


4月22日至24日,谷歌重磅云年度大会GoogleCloudNext2026将在美国拉斯维加斯召开,预计将发布新一代TPUv8架构,并披露光路交换机OCS等AI算力关键技术进展。
早前谷歌表示,为应对持续上升的AI服务需求,必须每6个月将AI算力翻倍,并在未来4到5年内额外实现1000倍的增长。
近期谷歌更新了TPU的出货规划,目标大幅上修。谷歌与博通签订到2031年的TPU供货协议,以及Anthropic通过博通向谷歌加单27年以后的3.5GWTPU算力。
在新一代TPU出货预期提升的情况下,有望带动算力和光互联产业链进一步提速,实现多场景高效联动。
在之前的文章中,我们梳理了OCS光交换机全解析、光模块产业链全景解析、硅光模块梳理、国产AI算力数据中心全解析。
本文重点解析TPU产业链以及核心环节。
01
TPU行业概览
TPU(TensorProcessingUnit,张量处理单元)是谷歌专为加速人工智能机器学习训练与推理任务定制开发的一种专用集成电路ASIC。
ASIC芯片:性能上针对特定任务的硬件架构优化使其计算效率远超通用芯片,流水线结构还能降低数据处理延迟;能效比卓越,功耗可比通用芯片低且散热压力更小。
TPU:从硬件到软件栈深度整合,支持谷歌AI生态的快速迭代。其核心优势在于“用硬件定义算法”,高效矩阵运算、能效比突出以及定制化设计。与通用计算芯片不同,TPU的硬件设计完全围绕深度学习中最核心的张量运算展开,针对深度学习中的矩阵乘法、卷积等张量操作优化。

TPU的硬件架构组成
TPU的硬件架构围绕"计算-存储-互联"三大核心模块展开。
核心计算单元采用脉动阵列结构,由数千个算术逻辑单元(ALU)组成二维网格,数据通过流水线方式在阵列中传递,每个周期可完成数千次乘加运算(MAC)。
通过硬件架构的专用化实现计算效率的数量级提升,TPU的算力密度远超通用CPU/GPU。
此外,TPU通过OCS、3D拓扑、液冷等技术,突破集群扩展瓶颈,形成“芯片-网络-散热”协同优化。TPU与GoogleCloud结合,提供算力解决方案。

TPU发展历程
谷歌TPU自2015年首次推出以来,历经多次迭代升级。
从初代仅支持推理,到v2引入训练能力,再到v4后支持超大规模混合负载,当前TPU逐步形成完整的技术体系。
