

AI产业正加速迈向以推理需求扩张和生产力场景落地为核心的新阶段。模型层竞争焦点转向复杂与长程任务的交付;Agent加速落地持续推高算力总需求,带动CPU、AI互联、超节点、云服务及国产算力产业链景气全面上行;Infra层面边缘云正逐步成为承接AI应用落地的关键基础设施;Physical AI正从技术验证稳步迈入产业化阶段。我们持续看好三大主线:头部模型环节;算力通胀链条/国产算力链,短期关注算力租赁/云等环节,中期持续看好全球算力产业链上游的GPU/存储/互联环节以及国产算力链;AI应用环节重点看好营收和利润有望双提速的标的。
AI模型:全球模型迭代加速
AI模型演进延续向复杂任务执行深化的主线,国内外厂商均在推动模型从能力展示走向任务闭环与产品落地。DeepSeek或进一步强调国产化软硬件适配,有望带来推理侧算力国产替代的拐点;海外模型强化开发平台生态、流量场景闭环与企业级安全交付。我们认为,模型竞争正从通用能力比拼转向复杂任务交付、场景适配与商业化路径竞争,多Agent、多模态与工具调用协同深度,以及国产算力生态适配,仍是后续重要观察变量。
AI算力:Agent推动算力需求扩散,云涨价与国产替代强化
我们判断,Agent加速落地正推动AI算力需求由训练向推理持续外溢,CPU、互联、超节点与云服务等基础设施环节随之进入系统性重构阶段。CPU在AI工作流中的重要性持续提升,互联侧CPO与OCS落地节奏加速,光芯片供需差持续扩大;云服务进入涨价周期,算力资源稀缺性进一步强化。在此背景下,国产模型与国产硬件协同优化持续推进,国产加速卡与超节点方案进入密集落地阶段,国内算力景气度与国产替代进程均有望持续强化。
AI Infra:AI应用推理下沉,边缘云景气上行
我们观察到推理需求开始随着Agent落地向边缘侧持续下沉,随着AI应用从训练驱动逐步转向推理驱动,边缘云战略地位持续提升。海外相关公司持续完善边缘AI平台布局并取得大额订单,边缘云商业化已率先进入落地阶段;国内OpenClaw带动Agent应用提速,网宿等厂商已初步具备边缘AI平台能力,边缘云有望在AI应用放量过程中快速受益。
Physical AI:世界模型赋能,AI迈入物理世界
我们认为,AI正进一步走向对物理世界的感知、决策与执行,Physical AI有望成为下一阶段的重要演进方向。我们观察到,自动驾驶有望突破长尾场景瓶颈并加快商业化落地,具身智能则有望在合成数据、仿真训练和量产推进带动下持续演进。基于Physical AI规模化落地与高景气趋势,我们看好世界模型与仿真平台、自动驾驶物理AI化及英伟达生态链三条主线。
我们与市场不同的观点
市场担忧本轮算力主升浪后续动能不足,我们关注到,CPU环节市场表现较其他算力环节偏弱,同时市场对边缘云商业化节奏的预期可能存在低估。我们认为算力景气并未见顶,Agent落地有望持续推高需求,推动云服务涨价,国产替代加速推进,5月CSP厂商Token消耗数据有望成为第二波主升浪的重要催化;CPU滞涨构成预期差,Agentic AI驱动需求扩张,补涨行情有望演绎;边缘云商业化节奏正在加快,我们持续看好相关主线景气上行。
风险提示:宏观经济波动,技术进步不及预期,中美竞争加剧。研报中涉及到未上市公司或未覆盖个股内容,均系对其客观公开信息的整理,并不代表本研究团队对该公司、该股票的推荐或覆盖。
投资观点
我们持续看好三大主线:头部模型环节;算力通胀链条/国产算力链,短期关注算力租赁/云等环节,中期持续看好全球算力产业链上游的GPU/存储/互联环节以及国产算力链;AI应用环节重点看好营收和利润有望双提速的标的。
模型侧,我们看好具备基础模型和Agent执行能力的平台型厂商。模型竞争正从能力展示转向闭环交付与商业兑现,行业主线已由单一Benchmark表现逐步转向“基座能力升级—多模态补齐—工具调用增强—Agent执行闭环—产品与生态落地”的连续验证过程。国内智谱、MiniMax围绕长程任务执行与自反馈训练闭环持续推进,DeepSeek V4或进一步强调国产化软硬件适配,有望带来推理侧算力国产替代的拐点;海外Google、Meta、Anthropic分别强化开发平台生态、流量场景闭环与企业级安全交付。我们认为,既能持续提升长程任务、复杂推理与多模态能力,又能打通产品入口、开发者生态、企业交付及国产软硬件适配的平台型厂商,具备更高的产业跟踪价值。
算力层面,Agent推动算力需求扩散,建议关注算力通胀链条相关行业环节,重视国产算力芯片与超节点产业链机会。算力层本轮需求扩张已从单一训练侧拉动演进为训练、推理、部署全链条共振驱动的系统性重构。Agentic AI加速落地推动需求由训练向推理持续外溢,CPU供需失衡短期难以缓解、价格中枢上行趋势确立,CPO与OCS落地节奏加速,磷化铟光芯片供需缺口在Scale out与Scale up双轮驱动下持续扩大,云服务从CDN、存储到AI算力逐层提价,本质是算力稀缺性的重新定价。DeepSeek V4若深度适配国产算力,有望成为国产替代加速的非线性催化,国产加速卡与超节点方案有望进入密集落地阶段。中期视角下,当全球总Token消耗量的指数级增长获得大众层面的感知验证,算力产业链有望开启第二波主升浪,节奏或仍将沿GPU(PCB/光模块)—ASIC—存储—先进制程—CPU—云服务—IDC依次演绎。
Infra与Physical AI同步进入景气上行通道,建议关注边缘云、Physical机会,看好AI应用环节营收/利润双提速的标的。推理需求向边缘侧下沉推动云服务架构向云、边、端协同的分布式体系升级,边缘云战略地位持续提升,海外Akamai、Cloudflare商业化已率先落地,边缘云有望在AI应用放量过程中快速受益。Physical AI方面,世界模型对自动驾驶与具身智能的赋能路径进一步清晰,自动驾驶有望突破长尾场景瓶颈并加快商业化落地,2026年人形机器人全面进入量产阶段,行业从技术验证稳步迈入产业化阶段。AI应用侧,26年投资策略聚焦寻找营收/利润双提速的标的。
与市场不同的观点
市场担忧本轮算力主升浪后续动能不足,我们关注到,CPU环节市场表现较其他算力环节偏弱,同时市场对边缘云商业化节奏的预期也可能存在低估。我们认为,算力景气并未见顶,Agent加速落地持续推高算力总需求,云服务涨价周期已经开启,国产算力替代进程加速推进,第二波主升浪的核心催化剂在于全球总Token消耗量是否指数级增长并获得大众层面的感知验证,5月份全球CSP厂商对Token消耗量的数据公布值得重点关注。CPU环节行情的相对滞涨恰恰构成预期差,Agentic AI驱动CPU需求结构性扩张,Intel管理层已坦承此前低估了AI场景对CPU的需求,补涨行情有望演绎。边缘云商业化节奏正在加快,海外Akamai、Cloudflare已率先落地大额订单,我们持续看好相关主线的景气上行趋势。
AI模型:全球模型迭代加速
国内模型:从基座升级走向任务执行闭环
智谱:基座、视觉与产品入口协同推进
智谱本轮迭代以Agent场景为核心,推动基座能力、多模态能力及执行能力同步提升。据Z.ai官网3月15日发布说明,GLM-5-Turbo面向高吞吐OpenClaw类任务,强化Tool Calling、复杂指令拆解、定时与持续性任务及长链路执行能力;据4月1日发布说明,GLM-5V-Turbo补足视觉能力,可理解界面、设计稿、图表与文档,并强化多模态工具调用与GUI任务执行;根据4月7日发布说明,GLM-5.1面向Long-Horizon Task,支持单次运行最长8小时,形成从规划、执行到迭代优化的完整任务链路。模型能力呈现出由单点提升向多能力协同演进的特征。
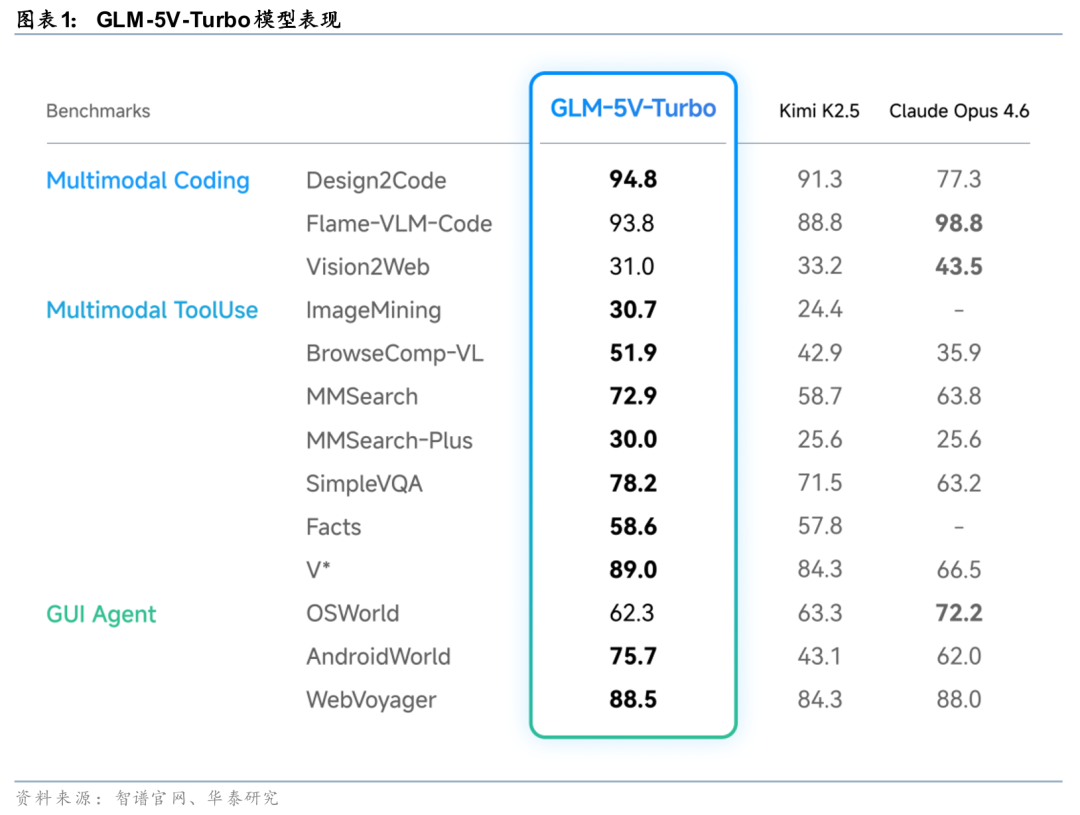
智谱产品化路径逐步清晰并延伸至执行体系。在模型能力持续提升基础上,智谱产品化路径逐步明确。据Z.ai开发者文档与产品介绍,AutoClaw支持多模型接入,并通过视觉能力、浏览器执行及Skill调用扩展复杂工作流;据智谱AI官方微信公众号披露,GLM-5-Turbo已接入机械革命“龙虾盒子”,推动AI Agent终端形态落地。整体路径与“模型升级—工具增强—产品落地”的逻辑一致,显示其正在构建面向开发者与企业的任务执行体系。
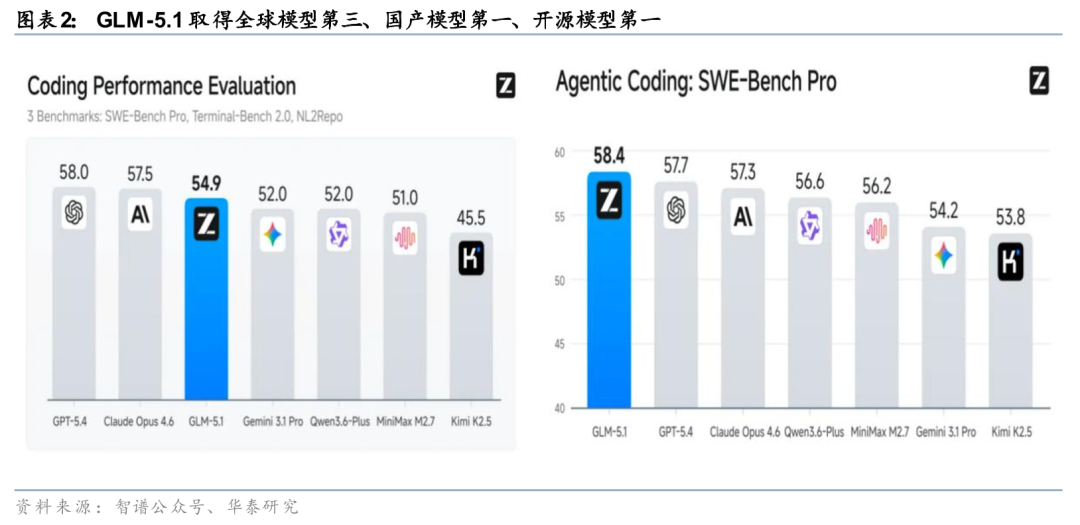
