

存储芯片是仅次于逻辑芯片的第二大半导体品类,历史上是兵家必争之地、需要强资产投入,周期性明显。但随着AI这波浪潮中对于上下文context和推理缓存的极致需求,内存价格随着供需失衡持续高涨,AI服务器中内存芯片价值量不断提升并逼近逻辑芯片,黄仁勋也需要去韩国请海力士工程师团队吃炸鸡确保产能(LOL),2026年存储三强三星、SK海力士、美光可能都会达到千亿美金级别净利润。
那么这波AI带来的超级周期与之前几波相比会有什么异同?本文通过五个阶段复盘以获得启示。
阶段一:周期绞肉机与三寡头格局形成 (1980s-2012)
政府补贴使得DRAM行业的竞争格局在上世纪八十年代进入日本主导。七十年代末,日本政府启动“超大规模集成电路(VLSI)计划”,整合日立、NEC、富士通等企业,通过资金补贴提升良品率,向全球DRAM市场输出产能。这一举措直接冲击了全球商用DRAM开创者英特尔,其市场份额从超过80%跌至不足2%。1985年,安迪·格鲁夫与戈登·摩尔决定彻底关停DRAM业务,全面转向CPU。日本半导体企业借此夺下全球近80%的DRAM市场份额。
随后韩国企业通过逆周期扩产改变行业规则。在1995年至1997年的亚洲金融风暴期间,全球DRAM价格暴跌超过70%,日本企业普遍缩减投资。三星集团掌舵人李健熙(Lee Kun-hee)通过集团内部资金调配,将半导体部门的资本开支逆势翻倍,通过降价策略抢占市场。2008年全球金融危机爆发,DRAM现货价格跌破0.3美元的材料成本线。全行业放缓在60纳米节点的投资时,李健熙再次追加超过70亿美元的年度资本开支,凭借设备先期投入,将量产工艺直接推进至40纳米及30纳米级别,大幅提高了制造成本的准入门槛。
制程的快速迭代加剧了企业在技术路径选择上的分歧与风险。2009年初,德国存储企业奇梦达宣告破产。其首席执行官罗建华坚持采用传统“沟槽式”电容架构,但当制程向70纳米及58纳米微缩时沟槽的深宽比大幅增加,导致硅片在蚀刻过程中大面积坍塌,良品率暴跌。同期,三星已提前转向新式“堆叠式”电容路线,向硅基底上方垂直构建电容。底层架构的误判导致奇梦达良率无法达标,在寻求3.2亿欧元政府救助贷款失败后退出市场。——后来合肥长鑫技术起步来自2019年收购的奇梦达1000万份技术文件遗产。
SK海力士凭借极致的工程师精神经历了长期的债务重组与产能维持。1999年亚洲金融危机后,韩国政府撮合现代电子与LG半导体合并,新生的海力士背负了150亿美元的债务,虽有政府注资但也陷入全球反倾销诉讼。在缺乏预算采购新型光刻设备的情况下,海力士团队在研发主管朴星昱(Park Sung-wook)带领下展现了极强的韧性,在66纳米向54纳米演进的节点,通过光罩优化和晶圆边缘良率提升技术在老旧机台上维持了堆叠式技术的产能跟随,其当年资本支出不到竞争对手的一半。2012年初,SK集团董事长崔泰源决策斥资约30亿美元收购海力士近21%的股权,这笔资金注入化解了海力士长达十年的债务危机。
