

摘要
行业观点:
AI 入口之争,大厂投资力度再增强。
1)中国 AI 全球存在感大幅提升,国内大模型迭代不断。据 AA,尽管 GPT-5.2 与 Gemini 3 Pro 仍占据塔尖,但中国国产模型已有效改变了北美单极主导的竞争格局。在全球 Top 10 阵营中,GLM-4.7、DeepSeek V3.2、 Kimi K2 Thinking 已占据 3 席;若将观测范围扩大至 Top 15,中国企业席位达 6 个,2025 年中国开源 AI 模型调用量约占全球市场的 70 %。2)推理需求激增:o1 类推理模型的出现,使推理阶段的计算量(Inference-time Compute)相对传统模型解锁了约 10 倍的潜力,算力需求已从单一的“训练驱动”转向“训练 推理双轮驱动”。3)流量入口重塑:入口不再仅限于手机,而是演变为“OS 级智能体”与“超级 APP“层面较量。2025 年 12 月 24 日,字节跳动旗下 AI 应用豆包宣布日均活跃用户数(DAU)突破 1 亿;千问 App 近期持续扩大投流,截止 12 月 10 日(公测 23天)月活已突破 3000 万,下成全球增长最快 AI 应用。豆包绕开传统接口,用“看屏幕 代操作”的方式在现有生态之上再搭一层“AI 操作系统”,AIOS 直接触碰微信、支付宝等超级 App 的商业命门,传统 App 时代的游戏规则面临挑战,微信、淘宝等超级 App 陆续封禁豆包手机权限。在此背景下,我们认为入口之争的背后是流量之争,直接指向大型互联网企业广告及电商业务的基本盘,2026 年各家在模型、AI 应用产品上的算力投入将进入白热化的锦标赛阶段。
国产卡持续突破,2026 年爆发之时。
1)智算中心持续扩容,国产替代加速:2020-2028 年中国智能算力规模预计保持 57%复合增长率。2)国产通用GPU 从“可用”向“好用”升级:国产算力芯片在工艺与架构上持续突破,在处理大模型长文本、复杂算子融合等方面的表现已显著缩小与国际巨头的差距,以中芯国际为代表的本土晶圆厂产能/利用率持续高位运行,为国产 AI 芯片的产能提供了坚实保障。3)CSP 厂商加速适配,助力国产芯片生态建设:腾讯云宣布全面适配主流国产芯片,百度、阿里等企业加速适配国产芯片,推动“芯片-模型-应用”闭环形成。
