破“通信墙”、“功耗墙”与“软件墙”三大核心瓶颈。首先,它通过极致优化的内部互联技术,将GPU间通信延迟从微秒级降至纳秒级,彻底解决了因网络瓶颈导致的“通信墙”问题,确保了在张量并行等高频通信场景下的极致效率,将计算资源利用率推向新高。其次,面对“兆瓦级”的集群功耗,超节点通过原生集成液冷系统,解决了传统风冷散热的物理极限(“功耗墙”),在大幅提升PUE(能源使用效率)的同时,也为在有限空间内实现更高的算力部署密度铺平了道路。最后,超节点提供了一套统一、高效的软件栈,实现了对海量计算资源的池化管理、智能调度和秒级容错,攻克了管理运维上的“软件墙”难题,将物理上分散的硬件集群在逻辑层面视作一个整体。

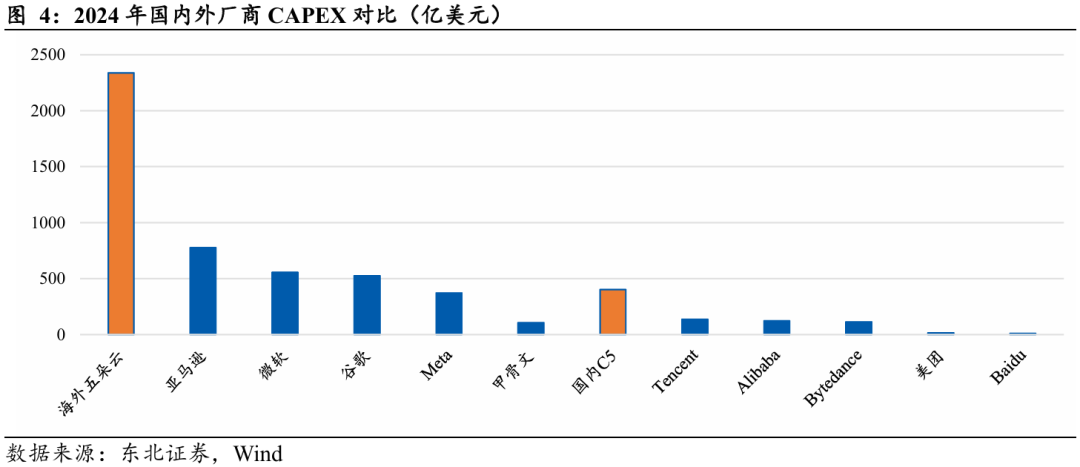
中国算力集群总规模远低于海外。根据中国信通院(CAICT)的数据,尽管中国算力总规模位居全球第二,但在支撑前沿大模型训练的高性能AIDC(AI数据中心)方面存在显著缺口。以2024年为例,海外五朵云资本开支约为国内C5资本开支6倍,侧面印证海外算力集群总规模远超国内水平。在训练算力不足的情况下,甚至出现了“算力飞地”现象,即在特定地缘政治和供应链约束下,并非通过物理运输GPU,而是通过租用美国本土云服务商的算力集群,建立起一块临时的“算力飞地”来完成模型迭代。
算力不足限制国内大模型演进速度与质量提升。一方面,算力集群规模不足直接延长了训练周期,显著削弱了模型迭代效率。例如,Meta在训练Llama 3.1 405B模型时动用了约1.6 万张H100 GPU的超大规模集群,训练周期控制在数周;若集群规模缩小至千卡级,训练时间将从“数周”拉长至“数月”,意味着模型在版本更新周期中将完全错失迭代窗口。另一方面,算力差距在多模态模型阶段进一步放大。国内在语言模型方面尚可追赶,但在图像、视频等多模态任务中,海外厂商已逐步实现从“可用”到“好用”再到“可生产”的进化,而国内仍处于模型性能和响应质量不稳定的早期阶段。
国产算力短板的根源不仅在于投资不足,更在于可获得的高性能算力资源有限。一方面,受制于地缘政治环境,国内机构难以采购先进的海外GPU,导致可用于大模型训练的算力受限。另一方面,国产加速卡在算力密度、能效比及互联能力上与海外存在显著差距,目前主要用于推理环节,而难以支撑大规模模型训练。在此背景下,国内算力投资成为了纯粹的成本项,进一步削弱了资本投入意愿。需要强调的是,大模型训练效率由集群算力决定,而集群算力并不能通过简单的堆卡获得提升。大模型训练更类似一场“带兵打仗”——在缺乏完善调度体系与高速互联支撑的情况下,即使“百万大兵”也可能因通信瓶颈和指挥失序而使整体算力利用率下降,反而可能不及“十万精兵”作战高效。
超节点的魔术:赋予国产算力堆卡取胜可能性。超节点架构的出现,实质上为算力组织方式带来了“体系化指挥”的革命,使得不同计算单元能够以更低通信延迟和更高带宽进行协同,从根本上提升集群有效算力。可以说,超节点赋予了“三个臭皮匠顶一个诸葛亮”的现实可能性——在架构与互联层面的创新,使得国内算力体系真正有可能不必完全依赖单卡性能提升,而是能够通过堆叠更多数量的卡,在集群有效算力上逼近甚至部分超过海外领先水平。
不止于理论,超节点已成为AI算力基础设施演进的核心方向。从产业层面观察,全球主要AI算力厂商(例如英伟达、华为、阿里与中科曙光等)均已推出超节点产品。超节点不再是单一厂商的技术尝试,而是AI基础设施体系向更高密度、更强互联形态演进的确定性趋势。
Ø 英伟达:当前以 Blackwell Ultra NVL72(2025H2)为核心代表,单机架配置 72 节点,在推理与训练性能上分别达到 1.1 EFLOPS@FP4 与 0.36 EFLOPS@FP8。系统配备 20 TB HBM 与 40 TB Fast Memory,互联采用 CX8 网络架构,总带宽高达 14.4 TB/s。中长期路线明确指向更大规模的 Rubin 系列,包括 NVL144(2026H2,3.6 EFLOPS@FP4) 与 NVL576(2027H2,15 EFLOPS@FP4),通过阶梯式产品矩阵覆盖从模型验证到超大规模训练的全场景需求。