日本存储企业尔必达在DRAM制程跨越期因资金短缺而破产,最终被美光收购。尔必达问题来自于过于追求极致良率~98%、但生产效率只有三星1/3,导致成本高昂、连年亏损。在公司社长坂本幸雄面临向30纳米世代跨越的节点,因缺乏资本开支更新光刻设备,导致单颗芯片制造成本劣势进一步拉大。2012年2月,尔必达背负55亿美元债务宣告破产。随后,美光科技首席执行官马克·德坎(Mark Durcan)主导以25亿美元的对价收购了尔必达。这笔并购使美光接管了尔必达的30纳米级晶圆厂产能及其在苹果供应链中的份额,美光的全球市占率借此提升至24%以上。自此,全球DRAM市场在经历一轮资产重组与产能出清后,确立了三星、SK海力士与美光三家企业主导的市场格局。
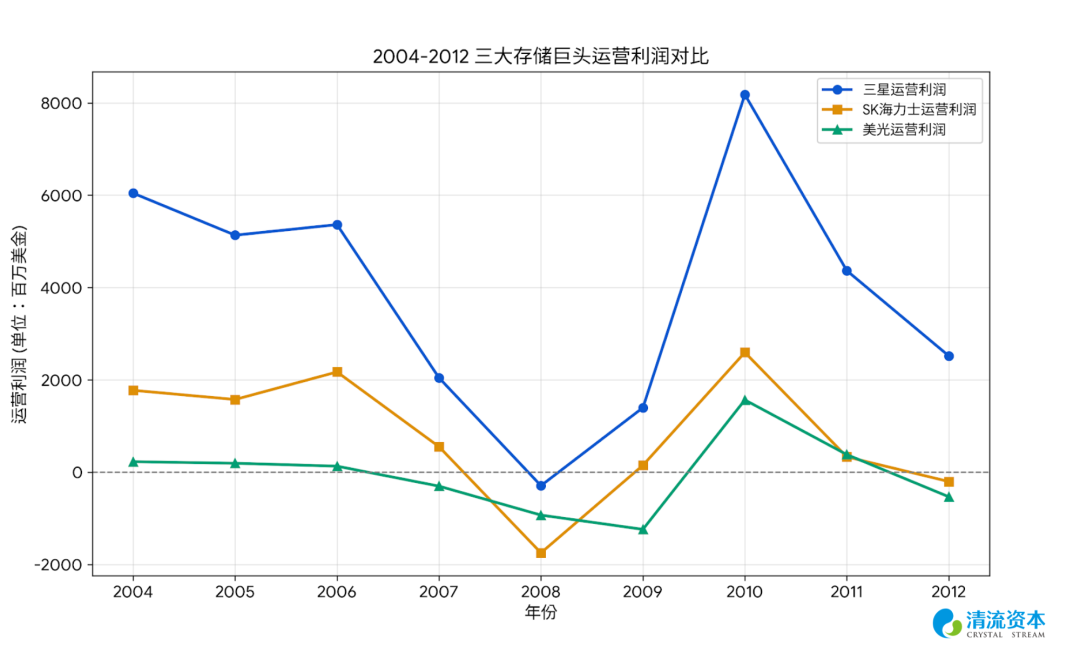
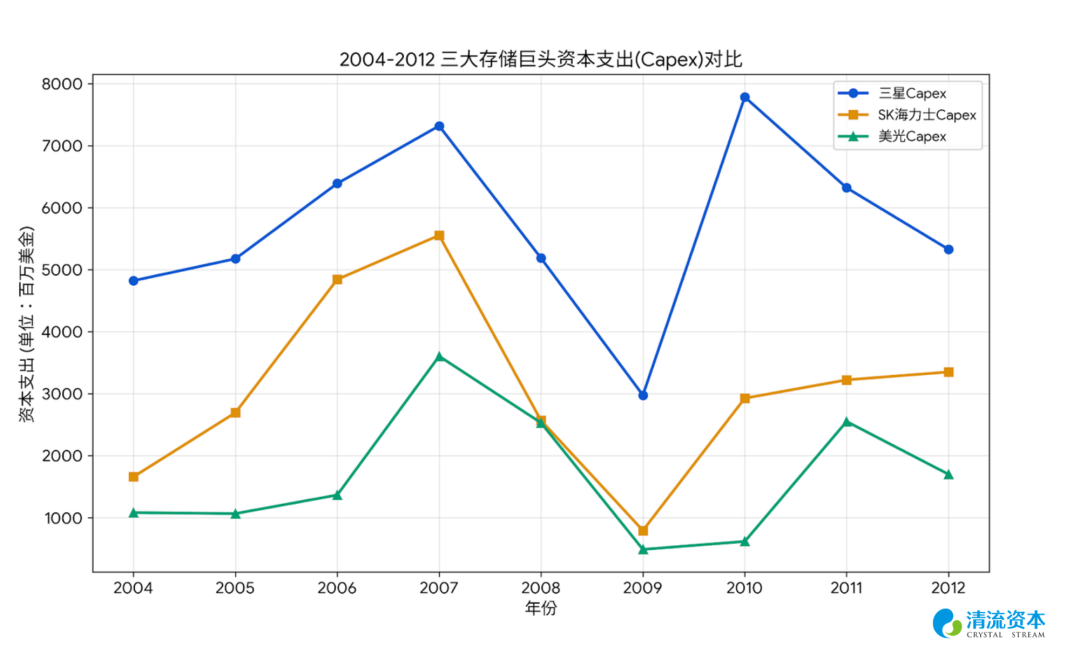
随着2010年苹果iPhone 4的横空出世与安卓智能手机阵营的全面爆发,全球科技产业的权力中心正式从桌面端向移动端发生历史性迁徙。移动终端极其严苛的电池容量和内部物理空间,迫使DRAM的战略竞争核心从单一的容量性能,转向了极致的低功耗与极高的封装密度,即LPDDR(低功耗双倍数据率内存)。为了节省空间LPDDR必须采用复杂的叠层封装技术,将打磨得极薄的内存裸片直接立体堆叠在苹果A系列或高通骁龙等系统级芯片的正上方。这种物理层面的强行绑定,要求存储寡头必须提前一到两年与无晶圆厂的芯片设计巨头进行深度的功耗协同设计,存储厂商们开始拥有了与下游终端硬件厂商进行长期议价的战略筹码,出现了客户通过预付款获取半年到1年产能的锁量(但不锁价)的较长期协议。
在这个向移动端全面迁徙的抢跑期,三星电子凭借恐怖的资金弹药和自家Galaxy智能手机庞大的内部消化系统,率先攻克了20纳米及18纳米LPDDR4的量产难关,挥舞着先进产能横扫了各大手机终端供应链。面对三星的绝对压制,2013年接任SK海力士首席执行官的朴星昱(Park Sung-wook)果断切断了部分传统PC内存的低效扩产计划,专注在移动端技术的攻坚。海力士的研发团队极其高效地驻扎在深圳和硅谷,与高通、联发科以及中国各大终端大厂进行深度的底层工程对接,最终在2015年前后迎来了21纳米LPDDR4良率的大规模突破。海力士借此以超过25%的移动端市占率,在智能手机供应链中抢下了生存空间,打破了三星一家独大的技术垄断。
