


新智元报道
新智元报道
【新智元导读】支撑Facebook Ads、Instagram Ads、Reels Ads等万亿级推荐系统的技术底座,正在经历一场由AI智能体驱动的自我重构。面对指数级增长的算力需求与自研芯片MTIA的大规模部署,传统的工程师调优模式已触及极限。Meta最新论文揭示了背后的秘密:一种基于树状思维链搜索的智能体框架,正在以「无人驾驶」的方式,在复杂的异构硬件上暴力重写Meta广告系统的底层内核。该论文揭示了如何用自动化代码生成, 将NVIDIA GPU, AMD和Meta Training and Inference Accelerator (MTIA)内核开发时间从数周压缩到数小时, 并在生产环境中实现最高17倍的性能提升。
在Meta的广告推荐业务中,深度学习推荐模型(DLRM)是支撑数十亿用户日常体验的核心技术。
然而, 随着业务规模的急剧扩张, 一个被称为「维度诅咒」的系统性难题正在成为制约发展的瓶颈。
这个难题由三个维度构成:
模型架构的多样性: 从传统的检索模型、粗排、精排模型,到基于Transformer的序列模型和生成式推荐模型,每种架构对计算的需求截然不同。
算子原语的多样性: 除了传统的矩阵乘法(GEMM)等密集计算算子, 推荐系统还依赖超过200种数据预处理算子包括特征提取、归一化、去重、掩码等操作。这些看似简单的算子, 在大规模部署中却至关重要。
硬件异构性: Meta的基础设施横跨多代NVIDIA GPU、AMD GPU, 以及自研的MTIA v1-v3加速器。每种硬件都有独特的内存层次、编程模型和架构特性, 代码无法直接移植。

图 1 展示了Meta自研的MTIA芯片。从宏观的数据中心布局到机架部署,再到微观的电路连接与芯片核心,多维度呈现了MTIA在提升AI负载性能与能效方面的先进设计。

图 2 展示了MTIA 2i架构详情。其核心为8×8的处理单元(PE)阵列,通过片上网络互联。每个PE集成了双RISC-V内核及四大专用硬件引擎:用于数据转换的MLU、矩阵运算的DPE、聚合计算的RE和向量处理的SIMD,并由命令处理器(CP)统一调度。
这三个维度相乘, 产生了数千种「模型-算子-硬件」的组合。
传统的手工优化方式下,一个经验丰富的内核工程师需要数周时间才能为单个组合完成高性能实现。这种开发模式在面对快速迭代的业务需求时, 已经难以为继。
面对这一挑战,Meta提出了一个基于智能体的内核代码生成框架KernelEvolve, 将内核优化过程重新定义为一个图搜索与进化的过程。

论文链接: https://arxiv.org/abs/2512.23236
KernelEvolve的设计灵感来自进化算法, 将内核优化建模为一个经典的搜索问题, 包含四个核心组件:
选择策略(Selection Policy): 基于Upper Confidence Bound (UCB) 的树搜索算法, 智能地选择最有希望的优化方向。系统会根据历史执行结果动态调整探索与利用的平衡。
通用算子(Universal Operator): 这是KernelEvolve的创新之处。不同于传统系统使用多个静态提示模板, KernelEvolve 采用单一的、动态适应的转换函数。该函数基于运行时上下文包括性能分析结果、错误信息、硬件约束和历史优化记录, 通过检索增强的方式动态合成提示, 使得大语言模型能够对正确性、性能和架构权衡进行整体推理。
适应度函数(Fitness Function): 综合评估内核的正确性和性能。系统不仅验证数值精度,还通过多层次的性能分析工具(从系统级到指令级)全面评估执行效率。
终止规则(Termination Rule): 当计算预算耗尽、优化进展停滞或达到性能阈值时,搜索过程自动终止。
这一突破性进展不仅震撼了硬件圈,更引起了全球AI权威观察家的震动。
Anthropic联合创始人Jack Clark在其影响深远的周刊《Import AI》(第 439 期)中,将KernelEvolve放在了头条位置进行深度剖析,他高度评价Meta正利用GPT、Claude和Llama/CWM等模型混合驱动来实现「万亿级基础设施的自动化」,并断言这预示着「LLM 智能体将成为异构AI系统的通用编译层」,开启了软件工程范式的深刻变革。

文章链接:https://jack-clark.net/2026/01/05/import-ai-439-ai-kernels-decentralized-training-and-universal-representations/

KernelEvolve的一个关键优势是其对多层次编程抽象的支持, 从高级 DSL 到底层硬件指令,覆盖了完整的软硬件优化栈:
Triton DSL: 用于快速原型和跨平台开发
CuTe DSL: 针对NVIDIA GPU的深度优化
硬件诊断语言: 针对MTIA等专有加速器的底层优化
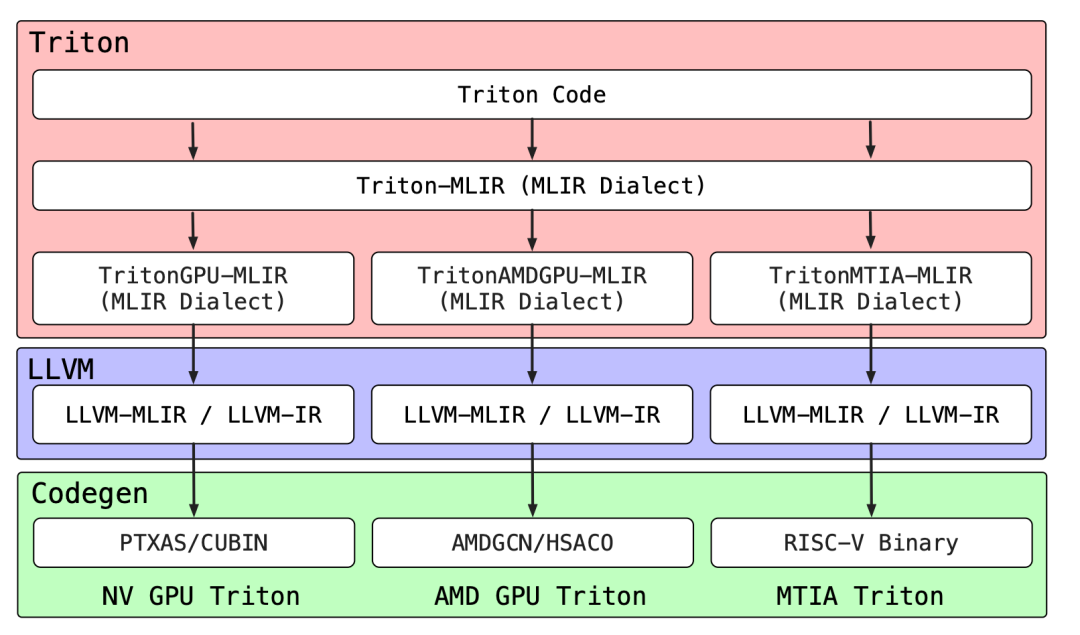
图 3 展示了Triton多目标编译架构。源代码通过MLIR进行逐层降级:从平台无关的Triton-MLIR,到针对特定硬件(GPU/AMDGPU/MTIA)的方言,最终生成支持NVIDIA (PTX)、AMD (AMDGCN) 以及MTIA (RISC-V)平台的原生二进制文件。
这种多层次设计使得KernelEvolve能够为每个硬件平台选择最合适的抽象层次。
