

在人工智能技术飞速发展的当下,大模型训练与推理对算力的需求呈爆发式增长,超节点(SuperPod)应运而生并迅速崛起。作为新型算力基础设施的关键组成部分,超节点凭借卓越的性能和高效的互联架构,成为推动算力升级的核心力量,代表着算力技术的前沿方向,更是未来智能社会发展的重要支撑。超节点的概念由英伟达率先提出,其核心在于通过高效的互联协议和架构设计,实现大规模GPU集群的紧密耦合与协同工作。这种架构在模型训练和推理过程中展现出显著优势,能够有效提升算力的整体性能。如今,全球科技巨头纷纷布局,国内企业也在加速追赶,超节点行业正站在时代的风口,展现出巨大的发展潜力与变革能量,有望重塑整个算力产业的格局,为人工智能的进一步发展提供强大动力。
本报告深入剖析了超节点行业的全貌。从概念内涵、优势特性,到国内外布局案例、规模演进、产业链影响,再到相关企业的发展态势,全方位、多维度地呈现了这一前沿领域的关键信息。旨在为行业从业者、投资者以及关注技术发展的各界人士提供一份极具价值的深度参考,助力大家把握超节点行业发展的脉搏,洞察未来算力世界的走向。
01
行业概述
1、超节点概念
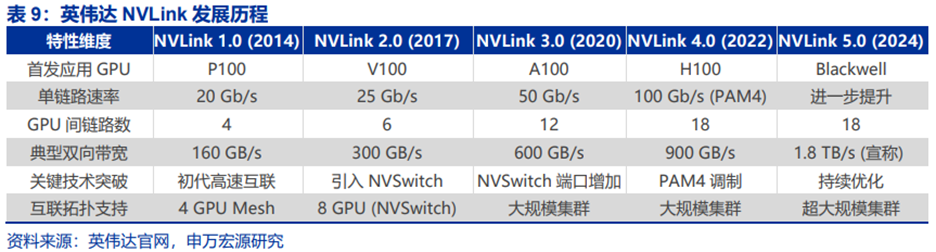
超节点,英文名为SuperPod,是英伟达公司最先提出的概念。
GPU作为关键的算力硬件,在AIGC大模型的训练与推理过程中发挥着至关重要的支撑作用。随着大模型参数规模的持续扩张,其对GPU集群规模的需求也在与日俱增,从千卡级别逐步迈向万卡级别,甚至未来有望达到十万卡级别乃至更高规模。
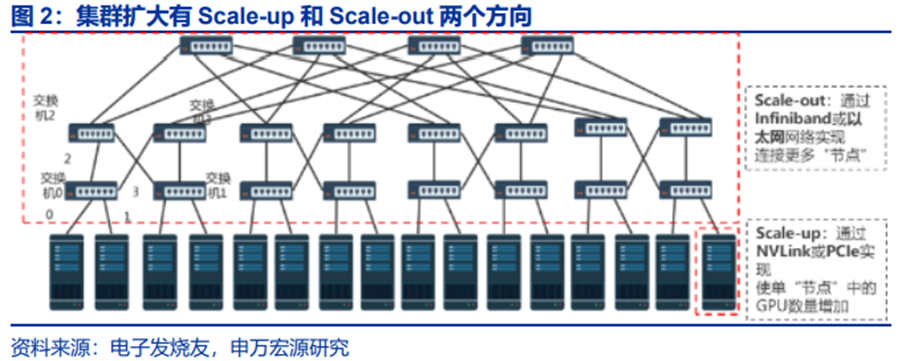
在构建规模日益庞大的GPU集群时,主要可采用两种策略:Scale Up(纵向扩展)与Scale Out(横向扩展)。
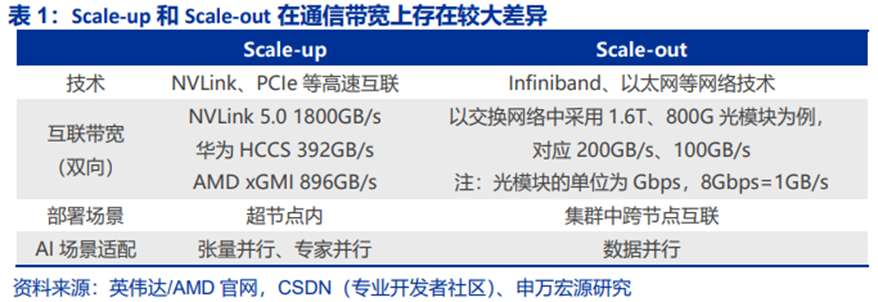
以货轮为比喻,当总运力需求扩张时,Scale-up是建造更大的货轮,而Scale-out则是增加货轮的数量。Scale-up追求硬件的紧密耦合;Scale-out追求实现弹性扩展,支撑松散任务(如数据并行)。二者在协议栈、硬件、容错机制上存在本质差异,通信效率不同。
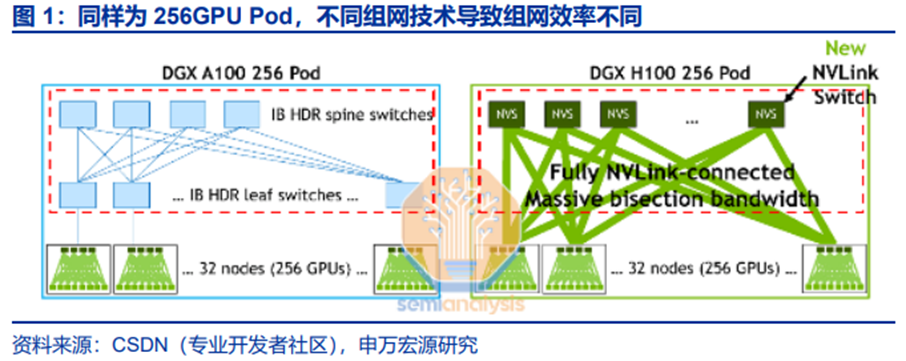
以A100和H100分别组成的DGX 256 Pod为例,两者均由32台8卡服务器跨机柜组成。DGX A100实际为服务器通过Infiniband交换网络Scale-out组成;而DGX H100通过第二层NVSwitch组网,实现256个H100全互联,为Scale-up,形成1个超大节点,在通信性能方面具备优势。
Scale Up较多表示GPU在节点内部的性能扩充。例如:增加Compute die或HBM的数量、性能;增加服务器等节点内的GPU数量,通过PCB、铜线等进行小范围互联;有时会增加一层交换芯片,例如PCIe Switch、NVSwitch都是算力Scale Up的一部分。(传统的AI4卡、8卡、16卡服务器都是典型的Scale Up形式。)
Scale-up系统往往对基于算力优化的网络协议与标准有更高技术要求。代表性的Scale-up网络包括英伟达多年迭代的NVLink、基于AMD早期Infinity Fabric协议的UALink、博通发布的Scale Up Ethernet(SUE)等,拥有更高的带宽和信令速率,从底层协议到系统硬件一般均独立与传统通信网络。例如英伟达的Blackwell芯片,其NVLink带宽达到1.8TB/s,由18个Port构成,每个Port 100GB/s、四对差分线构成、包含两组224Gbps的Serdes。
Scale Up场景:张量并行、专家并行等,高频交互、内存读写是重点,通常放在超高带宽、超低时延的网络中进行处理。Scale Up本质上是支持内存语义的网络。例如NVLink,在节点范围内实现内存语义级通信和总线域网络内部的内存共享,本质上是一个显存的Load-Store网络,性能和延迟均优于传统网络协议。一般Scale Up网络是GPU芯片直出互连,不采用传统网络的传输层和网络层,采用信用机制流量控制、链路层重传等机制保障可靠性。
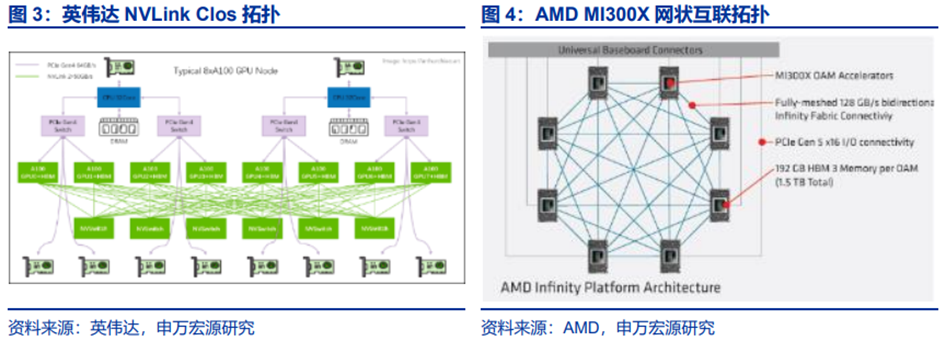
上代Scale-up规模为8卡,英伟达Clos结构领先。8卡服务器时代Scale-up主要为两种拓扑。1)网状拓扑:GPU之间以“手拉手”形式实现全互联,无交换芯片导致通信压力集中于GPU上,且GPU一对一通信效率下滑。2)Clos拓扑:英伟达将引入交换芯片引入Scale-up,使通信压力集中于NVSwitch,GPU间形成无阻塞的全互联;通信带宽弹性较大,能更好处理通信峰值,使集群性能提升。
当前Scale-up突破传统单服务器、单机柜限制进入“超节点”时代。Scale-up可理解为增加单个节点(过去指单台服务器)内GPU数量(从2卡到8卡);但其核心在于实现节点内全互联GPU,而非物理地存在于单台服务器或单个机柜。随着互联技术的演进,Scale-up正在突破单服务器、单机柜的限制,“超节点”可以跨服务器、跨机柜。
Scale Up已成为全球算力方案商的发力重点。英伟达除了将NVLink的性能迭代作为重要定期更新之外,在2025 COMPUTEX会议上还以NVLink Fusion IP授权的形式对第三方部分开放了NVLink机柜级的架构互联;台媒《电子时报》报道称,首款支持UALink规范高速互联芯片最早可能今年底实现流片;博通发布Scale Up Ethernet技术框架,在多XPU系统中提供XPU间的通信。
超节点实际就是算力网络系统在单个或多个机柜层面的Scale Up,节点内主流通信方案是铜连接与电气信号,跨机柜则考虑引入光通信;其与Scale Out的硬件边界是NIC网卡,外部借助光模块、以太网交换机等设备。二者的架构设计、硬件设备、协议标准有本质不同。
超节点作为新型算力基础设施,其大规模组网能力决定了模型训推效率与规模拓展的边界。以华为昇腾超节点产品为例,在Scale Up和Scale Out组网的技术协同下,超节点构建起高效、灵活的通信网络,成为突破算力瓶颈、支撑不同规模大模型训练及推理的核心技术路径。
2、超节点的优势
在探讨超节点的必要性时,有人可能会提出,如果Scale Up路线存在诸多困难,是否可以通过Scale Out路线,即增加节点数量来构建大规模GPU集群。然而,事实并非如此。超节点作为一种加强版的Scale Up架构,其重要性在于它能够在性能、成本、组网以及运维等多个方面带来显著的优势。
Scale Out架构的核心在于节点之间的通信能力。目前,主要采用的通信网络技术包括Infiniband(IB)和RoCEv2。这两种技术均基于RDMA(远程直接内存访问)协议,相较于传统的以太网,它们能够提供更高的传输速率、更低的时延,并且具备更强的负载均衡能力。其中,Infiniband是英伟达的私有技术,它起步较早,性能出色,但价格相对较高;而RoCEv2则是开放标准,它是传统以太网与RDMA融合的产物,成本较低。近年来,两者之间的性能差距正在逐步缩小。
然而,从带宽角度来看,IB和RoCEv2目前仅能提供Tbps级别的带宽,而Scale Up架构则能够实现数百个GPU之间10Tbps带宽级别的互联。在时延方面,IB和RoCEv2的时延通常在10微秒左右,而Scale Up架构对网络时延的要求极为严格,需要达到百纳秒(100纳秒=0.1微秒)级别。
在AI训练过程中,通常会涉及多种并行计算方式,包括张量并行(TP)、专家并行(EP)、流水线并行(PP)以及数据并行(DP)。其中,PP和DP的通信量相对较小,通常可以通过Scale Out架构来实现;而TP和EP的通信量较大,需要借助Scale Up架构(即超节点内部)来完成。
超节点作为当前Scale Up架构的较优解决方案,凭借其内部高速总线互连的特性,能够有效支撑并行计算任务,加速GPU之间的参数交换与数据同步。此外,超节点通常具备内存语义能力,允许GPU之间直接读取彼此的内存,这一特性是Scale Out架构所不具备的。
从组网与运维的角度来看,超节点同样展现出显著优势。超节点的超带宽域(HBD)规模越大,其内部集成的Scale Up架构中的GPU数量越多,相应地,Scale Out架构的组网复杂度将大幅降低。超节点本质上是一个高度集成的小型集群,其内部总线连接已预先完成,这不仅降低了网络部署的难度,还有效缩短了部署周期。在后期运维过程中,超节点的管理也更为便捷。
然而,超节点的规模并非可以无限制扩大,仍需综合考虑其成本因素。其具体规模应根据实际应用场景的需求进行科学测算。总体而言,超节点的核心优势在于通过增加局部带宽,有效降低增加全局带宽的成本,进而实现更高的性能收益。
3、超节点可选的方案
超节点的核心在于“互联”,需要一套完整的硬件和软件协议。包括Scale-up节点内和Scale-out节点间的互联。而互联生态,存在两种发展模式:
第一种是“垂直整合”模式,例如英伟达,构建了从NVLink-NVLink SwitchInfiniBand-CUDA完整技术栈。用户通过CUDA便可直接控制整个AI算力,性能和效率都非常高。但互联协议本身是闭源的,用户成本较高,并且存在厂商锁定风险。
第二种是由其他芯片巨头、云服务商和大型科技公司组成的“协议开放”模式。目前来看,超节点的开放标准还不止一个,但基本上都是以以太网技术(ETH)为基础。因为以太网技术最成熟、最开放,也拥有最多的参与企业。核心参与者包括AMD、博通、Intel、微软、Meta等,是以“兼容性”和“选择权”来对抗“封闭性”,构建一个基于开放标准的、更加多元化的生态系统。但生态碎片化程度更高。
开源开放将是未来超节点互联的行业趋势。值得注意的是,此前,NVLink是英伟达专用技术。但2025年是一个重要转折点:
英伟达推出NVLink Fusion,将原本封闭的NVLink开放给第三方伙伴。2025年,英伟达宣布向第三方开放NVLink IP授权,允许合作伙伴(如富士通、高通等)的CPU或定制ASIC芯片与英伟达GPU进行高速互联。这意味着未来可能有更多非英伟达芯片能融入其高速计算生态。2025年9月,英伟达与英特尔宣布合作,其中就包括将NVLink技术开放给英特尔,用于连接英特尔至强(Xeon)CPU和英伟达GPU。这标志着NVLink开始拥抱x86生态。
国内采用开源开放方式的以华为、海光两大超节点生态为代表,体系雏形初具。海光HSL:面向GPU、IO、OS、OEM等产业全栈,开放CPU互联总线协议(HSL)。华为:开放灵衢统一总线(UnifiedBus),支持超节点内不同类型、不同距离的组件统一互联。
4、国外超节点布局案例
(1)英伟达:专用网络支持,单节点密度提升
英伟达在Hopper GPU一代尝试突破服务器架构、在机柜层级拓展Scale Up系统。英伟达2023年发布DGX GH200系统是较早的“超节点”尝试,同过去A100和H100系列服务器最大区别在于,将Grace CPU和Hopper GPU封装在同一块板卡上,连同其他部件形成1U大小的“刀片服务器”,并将其通过内部线缆(cable cartridge)和光模块的方式和2层专门设计的NVLink交换机连接在一起。预计,早期成本和节点规模设计等因素影响了GH200的实际推广。

