

3月31日晚,智谱发布上市后首份年报,2025年业绩表现超预期,智谱MaaS API平台实现ARR 17亿元(约2.5亿美金),同比提升60倍。2026年一季度智谱的API调用定价提升83%,即便如此,市场依然呈现出供不应求的情况,调用量增长400%。
据OpenRouter数据显示,截至3月15日,中国AI大模型的周调用量达到4.69万亿Token,连续第二周超越美国。
AI应用普及与OpenClaw框架引爆推理需求,叠加外部英伟达GPU产能受限、硬件成本上行及国产替代缺口,驱动市场进入“卖方市场”,算力租赁短期内涨价或持续。
国产算力租赁景气加速,有望量价齐升。而整个算力产业链或将进入“全链通胀”周期。

一、为什么要大力发展算力租赁
在当前大模型爆发、Token 消耗量呈指数级增长,而顶尖硬件(如英伟达高端 GPU)面临供应链与地缘政治双重挤压的背景下,国内“算力租赁”量价齐飞并非偶然的短期炒作,而是中国 AI 产业跨越技术与商业鸿沟的必然基础设施化路径。
大力发展算力租赁,本质上是为了解决 AI 时代的“水电煤”供应问题,其核心逻辑可以从供需矛盾、商业模式、底层基础设施以及国家宏观战略四个维度进来剖析:
1、 供给端:突破硬件封锁,提升稀缺算力的闲置利用率
高端 GPU 的紧缺是目前硬科技领域面临的最直接痛点。 由于外部出口管制,国内企业获取诸如 H100/B200 等先进制程 GPU 的难度和成本极高,市场上流通的多为特供版或存量卡。单张芯片的算力受限,意味着必须依靠大规模集群和高速互联网络来弥补单卡性能的不足。
而 许多非头部企业、高校或科研机构手中握有少量 GPU,但无法形成有效的大规模训练集群。算力租赁平台通过虚拟化、容器化技术,将分散的、异构的算力资源池化,大幅提升了高端 GPU 的时间复用率和整体利用率。
2、 需求端:从“重资产支出”向“轻资产运营”转移
Token 消耗的暴增和类似智谱等头部 API 价格的波动,折射出大模型公司面临的巨大成本压力。
降低 AI 创新门槛:无论是底层大模型训练,还是上层 AI 应用(Agent、行业垂直模型)的微调与推理,都需要庞大的算力支撑。如果要求每一家 AI 创业公司或传统企业都自建智算中心,高昂的资本支出将扼杀90%以上的创新。算力租赁将其转化为运营支出,企业按需付费,极大降低了试错成本。
承接爆发的“推理”需求: 随着大模型从“百模大战”的训练期进入商业化落地的应用期,算力需求正从集中的“训练算力”向海量的“推理算力”倾斜。推理算力具有明显的并发性、碎片化和潮汐效应,租赁模式天然契合这种弹性需求。
3、基础设施端:“算电协同”与产业链重塑
算力不仅仅是芯片,它是一个融合了半导体、网络架构和能源管理的超级系统工程。
