

![]()
新智元报道
新智元报道
【新智元导读】百川发布并开源全球最强医疗模型 Baichuan-M3,各项指标均已 SOTA!同时 M3 也超越了人类医生的平均水平。它最大的进步是告别了机械的「背医书」,学会了像真人医生一样主动追问、排查病因,主打「严肃问诊」,不仅能把模糊的病情问清楚,更解决了 AI「胡说八道」的顽疾,准确度超越 GPT-5.2-High。这是 AI 从「聊天机器人」向「专业医生」进化的关键一步。AI医疗,奇点已至。
在很长一段时间里,人们习惯了这样一种人机交互:你在搜索框或聊天窗口输入「头痛怎么办?」,屏幕对面会瞬间抛回几千字关于脑瘤、高血压或颈椎病的百科知识,最后附上一句正确的废话——「建议您及时就医」。
这不仅是搜索引擎时代的顽疾,也是目前大模型的通病。
它们像是一个博闻强记但缺乏临床经验的医学生,背下了所有医书,却不懂得如何面对一个活生生的人。
就在今天,这个僵局要被打破了。
百川智能发布并开源了新一代医疗增强大语言模型 Baichuan-M3。
在百川创始人王小川看来,这绝非仅仅是模型参数的升级,更是一次对「AI 医疗」的重新定义。
M3 不再满足于做一个被动的答题者,它试图掌握一种人类医生最核心的职业本能——严肃问诊。
数据显示,Baichuan-M3 在全球权威医疗 AI 评测 HealthBench 及其高难度子集 HealthBench Hard 上双双夺冠!
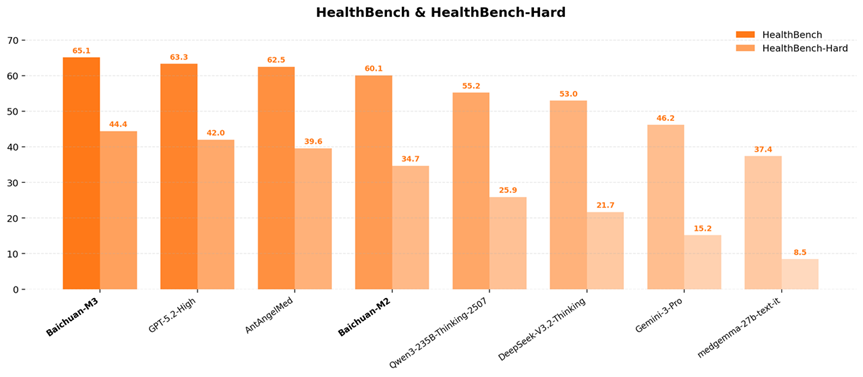
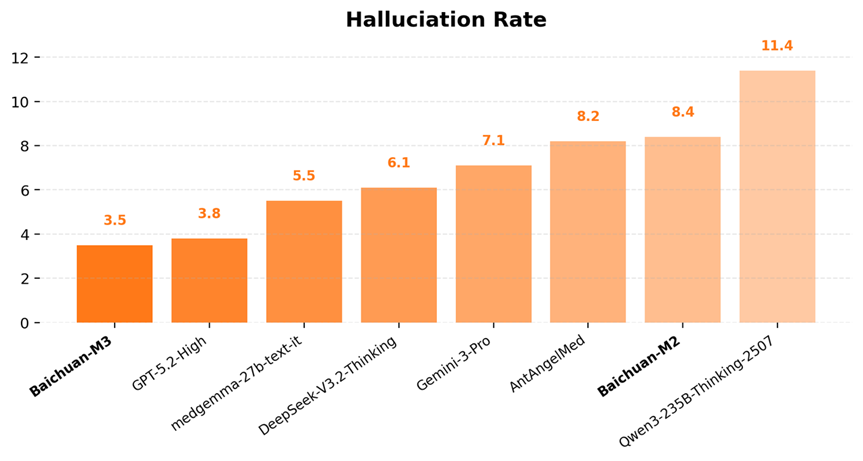
甚至在 OpenAI 最引以为傲的低幻觉领域,Baichuan-M3 也以 3.5% 的幻觉率击败了 GPT-5.2,实现全面 SOTA!