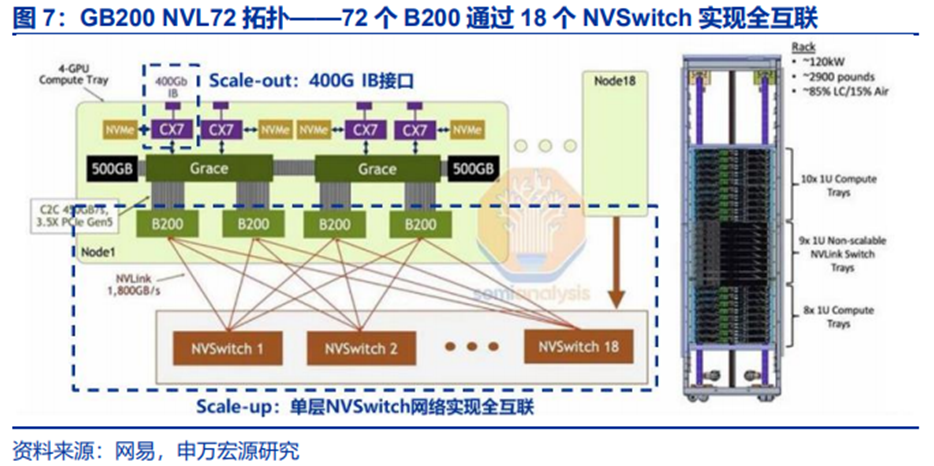
2024年3月,英伟达推出基于Blackwell GPU打造的GB200 NVL72超节点产品,NVL72是较为成熟的超节点产品。借助第五代NVLink,GB200系统最大可576个GPU扩容,目前商用方案在柜层面连接72个GPU,相较此前GH200系统,Scale Up的带宽与寻址性能大幅提升。
Scale-up方案:NVL72中72个B200 GPU分布于18个Compute Tray中;18个NVSwitch交换机芯片分布于9个Switch Tray中。72个GPU通过盲插高速背板(blindmate backplane)实现Scale-up,铜线为主。NVL72中所有Tray部署在单个机柜中,可视为一个超节点。
Scale-out为光通信方案:依靠InfiniBand或以太网,对应ConnectX-7的400G(800G)网卡与交换机,或未来升级的ConnectX-8的800G(1.6T)网络,带动800G至1.6T光模块、交换机的放量。

拓扑结构上,72个B200通过单层的NVSwitch(图7中橙色部分)实现全互联,每个B200对超节点内其他71个GPU的通信带宽均达到1800GB/s,应对通信峰值的能力显著提升。
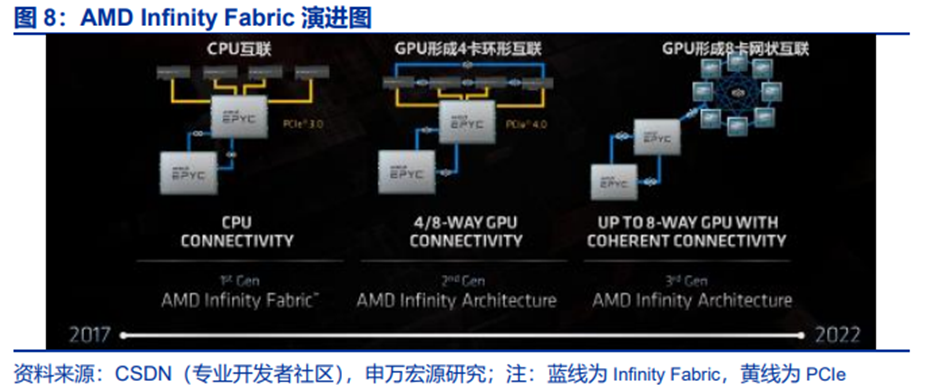
(2)AMD:IF128探索超节点新路径
Infinity Fabric是AMD的互联总线技术,既用于芯片内部的不同模组,也用于外部互联。IF的总线结构包含两个部分:负责数据传输的Scalable Data Fabric(SDF)、负责控制的Scalable Control Fabric(SCF),分别类比为血管和神经。IF的设计目标是将不同芯片纳入同一控制下的系统并确保数据传输的高拓展性,包括异构芯片(如CPU和GPU)以及同个芯片上的不同Die。
Infinity Fabric演进路径:第一代:用于CPU-CPU通信,①实现双路或多路服务器中多个CPU间频繁交换数据和同步任务;避免传统PCIe总线的瓶颈;②支持全局地址空间,使多个CPU可共享内存资源。第二代:4个GPU间形成环形连接,但CPU-GPU通信仍为传统PCIe。第三代:8个GPU通过IF连接形成网状拓扑,同时CPU-GPU间通过IF连接,IF实现CPU与GPU的统一内存寻址;CPU可直接访问GPU显存,避免数据迁移开销,加速AI推理中的模型参数传递。
根据TechPowerUp,AMD将在26H2推出搭载128个MI450X的超节点产品。AMD或将带来超节点新的融合技术路径,MI450X IF128通过实现以太网Scale-up。
与NVL72类似,4个MI450X与1个EPYC CPU组成1U的Compute Tray,32个Compute Tray分布于2个机柜中,由Switch Tray中的定制IFoE交换芯片实现互联,两个机柜通过铜背板实现连接。
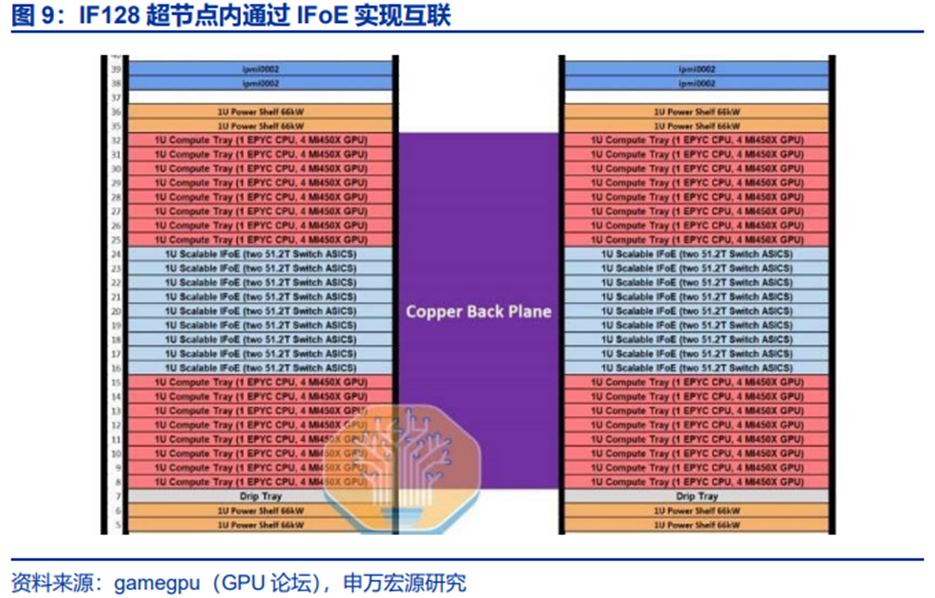
与NVL72不同的是,IF128内GPU的连接通过IFoE(Infinity Fabric over Ethernet)连接,可以理解为基于以太网技术的打造了新的超节点互联方式,对标UB互联网络及NVLink,一定程度地打破Scale-up和Scale-out界限。能够认为,在当前大模型和超节点趋势下,集群Scaling采用Clos类拓扑的确定性较高,而Scale-up的技术路径将受到工程、通信协议优化等因素影响。
02
驱动因素
1、计算需求演进,超节点成为AI基建共识
(1)算力需求演进对高带宽、低时延提出更高要求
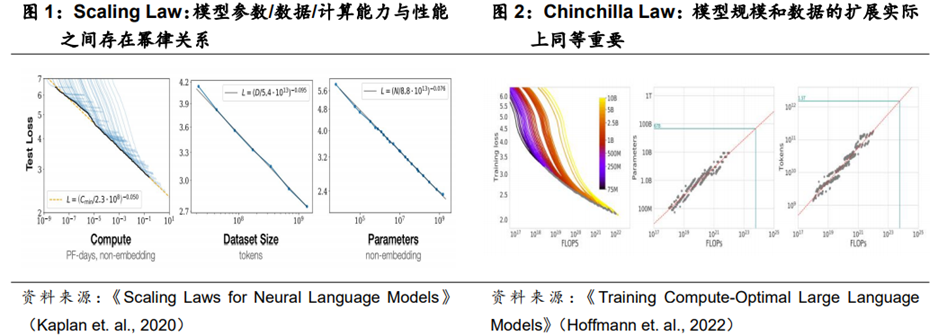
模型需求演进:从单纯堆砌算力转向搭建高带宽、低时延、持续数据供给的均衡系统。规模定律(ScalingLaw)揭示了模型性能与参数、数据量、计算投入的关系,钦奇拉法则(ChinchillaLaw)进一步要求参数与数据按比例协同扩展,使得算力需求从单纯堆砌算力转向搭建高带宽、低时延、持续数据供给的均衡系统。
产业演进:从硬件聚合到系统构建。超节点内涵逐渐从最初聚焦硬件互联,深化为软硬件一体化的全栈协同设计。在缺少配套软件的情况下,容易面临生态系统碎片化和性能优化难度较高等挑战。
(2)基础技术特征:超高带宽互联与内存统一编址
超高带宽互联与内存统一编址是超节点的基础技术特征。(1)超大带宽和超低时延互联:超节点借助高效的互联协议打破传统架构限制,支持更大规模AI处理器的高效协同,实现更大范围、更高流量的数据传输,从而突破系统性能。(2)内存统一编址:超节点内所有互联设备的内存地址需全局唯一,基于全局内存可实现任意设备间的灵活访问。这使得大模型训练中频繁的参数同步操作,无需经过传统的“序列化-网络传输-反序列化”流程,直接通过内存语义通信完成,提升小包数据传输及离散随机访存通信效率。
(3)追求多级存储池化、资源灵活配比以及高可靠性
多级存储资源池化突破系统间资源壁垒。超节点通过资源池化技术将分散的计算、存储、网络资源抽象为统一逻辑资源池,以集中化管控的方式消除资源孤岛,实现动态弹性调度。以大模型推理核心组件KV Cache为例,传统静态分配模式因资源隔离导致KV Cache重复存储与访问阻塞,资源池化技术可将KV Cache从单机显存的物理限制中解放,单卡显存只需保留热数据,冷数据动态迁移至内存或存储层,从而支持百万Token级长上下文处理并实现批处理规模的倍级提升。
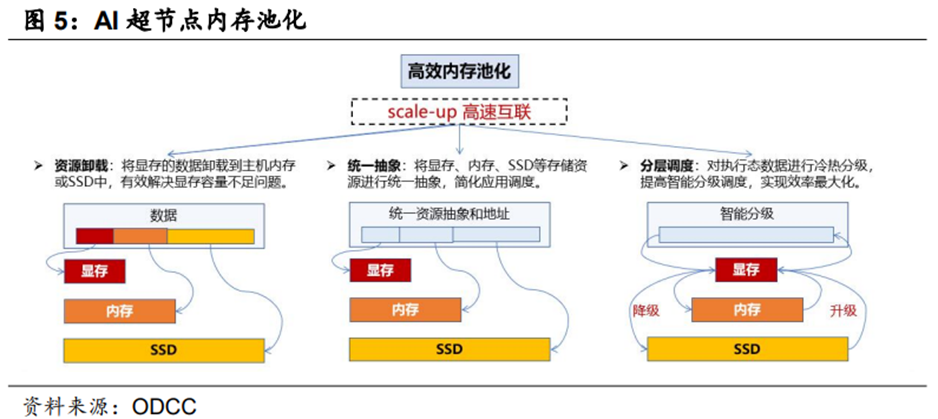
资源灵活配比实现资源精准按需配置。超节点通过资源池化与软件定义架构的深度融合,将CPU、NPU、内存、存储等物理资源解耦为可独立调度的资源池,根据任务特征自动调整各类型资源的配比比例,如在计算密集型任务中提升NPU与内存占比,在访存密集型任务中提升带宽与显存资源占比,在存储密集型场景中增加CPU与存储资源配额。多任务(如同时运行模型训练、在线推理、数据预处理)场景下,超节点通常可采用逻辑切分技术,将物理超节点拆分为多个逻辑超节点,各逻辑节点间通过高速互联协议实现低时延通信。