能源成本的终极博弈: 智算中心是名副其实的“电老虎”。大力发展算力租赁,可以将算力中心布局在能源丰富、电价低廉的区域。通过统一的调度平台,实现“算电协同”。例如,利用西部丰富的风光绿电甚至未来的新型清洁能源进行高耗能的非实时训练任务,从而在底层逻辑上压低中国 AI 产业的整体能耗成本。
带动国产半导体生态: 算力租赁平台作为“包工头”,在采购英伟达设备受阻时,更有动力和容错率去批量采购和适配国产 AI 芯片及底层异构架构(如基于 RISC-V 架构的 AI 加速方案)。这为国产 GPU/NPU 提供了一块巨大的“练兵场”,加速了软硬件生态(CUDA 替代方案)的成熟。
4、宏观战略端:十五五规划下的“数字底座”
在十五五规划纲要中,算力网络已经被提升到了与高铁、特高压电网同等重要的国家战略基础设施地位。
全国一体化算力网: 算力租赁是“东数西算”工程商业化落地的最佳载体。通过统一的算力调度和交易市场,打破地域和企业壁垒,让算力像水网、电网一样全网自由流转。
数字经济的乘数效应: 无论是工业制造、航空航天(如卫星数据的实时处理、3D打印的复杂拓扑优化),还是金融市场的量化分析,千行百业的数字化转型都需要算力支撑。普惠的租赁算力是推动宏观经济向高质量、智能化转型的基础底座。
算力租赁,Computing Power Leasing),是指企业或个人无需自行购买昂贵的服务器硬件(如 GPU、NPU 等)和建设数据中心,而是通过云计算服务商或专业的算力调度平台,以按需付费(按时、按月或按算力量)的方式,租用计算资源来完成 AI 训练、推理、科学计算等任务的服务模式。
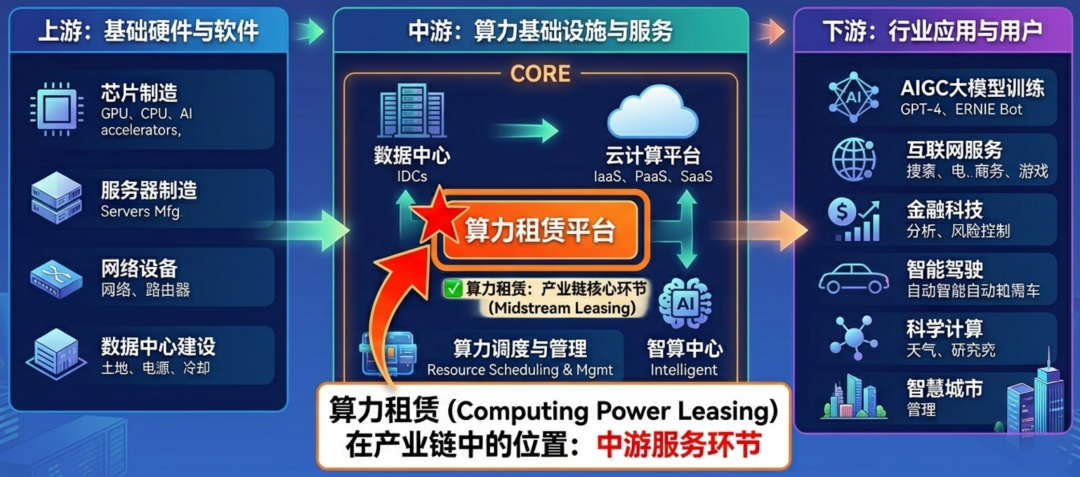
算力租赁属于算力服务的环节,位于整个算力产业的中游,如下图:
2、特点
(1)轻资产,降成本:无需一次性大额投入采购高端芯片(如英伟达 H100/B200 或国产昇腾 910B)等硬件、搭建机房,运维、升级等费用,按需付费即可使用算力,同时规避芯片快速迭代的贬值风险,大幅降低算力使用门槛。
(2)弹性灵活,高利用率:租户可以根据项目周期(如集中训练大模型的 3 个月);而且支持分钟级扩缩容,完美适配算力需求的潮汐波动,算力利用率远高于自建模式,避免资源闲置浪费。
(3)即开即用,免运维:预制 TensorFlow/PyTorch 等主流 AI 框架环境,一键部署训练 / 推理任务,算力获取周期从自建的 3-6 个月缩短至分钟级。而且开箱即用,服务商提供专业运维与合规保障,企业无需投入精力维护底层设施,可聚焦核心业务。
3、分类
按算力类型,主要分为三类:
(1)通用算力(CPU 驱动): 用于日常网站运行、数据库处理等,技术成熟。
(2)超级算力(HPC): 面向高精尖科研,如气象预测、航空航天模拟。
(3)智能算力(智算,GPU/NPU 驱动): 这是目前算力租赁市场的核心绝对主力,专门用于 AI 大模型训练、AIGC 生成、自动驾驶等大规模并行计算任务。