TPUv7:2025年4月,谷歌在CloudNext大会发布了最新的第七代TPUv7,代号"Ironwood",是目前谷歌性能最强大、能效最高的定制芯片。
Ironwood实现算力、能效与生态的三重突破。单芯片算力4614TFLOPs(FP8精度),集群规模扩展至9216颗芯片。算力达42.5ExaFLOPs,相当于全球最强超算ElCapitan的24倍,训练和推理性能比第六代TPU(Trillium)提升4倍。
TPUIronwood的推出标志着AI算力从“单芯片竞争”转向“系统级竞争”,其算力爆发与OCS技术创新为产业链带来重构机遇。
TPU7Ironwood芯片:
 资料来源:谷歌
资料来源:谷歌
TPUv8即将发布:谷歌计划在本周于美国拉斯维加斯举行的GoogleCloudNext大会上,发布其新一代TPUv8AI芯片。TPUv8在性能上有了显著提升,特别是针对AI推理任务进行了优化。
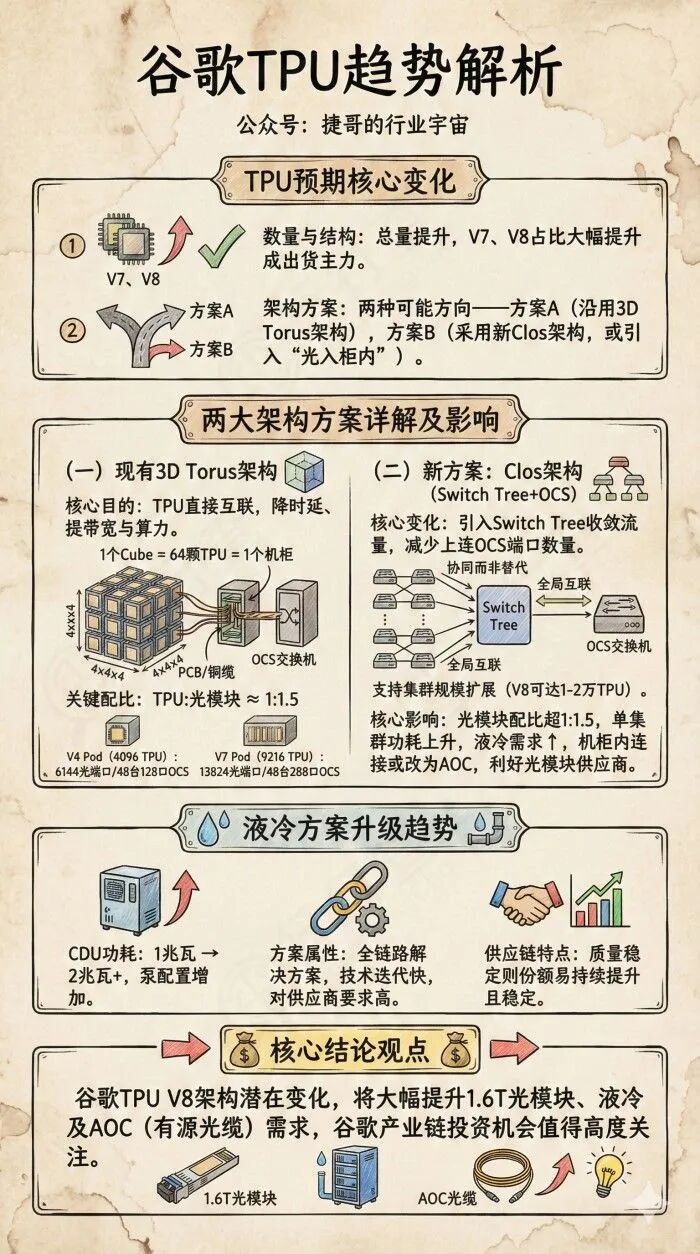 资料来源:公众号 捷哥的行业宇宙
资料来源:公众号 捷哥的行业宇宙
03
谷歌TPU产业链核心环节
芯片设计
芯片设计是整个产业链的核心和技术壁垒。
谷歌自主掌控TPU的架构设计,从TPUv1到v7的全代际架构设计,包括稀疏计算单元(SparseCore)、3DTorus互联拓扑、HBM内存集成等核心技术的研发。
TPUv8将采用"双芯片"策略,其中TPUv8t由博通设计,定位高性能训练加速器;TPUv8i由联发科操刀,主打高性价比推理加速器。
近期据Theinfomation称,谷歌正与迈威尔科技洽谈合作开发新型人工智能推理芯片。随后摩根大通表示,关于迈威尔科技赢得谷歌TPU业务的报道不实,并指出谷歌正在与多方进行洽谈,而博通仍然是明确的现有供应商,并指出更多明确信息可能在本周的CloudNext大会上公布。
TPU设计架构图:
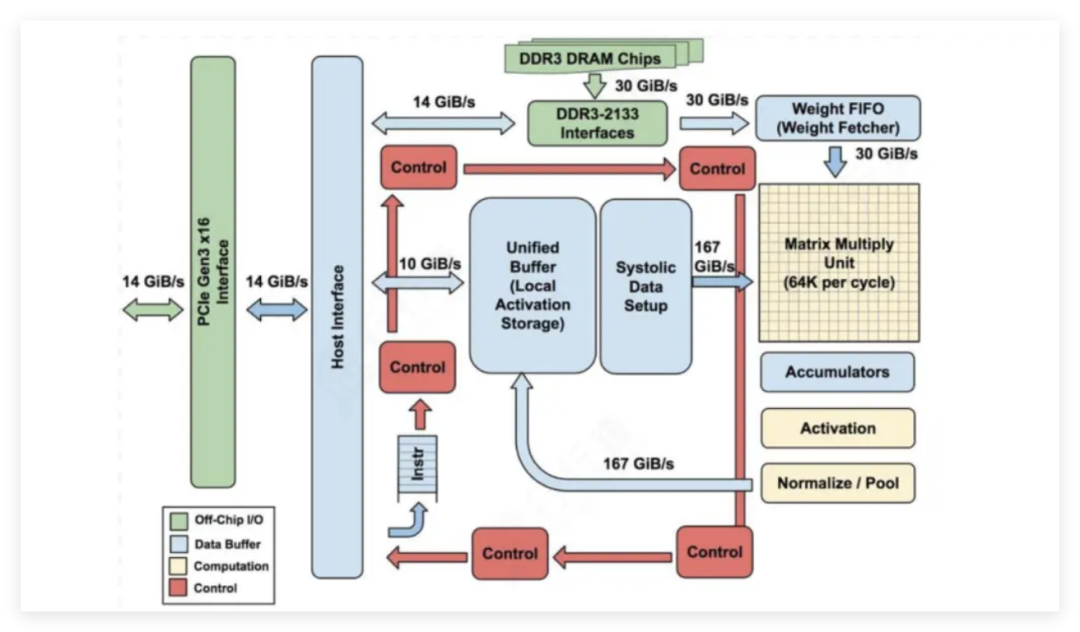 数据来源:Norman P. Jouppi《In-Datacenter Performance Analysis of a Tensor Processing Unit》
数据来源:Norman P. Jouppi《In-Datacenter Performance Analysis of a Tensor Processing Unit》
OCS光交换