而在2012年完成惊天大并购的美光科技,则走出了一条依靠整合优质资产进行移动端套利的独特路线。强悍的首席执行官马克·德坎(Mark Durcan)决策当年以25亿美元的极低代价吞并日本尔必达,看中尔必达在苹果供应链中极其深厚的移动端DRAM护城河。德坎迅速将尔必达位于日本广岛的研发中心直接升格为美光全球移动端存储的核心部门,充分榨取日本工程师团队在低功耗封装上的残余技术红利,极其平稳地消化了苹果和安卓阵营爆发初期的海量订单。这不仅让美光在极短时间内将自身的移动端DRAM市占率稳固在20%以上,更让其彻底坐稳了全球第三大寡头的牌桌。
伴随着全球智能手机渗透率从2010年的不足20%狂飙至2018年超过70%的宏大红利期,这套基于LPDDR的高粘性商业模型迎来了最疯狂的财务变现。随着各大手机厂商将终端的运行内存从2GB一路狂飙至8GB,叠加云服务器数据中心对于Server DRAM的需求共振,庞大的Bit需求增量与三大寡头受限于制程瓶颈而无法迅速释放的产能产生了历史性的供需错配,在2018年的存储周期顶点时三大寡头的营业利润率频频突破40%乃至50%。
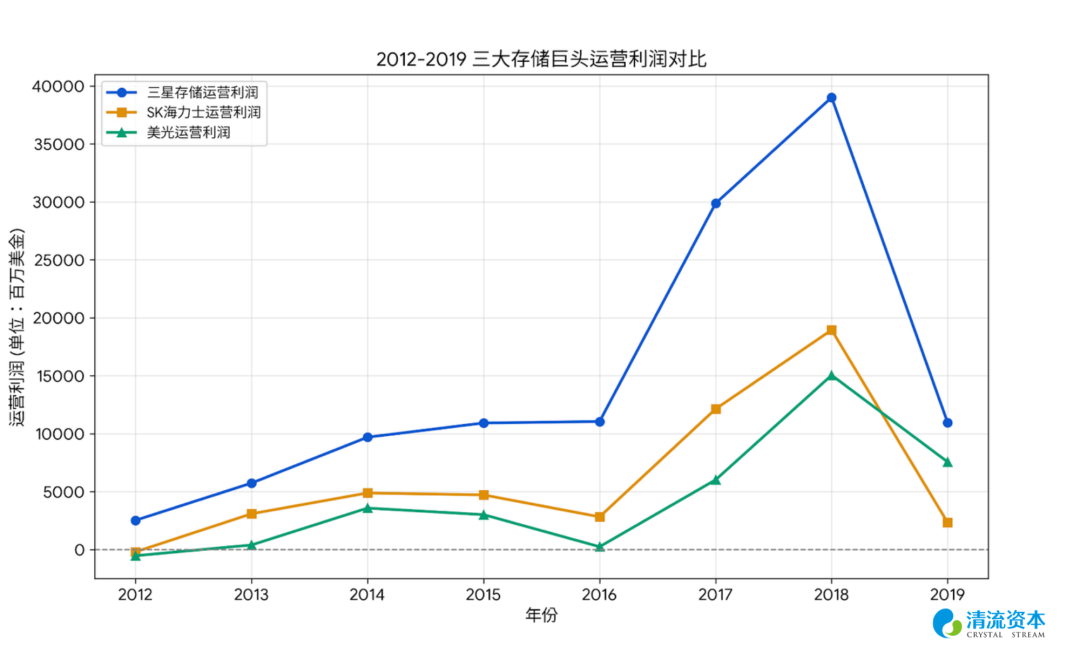
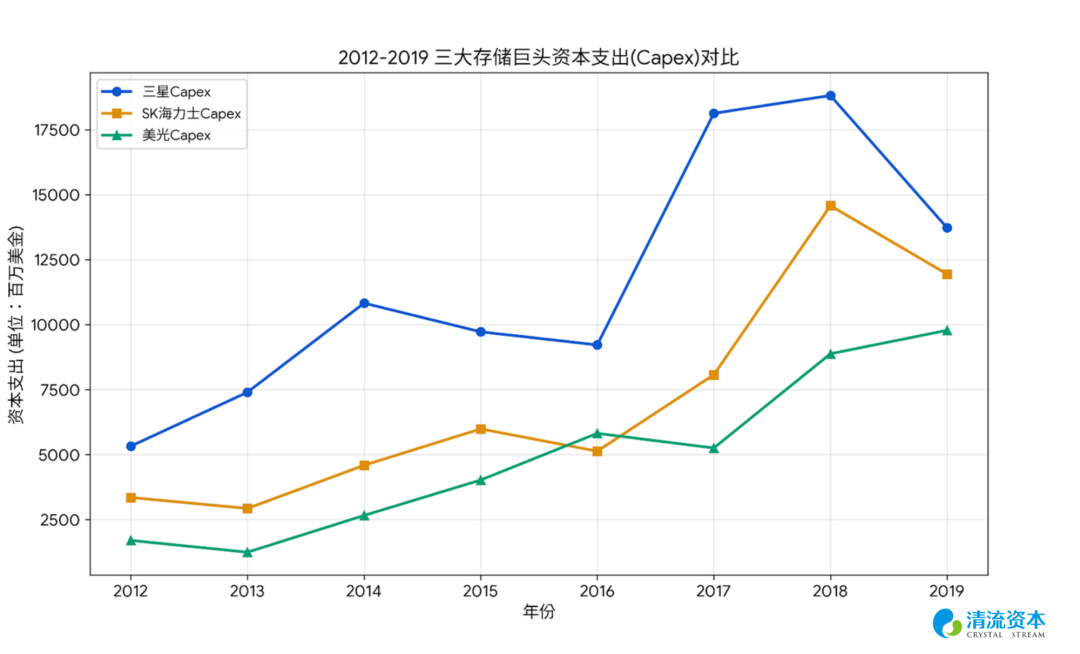
表:智能手机 云业务浪潮下OP和capex双涨,存储行业仍有较强周期性
在这个周期中,华尔街认为4G智能手机时代由于采取了SOC叠层封装工艺,一旦进入了苹果等手机厂供应链,替换成本极高,LPDDR 从此具备定制化和客户粘性特性,摆脱了PC DRAM内存条随时可插拔替换的commodity属性,并且正处于高端旗舰机时代,市场认为手机厂商为了追求极致的轻薄、省电和流畅度,不在乎几美元的内存差价,只在乎性能和供货稳定性。
当时间推移至2018年后,全球智能手机年出货量在触及14亿部的天花板后陷入永久性停滞,消费者对于内存升级的边际体验提升变得极其麻木。随着LPDDR4和LPDDR5技术在三大寡头之间彻底走向成熟和标准化,定制化LPDDR变回了无底线倾销的大宗商品,短短几个季度内,移动端DRAM价格雪崩超过50%,迫使幸存者们不得不将绝望的目光投向下一个能够榨取极高溢价的物理瓶颈。
“这次不一样”仍然是投资界最昂贵的几个字,存储厂商股价均大概提前于业绩峰值的4-6个月触顶,随后到年底腰斩。美光2018年5月底的市值顶点大概是2018年当年的2x PB 5.5x PE,随后业绩于2018年Q3见顶;海力士2018年5月底市值峰值则是当年的1.6x PB 4.7x PE。
历史总会押韵,在下个周期即2021年底内存行业在疫情带来的在线经济爆发、数据中心扩张、EUV下的DDR5疯狂短缺以及“元宇宙”概念炒作中,内存公司再次在扩产中触及周期顶部、随后半年回撤40%,这轮的顶部定格在了——美光21年底峰值市值是当年的2.5x PB 15x PE,海力士则是1.5x PB 10x PE——纯周期行业的PB估值仍然低廉,相比静态估值,判断行业拐点更重要。