长程任务与多模态能力拓展应用边界。长时程任务能力与多模态能力的同步提升,推动模型应用边界持续拓展。据智谱AI官方X账号与官方博客4月8日披露,GLM-5.1在SWE-Bench Pro、Terminal-Bench及NL2Repo等评测中位列开源模型前列,并支持单次任务持续运行超过8小时;据智谱AI官方微信公众号4月1日披露,GLM-5V-Turbo在预训练阶段实现视觉与文本深度融合,并通过CogViT视觉编码器提升物体识别、空间理解与细粒度分析能力,在PinchBench、ClawEval及ZClawBench等评测中取得较好表现。在应用层面,模型已在AutoClaw中支持“股票分析师”等Skill,可解析K线图、估值图及研报图表,实现多源数据并行处理并输出图文结合结果。
MiniMax:模型开始参与自身演进
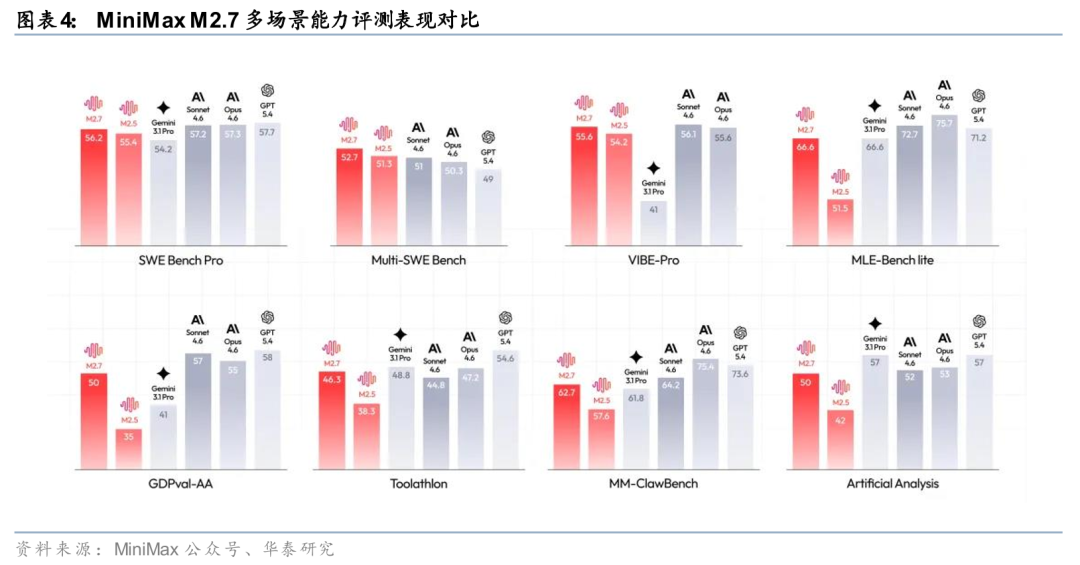
MiniMax推动模型参与自身演进形成研发闭环。MiniMax本轮迭代的核心在于模型参与自身研发过程。据MiniMax官网3月18日发布信息,M2.7能够构建复杂Agent Harness,并通过Agent Teams、复杂Skills与Tool Search完成高复杂度生产力任务;在模型训练过程中,M2.7被用于更新memory、辅助强化学习实验并反向优化Harness与训练流程。同时,官网披露M2.7在SWE-Pro、VIBE-Pro、Terminal Bench 2及GDPval-AA等任务中表现较好,体现出其在软件工程与专业场景中的综合交付能力。
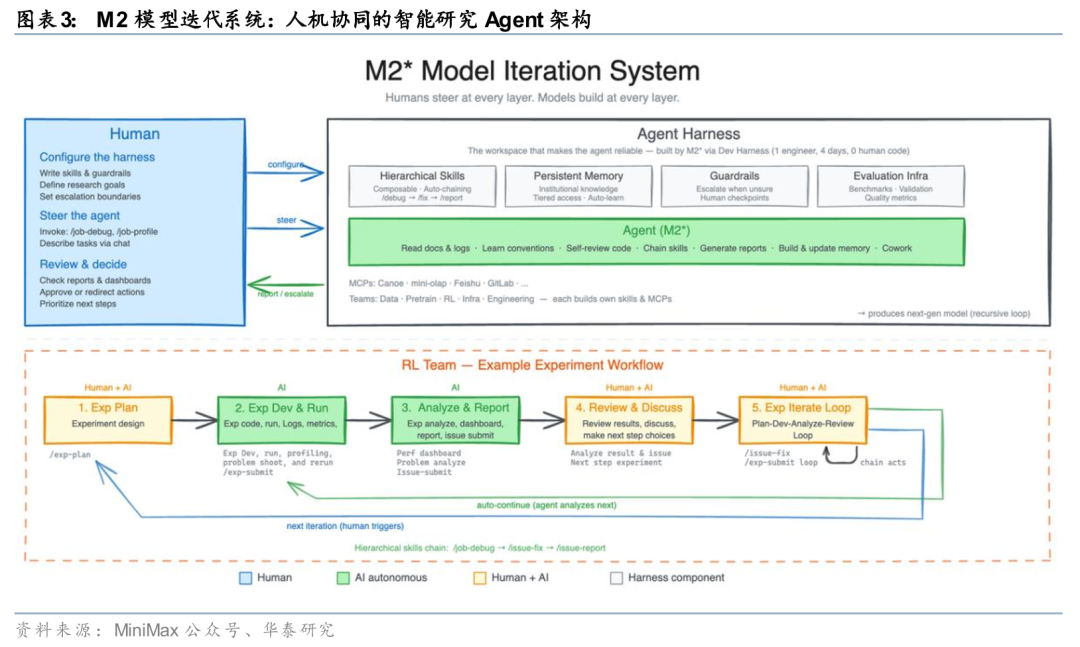
MiniMax构建Agent贯穿研发全流程能力体系。MiniMax通过Agent体系将模型能力延伸至研发全流程。据MiniMax官网披露,M2.7在MLE Bench Lite的22个机器学习任务中进行验证,覆盖数据构建、模型训练、推理架构及评测等关键环节;模型在执行过程中能够自主构建所需技能模块,并基于任务结果动态调整执行路径与策略,实现对复杂研发流程的端到端参与。该体系使模型由单一能力工具向研发流程参与主体转变。
记忆与自反馈机制推动训练范式演进。记忆、自反馈与自优化机制成为MiniMax训练体系的重要组成。据MiniMax官网披露,其核心框架包括:1)通过短时记忆记录每轮任务结果;2)通过自反馈机制对当前输出进行评估并提出改进方向;3)基于历史记忆与反馈链实现下一轮自优化。该机制使模型在多轮迭代中持续积累经验并改善表现,推动训练模式向模型参与优化演进。
小米:多模态底座加速补位Agent场景
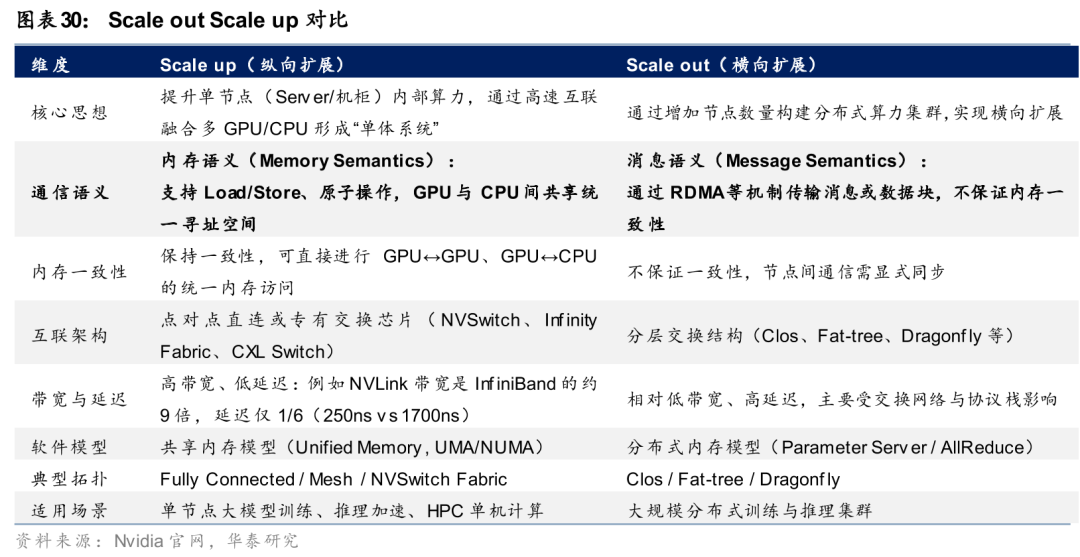
小米加速补齐多模态能力并强化Agent场景定位。小米本轮模型推进重点在于多模态底座补齐与Agent场景强化。据小米官方微信公众号披露,其推出MiMo系列模型并持续迭代,其中MiMo-V2-Pro明确定位于高强度Agent场景,强调在复杂任务中的执行能力。同时,小米在语音方向推出MiMo-V2-TTS,基于自研Audio Tokenizer与多码本语音-文本联合建模架构,提升语音生成的自然度与稳定性,推动多模态能力向实际交互场景延伸。整体来看,小米正从单一模态能力向语音、视觉与文本融合的多模态体系过渡。
围绕AIoT生态推进模型落地路径。小米模型推进路径与其硬件生态深度绑定。根据产品定位信息,MiMo系列模型能力优先服务于其终端设备与AIoT体系,通过端侧与云侧协同实现能力落地。从结构上看,其通过“模型能力—终端设备—用户场景”的联动,将语音、多模态理解与Agent执行能力嵌入智能硬件使用流程中,使模型不仅承担理解与生成功能,同时参与实际任务执行,强化应用闭环与用户触达能力。
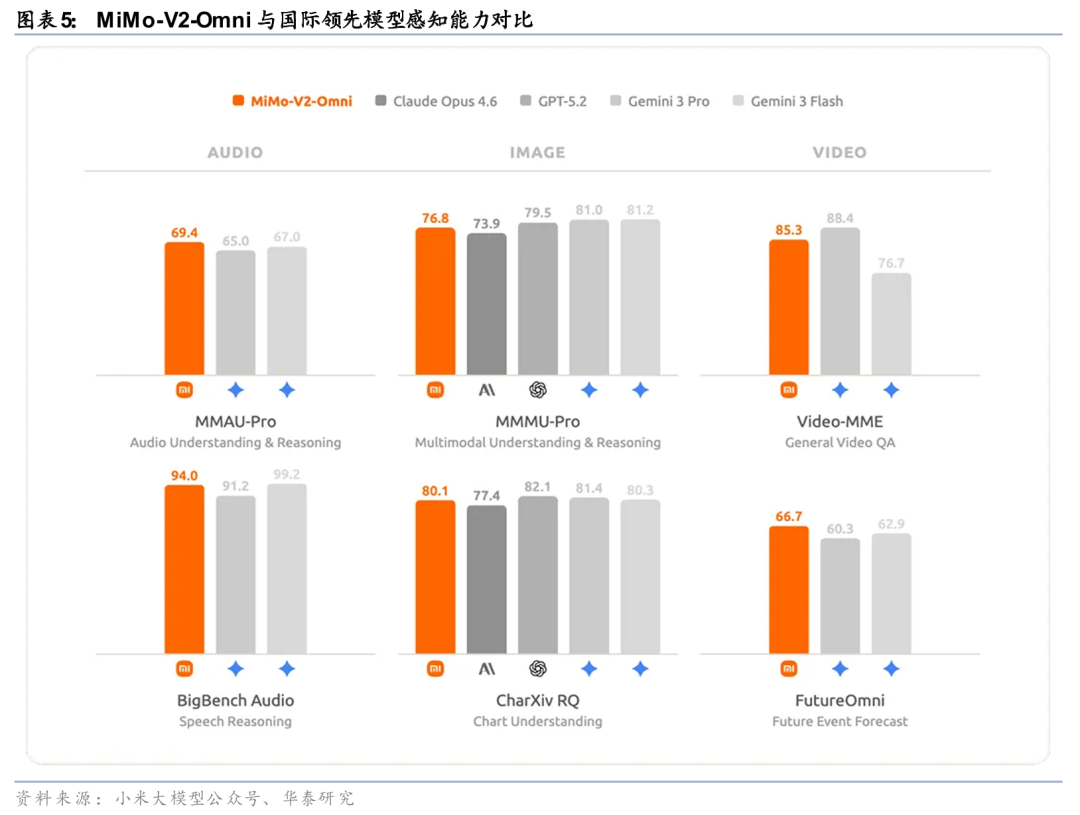
多模态底座叠加终端入口为端侧Agent落地奠定基础。在模型体系构建基础上,小米进一步将能力与终端生态结合。据小米官方微信公众号披露,上述模型能力将服务于其终端设备与AIoT生态,通过统一模型底座实现语音、视觉与文本能力在实际场景中的协同调用。从路径上看,多模态能力提供感知基础,Agent能力负责任务执行,而终端入口与系统权限则提供落地环境与数据闭环,为后续端侧Agent的实际应用奠定基础。该模式体现出模型能力与硬件生态协同推进的特征。
DeepSeek:国产化软硬件适配或是V4重点
DeepSeek V4的核心看点或是国产软硬件适配,而非单纯的能力抬升。4月3日,据The Information信息,DeepSeek新一代模型V4预计将在未来数周发布,且过去数月一直与华为、寒武纪合作,重写部分底层代码模块,以确保模型能够在国产芯片上稳定运行;同时,DeepSeek并未按行业惯例向美国芯片厂商提供早期优化访问权限,而是优先向国内供应链开放。由此看,V4更像是在外部算力约束与国产替代诉求下,对模型底座、推理路径与部署体系进行的一次系统性重构。这次DeepSeek V4更新重点或不在于能力提升,而在于国产软硬件的适配。
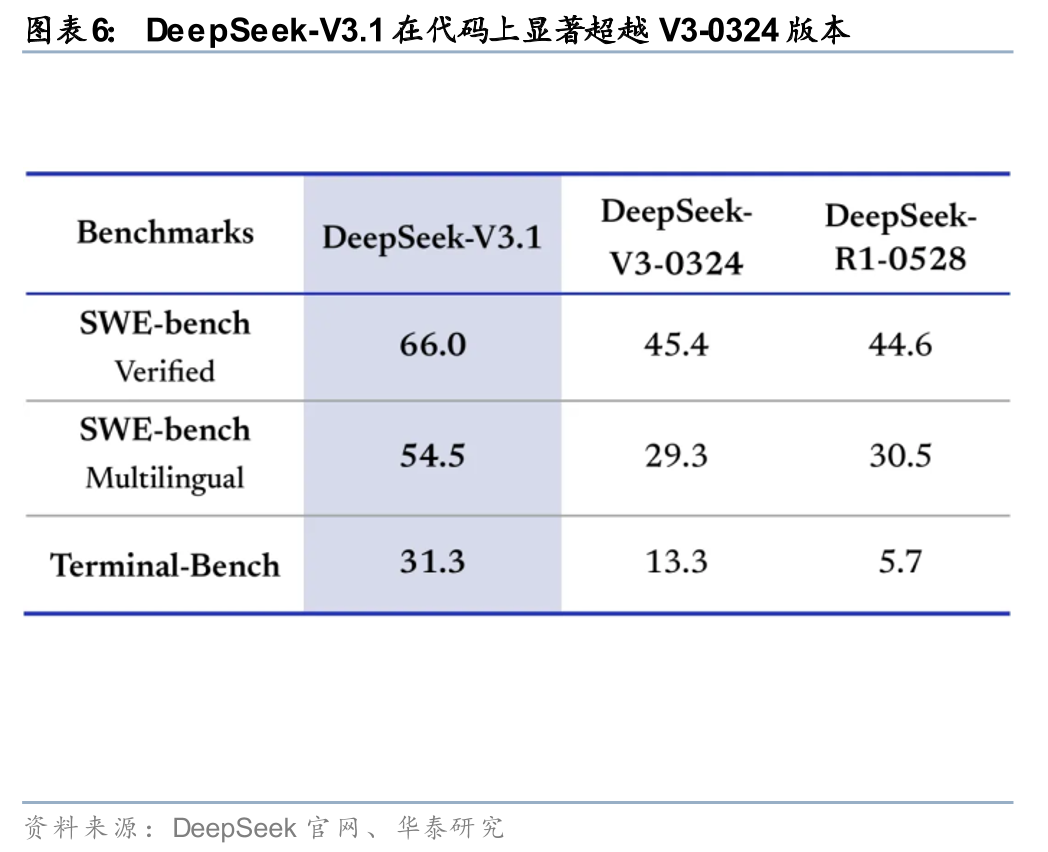
DeepSeek近几轮技术演进,已经预示出这一方向。据DeepSeek官网信息,2025年8月的DeepSeek-V3.1重点是混合推理架构、Agent能力增强与推理效率改善;9月的DeepSeek-V3.2-Exp则在公开评测表现与V3.1-Terminus基本相当的前提下,引入DSA稀疏注意力,用于提升长上下文场景下的训练与推理效率,并同步开放TileLang内核用于研究与快速原型开发。这意味着DeepSeek近期更新的主线,并不是持续追求单轮版本在Benchmark上的大幅跳升,而是围绕效率、工具使用、长上下文与底层算子栈迁移能力做铺垫,从而为国产生态承接更复杂模型服务创造条件。
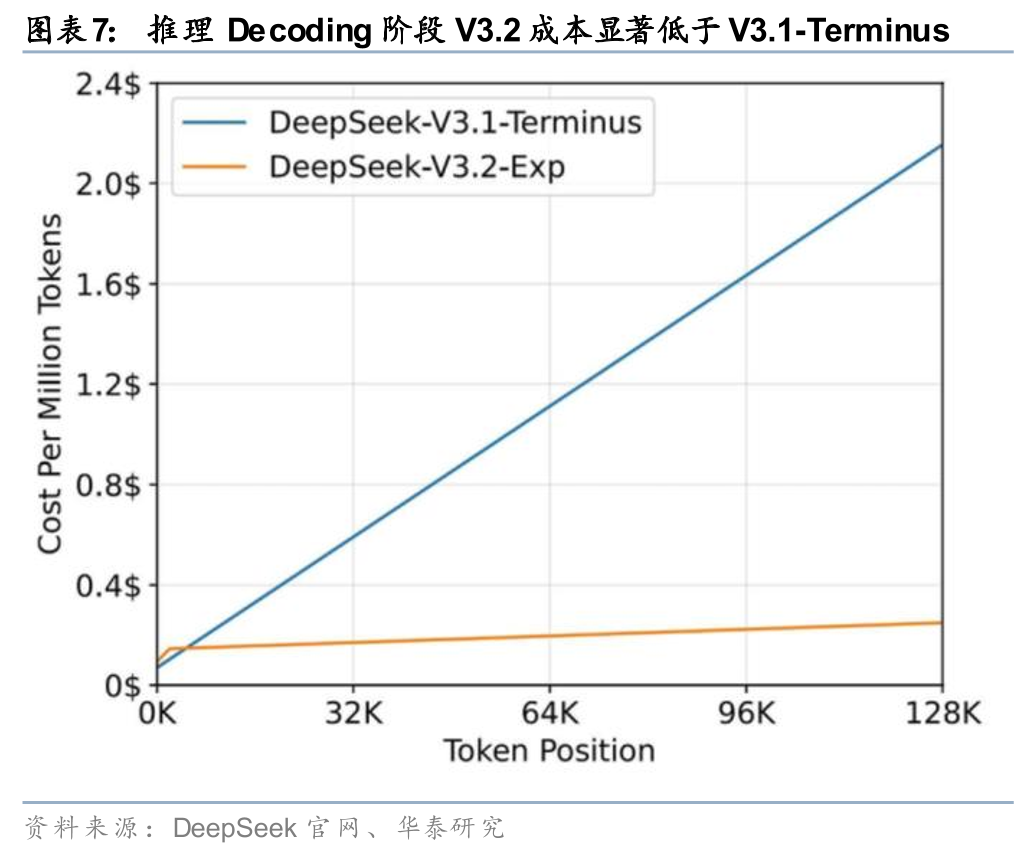
V4对国产生态的意义,还在于它可能标志着DeepSeek从“依赖英伟达”走向“先完成推理侧国产替代”的现实拐点。3月27日,据Reuters信息,国内950PR较前代产品对CUDA体系更友好,样片已于1月送测,量产预计随后启动;面向模型训练和解码阶段的950DT预计在2026年四季度推出。V4当前更现实的突破方向,或是率先实现推理部署侧的国产化闭环,再为训练侧迁移逐步铺路,这比单一能力分数的变化更值得重视。
DeepSeek的组织文化与资源配置,或也一定程度上侧面印证了V4或押注在适配与原创架构上。据晚点LatePost信息,DeepSeek人数已超过幻方时期规模,梁文锋深度参与基础模型架构定版,基础模型架构、Infra与数据团队各有小几十人;公司内部没有明确绩效考核和DDL,延续“自然分工”机制,且仍保留对长周期研究的投入。与此同时,团队已开始重视产品化与商业化,但C端目前仍以Chatbot为主,尚未全面进入AI编程和通用Agent等热门应用方向。这种组织形态决定了DeepSeek并不急于在每一轮版本上做外显能力冲刺,而更倾向于把有限资源投向基础架构、系统效率和生态兼容这些更长期的变量。
从《南华早报》在26年4月8日发布的DeepSeek新模式测试结果来看,V4仍处于“发布窗口临近、形态逐步浮现、能力边界尚未完全确认”的阶段。目前,DeepSeek新模型或已在部分用户中测试,界面或包含快速模式、专家模式与视觉模式,能力上更偏向多模态推理和Agent体系补齐;或存在接近300B的先行版本,以及更大参数版本后续推出的可能。但无论具体参数规模如何变化,V4更值得跟踪的验证指标,不是单一评测榜单名次,而是其在国产算力及软件栈上的可用性、稳定性、成本效率和开发者迁移门槛能否形成闭环。我们认为,若这一闭环成立,V4的产业意义将明显高于一次常规模型升级。
海外模型:平台生态、流量闭环与安全交付三线并进
Google:闭源强化工具协同,开源扩展生态覆盖能力