Ø 华为:代表性产品为 Atlas 900 A3 SuperPoD(2025-04),系统规模 384 节点,综合算力 300 PFLOPS@BF16,总互联带宽 1,229 TB/s,总显存容量 49.2 TB。其后续路线图指向 Atlas 950(2026H2) 与 Atlas 960(2027H2),峰值性能预计分别达到 8 EFLOPS@FP8 与 30 EFLOPS@FP8,整体架构将支持从百级到千级乃至万级 GPU 的规模扩展。
Ø 阿里云:2025年9月发布磐久128超节点产品,系统互联带宽已达Pb/s级别,单机功耗约 350 kW。该架构在能效与密度间实现平衡,主要面向多模态大模型的高并发推理与持续训练场景。
Ø 中科曙光:2025年11月发布曙光ScaleX640超节点,单系统在FP16精度下算力超过 600 PFLOPS,访问带宽达 2.3 PB/s,内部互联总带宽超 570 TB/s,系统功耗约 860 kW。
超节点架构的核心在于实现GPU集群间高带宽、低延迟的数据互连,旨在突破传统PCIe总线及以太网(Ethernet)的通信瓶颈,最大化AI集群的有效算力(Effective Compute Power)与训练吞吐量。在技术方案上,行业正呈现多元化的实现路径,下面我们将对主流超节点产品的技术特征与组网方式进行详细拆解:
1)英伟达
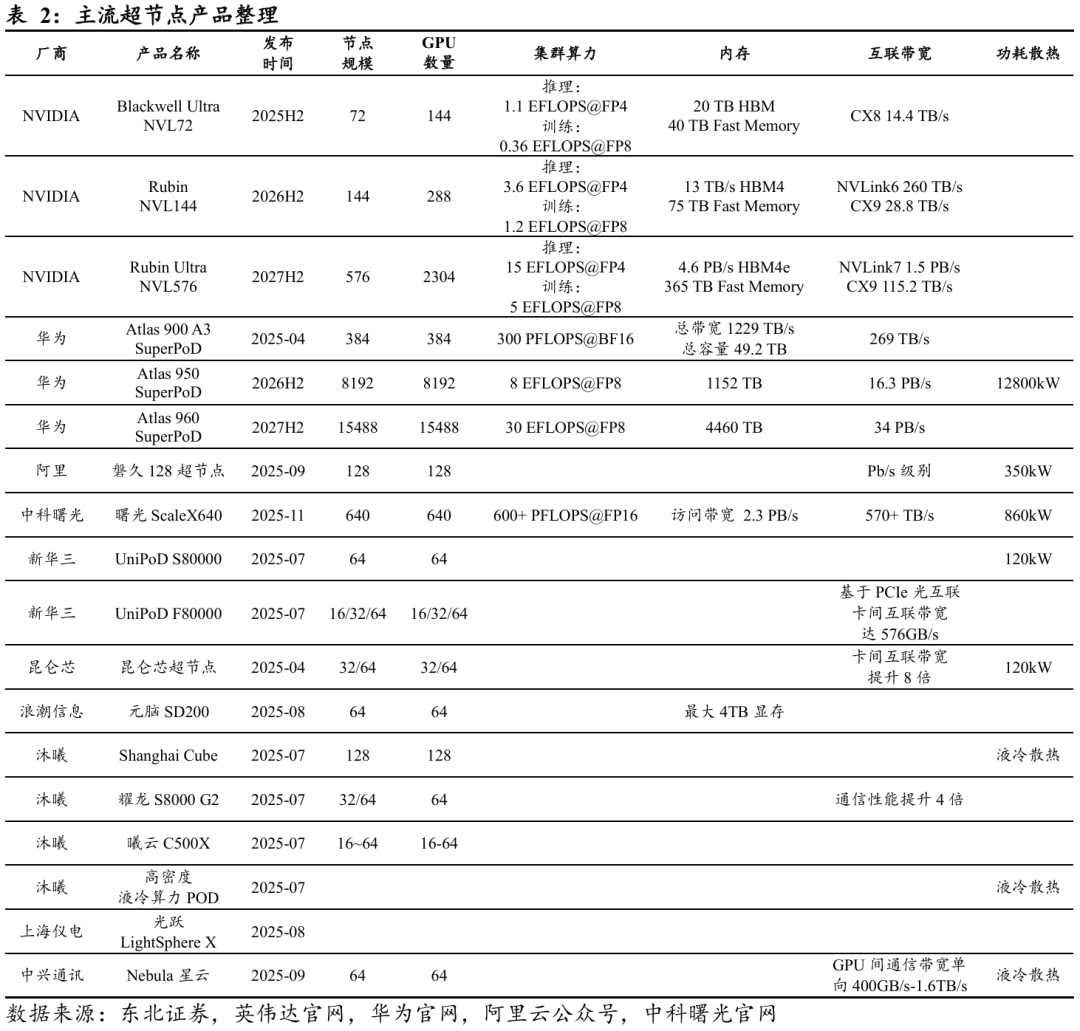
英伟达早期推出了A100 SuperPoD与H100 SuperPoD产品。A100 SuperPoD是基于Ampere架构的GPU集群,可提供数百到上千块A100 GPU,通过自研的NVSwitch高速互联技术实现全互联带宽,单节点GPU之间的通信延迟极低,适合大规模模型训练。H100 SuperPoD则基于Hopper架构,单卡算力大幅提升,同时支持更高带宽的NVLink与PCIe Gen5互联。
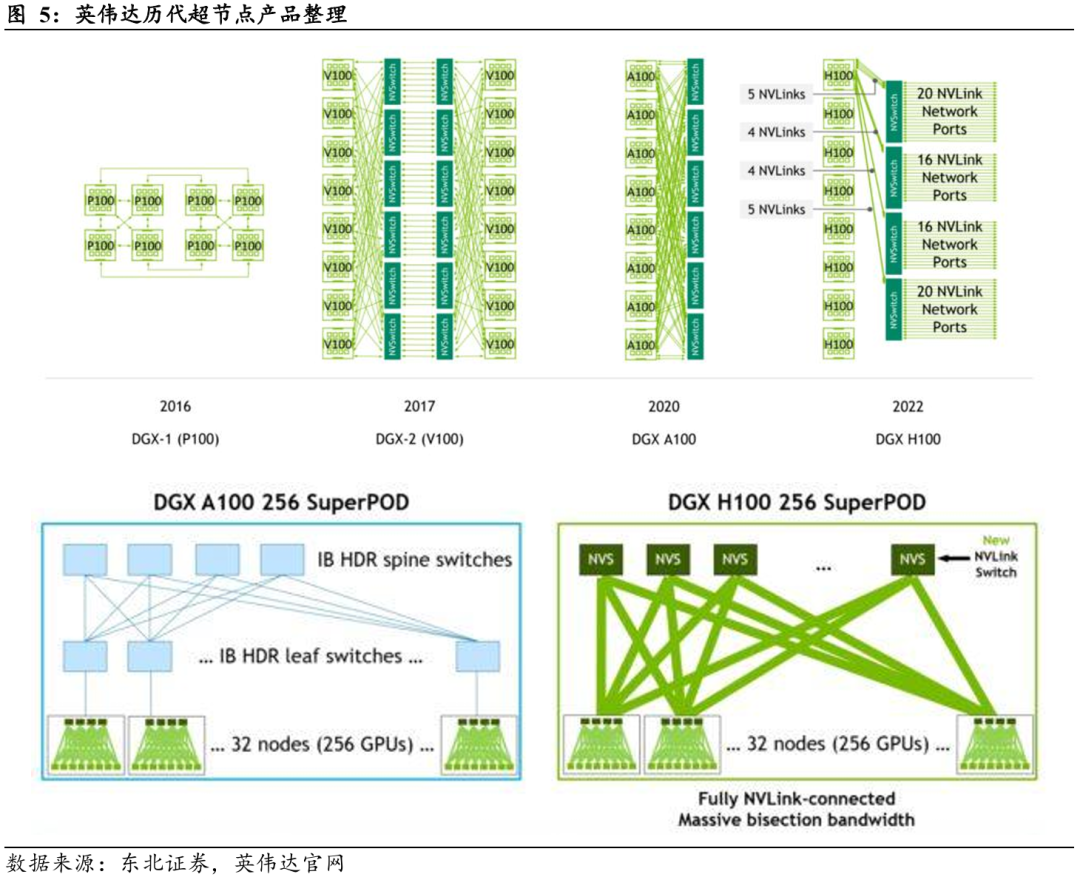
英伟达NVL72超节点在单个超级芯片GB200内实现CPU与GPU的紧耦合互联,每个模块由1颗NVIDIA Grace CPU与2颗B200 Blackwell GPU构成,CPU与GPU之间通过高带宽NVLink-C2C(Chip-to-Chip)技术直连。单机架系统整合18个GB200 Superchip模块,共计36颗Grace CPU与72颗B200 GPU,所有GPU通过9个NVLink Switch芯片高密度互联,被抽象为一个逻辑统一的高性能计算单元。
2)华为
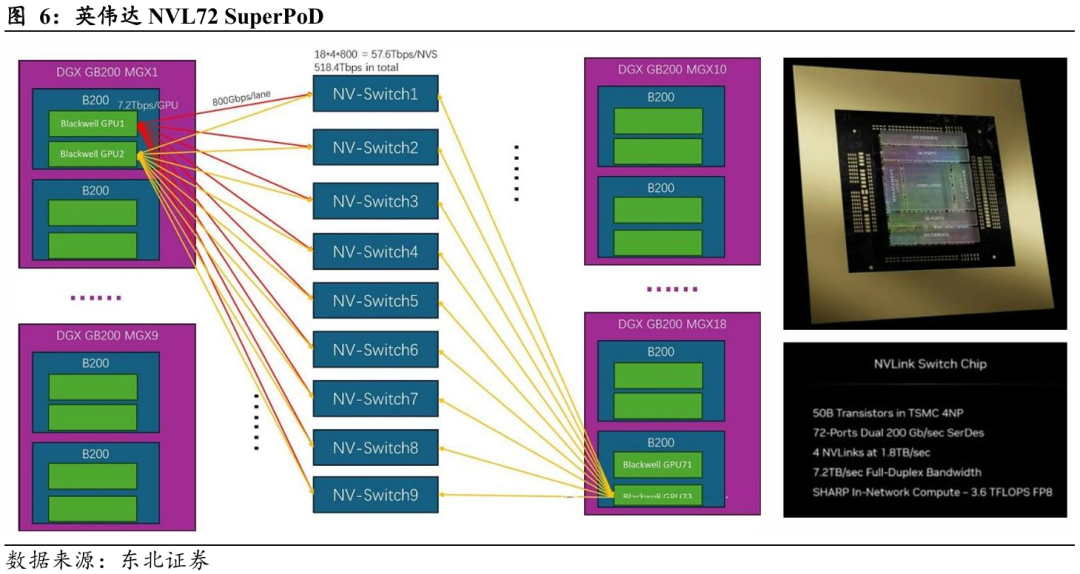
华为在超节点领域的布局以其自研昇腾系列AI处理器为核心,打造了高度集成、全自研互联架构的系统方案。此外,从Atlas 950 SuperPoD开始,华为配套了完整的昇腾CANN算子库与MindSpore框架生态,实现了从芯片到集群的端到端国产化与全栈优化。
华为超节点组网方式如下图所示,采用分层、全互联的组网设计,具备极高的可扩展性与计算效率。在单个板卡层面,华为通过8个NPU的全互联实现板内高带宽低延迟通信——每个NPU与同一板卡上其余7个NPU直接连接,形成一个完整的全互联拓扑结构。机柜(Rack)层面,一个机柜内配置8块NPU板卡,每个NPU与其他七块板卡中相同位置的NPU互联,实现板间的水平扩展和计算协同。此外,系统内还配备4个LRS模块,用于连接备用NPU、主要NPU与CPU节点,构建起高可靠、可冗余的通信网络。
3)阿里云
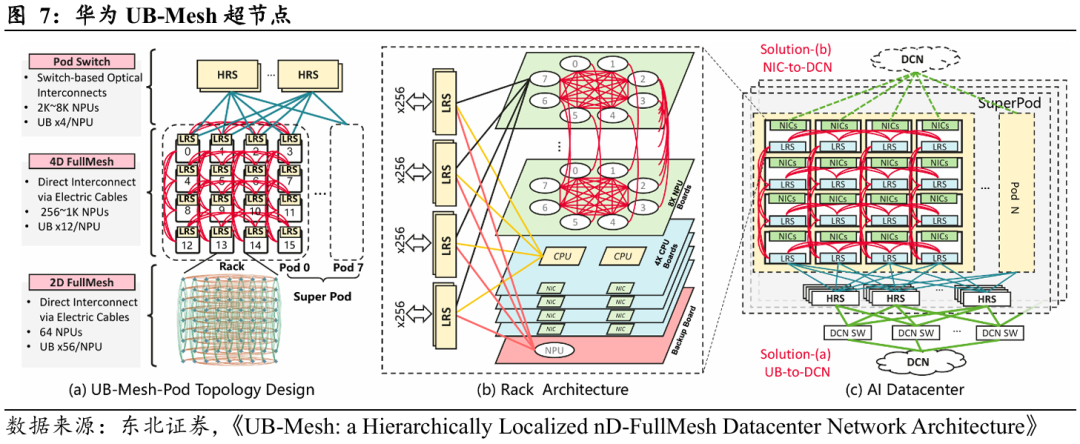
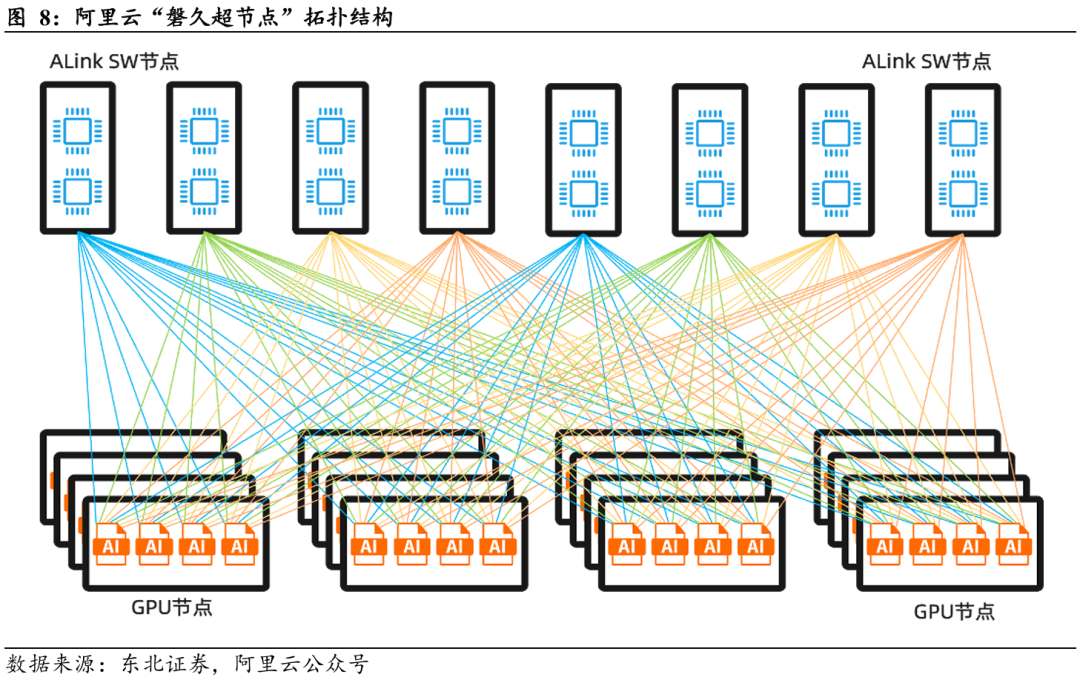
阿里云“磐久超节点”是面向AI大模型训练与推理的高性能计算架构。该架构的基石是其自研的非以太Alink互连协议,SerDes速率高达224Gbps,在单柜128颗GPU(采用正交互连)内实现了PB/s级的Scale-up带宽和百纳秒级延迟。