高可靠性是决定系统计算效率及成本的重要指标之一。万级处理器通常会带来故障常态化。据华为《超节点发展报告》,以GPT-3(175B)到GPT-4(1.9T)的演进为例,当参数增至10.8倍,总集合通信达34.1倍,跨节点RDMA达49.3倍,光电转换49.3倍。任一组件或一次光电转换失败都会放大为全局可用度/利用率问题,进一步抬升运维复杂度,超节点稳定而可靠的运行依赖可靠的硬件、可靠的网络以及可靠的系统:
(1)可靠硬件是系统稳定运行的核心前提。据《The Llama 3 Herd of Models》研究显示,Llama3.1模型在万卡集群训练时,平均3小时会出现一次故障,其中绝大多数故障源于器件层面的失效。超节点在考虑硬件可靠性时需覆盖器件生产、选型和使用阶段等全生命周期。
(2)可靠网络保障数据传输无中断。超节点网络涵盖超节点通信域与跨节点通信域,据华为《超节点发展报告》,相比传统服务器系统,超节点集群光模块的数量增长,面临更高的网络失效率的挑战。常见可靠网络保障措施有:①通信域内设置冗余节点:由于超节点通信域内带宽显著高于跨域带宽,当域内计算节点故障时,需设计域内冗余节点配置与整节点迁移机制,避免因带宽不匹配导致故障无法及时恢复。②光模块故障检测与动态修复机制:当光模块发生局部故障时自动切换至冗余通道,保障数据传输链路的连续性。③多平面通信架构应设计链路收敛算法:在某一平面链路故障时快速路进行路径切换与流量重定向,大幅缩短故障修复时间。
(3)可靠系统实现全域统管与故障排除。故障主动预防与恢复能力是超节点系统运维的关键能力。①故障主动预防:通过对器件运行数据的挖掘与趋势分析,提前感知器件的亚健康状态,预判潜在故障风险。②分级故障恢复:分级恢复策略能确保不同类型业务在故障发生时均能被实时高效地处理,以最小时间代价保障业务连续性。
2、算力需求持续增长,推理市场与主权AI加速推进
(1)算力总需求仍在持续增长
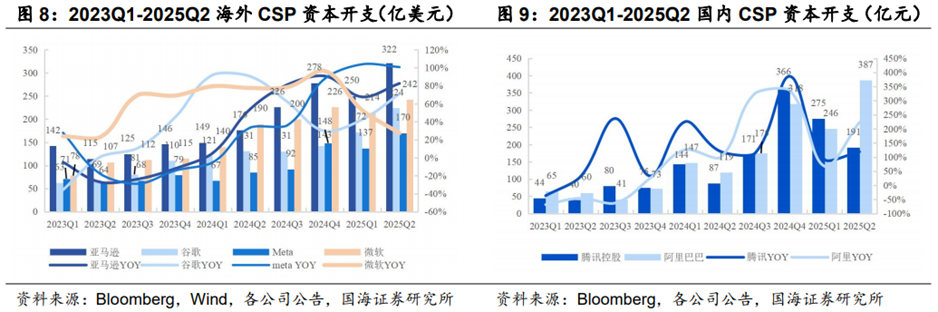
国内外CSP在二季度财报电话会纷纷上调资本开支指引。谷歌将2025年CapEx预期从750亿美元上调至850亿美元,主要用于AI基础设施建设;微软Q2的CapEx为242亿美元,接近一半的支出用于服务器(包括CPU和GPU),预计Q3的CapEx将超300亿美元;Meta调整2025年CapEx区间为660-720亿美元,并表示2026年CapEx仍将显著增长,主要用于扩展生成式AI所需的服务器、网络和数据中心建设;亚马逊在财报电话会表示Q2的314亿美元(财报值为322亿美元)CapEx很大程度上可以代表公司下半年预计支出,公司强调将继续在芯片、数据中心和电力方面投入更多资本;甲骨文FY2026Q1的Capex为85.02亿美元,同比增速提速至 269.17%(FY2025Q4增速为 224.52%),公司预计2026财年CapEx将达约350亿美元;阿里巴巴在2025Q2财报电话会上重申三年3800亿元人民币AI资本开支计划。英伟达预计未来五年全球AI资本支出将达3-4万亿美元。
(2)产业重心从训练到推理,主权AI成新增需求方
大模型产业重心从训练到推理的转变,已成行业共识。9月16日,腾讯在2025腾讯全球数字生态大会上表示,大模型产业重心从训练到推理的转变,已经成为行业共识。甲骨文在9月9日财报电话会上也强调,AI推理市场将“远大于”AI训练市场,为了在AI推理市场占据主导地位,甲骨文还新推出了“AI数据库”。
主权AI正在崛起。英伟达在8月27日财报电话会上表示,今年有望实现200亿美元的主权AI收入。英伟达认为,主权AI正在崛起,比如,欧盟计划投资200亿欧元,在法国、德国、意大利和西班牙建立20个AI工厂,包括5个超级工厂,将AI计算基础设施提升十倍。鸿海预计未来五年主权AI领域投资有望超1万亿美元,主要包括美国的Stargate(5000亿美元)、欧盟InvestA(I2000亿欧元)以及沙特Humain AI(1000亿美元)。

