

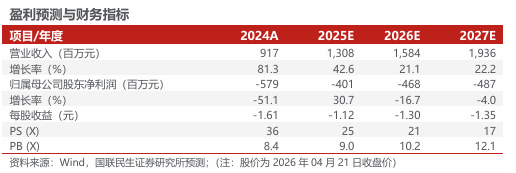
摘要
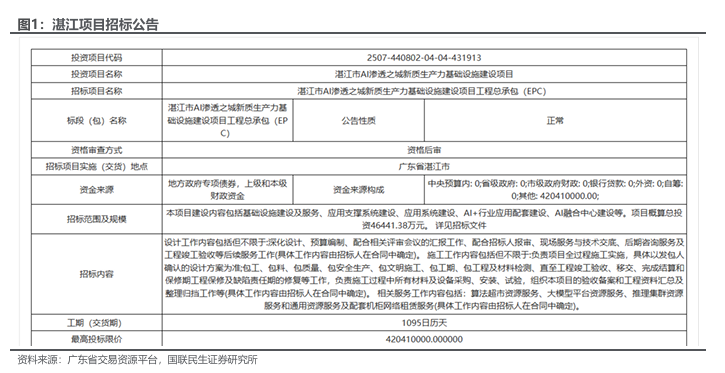
中标湛江AI推理千卡集群项目,DeepSeek创始人家乡打造“国模国芯”深度融合的算力生态. 2026年3月12日,云天励飞中标湛江市AI渗透之城新质生产力基础设施建设项目,该项目为全栈国产AI推理千卡集群,基于公司自研国产AI推理加速卡,推动DeepSeek等国产大模型在相关应用场景中的适配与部署。云天励飞中标此项目,项目建设的AI推理算力集群将围绕大模型推理任务需求进行系统设计。
本次AI推理算力集群将分三期建设,并将采用云天励飞自研的国产AI推理加速卡。一期项目将部署云天励飞 X6000 推理加速卡;未来将率先搭载公司最新一代芯片产品。公司未来将逐步推出针对Prefill阶段优化的芯片产品,以及面向Decode阶段低延迟需求的推理芯片。公司首款面向长上下文推理场景优化的Prefill芯片DeepVerse100预计将在2026年底前后完成流片,并计划在相关算力系统中开展部署。
公司芯片积极适配DeepSeek,已在R1发布后,成为首批完成适配的国产芯片企业,目前也在积极准备DeepSeek V4适配工作。公司未来旗下的AI推理加速卡将全面承载DeepSeek大模型能力,赋能千行百业。公司此前在DeepSeek-R1发布后,便快速进行了适配,未来芯片体系有望进一步适配新型模型。
规划未来三代芯片,手握充足产能保障产品推出。公司未来三年规划了三代芯片产品:2026年,打造第一代超节点 P 芯片,面向百万级长上下文场景进行 Prefill推理优化,算力水平对标Hopper架构;2027年,研发第一代超节点 D 芯片,聚焦Decode推理的低时延目标,算力水平对标Blackwell架构;2028年,推出第二代超节点D芯片,面向毫秒级推理时延目标进一步优化,带动Prefill与Decode性能提升,算力层面有望看齐下一代Rubin芯片。
面对不同场景需求,推出不同系列产品覆盖边缘全场景需求。DeepEdge10系列使用公司自研神经网络处理器NNP400T,提供自8T-128T的算力。 DeepEdge200为面向云端大模型推理的高性能SOC芯片,采用D2D的chiplet片上互联技术,实现单芯片算力的灵活可扩展,边缘侧场景全覆盖。
投资建议:公司部署AI算力到应用全产业链,多项平台技术优势明显。此外,公司多方向开拓AI市场,通过企业级、消费级、行业级三方向渠道开拓,销售额增长显著。后续随着自研芯片及相关产品在云端推理市场,公司营收有望迎来快速增长。我们预计公司2025-2027年营业收入为13.08、15.84、19.36亿元,当前股价对应PS分别为25X、21X、17X,维持“推荐”评级。
风险提示:核心芯片产品销售不及预期,技术研发不及预期,端侧设备产品销售不及预期风险,单一大客户依赖风险。