Google在闭源旗舰与开源模型两端同步推进,强化Agent生态与开发者覆盖。据Google官方Gemini API更新日志,2月19日发布Gemini 3.1 Pro Preview,并推出gemini-3.1-pro-preview-customtools端点,以增强bash与自定义工具混合调用场景的可用性;据Google于2025年11月发布的Gemini 3官方博客,Gemini 3系列已将推理、工具使用、长时程规划与开发者工作流作为核心能力方向。结合本期更新节奏,Google正将旗舰模型由“强推理”进一步延伸至“强推理 强工具协同”的开发平台能力。
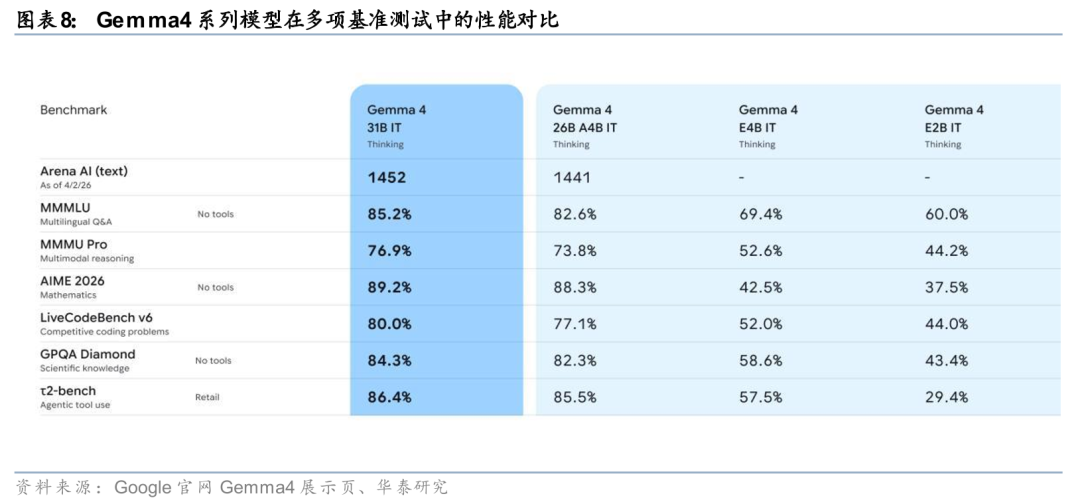
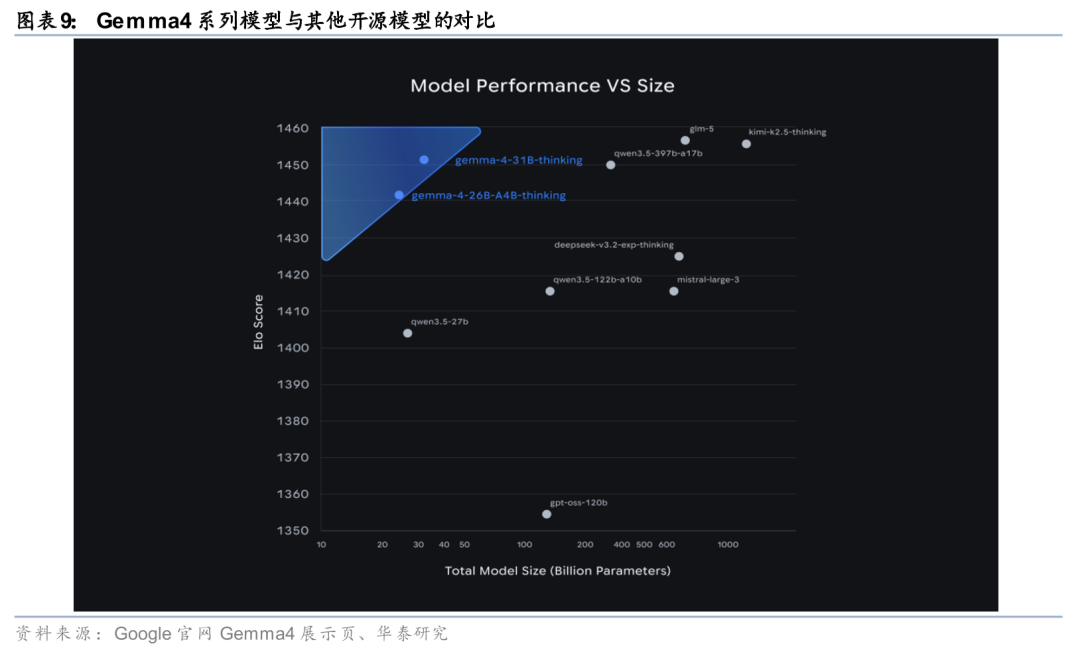
开源模型Gemma 4通过多规格与工具能力下沉扩大开发者生态。Google在开源侧同步推进模型能力扩散。据Google官网4月2日发布信息,Gemma 4沿用Gemini 3同源研究成果,采用Apache 2.0许可,提供31B Dense、26B MoE、E4B与E2B四个尺寸,其中大模型支持最高256K上下文,并原生支持函数调用与结构化JSON输出,边缘侧小模型则强调离线运行、低时延及音频输入能力。官方同时披露,31B模型在Arena AI开源模型文本榜单位列第3,26B模型位列第6,并可在单张80GB H100上运行未量化权重。整体来看,Gemma 4通过模型规格分层与工具能力下沉,推动Agent开发能力向更广泛开发者群体扩展。
Meta:以Muse Spark打通模型能力与流量入口闭环
Meta通过Muse Spark推动模型能力与自有流量场景的深度融合。据Meta AI官网4月9日博客,Muse Spark为Meta Superintelligence Labs推出的首个前沿模型,定位为原生多模态推理模型,支持文本与视觉输入、文本输出,并具备工具使用、视觉思维链及多代理编排能力;据文中转引Artificial Analysis信息,该模型采用专有许可,发布时未开放公开API,但已开始整合至Meta AI以及Facebook、Instagram和Threads等一方产品。同时,Meta在过去9个月中重建预训练栈,对基础设施、模型架构与数据管道进行系统升级,并表示相较此前的Llama 4 Maverick,可用更少计算实现相近能力。
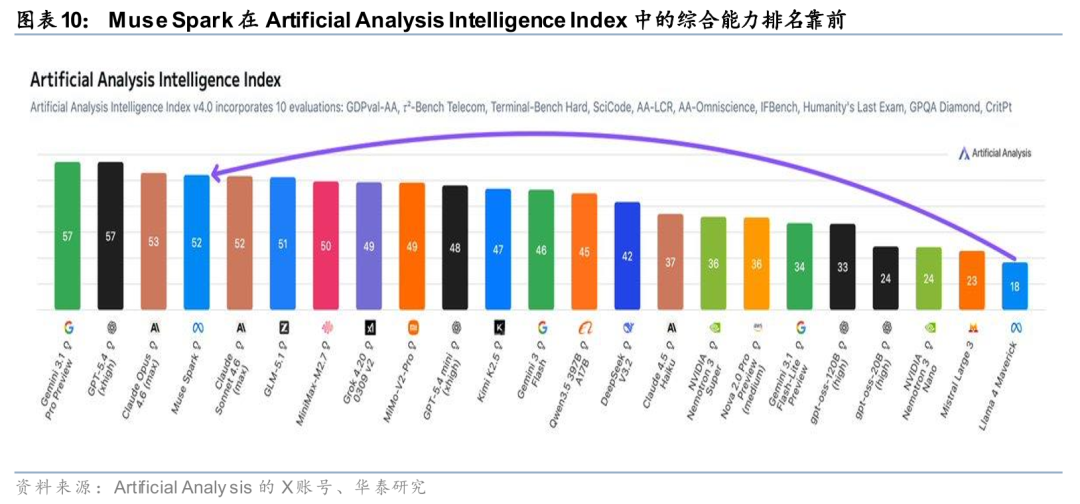
Muse Spark围绕高频消费场景强化平台内商业转化能力。Meta对Muse Spark的应用布局更侧重高频消费场景与平台内商业转化。据Meta AI官网4月9日博客,Muse Spark当前已在Meta AI中落地,并向精选合作伙伴提供API私有预览,后续计划开源其后续版本;在具体应用层面,1)“沉思模式”通过多个并行推理代理协同处理复杂科学与推理查询,体现长链路任务调度能力。2)“购物模式”可识别Meta应用内的创作者、品牌与风格内容,并转化为推荐结果,显示模型与广告、电商及内容分发链路的结合。3)在健康场景中,Meta与1000多名医生合作构建训练数据,使模型能够生成交互式展示,并对健康信息进行解析与解释。整体来看,Meta此轮推进更强调模型能力对社交平台、内容分发与商业生态的直接支撑,而非优先发展独立模型服务收入。
Anthropic:以安全准入机制强化企业级模型交付能力
Anthropic通过提高安全准入门槛,将前沿模型能力与企业级安全场景深度绑定。据Anthropic官网4月7日发布的Project Glasswing信息,公司围绕Claude Mythos Preview启动面向关键软件与关键基础设施的定向合作机制,访问采取邀请制,仅向经过筛选的防御型组织开放;根据Claude API release notes,该模型当前未面向通用开发者开放,而是以gated research preview形式服务于防御性网络安全工作。整体来看,模型发布策略更强调可控性与安全性。在模型能力持续提升背景下,Anthropic资源配置逻辑正向高价值企业客户倾斜。在推理能力增强及Agent调用成本上行的背景下,公司业务重心仍以企业客户为主,由此前的广泛订阅扩张逐步转向定向合作与审慎放量,体现出公司在能力外扩过程中对风险控制与商业回报的平衡。
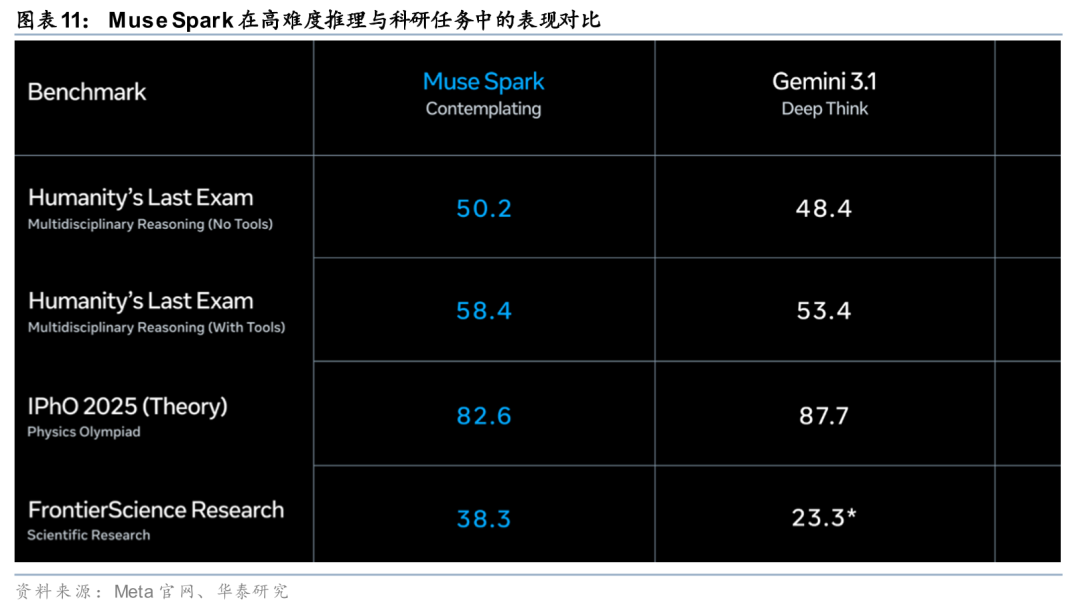
Mythos在多类复杂任务场景中实现能力跃升。据Anthropic官网披露,Mythos在软件工程、推理、computer use、知识工作与科研辅助等方向均较此前模型明显提升,其中软件工程Agent能力达到93.9%/77.8%/87.3%/59%,分别对应SWE-bench Verified、Pro、Multilingual与Multimodal;在Terminal-Bench 2.0中取得82%,反映其在CLI环境下多步操作、纠错与工具协同方面的执行深度进一步增强。Anthropic官网system card亦指出,Mythos Preview相较Claude Opus 4.6在多项评测中表现提升,并被定义为能力更强的前沿模型之一。整体来看,模型评价重点正由单点能力指标转向复杂任务的整体交付能力。
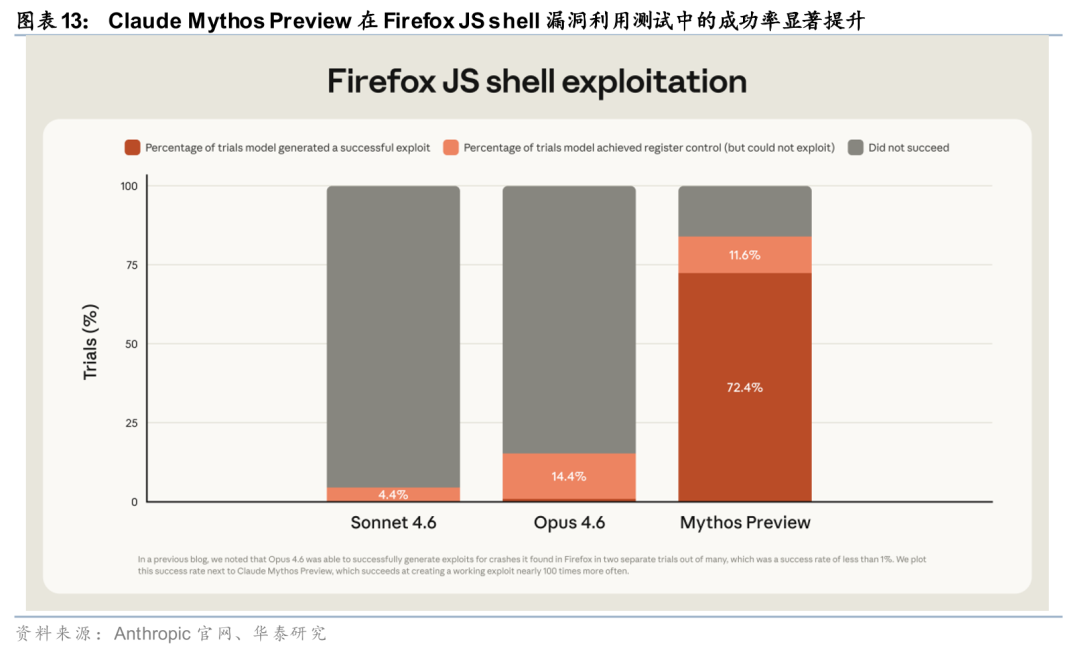
能力提升伴随安全约束同步强化,商业化边界向高门槛场景延伸。Mythos的审慎开放策略反映出能力跃升与安全约束的同步提升。据Anthropic官网披露,Mythos Preview定价为每百万输入/输出token 25/125美元,高于Opus 4.6的5/25美元;同时,该模型发现了存在27年的OpenBSD漏洞及存在16年的FFmpeg漏洞。Anthropic官网风险报告与网络安全能力评估进一步显示,Mythos Preview在漏洞发现、利用链构造及高自主性网络安全任务中已进入更高风险区间,因此未进行公开发布,而是通过Project Glasswing与政府、云厂商及大型企业协作推进补丁修复与防御验证。由此可见,前沿模型的商业化边界正逐步向安全治理、准入机制与企业信任体系交汇处延伸。
投资建议:看好具备基础模型和Agent执行能力的平台型厂商
模型竞争正从能力展示转向闭环交付与商业兑现。综合国内外厂商近期迭代方向看,行业主线已由单一Benchmark表现,逐步转向“基座能力升级—多模态补齐—工具调用增强—Agent执行闭环—产品与生态落地”的连续验证过程;其中,既能持续提升长程任务、复杂推理与多模态能力,又能打通产品入口、开发者生态、企业交付及国产软硬件适配的厂商,具备更高的产业跟踪价值。我们认为,具备基座模型持续迭代与Agent执行能力的平台型厂商具有持续的投资价值。
AI算力:Agent推动算力需求扩散,云涨价与国产替代强化
CPU供需失衡加剧,Agentic AI开启新一轮算力重构
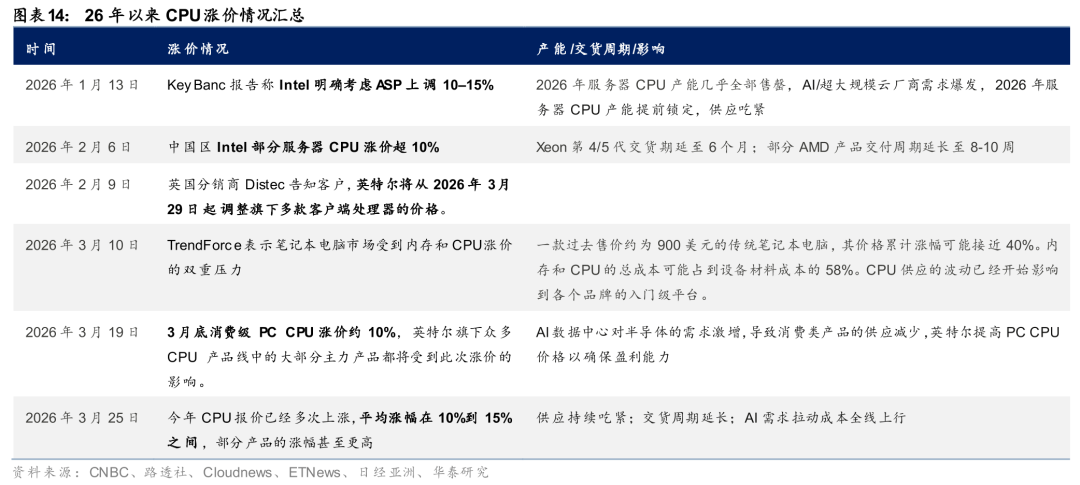
Intel/AMD服务器CPU供需缺口持续扩大。26年以来,CPU市场供需失衡持续恶化,Intel与AMD上调产品价格。1)价格端:26年2月6日,根据路透社报道,Intel和AMD已通知中国客户服务器CPU供应短缺,Intel服务器产品在中国价格普遍上涨10%以上,交货周期可能长达6个月;3月25日,根据日经亚洲报道,26年以来CPU报价已多次上涨,平均涨幅在10%-15%之间,部分产品涨幅更高,Intel和AMD分别从3月和4月起提高所有CPU的价格。2)供给端:Intel管理层在1月业绩会上坦承库存已降至峰值40%左右,现有工厂产出即为最终交付量,由于6个月前对CPU需求的判断失误、执行能力仍有待提高,短期内无法完全满足市场需求。

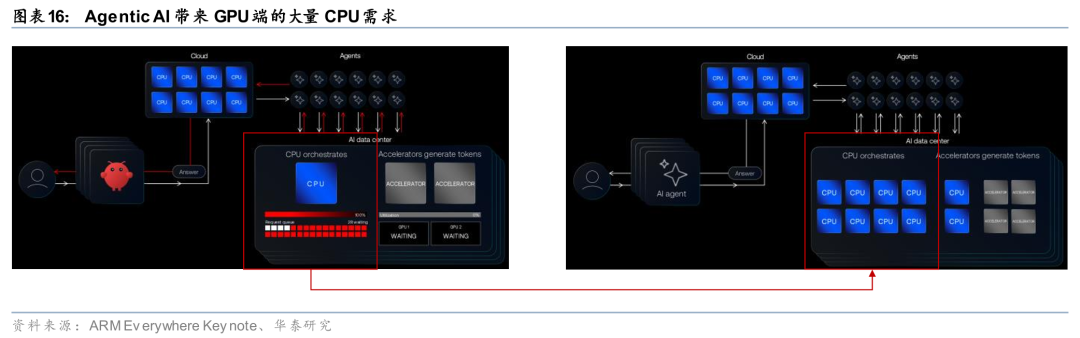
GPU算力高速扩张之下,CPU成为Agentic AI工作流中的关键瓶颈。 Agentic AI的运行逻辑决定了CPU需求结构性扩张,因为Agent在执行任务时不仅生成Token,还需要在CPU侧完成任务编排、工具调度、反馈循环等串行计算,而这些任务无法被GPU并行替代。ARM在ARM Everywhere会议上指出,Chatbot时期,CPU承担的功能与云时代类似,用于用户与GPU端AI的信息调度,但是Agentic AI时代,GPU端Agent和Agent之间的信息调度需求大幅提升,带来GPU端的CPU需求。根据ARM给出的数据,Agentic AI使每次查询的Token消耗增长约15倍,且Agent全天候24小时不间断运行,将产生远超传统云请求量级的CPU调度压力。由此带来的结果是:数据中心正面临CPU侧的结构性供应缺口,与GPU算力的快速扩张形成不对称失衡。
