

在3D角色动画创作领域,高质量动作资产的匮乏长期制约着产出的上限。
游戏、动漫、影视与数字人等产业始终面临一个成本困局:从数万元起步的专业动捕采集,到动画师以“天”为单位的手工精修骨骼动画,每一秒丝滑动作的背后,都是高昂的资源堆砌。
而在生成式AI领域,文生动作(Text-to-Motion)也因高质量数据的稀缺与计算范式的局限,长期处于“小模型”阶段,这类模型在面对复杂的自然语言指令输入时,很难做出创作者希望得到的正确动作。
近年来,也有不少研究开始尝试通过大语言模型扩展词表的方式来做动作生成,这类模型虽然能将模型尺寸扩展到了较大的规模,但由于采用了离散的动作Tokenizer,生成的动作质量往往并不理想。
在这个背景下,腾讯混元团队借鉴其在视频生成大模型上的成功经验,提出了一套全新的、旨在突破当前瓶颈的文生动作解决方案,通过构建一套严格的数据处理与标注管线,覆盖大规模预训练、高质量精调、强化学习对齐的全阶段训练流程,并将Diffusion Transformer(DiT)模型扩展至10亿级别参数量,成功研发了混元Motion 1.0(HY-Motion 1.0)这一业界领先的动作生成基础模型,并将该模型于2025年12月30日对外开源(见文末链接)。
其核心思路在于,将动作生成任务从“手工作坊”式的模型训练,升级为“现代化工业”级别的大模型构建范式,它不仅在规模上实现了里程碑式的突破,更通过全链路的算法创新,为3D角色动画生成确立了新的技术范式。
HY-Motion 1.0的研发过程,并非单一的算法创新,而是一整套数据工程与训练范式协同进化的结果。
一、核心技术
1. 数据引擎:3000 小时多源资产的工业级精炼
大规模、高质量的数据是支持1B参数模型性能的基础,为此,混元团队构建了一套标准化的数据处理管线,最终沉淀出总计超过3000小时的动作数据。
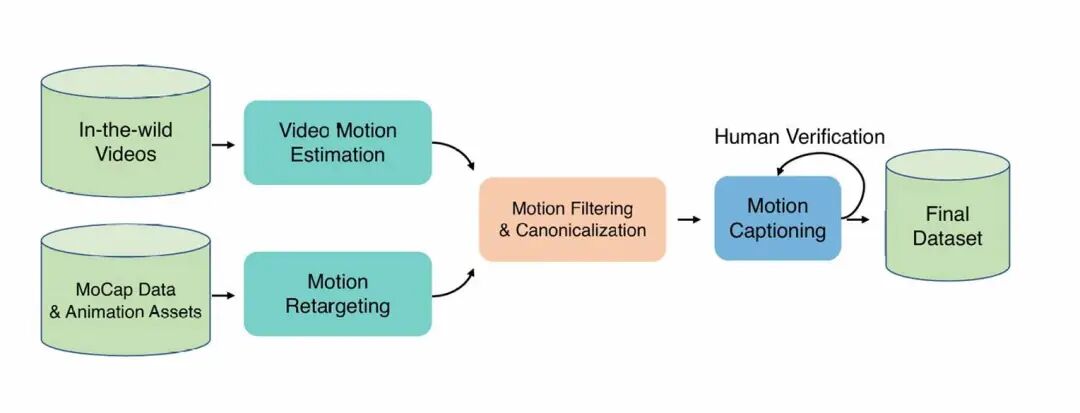
△ HY-Motion1.0数据处理流程图
多源数据的融合:整合了提供动作场景多样性的单目视频动捕、保障高精度的光学动捕,以及具备极高表现力的艺术家手K动画资产。通过多元数据融合,平衡模型的泛化能力与生成质量。