1 中标湛江AI推理千卡集群项目,DeepSeek创始人家乡打造“国模国芯”深度融合的算力生态
在该架构下,Prefill阶段主要负责长上下文理解和计算,对算力和带宽需求较高;Decode阶段则持续生成Token,对系统延迟更加敏感。项目建设过程中,将结合不同阶段的特点进行算力资源配置和系统优化。
同时,随着模型上下文长度不断增加,大量中间状态需要以KV Cache形式存储。围绕这一特点,项目在系统设计中对计算、存储与网络之间的协同进行了优化,以提升数据访问效率和整体系统性能。
在网络架构方面,系统将采用统一高速互联架构,通过400G光网络构建集群物理层网络,实现节点之间的高带宽、低延迟通信,并支持从单节点数十卡规模扩展至千卡级集群规模,以满足不同规模AI应用需求。
根据项目规划,本次AI推理算力集群将分三期建设,并将采用云天励飞自研的国产AI推理加速卡。一期项目将部署云天励飞 X6000 推理加速卡;未来将率先搭载公司最新一代芯片产品。公司未来将逐步推出针对Prefill阶段优化的芯片产品,以及面向Decode阶段低延迟需求的推理芯片。公司首款面向长上下文推理场景优化的Prefill芯片DeepVerse100预计将在2026年底前后完成流片,并计划在相关算力系统中开展部署。
公司芯片积极适配DeepSeek,已在R1发布后,成为首批完成适配的国产芯片企业,目前也在积极准备DeepSeek V4适配工作。公司未来旗下的AI推理加速卡将全面承载DeepSeek大模型能力,赋能千行百业。公司此前在DeepSeek-R1发布后,便快速进行了适配,未来芯片体系有望进一步适配新型模型。
2025年春节期间,云天励飞芯片团队完成 DeepEdge10 “算力积木”芯片平台与DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8、DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-70B大模型、DeepSeek V3/R1 671B MoE大模型的适配。适配完成后,DeepEdge10芯片平台将在端、边、云全面支持DeepSeek全系列模型。
云天励飞芯片团队在FlashMLA开源后,迅速完成了DeepEdge10平台与FlashMLA的适配工作。在适配过程中,云天励飞采用了Op fusion tiling、Online softmax、Double buffer、细粒度存算并行等先进技术,并基于自研的Triton-like编程语言快速开发验证了高效的FlashMLA算子。通过一系列优化,不仅显著提升了计算效率,还大幅降低了显存占用,充分展现了DeepEdge10平台“算力积木”芯片架构的卓越优势,以及其与DeepSeek生态的高度契合性。已将相关代码提交至开源平台Gitee,为开源AI贡献了重要的技术力量。