1)需求侧:①下游推理需求伴随 AI 手机等终端 AI 进入落地放量临界点确定性增强;②大模型 Scaling Law 仍然有效,模型迭代持续加速提升训练需求的确定性。2)供给侧:①国产 GPU 性能持续提升;②国内 CSP 厂商加速适配国产 GPU。上述背景下,GPU、服务器、柴发、电源、IDC、云 6 大产业环节供需两高,其中,AI 服务器整合 GPU、存储等直接影响模型效果的硬件基础;AIDC 承载算力与数据;AIDC 电源是 AIDC 的主要供电系统;柴油发电机是 AIDC 不可或缺的备用电力来源;大模型公有云本质上是算力的共享化与弹性化。
国内算力:寒武纪、东阳光、海光信息、协创数据、星环科技、神州数码、百度集团、大位科技、润建股份、华丰科技、中芯国际、华虹半导体、兆易创新、大普微、中微公司、兴森科技、中科曙光、禾盛新材、润泽科技、浪潮信息、东山精密、亿田智能、奥飞数据、云赛智联、瑞晟智能、科华数据、潍柴重机、金山云、欧陆通、杰创智能。
海外算力/存储:中际旭创、新易盛、天孚通信、源杰科技、胜宏科技、景旺电子、英维克等;闪迪、铠侠、美光、SK 海力士、中微公司、北方华创、拓荆科技、长川科技。
风险提示
行业竞争加剧的风险;技术研发进度不及预期的风险;特定行业下游资本开支周期性波动的风险。
报告正文:
01 AI 入口之争,大厂投资力度再增强
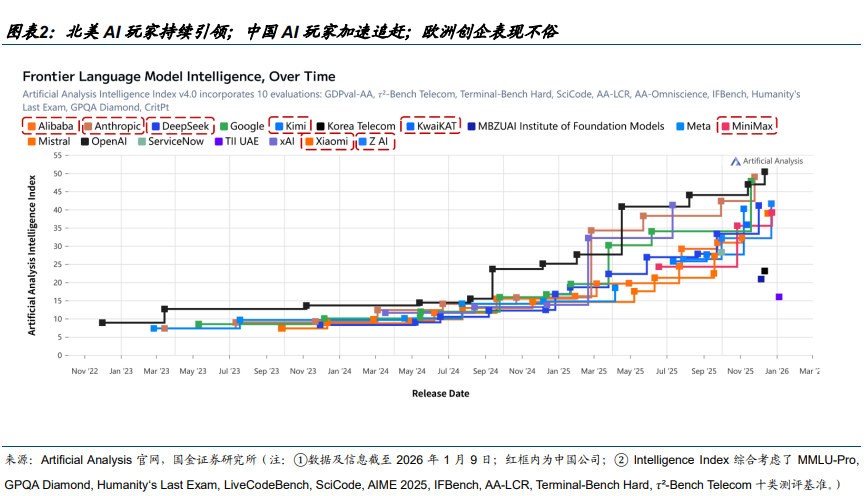
模型迭代持续精彩:中国 AI 全球存在感大幅提升,国内大模型迭代不断。
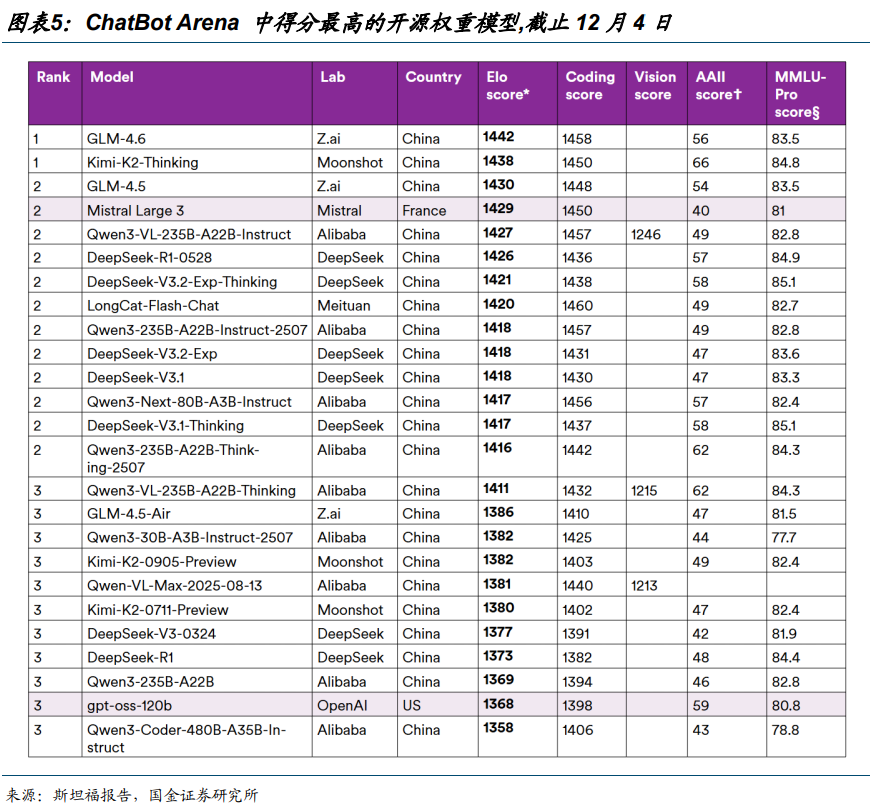
中国 AI 在全球顶级模型排名中位居中端。据 AA,尽管 GPT-5.2 与 Gemini 3 Pro 仍占据塔尖,但中国国产模型已有效改变了北美单极主导的竞争格局。在全球 Top 10 阵营中,GLM-4.7、DeepSeek V3.2、 Kimi K2 Thinking 已占据 3 席;若将观测范围扩大至 Top 15,中国企业席位达 6 个。