更重要的是,系统集成了一个持久化的知识库,编码了各种硬件的特定约束和优化经验。这使得即使对于大语言模型训练语料中不存在的专有加速器,系统也能生成有效的内核代码。
KernelEvolve采用了复杂的智能体系统架构, 包含多个专门化的子智能体:
上下文记忆子智能体: 分析动态运行时信息(内核实现、性能测量、错误诊断), 诊断性能瓶颈并合成优化指令。
深度搜索子智能体: 当遇到复杂优化场景时, 执行更深入的搜索和分析。
硬件解释器: 为NVIDIA、AMD和MTIA平台提供专门的执行环境,确保代码在真实硬件上的准确评估。
LLM合成器: 生成动态提示,可以对接外部模型(Claude 4.5、GPT-5) 或Meta内部的Code World Model(CWM)模型。
系统还维护了一个完整的元数据存储,记录搜索树中每个节点的执行分数和父子关系,支持持续学习和优化策略的迭代改进。
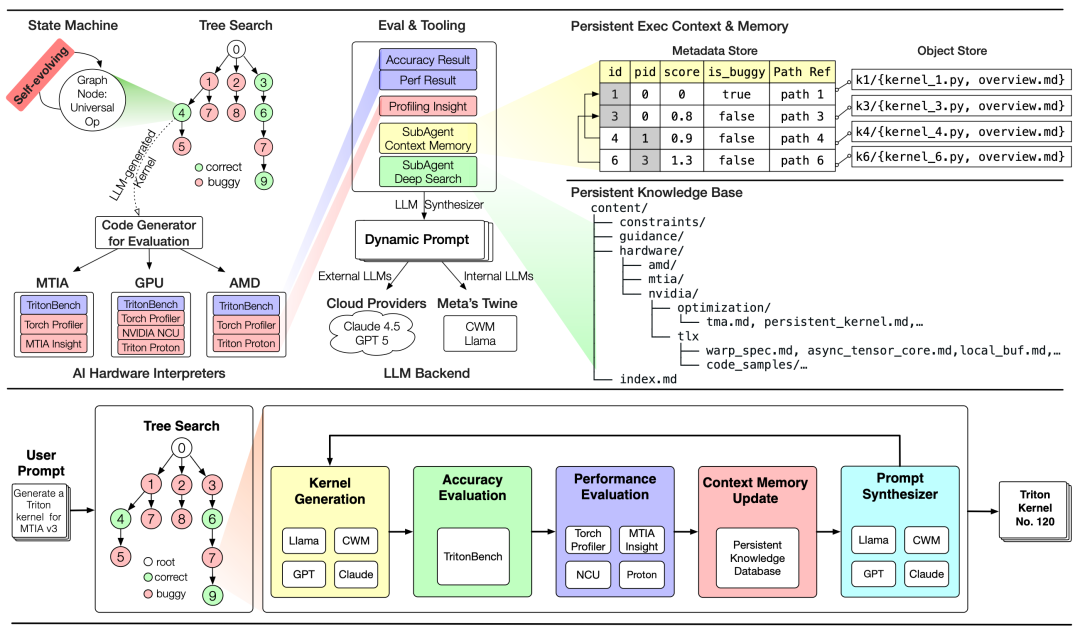
图4 展示了KernelEvolve的系统架构(上)与执行工作流(下)。该系统通过具备「自进化」能力的树搜索(Tree Search)状态机,协同子智能体、评估工具及AI硬件解释器(MTIA/GPU/AMD),利用Claude 4.5、GPT-5或Meta内部CWM等大模型后端动态生成Triton内核候选方案,并通过持久化知识库与元数据存储,实现内核优化的闭环探索与性能压榨。
如果说Tree Search是KernelEvolve的「大脑」,那么端到端评估流水线就是它的「神经反射弧」。
Meta并没有简单地将代码扔给编译器,而是构建了一套极其严密的自动化验证与性能反馈闭环。KernelEvolve 的完整工作流程体现了其工程化的严谨性。整个系统分为三个主要模块,形成一个闭环的优化过程:

这是整个系统的「大脑」, 维护着一棵动态演进的搜索树。树的每个节点代表一个内核候选方案,包含PyTorch基线实现和Triton优化版本的双重实现。
系统通过在多组相同输入下对比两者的输出结果,确保AI生成的内核在数学逻辑上与原生代码100%一致,从根源上解决了大模型生成代码可能带来的准确性风险。搜索引擎通过UCB策略在树中游走, 不断探索新的优化路径。当需要生成新的候选方案时, 系统会调用非LLM静态代码生成器, 基于模板快速生成标准化的评估框架代码。
这是系统的「创造力来源」,生成的代码会被送入专门的工具链进行编译和性能分析。
值得注意的是, KernelEvolve采用了多层次、多维度的评估策略: TritonBench验证功能正确性, Torch Profiler提供系统级性能视图, NVIDIA NCU深入到GPU指令级分析, Triton Proton工具测量内核内部延迟, MTIA Insight则针对 Meta 自研芯片提供专属诊断。这些性能分析工具产生的反馈会重新输入搜索引擎, 指导下一轮迭代。