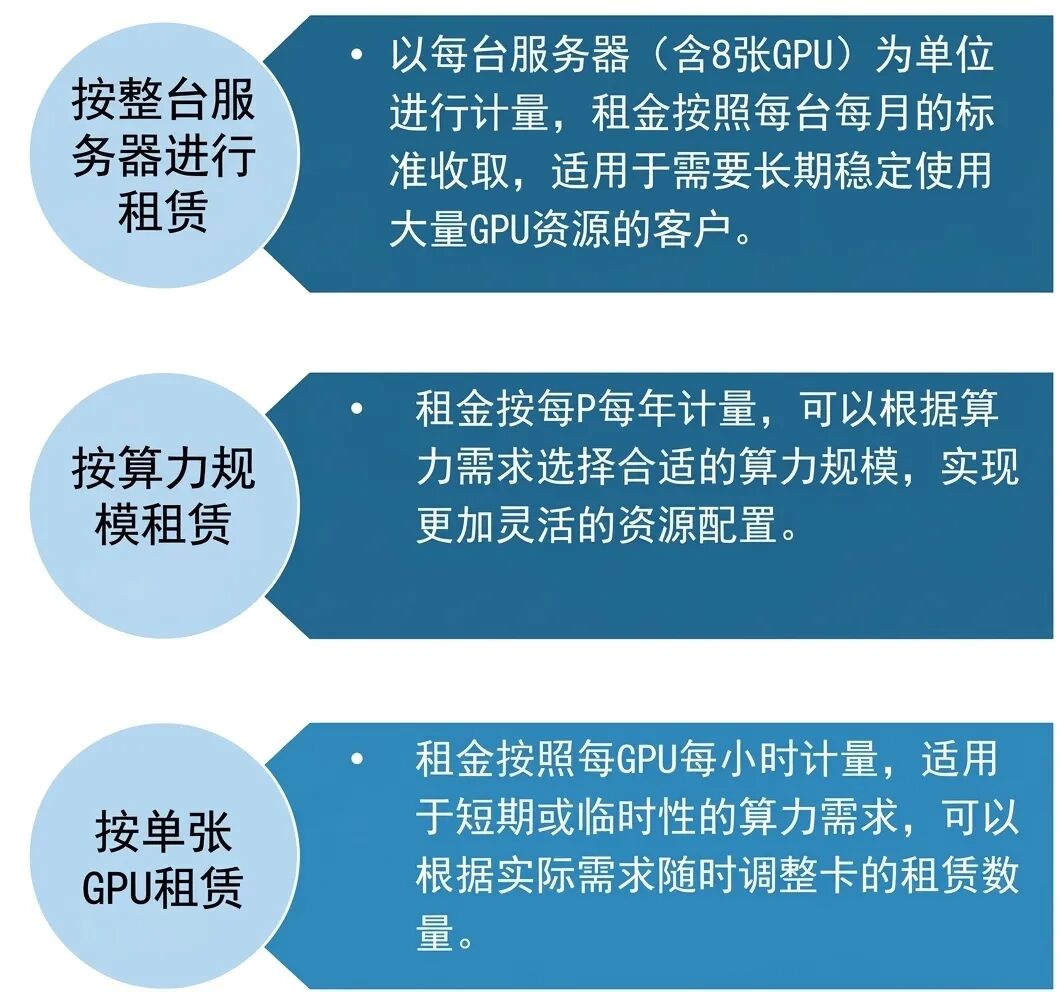
4、算力租赁的商业模式
目前市场上主要跑通了以下几种商业模式:
(1)按整台服务器进行租赁:
以每台服务器(含8张GPU)为单位进行计量,租金按照每台每月的标准收取,适用于需要长期稳定使用大量GPU资源的客户。
也可理解为IaaS(基础设施即服务)裸金属租赁。如大模型初创公司最喜欢这种模式,因为他们需要自己掌控底层的分布式训练框架和网络拓扑。
(2)按算力规模租赁:
租金按每P每年计量,可以根据算力需求选择合适的算力规模,而非按固定设备或时间单位收费,实现更加灵活的资源配置。
通常以“Peta FLOPS(P)”为计量单位,1P相当于每秒1000万亿次浮点运算(10^15 FLOPS)。例如,用户若需要5P的算力,则按5P/年的标准支付租金。
(3)按租用GPU付费租赁:
租金按照每GPU每小时计量,适用于短期或临时性的算力需求,可以根据实际需求随时调整卡的租赁数量,如AI模型训练调试、短期数据计算、临时渲染任务等。
5、算力租赁和云服务的区别
云租赁(云计算)= 通用共享、虚拟化、弹性便宜;适用于做网站、电商、办公系统、轻量AI开发等行业。
算力租赁 = 专属物理GPU、高性能、AI/大模型专用;适用于做大模型训练、自动驾驶、科研超算、高清渲染等行业。
| 核心定位 | ||
| 主要硬件 | ||
| 资源模式 | ||
| 性能损耗 | ||
| 典型场景 | ||
| 计费方式 | ||
| 成本特点 | 可以根据实际使用情况进行计费,有效降低成本 | 成本相对较高,需要支付固定的套餐费用 |
| 运维难度 |
三、市场空间&主要玩家
1、全球市场空间
2、国内市场空间
根据华经产业研究数据,算力租赁市场平均单位算力价格为1.7万元/PFLOPS/月(即20.4万元/PFLOPS/年),2024年我国智能算力规模为725.3EFLOPS,市场规模约为1479.6亿元;2025年我国智能算力规模将达到1037.3EFLOPS,市场规模将增长至2116.1亿元,2026年有望突破2600亿元,年复合增长率约50%。
3、 国内外主要玩家
(1)国际玩家:
公有云巨头: AWS、微软 Azure、Google Cloud、英伟达DGXCloud、甲骨文Oracle Cloud。
新兴算力“新贵”: CoreWeave(英伟达扶持的 GPU 租赁黑马)、Lambda Labs。
(2)国内玩家:
第一梯队:互联网云巨头&三大运营商: 阿里云、腾讯云、华为云、火山引擎、百度智能云; 三大运营商为中国电信(天翼云)、中国移动、中国联通等。
这类企业自带生态和极强的底层技术,依托自有数据中心和网络带宽优势主导市场,占据70%的市场份额。