Deepseek开源模型,推动“算法-芯片协同进化”,公司核心设计理念高度相似。Deepseek开源推理模型R1引起产业变革,低成本高效能的模型开源,推动了行业的整体发展。由于硬件GPU使用受限,Deepseek采用软件端技术创新提升训练效率,整体训练成本约为550万美元,仅为OpenAI o1开发费用的3%。Deepseek R1通过关键设计的奖励系统、训练模板、自进化现象,以及用于强化学习的核心算法GRPO,用低算力的GPU训练出了媲美OpenAI o1的模型,证实了在AI行业中,软件端算法的创新可弥补硬件端差异,也可推动行业整体发展并产生经济效应。云天励飞持续强调的算法芯片化,通过自定义指令集、处理器架构及工具链的协同设计,通过软件端的改良提升芯片能力,从而拓展推理应用市场。

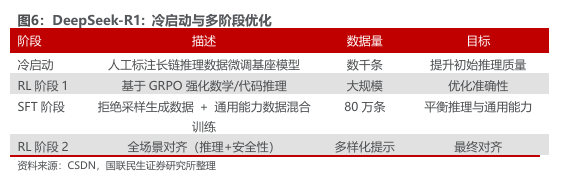
2 公司未来算力规划:推出大算力芯片迎接推理时代起量
公司于2月3日举办“大算力芯片战略前瞻会”,对外公布未来三年的大算力 AI 推理芯片战略布局。现阶段,国产算力市场呈现“训练追赶、推理超车”,云天聚焦推理赛道,发布了基于“PD 分离”思路的芯片路线图:力争实现百万 Tokens 推理成本降低 100 倍以上的目标。公司认为训练芯片更侧重“绝对值”,对算力规模、带宽能力以及科学计算的复杂精度要求更高,且对成本相对不敏感;推理芯片的核心考量则在于成本、效率与市场经济学,关键在于每一个 Token 背后的边际成本与整体性价比。
公司致力于持续降低百万 Token 的成本,目标是通过下一代芯片实现“百万 Tokens 一分钱”。未来,公司希望将成本进一步降至“百亿Tokens 1分钱” 公司未来按照“PD 分离”的系统架构规划两类大算力芯片:P芯片(Prefill):面向计算密集型需求设计,满足 Prefill 阶段的高算力要求;D芯片(Decode):面向访存密集型需求设计,满足 Decode 阶段的高带宽需求。
公司在芯片微架构层面针对 Attention 及 AFN 等计算特点进行细粒度分析,并在底层实现针对性优化。在一个包含 1024 颗芯片的超节点内,P 芯片与 D 芯片可实现有效组合,以满足大模型云推理的集群化部署需求。

规划未来三代芯片,手握充足产能保障产品推出。公司未来三年规划了三代芯片产品:2026年,打造第一代超节点 P 芯片,面向百万级长上下文场景进行 Prefill推理优化,算力水平对标Hopper架构;2027年,研发第一代超节点 D 芯片,聚焦Decode推理的低时延目标,算力水平对标Blackwell架构;2028年,推出第二代超节点D芯片,面向毫秒级推理时延目标进一步优化,带动Prefill与Decode性能提升,算力层面有望看齐下一代Rubin芯片。
公司领导在发布会上介绍,公司为国内屈指可数、手握充足国产产能保障的企业之一。现阶段,AI应用需求激增带动tokens消耗量,算力需求激增,产能或成为制约算力企业快速发展的核心因素。公司手握充足产能,未来或凭借产能优势迎来快速发展机遇。