这是系统的「试验场」,KernelEvolve为每种硬件平台配备了专门的解释器。每个解释器都能实时采集硬件特定的性能指标,比如GPU显存吞吐量、L2缓存命中率、计算单元利用率等细粒度数据,甚至还能追踪到具体的停顿指令。
这些硬件级洞察为LLM提供了宝贵的优化线索。
整个流程形成了一个「生成-评估-反馈」的自适应循环: 搜索引擎选择候选节点 → 代码生成工具链产出实现 → 硬件解释器执行并采集性能数据 → 多维度分析工具提供诊断反馈 → 搜索引擎根据反馈调整策略。
这种紧密集成的评估管线, 让 KernelEvolve 能够在数小时内完成人类工程师需要数周才能完成的优化探索。
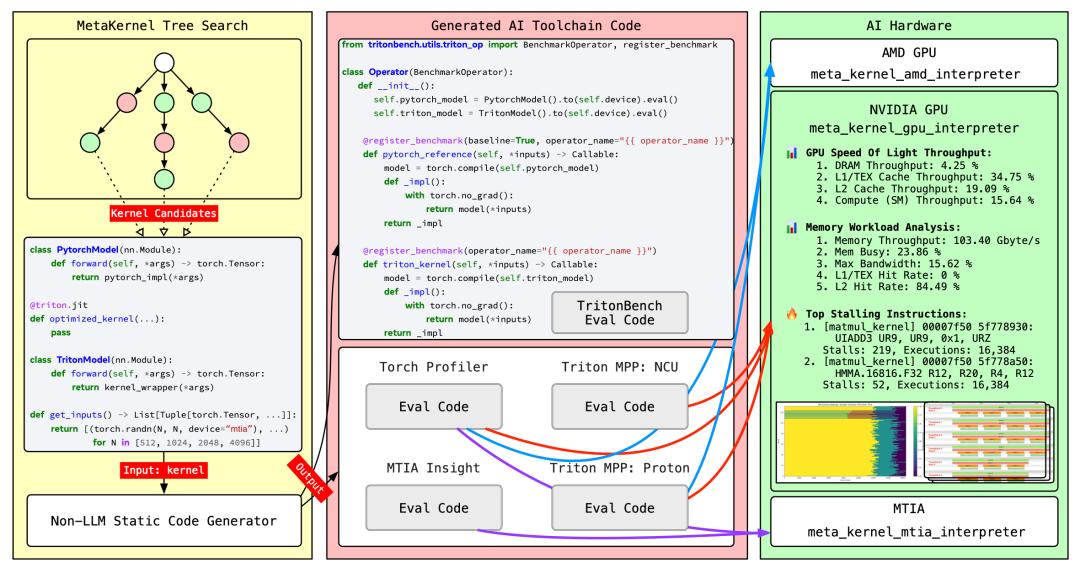
图5 展示了端到端评估流水线:系统通过树搜索(Tree Search)生成具备标准双实现(PyTorch 基准与 Triton 优化)的候选内核,并在专用的硬件解释器(GPU、AMD、MTIA)上执行。利用 TritonBench、NCU、MPP 和 MTIA Insight 等工具收集平台特定的性能剖析指标(Profiling metrics),其反馈结果将直接指导后续的搜索迭代。为了实现跨异构加速器的自动化评估,AlphaKernel 基于 Meta 的 Bento 平台构建了集成了完整软件栈、编译工具链和运行时依赖的标准化解释器环境。
KernelEvolve的有效性在多个层面得到了验证。
在公开的KernelBench测试集上, KernelEvolve 展现了卓越的鲁棒性:
在三个难度级别的全部250个问题上达到100%通过率
在三个异构硬件平台上测试160个PyTorch ATen算子
480个「算子-平台」配置全部正确,准确率100%
更令人印象深刻的是在Meta真实生产环境中的表现:
性能提升: 在多样化的广告训练和推理工作负载中,KernelEvolve生成的内核相比PyTorch基线实现了1.25至17倍的加速。这证明自动化合成的代码可以超越最先进的编译器生成代码。
开发效率: 将内核开发时间从数周压缩到数小时,极大降低了新模型部署和硬件适配的时间成本。
硬件支持: 成功为NVIDIA多代GPU、AMD GPU和Meta自研的MTIA v3加速器生成了高质量内核,显著降低了新硬件的编程门槛。
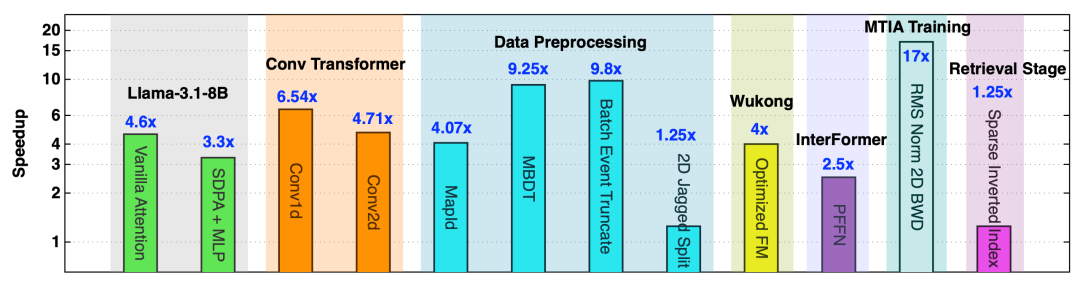
图6 展示了KernelEvolve在异构AI硬件上的卓越性能。相比传统方案,它在卷积 Transformer、数据预处理算子及推荐系统等Meta核心生产场景中,实现了1.25倍至17倍的加速。