真正的变化体现在「百小应」App 里:当患者描述模糊的症状时,AI 不再急于给出结论,而是像一位经验丰富的老大夫一样,开始了一场抽丝剥茧的「侦探游戏」。
百小应网页端:https://ying.baichuan-ai.com/chat

医疗的本质,是信息不对称的博弈。
患者往往无法准确描述自己的痛苦,「肚子疼」在医学上可能对应着从胃痉挛到急性胰腺炎等数十种可能。
之前,大多数医疗大模型的训练逻辑是「完形填空」——尽力补全用户话语中的缺失。
OpenAI 发布的 HealthBench 评测集,本质上考查的也是这种「单轮静态问答」能力。
然而,百川的技术团队发现,这种逻辑在真实临床中是危险的。
医生看病,第一件事永远是排除危急重症。
但在传统的提示词工程下,AI 往往因为急于表现「博学」,而忽略了对「红旗征」(指危险信号)的排查。
Baichuan-M3 的核心突破,在于它首次具备了原生的「端到端」严肃问诊能力。
这种能力源于百川独创的 SCAN 全新问诊原则。
在百小应的实际体验中,如果用户说「头晕」,M3 不会立刻列举头晕的原因,而是会启动一套缜密的追问逻辑:
安全分层(Safety Stratification):「是一阵一阵的晕,还是天旋地转?有没有伴随恶心呕吐?」(排查中风或耳石症风险)
信息澄清(Clarity Matters):「最近有没有熬夜或测量过血压?」(量化诱因)
关联追问(Association & Inquiry):基于初步回答,像侦探一样锁定嫌疑病因。
在以往,长轮次的对话训练容易让模型「迷路」,导致逻辑破碎。
百川新的SPAR 算法通过分步惩罚机制,让 AI 学会了在有限的对话轮次中,精准地问出最关键的信息。
在百小应上,这意味着 AI 能将患者口中「有点痛」、「不舒服」等主观体感,转化为医生看得懂的、结构化的临床数据。
如果说「不会问诊」只是让 AI 显得笨拙,那么「幻觉」则意味着安全风险。
在严肃医疗场景下,大模型一本正经地胡说八道(即 AI 幻觉)是不可接受的。
2025 年,尽管 DeepSeek 等国产模型让 AI 普及到了千家万户,但大多数通用模型公司并未将「降幻觉」提升到与写代码、做数学题同等的高度。
百川选择了一条更难的路:将医疗幻觉抑制前移。
不同于行业通用的「外挂知识库」(RAG)模式,Baichuan-M3 试图从「基因」里剔除幻觉。
技术团队构建了一套事实感知强化学习(Fact-Aware RL)架构。
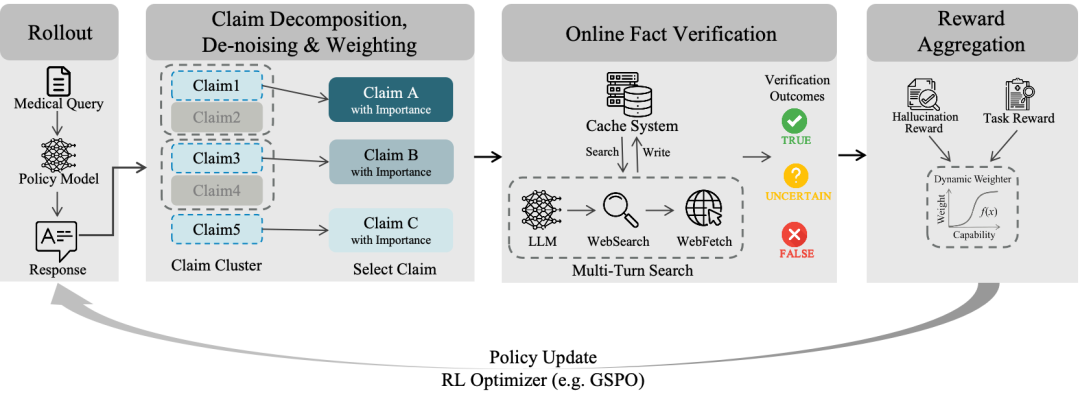
简单来说,就是在模型训练的每一次奖惩中,都加入对医学事实的严苛校验。
这相当于在 AI 的大脑里植入了一个实时的「审稿人」。
当模型试图为了让答案看起来通顺而编造一个药物剂量时,惩罚机制会立刻介入。
这种「内化」的训练方法效果显著。
在不依赖任何外部搜索工具的情况下,M3 的医疗幻觉率降至 3.5%!
这一数据不仅优于 GPT-5.2,更是刷新了全球的最好成绩。
对于百小应的用户来说,这意味着 AI 给出的每一条建议,是基于严谨医学逻辑的「负责任表达」。
在遇到自身知识边界外的复杂病例时,M3 更倾向于引导就医,而不是盲目自信地开方。
如何评价一个医生的水平?看他背了多少书,还是看他治好了多少人?