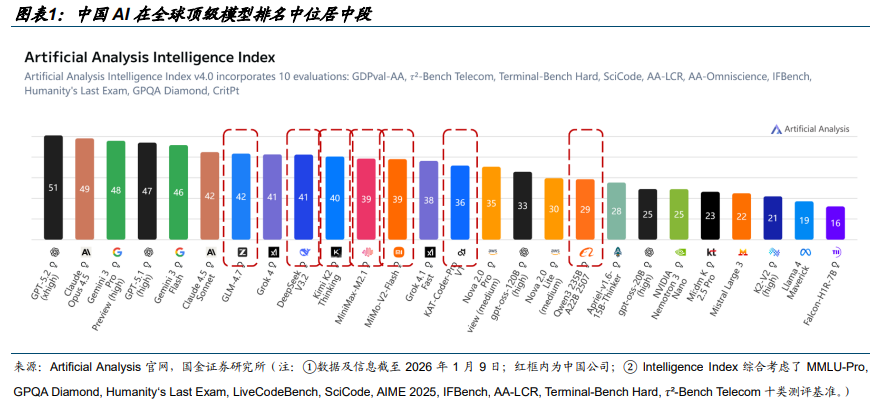
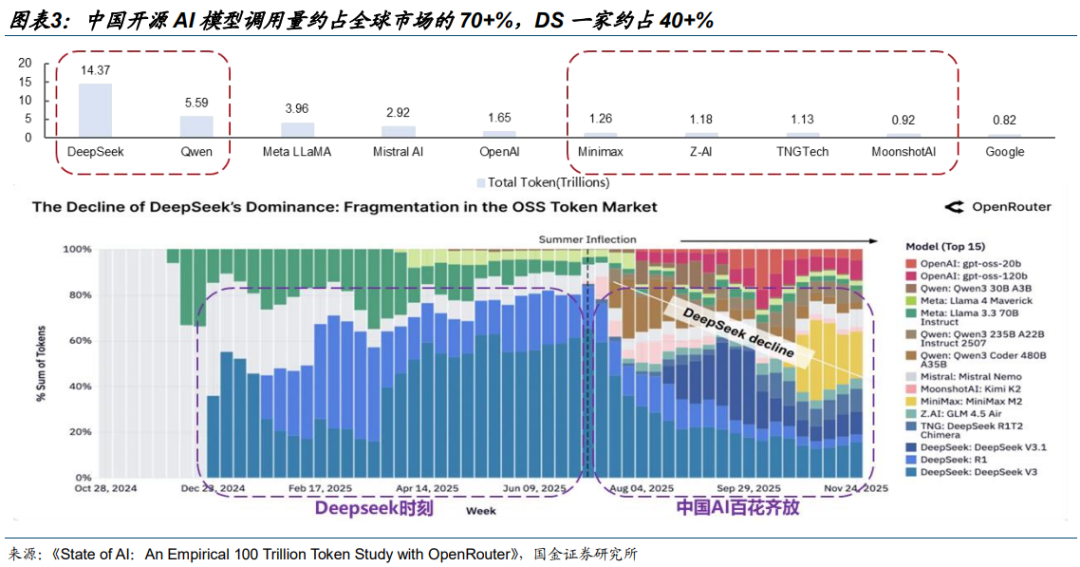
2025 年中国开源 AI 模型调用量约占全球市场的 70 %。据《State of AI:An Empirical 100 Trillion Token Study with OpenRouter》,DeepSeek 与 Qwen 分别以 14.37 万亿及5.59 万亿 Token 消耗量领跑开源市场,这一数据远超同口径下 OpenAI(1.65 万亿)与Google(0.82 万亿)的表现。去年 8 月份之后,国产开源模型厂商竞相繁荣,驱动中国厂商整体份额稳中有进,合计占据了全球超过 70%的开源份额。
DeepSeek V3.2 系列模型提出多项创新:延续使用 DSA 稀疏注意力机制、加码后训练、大规模合成数据。
DSA 全称 DeepSeek Sparse Attention,旨在降低计算复杂度,同时在上下文场景中还能保持模型性能。举个例子,当你面前有一本超厚的书(假设页数上万页),现在需要从这本书里查询特定信息,要求只能一页一页地看,且需要记忆看过的内容,这就是传统 AI 模型处理长文本时的困境——计算量随文本长度呈平方级增长。而 DSA 的作用如同将这种“大海捞针”的方式转为“精准定位”,不是每页都要看,而是能够只关注与目标信息最相关的几页,大幅提升了
模型记忆与理解效率。
此外,DeepSeek 意识到开源模型的后训练投入普遍不足,限制了模型任务表现,于是采用更激进的方式,将后训练算力预算调整到超过预训练成本的 10%。
DeepSeek 这次用到了大规模智能体数据合成,根本原因在于缺乏足够多样化的真实训练环境,无法让智能体具备任务泛化能力。从测试评估结果看,使用合成数据使模型泛化能力提升显著。
12 月 16 日斯坦福大学发布研究报告指出,在能力与采用率方面,中国的 AI 模型尤其是开放权重的大语言模型,已接近甚至部分领先于国际先进水平。