“磐久超节点”的具体组网方式如下所示:在组网架构上采用高密度Scale-up互连域,每个超节点包含16至17个GPU节点(每个GPU节点内置4颗GPU芯片),背端配备8个Alink SW节点,Alink SW节点内置多颗Alink Switch芯片,在单级交换拓扑下实现Scale-up域内的全带宽、全互连。具体拓扑上,以64端口Alink Switch为例,每个SW节点内置1至2颗Alink Switch芯片,16个GPU节点上的64颗GPU芯片通过正交连接器实现端口映射:每颗GPU的Scale-up port0/8直连Alink SW0节点的Switch芯片,port1/9直连Alink SW1节点,以此类推,确保GPU与交换节点间的低延迟、高带宽互联。对于两组64卡以上的超节点互连域,还可通过支持128端口的Alink Switch芯片实现交叉扩展。
“磐久超节点”还针对三大工程挑战提出了解决方案:
1)供电层面,采用 /-400V高压直流(HVDC)集中供电以支持超650kW的整柜峰值功耗,并通过垂直供电技术实现了>10,000A/μs的超高瞬态响应(di/dt),将PDN(供电网络)损耗降低70%;
2)散热层面,为应对3kW 的单芯片功耗,系统采用了导热系数>100W/mK的液态金属电磁冷板,超越传统液冷方案,支撑350kW的整柜散热需求(PUE 1.09);
3)高速互连层面,通过HDi-AEC(有源电缆)技术实现了2米以上的224G铜缆互连,并利用“高性能NCC 低成本PCB”3D混合堆叠架构优化了70%的封装成本。
4)中科曙光(海光)
中科曙光的曙光ScaleX640超节点,是全球首个单机柜集成640张加速卡的超高密度计算平台。该系统采用创新的“一拖二”高密架构设计,在单柜内实现超高速总线互联,总算力超过600 PFlops、访存带宽达2.3 PB/s、卡间互连带宽超过570 TB/s,可支撑万亿参数大模型的训练与推理需求,并可通过双机柜扩展至千卡乃至十万卡级集群。在能效方面,ScaleX640采用浸没相变液冷与高压直流供电方案,PUE低于1.04,算力密度提升20倍的同时能耗显著下降,训练MoE大模型性能较传统方案提升30%–40%。系统在开放性上支持多品牌加速卡及主流AI生态,兼容超过400款大模型应用,打破算力平台封闭格局。此外,ScaleX640通过超过30天的稳定性测试,具备100余项RAS设计,确保大规模集群的高可靠性。

超节点时代,GPU将从主角变为配角。在传统AI集群中,GPU厂商主导架构设计与通信协议,算力体系高度依赖单一厂商生态;而在超节点架构下,网络互联、同步效率与系统调度成为性能瓶颈的决定性因素。由此,主导权正从上游GPU厂商向下游超大规模客户转移。当前主流超节点互联协议中,除英伟达的NVLINK和华为的UB协议仍为私有封闭标准外,其他均转向由国内外互联网与运营商主导的开放标准:如腾讯牵头的ETH-X、中国移动牵头的OISA,以及阿里牵头的ALS协议,均由下游客户发起,GPU厂商(如AMD、Intel)多以“参加单位”形式参与。这一趋势表明,未来算力生态的核心竞争力将不再由GPU单体性能决定,而在于对不同超节点系统的互联适配能力与软件生态兼容性。
同等数量GPU,超节点使得先进制程需求翻倍
超节点架构显著提升了交换机芯片消耗量。为满足AI大模型训练对极致通信效率的严苛要求,智算中心网络架构正从传统的Spine-Leaf演进至超节点Scale-up形态,这一转变将从根本上重塑AI集群的价值构成。在同等数量GPU(网络处理器)规模下,超节点架构对交换机芯片的消耗量实现了数量级的增长。
下面我们将以华为Atlas 950 SuperPoD为例对比超节点架构与传统架构在交换机用量上的差异。
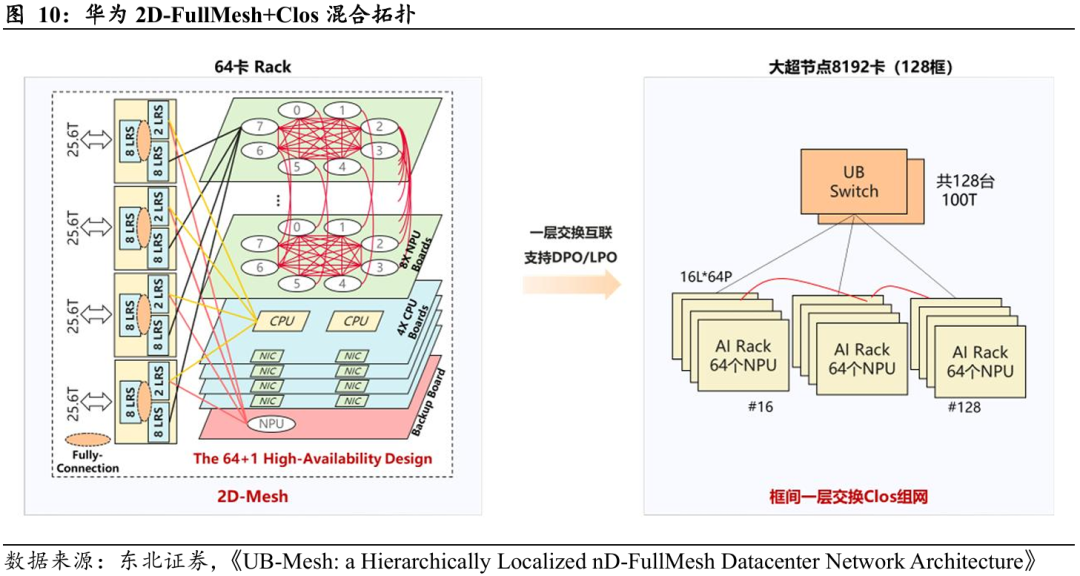
华为Atlas 950 SuperPoD超节点架构:交换机在计算单元内部实现高密度部署,扩展至8192个NPU的完整集群时,该架构共需要9216颗LRS芯片及648颗HRS芯片,总计9864颗交换芯片。详细结构如下所述:
Ø 机柜内部高密度部署使交换芯片数量超过计算单元数量。在Atlas 950 SuperPoD超节点架构中,典型64 NPU机柜内部采用2D-FullMesh全网状拓扑。每个机柜配备4台“灵衢”交换机柜,每台含18颗LRS芯片,单机柜共72颗LRS芯片,部署比例达到1.125:1(72/64),超过计算单元数量。此设计确保机柜内部点对点通信的高带宽与低延迟要求,但也显著增加机柜内交换芯片消耗。