阶段三:跨越存储墙与HBM算力税的价值重估 (2022-2026)
在2013年前后,传统二维DRAM的微缩工艺逼近物理极限,处理器与内存之间的数据传输带宽瓶颈凸显,为打破存储墙,业界提出了基于硅通孔(TSV)的三维堆叠架构,即HBM技术。该技术要求在裸片上穿透数千个微米级孔洞并实现垂直互连,初期良品率偏低,制造成本远超传统内存。当时占据市占率优势的三星电子经内部财务测算,认定该技术缺乏短期回报率,于2019年前后削减相关预算并调整了内部研发团队。SK海力士则对未来技术足够积极,在2013年选择与苏姿丰刚回归的AMD合作推进HBM的量产,并招揽了曾在三星电子长期负责封装研发但被边缘化、后赴日本专攻硅通孔技术的专家李康旭。在这位三星旧将的主导下,海力士引入了批量回流模塑底部填充(MR-MUF)工艺。这种工艺利用特殊的环氧树脂材料进行一次性注入与固化,解决了堆叠层数增加后的散热与硅片翘曲问题,确立了良率基础。
随着2022年底生成式AI爆发,英伟达在计算架构迭代中持续放大HBM物理容量,价值量指数级提升。英伟达H100 GPU于2022年搭载80GB内存HBM3,而到2027年Rubin Ultra版本通过四计算芯片堆叠实现的1TB HBM4E配置,实现12倍的增长;HBM在H100时代的成本占比约为41%,到B200时代升至45%,而在Rubin Ultra中预计将突破55%。这意味着存储正式超越逻辑计算芯片,成为AI硬件成本的第一权重项。
面对HBM4更复杂的逻辑接口要求及对ASML极紫外光刻机等尖端设备的依赖,SK海力士做出了放弃完全垂直整合制造(IDM)闭环的战略决策。公司选择将HBM底层逻辑裸片(Base Die)的制造环节让渡给制程更强大的台积电,并与台积电的CoWoS先进封装工艺深度绑定。这种“海力士存储 台积电代工 英伟达设计”的铁三角生态,使其得以绕开单一公司的制程限制,确立了极强的定制化竞争壁垒。
错失先机的三星电子被迫进入了极为惨烈的应急追赶模式。2023年上半年,三星在内部紧急成立了直接向半导体部门负责人汇报的“HBM特别工作组(Task Force)”,试图利用其同时拥有存储制造与先进晶圆代工(Foundry)的垂直整合能力发起反击。在技术路径上,三星并未直接跟随海力士的MR-MUF工艺,而是选择在传统的TC-NCF(热压非导电胶膜)工艺上进行极限压榨。为了扭转被动局面,三星在2024年投入天量研发资源强攻12层堆叠的HBM3E,试图凭借单芯片更高的密度(36GB)来重新绑定英伟达等核心客户。
与此同时,一直处于第三位的美光科技则采取了更为激进的“跨代飞跃”策略。首席执行官桑杰·梅赫罗特拉(Sanjay Mehrotra)果断下令跳过已经失去先发优势的HBM3,将全部工程兵力直接压注在HBM3E的开发中。美光充分利用其在1-beta(1β)制程节点上积累的功耗控制优势,在2024年初率先让其24GB的8层堆叠HBM3E产品通过了英伟达H200的严苛认证。至此,由海力士独占80%以上份额的初始垄断格局开始动摇,市场正式进入了海力士占50%、三星占30%、美光占20%的“532”竞争格局,三大寡头开启了围绕良率与产能规模的重资产厮杀。