2025 年 9 月,阿里巴巴的 Qwen 模型家族超越 Llama,成为 Hugging Face 上下载量最多的 LLM 家族。2024 年 8 月至 2025 年 8 月期间,中国开源模型开发者占 Hugging Face 所有下载量的 17.1%,略超过美国开发者,后者占下载量的 15.8%。自 2025 年 1 月起,基于阿里巴巴和 DeepSeek 发布的开源模型的上传衍生模型已超过基于美国和欧洲主要模型的衍生模型。并且在 2025 年 9 月,中国微调或衍生模型占 Hugging Face 上发布的所有新微调或衍生模型的 63%。
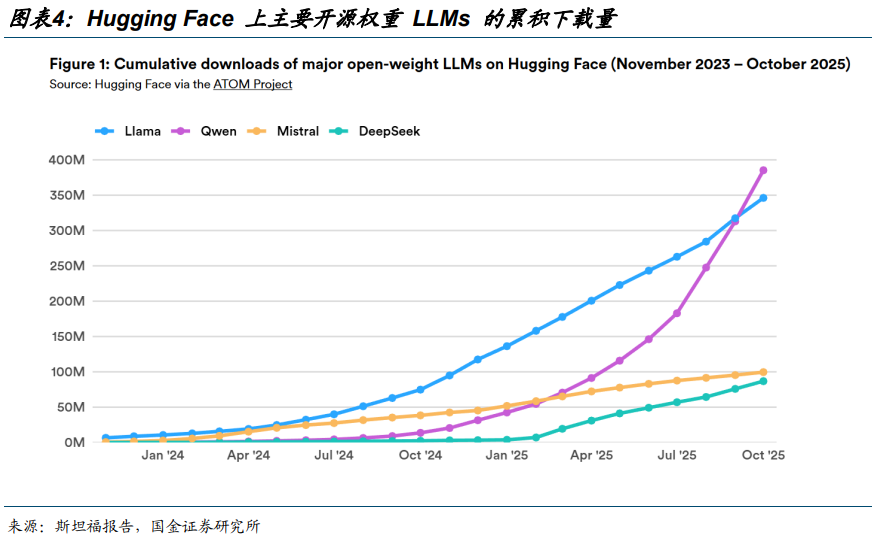
中国的开放权重模型现在在主要基准和排行榜上表现接近顶尖水平,涵盖通用推理、编码和工具使用。在 Chatbot Arena 这个著名的用户比较和评分排行榜上,中国生产了顶尖的开放权重模型,而且其中最好的模型几乎与美国公司领先的闭源模型不相上下。
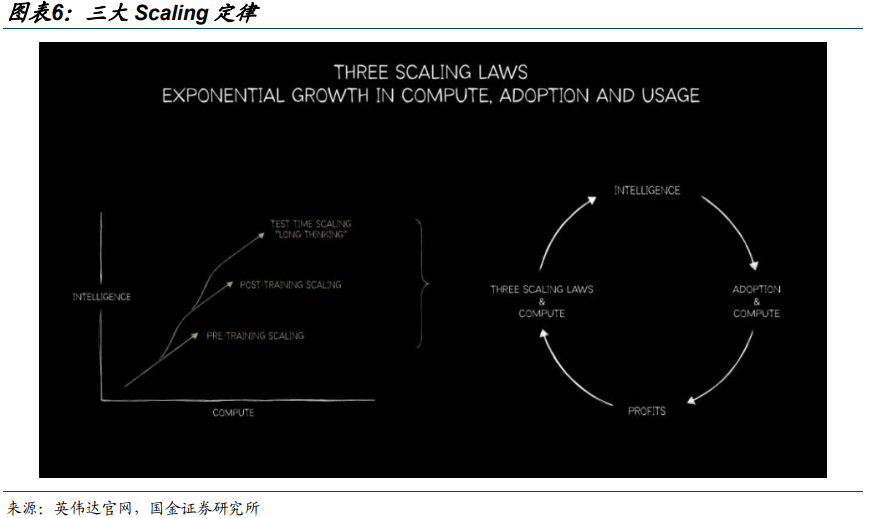
Scaling-law 仍然有效:三大 Scaling 持续演绎,DS 发布 mHC 提升训练稳定性。
大模型三大 Scaling 定律:预训练(pre-training)/后训练(post-training)/推理深度思考(test-time long thinking)。算力与应用循环促进: 算力 Scaling—>智能提升(Intelligence)—>应用的广泛采用(Adoption)—>经济效益(Profits)—>算力 Scaling。GPTo1 之后,模型 Scaling law 从单一的预训练(pre-training)向三大 Scaling 转变。1)模型在回应用户之前产生很长的内部思考链,思考时间越长,答案的质量就越高;2)Multi-agent 进一步提升模型性能,但其Token 消耗量往往达到对话聊天的数倍。
训练层面,预训练重启,后训练加码。预训练方面,DeepSeek 团队在论文中坦言,受训练算力约束,DeepSeek-V3.2 的世界知识广度仍落后于领先闭源模型(如 Gemini 3 Pro),后续将通过扩大预训练规模补齐能力上限。此外,V3.2 往往需要更多 token 才能逼近 Gemini3.0-Pro 等模型的输出质量,未来将聚焦提升推理链的“智能密度”,以更少 token 达到同等效果;后训练投入强度提升:DeepSeek 认为开源模型后训练投入普遍不足并制约任务表现,因