数据清洗与标准化:所有异构数据被统一重定向至一套标准骨骼。通过自动化工具剔除重叠、异常姿态、异常位移及严重滑步片段,最终统一为30fps对齐的切片数据,确保模型学习效率。
VLM LLM的标注闭环:采用“渲染→VLM初标→人工校验→LLM结构化扩写”流程。利用视频多模态模型捕获语义,结合人工修正补全细节,最后通过LLM进行描述多样性扩充,避免模型对特定句式过拟合。
极致的动作覆盖:数据涵盖了基础移动、日常生活、社交休闲、健身户外、体育竞技、游戏角色动作6大领域,200 细分动作类别,为模型的泛化能力打下了最坚实的基础。
2. 生成管线:让模型“听懂”指令
用户的输入往往很随意(比如“跳个舞”),但模型生成需要精确的语义与时序引导。为此,混元团队设计了一个专门的LLM Prompt Engineering模块来做用户Prompt改写及动作时长估计,类似于充当“动作导演”的角色。
数据合成:构建了包含{用户指令,优化指令,动作时长}的三元组数据集,利用Gemini-2.5-Pro模拟了海量真实、模糊的用户Prompt,并与高质量描述及真实时长进行精准对齐。
两阶段微调:SFT阶段—基于Qwen3-30B-A3B进行微调,使模型具备将多语言模糊指令转化为“结构化英文描述 精确时长”的能力;GRPO强化学习—引入Qwen3-235B作为奖励模型(Reward Model),从“语义一致性”与“时序合理性”维度进行打分优化,进一步提升模块的泛化性能。
最终,Prompt Engineering会将用户的中文/模糊指令转化为“英文动作描述 精确时长”,显著提升了生成的可控性。
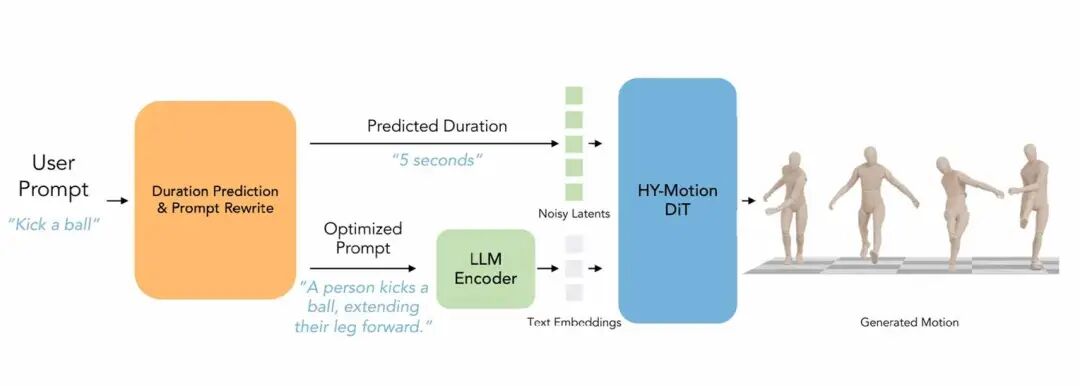
△ HY-Motion1.0框架
3. 模型设计:DiT Flow Matching
在核心生成架构上,混元团队采用了Diffusion Transformer(DiT)结合Flow Matching。
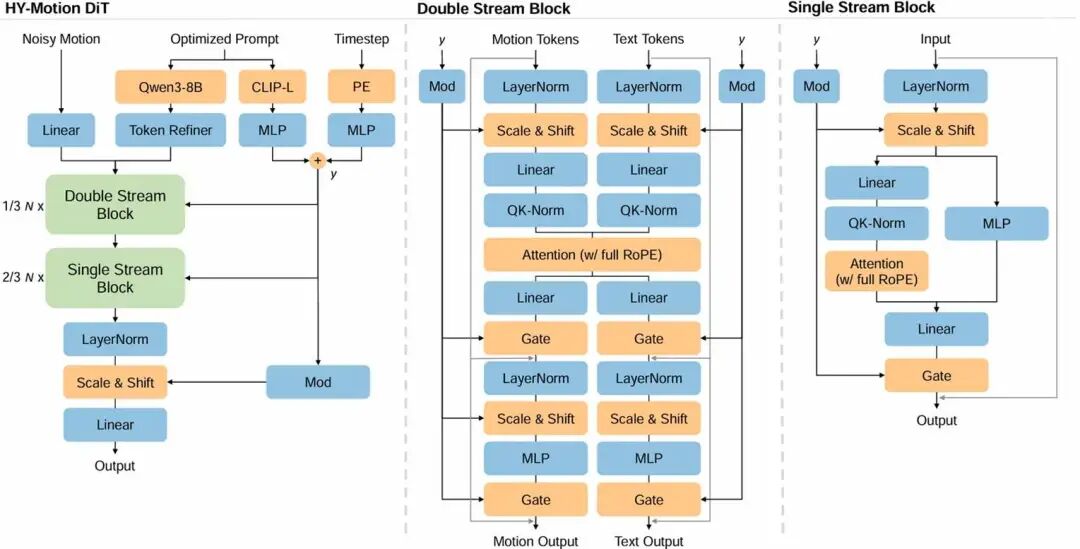
△ HY-Motion1.0模型结构