这种对算力的极致追求引发了存储行业历史上最严重的产能挤压与价格倒挂。由于HBM的制造工艺极其复杂,生产相同Bit的HBM所消耗的晶圆数量是传统DRAM的三倍左右,且其芯片面积显著大于普通内存,这导致全球DRAM的有效供给增速在2025年至2026年间陷入停滞。2026年第一季度,随着英伟达Rubin架构进入量产深水区,三巨头为了保住利润率近60%的HBM4订单,将超过45%的DRAM晶圆产能转产HBM,这导致标准DDR5颗粒出现了历史上最严重的结构性短缺,预计短缺将持续到2027年底。
最终,这种短缺会体现在有史以来最大的运营利润与Capex的剪刀差,公司净资产将会指数提升,对于以PB估值的周期性企业来说尤为值得注意。
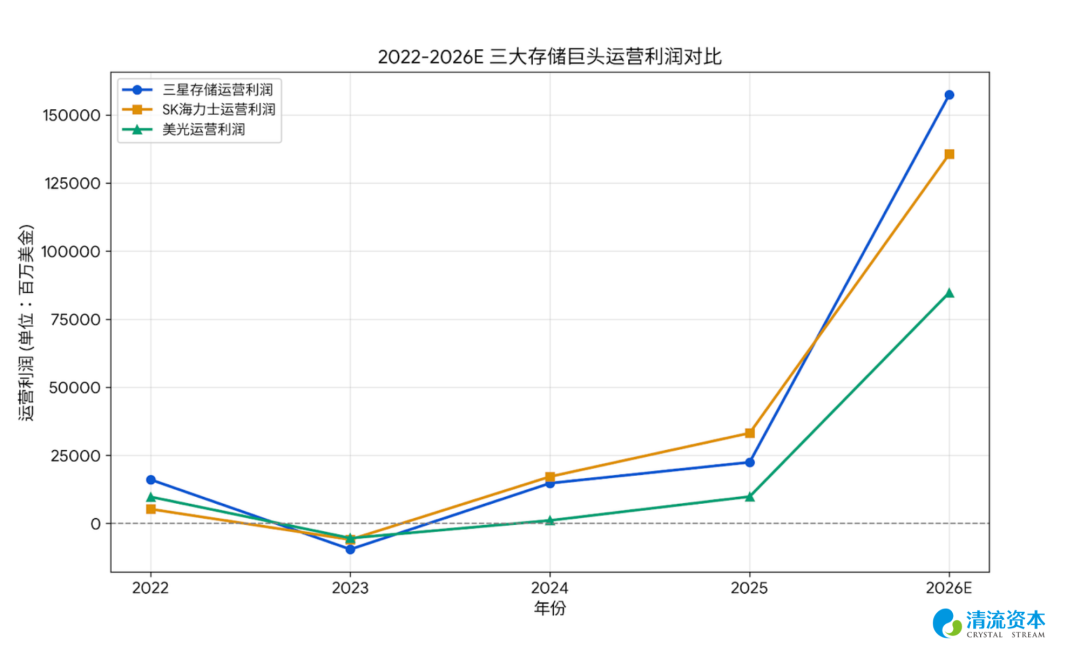
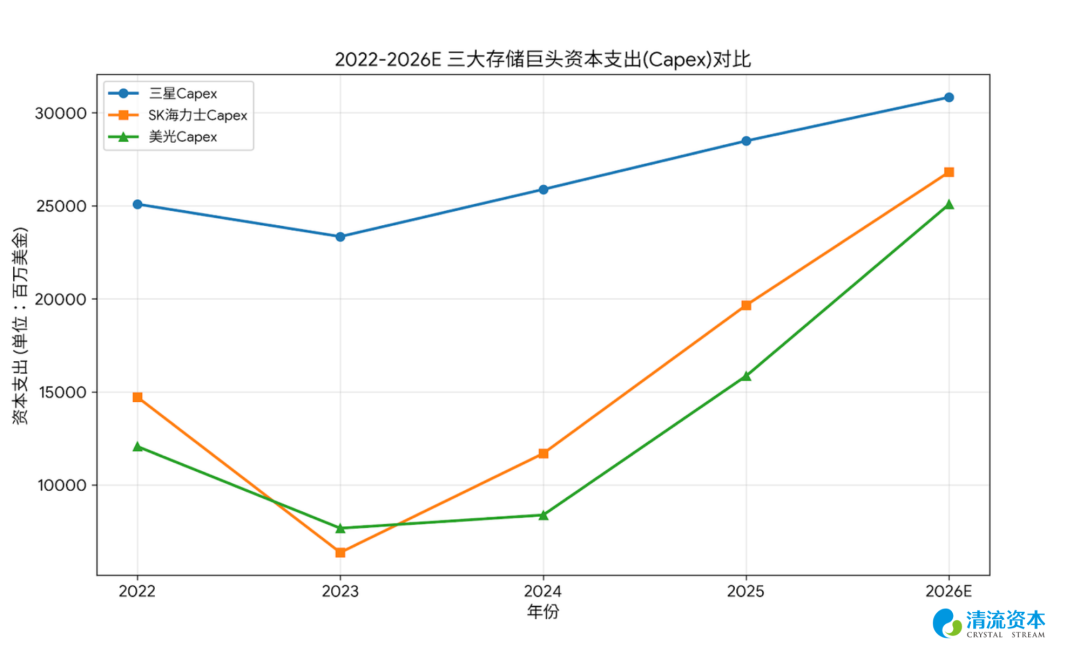
表:存储巨头扩产纪律性加强,OP和Capex的GAP极速放大、带动未来净资产增长,打开PB估值空间
阶段四:确立锁量锁价LTA长约,商业模式结构性重估 (2023-2027)
在确立了HBM的技术门槛与产能稀缺性后,存储寡头们实质性地终结了主导DRAM产业长达四十余年的现货市场(Spot Market)交易法则。过去几十年,商业模型高度依赖价格随行就市的短期合约,导致巨头们的资产负债表在产能错配中剧烈震荡。然而,随着制程演进至1-beta及1-gamma节点,单条HBM产线的资本开支动辄以数十亿美元计,且极紫外光刻机(EUV)与CoWoS先进封装设备的搬入周期长达18至24个月。如果继续沿用大宗商品逻辑盲目扩产,巨额的重资产沉没成本将直接引发财务危机。面对这一极端的资产敞口,三大巨头极其强硬地向超算云服务商(CSP)全面推行了长期协议(LTA,Long-Term Agreement)与不可退还的预付款(Non-refundable Pre-payments)制度。
在2026年初最新一季的财报电话会议中,这种“锁量且锁价”战略被存储巨头的高管完成了闭环确认。美光科技首席执行官桑杰·梅赫罗特拉(Sanjay Mehrotra)在2026年3月的财报会议上直接向华尔街展示了订单的极致刚性:“我们2026日历年的HBM3E及初代HBM4产能不仅早已全部售罄,并且2027年的绝大部分供应量和定价结构,也已经通过不可撤销的长期协议被全面锁定(Our calendar 2026 capacity is fully sold out, and the overwhelming majority of our 2027 volume and pricing structures are already locked through irrevocable LTAs)。”这种跨度长达两年以上的物理“锁量”,彻底消除了新产能投放初期的库存积压风险。