第二梯队:为万国数据、世纪互联、鸿博股份、中贝通信、真视通、润建股份、首都等第三方独立算力租赁商和IDC服务商及浪潮信息、中科曙光等设备商。
这类企业通过敏锐的嗅觉,提前囤积 GPU 或与国产芯片厂商合作,切入算力租赁赛道。
第三梯队:其他企业,如AI软件公司商汤科技,吉利汽车、长城汽车等车厂的AI算力用户向上游扩张。
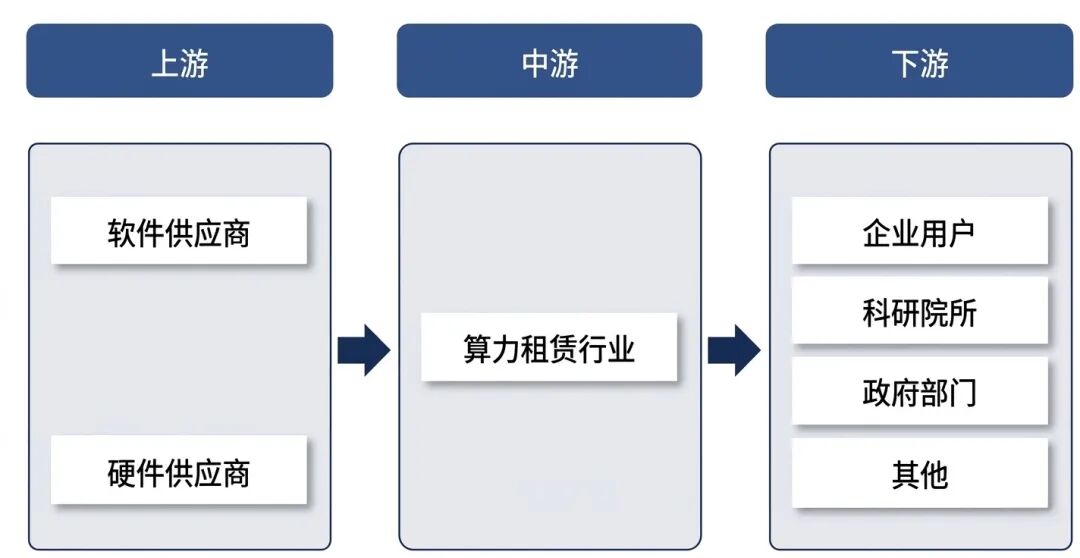
四、产业链
算力租赁产业链主要包括:上游软件、硬件基础设施;中游云厂商和算力租赁服务商;下游为具体的行业应用与客户。
1、上游:软硬件基础设施
(1) 硬件供应--物理底座
1) 算力芯片:
包含主机处理器CPU、AI专用并行计算芯片GPU、NPU、ASIC等,是算力的绝对核心,大规模矩阵运算引擎;
这是算力产业链中价值量最高、技术壁垒最深的环节,直接决定了集群的算力上限。
2)网络互联:
在万卡甚至十万卡级别的算力集群中,单卡算力再强,如果网络存在木桶效应,整体算力也会大打折扣。网络互联包含以下:
① 高速光模块:计算节点间的海量数据互连极大地拉动了800G乃至1.6T等超高速率光模块的需求,用于实现光电信号的高效转换。
② 高性能交换机:专为超低延迟和无损网络设计。主要依托特定的高速互联协议(如专用的高带宽协议或基于无损以太网的RoCE协议),构建无阻塞的胖树(Fat-Tree)等网络拓扑架构。
③ 数据处理器/智能网卡(DPU/SmartNIC): 负责将网络数据包处理、存储加速和安全隔离等任务从CPU中卸载下来,释放CPU算力,从而加速整个数据中心的数据流动。
3)整机系统与基础设施--物理躯干
包含AI服务器整机(多组件高密集成)、先进散热系统(冷板或浸没式液冷,解决超高功耗问题)及电源管理(不间断电源UPS,保障瞬时高负载下的稳定供电)。
(2) 软件供应--算力的神经与调度系统
硬件决定了算力的“理论上限”,而软件生态、虚拟化切分与调度能力则决定了算力租赁厂商能否将资源最大化变现,并决定了算力的“实际下限”。
1) 底层架构与通信: 包含并行计算平台(调用底层物理算力的核心接口)和分布式通信库(保障多卡、多机之间的数据同步效率)。
2)虚拟化与容器: 包含算力虚拟化(将物理资源切分为多个安全隔离的虚拟实例)和容器编排引擎(实现计算环境的秒级部署与弹性扩缩容)。
3) 集群调度与运维: 包含智能调度系统(最优化分配算力与网络,拉升集群综合利用率)、故障容错机制(大模型断点续训与故障节点自动迁移)及云管平台(实现多租户计费、权限分配与全局监控)。
4)高性能存储与网络: 包含并行文件系统(支持成百上千节点并发极速读取训练数据)和软件定义网络(动态灵活组网,保障租户间的绝对隔离)。
2、中游:云厂商和算力租赁服务商