四大技术亮点支撑公司下一代GPNPU技术路线,提出了“GPNPU = GPGPU NPU 3D 堆叠存储”的核心公式,在兼顾通用计算的“通用性”与 NPU 的“高效性”,打造极致性价比推理芯片。公司下一代芯片的核心架构为自研GPNPU架构,技术亮点主要包括四个方面:GPGPU级通用编程能力(CUDA兼容):面向国内芯片“易用性”痛点,GPNPU 架构强调对主流CUDA等生态的兼容与迁移支持,以降低客户模型部署与迁移门槛;极致能效的NPU内核:围绕推理效率与能效比进行深度优化,提升推理侧性价比;引入3D Memory结构:采用3D Memory结构,以获得更高带宽与更低访问时延,提升推理效率;算力积木架构:公司延续过去五年在国产工艺上的探索,以“算力积木”架构定义下一代芯片的 Scale-up 超节点,以满足万亿级乃至十万亿级 MoE 架构大模型的推理需求。

3 现有算力储备:DeepEdge系列迎接应用带动边缘算力市场起量
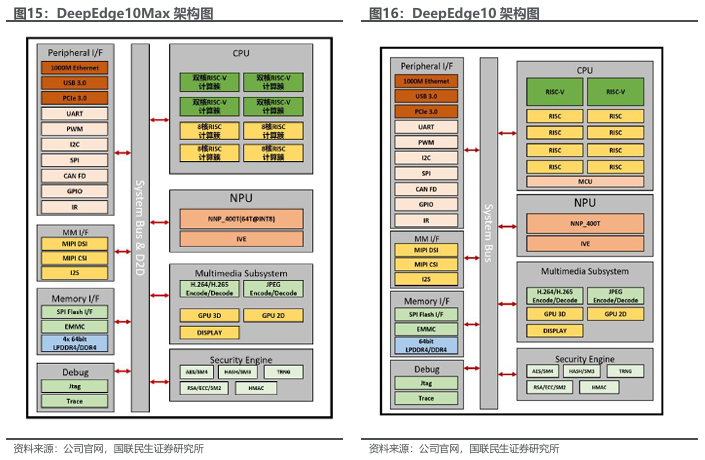
多代AI推理芯片持续发展,算力水平持续提升。公司推理芯片目前已更新至第四代,DeepEdge系列对应Nova 400,采用算力积木设计,融合D2D chiplet和C2C mesh tour互连技术。DeepEdge10系列可支持单个芯片8T至128T的算力需求。
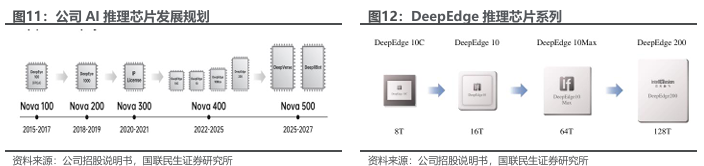
公司支持多芯粒扩展Chiplet技术,全自研DeepEdge10芯片满足市场多样化需求。DeepEdge10基于公司自研的神经网络处理器(NNP400)架构,采用国内先进工艺、支持多芯粒扩展的Chiplet技术,DeepEdge10可提供16TOPS(INT8)整型计算和2TFLOPS FP16浮点计算的深度学习推理计算算力,满足市场对处理芯片在算法的多样性、准确性、算力密度及效能方面的要求。
针对各类应用场景,云天励飞已开发出Edge10C、Edge10标准版、Edge10E和Edge10Max系列芯片。Edge10系列主要应用于边缘大模型推理领域,能高效支持Transformer模型中的矩阵乘法运算。 DeepEdge10芯片主要应用包括摄像头、边缘计算设备、机器人、汽车智能座舱等行业的客户。依托 DeepEdge10创新的 D2Dchiplet架构打造的X6000系列推理卡,目前已适配多个主流大模型。
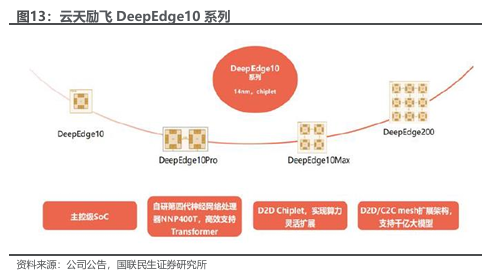
面对不同场景需求,推出不同系列产品覆盖全场景需求。DeepEdge10系列使用公司自研神经网络处理器NNP400T,提供自8T-128T的算力,其中 DeepEdge10C、DeepEdge10、DeepEdge10max、DeepEdge200为面向边缘视频智能计算和边缘大模型推理推出的高集成度、高性能、低功耗轻量级SOC主控芯片,DeepEdge200为面向云端大模型推理的高性能SOC芯片,采用D2D的chiplet片上互联技术,实现单芯片算力的灵活可扩,满足人工智能大模型云端推理对算力的需求。