03
规模选择:模型需求与工程成本的平衡
Scale Up超节点设计对模型训练、推理性能提升效果显著,尤其相较于传统8卡服务器架构。LLM的实时延迟、多用户并发、降低服务成本是当前AI应用的刚需。使用多GPU的超节点架构和张量并行等技术来运行大型模型,可以快速处理推理请求,从而实现实时响应;若进一步均衡选择超节点内的GPU数量,还可以同时优化用户体验和成本。
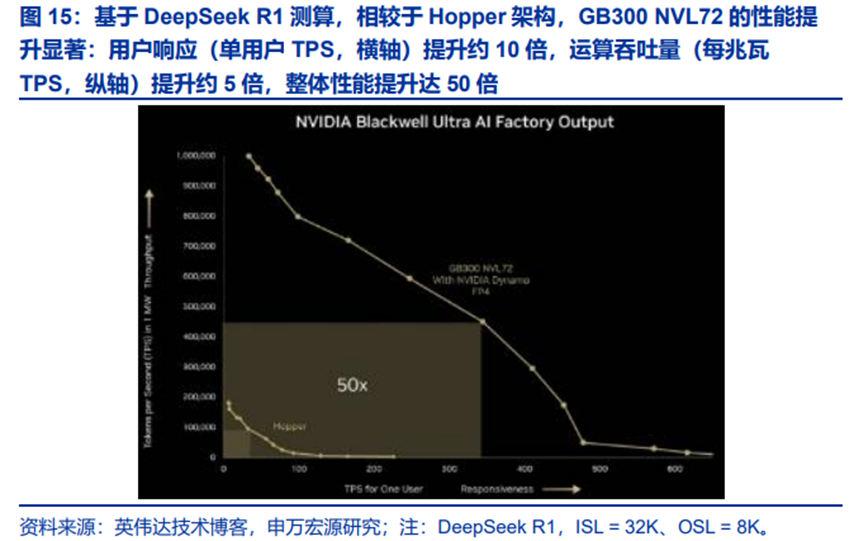
超节点的多GPU推理是通信密集型推理。据英伟达技术博客,多GPU TP推理的工作原理是将每个模型层的计算拆分为服务器中的2个、4个甚至8个GPU,理论上GPU的数量等同于模型运行速度的提升倍数。但每个GPU完成模型层各自部分的执行后,必须将计算结果发送到每个其他GPU(all-to-allreduction),且通信时计算闲置,因此缩短GPU之间的结果通信时间至关重要。
而对比全球主要科技厂商的超节点方案,基本可分为单柜更多GPU的单柜高密高电路径、多机柜多GPU路径两大方向。目前,前者对单体供电要求、柜内铜/电气信号和背板连接、液冷要求更高(如英伟达NVL72),而后者对光学连接要求更高(如谷歌TPU、华为CloudMatrix)。
超节点内GPU数量与架构的设计,受底层模型并行、数据中心架构、成本性能均衡等影响,壁垒较高。
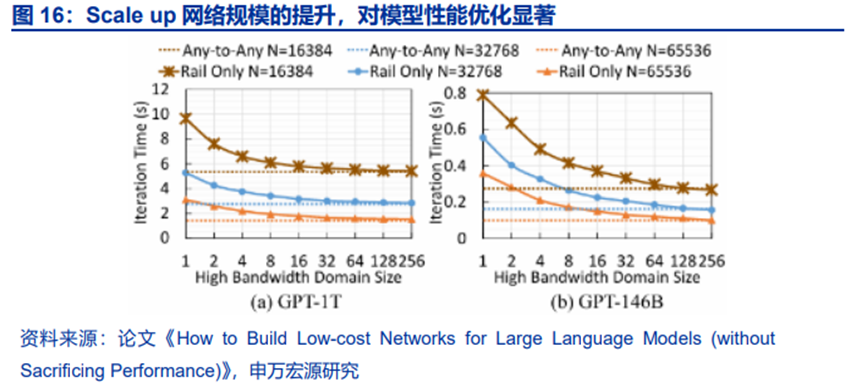
1)模型角度,参考Meta论文(下图)基于英伟达H100GPU对GPT模型进行研究,当前72卡规模以上的Scale Up节点是较优的选择。如果将NVLink互联的Scale Up网络理解为一个高带宽域(High Bandwidth Domain,HBD),对于GPT-1T模型,GPU数量在64卡以上时相较于传统8卡系统性能提升显著;同时,当Scale Up的NVLink网络规模增大时,实际上节点内互联的RDMA带宽带来的性能收益在减小。在考虑系统复杂度、工程难度和成本等因素下,72卡是目前英伟达Blackwell超节点的均衡选择。而当模型架构变化(例如MoE增加对显存的访问需求)、参数量继续增长后,更大规模的Scale Up超节点预计是必然选择(例如华为CloudMatrix 384系统、英伟达VR NVL576系统等)。
2)IDC实践角度,超节点设计应考虑机房内液冷、供电、布线和整体布局的实际情况。以英伟达GB200 NVL72机柜为例,整个机柜功率大约120kW、采用标准的19英寸机柜,按照物理原理和行业惯例,单机柜功率超过30至40kW则有必要采用液冷方案,此时72GPU的Scale Up超节点是目前单机柜内的扩展密度的极限,除非进一步优化供电和散热能力;以华为为代表的国产硬件厂商工程优化能力出色,结合我国市场的制造、基建、能源和产业链优势,则可以考虑将Scale Up扩展至多机柜布局,如华为CloudMatrix 384系统。
模块化布局也是AI机房发展的重要趋势,利于交付和运维。维谛技术、科华数据、英维克等公司针对算力集群需求推出模块化和一体化解决方案,整合计算、电气、温控等模块,符合云厂商定制化需求、同时加快交付节奏。传统IDC通常逐机柜上架,依照经验,上架率达到90%大约需要12-18个月的上架周期;而智算中心交付需求时间通常在3-9个月,未来甚至更短,超节点的模块属性满足AI大厂快速投建投产的需求。
3)成本角度,光通信等组网成本、系统复杂度和维护也制约了超节点Scale Up的规模设计。
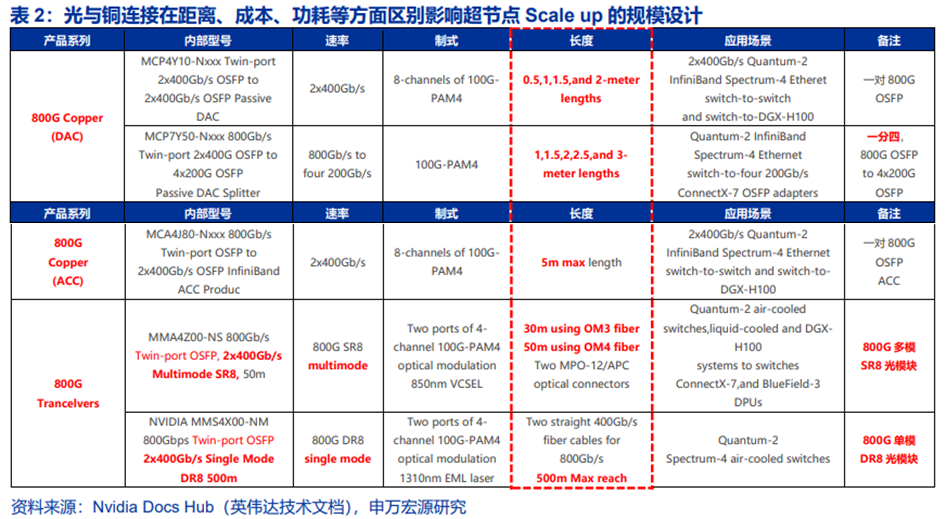
AI集群的通信需求,带宽固定(等宽网络),但距离多变。参考标准的19英寸机柜,仅一个5台机柜的节点,服务器到一层交换机的连接距离预计在3至5m以上,光连接是跨机柜连接的必要选择,小集群内的多模光模块 多模光纤连接是主流;而机柜内连接则可选择背板、铜缆、PCB等方案。
铜连接(DAC等)最大优势是成本与功耗,痛点则是距离。参考英伟达官方配置的800G无源铜缆,最大传输距离3m;但优势是功耗极低,几乎没有额外耗电;以及相较于有源电缆更低的成本(无驱动芯片)。有源铜缆可以以1.5W的功耗将距离扩展至最大5m;预计1.6T网络下,该距离缩短。而光模块的有效连接距离、速率升级潜力是最大优势。
因此从英伟达的NVL72方案到华为的CloudMatrix 384系统,参考当前不同速率光模块的采购成本(400G、800G到1.6T之间差异巨大),超节点的规模选择也考虑了综合成本、系统运维因素。
04
国内超节点布局
1、华为以开创的超节点互联引领AI基础设施新范式
(1)昇腾Atlas 900 AI集群:打造首个万卡AI集群
昇腾384超节点(Atlas 900 A3 SuperPoD),华为CloudMatrix的核心愿景是构建一个「万物皆可池化、平等对待、自由组合」的AI原生数据中心。2025年4月,华为正式推出基于384个昇腾NPU构建的CloudMatrix 384超节点。产品形态上,384个NPU分布于48台8卡服务器中,48台服务器分布于12个计算机柜内;通过4个交换机柜实现384个NPU的全互联。该超节点可进一步扩展为包含10万卡的Atlas 900 Super Cluster超节点集群,为未来更大规模的模型演进提供有力支撑。
截至2025年9月18日,华为Atlas 900 A3 SuperPoD超节点累计部署300多套,服务于互联网、金融、运营商、电力、制造等行业的20多个客户。

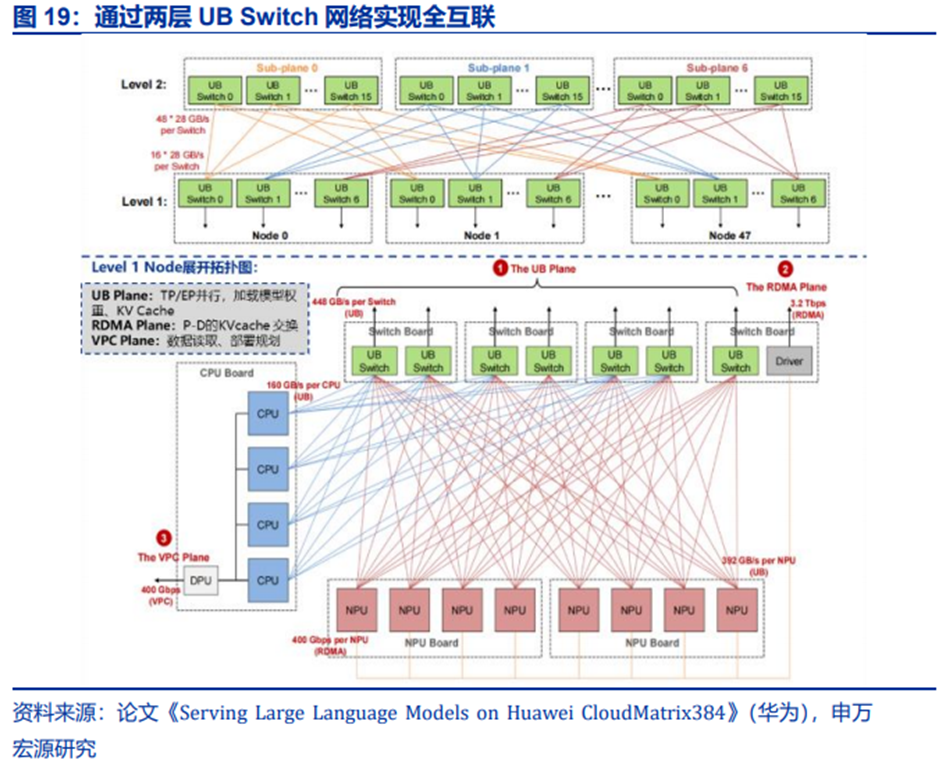
拓扑结构上,计算机柜内的所有处理器通过UB链路连接到板载的UB Switch交换芯片上,形成单层的UB平面。这些板载交换机(L1层)再通过高速链路连接到位于通信机柜中的第二层(L2)UB交换机。
整个UB交换系统被精心设计成一个两级、无阻塞的Clos网络拓扑。L2交换机被划分为7个独立的子平面,每个L1交换芯片精确地连接到对应子平面的所有L2交换机。这种设计保证了从任何一个节点到L2交换矩阵的上行总带宽与其内部UB容量完全匹配,从而在整个384-NPU的超级节点范围内实现了无带宽收敛,确保了任意NPU之间都能获得稳定、高带宽的通信能力。
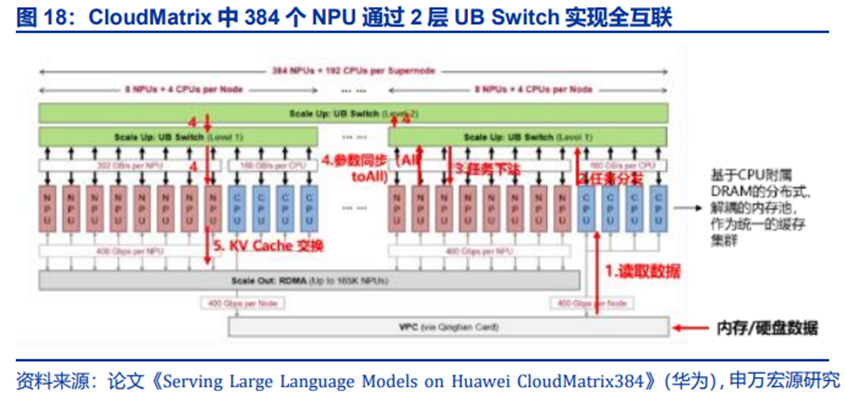
而在信号和数据传输层面,CM384包含三大通路:
1)UB平面:核心的Scale-Up网络,以全互联(All-to-All)拓扑连接所有NPU和CPU。每颗昇腾910C贡献超过392GB/s的单向带宽。它专为TP、EP等细粒度并行以及内存池的快速访问而设计。
2)RDMA平面:用于超级节点间的Scale-Out通信,采用RoCE协议,确保与现有生态兼容。NPU是该平面的唯一参与者,用于KV Cache在Prefill和Decode节点间的传输、分布式训练等。
3)VPC平面:通过华为自研的擎天卡连接到数据中心网络,负责管理、控制、访问持久化存储等。
对于一个AI推理任务,其在CM384网络中的流转大致可抽象为:CPU通过VPC平面读取内存/硬盘数据,通过UB平面将任务分发到各NPU,NPU进行计算,并通过UB平面同步模型权重及KV Cache,再通过RDMA平面与另一机柜间进行KV Cache交换。
CloudMatrix 384超节点核心:UB网络保证节点间通信。CloudMatrix 384通过两层UB Switch实现Scale-up。分层看,第一层UB网络(图19红线)实现了小节点内8张NPU的全互联,而二层UB网络实现了48个小节点的无收敛全互联。两层Scale-up网络结构与英伟达此前推出的DGX H100 256 Pod类似,而由于热功耗、稳定性等工程问题,双层NVLink的Scale-up并未大面积推广。
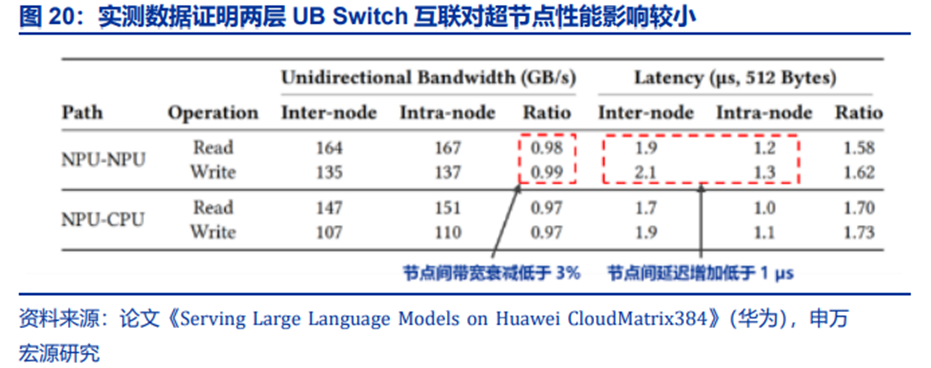
从实测数据看,CloudMatrix 384两层网络对性能影响较小。如图20,Intra-node表示最小节点内的GPU通信(即8卡服务器内),Inter-node表示不同服务器中的GPU通信;由于Inter-node通信需要经过L2 UB Switch(多一跳)因此通信性能有小幅影响。节点间带宽衰减低于3%,节点间延迟增加低于1µs。鉴于现代AI工作负载主要依赖带宽而非延迟,这种边际延迟开销对AI任务的端到端性能的影响微乎其微,因此CloudMatrix 384可以理解为超大规模、紧密耦合的超节点。
CloudMatrix 384核心进展在于UB网络的工程能力突破,弥补单卡性能短板。与过去网状8卡互联相比,UB网络将通信压力更多转移到UB Switch上,提升NPU间一对一通信带宽和超节点内应对通信峰值的能力,叠加优化的通信协议显著提升通信效率。能够认为,在国产算力单卡性能仍有差距的情况下,通过光互联组建大规模Scale-up超节点将成为趋势。
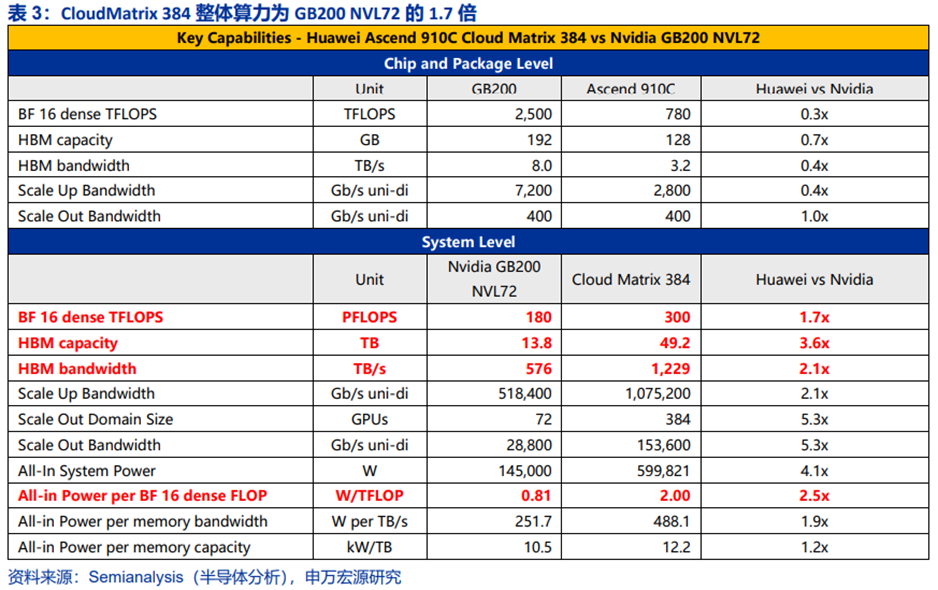
大规模超节点将更适合未来AI工作负载。与NVL72相比,CloudMatrix 384超节点的算力达到300P,为NVL72的1.7倍;内存为NVL72的3.6倍。随着模型参数量、MoE模型趋势下专家数量的增加,推理对计算、内存和互连带宽的要求将继续提升。
新兴的架构模式,如用于专门推理的模块化子网络、检索增强生成或混合密集/稀疏计算,要求模型组件之间更紧密的耦合,从而增加模型内部的通信和同步。这些工作负载需要将计算和内存共置在一个紧密集成的超级节点内,以减少通信延迟并保持高吞吐量。
因此,超节点的容量对维持MoE模型所需的细粒度局部性和性能特性较为重要。更大的资源池可以为非均匀大小的作业提供更大的部署灵活性,在实际工作负载分布下,扩展超级节点规模可显著提高系统吞吐量和效率。
此外,扩大超节点规模并不会必然导致每个NPU的网络成本增加。假设网络架构相同,例如双层Clos类交换拓扑,只要配置实现交换机端口充分利用,每个NPU的网络基础设施摊销成本在不同规模间几乎保持不变。给定交换层数下,超节点规模的扩展不会带来额外的成本开销,因此从网络角度来看,这是一种经济高效的策略。
(2)昇腾Atlas 950/960 SuperPoD计划于2026/2027年上市
1)Atlas 950超节点:华为预计2026Q4上市,满配支持8192颗Ascend 950DT芯片,FP8算力达8EFLOPS,FP4算力达16EFLOPS。互联带宽达到16PB/s,超过今天全球互联网峰值带宽的10倍有余。相比英伟达NVL144,Atlas 950超节点卡的规模是其56.8倍,总算力是其6.7倍,内存容量是其15倍,达到1152TB;互联带宽是其62倍。即使是与英伟达计划2027年上市的NVL576相比,Atlas 950超节点在各方面依然是领先的。