此将后训练算力预算上调至超过预训练成本的 10%。
推理方面,MiniMax M2、DeepSeek V3.2 等国产大模型,把“思考 → 行动 → 观察 → 再思考”的动态循环模式(Interleaved Thinking)融入推理流程,正成为 Agent 模型标配。我们认为,国内 Interleaved Thinking 范式渗透,能够显著提高 Agent 的准确性和规划能力,2026 年Token 消耗与推理需求有望加速爆发。
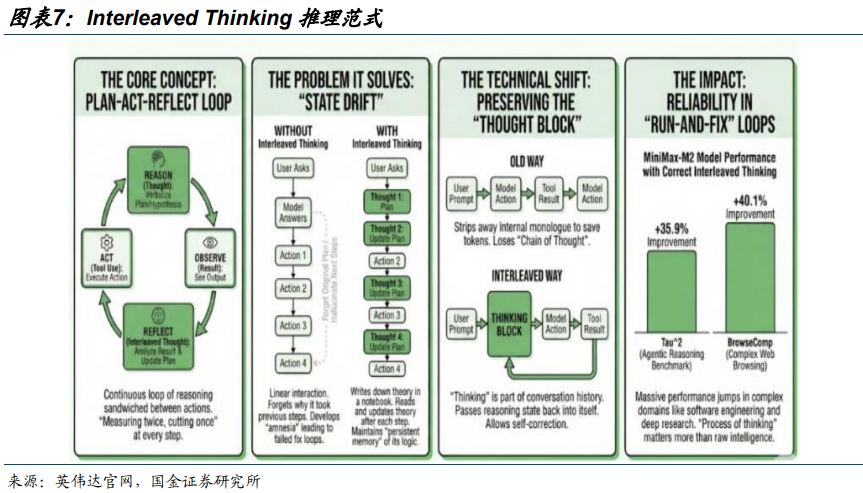
我们认为模型的进步目前并未到瓶颈,2026 年模型的进展会更值得期待:
1)靠 Scaling law 提升模型能力的路径依旧有效。
DeepSeek V3.2 后训练规模扩展到预训练规模 10%,预计未来比例还会提高,而且 DeepSeek团队在论文表示由于训练算力有限,DeepSeek-V3.2 的世界知识广度还是落后于 Gemini 3 pro这样的顶尖闭源模型,团队计划未来进一步扩大预训练规模。同时 DeepSeek 大量使用合成数据有效说明不用担心数据会遇到瓶颈。
2) DeepSeek-V3.2 提出的 DSA 机制展示出强大算法创新能力,不必担心大模型技术创新已经到达瓶颈。
3)大模型训练的硬件基础正从英伟达的 Hopper 架构转向 Blackwell 架构,Blackwell 相比前代在单卡算力、显存带宽、显存容量、以及集群互联都大幅提升,这对大模型训练的意义一方面是加速和降低成本,另一方面是可以使用更大的 Batch Size(模型更新学习内容前一次性处理的训练样本数量),这对训练稳定性有帮助,更大的 Batch Size 能够更准确地估计整个数据集的梯度,从而使学习过程更加稳定,而较小的批次则会产生噪声过大且特征过于明显的信号,这可能导致模型的学习路径出现不稳定的跳跃。