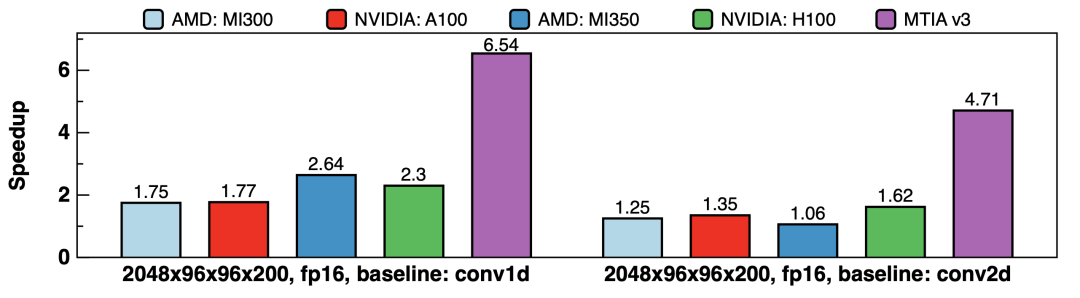
图7 展示了在Meta的生产环境场景中,针对Convolutional Transformer的张量形状,KernelEvolve生成内核与PyTorch原生算子的对比 (atol=10^−4, rtol=5×10^−4)。在 NVIDIA、AMD 和 MTIA 架构上,其生成的内核相比conv1d基准和优化后的conv2d基准,最高实现了6.22倍的加速。
对于像MTIA这样的专有加速器,传统的开发流程面临更大挑战,相关的编程范式和优化技巧并未包含在主流大模型的训练数据中。
KernelEvolve通过知识库注入硬件特定约束的方式,成功解决了这一问题,这意味着即使是全新的、文档稀缺的硬件平台,也能快速获得高性能的算子库支持。
KernelEvolve的意义不仅在于提升了单个内核的性能,更在于它改变了整个推荐系统基础设施的开发范式:
完整的算子覆盖: 通过自动化生成,KernelEvolve能够快速实现完整的算子矩阵,使得模型可以在单一加速器上整体部署, 避免了分离式架构带来的系统级开销。
持续优化循环: 系统的搜索树和知识库会不断积累优化经验, 形成正向循环。每次优化不仅解决当前问题, 还为未来的优化提供了参考。
降低创新门槛: 新的模型架构或硬件平台不再受限于内核开发的瓶颈, 研究人员和工程师可以更快地将创新想法付诸实践。
KernelEvolve的成功为AI系统优化领域带来了几个重要启示:
智能体的有效性: 将复杂的工程问题建模为搜索和优化过程, 通过智能体进行自动化求解, 在异构硬件(HH)等复杂解空间中可以达到甚至超越人类专家的水平。
知识与推理的结合:通过检索增强和知识库注入,有效扩展了大语言模型(LLM)的能力边界,使其能够精准处理 MTIA 等专有硬件架构的底层约束。
多层次抽象的价值: 支持从高级DSL(如 Triton)到底层指令的多层次优化,使得系统在保持快速迭代的同时,能实现对硬件性能的精细压榨。
生产部署的挑战: 论文也分享了在生产环境中操作KernelEvolve的实践经验,包括失败模式分析、调试策略、性能验证方法论和组织整合模式, 为后续研究提供了宝贵参考。
展望未来,KernelEvolve正在开启基础设施演进的新篇章:
迈向Agentic RL:未来的演进方向将引入Online Agentic Reinforcement Learning(在线智能体强化学习)。这意味着系统能根据生产环境中的运行时负载(Live Workloads)和硬件遥测数据,动态调整搜索策略和奖励函数,实现内核性能的「热进化」。