2)Atlas960超节点:华为预计2027Q4上市,满配支持15488颗Ascend 960芯片,FP8算力将达30EFLOPS,FP4算力将达60EFLOPS,内存容量达4460TB,互联带宽达34PB/s。大模型训练和推理的性能相比Atlas 950超节点,将分别提升3倍和4倍以上,达到15.9MTPS和80.5MTPS。
(3)基于超节点,华为发布全球最强超节点集群:Atlas 950 SuperCluster和Atlas 960 SuperCluster
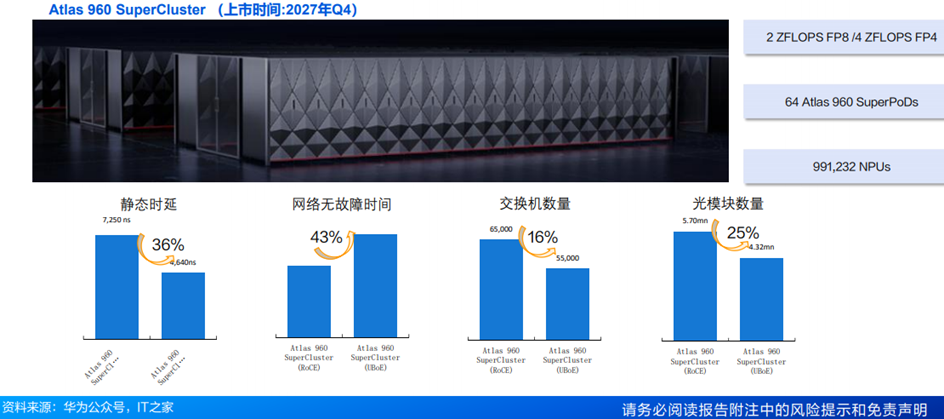
1)Atlas 950 SuperCluster 50万卡集群:华为预计于2026Q4,由64个Atlas 950超节点互联组成,FP8算力达524EFLOPS,同时支持UBoE与RoCE两种协议。Atlas 950 SuperCluster集群相比当前世界上最大的集群xAIColossus,规模是其2.5倍,算力是其1.3倍。

2)Atlas 960 SuperCluster百万卡集群:华为预计于2027Q4上市,FP8算力达2 ZFLOPS,FP4算力达4ZFLOPS,同样也支持UBoE与RoCE两种协议。
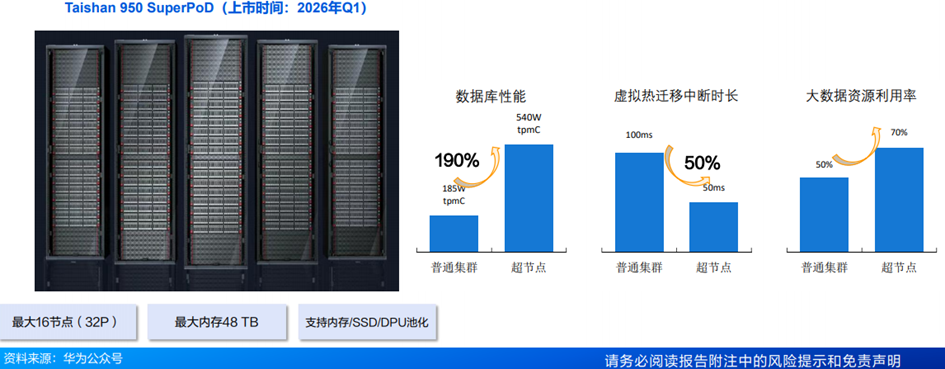
(4)昇腾Taishan 950 SuperPoD:业界首款通算超节点
Taishan 950 SuperPoD——华为推出的业界首款通算超节点,为通算性能提升开辟全新路径。预计2026Q1上市,基于Kunpeng950打造,最大支持16节点,32个处理器,最大内存48TB,同时支持内存、SSD、DPU池化。未来还有望基于TaiShan 950和Atlas 950打造成混合超节点,为下一代生成式推荐系统打开全新架构方向。
(5)昇腾Atlas850:首款企业级风冷AI超节点
Atlas 850——业界首个企业级风冷AI超节点服务器。该产品搭载8张昇腾NPU,有效满足企业模型后训练、多场景推理等需求。Atlas 850支持多柜灵活部署,最大可形成128台1024卡的超节点集群,是目前业内唯一可在风冷机房实现超节点架构的算力集群。

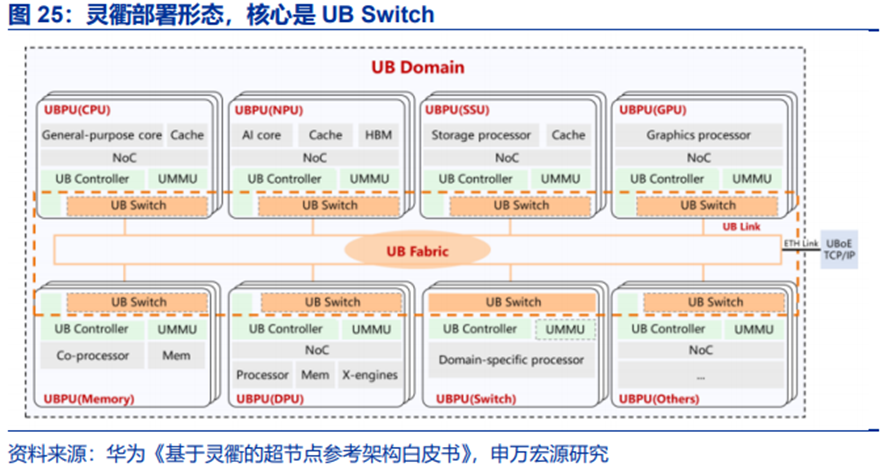
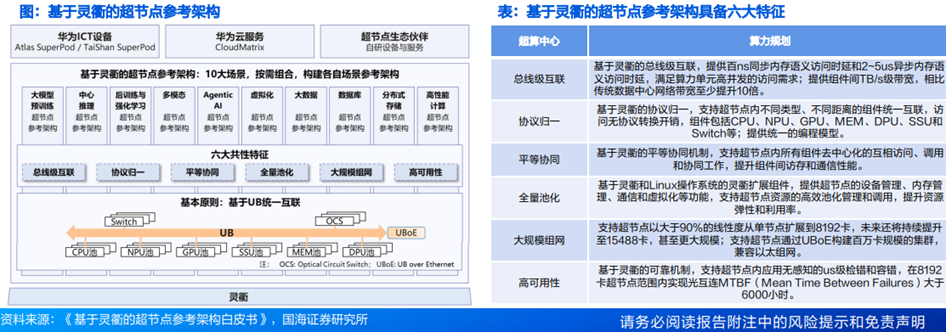
(6)华为灵衢:面向超节点的互联协议
灵衢是一种面向超节点的互联协议,将I/O、内存访问和各类处理单元间的通信统一在同一互联技术体系,实现数据高性能传输、算力高效协同、资源统一管理和灵活组合,是超节点参考架构的基础。基于灵衢(UnifiedBus,简称UB)的超节点架构,支持CPU、NPU、GPU、MEM、DPU、SSU(Scalable Storage Unit)和Switch中的一种或者多种组件资源池化和平等协同,构建逻辑上的一台计算机。
华为于2019年开始研究灵衢技术,2025年灵衢1.0正式在Atlas 900 A3 SuperPoD上商用验证,2025年9月,华为正式开放灵衢2.0协议。
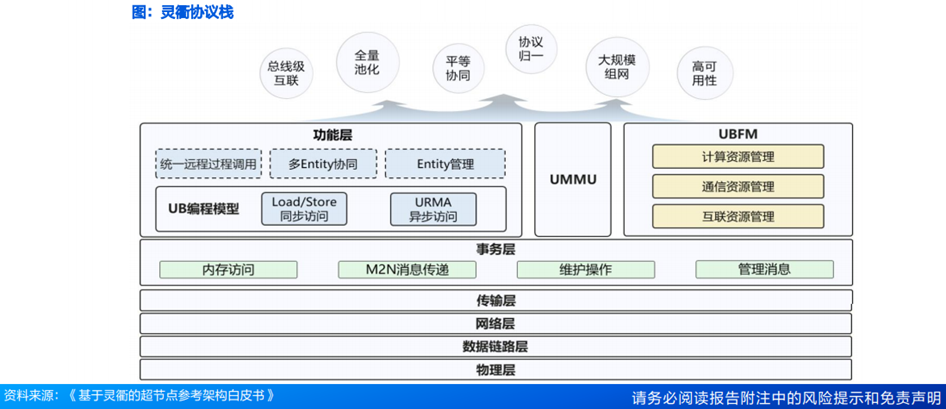
灵衢提供分层的协议栈,从下到上由物理层、数据链路层、网络层、传输层、事务层、功能层以及UMMU、UBFM(UB Fabric Manager)组成。其中,Entity为功能实体,是全局通信的基本单元;URMA(Unified Remote Memory Access)为统一远程内存访问。
2、阿里云发布全新一代磐久128超节点AI服务器
阿里云正式发布全新一代磐久128超节点AI服务器。该服务器由阿里云自主研发设计,具备强大的兼容性,可支持多种AI芯片,单个机柜能够容纳128个AI计算芯片。值得一提的是,磐久超节点集成了阿里自研的CIPU2.0芯片以及EIC/MOC高性能网卡,并采用开放架构。这一设计使得其能够实现Pb/s级别Scale-Up带宽和百ns极低延迟。与传统架构相比,在同等AI算力的情况下,磐久128超节点AI服务器的推理性能可提升50%。
磐久128超节点采用模块化设计,单机柜支持128个AI计算芯片,密度刷新业界纪录。通过正交架构优化空间布局,机柜功率密度可达350kW,支持单芯片2000W高负载运行,同时实现99%的硬件故障预测准确率。这一设计显著提升了数据中心的算力集中度,尤其适合万亿参数级大模型的分布式训练。