过去,以 HealthBench 为代表的评测集,更像是医学院的笔试题。
它考核的是 AI「会不会回答问题」。
但在百川看来,这远远不够。
临床如战场,医生面对的是动态的、混乱的、信息不全的真实世界。
医疗模型必须要能够带着诊疗目标,完整的收集患者信息。
为了给 M3 一场真正的「临床大考」,百川联合 150 多位一线医生,借鉴医学教育中经典的 OSCE(客观结构化临床考试)方法,搭建了 SCAN-bench 评测体系。
这是一个包含病史采集、辅助检查、精准诊断全流程的动态考场。
AI 不仅要答对最后的病名,还要被考核「问诊思路是否清晰」、「检查开得是否合理」、「有没有漏掉高危风险」。
在实验过程中百川发现,问诊准确度每增加 2%,最终诊疗结果的准确度就会提升 1%。评测结果显示,M3 在SCAN的四个维度均显著高于人类医生基线水平,并大幅领先于国内外顶尖模型。
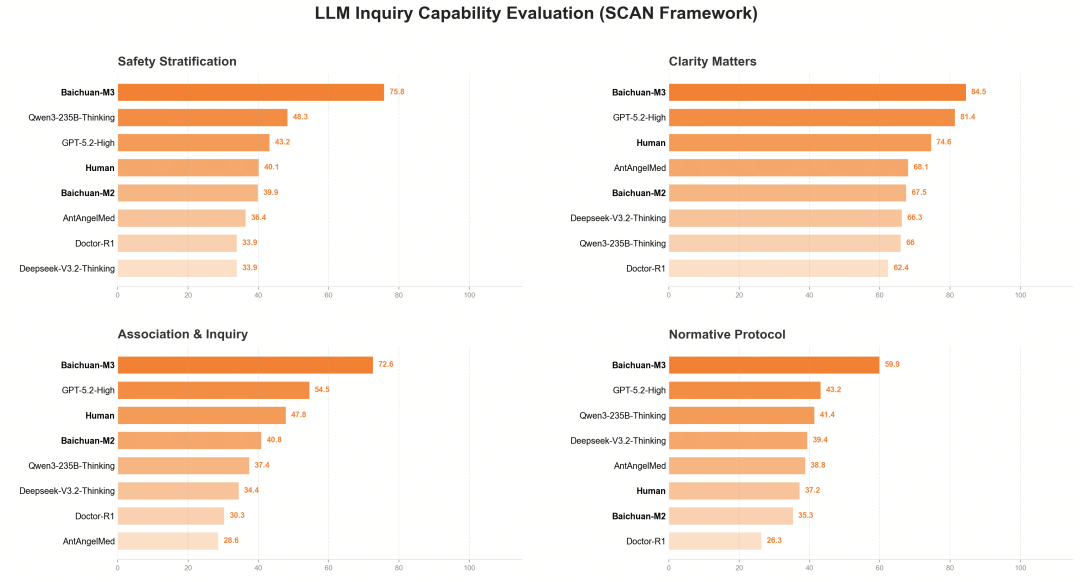
分数超越人类医生平均值并非意味着 AI 已经全面超越了名医,但在标准化的问诊流程、知识的广度以及对指南的绝对遵循上,AI 展现出了人类难以比拟的稳定性。
技术的高低,最终要落回到具体的应用场景中。
随着 M3 的发布,百川智能旗下的医疗应用「百小应」正在经历一场静悄悄的质变。
在过去,患者去医院就像是一场「盲盒游戏」。
排队三小时,看病三分钟,面对医生时语无伦次,把关键病史忘得一干二净。
而接入 M3 后的百小应,正在试图成为医患之间的「翻译官」。
在患者端,它是一个 24 小时在线的「全科医生助理」。
当你感到不适,它通过多轮专业的追问,帮你理清病情,生成一份专业的病情摘要。
在医生端,这可能意味着工作流的重塑。
当患者坐到诊室时,医生看到的将会是一份已经排除了基础风险、罗列了关键症状的结构化报告。
医生可以跳过机械的信息收集环节,直接进入高价值的诊断与治疗决策。
这就是百川强调的「强推理、低幻觉的医疗服务能力」的真实落地。
它不试图取代医生,而是试图通过提升问诊能力、准确性,来帮助医生决策。
2026 年初,全球 AI 医疗的竞争已进入深水区。
从 OpenAI 的 ChatGPT Health 到 Anthropic 的 Claude for Healthcare,巨头们都在争夺这块最难啃的骨头。
在这场竞速中,Baichuan-M3 的出现具有特殊的标本意义。
它标志着中国 AI 医疗从「跟随者」转身为「定义者」。
百川证明了,通过对医疗决策过程的深度建模,大模型可以走出「聊天机器人」的舒适区,进入严肃、严谨且充满敬畏的临床世界。
技术是冰冷的,但医疗永远关乎人性的温度。
AI 无法替代医生握住患者颤抖的手,但它可以让医生在握手之前,看得更清楚、判得更准确。
针对人口老龄化,AI 是最靠谱的解决优质医疗资源短缺的几乎唯一的方案。
百川作为国内最早一批开始探索 AI 医疗的公司,在迷雾中努力探索出一条可落地的 AI 赋能医疗的道路。

 VIP复盘网
VIP复盘网