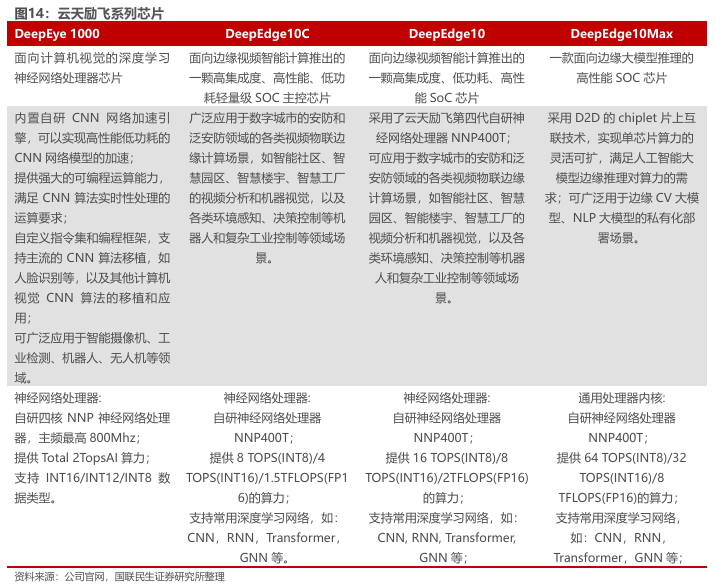
公司自研芯片结构助力多场景应用落地。DeepEdge10Max搭载了4个八核64位RISC通用处理器计算簇,4个双核64位RISC-V处理器计算簇,支持RV64GCV指令集,支持256-bit数据位宽。DeepEdge10搭载了八核64位RISC通用处理器,双核64位RISC-V 处理器,支持RV64GCV 指令集,支持64-bit 数据位宽。
智能硬件产品推动公司软硬一体销售。基于公司自研“云天天书”大模型和神经网络处理器,打造面向各类边缘AI场景的各类硬件设备并对外销售,包括 AI芯片、天舟系列云边服务器、边缘计算盒子、“深目” AI模盒 、X6000推理加速卡,以及基于X6000加速卡打造的推理服务器等。

云天励飞推出X6000加速卡。X6000具备256T算力、128GB显存容量、486GB/S显存带宽;采用C2C Mesh互联技术,可实现卡间高速互联,带宽达64GB/s,最大可实现64张卡的互联;可应用于语言、视觉、多模态等各类大模型的推理加速,目前已适配云天天书、通义千问、百川智能、Llama2/3等近10个主流大模型。
X6000加速卡内置全国产算力芯片DeepEdge200,该芯片采用D2D Chiplet技术,基于DeepEdge10芯片平台打造。X6000单卡可实现130B参数量大模型推理,在执行70B参数量大模型推理时性能达11 tokens/s,有望在大模型推理领域逐步实现国产替代。

公司智算运营项目分为重资产模式与轻资产模式,稳定补充现金流,未来拓展推理芯片销售。公司于2023年入局AI基础设施运营创新业务,通过落地超大规模异构高性能算力集群,为客户提供AI训练集推理算力服务及对应交付物,包括智能算力调度及 AI大模型开发配套服务。公司智算运营项目分为重资产模式与轻资产模式,重资产模式为公司持有算力卡及相关算力基础设施,为客户提供算力服务;轻资产模式为客户持有算力卡,公司提供日常算力运维服务。公司在同行业中资源储备较为齐全,已逐渐开拓了相关业务客户资源,形成了部分已落地项目并取得了相关收入或在手订单。公司推理芯片为未来发展重点,公司有望凭借智算运营积累的渠道满足不同客户需求,从而凭借渠道优势在未来推理需求提升的背景下拓宽公司推理芯片渠道。
与德元签订合同项目,大额订单补充现金流。2024年,公司与德元方惠就德元向公司购买 AI训练及推理算力服务达成框架安排。在正式提供服务后三年内,公司预计将获取金额约为人民币16亿元的AI算力服务收入。公司全资子公司励飞科技与德元方惠于2024年7月初签署合作正式合同,目前处于合同履约中,将对公司经营业绩产生积极影响。