适配下一代MTIA架构:随着Meta自研芯片的快速迭代,KernelEvolve将成为下一代MTIA研发中的核心组件。通过硬件与软件智能体的深度协同(Co-design),在芯片流片前即可通过仿真环境进化出最优算子库,极大缩短新硬件的TTM(上市时间,time to market)
软件工程范式的深刻变革:自动化代码优化将从内核编程扩展到更广泛的系统软件领域。我们或许正在见证从人工编写到智能体辅助,再到智能体主导(Agent-Led)的演进路径。
对于Meta而言, KernelEvolve不仅是一个技术工具, 更是其在AI基础设施领域保持竞争优势的战略投资。
在万亿级广告推荐系统的支撑下,每一个百分点的性能提升都意味着巨大的商业价值,而KernelEvolve所展现的, 正是用AI重构AI基础设施的无限可能。
Gang Liao
Meta研究科学家 (Research Scientist) 马里兰大学(UMD)计算机博士,师从数据库传奇人物Daniel Abadi。 他是Meta广告与推理基础设施领域的底层优化专家,曾在百度、字节跳动及微软研究院担任核心角色,致力于推动支撑Meta 98% 年收入处理的底层基础设施优化。
Carole-Jean Wu
Meta FAIR 研究总监 (Director of AI Research) 领导系统和机器学习研究团队,同时担任MLCommons创始成员兼副主席。她拥有普林斯顿大学博士学位,曾任亚利桑那州立大学终身教授。她的研究聚焦于计算机体系结构与机器学习的交叉领域,曾获ACM SIGARCH Maurice Wilkes 奖等顶级荣誉,是 ISCA和HPCA名人堂成员,她同时担任了MLSys'22和ISCA'26 机器学习系统和体系结构顶级会议联名主席。
Gaoxiang Liu
Meta杰出工程师 (Distinguished Engineer) Meta广告服务系统和推理引擎的核心掌舵人,毕业于密歇根大学安娜堡分校。他共同领导了Meta 全公司范围内的现代化推理平台建设,主导设计了支撑 LLM 规模推荐模型的下一代广告服务系统。作为商业化 AI 硬件项目的技术负责人,他深度参与了 MTIA 的协同设计,构建了实现异构硬件(Nvidia GPU/AMD GPU/MTIA) 「可互换性」的架构栈。
这一里程碑的达成离不开Meta内部各团队的卓越协作, 包括Monetization Infra and Ranking (商业化基础设施与排序), FAIR (基础人工智能研究中心), Compiler (编译器), MTIA, Serverless Compute (无服务器计算) 等团队。

 VIP复盘网
VIP复盘网