Ø 跨机柜高速互连构建大规模集群进一步放大交换机需求。高密度2D-FullMesh组网构建了强大的单个计算节点(Rack),随后通过高速光互连将多个(如此例中的128个)这样的超节点机柜连接成一个大规模集群(Scale-out)。在一个包含8192个NPU的超大规模集群中,外部连接依赖于一个由128台100T UB(Unified Bus)交换机构成的Clos网络。
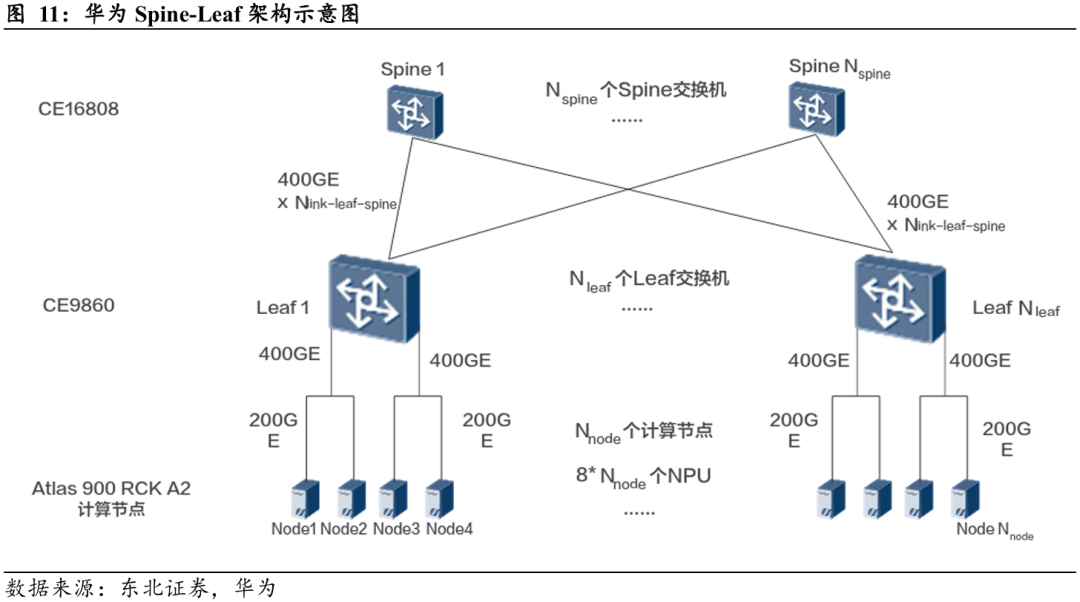
传统Spine-Leaf架构:交换机作为外部连接设备,扩展至8192个NPU的完整集群时,需部署256台Leaf层交换机与16台Spine层交换机,总计272台交换设备。详细结构如下所述:
Ø 以采用经典两层CLOS网络拓扑的非超节点数据中心为例,其网络部分通常由Leaf层交换机(如华为CE9860,与LRS性能接近)和Spine层交换机(如华为CE16808,与HRS性能接近)构成。
Ø 若同样部署8192个NPU(以1024个计算节点,每节点8 NPU计),该规模集群需部署256台Leaf层交换机与16台Spine层交换机,总计272台交换设备。
架构演进驱动交换机用量实现约36倍的增长。超节点架构在各机柜内部署了合计9216颗LRS芯片,而传统Spine-Leaf架构仅需256台功能相近的Leaf层交换机,用量增长为36倍。在负责全局互联的核心层,超节点架构部署了648颗HRS芯片,相较于传统架构的16台Spine层交换机,用量增幅更是高达40.5倍。

交换机芯片正逐步成为先进制程产能消耗的关键增量。以往在AI集群的产能测算中,市场关注焦点多集中于GPU晶圆占用,而交换芯片的贡献常被低估。随着数据中心架构由传统Scale-out向高密度的Scale-up方向演进,GPU与交换芯片之间的带宽能力日趋对称。由于芯片性能与Die面积在高带宽设计中高度相关,这种带宽层面的对称性,实质上也意味着在集群层面,交换机芯片的面积占比正逐步逼近GPU的IO Die。在更高层级的互联架构中(如HRS交换芯片),其面积占用(LRS HRS)甚至可能进一步超越GPU,从而使交换机芯片在先进制程产能结构中的权重持续提升。
下面将基于晶圆切割效率与良率的综合测算各类芯片的先进制程产能需求:以华为Ascend 950系列及配套LRS/HRS交换芯片为例,首先通过芯片面积(Die size)与良率推算单片晶圆的有效出片量,再结合系统配置比例反算先进制程产能需求。
首先测算各类芯片的KGD(已知合格芯片):
Ø Ascend 950的核心NPU Die面积约390mm²,良率约35%,每片晶圆可产出约26颗完整芯片;
Ø LRS(低速交换芯片)Die面积约130mm²,良率约70%,单片晶圆可产出约168颗;
Ø HRS(高速交换芯片)Die面积更大,导致良率低至约30%,单片晶圆仅能产出约9颗良品;
Ø CPU Die面积约252mm²,良率58%,每片晶圆约可产出69颗。
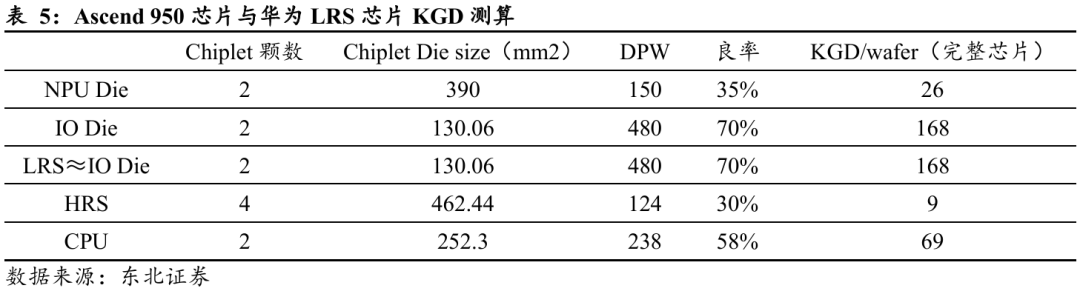
在超节点应用情景中,以1000套8192卡集群为例。根据前述单片出片量及良率测算,三类芯片对先进制程产能的需求分别达到:NPU约2.63万片/月,LRS约0.86万片/月,HRS约0.6万片/月。两类交换芯片合计(LRS HRS)消耗约1.46万片/月,接近NPU产能需求的六成水平。
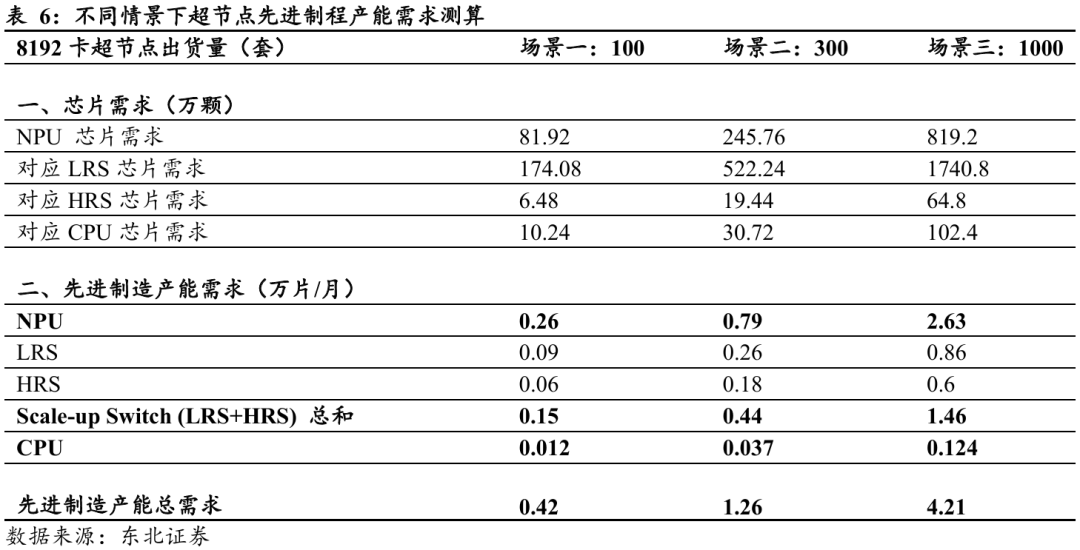
上述以华为方案为例,2025年11月中科曙光发布了曙光ScaleX640超节点产品,该方案尽管在组网架构上与华为存在差异,但同样使用了大量交换机芯片。下面将详细介绍曙光ScaleX640的组网方式:
曙光ScaleX640实现了单机柜640卡超高速总线互连。ScaleX640采用左右对称的全浸没式相变液冷设计。每个机柜由四层刀片组成,每层包含10个刀片,共计40个刀片。每个刀片正反面对称布置,每一面集成2颗CPU与8颗GPU芯片,合计16颗GPU芯片。以此计算,单柜共配置16×40 = 640颗GPU,两柜合计1280颗GPU,单柜算力可达约600 PetaFLOPS。通过相变液冷与表贴封装的结合,系统在高功率密度下仍可维持稳定散热与紧凑堆叠,实现了算力与能效的同步提升。