算力租赁的中游是云厂商(如阿里云、AWS等)和算力租赁服务商(如优刻得、首都在线等),是算力租赁市场中的两大重要主体。
其中,云厂商指提供云计算服务的企业,其核心业务是通过自有的云计算平台,将算力资源(如GPU、CPU等)以按需、弹性的方式出租给用户,通常以IaaS(基础设施即服务)、PaaS(平台即服务)等形式提供算力支持。
算力租赁服务商指专注于算力租赁业务的企业或机构,不一定是传统意义上的云厂商,可能包括IDC(互联网数据中心)运营商、算力平台提供商等,主要业务是整合算力资源(如自建或租赁的算力集群),以租赁形式提供给用户。
两大主体扮演着“调度枢纽”的角色,其核心是将高门槛的物理硬件转化为客户可按需购买的灵活服务。
3、下游:行业应用与客户
下游需求体量巨大,包括使用算力租赁服务的企业和个人,创业公司、科研院所、政府与公共部门、金融、医疗、科研等领域的企业和机构。
(1)AI公司:
1)大模型公司(如智谱、Kimi、MiniMax等),需大量算力进行模型训练、迭代和推理,通常采用“自建 租赁”混合模式,租赁需求集中在千卡-万卡集群规模。2)AI初创公司:包括具身智能、AI Agent等领域的初创企业,算力需求灵活,多为几十卡至几百卡,租赁占比高,注重成本控制和快速部署。
(2)科研机构与高校
如清华、北大、中科院等,用于科学计算、模拟仿真、算法研究等,预算有限,倾向国产芯片和算力券支持,需求以几卡至几十卡为主。
(3)传统企业
金融(风控模型、量化交易)、制造(工业互联网、数字孪生、智能质检)、中小企业(AI数字化转型)等领域的企业,,需算力支持数据分析、智能应用开发等,需求起步阶段多为几卡至几十卡,重视合规和数据安全。
(4)政府与公共部门
参与“智慧城市”、电子政务、公共安、政务大模型等项目,需算力支持公共服务、数据治理等,通常通过政府采购或政策引导获取算力租赁服务。
五、细分标的
以下为不完全列举:
1、上游标的:
(1)国产 AI 芯片龙头: 海光信息、摩尔线程、寒武纪、景嘉微、龙芯中科。
(2)服务器与代工龙头: 工业富联(AI 服务器绝对龙头)、中科曙光、浪潮信息。
2、中游标的:
(1) 跨界算力先锋:
① 鸿博股份(英博数科,较早切入英伟达算力租赁)
② 中贝通信(通信基建与算力租赁龙头)
③ 润建股份(算电协同租赁企业)。
(2)算力网络与云服务:
① 润泽科技(园区级智算中心)
② 首都在线(跨境算力租赁龙头)
③ 云赛智联(上海地区云服务&算力租赁领域的核心企业)
④ 利通电子(英伟达生态算力租赁,液冷技术出众)
⑤ 优刻得(中立第三方算力租赁领域的代表性)
⑥ 协创数据(国内算力租赁、智能存储设备制造及服务器再制造)
⑦ 网宿科技(边缘算力赛道龙头,算力租赁业务毛利率高达78.9%)。
3、下游需求方:

 VIP复盘网
VIP复盘网