公司子公司成都云天励飞中标天府智算中心项目采购,轻资产模式算力租赁亦增加营收。公司子公司中标天府智算中心项目设备采购,中标项目金额约为1.30亿元(含税),该项目为轻资产模式,公司交付智算整体方案,而不持有算力卡等硬件设施。与重资产模式相比,轻资产模式毛利率偏低,亦可补充营收现金流。
4 算力行业近期变化:应用开发带动tokens消耗量激增,算力供需缺口持续扩大
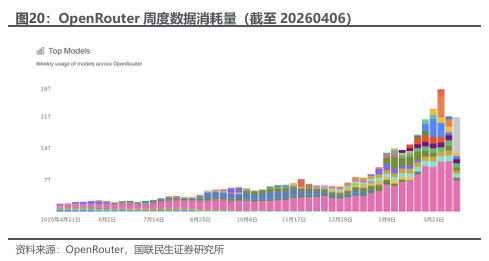
AI应用带动token消耗量快速提升,模型厂商出现涨价、限量限时现象,进一步带动算力需求提升。根据OpenRouter数据,从年度变化上看,2025年4月21这周的周度模型数据使用量为1.76T,截至2026年4月6日的最新数据,周度模型数据使用量为21T,相较一年前增长了近12倍。在OpenClaw以及各种Agent应用的使用程度提升的背景下,模型tokens消耗量快速提升,部分模型厂商出现涨价、限量限时的现象。Tokens消耗量的快速提升进一步带动了算力需求度的提升。
英伟达收购Groq, 推出RubinGPU适配推理提升效率,推理市场重要性提升至战略地位。25年年底,英伟达以200亿美元(约合1402亿元人民币)现金收购Groq资产,完成了一次 “人才 技术收购”:拿下 Groq 大部分研发团队,并获得其用于AI推理的LPU数据流引擎底层技术授权。公司后续推出的Rubin GPU为实现优化完整的执行路径,将功耗、带宽和内存高效转化为tokens进行设计,从计算密度、内存带宽和机架级通信三个维度改进架构。现代 AI 工作负载包括推理、多专家模型(MoE)、长上下文推理和强化学习等领域,推理在工作负载的占比比例提升,为迎接推市场的快速增量,英伟达进行重量并购并推出相对应产品,推理市场重要性提升至战略地位。

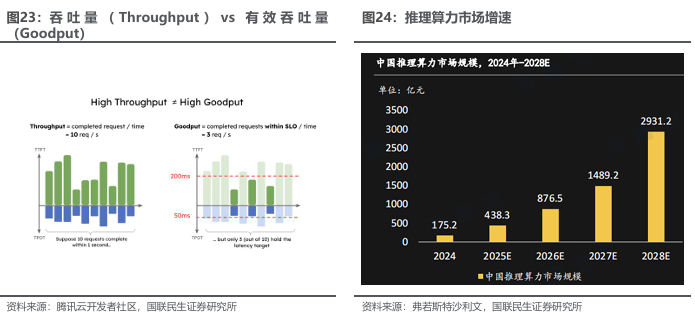
PD分离成为行业趋势,推理算力市场快速增长,公司产品竞争优势明显。PD分离架构是一种大型语言模型推理优化技术架构,由AMD在ROCm博客中提出。该架构将LLM推理的Prefill(预填充)与Decode(解码)两个阶段分离并分布在不同GPU上执行,以优化资源利用。prefill 阶段需要并行处理整个输入序列来生成首个 token,属于计算密集型操作。decode 阶段则逐个生成后续 token,需要频繁访问 KV cache,属于内存密集型操作。传统的 continuous batching 将两个阶段混合处理,导致相互干扰,难以同时满足 TTFT(首 token 延迟)和 TPOT(token 间延迟)的严格要求。为了解决这一问题,PD 分离架构应运而生,通过将 prefill 和 decode 分配到不同的 GPU 实例上,针对各自特性进行专门优化。这种分离式设计不仅消除了阶段间的干扰,还能显著提升系统的有效吞吐量(Goodput),为大规模 LLM 服务提供了更优的解决方案。避免了在同片GPU上因数据资源等待,导致较差的反应服务体验。因此在推理阶段,PD分离逐步成为行业的主要发展趋势之一。