大模型训练需要海量GPU/TPU协同计算,对通信带宽和时延提出极高要求,OCS网络在能耗/延时/宕机时间/升级迭代等多个方面具备显著优势。
谷歌是目前OCS最大的采购方,在OCS布局多年,在2022年首次将OCS引入TPUv4网络中且在后续一直沿用。
多个TPU机架通过OCS(光交换机)互联,构建起包含48台OCS的集群网络,最终形成由9216个TPU芯片组成的超大规模计算组网。
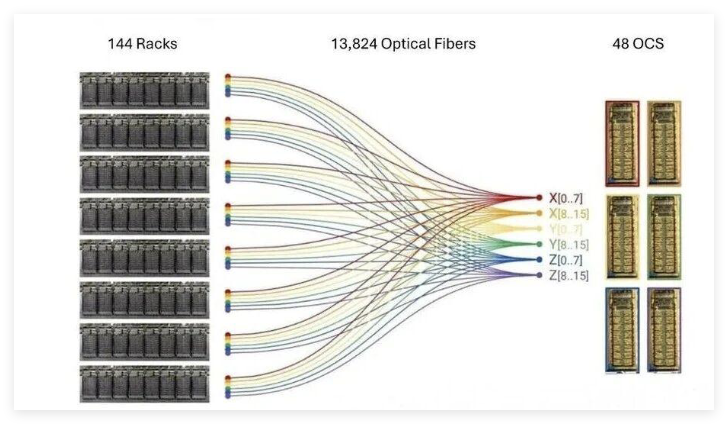
整体架构依托可扩展的ICI网络,使用1.8PB带宽连接43个Superpod块(每个块含64个芯片),并保持与前代一致的OCS数量,体现了谷歌在AI算力基础设施上的持续优化与规模化部署能力。
该架构体现了大规模AI计算集群中光互连技术的关键作用。
根据SemiAnalysis,谷歌的OCS定制化网络使其整个网络的吞吐量提升了30%,功耗降低了40%,数据流完成时间缩短了10%,网络宕机时间减少了50倍,且资本开支减少了30%。
此外,OCS可将交换机和光纤升级到更快的几代,而无需更换网络的“主干”,使用寿命比传统EPS长得多。
Ironwood集群直接连接9,216个IronwoodTPU形成一个单一域:
 资料来源:谷歌
资料来源:谷歌
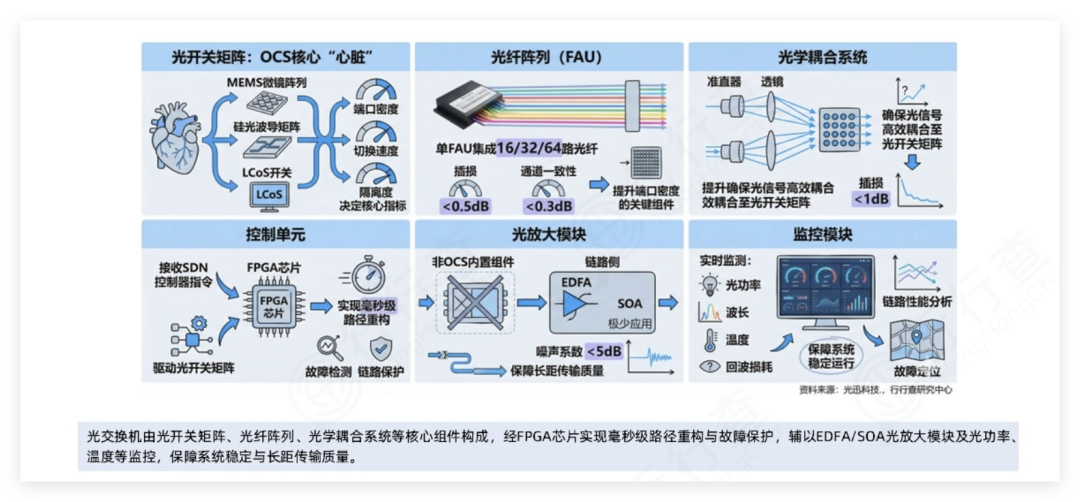
OCS光交换机核心技术
目前主要有四种方案:MEMS方案、数字液晶技术(DLC)、压电Directlight光束偏转技术(DLBS)和光波导方案。
MEMS目前相对成熟,是OCS市场中占比超过70%的主流方案,其端口扩展能力和成本控制比较均衡。全球主要厂商中,谷歌和Lumentum以MEMS方案为主,谷歌核心采用的MEMS微镜方案光路切换延迟仅10-100纳秒。
光交换机核心组件图:
谷歌OCS供应格局
目前谷歌的直接供应商主要为海外厂商Lumentum与Coherent等厂商,国内厂商目前已经参与到元器件与代工产业链中。
谷歌国内OCS产业链相关配套厂商包括德科立(整机)、赛微电子(MEMS芯片代工、OCS关键的微镜阵列晶圆)、光库科技(收购武汉捷普光学业务,切入MEMSOCS整机代工,间接供应谷歌)、腾景科技(供应OCS核心光学元件)等。