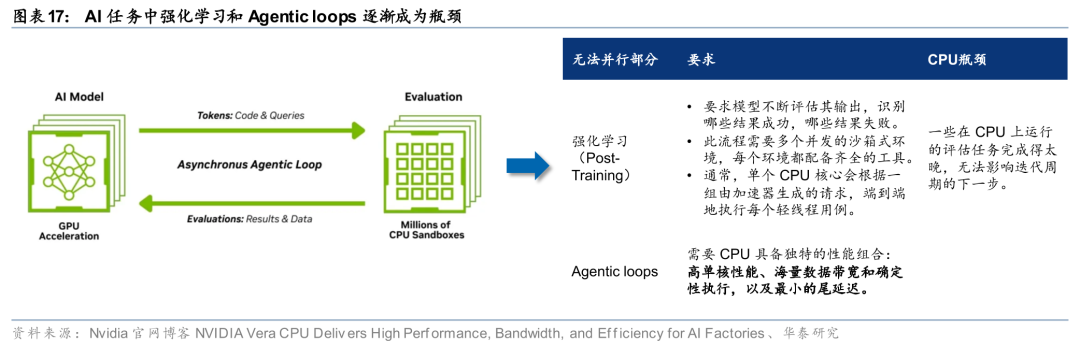
Nvidia正式披露Vera CPU机柜方案,CPU算力进入机架级部署时代。Nvidia于26年GTC大会上披露,Vera CPU可作为独立计算节点部署,并推出面向AI工厂场景的Vera CPU机架产品。Nvidia指出,系统性能的提升上限受限于无法被并行的部分(阿姆达尔定律),而在当前的AI任务中,无法被并行的部分主要是Post-Training中强化学习部分和推理过程中Agentic loops部分,CPU执行密集型串行任务的能力正在成为AI任务的瓶颈。因此,每个AI工厂都需要数百万个CPU核心来支持强化学习和工具使用的Agent循环,Vera CPU机架旨在通过机架级部署缩短建设时间、加快新容量上市速度。
ARM进军CPU产品业务,Agentic AI带来4倍CPU Core需求。26年3月,ARM正式推出AGI CPU,单颗芯片包含136个CPU Core,单CPU Tray配置2颗CPU芯片,当前客户涵盖Meta、OpenAI等,强调每瓦性能大幅领先x86架构竞品。公司指出,从每GW算力对应的CPU Core数量看,Chatbot AI数据中心每GW约需3,000万个CPU Core,Agentic AI场景下保守估计约需1.2亿个CPU Core。从整体数据中心CPU需求来看,ARM预计全球市场规模将从当前500亿美元增长至2031财年的1,000亿美元,公司的CPU业务有望从2028财年的10亿美元拓展到2031财年的150亿美元。我们认为,Agentic AI的加速落地将持续催化CPU需求高增,我们看好各类CPU厂商受益于Agentic AI趋势业绩加速增长。

AI互联:CPO与OCS落地节奏加速,光芯片供需差持续扩大
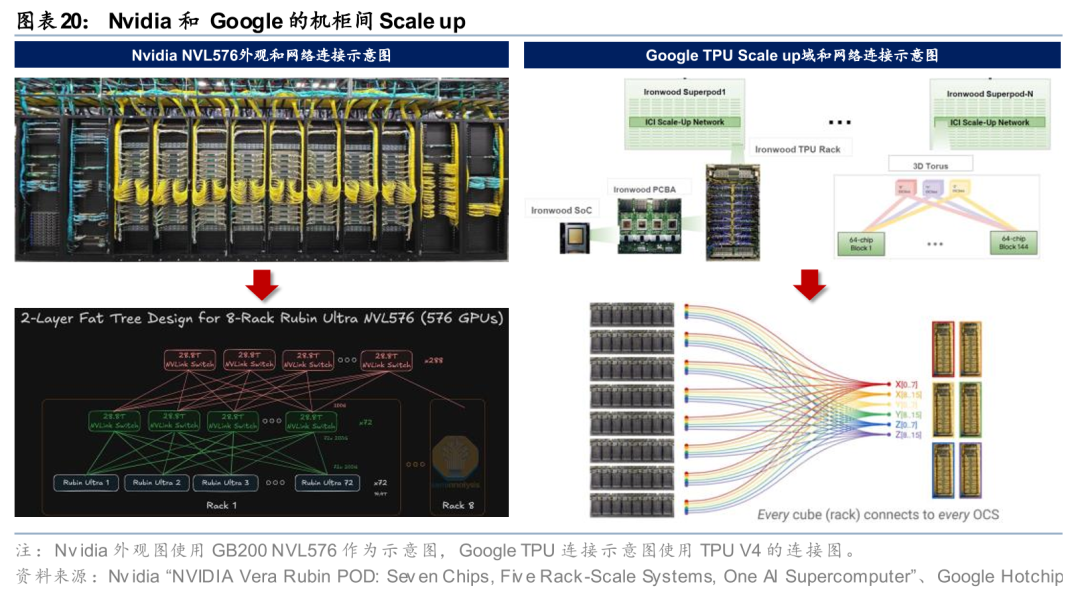
CPO出货节奏逐步明确,Scale out先行、Scale up跟进。Lumentum给出CPO发展的三个阶段,当前的阶段0在Scale out网络中使用CPO,同时在更高的聚合层如Spine和SuperSpine使用OCS,时间可能在26年末;之后的阶段1将形成多机柜的Scale up域,在机柜间的Scale up部分引入CPO,CPO需求将是Scale out部分的3-4倍,时间可能在27年末;未来的阶段2,光纤将进入机柜内部,带来相对阶段1的3-4倍CPO需求,28年底有望看到这部分的增量。26年3月初,Lumentum和Coherent陆续与Nvidia达成20亿美元合作,内容均与CPO相关,根据投资协议,Nvidia几乎拿走Lumentum现阶段所有可制造的UHP产能。我们认为,Scale out率先贡献收入、机柜间和未来机柜内的Scale up带来更大量级增量的节奏已较为清晰,看好相关厂商的收入爬坡。

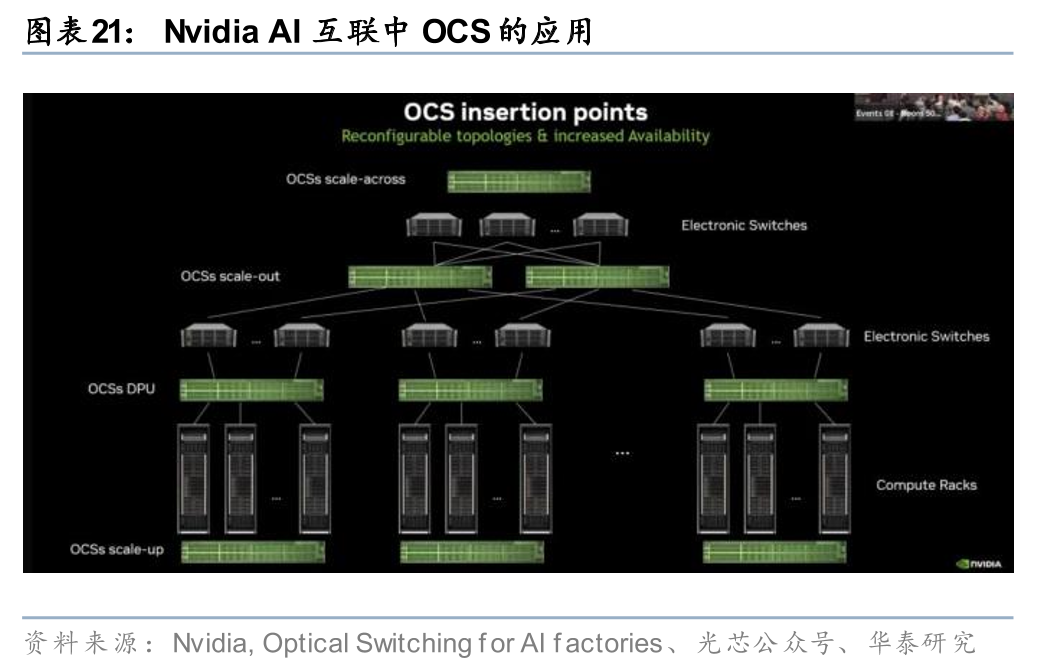
OCS热度高涨,市场空间持续上调,多场景落地加速。Lumentum在OFC现场宣布与大型客户签订新的多年期、数十亿美元协议,OCS backlog已达多年,26H2的4亿美元交付目标当前进展完全符合预期,2027年收入有望超过10亿美元;Coherent将OCS 2030年全球市场空间从20亿美元上调至40亿美元,已向超过10家客户出货。我们看到OCS的应用场景逐渐拓宽:
Scale up域:根据Lumentum的三阶段划分,从阶段1开始,OCS有望起到机柜间Scale up的补充作用,并在柜内光互联阶段发挥更重要的作用。我们认为机柜间Scale up和Google Ironwood集群网络具备一定的相似性,OCS可以构建灵活高效的Scale up域,适配动态训练任务流量需求。
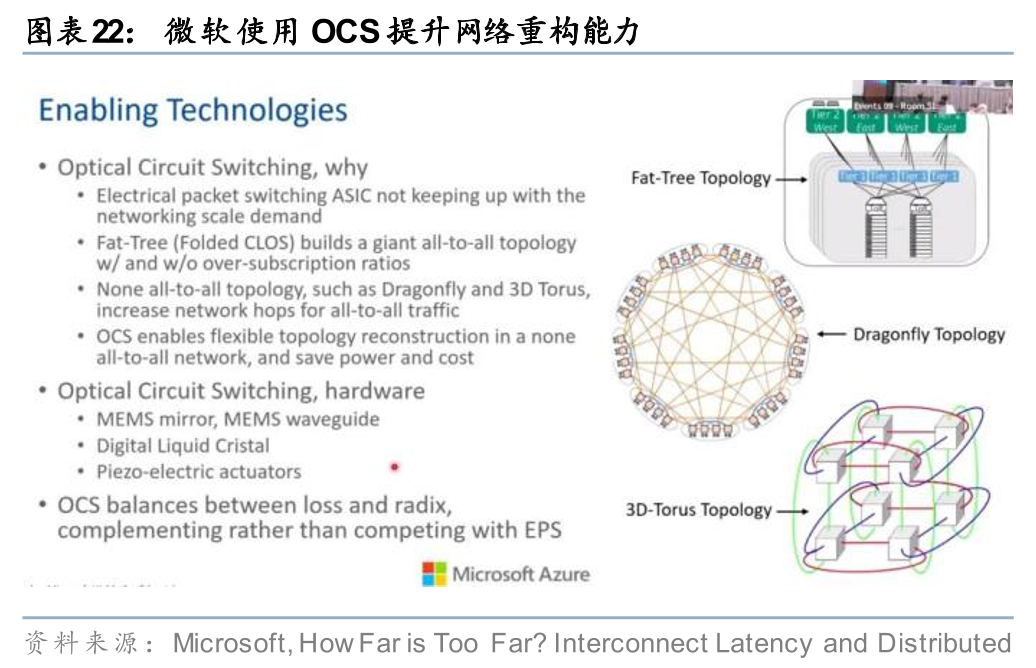
Scale out/Scale across域:除了此前已有应用的替代Spine/SuperSpine电交换机、作为冗余硬件设计提升网络弹性外,参考Coherent CTO Julie Sheridan Eng的表述,OCS不是对电交换机的简单替代,而更适合被理解为数据中心的一种新能力,用户可以通过软件指令重新定义GPU之间的光纤连接关系。基于这种新的理解,我们注意到一些新的应用,例如微软使用OCS参与数据中心间连接的构建,Dragonfly和3D Tour网络相比传统的Fat-Tree网络更稀疏,OCS动态重构的能力帮助网络在需要的时候获得临时的全互联能力,从而相较Fat-Tree节省功耗和成本。
我们认为,OCS已从概念验证进入多客户商业落地阶段,OCS有望持续进入Scale up/out/across网络,市场空间广阔。
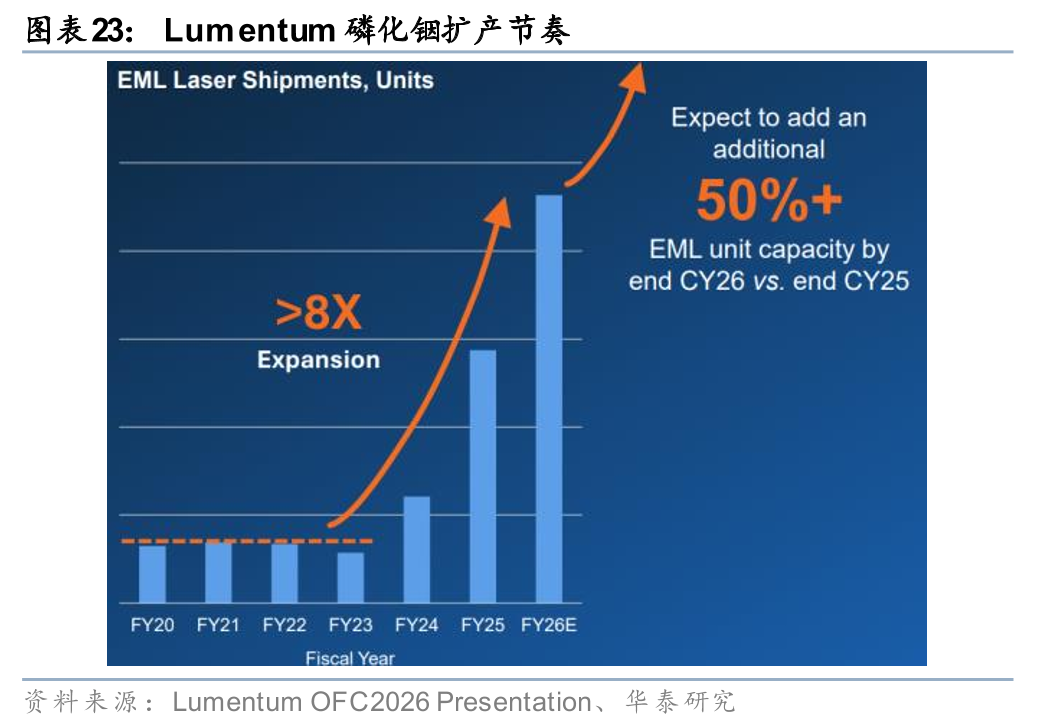
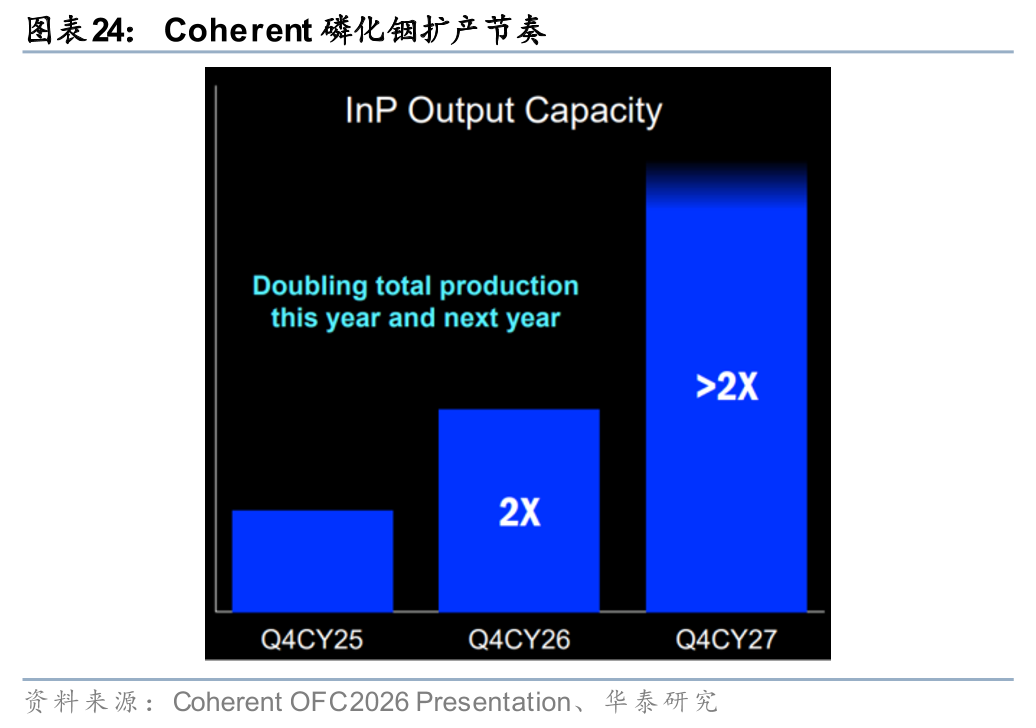
光芯片产能供不应求,磷化铟扩产进入加速周期。Lumentum在OFC 2026上表示,自23年以来公司EML产能已提升8倍,以25Q4末为基准、至26Q4末磷化铟产能将再增50%,但市场供需缺口目前仍约为25-30%,并预计未来几年随Scale out与Scale up双轮驱动持续扩大,公司激光器芯片(EML、CW)及UHP产品backlog均超过两年。公司宣布完成第五座磷化铟晶圆厂的收购,预计28年开始出货。Coherent在OFC 2026披露,公司目前运营四座磷化铟晶圆厂,预计到26年底整体产能较25年底翻倍,27年底再翻倍或更多,新增产能几乎全部以6英寸产线为主。我们认为,磷化铟光芯片供需缺口短期内难以收窄,Lumentum和Coherent均已提前锁定多年期backlog,光芯片供应商有望在本轮AI互联需求扩张中持续受益。
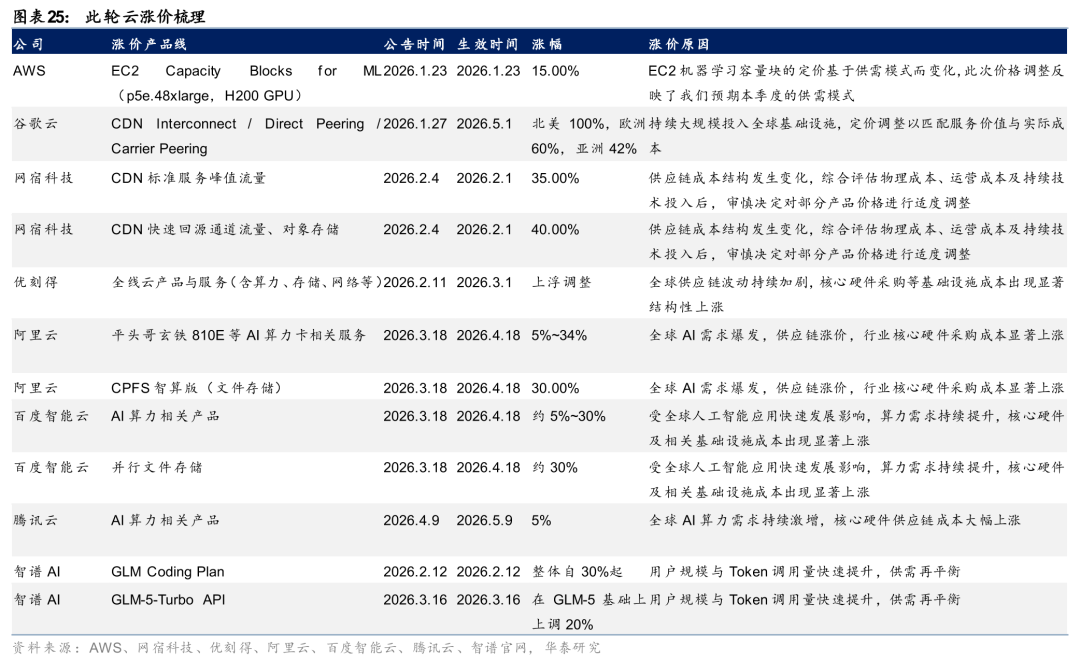
云服务进入结构性涨价周期
本轮云计算提价从CDN边缘节点扩散至全线云产品,正式进入结构性涨价周期。2026年1月,海外云巨头率先打破近二十年降价惯例,高端算力卡与CDN等成为首批提价品类。 AWS于1月中旬上调EC2 Capacity Blocks for ML价格,反映弹性GPU预留资源供需率先承压,该品类采用按预订时点动态定价机制;1月27日谷歌云确认自5月1日起上调CDN Interconnect、Direct Peering等出网单价,北美涨幅达100%、亚洲约42%,为其近二十年来首次对基础云服务大幅提价。2月初,国内开始跟进,路径从CDN/存储向AI算力逐步蔓延。2月4日,网宿科技对部分CDN与存储产品调价,最高涨幅约40%;优刻得2月11日发布公告,自3月1日起对全线产品与服务价格上浮,为国内首家发布正式全线涨价公告的云厂商。3月18日,阿里云与百度智能云在同日宣布上调AI算力与存储产品价格——阿里云平头哥真武810E等算力卡涨5%~34%、CPFS智算版涨30%,百度智能云AI算力产品涨约5%~30%、并行文件存储涨约30%。4月9日,腾讯云宣布AI算力相关产品服务上调5%,容器服务TKE-原生节点相关产品服务上调5%,EMR相关产品服务上调5%。
本轮云计算提价本质是由算力需求快速增长带来的价格体系重构。在此背景下,云厂商从CDN、存储到AI算力的逐层提价,不是简单成本传导,而是对算力稀缺性的重新定价。随着Agent应用加速落地,推理侧需求将呈现长尾且高频特征,驱动算力利用率持续维持高位,叠加供给扩张节奏有限,云厂商具备较强的价格传导与利润增厚能力,预计云服务价格中枢有望维持上行趋势,产业链相关环节:1、AI Infra;2、算力租赁&AIDC。标的梳理,请见研报原文。
国产AI算力崛起:性能追赶与市场替代加速
