阿里甩出AI语音转写神器!准确率击败字节腾讯,连方言都能写对
时间:2026-04-20 18:53
上述文章报告出品方/作者:智东西;仅供参考,投资者应独立决策并承担投资风险。

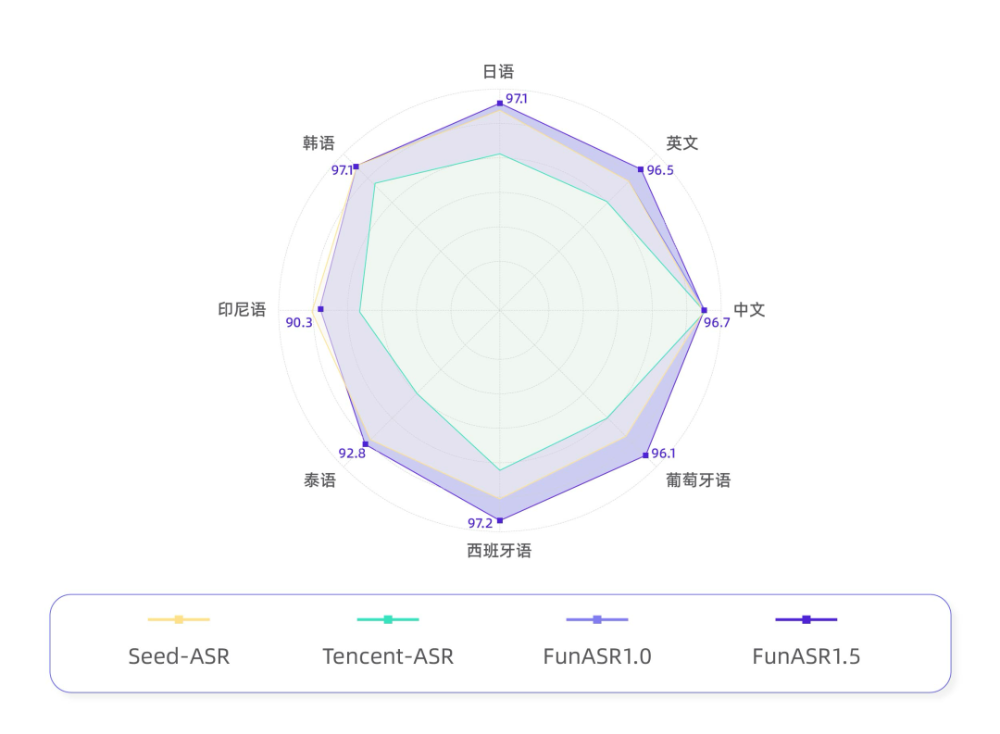
智东西4月20日报道,刚刚,阿里发布语音识别大模型Fun-ASR1.5,该模型是千问端到端语音识别大模型的新一代版本。该模型可以识别30种语言,覆盖中文七大方言体系及20余种地方口音,并强化了古诗词诵读的专项识别。Fun-ASR1.5可以分辨出语音中的抑扬顿挫,重点优化了标点预测和文本归一化能力,可以应用于会议纪要、新闻采访整理、法律笔录等场景。技术团队介绍称,与Seed-ASR和Tencent-ASR模型相比,Fun-ASR1.5在西班牙语、葡萄牙语和英语方面的识别准确率成绩较为突出,均在96分以上。▲Fun-ASR1.5在开源多语言测试集中获得多项SOTA
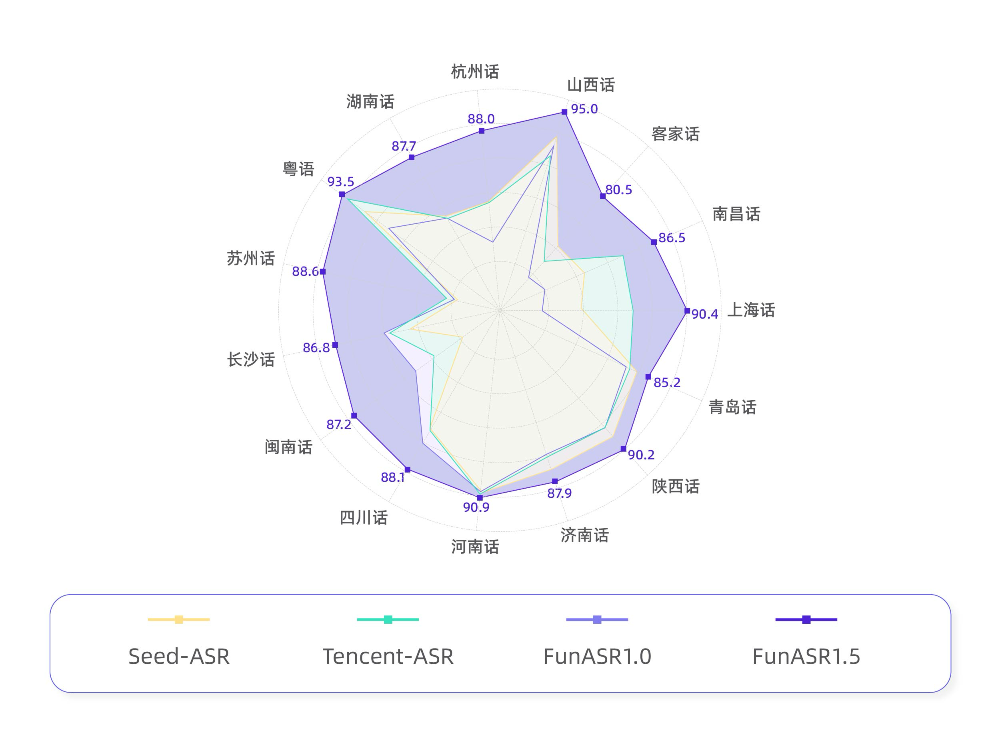
中文方言方面,Fun-ASR1.5则在四川话、闽南话、长沙话、苏州话等13种方言识别准确率上,超越Seed-ASR和Tencent-ASR模型。▲Fun-ASR1.5在工业方言测试集中获得多项SOTA智东西第一时间体验了其音频转写功能。我们上传了一段三星CES 2026“First Look”演讲的录音音频。在原音频中,背景环境声音嘈杂,演讲人使用英语演讲但带有韩语口音,且录制声音较小。Fun-ASR1.5不仅将演讲内容准确完整地转写了出来,还根据演讲人的语气和内容,对相关语句进行了大写强调处理,提高了会议转写的效率。▲智东西实测体验音频转写
目前用户可以在魔搭社区体验该模型,开发者可以通过阿里云百炼平台调用API。https://modelscope.cn/studios/iic/FunAudio-ASRhttps://bailian.console.aliyun.com/cn-beijing?tab=model#/efm/model_experience_center/voice?modelId=fun-asr