双流混合架构:参考HunyuanVideo的设计,采用了“双流(Dual-stream)→单流(Single-stream)”的结构。在双流阶段,动作Latent和文本Token独立处理,通过self-attention进行交互;在单流阶段,两者拼接为统一序列,进行深度的多模态融合。
长时序稳定性:针对长序列生成中的逻辑崩坏与动力学断裂,混元团队通过“语义防污染”与“局部约束”双管齐下,确保了动作的演进既符合指令逻辑又满足物理连续性。
非对称掩码机制:强制执行“动作感知文本,文本屏蔽动作”的注意力偏置。这一设计有效切断了扩散过程中噪声向文本语义的回流,保障了全局语义引导的纯粹性与稳定性。
窗口注意力:基于动作的短时相关性,通过窗口限制鼓励模型专注于动作片段内部的建模和片段间的过渡,提升潜在的泛化性并缓解生成长序列时遇到的“动作跳变”或“鬼畜”现象。
4. 全流程训练:RLHF注入指令执行力
混元团队将LLM领域的RLHF范式完整迁移到了动作生成中,完整跑通了“Pre-train->SFT->RLHF”的三阶段训练:

△ HY-Motion1.0训练范式
Large-scale Pretraining(预训练):在3000小时全量数据上进行大规模预训练,让模型“见多识广”,学会各种动作的基本范式。
High-quality Fine-tuning(精细化微调):筛选了400小时的精标高质量数据进行微调,显著减少了动作抖动和滑步,提升画质。
Reinforcement Learning(两阶段强化学习):采用“DPO Flow-GRPO”策略:
DPO:基于9K 对偏好数据,通过最大化优胜样本似然差,解决“动作像不像”的审美对齐问题,大幅提升生成Pass Rate。
GRPO:引入包含语义一致性与物理约束的奖励函数,补齐DPO难以处理的硬性评价准则,强化动作的物理真实感。
二、生成结果展示
得益于参数规模及数据质量带来的提升,HY-Motion 1.0在SSAE(语义结构自动评测)指标上达到了78.6%,指令遵循能力远超SOTA模型。该结果在人工5档打分中得到了印证(如下图)。