随着国产算力生态逐步成熟,国产大模型与底层硬件之间的协同优化正加速推进。DeepSeek V4或以国产算力优先,核心适配国产算力芯片。根据晚点财经消息,该模型自设计阶段即围绕国产硬件进行优化,未向美国芯片厂商开放早期测试,并通过数月底层代码重写与全栈联合调优,完成从CUDA到CANN框架的迁移,体现出模型侧向国产算力体系深度绑定的趋势。在具体适配层面,根据路透社在26年4月3日的报道,华为和寒武纪与DeepSeek直接合作,帮助重写模型的部分底层代码并进行测试。与此同时,更多国产算力厂商也在加快对主流大模型的适配进程,4月8日智谱GLM-5.1开源当天,华为、海光、昆仑芯、壁仞、摩尔线程、沐曦、清微智能等多家国产算力厂商同步完成Day-0适配,覆盖NPU、GPU、DCU及可重构芯片等多类基础设施,展现出较强的生态兼容性与工程化落地能力。

华为新一代AI计算产品,详情请见研报原文。
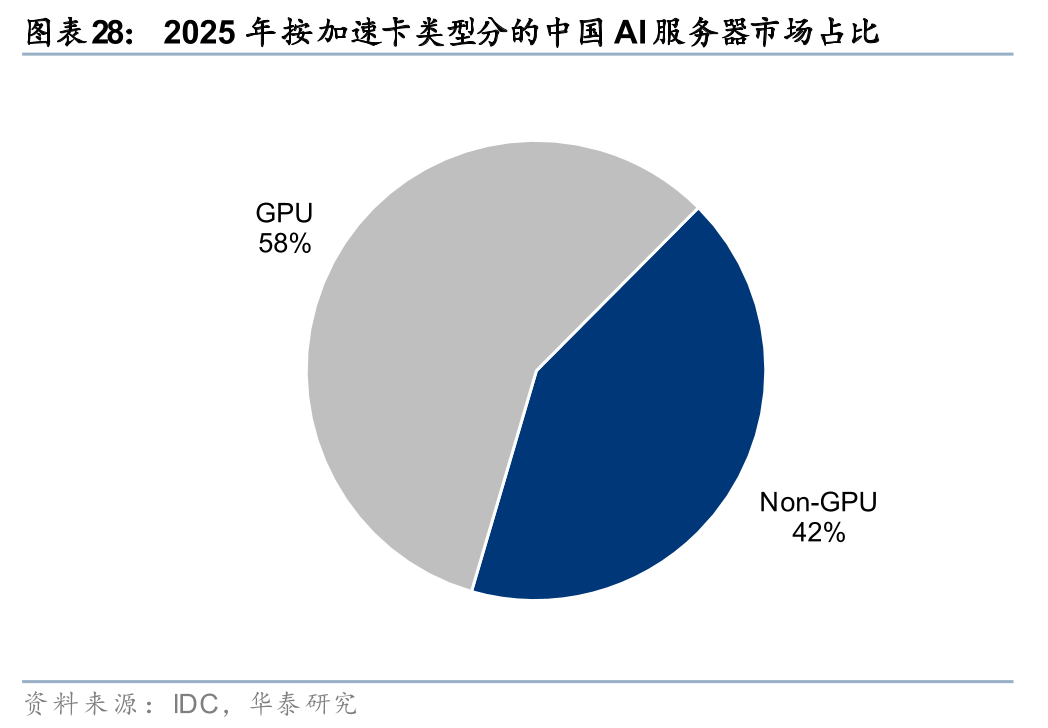
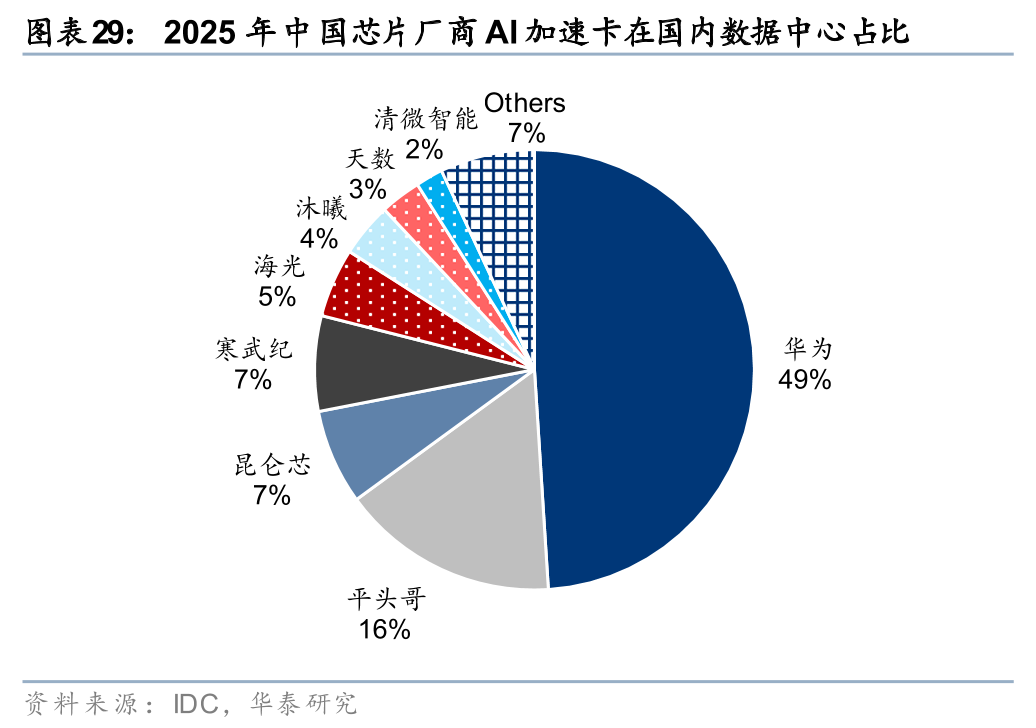
2025年,国产AI加速卡市场份额已超过40%,非GPU芯片凭借差异化技术路线加速追赶。根据IDC数据,2025年中国AI加速卡市场总出货量约为400万张,其中本土芯片厂商合计出货约165万张,市场份额接近41%。从厂商表现看,华为以约81.2万颗的出货量显著领先,平头哥位居第二,昆仑芯与寒武纪并列第三,海光信息、沐曦、天数智芯等厂商也保持在市场前列。相比之下,曾长期主导国内市场的英伟达出货量约为220万颗,市场份额明显回落。与此同时,非GPU加速卡在AI服务器市场中的占比已超过40%,表明以差异化架构为代表的非GPU技术路线,正成为我国推动AI算力自主可控的重要增长方向。
超节点有望迈入规模化交付阶段
推理范式变化使得Scale up成为必然
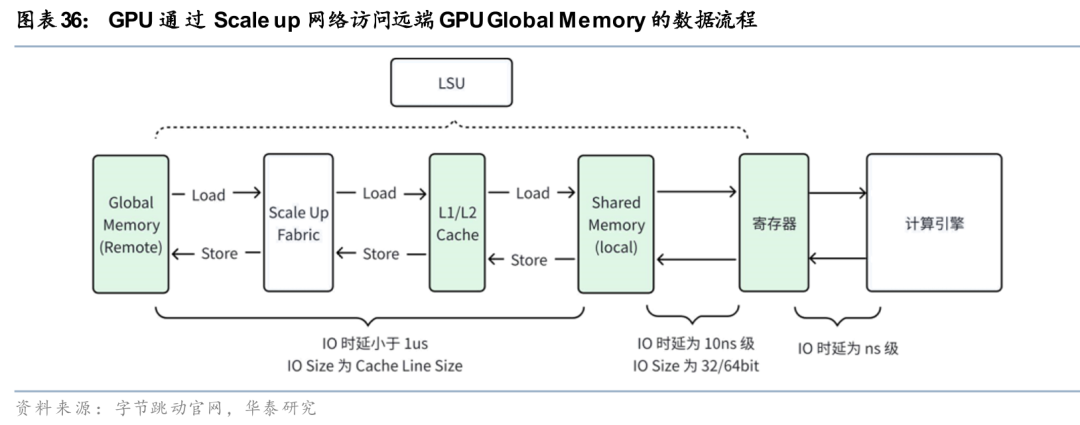
Scale up与Scale out的核心差异在于内存一致性,由此带来带宽与延迟的差异。Scale up侧网络支持内存语义(Load/Store)访问与原子操作,可进行GPU与GPU、GPU与CPU间的统一内存寻址,保证内存一致性,通过点对点或者专有交换芯片进行传输;而Scale out侧为消息语义,通过RDMA(远程直接内存访问)进行数据传输,架构一般为Clos、Fat-tree、Dragonfly等分布式拓扑。因此两者在带宽与时延上存在显著差异,以英伟达的系统为例,Scale up的NVlink传输带宽比其最快的Scale out InfiniBand网络高9倍,前者延迟(250ns)仅为后者(1700ns)的1/6。伴随模型参数的扩大与推理算力需求的起量,模型的推理范式发生了变化,体现为内存墙带来的显存池化的需求与并行策略带来的高通信需求,使得Scale up网络的重要性不断提高。下面从模型推理过程的原理出发,阐明为什么需要Scale up网络。
1)内存墙问题催生显存池化需求
拆解推理环节的技术原理,KV Cache需要大量显存。在Transformer的自注意力(Self-Attention)机制里,每个Token都会生成三种向量:Q(Query)、 K(Key)、V(Value),在Transformer生成文本时,每次只会生成一个新Token,模型会用这个Token的Q去和所有历史Token的K做匹配,找到相关性,然后用这些相关的V计算输出,在这个过程中为了避免重复计算催生了KV Cache。KV Cache的原理是将历史的K与V进行存储,无需每次重复计算,将推理的计算量从二次方降低为线性。在这个过程中需要大量的显存来支持, KV Cache占用显存大小可达模型的50%以上。假设一个模型上下文长度是8万个Token,而每个Token的K和V都要储存,那么KV Cache就能占用几十GB的显存。
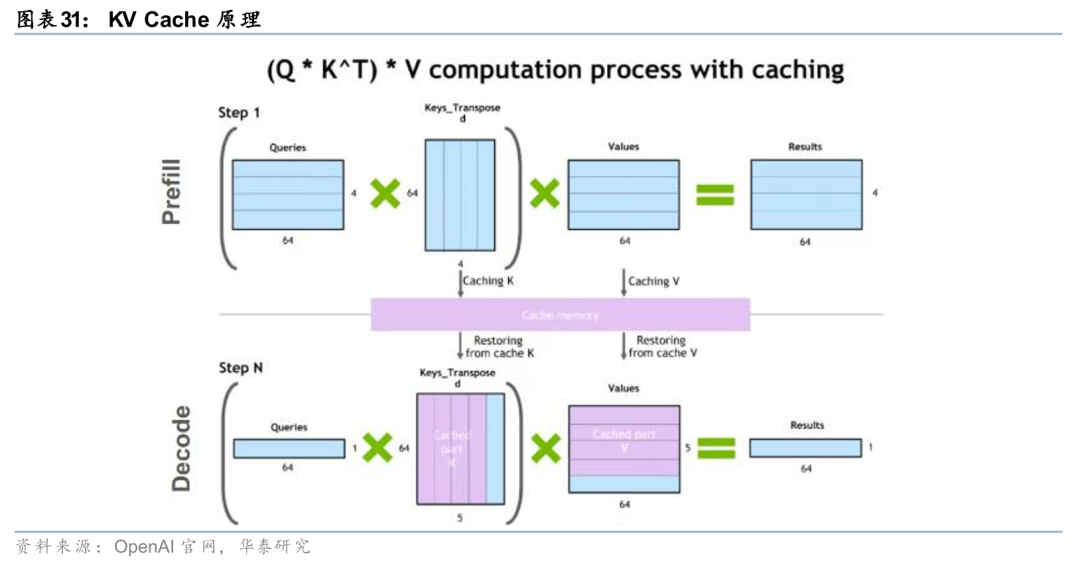
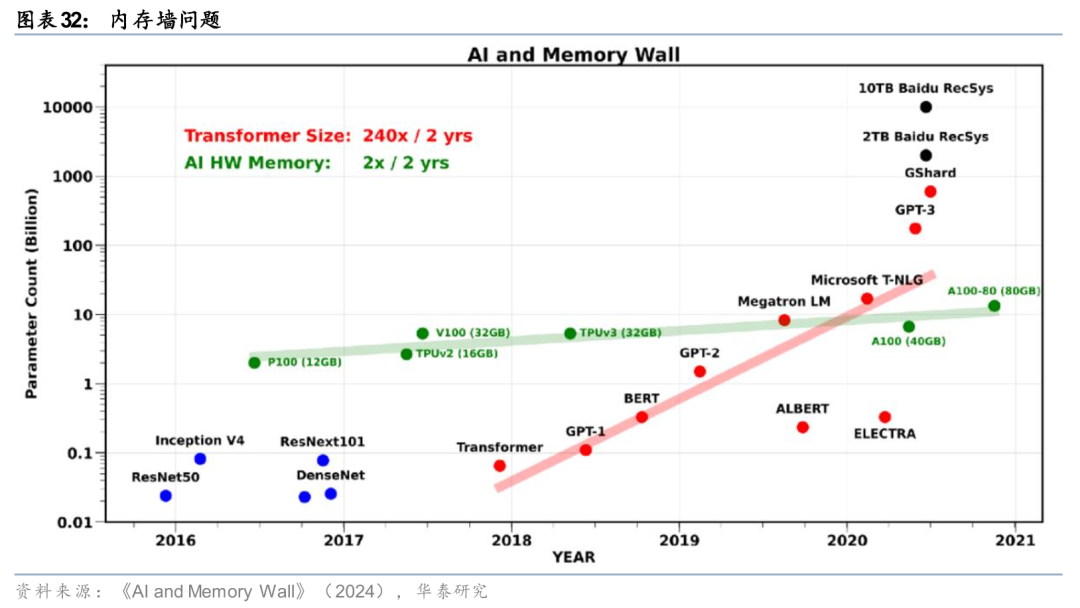
内存墙问题需要借助Scale up网络将显存池化来解决。在模型推理过程中,某些情境下制约模型推理效率的瓶颈是单卡显存而非单卡算力,因此单卡算力与单卡显存之间的差距催生了内存墙问题。KV Cache需要借助多卡的内存进行存储,因此单卡运算时需从多张卡的显存读取所需参数、数据,为了尽可能减少数据传输时延,目前产业化应用最优解是使用Scale up网络将显存池化。
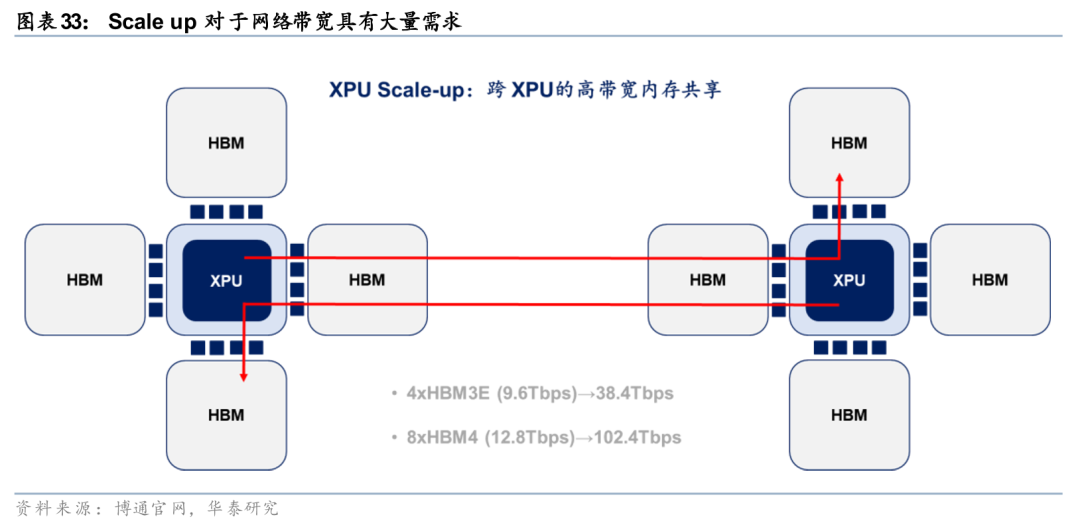
XPU间的内存共享对于网络带宽具有大量需求。加速器处理器(XPU)应能像访问本地内存一样,对远程加速器内存执行加载/存储操作。以单个XPU的内存带宽需求为例,每个XPU通常配备4个HBM(高带宽内存),每个HBM与XPU连接的带宽大约为每秒9.6TB,那么4个HBM的总带宽约为40TB。下一代XPU将配备HBM4,并且可能拥有多达8个HBM,这样一来,每个XPU连接的内存总带宽将达到约100TB。在一个包含两个XPU的系统中,如果一个XPU的计算任务需要访问另一个XPU的内存,那么在未来就需要100TB的带宽。
2)多并行策略带来高带宽、低时延的通信需求
张量并行与专家并行策略对卡间通信提出了更高的要求。千亿参数模型主要包含数据并行、张量并行与流水线并行三种策略,其中张量并行将模型参数运算的矩阵拆分为子矩阵传输至各个负载,各负载分别进行不同的矩阵运算,在每一层神经网络的计算后都需要将新的计算结果收集、汇总,并将完整结果重新分发,对通信要求更高。随着训练/推理任务规模扩大,超万亿参数模型的训练与推理中新增专家并行策略。专家并行的数据量非常大,通常在MB级~GB级,同时,对时延极为敏感,任何微小延迟都会引发等待与算力浪费(每增加10μs时延,GPU利用率将下降1%至3%),因此专家互联对高带宽和低时延提出了更高的要求。
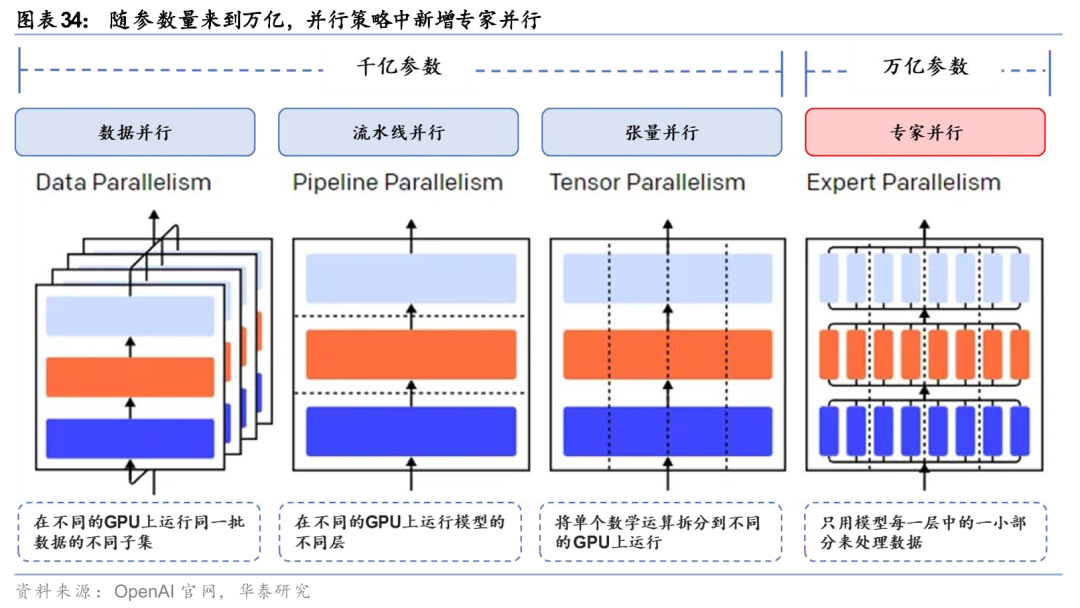
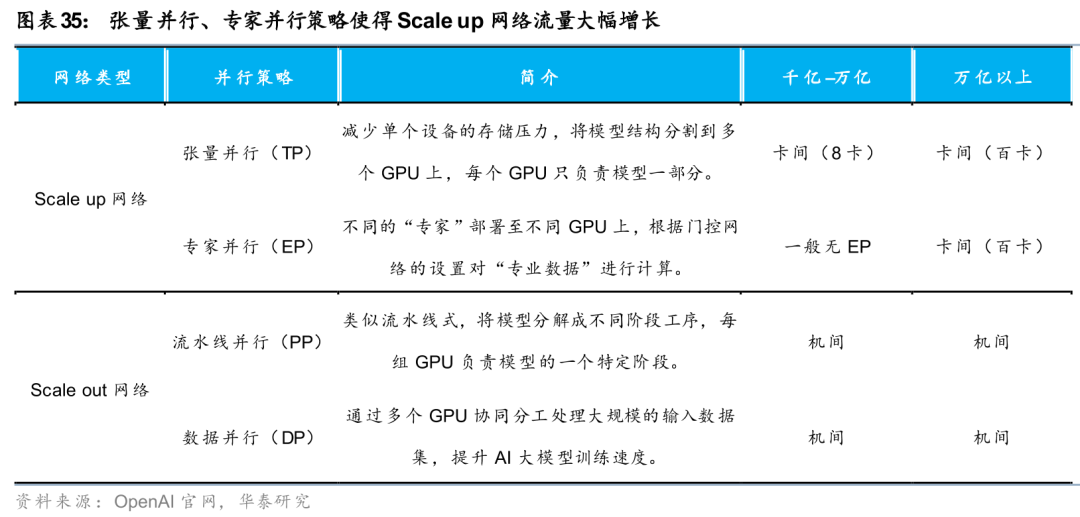
只有Scale up网络才能满足高带宽、低时延的需求。如前文所述,Scale up网络具有高带宽、低延迟的特性,Load/Store语义传输小块数据的效率高,时延小,特别适合用于传输控制信息和内存中位置不连续的数据,以及用于对时延要求较高的AI推理场景。因此需要通过一个高吞吐量的Scale up网络实现计算单元内部互联,要求在单台服务器和AI Rack内实现超百卡GPU的高带宽、低时延互联,为模型的张量并行(TP)和专家并行(EP)提供支持,通过Load/Store操作在Scale up网络实现大块数据的传输。
国内超节点方案层出不穷
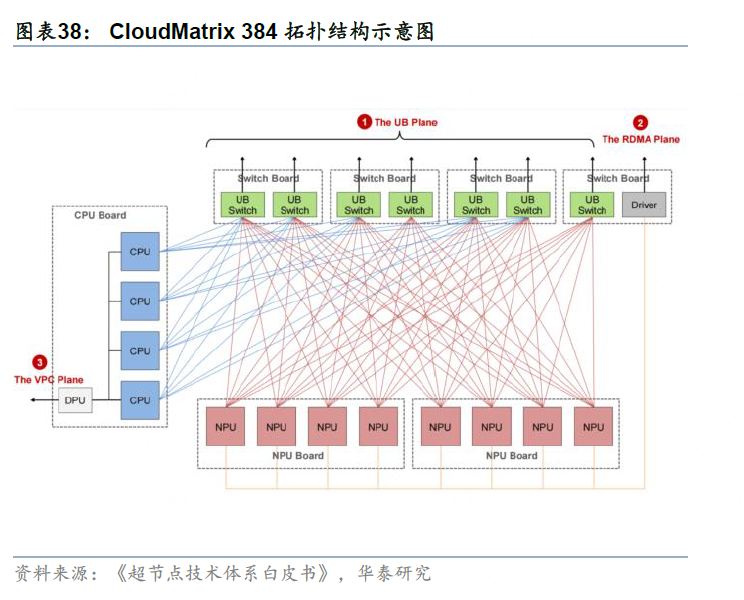
华为是国内较早推动超节点产品化与落地实践的厂商之一。2025年,华为云先后推出CloudMatrix 384超节点架构与Atlas 900 A3 SuperPoD超节点产品;同年,华为进一步发布面向更大规模AI训练与推理场景的Atlas 950 SuperPoD和Atlas 960 SuperPoD,分别支持8,192张和15,488张昇腾卡,持续完善其超节点产品体系。根据华为官网披露,Atlas 900 A3 SuperPoD已累计部署300多套,服务互联网、金融、运营商、电力、制造等行业20多个客户。

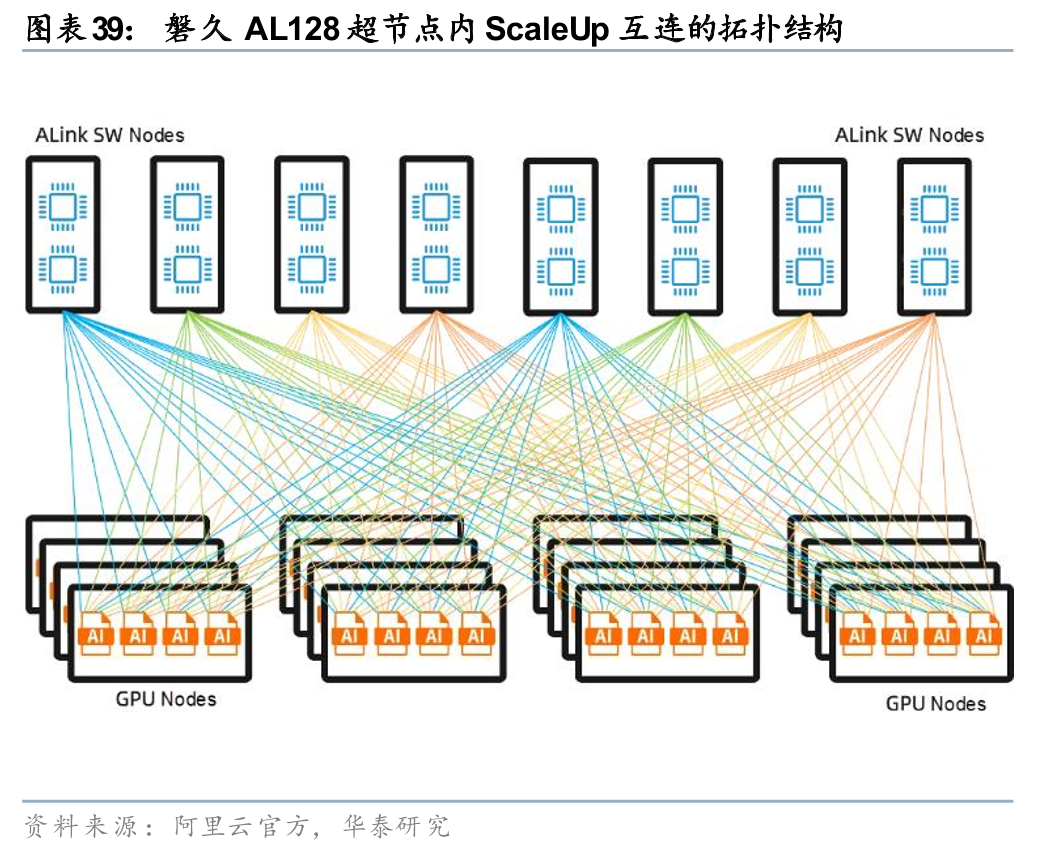
阿里云磐久AL128超节点于2025年9月18日在2025杭州云栖大会正式发布。阿里磐久AL128超节点采用模块化多维解耦架构,单柜为定制双宽液冷机柜,支持128–144颗AI芯片、350kW供电与500kW散热(单GPU 2kW液冷),内部以自研非以太ALink单级交换(兼容UALink/NVLink/xLink/UB等)实现Pb/s级Scale up带宽、百ns级时延,集成CIPU 2.0 EIC/MOC网卡,搭配HPN 8.0 800G高性能网络,可支撑单集群10万卡级训练,相比传统架构推理性能提升50%,核心目标是在大规模AI场景中实现高带宽、低时延与算存协同优化。磐久AL128超节点2025年Q4起在阿里云内部万卡级商用,并已落地短视频、金融、自动驾驶等外部客户,同时在三江源智算中心大规模部署平头哥PPU国产算力集群。