Fun-ASR1.5可精准识别欧洲、东亚、东南亚、南亚及中东主流语种,覆盖中、英、日、韩、法、德、西、葡、俄、阿拉伯语等30种语言。▲ASR结果:저는 이 주제에 따라 한 말씀 드리자면, 사실 저희도 이전에 비슷한 상황을 겪은 적이 있습니다.▲ASR结果:Kejayaan projek ini tidak dapat dipisahkan daripada usaha pasukan, terutamanya kerja keras siang malam oleh jabatan penyelidikan dan pembangunan.▲ASR结果:La diversidad cultural es un tesoro invaluable para la sociedad humana, y debemos respetar y proteger todas las tradiciones culturales.在跨语言切换(Code-Switching)场景下,Fun-ASR1.5可以做到无需预设语种标签,就自动识别并切换,保证转写的准确性。比如,同一段对话里夹杂多种语言,模型也能准确识别,无需提前告诉它接下来要说哪种语言。▲ASR结果:We've all had that experience of finally visiting a place we've dreamed about for years,only to find that it doesn't quite live up to our expectations.There's even a term for this in one of the most visited cities in the world,Paris Syndrome.何年も前から行きたかった場所をやっと訪れてみたら、思っていたほどではなかったという経験は誰しもあることだと思います。技术团队介绍称,这种多语言能力,源于模型的架构和训练创新。Fun-ASR1.5采取MoE(混合专家)架构,模型内部可以分工协作,听到特定语言时仅激活相关部分进行处理,因而更为灵活高效。同时,技术团队在模型的训练阶段分级、分阶段地使用精准数据,也可以使模型更能适配真实世界中的复杂语音场景。
在中文本土化方面,基于数十万小时真实方言语音数据训练,技术团队称,Fun-ASR1.5的平均字错误率(CER)相比上一版本下降56.2%。▲ASR结果:现在发展了蛮快个现在伊拉用户算大户唻▲ASR结果:呃,那些吃的不就这样的土笋冻啊,我觉得不好吃。