除谷歌外,OCS有望在其他CSP中得到更多重视和应用,当前微软、Meta、亚马逊AWS也都在探索自己的光交换网络。
谷歌TPUv7服务器架构:
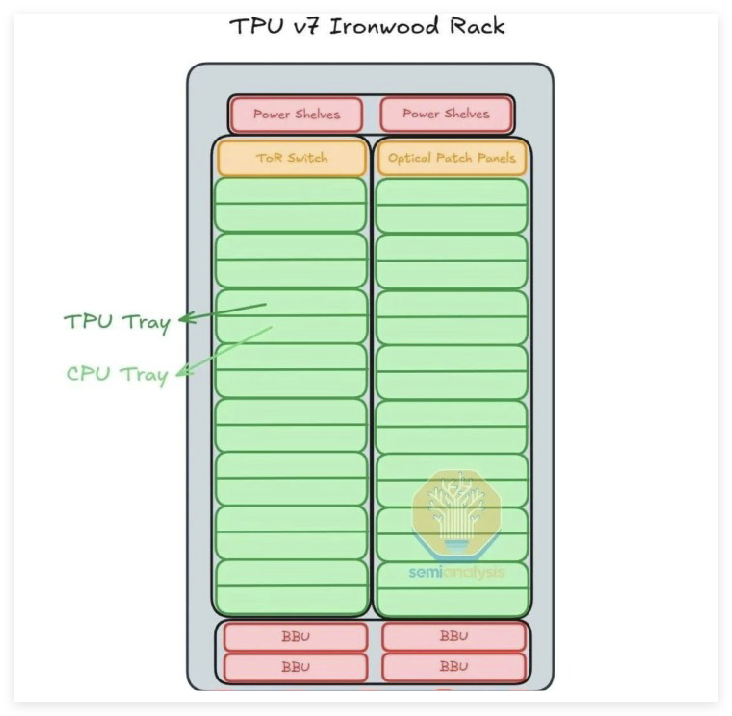 数据来源:Semianalysis
数据来源:Semianalysis
光模块&铜缆
TPU集群通过光模块实现芯片间ICI的高速数据传输,支撑大规模分布式计算。
谷歌第七代TPU(Ironwood)单集群串联超9000颗芯片,需部署超10万只光模块,构建低延迟、高带宽的3D环面拓扑网络,当前高速率的1.6T光模块成为刚需。
高速光模块:作为OCS系统的核心组件,需与MEMS光开关、液晶阵列等器件协同,提升网络灵活性和可靠性。因单芯片ICI带宽提升至1.2TBps(9.6Tbps双向),需更高速率光模块支撑。中际旭创(谷歌1.6T光模块独家供应商,产品适配2026年TPU扩张需求)、新易盛(为谷歌TPU边缘节点提供800G光模块)、太辰光MPO光纤连接器作为光通信配套供应谷歌,适配数据中心高密度互联需求。
1.6T光模块成为刚需,因单芯片ICI带宽提升至1.2TBps(9.6Tbps双向),需更高速率光模块支撑。
铜缆:随着TPU芯片数量指数级增长(如从v4的4096颗增至Ironwood的9216颗),铜缆的带宽和距离限制愈发明显。国内铜缆相关厂商中,长芯博创与Marvell合作的1.6TAEC有源铜缆已向谷歌送样,适配TPUv7集群需求。通宇、长飞、汇绿、瑞可达、意华、胜蓝、兆龙等众多厂商在铜缆环节有所布局。
 资料来源:谷歌
资料来源:谷歌
PCB
TPU作为谷歌AI算力的核心硬件,其性能提升依赖PCB印制电路板的技术迭代。
PCB作为芯片模组与整机的物理载体,直接决定算力设备的传输效率。
TPUV7/V8世代对PCB的“高带宽、低延迟、高可靠性”要求远超传统服务器,需支持224Gbps以上传输速率。
此外,TPUV7主版本为36层板,V7P版本升级至44层板,单价从1.5万元提升至2.5万元人民币。
拆解谷歌TPU服务器架构,单机柜共有16个TPUTray和CPUTray,单Tray上集成4张TPUv7芯片,PCB以高多层为主。
ASIC芯片在推理端的性价比表现突出,伴随后续模型的部署与应用谷歌TPU服务器出货有望快速提高。ASIC服务器市场的快速扩容也将为AIPCB行业带来进一步的增量空间。