曙光方案同样依赖大量交换芯片以支撑全互联架构。ScaleX640采用典型的“节点内全互联 机柜间高带宽互联”网络设计。在节点层面,我们推测每8卡节点配置11颗交换芯片与机柜外部网络连接;在机柜层面,节点间互联由约60颗高带宽Scale-up Switch承担。综合测算,系统共部署约11/8×640 = 880颗节点内交换芯片及60颗节点间交换芯片,与传统Spine-Leaf架构相比,交换芯片的使用量同样大幅提升。
大规模互联需求推动交换芯片向更高带宽与更大面积演进。曙光、华为的超节点方案,为了支撑超节点内部数千GPU间的通信需求,大量采用大Die、高通道数的交换芯片。根据行业设计参数惯例,基于PCIe 5.0、32G SerDes的早期Switch芯片面积约100 mm²;300 lane的Scale-up Switch面积约200 mm²以上;而采用112G SerDes、300 lane的巨型交换芯片单Die面积可达约800 mm²。由此可见,在超节点架构中,交换芯片的面积、制程复杂度与GPU趋于同量级,其在先进制程产能中的权重正显著提升。
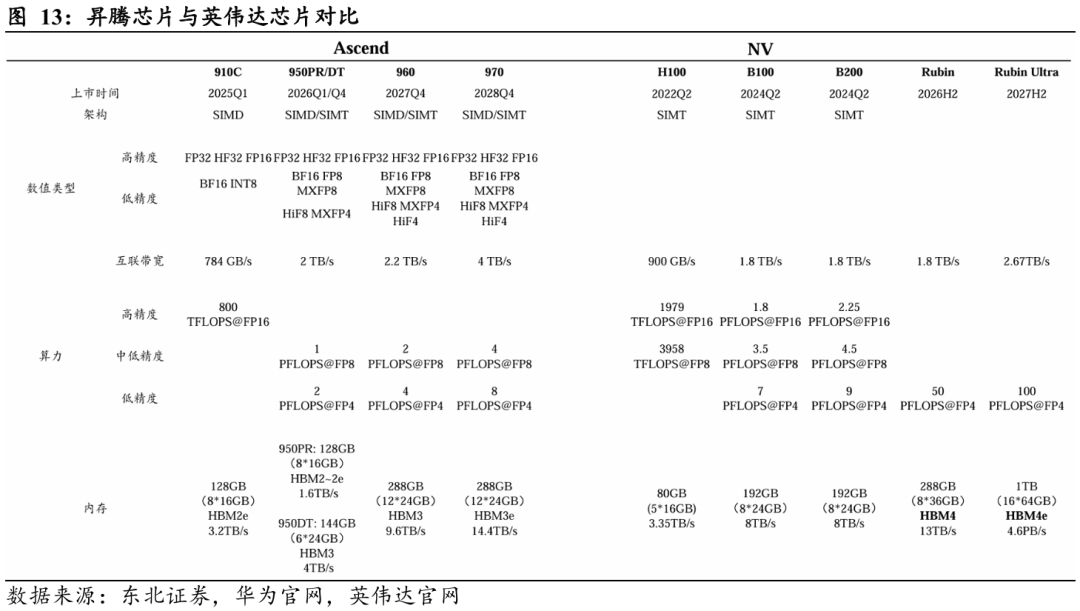
先进制程受限,国产芯片与海外芯片差距短期难以追平。以华为昇腾(Ascend)系列与英伟达(NVIDIA)对比为例:
Ø 昇腾910C vs 英伟达H100: 910C 与 H100 在互联带宽方面基本可比(784 GB/s vs 900 GB/s),但在算力维度差距明显:910C 的 FP16 算力为 800 TFLOPS,仅为 H100(1979 TFLOPS@FP16)的约 40%。内存容量上两者接近(128GB vs 80GB),但910C采用了更多 HBM 芯片以获得更高带宽(3.2TB/s vs 3.35TB/s)。整体而言,910C在系统互联与内存设计上具备对标能力,但在核心算力和能效比上仍处于明显劣势。
Ø 昇腾950/960/970 vs 英伟达B100/B200: 950 系列的互联带宽(约2TB/s)超过 B100/B200,但算力仅为后者的约1/4,内存容量和带宽也更低。960通过使用更多HBM堆叠在内存指标上超过B200系列,但在算力端仍显不足(2 PFLOPS@FP8 vs 4.5 PFLOPS@FP8);而970的算力(4 PFLOPS@FP8)才逐步接近 B200。考虑时间轴,910C于2025年上市,而B200在2024年已量产,后续970需至2028年才能部分追平,显示出代际迭代的时间差正在拉大。
Ø 英伟达Rubin系列(2026H2–2027H2):其算力(50–100 PFLOPS@FP4)已远超出昇腾芯片可比范围。
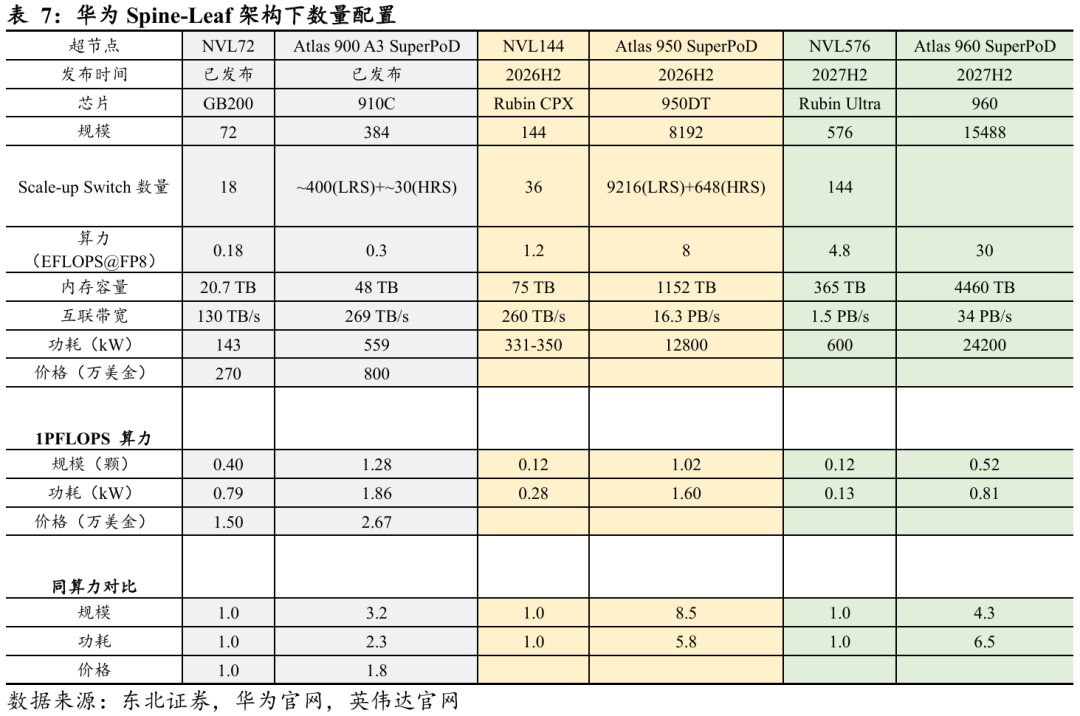
国产单卡性能不足,以规模、功耗为代价获得更高集群性能。以NVL72与Atlas 900 SuperPoD Cloud Matrix 384为例:
Ø NVL72:基于GB200芯片构建,整机算力达到180 PFLOPS@FP8,采用72颗GPU,总互联带宽130 TB/s,整机功耗约143 kW;
Ø Atlas 900 SuperPoD Cloud Matrix 384:基于华为910C芯片构建,总算力300 PFLOPS,共集成392颗NPU,互联带宽269 TB/s,整机功耗约559 kW。
若按同等算力规模进行换算,华为在达到英伟达相同算力时需使用约3.2倍的算力芯片数量,系统功耗约为英伟达的2.3倍。
随着时间推移,单位算力加速卡数量与功耗的差距还在不断拉大。以2026H2发布的NVL144与Atlas 950 SuperPoD为例:
Ø NVL144:基于Rubin芯片构建,整机算力达到1.2 EFLOPS@FP8,采用144颗GPU,总互联带宽260 TB/s,整机功耗约331~350 kW;
Ø Atlas 950 SuperPoD:基于华为950DT芯片构建,总算力8 EFLOPS,共集成8192颗NPU,互联带宽16.3 PB/s,整机功耗约12,800 kW。
若按同等算力规模进行换算,华为在达到英伟达相同算力时需使用约8.5倍的算力芯片,系统功耗约为英伟达的5.8倍。
国产算力进入大资本开支时代,
超节点就是大模型的“光刻机”