SK海力士在LTA的财务变现上则表现得更为强悍。随着2026年HBM4世代将存储底片(Base Die)与下游GPU逻辑架构深度融合,极高的客户转换成本赋予了海力士空前的定价权。首席执行官郭鲁正(Kwak Noh-jung)在2026年第一季度的业绩说明会上披露了现金流结构:“针对2026与2027年定制化HBM4产线收取的客户预付款,已经实质性覆盖了我们今年在先进封装领域的绝大部分资本开支(Pre-payments for our custom HBM4 pipelines have substantially covered our advanced packaging CapEx for this year)。”这意味着下游算力巨头不仅在购买物理芯片,更是在真金白银地分担晶圆厂极其昂贵的折旧风险。海力士高管团队更是用清晰的财务模型定调了这一转变:得益于LTA的保驾护航,以HBM和服务器DDR5为主的AI内存占公司DRAM总销售额的比例,已从2023年的不足10%,在2026年历史性地突破了50%。
而曾因误判而短暂掉队的三星电子,在2026年初的业绩沟通中,展现了利用其独有的“存储 逻辑代工”IDM优势重夺话语权的防守反击策略。三星明确披露,其正在与核心云厂商执行跨度长达三年的“交钥匙(Turnkey)长协”。这种协议不仅将16层堆叠的HBM4物理出货量与三星自家的2纳米逻辑代工产能强行绑定,更在合同中预设了严格的价格走廊(Pricing corridor),这种基于全栈硬件生态的锁价机制,实质上充当了极其厚实的财务缓冲垫。
这种由天量预付款 锁量锁价驱动的财务模型,使三大寡头自上世纪八十年代以来首次摆脱了对赌宏观经济周期的宿命,获得了极其健康且可高度预测的正向自由现金流,订单可见度(Visibility)被拉长至24个月以上。
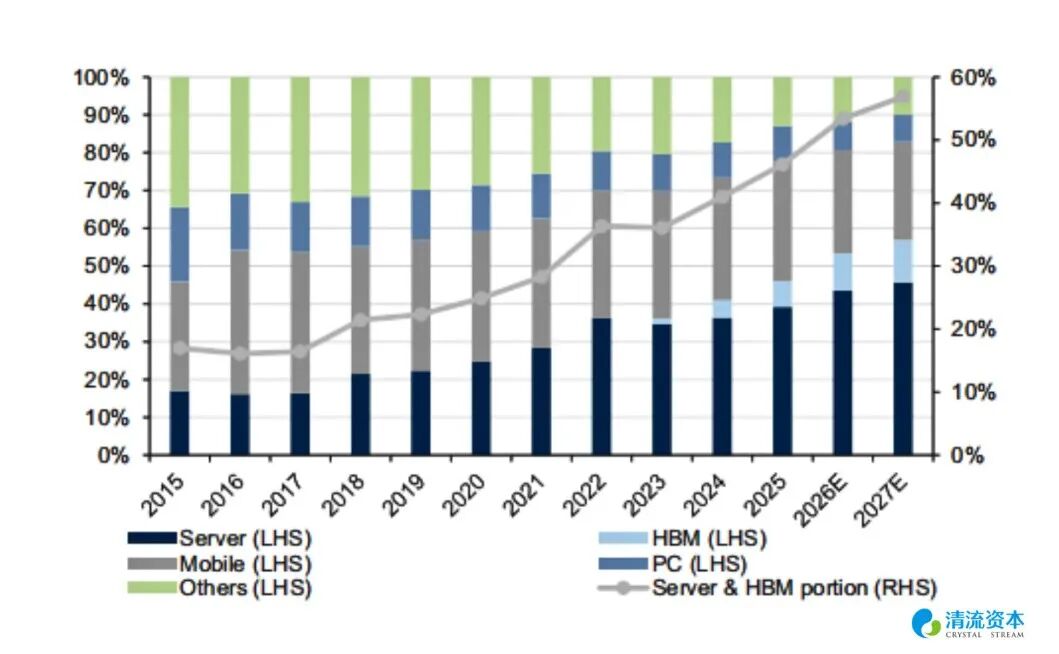
表:AI内存需求占比突破50%
阶段五:绕开HBM封锁,海外创企与中国厂商的内存架构创新突围(2026-?)