2026 年 1 月 1 日,DeepSeek 在 AI 开源社区 HuggingFacear 和研究分享平台 arXiv 发布论文,提出了名为 mHC(Manifold-Constrained Hyper-Connections)的新型神经网络架构优化方案。mHC 通过数学上的流形约束(Manifold Constraint)强制信号在跨层传播中保持范数守恒 。这成功解决了传统超连接(HC)架构虽能带来性能增提升,但因信号发散导致训练不稳定的痛点。扩展残差流会增加显存和通信的压力,同时流形约束数学理论的落地也较复杂,DeepSeek 进行了大量底层算子和通信优化,再一次展现了极高的软硬结合能力。mHC 解决了超宽残差流的训练稳定性难题,为训练更大参数规模的基模扫清了架构障碍,我们预计DeepSeek 下一代更大的基模正在酝酿中。
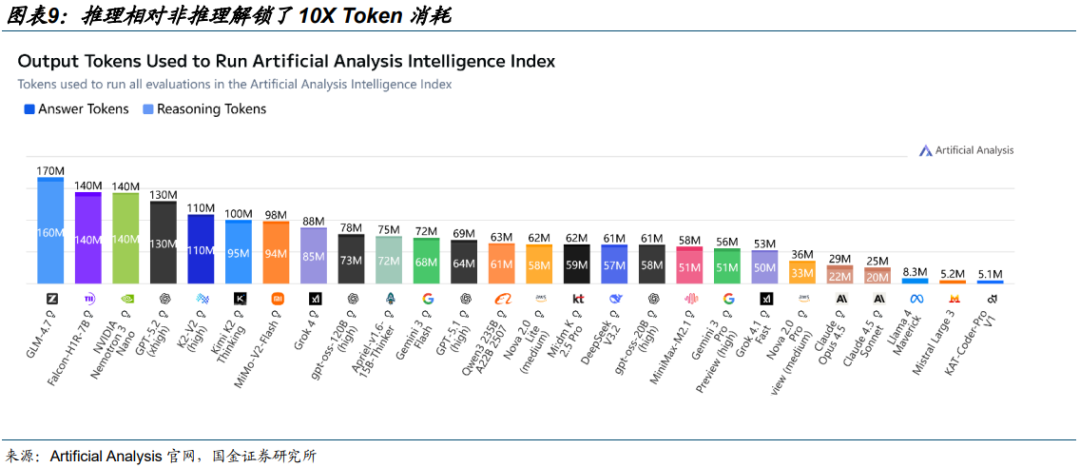
推理需求高增:推理模型解锁 10X 算力需求,英伟达或将收购 Groq 布局推理算力技术。
推理相对非推理解锁了 10X Token 消耗。随着大模型参数边际效应的初现,技术竞争的关键变量开始向后训练发生结构性转移。Post-training 将训练从通用的参数堆叠转向了基于高质量私有数据的监督微调与人类反馈强化学习,训练过程需要引入海量由高算力生成的合成数据进行反复迭代。在这一阶段,模型在响应用户指令之前,会先在内部生成长思维链,自主进行策略试错、逻辑推演与自我纠错,从而显著提升了解决复杂数学与逻辑问题的准确率。据 AA,推理模型相对非推理模型在 Token 消耗量上出现 10X 提升。
据界面新闻报道,美东时间 2025 年 12 月 24 日,AI 芯片初创公司 Groq 宣布已与英伟达就其推理技术达成非独家许可协议。根据协议条款,Groq 创始人 Jonathan Ross、总裁 Sunny Madra 及其他核心团队成员将加入英伟达,共同推进授权技术的升级与规模化应用。
Groq 将继续作为独立公司运营,Simon Edwards 将接任首席执行官职务。Groq 云服务将保持正常运行,不受此次合作影响。