本节将系统测算超节点及其各细分环节的市场空间。首先,对未来数年互联网行业资本开支进行预测;随后,推算超节点出货量;最后,基于各细分环节的价值量评估市场规模及弹性,形成完整的市场空间测算框架。
超节点已成为大模型时代的“光刻机”,是整个AI产业迭代的核心驱动器。正如光刻机在半导体制造中决定先进制程能否实现,超节点决定了大模型训练的规模、速度与效率。
从价值量来看,超节点与光刻机在同一量级。华为Atlas 950 SuperPod每套投资约1.2亿美元,Atlas 960 SuperPod高达3.1亿美元,其单机柜的高密度GPU部署和系统级互联,使其成为数千卡GPU级训练任务的必备基础设施。与之类比,ASML EUV NXE:3600D单台价格在1.2~1.7亿美元,高端High-NA EUV EXE:5000/5200B甚至可达3.4~3.8亿美元,显示出超节点在成本与战略价值上的可比性。
从资本开支规划来看,超节点已占据举足轻重的地位。以2025年为例,字节跳动在AI及数据中心建设的投入预计达到222亿美元,台积电全年资本开支约400亿美元,凸显了超节点在推动大模型迭代与训练规模扩张中的核心作用。
大模型驱动北美五朵云资本开支扩张周期。自2023年以来,北美五朵云(AWS、Azure、Google Cloud、Meta、Apple)进入了新一轮资本开支扩张周期。AI大模型训练与推理需求的爆发,使云厂商的算力与基础设施投资显著加速。2023年五朵云合计资本开支达到约1,498亿美元,同比虽持平,但2024年迅速上升至2,337亿美元,同比增长超过50%,资本开支强度(CAPEX/Revenue)亦从12%跃升至16%,2025年上半年进一步攀升至23%,创历史新高。
从利润视角看,AI时代的资本开支占比亦显著提升。2023年CAPEX/Profit为63%,2024年提升至72%,2025年上半年更达到约91%,反映出厂商在利润释放与再投资之间的平衡明显向后者倾斜。相较2010年代初期资本开支仅占利润两成出头,如今的投资力度已提升三至四倍。整体来看,AI基础设施正成为北美云巨头的核心竞争力支点,GPU集群、专用AI加速器、CXL架构服务器、光互联网络与自建数据中心均为主要投入方向。
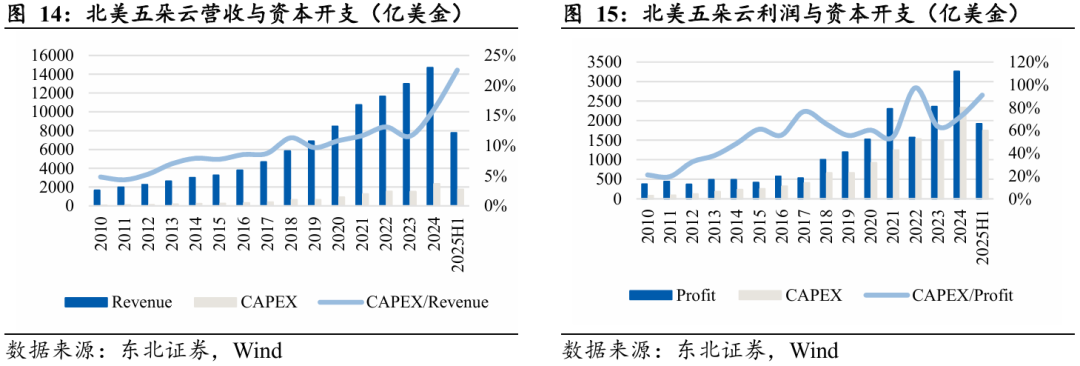
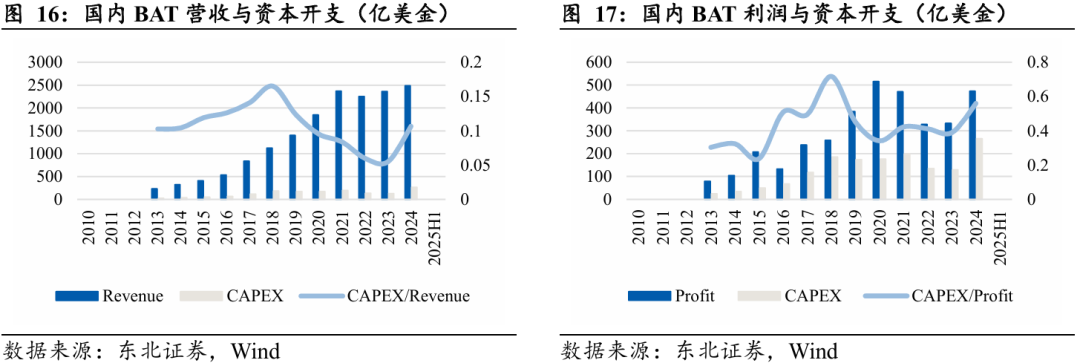
国内云厂商资本开支强度整体仍处较低水平。过去十年,中国云厂商的资本开支保持稳步增长,但与北美五朵云的高强度扩张相比,仍存在显著差距。2013年至2024年,国内云厂商合计资本开支由24亿美元提升至265亿美元,十一年增长逾十倍;然而CAPEX/Revenue整体维持在约10%的区间,明显低于北美的16%至23%。从利润角度来看,2024年CAPEX/Profit约为56%,而北美主要云厂商普遍处于70%至90%的区间。
2023年国内云厂商资本开支进入加速通道。2023年开始,AI训练与推理需求逐步放量,驱动国内云厂商进入新一轮资本开支上行周期。BAT(百度、阿里、腾讯)等头部企业的算力基础设施投资显著提速,资本开支强度连续两年提升:CAPEX/Revenue由2023年的约5%升至2024年的11%,CAPEX/Profit则从39%提升至56%。公开资料显示,这一趋势在2025年仍将延续,例如腾讯的CAPEX/Profit预计将从49%进一步上升至56%。
下面我们将聚焦头部科技企业的资本开支结构演变,分析AI相关投入的增长路径:
假设1:核心企业资本开支预测
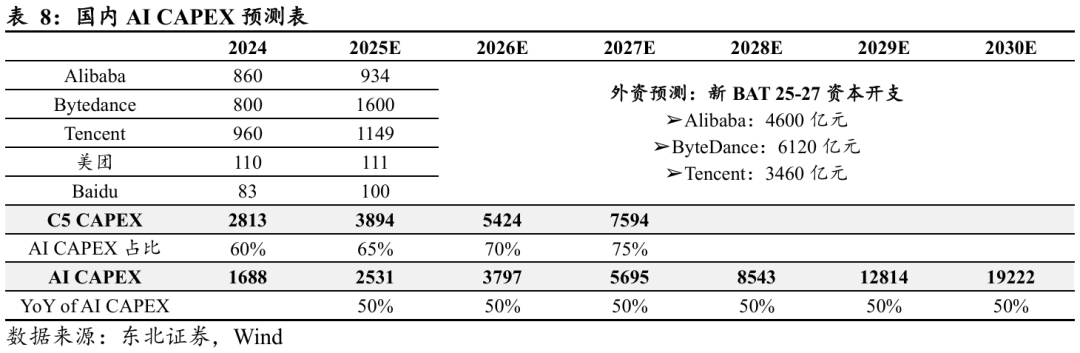
Ø 头部企业CAPEX规模: 预计2025年国内核心五家科技巨头(C5,包括阿里巴巴、字节跳动、腾讯、美团及百度)的年度资本开支总额将达到约3894亿元人民币。其中,阿里巴巴、字节跳动和腾讯分别对应934亿元、1600亿元和1149亿元。
Ø 外资机构长期预测: 据外资研究机构测算,新一代BAT在2025年至2027年期间的三年累计资本开支将达到约1.42万亿元人民币。其中,字节跳动(6120亿元)居首,体现其在AI算力方面的积极投入;阿里巴巴(4600亿元)紧随其后,持续加码云计算与AI基础设施;腾讯(3460亿元)维持稳健增长,投资重点或聚焦于大模型与内容生态的融合。