随着生成式AI全面转向大规模应用侧,内存的数据吞吐延迟正式成为禁锢推理芯片性能提升的绝对物理瓶颈,传统存算分离架构的冯·诺依曼架构面临升级。2025年底英伟达斥资200亿美元完成对初创公司Groq的收购,并在GTC大会上宣布将Groq的底层架构全面整合进其AI数据中心版图,建议Coding和Agent需求将25%容量分配给Groq机柜。Groq的语言处理单元(LPU)直接废除了传统的外部存储调用逻辑,通过在芯片内部暴力铺设海量500MB的SRAM(静态随机存储器)实现H100的20倍以上带宽的极速存内计算,但这不意味着取代DRAM,Groq每个256GB机架仍然需要配备12TB的DDR5。这与硅谷另一家AI硬件创企Cerebras的晶圆级引擎(WSE)异曲同工,Cerebras则是用巨型芯片集成了 44 GB 的超高速SRAM,两者均依赖庞大的SRAM阵列来碾压系统延迟红线,Cerebras估值也达到230亿美金。然而在逻辑节点步入3纳米及以下后,SRAM的面积微缩比例已触及物理与经济双重极限,并且容量较小仍然是瓶颈。台积电(TSMC)顺势加速了底层存储介质的革命,全面推动以SOT-MRAM(自旋轨道转矩磁随机存储器)和ReRAM(阻变存储器)为代表的新型非易失性技术商业化,意图通过更终极的存内计算带宽优势击穿内存墙。另一方面,初创公司Taalas等则开辟了更为暴烈的路线,Taalas直接采用极高密度的Mask ROM(掩膜只读存储器)技术,针对大模型推理阶段权重固定的“只读不写”特性,将庞大的神经网络权重彻底“硬编码”进硅片物理层中抹除动态内存的调用延迟。

在底层存储架构升维的全球背景下,中国本土半导体产业在国家战略资本的密集灌注下,于2016年正式开启了破局寡头垄断的重资产构建期。在DRAM主战场,合肥长鑫(CXMT)在地方国资与兆易创新的联合主导下挂牌成立,其底层技术基底建立在对已破产德国巨头奇梦达(Qimonda)资产的合法继承之上。通过系统性吸收约一千余万份技术文件及核心专利,长鑫在创立初期成功避开了三星与美光构筑的知识产权绞杀网,并在后续量产中将架构平稳切换至行业主流体系。而在NAND领域,同年在紫光集团与国家大基金重装加持下成立的长江存储(YMTC),则以武汉新芯(XMC)原有的晶圆代工产线为底层基建,深度融合了中科院微电子所(IMECAS)的基础结构专利与跨国资深工程班底。经历过数轮残酷的地缘设备禁运与实体清单压力测试后,这两大国产存储双核在2025至2026年的产业周期中迎来了产能与份额的历史性兑现,长鑫与长存在通用型存储市场的全球市占率双双强势突破高单位数(High single-digit)的战略临界点,但长鑫80%以上收入来自LPDDR4,普通DDR5产品良率仍在培育,而HBM3仍在攻克中、三强已从HBM3e步入HBM4、差距落后2代。
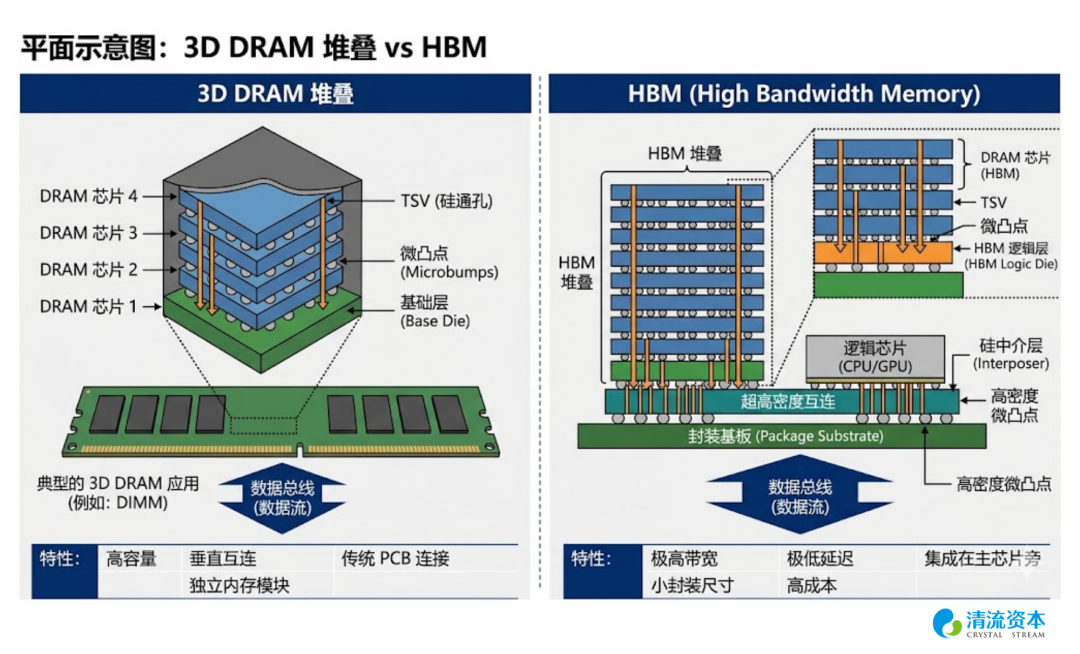