值得注意的是,此前有报道称,英伟达将以大约 200 亿美元收购人工智能芯片初创公司 Groq,这将是英伟达迄今为止规模最大的一笔收购。但英伟达很快表示,并没有收购 Groq,只是达成了技术许可,使用 Groq 的推理技术而已。
公开资料显示,成立于 2016 年的 Groq 由谷歌 TPU 核心开发者 Jonathan Ross 创立,公司自研的 LPU 推理芯片是本次合作的核心价值所在。
区别于英伟达通用型 GPU,LPU 专为 AI 推理场景深度优化,凭借确定性架构、片上 SRAM内存设计等核心技术,实现了超低延迟、超高能效与极速推理速度。在主流大语言模型运行中,LPU 推理速度可达英伟达 H100 GPU 的 5 至 18 倍,首 token 响应时间仅 0.2 秒,还能有效降低算力成本,解决传统 GPU 在推理环节的“内存墙”与高延迟问题。这家明星初创企业曾在9 月完成一轮 7.5 亿美元的融资,投后估值达 69 亿美元,累计融资超 30 亿美元。
我们认为英伟达与 Groq 的合作是对推理算力的前瞻布局,反映出 AI 算力需求正由以训练为中心向训练 大规模推理并重演进,印证大模型应用落地节奏加快、商业化前景乐观。

入口不再仅限于手机,而是演变为“OS 级智能体”与“超级 APP“层面较量。1)超级 APP的入口之争已经打响。2025 年 12 月 24 日,字节跳动旗下 AI 应用豆包宣布日均活跃用户数(DAU)突破 1 亿;千问 App 近期持续扩大投流,截止 12 月 10 日(公测 23 天)月活已突破 3000 万,下成全球增长最快 AI 应用。阿里巴巴在内部沟通中提及,千问 C 端事业群的首要目标是将千问打造成为一款超级 APP,成为 AI 时代用户的第一入口;2)“入口之战”从流
量分发层推到了系统权限层,已成必争之地。豆包绕开传统接口,用“看屏幕 代操作”的方式在现有生态之上再搭一层“AI 操作系统”,AIOS 直接触碰微信、支付宝等超级 App 的商业命门,传统 App 时代的游戏规则面临挑战,微信、淘宝等超级 App 陆续封禁豆包手机权限。但值得注意的是,华为、小米、荣耀、OPPO、vivo 等品牌均在旗舰机型里注入 AI Agent 能力,模型厂商仍有望通过开源或广泛结盟来绕过 APP 厂商的封锁。