假设2:国内AI CAPEX占比与长期增速
Ø AI CAPEX占比提升:预计C5整体资本开支中用于AI领域的比例将持续上升。2025年AI相关投资占比预计为65%,并将于2026年、2027年分别提升至70%与75%。
Ø AI CAPEX长期增长:假设AI大模型与垂直应用需求维持高弹性增长,2028-2030年间AI CAPEX将进入约50%的年均复合增长阶段。
测算结果:国内AI资本开支将在未来5年呈现持续高速增长趋势
Ø 中期(2025—2027年):随着头部企业AI投入占比持续上升,国内AI资本开支(CAPEX)将呈现加速增长。预计2025年约为2531亿元(3894亿元 × 65%),2026年约为3797亿元(5424亿元 × 70%),2027年约为5695亿元(7594亿元 × 75%)。
Ø 长期(2028—2030年):预计AI CAPEX将持续高速增长,2028年约为8543亿元,2030年预计突破1.92万亿元。
上述未来国内AI算力资本开支预测具有充分合理性。AI大模型训练对算力存在刚性需求,有算力才能支撑更高性能模型的训练;国产算力单位成本高于海外,且海外算力采购受政策、供应链及地缘政治约束,国内资本投入成为必要选择;中美在AI领域的竞争持续推进,中国有动力确保在算力基础设施上不落后,从而形成长期高增长的资本开支逻辑支撑。从投资绝对值来看,2024年中国C5类算力资本开支仅达到北美2015年水平,即便在连续高增长假设下,2030年预计投入1.92万亿元人民币,也仅相当于北美2025年的水平。
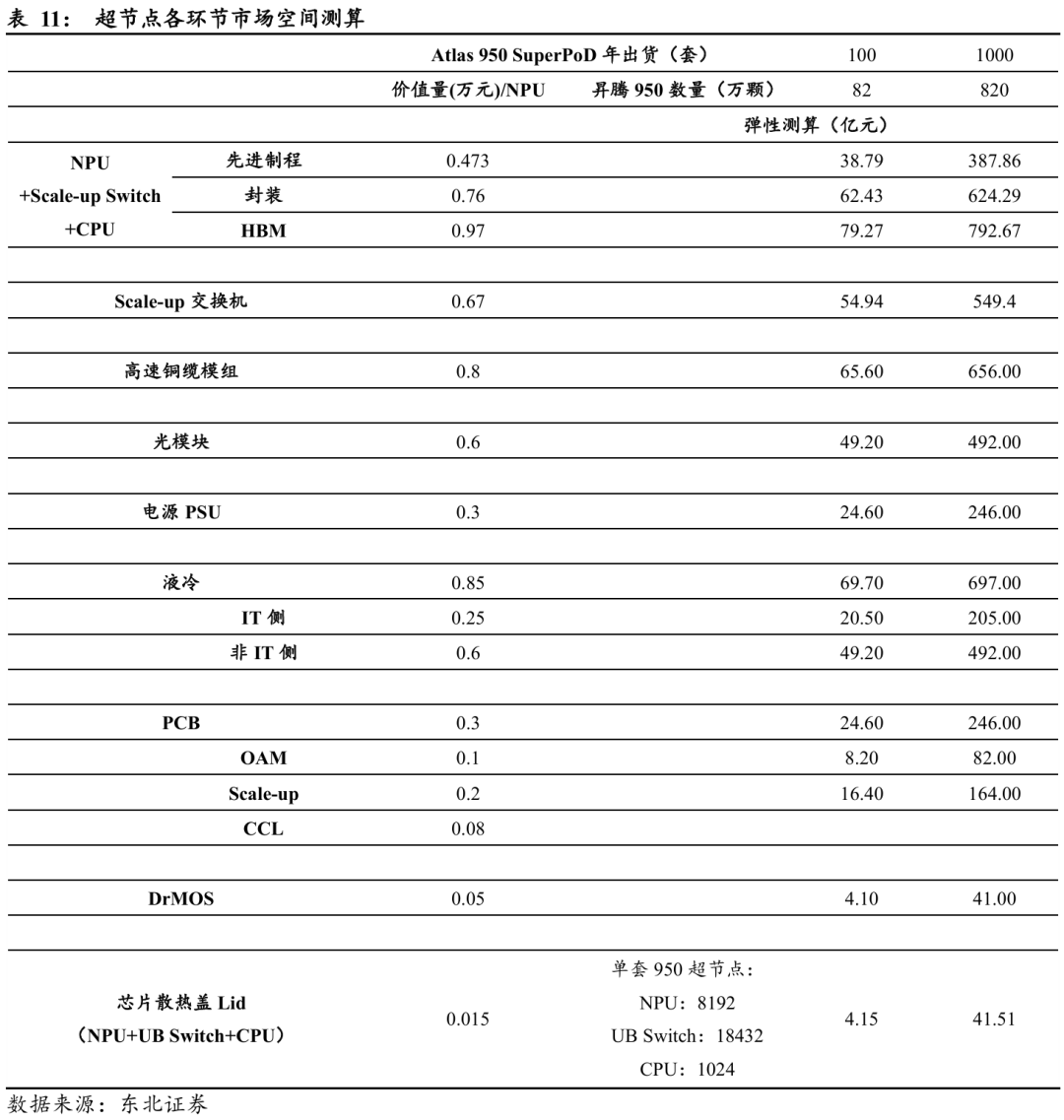
下面将通过对超节点架构中各类交换芯片、互联组件及关键硬件的部署量进行量化分析,结合各环节单价/成本,推算其对应的价值贡献,从而形成完整的细分环节市场规模测算框架。
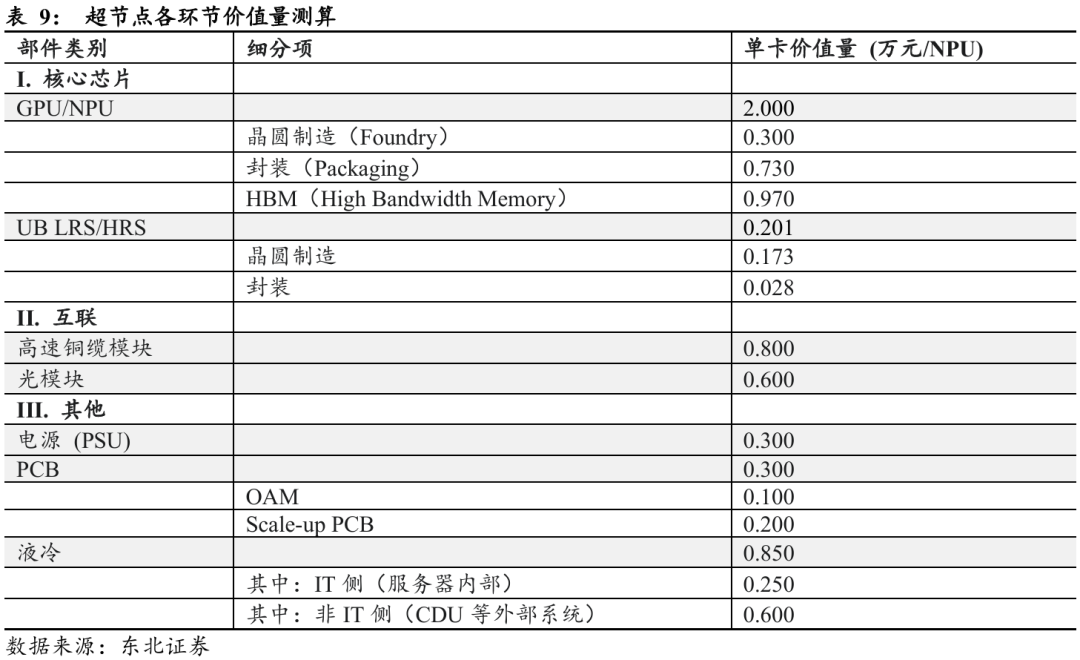
Ø GPU:假设GPU核心Die面积为390mm²,每片晶圆可切割约145颗,良率约35%,考虑单芯片含2颗核心Die,则每片晶圆可产出约25颗GPU核心;同时,IO Die面积约130mm²,每片晶圆可切割约450颗,良率70%,每芯片同样包含2颗IO Die,每片晶圆可产出约150颗。由此推算,每个7nm GPU芯片分别消耗约0.04片核心Die晶圆与0.007片IO Die晶圆,合计约0.047片晶圆。若按7nm制程晶圆成本9000美元/片折算,则单颗GPU对应的晶圆制造成本约为0.3万元人民币。
Ø LRS/HRS:根据前文测算平均每个GPU对应约2.25颗UB Switch芯片。假设交换芯片同样采用7nm制程,Die面积为300mm²,每片晶圆可切割约200颗,良率约50%,则每片晶圆可产出约100颗UB Switch芯片。由此推算,每个GPU约消耗0.0225片晶圆,折算晶圆成本约为0.173万元人民币/卡。
Ø 光模块:以Atlas 950 SuperPoD为例,该系统采用2层DFM Clos组网结构,8192张AI加速卡对应128台100T级交换机,需配备约3.2万个400G光模块。假设400G光模块平均售价(ASP)为0.15万元/个,则整体光模块价值约4,800万元,对应单卡价值约0.6万元/NPU。
Ø 电源(PSU):以Atlas 950 SuperPoD为例,整机功耗超过12.8MW。若按1元/W估算电源系统成本,并考虑数据中心高可靠性要求的双倍冗余配置,整体电源系统价值约2,500万元。折算到每张AI卡,对应电源单卡价值约0.3万元/NPU。
Ø 液冷系统:以Atlas 950 SuperPoD为例,整机功率12.8MW以上。按照液冷系统平均成本0.56万元/kW测算,总投资约7,000万元。其中,IT侧(冷板、机内管路等)约占0.16万元/kW,非IT侧(CDU、冷却塔、泵站等)约占0.4万元/kW。折算后,单卡液冷系统价值约0.85万元/NPU。
Ø PCB:参考NVIDIA B100设计,OAM载板成本约0.1万元/卡,而Scale-up架构下,由于GPU与交换芯片的高速互联需求,系统PCB(含背板)价值约0.2万元/卡。综合计算,整体PCB单卡价值约0.3万元/NPU。