▲ASR识别结果:但是一个人若是两三两百箍一百外箍安无算贵吧,吼自助餐啊,啊你也有肉咯也有菜咯也有水果咯也有甜点咯,啥物计有咯。
▲ASR结果:诶,其实可能有时候觉得去超市都几远下噶。此外,该模型不仅听得懂,还能“写得地道”,Fun-ASR1.5可原汁原味还原方言,如上海话的“侬”、苏州话“倷”(均指“你”),为下游模型处理方言文字提供了准确的基础语料。不同于现代口语,文言语法特殊、典故生僻字繁多,具有不少挑战。例如,文言语法简练,省略主谓宾;押韵严格,节奏固定(如五言、七言律诗);多用典故、异体字、古今异义词;诵读时存在拖腔、停顿、吟咏等非自然语流特征。Fun-ASR1.5对中文古诗词识别进行专项优化。研究团队构建了先秦至近代的古诗词语音-文本对齐语料库,涵盖《诗经》《楚辞》、李白杜甫诗集、苏轼辛弃疾词作等经典文本的真人诵读录音。在内部评测集中,Fun-ASR1.5对古诗词的字符级准确率达到97%,可应用于国学在线课程和有声诗词,助力文化传承。
▲ASR结果:子夏曰,博学而笃志,切问而近思,仁在其中矣。
语音识别最终都要落脚于生成可直接使用的文本,Fun-ASR1.5在后处理环节也重点优化了标点预测和文本归一化两项能力,大幅降低了会议纪要、新闻采访整理、法律笔录等场景的后期人工校对和编辑成本,具体如下:1、标点预测:更加智能模型基于上下文语义自动插入逗号、句号、问号、感叹号等标点,使转写结果接近书面表达。例如:输入语音:“今天天气怎么样啊我想出去走走但又怕下雨”输出文本:“今天天气怎么样啊?我想出去走走,但又怕下雨。”2、文本归一化(ITN)表现:进一步提升将口语中的非标准表达自动转换为规范格式:日期:“二零二六年三月二十九号” → “2026年3月29日”电话:“幺三八零零幺三八零零零” → “13800138000”
会议纪要、法律笔录等场景,长期处于“半自动”应用状态,核心痛点是AI识别结果需人工进行大量校对,不仅未能有效提升工作效率,还影响了实际工作推进。阿里Fun-ASR1.5针对这一痛点进行定向优化,补齐了传统语音识别的部分短板,也降低了各行业引入AI语音技术的门槛。目前,科大讯飞、百度、字节等企业的语音模型均在持续迭代,AI语音大模型正从技术研发逐步向实际应用推进,语音识别作为AI与人交互的重要入口,其实用性直接关系到行业落地的实际效果






 VIP复盘网
VIP复盘网