这背后也是中国本土半导体产业链面临极紫外光刻机(EUV)与台积电CoWoS先进封装产能限制的全面封锁,而本土厂商有了一个新思路:绕开HBM技术栈,依靠直接在逻辑芯片上三维DRAM堆叠(3D Stacking)技术实现比2.5D平行封装的HBM更具备优势的垂直带宽,在推理侧芯片赛道实现弯道超车。这项底层工艺的源起,深度植根于武汉新芯(XMC)早年为CMOS图像传感器代工所沉淀的晶圆级混合键合(Hybrid Bonding)技术,并由此孵化出长江存储(YMTC)的三维架构底座。目前,武汉新芯牢牢掌握了晶圆对晶圆(W2W)无凸块垂直互联的核心物理专利。在无需依赖EUV的前提下,本土厂商利用成熟的17纳米至19纳米节点DRAM颗粒,通过微米级精度的混合键合完成立体空间重构。在早期的工程暗线中,武汉新芯的3D DRAM方案已在对带宽极度敏感的加密货币矿卡上完成了“1 2”架构(单片逻辑控制Die垂直堆叠两片DRAM Die)的实片搭载验证,积累了海量的良率爬坡数据;近期,武汉新芯和合肥长鑫针对AI推理芯片定制的“1 4”复杂堆叠架构已与多家fabless芯片创业公司在推进流片过程(Tape-out),当前该路径的工程难点已从早期的键合对准精度,全面转移至多层逻辑与存储混合堆叠后的极限散热管理(Thermal Dissipation)与热应力控制。
而在NAND闪存主战场,长存凭借Xtacking的3D堆叠架构构筑的绝对物理壁垒,不仅在针对美光的全球核心专利侵权诉讼中取得历史性胜诉,更顺势向全球存储霸主三星电子及正跨越300层大关的SK海力士正式授权了其底层的混合键合关键技术,以直接支撑三星430层V10闪存的量产计划。
随着生成式AI的商业闭环从高成本的云端训练向海量部署的应用端发生不可逆的转移,底层存储架构彻底褪去了逻辑芯片廉价附属配件的历史标签,升维为决定未来全球算力硬件出货主力的推理芯片中最具爆发力的创新发源地。
总结:
1. 内存行业由于重资产属性,在历史上具有极强的周期性,无论是PC互联网、智能手机和移动时代、云服务时代等最终都沦为commodity,警惕“这次不一样”。
2. 下一代技术路径选择与坚决投入是关键,精准创新 十倍投入才能在这个行业带来阶段性超额利润。
3. 头部玩家的扩产纪律性和聚焦高价值产品的战略决策,叠加LTA长协锁价锁量的商业模式变化,对于头部公司会加强竞争优势、延长沦为commodity的时间。
4. 这种供需失衡的短缺会体现在有史以来最大的运营利润与Capex的剪刀差,公司净资产将会指数提升,对于以PB估值的周期性企业来说尤为值得注意;从历史上来看,业绩峰值的3x PB可能是股价顶、并先于业绩峰值4-6个月出现,但行业拐点本身何时到来的判断更为重要。
5. 存储技术逐步替代逻辑芯片成为AI芯片的瓶颈,产业链价值得到提升。一方面,内存占GPU价值量提升到55%;另一方面,为了实现更快的推理速度和更低的推理成本,SRAM存内计算和3D堆叠DRAM等新一代内存技术正在逐步定义AI芯片,创新价值增强会延长这轮周期时间,中国玩家可能也有机会参与其中凭借3D堆叠能力弯道超车、推进行业技术持续迭代

 VIP复盘网
VIP复盘网