Ø 铜缆:高速铜缆模组约0.8万元/NPU。
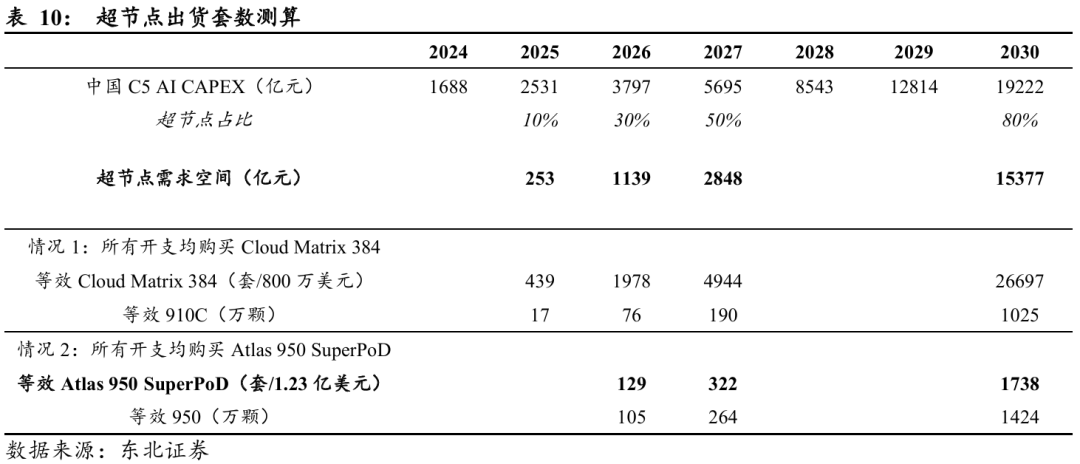
互联网C5 CAPEX高增长与超节点采购占比提升,超节点市场规模有望迅速增长。前文测算中国互联网C5类AI基础设施资本开支将从1,688亿元增长至1.92万亿元。超节点作为高密度算力部署的核心基础设施,其在C5 CAPEX中的占比将随时间快速提升,假设该占比从2025年的10%上升至2030年的约80%,对应的超节点需求空间从2025年的253亿元增至2030年的1.54万亿元。
需要注意,上述测算仅考虑互联网领域的C5 CAPEX,尚未纳入政企及运营商场景,实际市场空间可能更大。
2030年超节点市场空间1.54万亿元,假设全部用于购买Cloud Matrix 384,则对应出货量为26697套,等效910C出货量1025万颗;假设全部用于购买Atlas 950,则对应出货量为1738套,等效950出货量1424万颗。
以华为Atlas 950作为测算标准,假设年出货1000套,各环节占比分别为:先进制程晶圆代工约388亿元、封装约624亿元、HBM约793亿元,Scale-up交换芯片约549亿元,高速铜缆模组约656亿元,光模块约492亿元,电源约246亿元,液冷约697亿元,PCB约246亿元,DrMOS约41亿元,散热盖约42亿元。
建议重点关注下面具备高景气与高弹性的方向:
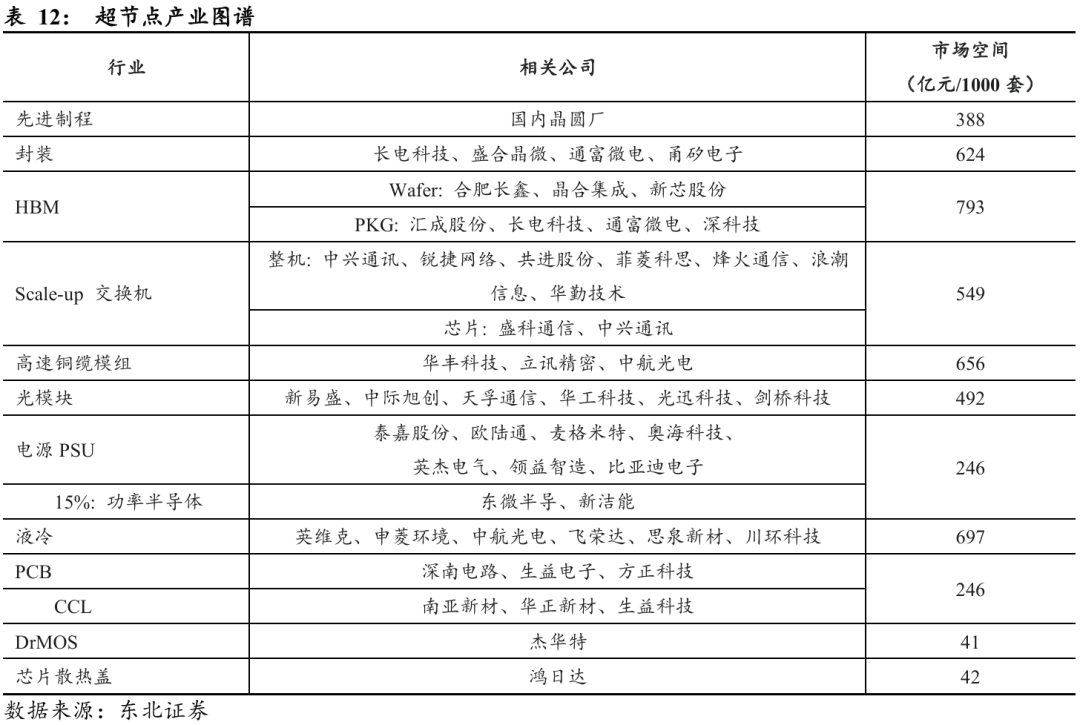
Ø 先进制程:先进制程环节仍是当前市场低估的核心主线。随着AI集群从Scale-out向Scale-up架构演进,交换机芯片的晶圆面积和产能占比显著提升,而这一部分的先进制程需求增量尚未被市场充分反映。国内方面,7nm产能建设如火如荼,相关晶圆厂有望在新一轮AI资本开支周期中充分受益。
Ø 交换机&交换芯片:虽然整机环节竞争激烈、盈利能力偏弱,但芯片环节的集中度与技术壁垒较高。国产厂商中,盛科通信与中兴通讯在高端以太网交换芯片和AI集群互联芯片方向均已取得突破,受益于国产替代与AI集群规模化部署,成长空间广阔。部分GPU厂商(例如海光)在Scale-up Switch芯片上也有配套,有望塑造超节点时代竞争壁垒。
Ø 高速铜缆模组:该环节具备显著的结构性机会。与海外AI机柜普遍采用“光进铜退”趋势不同,国内超节点架构以机柜内全铜互联方案为主导,依托高带宽、低延迟和更优的成本性能比,铜缆在超节点内部连接中具备天然优势,市场弹性突出。建议重点关注华丰科技、立讯精密等。
Ø 中国特色的超节点机会——液冷、电源:国产算力单卡性能不足,推动系统级液冷与电源技术的结构性机会。由于先进制程受限,国产芯片在核心算力与能效比上与海外产品仍存在明显差距,以2026H2的NVL144与Atlas 950 SuperPoD为例,若按同等算力换算,国产方案需约8.5倍芯片,功耗约为英伟达的5.8倍,孕育了液冷和高效电源在国产超节点架构中的结构性投资机会。
风险提示
Ø 超节点产业趋势不及预期:超节点架构的普及和应用仍处于早期阶段,其发展受上游技术成熟度、标准化协议推进及下游客户采纳速度影响。若超节点部署节奏低于预期,相关硬件、互联及散热环节的市场空间可能被压缩,导致投资弹性下降。
Ø 下游算力需求波动:超节点市场高度依赖大模型及云计算服务的算力需求。如果互联网巨头或行业客户对大规模训练的资本开支缩减,或者业务增长低于预期,将直接影响超节点出货量及上游硬件采购规模。
Ø 超节点规模和技术演进不确定性:当前超节点集群规模仍偏小,尚不足以支持大模型训练,万卡级超节点预计明年才会发布。如果超节点技术演进不及预期,其性能、互联和可靠性无法达到目标,将直接影响超节点投资逻辑的成立与相关环节市场空间释放。
Ø 单卡性能提升风险:若未来GPU或国产加速卡单卡性能显著提升,单位算力所需芯片数量与集群规模将下降,可能导致对超节点系统及其互联、液冷和电源环节的需求下降,从而影响相关市场空间与投资弹性。
Ø 训练算力需求变化风险:随着算法优化、混合精度训练及大模型架构改进,单个模型训练所需总算力可能下降。如果大模型训练效率提高或算力密集度降低,将减弱对超节点系统的大规模部署需求,影响超节点整体市场发展节奏。

 VIP复盘网
VIP复盘网