正交设计运维更便捷:Compute-Tray采用横放的结构,支持单个Compute Tray 4颗GPU,Switch-Tray采用竖放的结构,这样整个机柜本身没有任何Cable Tray(电缆桥架)。
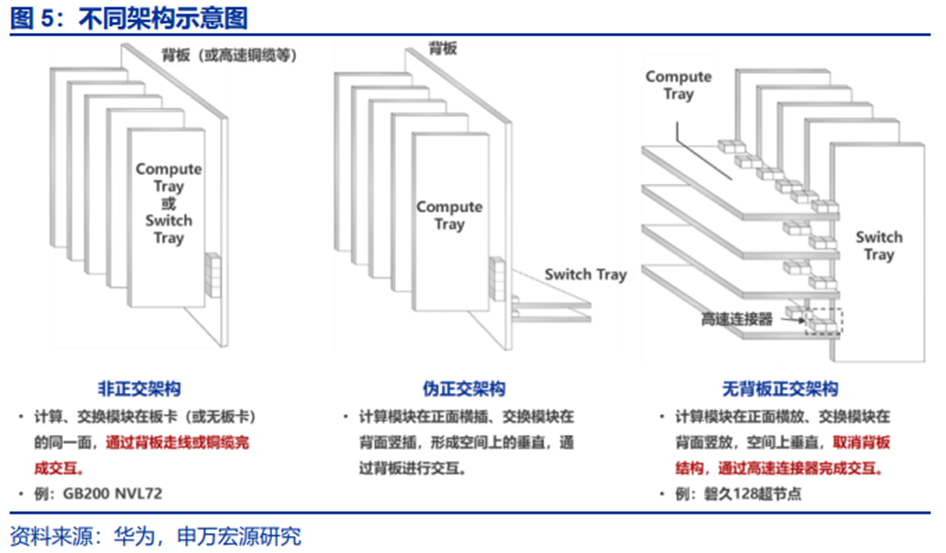
CPU和GPU分离设计:更灵活也容易迭代升级,支持8卡/OS,16卡/OS,CPU节点可以独立演进,支持不同CPU平台、代次,GPU节点支持多种GPU芯片方案,满足不同业务需求。

磐久128超节点为既华为CloudMatrix 384之后,又一国产超节点范式。磐久采用了单机柜 无中背板的正交结构,而CM384采用16机柜 机柜内铜互 机柜间光互连。与CM384相比,磐久为单机柜产品,节点内互联距离较短,Scale-up网络不使用光互连,单芯片互联网络的成本或相对较低;但Scale-up网络拓扑预计仍为双层CLOS架构。
考虑到其计算模块与CPU、交换模块分开等通用性设计,预计磐久128超节点将会成为CM384之后国产超节点的又一通用范式。一方面,可以降低在推理场景部署国产卡的适配难度;另一方面,这一方案或将被部分国产AI芯片厂商采用。
3、中科曙光发布AI超集群系统
中科曙光发布国内首个基于AI计算开放架构设计的曙光AI超集群系统。根据中科曙光公众号,9月5日,中科曙光在2025重庆世界智能产业博览会发布了国内首个基于AI计算开放架构设计的产品——曙光AI超集群系统。除了紧耦合设计,该集群系统还支持多品牌AI加速卡以及兼容CUDA等主流软件生态,为用户提供更多开放性选择,大幅降低硬件成本和软件开发适配成本。

海光系统互联总线协议(HSL)开放,打造国产算力核心基座。2025年9月13日,海光面向GPU、IO、OS、OEM等产业全栈,宣布开放CPU互联总线协议(HSL),核心内容包括开放完整的总线协议、提供IP参考设计、开放指令集等。产业上下游伙伴可通过海光系统互联总线,实现更高效的系统连接。比如降低访问延迟、自定义简化协议栈、提升链路利用率、支持缓存一致性和自由的多链路扩展。同时也将较大程度有助于部件及整机研制厂商快速设计不同品牌的GPU产品并推向市场,释放国产算力的产业协同效能。当前,加入HSL协议的参与者包括寒武纪、沐曦、摩尔线程等。
4、浪潮信息发布超节点AI服务器“元脑SD200”
浪潮信息发布面向万亿参数大模型的超节点AI服务器“元脑SD200”。根据元脑服务器公众号,8月7日,浪潮信息发布面向万亿参数大模型的超节点AI服务器“元脑SD200”。该产品基于自主研发的开放总线交换技术首创多主机三维网格系统架构,实现64路本土GPU芯片高速互连;通过创新远端GPU虚拟映射技术,突破多主机交换域统一编址难题,实现显存统一地址空间扩增8倍,单机可以提供最大4TB显存和64TB内存,为万亿参数、超长序列大模型提供充足键值缓存空间。

5、沐曦股份创新多种超节点形态
2025年7月,沐曦股份发布多种超节点形态。(1)曦云C500X光互连64x GPU超节点(16-64x GPU),通过光模块技术降低延迟,提升跨节点通信效率,适用于分布式训练场景;(2)耀龙S8000 G2超节点(32/64x GPU),业界首创3DMesh互联技术,实现64张曦云C550通用GPU高速互联的超节点,通信性能提升4倍,支持DeepSeek、Qwen、Kimi-K2、阶跃Step3等主流大模型全场景应用;(3)Shanghai Cube国产高密度液冷整机柜(128xGPU),采用47U单机柜4组超节点(1组超节点32xGPU、单机柜128xGPU)高密度液冷部署,8机柜并排组成千卡集群,算力密度与能效比达到行业领先水平;(4)高密度液冷算力POD,采用创新技术架构,与沐曦算力集群深度适配,可高效支撑AI训练、推理及通用计算等多样化场景,为高性能算力需求提供稳定、高效、灵活扩展的实时保障。


6、曦智科技发布国内首个光互连光交换GPU超节点
曦智科技在今年7月世界人工智能大会(WAIC)发布了国内首个光互连光交换GPU超节点光跃LightSphereX,并联合壁仞科技、中兴通讯首次进行示范应用,即将于上海仪电国产超节点算力集群落地。