百度昆仑芯超节点于2025年4月在Create 2025百度AI开发者大会发布。8月28日在百度云智大会随百舸AI计算平台5.0正式商用上线;采用天池高密液冷整机柜、32卡一层点对点全互联架构,单柜集成64张昆仑芯P800 XPU,卡间互联带宽提升8倍、时延低至1.5μs,单柜训练性能提升10倍、单卡推理性能提升13倍;2025年4月起已在百舸5.0大规模部署,支撑3.2万卡昆仑芯P800集群,服务文心大模型训练推理及金融、央企、自动驾驶等外部客户,2025年11月13日百度世界大会发布新一代天池256/512超节点(2026年上市),分别支持256/512卡全互联,天池512可独立支撑万亿参数模型训练。


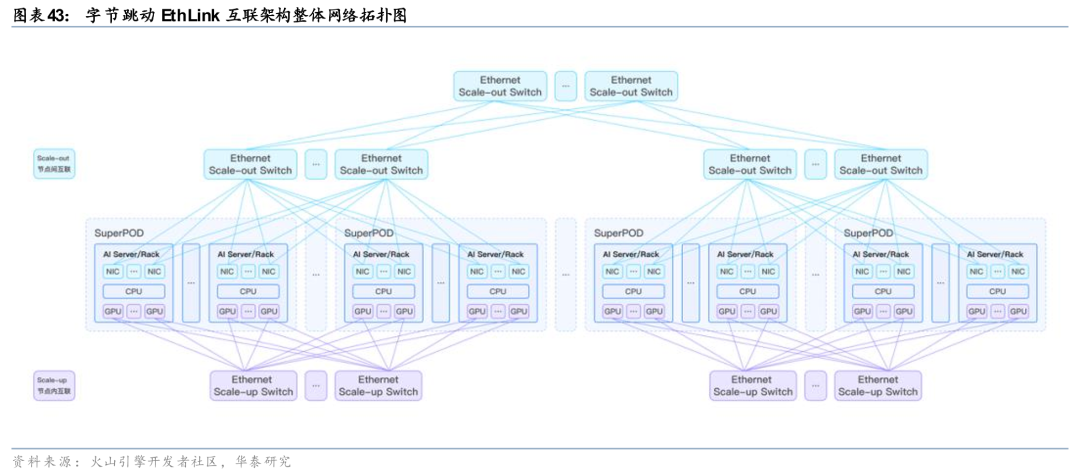
字节跳动已对外披露其面向GPU超节点的自研互联方案EthLink。该方案主要服务于GPU Scale up(节点内及AI Rack内)高速互联场景,适用于单机服务器及AI Rack内8卡及以上GPU部署。在架构设计上,EthLink基于原生以太网深度优化,同时支持GPU基于Load/Store内存语义的小数据块、低时延同步通信,以及基于RDMA消息语义的大数据块、高带宽异步传输,从而为GPU超节点提供专用高速互联能力。结合字节跳动同期披露的集群网络能力,其配套vRDMA网络公开指标可达最高320Gbps带宽、最低约5微秒时延、最高50M PPS,反映出字节在超节点内部互联与大规模集群网络协同方面已形成较为系统的技术布局。
中科曙光超节点包含两大核心系列:1)scaleX640于2025年11月6日在世界互联网大会乌镇峰会发布,采用 “一拖二” 紧耦合整机柜、浸没相变液冷、超高速正交互联架构,单机柜集成640张GPU、算力密度提升20倍、支持10万卡级集群扩展,2025年底起在国家智算中心、金融、科研机构规模化部署;2)scaleX40于2026年3月26日在中关村论坛发布,为全球首款 无线缆箱式超节点,采用 正交无线缆一级互联、标准19英寸箱式设计,单节点集成40张GPU、FP8算力 ≥28PFLOPS、HBM显存 ≥5TB、时延百ns级、于2026年4月启动交付,适配企业级AI训练与推理。


浪潮信息于2025年8月7日在开放计算技术大会发布面向万亿参数大模型的元脑SD200超节点AI服务器。采用多主机低延迟内存语义通信架构与3D Mesh开放总线交换技术,支持64路本土GPU高速互联,通过远端GPU虚拟映射实现统一显存扩增8倍,单机可提供最大4TB统一显存与64TB内存,适配超万亿参数模型与多智能体协同;实测DeepSeek-R1推理token生成速度仅7.3毫秒,64卡推理性能超线性提升比达3.7倍,已实现商用;配套Smart Fabric Manager实现全局最优路由与PD分离推理框架,并推出MW级泵驱两相液冷整机柜单芯片解热3000W;已在国家智算中心、金融、科研及智能制造等领域规模化部署。

壁仞科技于2026年3月12日推出光跃超节点128卡商用版。该款超节点方案采用曦智科技全球首创硅光OCS光交换芯片为核心、搭载壁仞科技壁砺166L自主架构GPU液冷模组,集成中兴通讯服务器与自研软件平台,构建全栈自主光互连架构,传输延迟较传统电交换降低90% 以上、模型切换延迟达微秒级,可跨机柜万卡级弹性扩展并支持拓扑实时重构,已实现数千卡规模部署、可长期稳定运行,成功适配阶跃星辰、DeepSeek、MiniMax、Kimi、GLM等主流大模型。

投资建议:关注算力通胀链条相关行业环节
本轮AI算力需求扩张已从单一训练侧拉动演进为训练、推理、部署全链条共振驱动的系统性重构。Agentic AI的加速落地持续推高串行计算对CPU的结构性需求,CPU供需失衡短期难以缓解,价格中枢上行趋势确立;AI互联侧CPO与OCS落地节奏加速,磷化铟光芯片供需缺口预计在Scale out与Scale up驱动下持续扩大;云服务从CDN、存储到AI算力的逐层提价,本质是算力稀缺性定价重构,产业链价格中枢有望维持上行;国产算力生态持续成熟,DeepSeek V4若深度适配国产算力,有望成为国产替代加速的非线性催化;超节点方案进入规模化交付阶段。中期视角下,当全球总Token消耗量的指数级增长获得大众层面的感知验证,算力产业链有望开启第二波主升浪,节奏或仍将沿GPU(PCB/光模块)—ASIC—存储—先进制程—CPU—云服务—IDC依次演绎。
基于以上判断,我们看好算力通胀链条相关行业环节,重视国产算力芯片与超节点产业链机会:
1. 短期关注算力租赁/云等环节。
2. 中期持续看好全球算力产业链上游的GPU/存储/互联环节以及国产算力链。
3. 关注国产算力芯片及超节点产业链机会。产业链相关环节包括,芯片、交换机、服务器机柜、高速连接器、光互连。
产业链公司梳理,请见研报原文。
AI Infra:AI应用推理下沉,边缘云景气上行
AI时代,云架构有望加速向“云 边 端”分布式架构转型。伴随AI大模型进入应用落地阶段,AI云计算也逐步从“训练为主”向“推理为主”转型,同时Agent应用带动模型调用、数据访问、流程触发的频率大幅提升,进一步放大延迟与带宽问题。我们认为,计算需求变化将带动云服务架构同步升级,传统集中式云架构难以满足AI应用程序超低时延、灵活拓展等需求,AI时代云服务或加速向“云 边 端”协同的分布式架构升级。“云 边 端”分布式架构,是基于算力密度、延迟要求、数据位置进行的功能重构,新架构下各环节功能定位明确,中心云负责训练与控制,边缘云负责推理与执行,终端负责本地感知与轻量智能。
云服务的分布式转型已具备技术基础。从技术可行性来看,云服务的分布式转型已具备技术基础。1)分布式计算与调度能力:容器编排(Kubernetes)技术、边缘调度(edge orchestration)技术均已成熟,搭建了云-边协同的基础;2)数据能力:分布式数据库、边缘缓存、状态管理技术逐步成熟,数据与状态可以安全地实现边缘侧部署;3)模型能力:模型压缩、蒸馏及轻量化技术持续进步,同时,推理框架(如ONNX Runtime、TensorRT等)优化了边缘执行效率,开发者可以将计算逻辑部署至分布式节点。CDN厂商搭建了分布式全球节点网络,具备布局边缘云的核心资产,看好此类公司在边缘云业务的优势卡位。
CDN厂商具备边缘云业务拓展的天然优势
CDN厂商拥有全球分布式节点网络,加速业务从“内容分发”向“计算执行”拓展。边缘云市场主要参与者包括公有云厂商、CDN厂商、NeoCloud厂商等玩家。公有云厂商仍是云计算的核心主体,其切入边缘云的逻辑是从中心云向外延伸,构建“云-边一体化架构”;NeoCloud是AI时代新兴的云基础设施提供商,其边缘云业务的核心切入点是“高性能GPU算力”;CDN厂商是边缘云最直接的参与者,其优势源于长期积累的分布式网络基础设施与流量入口控制能力。我们认为,CDN厂商有望加速实现业务从“内容分发”向“计算执行”的自然延伸。

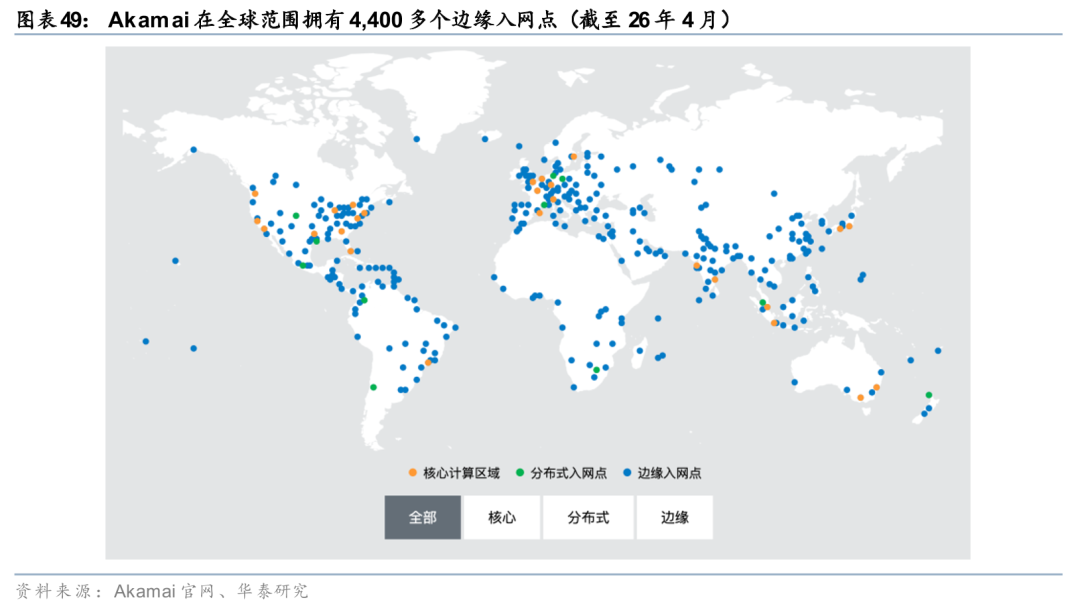
Akamai拥有全球最大CDN网络,22年收购Linode发力边缘云市场。Akamai是全球最大的CDN服务商,业务覆盖全球130多个国家和地区,覆盖全球1,200 网络,拥有4,400多个边缘入网点。22年公司收购Linode(开发者导向的IaaS云厂商),实现原有网络的计算能力拓展,开始业务的分布式云平台转型,21年-25年公司云计算收入占比从7.31%提升至16.83%,根据Visible Alpha预测,26年公司云计算收入占比有望提升至18.85%。针对AI推理场景,25年公司推出Akamai Inference Cloud产品,底层算力与Nvidia合作(NVIDIA Blackwell GPU、BlueField-4 DPU),为AI客户提供Agent多步推理、智能调度等计算服务。25年Akamai Inference Cloud初步在全球20个地区上线。
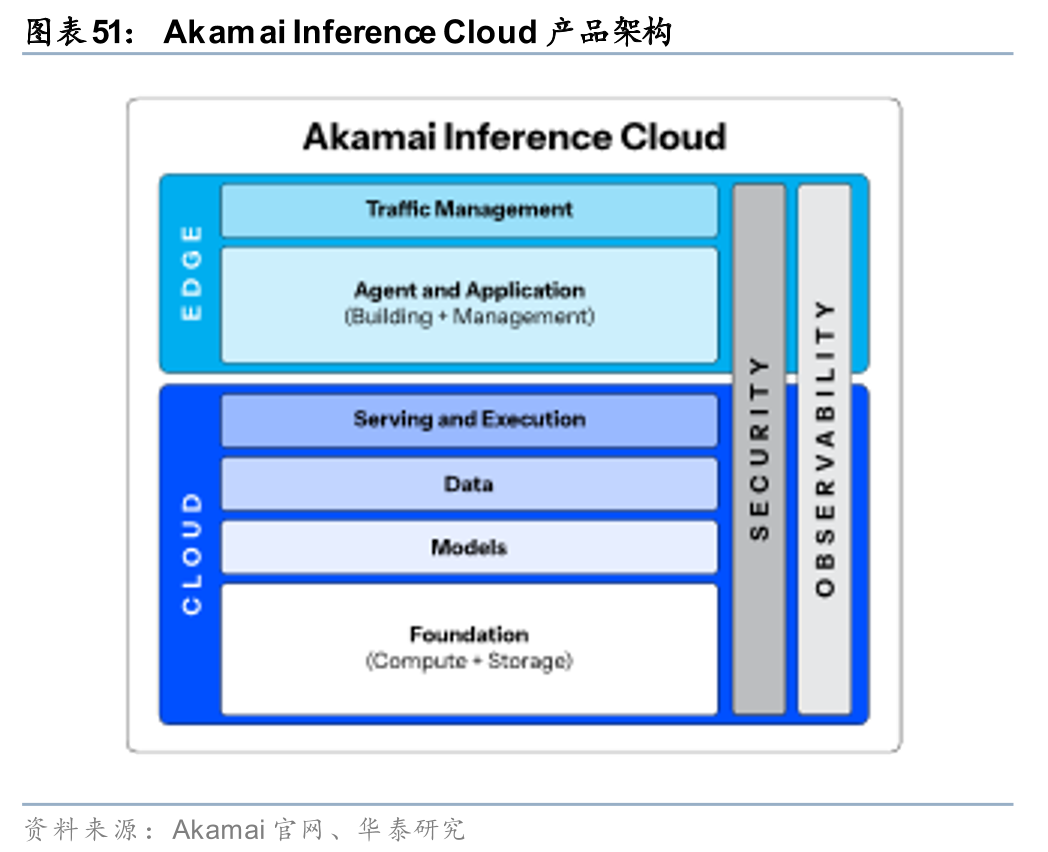