推理算力市场高速发展。据弗若斯特沙利文数据,截至2023年,通用算力与智能算力分别为171与59 EFLPOS,预计2027年将达330与240 EFLPOS,整体增速39%。中国日均Tokens消耗量从2024年初的1,000亿增长至今年6月底超过30万亿,1年半增长300多倍,这反映了中国人工智能应用规模快速增长。据弗若斯特沙利文数据,2025年中国推理算力市场规模预计达438.3亿人民币。
5 盈利预测与投资建议
5.1 盈利预测与业务拆分
由于公司于2024年调整业务营收分类,将公司业务主要分为消费级、企业级、行业级,我们按照公司最新业务分类进行盈利预测。
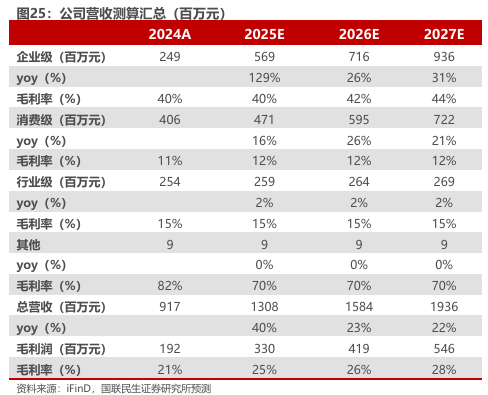
消费级:1)收入:公司消费级产品主要为多种AI端侧设备,包括可穿戴设备类产品、AI交互类产品等。随着大模型技术的进步,端侧设备的实效性有望提升,端侧设备消费端接受度提升,端侧设备市场规模有望迎来高速扩容期,公司相关产品有望迎来快速增长。受子公司岍丞技术收购协议营收目标与2025年公司加大子公司品牌噜咔博士宣发原因,25年为噜咔博士销售第一年,开始基数较低,相关业务增速呈现先升后降趋势。因此我们预计公司消费级营业收入2025-2027年增速分别为16%、26%、21%。2)毛利率:考虑到公司端侧设备销售业务模式稳定,预计毛利率会延续历史水平。预计2025-2027年毛利率分别为12%、12%、12%。
企业级:1)收入:公司企业级产品以推理芯片为核心,拓展系列产品,同时凭借算力储备提供算力支持与运维服务。公司该项业务营收为算力服务业务营收叠加以芯片为核心的相关的推理卡、边缘计算盒子、一体机等产品。公司算力服务业务营收规模较大,并于2024年下半年计入收入,2025年全年计入收入,因此预计2025年企业级业务增速提升较快,后续增速放缓。我们预计公司企业级营业收入2025-2027年增速分别为129%、26%、31%。2)毛利率:考虑到公司核心芯片产品加速卡推出,加速卡为高毛利率产品,相关产品起量有望带动毛利率提升,预计2025-2027年毛利率分别为40%、42%、44%。
行业级:1)收入:公司行业级业务为凭借软硬件通用平台,在六大行业开展智慧行业解决方案。公司此项业务主要在智慧警务、城市治理、智慧交通、人居生活、低空经济、智慧教育六大领域,向政府机构等终端客户、企事业单位等集成商客户,按需求交付硬件产品或解决方案。公司此项业务未来规划维持相对稳定,因此我们预计行业级营业收入2025-2027年增速分别为2%、2%、2%。 2)毛利率:考虑到公司该业务营收模式相对稳定,因此预计毛利率会延续历史水平,预计2025-2027年毛利率分别为15%/15%/15%。