注:SSAE是利用Video-VLM进行自动化评测。该方案将“文本-动作对齐”转化为视频问答任务:先将Prompt拆解为若干细粒度的判断题(如“是否在踢腿”、“是否在挥臂”),再调用VLM对生成动作的渲染视频进行逐项验证,以此量化模型对复杂语义的还原能力。
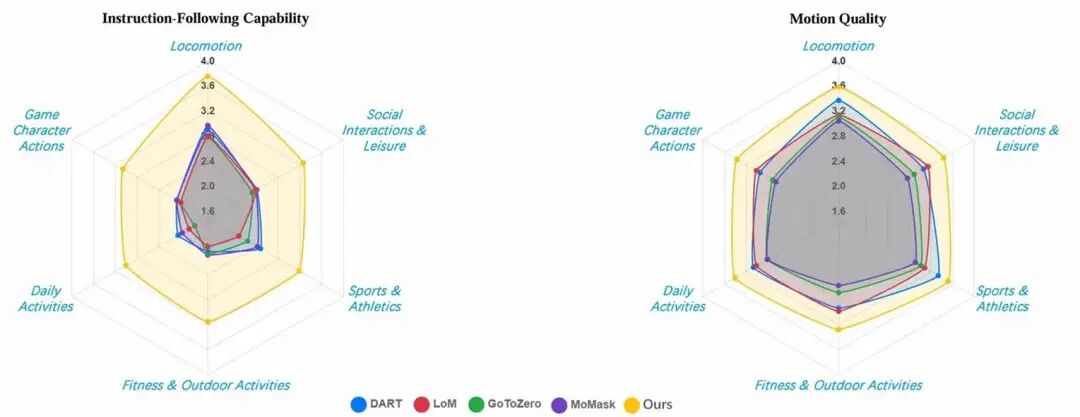
△ 数值结果对比图
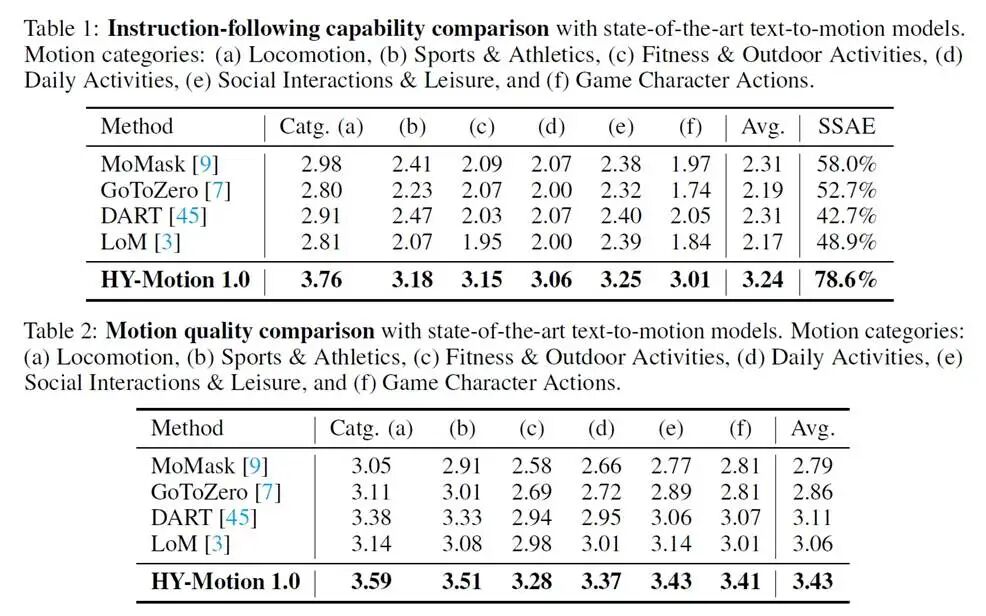
△ 数值结果对比表格
三、开源共建:技术演进与产业效能的进阶
自开源发布以来,HY-Motion 1.0在各平台热度持续上升。
游戏开发者、AI设计师、动画师、影视/广告创意导演等相关从业者纷纷投入使用,并在社交媒体与技术社区分享其实测效果。
游戏开发:开发者们自发将其集成至ComfyUI等主流AI工作流中,实现了3D动作资产的“即插即用”;同时,针对个性化创作需求,社区涌现出一系列自动化重定向脚本与工具,支持将生成的动作一键映射至用户自定义角色。
△ 结合ComfyUI的工作流
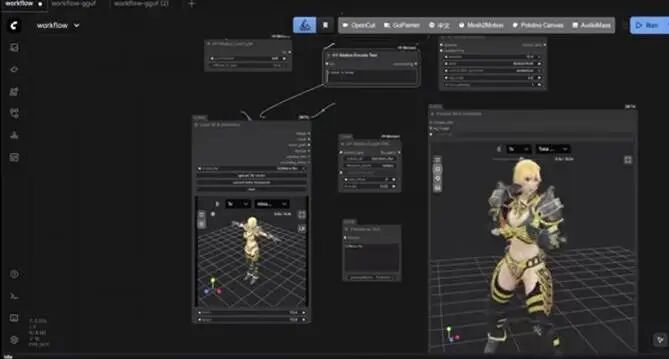
△ 结合ComfyUI支持自定义角色绑定
控制文生视频:有开发者也尝试将本研究输出的结果作为视频生成模型的控制信号,让其生成的动作更可控/可编辑。
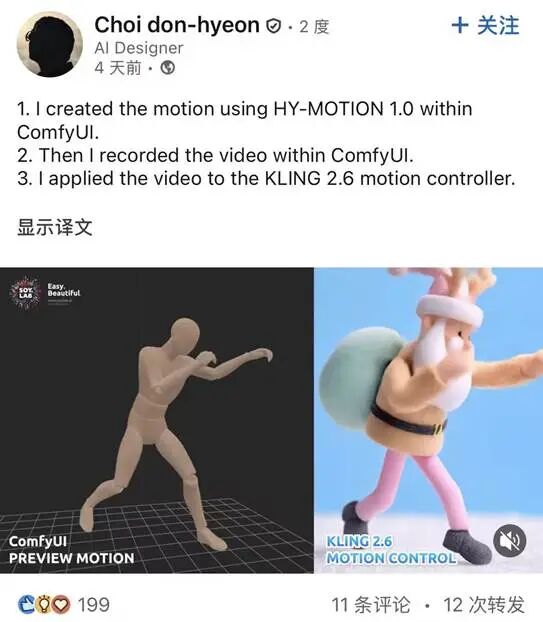
△ 一位AI设计师结合Comfy UI和KLING的工作流
HY-Motion 1.0的研发模式背后,依托的是腾讯在游戏、数字内容等领域深厚的业务场景。真实且高标准的落地需求,驱动模型在生成的视觉美感与工业精度上不断对齐。
对社区及个人创作者来说,HY-Motion 1.0不仅能让其在缺乏高昂动捕设备的情况下,依然产出高质量的动作资产,也为产业上下游提供了一套更具性价比的AI解决方案。
当前的3D动作生成模型仍面临着滑步处理、极端物理交互等行业性难题,距离“完美模拟”仍需持续探索。
腾讯选择此时将核心能力开源,希望通过技术普惠激发社区共建的力量,在真实的产业应用中不断迭代,共同推动3D角色动画制作从“手工精修”向“智能生成”的范式转型。

 VIP复盘网
VIP复盘网