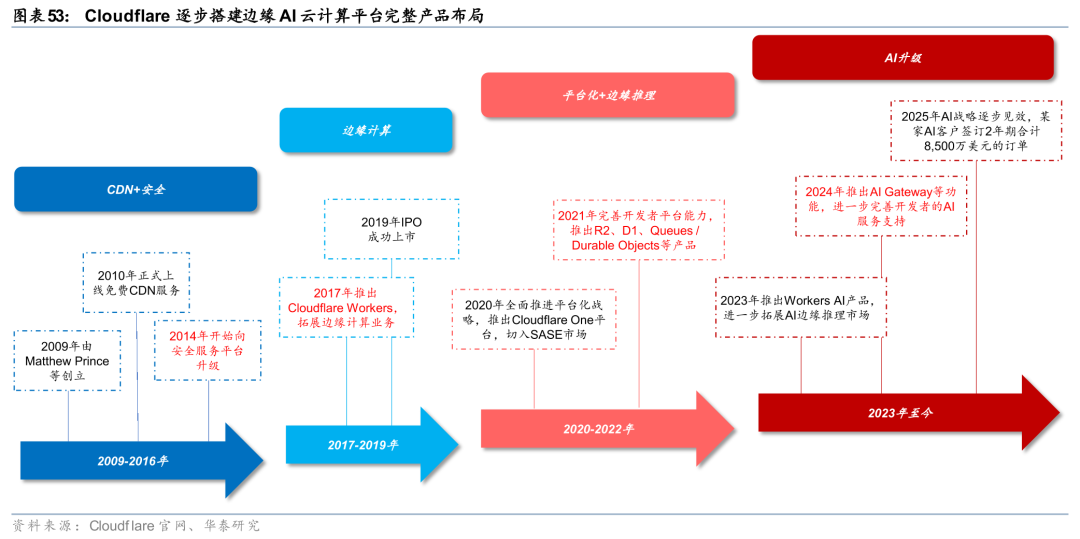
Cloudflare战略定位边缘AI云计算平台,全面推进边缘云业务转型。以边缘AI云计算平台为战略定位,Cloudflare已形成包括计算(Workers、Containers)、状态(Durable Objects)、数据(Workers KV、R2、D1)、AI(Workers AI、AI Gateway、Vector DB)、安全(Zero Trust)、网络(CDN)在内的完整产品布局。公司在AI推理场景具备先发优势,23年公司发布Workers AI(beta版),24年开放Workers AI正式商用版本,25年围绕模型生态(收购Replicate)、Agent交互、推理优化、AI安全等场景,对Workers AI进行全面升级。根据Cloudflare 25Q4电话会表述,公司正加速覆盖应用构建、流量承载、价值分配三大环节。
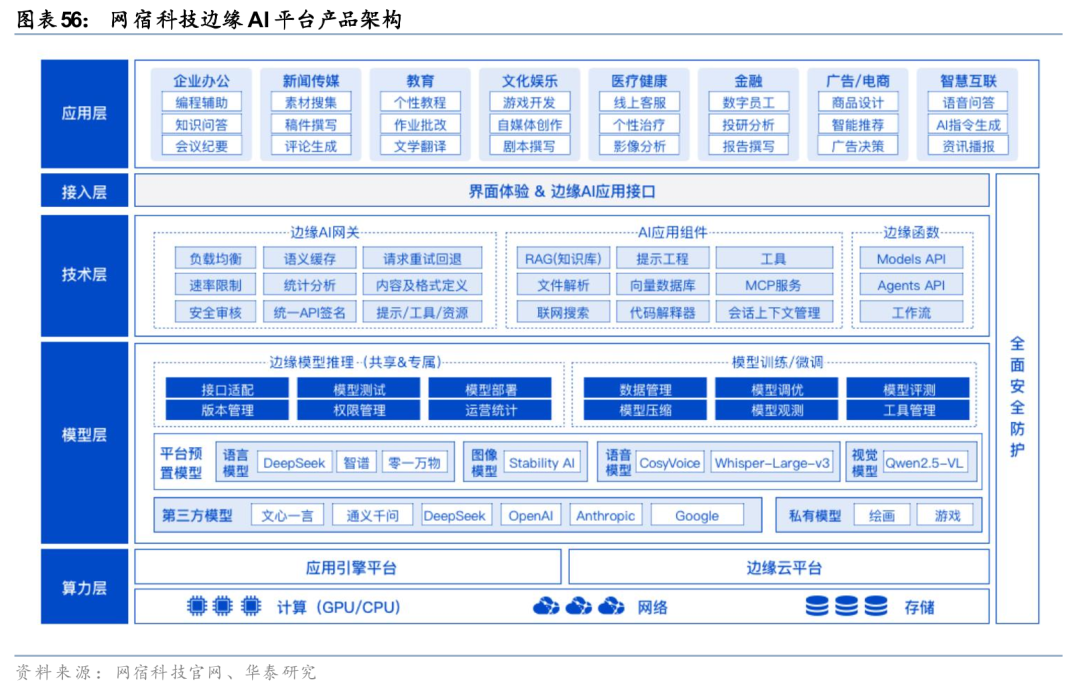
网宿科技推出边缘AI平台,提供计算、安全、AI模型的一体化服务。网宿科技(成立于2000年)深耕CDN行业二十余年,拥有全球2800 节点资源(其中国内节点2000 ,海外自有节点800 )。面向AI应用场景,公司自23年起持续推进产品升级。23年8月,公司推出GPU算力平台,基于全球分布的节点资源,提供高性能GPU算力资源;24年8月,公司推出边缘AI网关,轻松接管多种大模型;25年4月,公司对象存储全面兼容MCP协议,成为AI大模型的坚实“数据底座”;25年11月,公司发布边缘AI实时语音交互方案,为企业打造高品质、低延迟、低成本的下一代语音交互体验。公司打造的边缘AI平台,可以为客户提供包括AI计算、AI模型、AI服务中台、AI应用在内的一体化服务。
1)AI计算:高性能计算、网络和存储资源,支撑AI应用的数据高效流转;基于边缘云原生架构搭建的Serverless平台,为上层服务提供秒级弹性伸缩与高可用环境;
2)AI模型:集成全球主流模型,基于LLM技术栈等AI技术,提供模型推理加速和托管服务,支持文本生成、语音识别、图像处理任务;
3)AI服务中台:支持第三方、开源、私有模型灵活接入和管理,集成RAG知识库、联网搜索、MCP服务等能力组件,开发者可通过边缘函数自定义代码,实现业务逻辑组装,提升AI应用开发效率;
4)AI应用:基于“多模型协作 场景化工具链”技术,打造垂直领域智能体生态,驱动电商、医疗、新闻、娱乐、教育、金融等产业智能化升级。
海外边缘云商业化节奏领先,国内边缘云蓄势待发
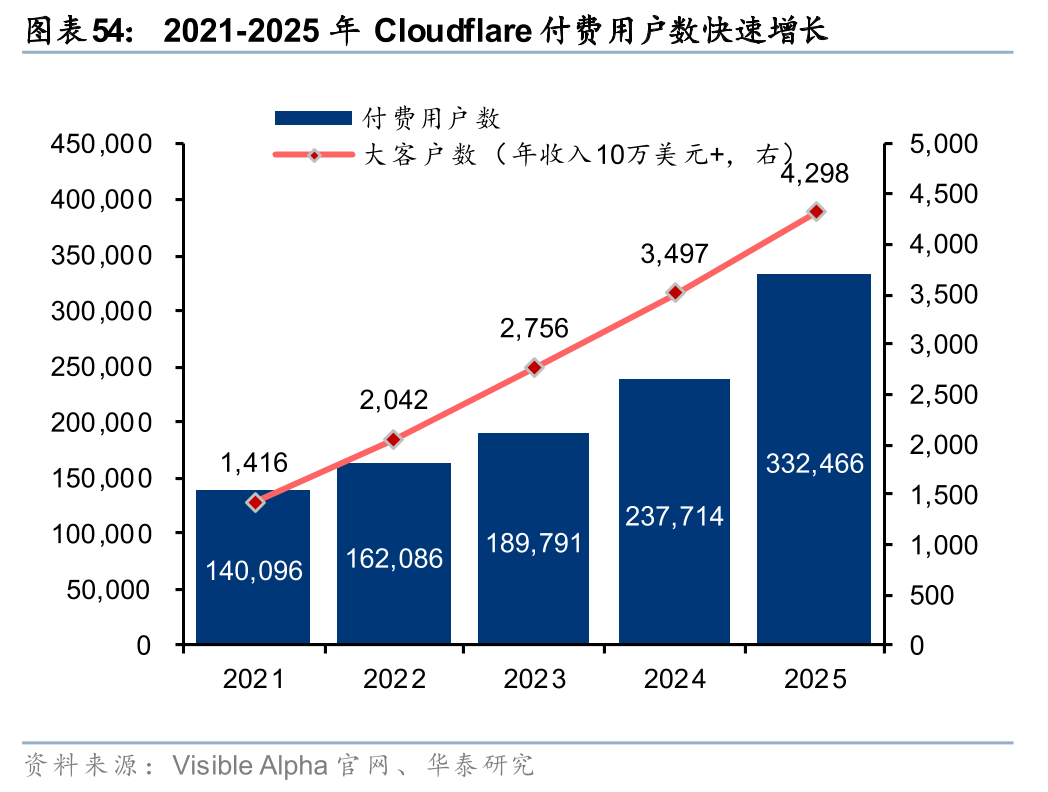
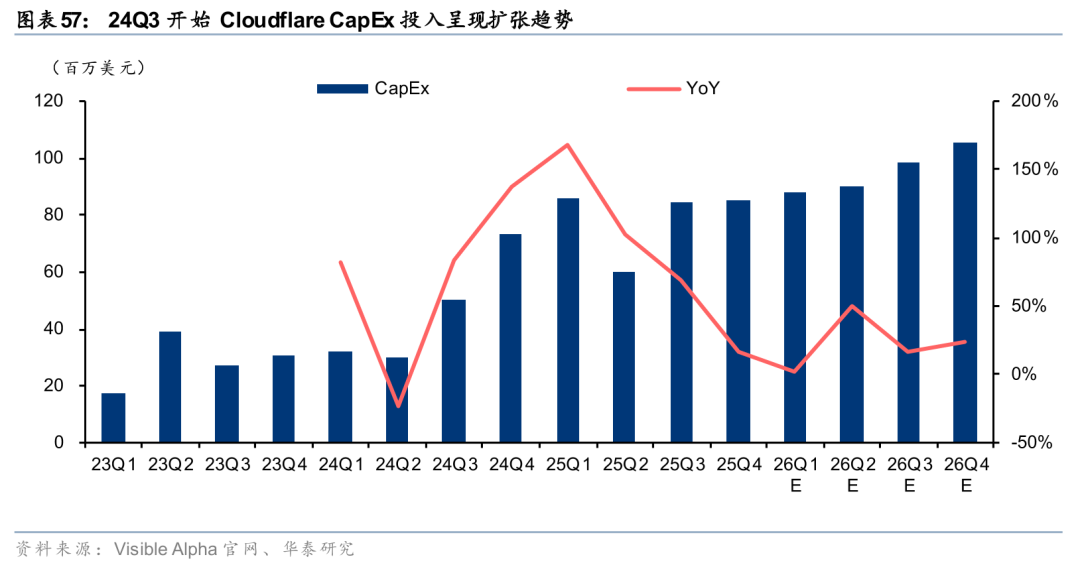
海外边缘云商业化节奏相对领先,25年Akamai、Cloudflare均收获大额订单。从商业化节奏上看,海外边缘云厂商的节奏相对领先。根据Akamai 25Q4电话会表述,公司与AI大客户签订为期4年价值2亿美元的大额订单,公司目前已部署20个Inference Cloud节点,短期内计划拓展至40个,长期目标拓展至100个;根据Cloudflare 25Q4电话会表述,公司与AI客户签订为期2年价值8500万美元的大额订单,同时收获多个百万美元级AI开发平台订单。海外边缘云业务已进入商业落地期,CDN扩大CapEx投入,25年Akamai、Cloudflare的CapEx分别为8.20、3.16亿美元,同比 19.59%、 70.57%。
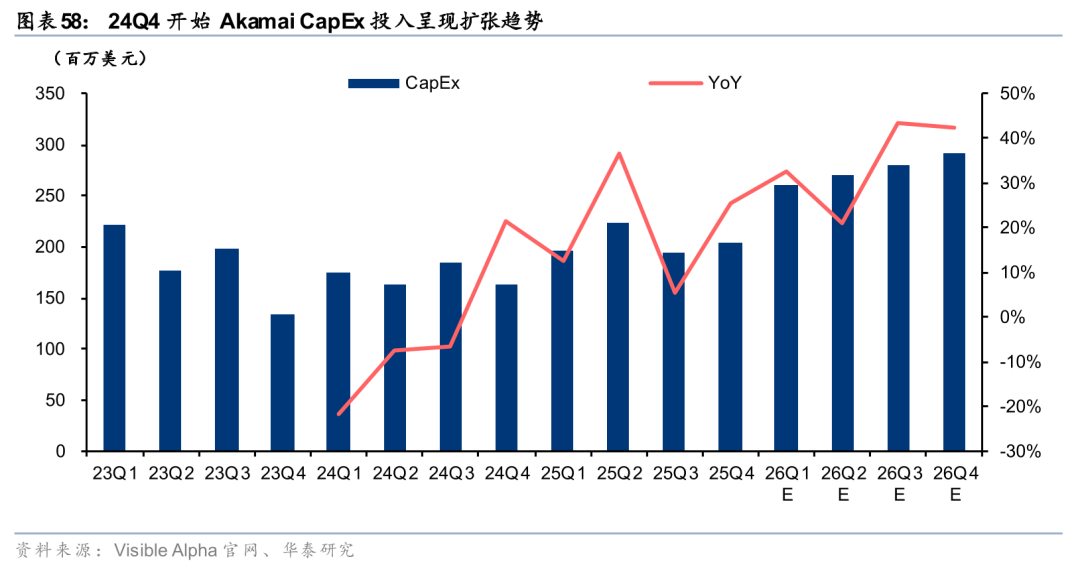
Agent应用全面提速,国内边缘云蓄势待发。从产品化角度来看,国内厂商已经具备边缘AI完整产品布局。26年初,OpenClaw带动国内Agent应用热潮,我们认为,Agent应用提速有望带动国内边缘云业务需求。
投资建议:建议关注边缘云
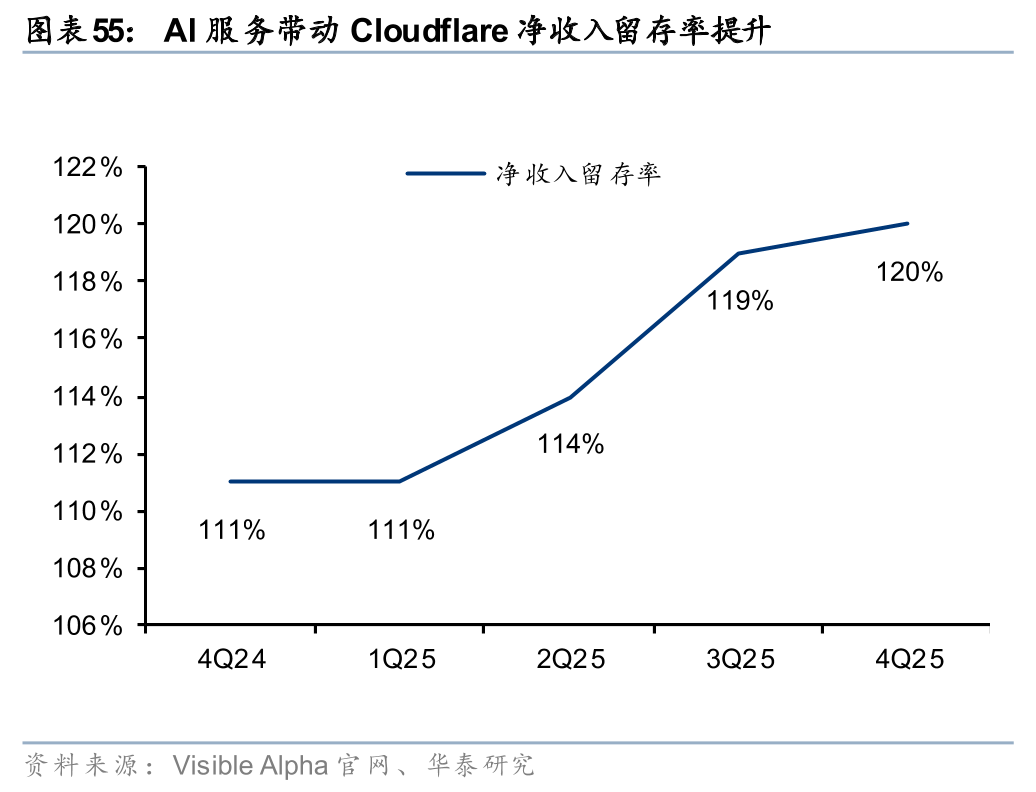
总结来看,伴随推理需求(Agent加速落地)向边缘侧持续下沉,云服务架构有望加速从传统集中式模式进一步向云、边、端协同的分布式体系升级,边缘云战略地位将持续提升。海外方面,Akamai、Cloudflare持续完善边缘AI平台布局并取得大额订单,边缘云商业化已率先进入落地阶段,26年核心关注相关公司的商业化进展;国内方面,OpenClaw带动Agent应用提速,国内厂商已初步具备边缘AI平台能力,边缘云有望在AI应用放量过程中快速受益,26年核心关注相关公司的产品升级及下游需求变动。
Physical AI:世界模型赋能,AI迈入物理世界
AI进入物理世界的“操作系统级跃迁”
Physical AI已实现从技术概念到产业落地的关键突破,成为AI产业较确定的成长主线。空间智能、实体载体、世界模型三大支柱逐步成熟,数据供给与虚实迁移技术持续突破,支撑人形机器人、自动驾驶等场景快速落地。2026年人形机器人进入全面量产周期,核心硬件需求高速释放;自动驾驶依托世界模型破解长尾难题,L3商业化进程显著加快。英伟达以全栈技术与全球化生态主导全球产业发展,带动国内软硬件产业链同步升级。中长期看,Physical AI市场快速增长,虚实融合、数据驱动、软件定义成为核心产业趋势,技术迭代、场景落地、生态扩张三重共振,行业进入持续高景气阶段。
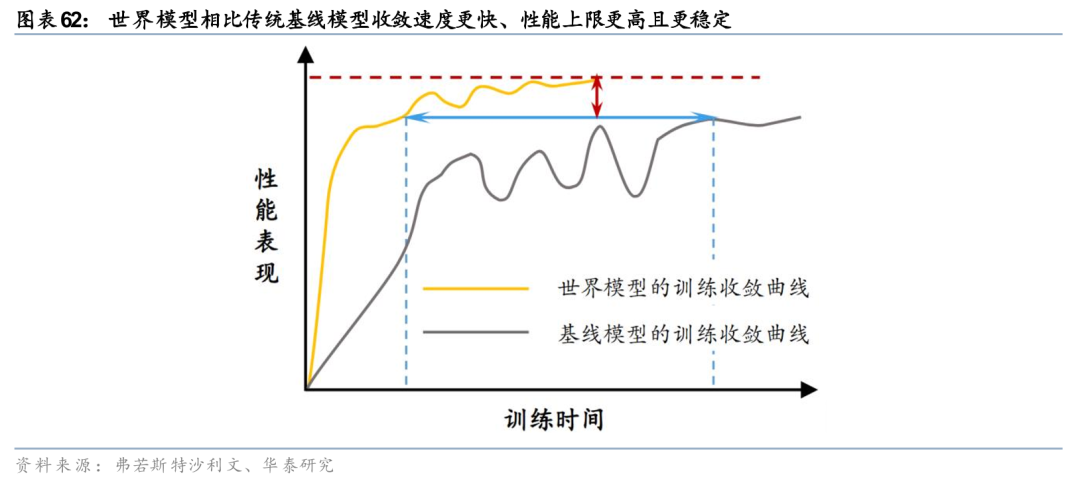
我们认为Physical AI是继生成式AI之后的最强产业主线。我们判断2026年为Physical AI规模化落地元年,人形机器人全面量产、自动驾驶L3加速落地,两大场景共振驱动行业进入高景气成长周期。空间智能赋予三维理解能力,物理AI为实体载体,世界模型为智能中枢。世界模型直击“感知-决策-执行”闭环,是Physical AI落地的核心引擎。数据是Physical AI最稀缺的生产要素,我们判断,能高效解决数据供给与虚实迁移的技术路线,将构筑最强商业壁垒,相关平台型公司具备长期投资价值。
2026年,AI技术正加速从Generative AI向Agentic AI和Physical AI迈进。AI技术的演进历程大致可以划分为Perception AI、Generative AI、Agentic AI、Physical AI四个阶段。Agentic AI具备自主完成复杂任务链条的能力,包括理解任务、规划路径、调用工具并执行反馈的端到端闭环;Physical AI的重点在于打破虚拟与现实的界限,让AI系统通过机器人等工业装备实体,在物理世界中实现环境感知、交互和执行;二者共同推动AI从“能理解”、“能生成”向“能认知”的新阶段跨越。
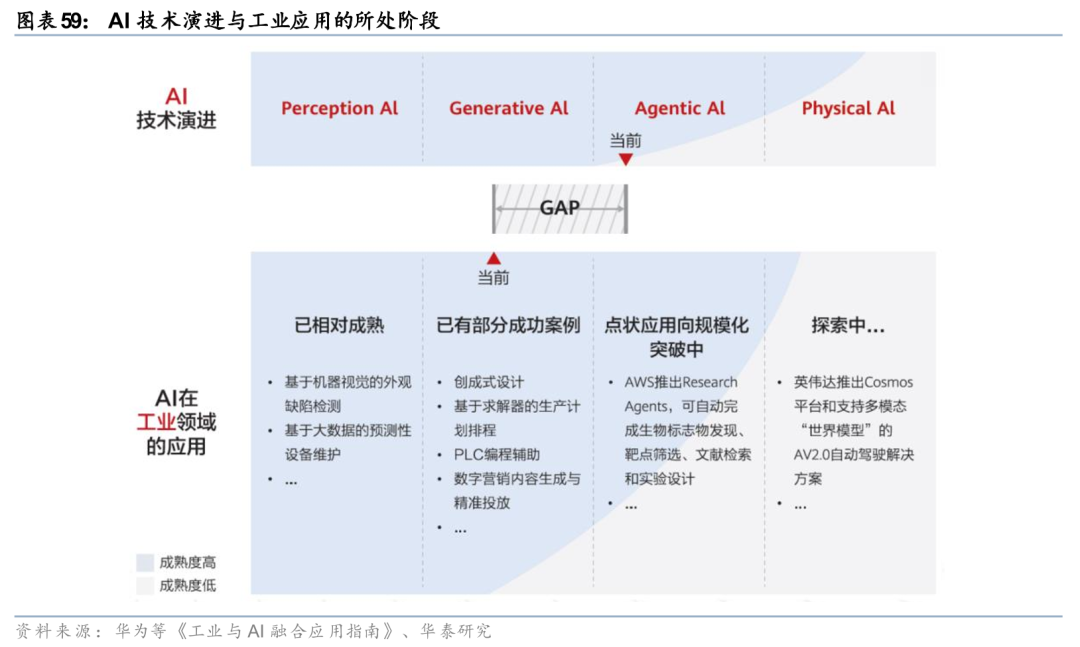
空间智能、物理AI与世界模型,共同构成了AI从“理解语言”迈向“物理交互”的核心概念体系。空间智能赋予AI理解三维世界的能力,物理AI(如机器人)是承载该能力的实体,而世界模型正是驱动这一切的“智能中枢”。LLM和世界模型的核心差异在于,LLM以文本为学习对象、以语言为输出形式,本质停留在“认知与表达”;而世界模型则以物理世界状态为建模对象,直接指向“感知—决策—执行”的能力闭环。
数据是Physical AI最稀缺的资源。不同于大语言模型互联网世界中提供了几乎无限的文本数据,Physical AI所面对的真实世界的操控数据较为稀缺,使得数据成为整个产业链中最稀缺资源之一,行业正探索三条主要路径:
1.真实数据路线(如Physical Intelligence):基于超1万小时真实机器人操作数据训练,提供“操控预训练基座”;
2.合成数据路线(如Google DeepMind、NVIDIA):通过世界模型生成模拟环境训练,核心挑战是“仿真到现实鸿沟(Sim-to-Real Gap)”;
3.人类遥操作路线:通过手套等设备采集高质量操作数据,但成本高、规模化难。

Physical AI先行落地场景——自动驾驶