主要费用率:1)销售费用率:随着公司营收规模扩张叠加公司企业级、消费级、行业级三方向业务销售渠道建设稳定,公司销售费用率有望合理收敛,预计2025-2027年销售费用率分别为11%、10%、10%;2)管理费用率:公司前期管理费用率较高涉及上市费用及股权激励费用,未来营收规模扩张及无相关费用影响,管理费用率有望合理收敛,预计2025-2027年管理费用率分别为18%、15%、12%。3)研发费用率:公司作为AI芯片和算法公司,研发投入需求较大。当前,其正全力转向推理市场,研发资源高度集中于AI推理芯片。尽管营收规模快速增长或使2025年研发费用率暂时被摊薄,但随着在推理芯片上的投入持续加大,研发费用率预计将回升并维持在较高水平,费用绝对值维持增长态势。预计2025-2027年,公司研发费用率分别为32%、35%和35%。

5.2 估值分析
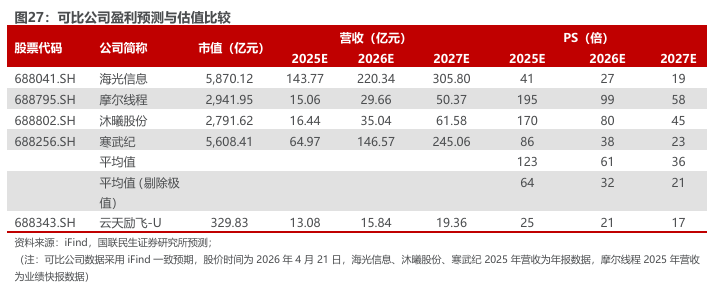
云天励飞主营业务涵盖AI推理芯片设计及AI软硬件产品销售,属于典型的Fabless芯片设计模式 。我们综合考虑业务形态、商业模式及行业属性,选取在AI芯片设计领域与公司业务相近的同类企业作为可比对象,具体包括:海光信息(国产CPU DCU双芯企业)、摩尔线程(国产高性能GPU厂商)、沐曦股份(国产高性能GPU企业)、寒武纪(国产AI芯片先行者)。可比公司2025-2027年平均PS分别为123X、61X,36X,云天励飞对应PS分别为25X、21X、17X。鉴于摩尔线程、沐曦股份两家公司目前均处于高投入亏损期,且享有高估值溢价,出于审慎考虑,剔除上述极值后2025-2027年平均PS分别为64X、32X、21X。横向对比来看,公司未来三年PS均显著低于可比公司均值水平,建议持续关注公司大算力推理芯片战略推进及商业化落地进展。
4.3 投资建议
公司部署AI算力到应用全产业链,多项平台技术优势明显。此外,公司多方向开拓AI市场,通过企业级、消费级、行业级三方向渠道开拓,销售额增长显著。后续随着自研芯片及相关产品在云端推理市场,公司营收有望迎来快速增长。我们预计公司2025-2027年营业收入为13.08、15.84、19.36亿元,对应PS分别为25X、21X、17X,维持“推荐”评级。
6 风险提示
1)核心芯片产品销售不及预期。公司的核心增长业务为芯片设计,该行业核心产品迭代快、市场竞争激烈,公司最新芯片及其相关产品如销售不及预期,或影响公司销售额变动。
2)技术研发不及预期。公司所研发芯片为NPU芯片,该芯片主要服务于人工智能行业推理端,行业需求变化快。为面对需求端的快速变化,公司已规划出未来几年芯片设计规划。如公司芯片研发进度不及预期,或影响公司核心竞争力。
3)端侧设备产品销售不及预期风险。公司消费级业务主要以向消费者销售带有AI功能的端侧设备,其中包含拍学机、AI眼镜、AI玩具等。如端侧设备销售不及预期,或影响公司消费级业务营收。
4)单一大客户依赖风险。公司企业级业务中,德元为主要单一大客户,存在单一大客户依赖风险。

 VIP复盘网
VIP复盘网