05
产业链影响
1、服务器:产业链分工细化
机柜/超节点趋势下,AI芯片厂商纵向整合,提升自身通信、存储、软件等能力是确定趋势。芯片巨头在强化自己在算力网络中的布局。英伟达、AMD、国内海光信息吸收合并中科曙光,均在动作。
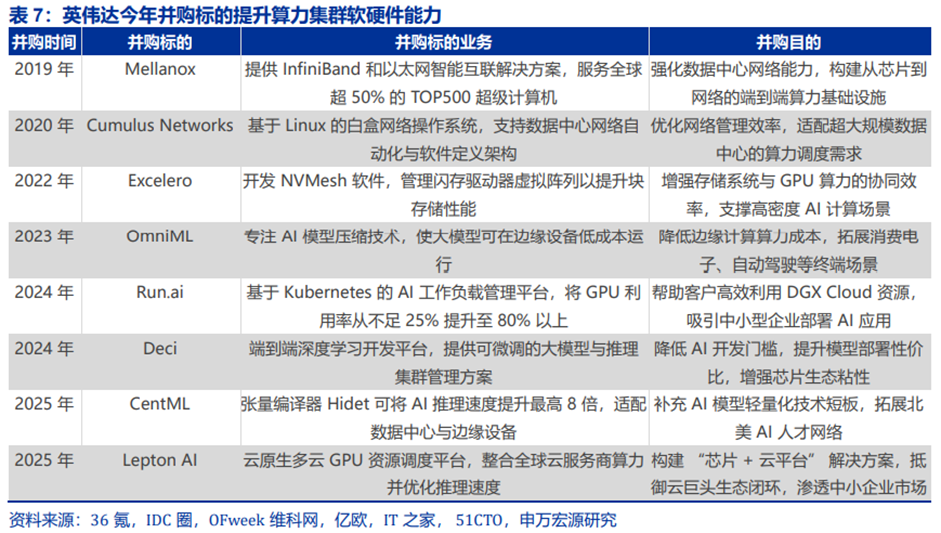
全球龙头英伟达近6年并购案例8宗,聚焦于算力全链条整合。通过收购网络技术(Mellanox)、软件定义网络(Cumulus)、行业应用(Parabricks)、云服务(LeptonAI)及AI开发工具(Run.ai、Deci),构建从芯片到应用的闭环生态,应对云巨头竞争并渗透新兴市场。
AMD并购频繁,并在AMD Advancing AI2025大会上推出全新AI产品阵容——旗舰数据中心AI芯片、AI软件栈、AI机架级基础设施、AI网卡与DPU。25年AMD收购硅光芯片初创公司Enosemi、AI软件Brium、AI推理芯片Untether AI三家公司,24年收购Silo AI(欧洲最大私人AI实验室,开发多语言大模型及企业级AI解决方案)和ZT Systems(定制化服务器、液冷机架及云原生解决方案),补足了AMD的全栈能力。
国内海光信息拟吸收合并中科曙光,也印证了这一产业趋势。产业协同角度。海光信息主要收入来源为CPU DCU,中科曙光主要收入来源为服务器 云基础设施。合并完成后,海光 曙光,完成从芯到云,硬件全产业链部署,协同效应明显。
服务器厂商生存空间是否受到挤压?首先,能够认为AI芯片厂商不会切入代工业务。AMD收购ZT System后剥离了其代工业务,避免与OEM/ODM的竞争,海光收购曙光目的也是为了强化协同,提升液冷、软件等能力。
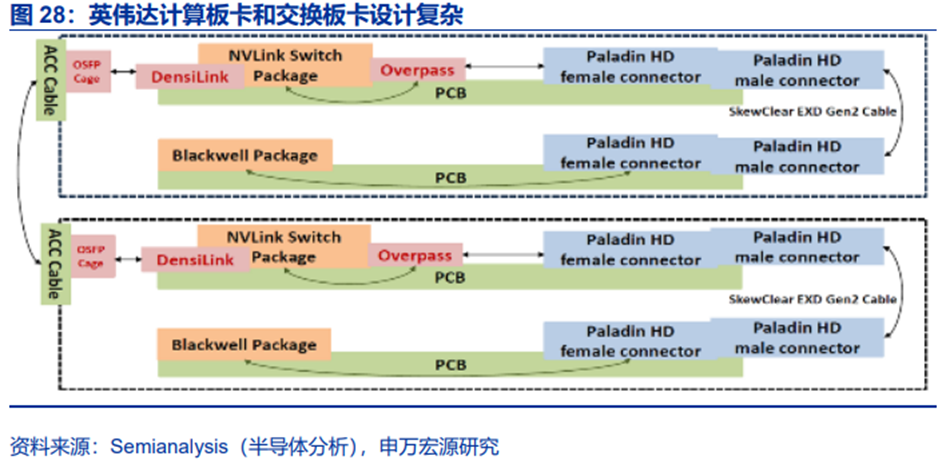
但是,算力链条的产业链分工可能会进一步细化。在超节点趋势下,AI芯片之间、AI芯片与交换机芯片之间的互联,大都需要通过板卡(尤其是电信号互联)。以英伟达为例,其板卡在产品推出初期自行设计,产品稳定后会开放给OEM合作伙伴,此时板卡设计的能力就成为了能否获取更多价值量的核心差异化能力。因此代工产业链分工可能进一步分化为板卡设计代工供应商、以及机柜代工供应商。对英伟达来说,其板卡、模组代工供应商主要为鸿海精密(中国台湾地区)、纬创,机柜代工商为广达等,已经体现出分工细化趋势,后续国内代工产业链或也将出现该趋势。
此时,代工厂商竞争的核心要素将从资金、供应链能力拓展到:1)是否具备板卡设计能力;2)能够与下游客户,如CSP厂商紧密协同。
相关标的:海光信息、中科曙光、浪潮信息、紫光股份、神州数码、联想集团、华勤技术。
2、光通信:国产超节点方案带来光模块增量
超节点目前分化为单柜更多GPU的单柜高密高电、多机柜多GPU两大路径。以CloudMatrix方案为代表的国产化方案预计将强调通过多机柜路径增强Scale Up网络,弥补单卡性能短板。预计产业链影响是增加400G或LPO等成本优化方案的采购,同时加速向800G演进。
光通信需求测算:
Scale Up维度——节点内12个Compute机柜,共48台服务器,48x8=384 NPU;中间4个网络机柜,负责384张卡的内部互联(Scale Up),类比为英伟达的NVLink网络。两层UB平面的Scale Up网络拓扑如下。
第一层:每个NPU由2个die组成、每个die提供7个224Gb通道连接至UB网络的第一层(在8NPU服务器内),因此每个NPU到第一层UB网络7x224Gbpsx2=392GBps(注意Gb到GB的换算)。这一层为电气信号连接。
第二层:在第一层的每个8NPU服务器内,均在板卡层面配置了7个UB Switch芯片,每个Switch芯片扇出16个连接,每个连接28GBps(对应224Gbps)连接至第二层网络。第二层网络由112个UB Switch芯片组成,分成7个平面组(Sub-plane、每组16个芯片,这16个芯片中的每一个都以无阻塞的拓扑网络连接上述第一层芯片的16个扇出连接,7个平面组在数量和拓扑上对应了第一层每个服务器内的7个Switch芯片。同时,第二层的UB Switch芯片中的每一个都提供了48个28GBps连接(对应224Gbps),在数量和拓扑上对应了第一层的48台服务器。
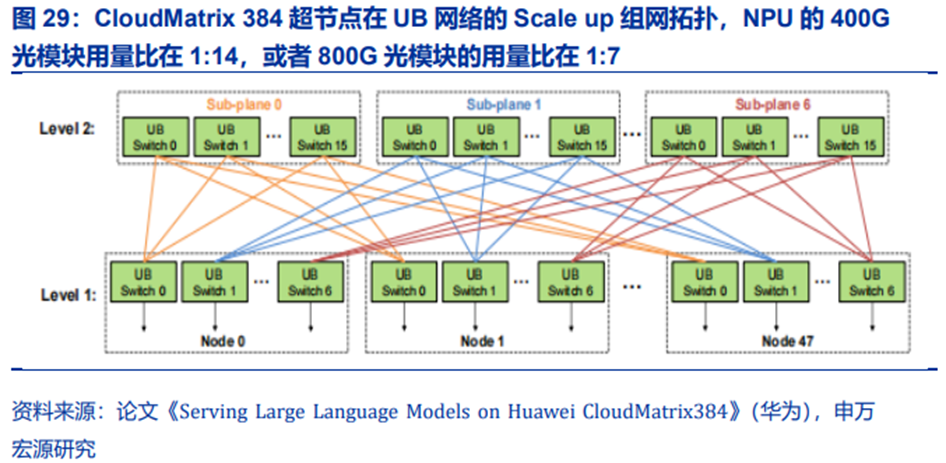
综上,在第一层和第二层网络之间,每台服务器中的每个UB Switch芯片都对应了对外16x28GBps=448GBps=8x448Gbps(注意Gb到GB的换算),也就是每台服务器中的每个UB Switch芯片都对应了8个400G连接(光模块),每台服务器总共需要使用56个400G光模块或28个800G双通道光模块,无阻塞网络的第二层交换机侧需要同样数量的模块,也就是说在UB网络系统中,每台服务器的8个NPU对应了112个400G光模块或56个800G双通道光模块。即NPU的400G光模块用量比在1:14,或者800G光模块的用量比在1:7。
Scale Out维度——12个Compute机柜为一个CloudMatrix节点,在此基础上复制扩容;假设8个节点,共8x384=3072GPU,按照胖树架构扩容,两层拓扑结构,Leaf网络8个交换节点。若继续扩容,总节点为8的倍数,需要增加Spine层网络。(假设:两层网络之间的连接数相等,不收敛)按照2层胖树架构推演,光模块需求比约在1:4。
整体光通信的需求测算,是上述Scale Up和Scale Out两个维度数量的叠加,总光模块的需求比最高可达1:18。
相关标的:1)光通信:华工科技、光迅科技、中际旭创、新易盛等;2)网络设备与芯片:盛科通信、紫光股份、锐捷网络等。
3、铜连接:高速背板连接、铜连接仍为重要选择
华为2025年3月论文解释了最新的UB-Mesh网络架构,具备流量模式驱动的网络拓扑、拓扑感知的计算与通信、容错自修复系统等特性。UB-Mesh的重要特性包括:降低成本并增强可靠性,一定程度上减少对高带宽交换机和光互连的依赖,更多使用短距离直接互连(机架内64个NPUs通过电气电缆直接互连);能高效支持复杂通信操作,如All-to-All通信(也是MoE架构的重要通信操作);显著减少传输距离和开销,多数传输可在2跳内完成。
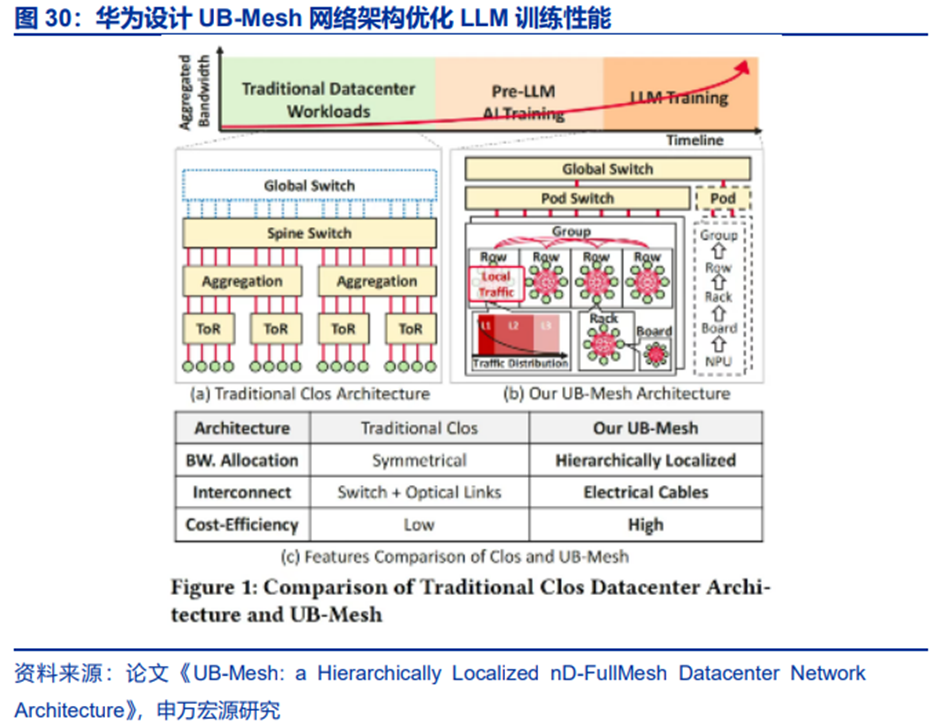

更长时间维度看,光通信也是Scale Up网络需求的演进方向。铜连接的范围一方面取决于工艺(速率和距离),另一方面则是工程问题,例如算力最小颗粒度的灵活性(匹配不同场景)、热管理(液冷)和供电难度(例如TeslaDojo)、维护难度,甚至IDC层面的载重等。
光电混合是当前出于成本考虑的重要架构,光网络和芯片层面的光互联是长期方向,包括硅光、CPO以及OpticalI/O为代表的光学技术。chiptochip(芯片间的光学IO)、boardtoboard(板卡间的光学模组)、machinetomachine(光模块/CPO)三大重要场景预计都有硅光技术的重要渗透,其中前两者是超节点Scale Up的重要场景。