2026年谷歌计划将覆铜板(CCL)从马8等级升级至马9(高频高速特性更优),推动PCB价值量进一步提升。V8世代可能引入HDI(高密度互连)技术,以提升传输速率至300Gbps,进一步优化PCB性能。沪电主导30-40层板生产、胜宏、中富电路等谷歌TPU的核心PCB供应商、深南电路为谷歌TPUV7芯片高端PCB独家供应商,供应44层板。
液冷散热
2018年,谷歌在其TPUv3版本中首次应用液冷技术。
随着TPU芯片数量指数级增长,40层以上PCB需优化导热设计,传统风冷技术已无法满足散热需求。
液冷通过直接接触芯片散热,支持超大规模集群稳定运行显著减少冷却系统能耗。
目前,谷歌TPU整柜的热设计功率约为80-90kW,大幅超出一般风冷散热的物理上限,因此服务器的TPU部分采用了独立冷板液冷覆盖,而CPU、电源、存储部分仍结合风冷散热。
以Ironwood集群为例,液冷散热技术使其能耗效率提升50%,相当于花同样电费获得双倍算力。
谷歌TPUv7(Ironwood)芯片液冷板:
 资料来源:谷歌云
资料来源:谷歌云
国内厂商已布局液冷方案,适配TPU高功耗散热需求。例如,英维克CDU支持超2.6万台液冷节点部署,适配谷歌AI芯片高功耗需求,提供全产业链液冷方案、思泉新材超薄VC均热板通过谷歌认证,新雷能切入谷歌TPU电源供应链,提供二次和三次电源模块、工业富联全球首创“冷板式 浸没式”混合液冷方案,获谷歌能效认证,适配TPU-v6集群部署。
谷歌TPU早期主要用于GoogleCloud及内部自用。2025年,谷歌开始大力向外部供应商供应TPU。
随着谷歌TPU产量的快速增加,Anthropic、Meta、xAI、OpenAI等TPU客户的名单也在不断扩大。其中,Anthropic与谷歌达成战略合作,计划采购100万枚TPU构建超1GW算力池;Meta与谷歌沟通计划2027年起或在数据中心部署数十亿美元TPU。
这些AI巨头们为了摆脱过于依赖单一供应商的风险,开始联手重塑AI算力格局。
今年Gemini3大模型横空出世,其超预期表现引起市场对于谷歌自研TPU服务器的重点关注。
谷歌凭借“AI应用(搜索、广告、视频)-大模型(Gemini)-算力(TPU)-网络设备(OCS)”打造的全栈布局模式,加速实现AI生态闭环,有望加速引领新一轮AI推理算力机遇。

 VIP复盘网
VIP复盘网