世界模型正在突破自动驾驶商用瓶颈。自动驾驶目前面临的核心痛点在于传统算法难以有效应对占比不足0.1%、却决定99.9% 安全性的长尾场景,极端天气、道路突发状况等高复杂度真实驾驶环境,成为高阶自动驾驶落地的核心阻碍。世界模型可构建高保真物理驾驶环境,生成并覆盖传统方案无法处理的极端与风险场景,显著提升系统决策鲁棒性与场景泛化能力,有效补齐安全短板。依托世界模型的技术赋能,自动驾驶长尾问题加速破解,有力推动L3级别系统快速落地,并为L4及以上高阶方案的技术迭代与商业化验证提供关键支撑。
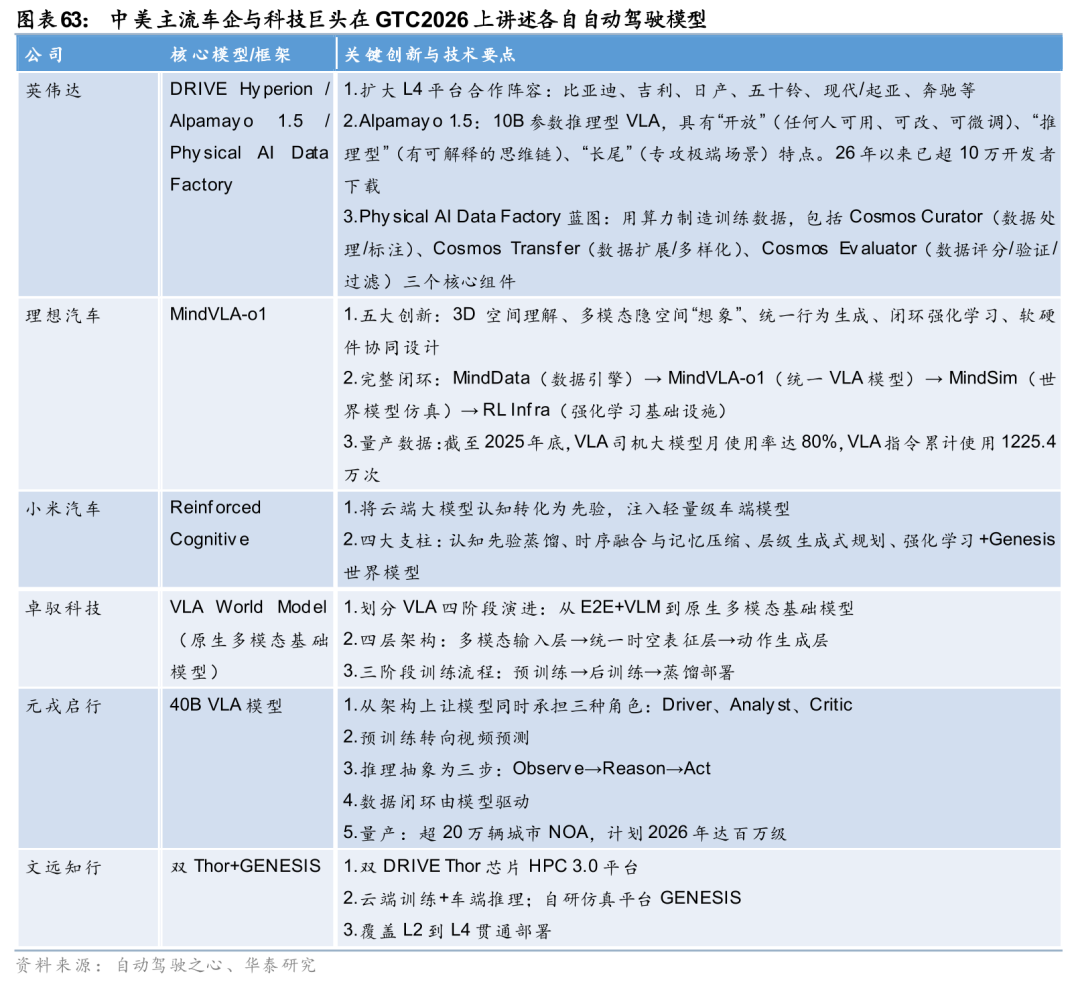
英伟达在GTC 2026大会重磅发布Physical AI全栈基础设施,覆盖L4自动驾驶平台DRIVE Hyperion、推理型VLA模型Alpamayo 1.5及Physical AI数据工厂,形成“硬件 模型 数据” 一体化解决方案。生态层面,比亚迪、吉利、Uber等国内外企业正式加入,进一步巩固其自动驾驶生态壁垒。国内厂商同步加速技术迭代,理想、小米、卓驭、元戎、文远知行等集中发布核心技术,围绕VLA架构、世界模型、生成式仿真三大方向推进研发,行业呈现两大清晰趋势:一是从模块化拼接转向原生多模态统一架构,二是由数据驱动升级为认知推理模式。
在全球科技巨头与本土车企协同推进下,自动驾驶场景技术成熟度快速提升,商业化落地节奏显著加快,正成为Physical AI领域最先规模化落地的核心应用方向。
Physical AI的终极形态——具身智能
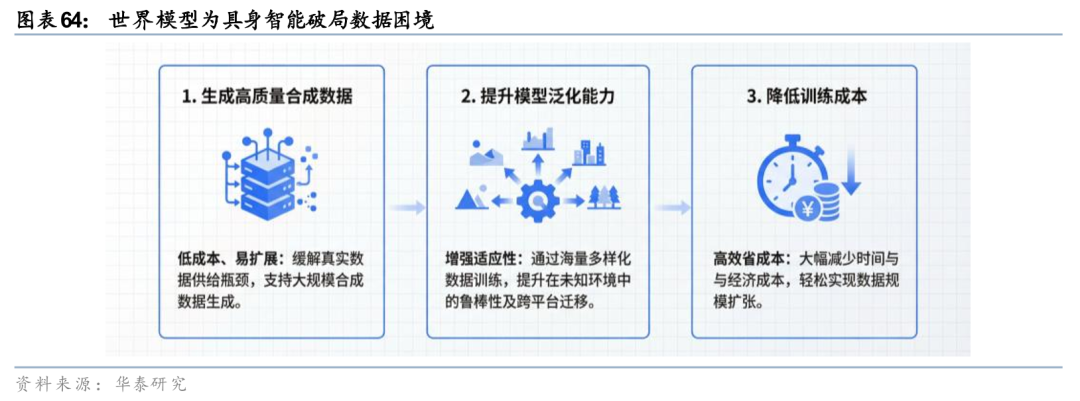
具身智能以人形机器人为核心载体,是Physical AI最活跃增长方向。具身智能现阶段发展的核心困境在于模型训练对数据的需求量大,但物理交互数据极度缺乏,世界模型为行业破局提供三重价值:
1. 生成高质量合成数据:为具身智能提供低成本、易扩展的合成数据,缓解真实数据供给瓶颈。
2. 提升模型泛化能力:通过海量多样化合成数据训练,增强模型在未知环境中的适应能力、鲁棒性及跨平台迁移能力。
3. 降低训练成本:大幅降低数据获取的时间与经济成本,轻松实现数据规模扩张。
2026年,人形机器人已全面进入量产阶段。2026年全球人形机器人进入全面量产阶段:根据马斯克在特斯拉24年股东会、24Q4业绩会的表述,特斯拉Optimus Gen 3部署超千台,规划千万台年产能;根据波士顿动力官网博客,波士顿动力Atlas与谷歌DeepMind合作,规划年产3万台;Figure AI获大额融资,产品在汽车工厂累计运行超千小时。国内方面,优必选、宇树科技、智元、小鹏等企业启动规模量产,宇树科技已向上交所科创板递交招股书,加速推进上市节奏。
英伟达:全栈布局先行,引领全球Physical AI产业发展
英伟达自2024年起持续引领Physical AI产业浪潮,战略布局清晰且节奏明确。2024年6月Computex大会,黄仁勋首次提出Physical AI核心概念,奠定AI向物理世界落地的产业基调;2025年3月GTC大会,公司正式发布Blackwell芯片架构、Cosmos物理AI平台及全栈技术方案,完成从底层算力到上层应用的完整布局。2026年1月CES大会,黄仁勋再度强调,Physical AI即将迎来ChatGPT时刻,将AI技术体系清晰划分为五层架构:能源、芯片、基础设施、模型与应用,自上而下构建全链路技术壁垒。该架构为Physical AI规模化落地提供底层支撑,也为机器人、自动驾驶、工业智能等下游场景打开广阔成长空间,成为全球Physical AI产业发展的核心指引。
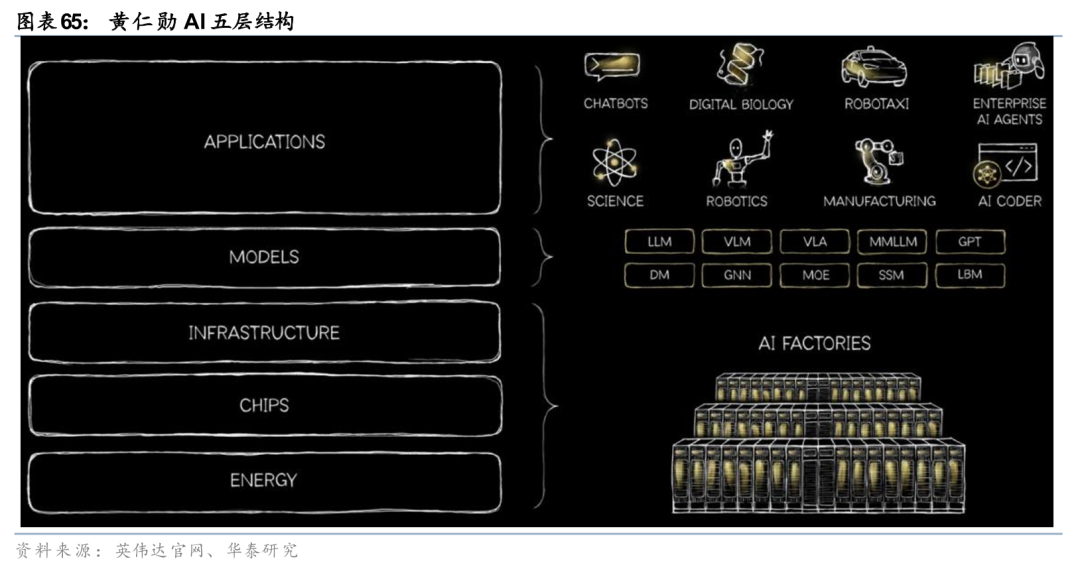
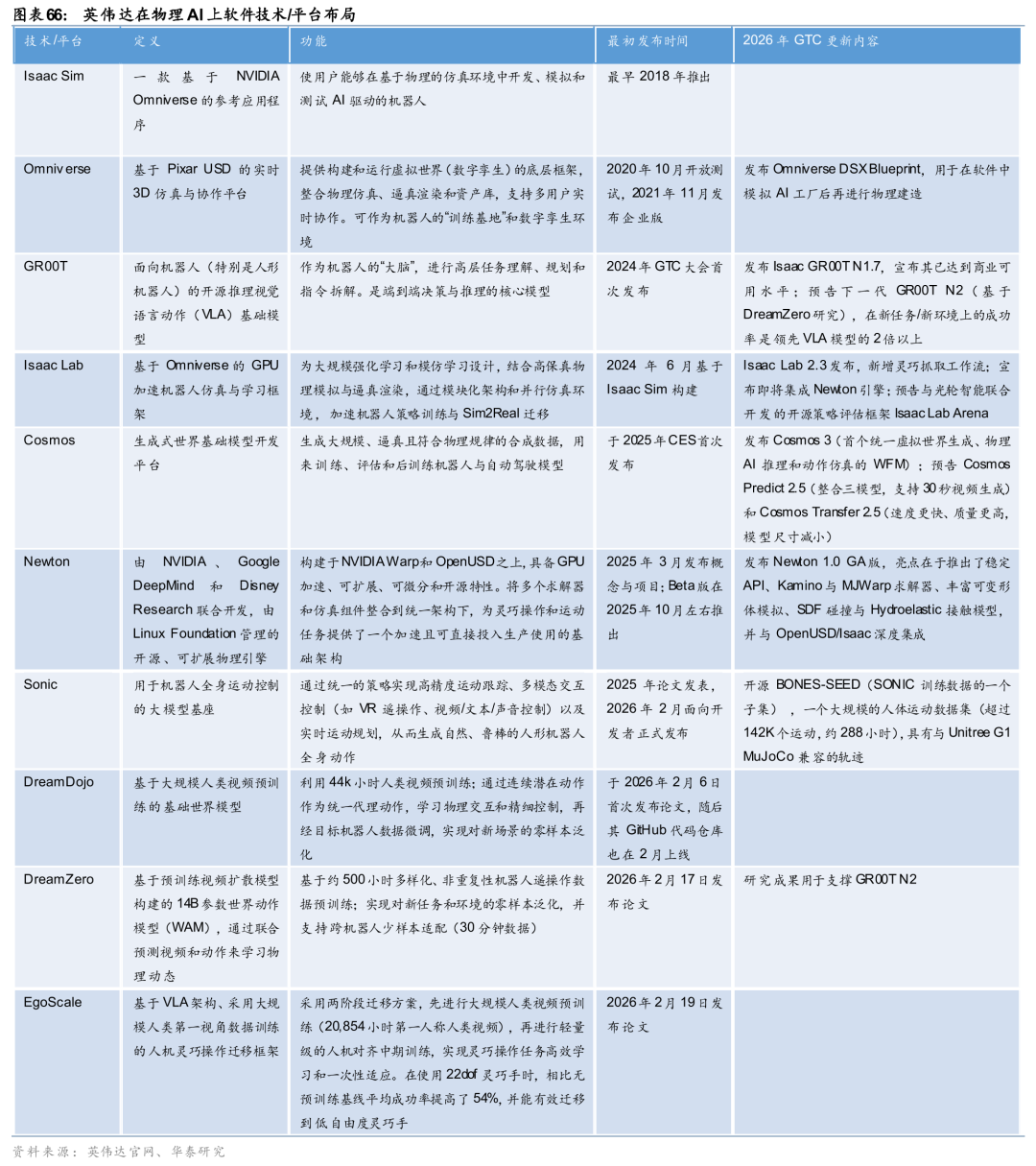
英伟达围绕Physical AI打造硬件 软件全栈闭环,技术布局深度领先。硬件端,公司推出面向边缘实时推理的Jetson Thor、IGX Thor平台,以及DGX Station桌面级AI超算,全面覆盖端侧低延迟推理与云端高强度训练需求,为物理AI实体提供充沛算力底座。软件端,构建一体化技术体系:以Cosmos实现大规模合成数据生成,依托Omniverse、Isaac Lab、Newton引擎完成高保真物理仿真训练,通过GROOT、Sonic、DreamDojo、DreamZero、EgoScale等基础模型算法支撑感知决策与动作控制,并配套自动化评估与部署工具链,形成“数据-仿真-模型-部署”完整闭环。依托该体系,机器人、自动驾驶等物理AI应用可在虚拟环境中完成全流程训练验证,以数据驱动、软件定义模式实现快速迭代与低成本优化,显著缩短产品落地周期、提升泛化能力,为Physical AI规模化商用奠定核心技术基础。
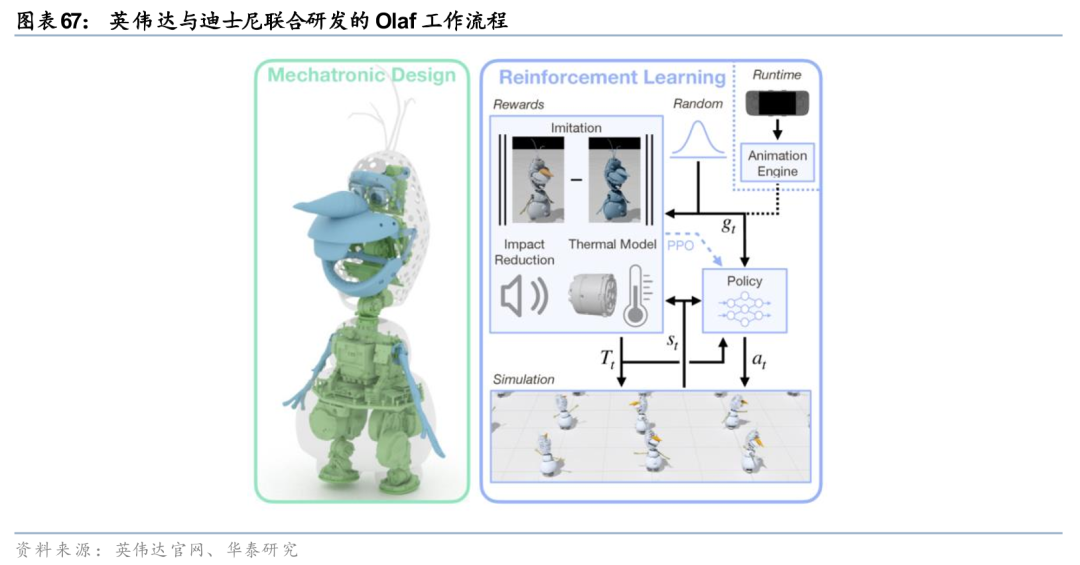
英伟达在GTC 2026进一步扩大物理AI联盟生态版图,全球化合作体系持续完善。自动驾驶领域,比亚迪、现代、日产、吉利正式加入RoboTaxi Ready平台,与奔驰、丰田、通用等国际车企形成强强联合,生态阵容持续强化;同时公司与Uber达成战略合作,加速无人驾驶车辆在全球多城市规模化落地与商业化运营。工业机器人领域,英伟达与ABB、KUKA等全球龙头深化协同,推进物理AI模型在智能制造产线的规模化部署与落地应用,赋能工业场景智能化升级。GTC 2026现场,英伟达与迪士尼联合研发的Olaf机器人正式亮相,该产品搭载Jetson系列芯片,依托Omniverse平台完成全流程仿真训练,充分验证公司在物理仿真、具身智能领域的技术实力与工程化能力。
投资建议:看好Physical AI相关产业链
Physical AI已成为AI技术从虚拟走向现实的操作系统级跃迁,行业进入规模化落地关键期。AI技术沿感知、生成、智能体、物理交互持续演进,空间智能、物理实体、世界模型构成三大核心支柱,数据稀缺与虚实迁移仍是产业核心瓶颈。2026年人形机器人全面进入量产阶段,国内外厂商加速产能扩张;自动驾驶依托世界模型破解长尾场景难题,L3商业化提速,成为Physical AI最先落地的主流场景。中长期看,Physical AI将覆盖机器人、自动驾驶、工业制造等赛道,虚实融合、数据驱动、软件定义成为产业发展主线,技术迭代与生态扩张共振下,行业进入高景气成长通道。
基于Physical AI规模化落地与高景气趋势,我们坚定看好三条核心投资主线:
1. 世界模型与仿真平台环节:关注具备合成数据生成、高保真仿真、VLA模型研发能力的平台型企业,把握算法与数据核心壁垒。
2. 自动驾驶物理AI化产业链:聚焦L3量产车企、算法与传感器龙头,受益场景落地加速与估值重构。
3. 英伟达生态链:布局具备协同能力的硬件、软件与应用企业,分享全栈技术扩散红利。
投资建议:看好模型厂商&算力通胀/国产算力链
AI产业正加速迈向以推理需求扩张和生产力场景落地为核心的新阶段。模型层竞争焦点转向复杂与长程任务的交付;Agent加速落地持续推高算力总需求,带动CPU、AI互联、超节点、云服务及国产算力产业链景气全面上行;Infra层面边缘云正逐步成为承接AI应用落地的关键基础设施;Physical AI正从技术验证稳步迈入产业化阶段。我们持续看好模型厂商&算力通胀/国产算力链三大主线:
头部模型环节。我们认为,模型竞争正从能力展示转向闭环交付与商业兑现,具备基座模型持续迭代与Agent执行能力的平台型厂商具有持续的投资价值。随着OpenClaw推动Agent需求放量,头部模型厂商的商业化加速趋势有望持续强化。
算力环节,我们看好算力通胀链条和国产算力链。算力层本轮需求扩张已从单一训练侧拉动演进为训练、推理、部署全链条共振驱动的系统性重构,Agentic AI加速落地推动需求由训练向推理持续外溢,我们建议短期关注算力租赁/云等环节,中期持续看好全球算力产业链上游的GPU/存储/互联环节以及国产算力链。
关注Infra与Physical AI机会,看好AI应用环节营收/利润双提速的标的。Infra环节,我们看好边缘云环节,海外Akamai、Cloudflare商业化已率先落地,边缘云有望在AI应用放量过程中快速受益,相关公司请见研报原文。Physical AI环节,我们认为自动驾驶和具身智能的商业化正在进一步清晰,建议关注相关环节。AI应用方面,我们重点看好营收和利润有望双提速的标的。

 VIP复盘网
VIP复盘网