4、IDC产业链:AIDC需求增加,液冷渗透提升
若对比GBNVL72单机柜性能,CloudMatrix是16机柜方案;可比性能下,CloudMatrix的占地面积与机柜数增加,预计增加AIDC需求,前提是电力资源充足,因此,预计将显著增加IDC机房环节、电源设备环节的需求。若要进一步节省占地面积、减少机柜数、减小组网开销,同时符合资源政策,那么液冷是必要选项。
因此可进一步推断,液冷 增加内部铜连接、中长距光网络是两条重要路径。
相关标的:润泽科技、奥飞数据、光环新网、英维克、科华数据、科泰电源等。
06
相关公司
1、华勤技术:国产超节点提速,数据业务弹性有望超预期
国内超节点进展超预期,预计2025-2028年国内超节点渗透率分别为5%、19%、45%、72%。Scale Up交换网络作为核心增量环节,有望显著增厚交换机市场规模,2028年国内Scale Up交换机市场规模预计达669亿元,是2024年的1.67倍。同时,AI RACK ODM厂商竞争格局有望集中化,头部厂商凭借核心技术优势,盈利能力将得到提升。
构建全栈式AI数据产品组合,客户和产品矩阵优势储备。公司自2017年开始布局数据中心领域,覆盖训练、推理、网络交换、网络节点、存储、通用计算等全栈产品。一方面公司提供差异化、极具市场竞争力的定制产品,另一方面打造面向全行业市场的标品,服务于更多客户及行业合作伙伴,满足不同客户的应用需求。
公司打造的算力矩阵已构建起开放兼容的生态系统。公司产品不仅全面适配NVIDIA、AMD、Intel等国际巨头GPU,更深度兼容各主流国产GPU芯片,形成"双循环"技术布局。以8UOAM、4U8卡、2U2卡为代表的训练、推理全栈AI服务器,既满足超大规模训练需求,也能为中小企业应用场景提供灵活支持。同时,依托公司在交换机领域的深度技术积累,以太网51.2TAI交换机可用于GPU之间的互联。
头部客户全面覆盖。公司以客户为中心,提供从芯片到整机到算力的全栈、全领域产品和服务,目前与国内腾讯、阿里、字节等多个知名的云厂商建立了密切的合作关系,并成为其核心供应商,2024年公司在头部客户实现全栈合围。
营收规模有望保持快速增长。近年来,公司加强客户粘性,不断推出新产品,业务呈现高速发展,2024年公司数据业务营收已突破200亿元,25Q1营收突破100亿元。后续公司有望凭借其全栈产品能力、兼容生态系统以及深厚制造加工经验等优势,在头部客户份额有望持续提升,带动公司业绩保持高速增长。
交换机 RACK ODM,超节点业绩弹性有望超预期。公司核心互联网公司交换机份额有望提升。目前交换机供应商主要包括华为、新华三、锐捷网络、中兴通讯、华勤技术等。公司凭借其出色的供应链管理能力和开放的生态系统,积极为客户提供支持,未来市场份额有望进一步提升。
公司前瞻布局多款AIRACK解决方案。在ODCC网络工作组的指导下,公司牵头设计符合ETH-X超节点架构(腾讯主推)的整机柜服务器,打造了一款集高密度、绿色、智能于一体的三总线架构液冷整机柜系统。
公司AI RACK针对不同国产GPU特性,设计两款通用型计算节点,支持多种系统互联方式,充分发挥在网络交换方面的技术积累优势,交换节点采用5nm交换芯片,可支持51.2T超算级带宽,专为万卡AI训练集群设计,可实现低时延高带宽AI智算网络。对外支持32个800G OSFP端口,向下兼容400G/200G/100G,同时支持铜缆DAC、AEC和光模块互联,可支持跨柜Scale Up模型搭建。背板Cable Tray互联设计,差分对数量最大达到6144对,通过搭配不同的Cable tray,即可实现单柜最高64pcsGPU的互联。
公司发布2025年半年报,25H1公司实现营收839.39亿元,同比 113.06%;实现归母净利润18.89亿元,同比 46.30%;实现扣非净利润15.09亿元,同比 47.95%。其中单季度Q2实现营收489.42亿元,同比 111.24%,环比 39.84%;实现归母净利润10.47亿元,同比 52.70%,环比 24.35%;实现扣非净利润7.49亿元,同比 52.70%,环比-1.59%。
2、中兴通讯:服务器存储增长超200%,自研芯片卡位超节点互联
强化“All in AI,AI for All战略,中兴微电子未来可期。公司自1996年开始芯片研发,已具备业界领先的芯片全流程设计能力,目前主要由中兴微电子主导芯片领域研发设计。计算芯片方面,公司自研定海芯片,支持RDMA标卡、智能网卡、DPU卡等多种形态,并可提供高性能、多样化的算力加速硬件。交换芯片方面,公司打造国产超高密度230.4T框式交换机,以及全系列51.2T/12.8T盒式交换机,性能业界领先,并在运营商、互联网、金融等市场的百/千/万卡智算集群规模商用。AI服务器方面,公司可提供高性能训练服务器、高性价比推理服务器、开箱即用智算一体机(包括:训推一体机、推理一体机、应用一体机)、全系列通算服务器等,并携手产业伙伴打造新互联超节点智算服务器。数据中心方面,公司推出第三代模块化间接蒸发冷却空调、全系列液冷等创新产品和方案,已部署30多万个机架。此外,公司还推出AI Booster智算训推软件平台,为客户提供一站式AI解决方案。
AI算力产品实现头部互联网突破,打造智算超节点系统。公司服务器及存储营收同比增长超200%,其中AI服务器营收占比55%。公司服务器、交换机及存储等算力业务获运营商、互联网、政企等客户认可。运营商领域,公司通算服务器在国内运营商份额领先,智算服务器陆续中标国产智算资源池项目。数据中心交换机,公司以综合排名第一中标中国移动数据中心交换机集采项目。数据中心配套,公司在京津冀节点、和林格尔节点、中卫节点等东数西算核心区域实现较大规模数据中心项目落地。互联网领域,公司在国内头部互联网公司智算需求方面取得突破性进展,实现规模销售,同时,在大型银行及保险公司保持规模经营,并在政务、企业市场实现多个重点项目突破。此外,中兴通讯智算超节点系统以自研AI大容量交换芯片为基石,可有效支持万亿参数以上大模型训练及高并发推理,初步建成国产化智算产业开放生态系统。
2025年8月28日,中兴通讯发布2025年半年度报告,公司实现营业收入715.53亿元,同比增长14.51%;归母净利润50.58亿元,同比下降11.77%;扣非归母净利润41.04亿元,同比下降17.32%。
3、中际旭创:光模块龙头业绩高增
公司主营业务为高端光通信收发模块的研发、生产及销售,产品服务于云计算数据中心、数据通信、5G无线网络、电信传输和固网接入等领域的国内外客户。公司注重技术研发,并推动产品向高速率、小型化、低功耗、低成本方向发展,为云数据中心客户提供100G、200G、400G、800G和1.6T的高速光模块,为电信设备商客户提供5G前传、中传和回传光模块,应用于城域网、骨干网和核心网传输光模块以及应用于固网FTTX光纤接入的光器件等高端整体解决方案,在行业内保持了出货量和市场份额的领先优势。根据LightCounting发布的2024年度光模块厂商排名,中际旭创位列全球第一。
公司发布2025年半年度报告,25H1实现营业收入147.9亿元,同比 37.0%;归母净利润40.0亿元,同比 69.4%;扣非净利润39.8亿元,同比 70.4%。25Q2实现营收81.1亿元,同比 36.2%,环比 21.6%;归母净利润24.1亿元,同比 78.8%,环比 52.4%。
800G需求强劲 1.6T规模起量,营收业绩环比加速攀升。25Q2公司营收增长势头强劲,同比 36.2%,环比 21.6%,主要受益于800G等高端光模块需求爆发式增长。分业务看,子公司业绩亮眼:25H1泰国工厂子公司TeraHop营收113.3亿元,同比 197%,占营收比例达77%,净利率6.5%,同比 0.5pct;硅光芯片子公司苏州湃矽营收3.5亿元,同比 148%,净利率15.2%。公司部分产品采用自研硅光芯片,降低外部依赖,有力支撑高端产品放量和成本优化。
800G放量 硅光渗透,毛利率大幅提升。公司25Q2毛利率达41.5%,同比 8.1pct,环比 4.8pct,主要得益于公司:1)800G等高端产品出货比重增加,以及硅光方案加速渗透;2)持续降本增效,在良率优化、物料方案改进、供应链管理上多点发力。公司1.6T产品已于25Q2开始逐步出货,预计三、四季度规模放量,且目前1.6T出货以硅光为主,毛利率有望进一步提升。公司25Q2销售/管理/研发/财务费用率0.6%/1.8%/3.6%/-0.3%,同比-0.1pct/-1.2pct/-0.8pct/ 0.4pct,环比-0.1pct/-0.5pct/-0.7pct/持平,规模效应持续体现。25Q2,公司盈利能力显著增强,归母净利率29.7%,同比 7.1pct,环比 6.0pct。
经营性现金流表现强劲,首推中期分红彰显信心。公司经营现金流充裕,25H1经营活动产生的现金流量净额达32.18亿元,同比大幅增长232.5%,为公司应对上游物料紧张、积极备货提供了坚实基础。公司首次推出半年度利润分配预案,拟每10股派发现金红利4元(含税),并将逐步加大分红比例。
积极扩产备货,高端模块交付能力持续领先。公司凭借行业龙头地位和规模采购优势,积极锁定供应链产能;截至25H1,公司存货达91.7亿元,较年初增长30.0%,保障下半年及明年订单交付。公司同步推进“铜陵旭创高端光模块产业园三期项目”等募投项目建设,积极扩张泰国等海外产能,高端产品交付能力持续提升。
4、光迅科技:光通信模块龙头,400G 交付加速,新技术布局引领未来
公司具备领先的垂直集成技术能力,产品涵盖全系列光通信模块、无源器件、光波导集成产品、光纤放大器、广泛用于数据中心、骨干网、城域网、宽带接入网、无线通信、物联网等。公司产品可分为传输类、接入类和数据通信类产品,2024年,接入和数据类产品占营收比为61.67%,传输类产品占营收比为37.50%。
公司发布2025年半年报,上半年实现营收52.43亿元,同比增长68.6%,实现归母净利润3.72亿元,同比增长79.0%,实现扣非归母净利润3.60亿元,同比增长74.7%。25Q2单季度来看,实现营收30.21亿元,同比增长66.1%,环比增长35.9%,实现归母净利润2.22亿元,同比增长69.3%,环比增长47.9%,实现扣非归母净利润2.19亿元,同比增长63.9%,环比增长54.8%。
2025年上半年,公司面向下游云厂商的400G 高速光模块加速交付,1H25数据与接入业务实现营收37.15亿元,同比增长149.27%,占总营收比重同比提升22.9ppt至70.9%。
重视研发创新,具备领先的垂直集成技术能力、一站式的产品提供能力、大规模柔性制造能力。公司具备从芯片到器件、模块、子系统的垂直整合能力,拥有多种类型激光器芯片、探测器芯片以及SiP芯片平台,为直接调制和相干调制方案提供支持,还拥有COC、混合集成、平面光波导、微光器件、MEMS器件等封装平台,为相关产品提供支持。公司在光通信传输网、接入网和数据中心等领域构筑全方位的综合解决方案及柔性制造与高质量交付能力,产品年出货量行业前三。
持续扩充产能;积极布局硅光、OCS等新技术。根据公司公告,1H25公司持续提升海外制造及高端数通产品交付能力,顺利完成海外制造基地及武汉东湖综合保税区高端光电子器件产业基地的产能建设。公司紧跟行业技术发展趋势,前瞻布局硅光、OCS(光交换机)等新领域,在硅光方面,2024年硅光产品快速上量,目前公司硅光月产能达50万只;OCS方面,公司于OFC2024就创新推出基于独创光学设计的MEMS系列OCS产品。
5、英维克:机房与机柜温控业务增长强劲,液冷技术助力数据中心发展
机房温控业务快速增长,机柜温控业务稳健发展。2025年上半年公司机房温控和机柜温控业务同比分别增长57.9%/32.0%,收入分别达到13.5亿元/9.3亿元。机房温控:在AI算力功耗大幅提升背景下,机房温控的液冷技术加速导入。公司作为全链条液冷开创者,率先推出高可靠Coolinside全链条液冷解决方案,持续受益数据中心发展,2025年上半年公司在算力的设备及机房的液冷相关营业收入超过2亿元。机柜温控:公司是最早涉足电化学储能系统温控的厂商,在储能温控行业处于领导地位,是众多储能系统提供商重要的温控产品供应商,机柜温控行业稳步发展。分区域看,公司国内和国外业务在2025H1同比分别变动61.0%/-5.92%。公司积极拓展海外数据中心业务,不断扩大客户基础。
公司持续加大投入,研发费用率相对保持稳定。2025H1公司毛利率26.15%,同比下降4.84pct。2024年销售/管理/研发费用率分别为3.91%/4.01%/7.61%,同比分别下降2.9pct/0.56pct/0.76pct。受益于营收增长显著,2025年Q2销售/管理/研发费用率同比分别下降1.72pct/2.00pct/3.76pct。2025H1公司经营性现金流净额为-2.34亿元,同比下降412.33%,主要系上半年销售规模增大及期末备货增加,从而采购商品、接受劳务的现金支付增加所致。
公司持续深耕设备散热与环境控制领域全链条产品,并拥有头部客户资源。公司拥有英伟达、字节、腾讯、阿里、运营商、华为、比亚迪等大客户资源。特别是液冷AI算力领域,公司的UQD产品已进入英伟达MGX生态系统合作伙伴,公司将继续巩固其在数据中心的既有技术创新和品牌优势,扩大销售规模,发挥液冷“全链条”平台优势。同时,公司积极拓展海外市场,在液冷领域加大海外合作与推广力度。
6、科华数据:HVDC与液冷业务加速增长
公司在AIDC供电相关领域储备早、产品矩阵全,其工业UPS亚洲第一,近几年,HVDC产品实现跨越,而液冷产品、海外市场正在突破中。公司在国内市场拥有强大客群,1Q25获得腾讯70%以上的HVDC订单。根据公司,其有望作为二级供应商进入阿里巴巴供应链,为其提供电力设备和液冷产品。此外,科华还积极进军海外供应链。公司旨在通过OEM模式与海外集成商合作打入海外超大规模云厂商供应链。管理层表示,到2025年底公司海外业务更新的可见度有望提升。若取得成功,可能意味着科华的市场规模扩大。尽管是后来者,公司也在积极拓展液冷业务。公司已向中国移动交付液冷产品。管理层称公司且近期已被添加到阿里巴巴白名单中,这可以证明其竞争力。HVDC和液冷的盈利贡献有望自2H26起加速。
07
参考研报
1.申万宏源-计算机行业ASIC系列研究之四:国产ASIC,PD分离和超节点
2.申万宏源-计算机行业GenAI系列深度之61:超节点,从单卡突破到集群重构
3.国海证券-计算机行业AI算力“卖水人”系列(8):昇腾AI,引领“超节点 集群”时代
4.国海证券-计算机行业专题研究:计算需求演进,超节点成为AI基础设施共识
5.申万宏源-计算机行业周报:摩尔线程IPO上会!阿里推出全新超节点、基础大模型!
6.国信证券-通信行业周报2025年第39周:阿里发布128超节点AI服务器,英伟达拟向OpenAI投千亿美元
7.浙商证券-华勤技术-603296-推荐报告:国产超节点提速,数据业务弹性有望超预期
8.中泰证券-中兴通讯-000063-服务器存储增长超200%,自研芯片卡位超节点互联
9.中原证券-通信行业中期策略:AI算力升级,价值成长主导
10.国元证券-技术硬件与设备行业:网络系列报告之CPO概览,光电协同,算力革新
11.国信证券-英维克-002837-2025H1营收同比 50%,积极建设海外资源平台
12.瑞银证券-科华数据-002335-科华电话会要点:HVDC、液冷和电池储能系统有望推动强劲增长

 VIP复盘网
VIP复盘网