在此背景下,我们认为入口之争的背后是流量之争,直接指向大型互联网企业广告及电商业务的基本盘,2026 年各家在模型、AI 应用产品上的算力投入将进入白热化的锦标赛阶段。

GUI Agent AI手机的出现有望驱动形成繁荣的AI终端生态。因为手机作为超级个人计算终端,承载了几乎所有 C 端的信息流,且是物理世界的超级入口,所以只有当 AI 击穿手机之后,其他 AI 终端才有可能依托 AI 手机持续繁荣,并且由于 AI 手机的信息流处理复杂度较高,所以AI 手机一定是“大云小端” 的,进一步拉动算力需求。
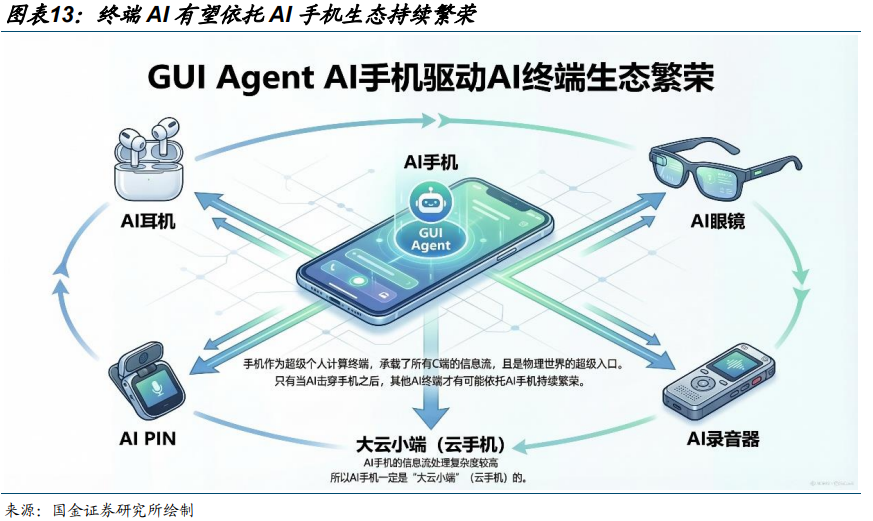
02 国产卡持续突破,2026 年爆发之时
02 国产卡持续突破,2026 年爆发之时
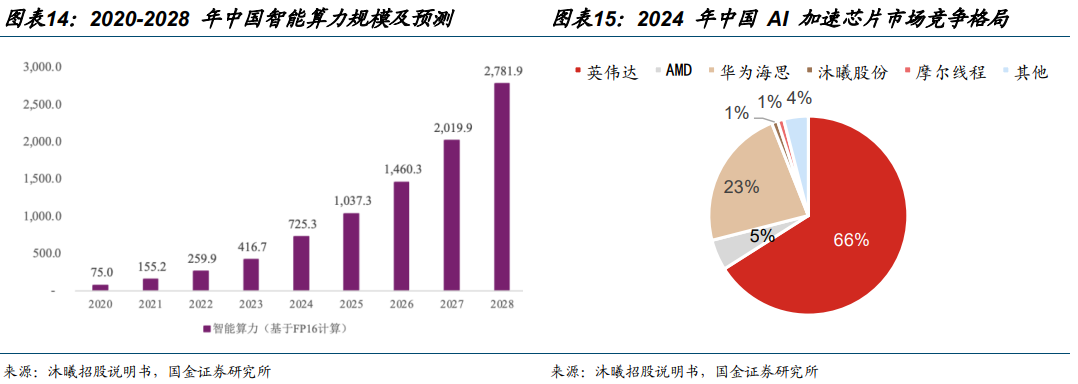
智算中心持续扩容,国产替代加速。根据 IDC 数据,2020 年中国智能算力规模为 75.0 EFLOPS,到 2028 年预计将达到 2,781.9 EFLOPS,预计 2020-2028 年复合增长率达到57.1%。随着地缘政治紧张局势推动中国企业寻求本地替代方案,以及国产芯片技术的稳步提升,国内云服务提供商正在加速构建异构环境(将不同类型的芯片结合使用,如 CPU、GPU、国内替代芯片)。例如,腾讯云已将其异构计算平台全面兼容所有主流国产芯片,以满足内部开发和客户对 AI 算力的需求 。根据 Bernstein Research,2024 年中国 AI 加速芯片市场中,英伟达、AMD 市场份额分别为 66%、5%,合计占比达 71%。但受益于国产替代趋势及供应链安全需求,国内计算芯片公司正迅速提升。其中,华为海思/沐曦/摩尔市场份额已分别达到23%/1%/1%。
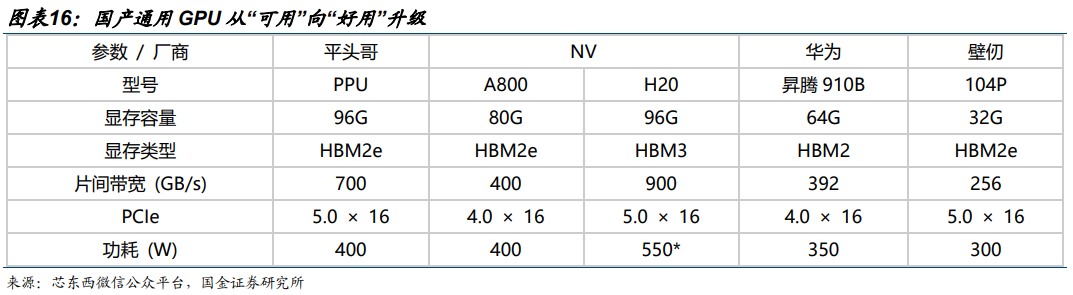
国产通用 GPU 从“可用”向“好用”升级。国产 GPU 在性能指标、软件生态、应用适配等方面与 NV 最先进一代仍有差距,但已基本追平 H20、A100 等,且在本地化服务、政策支持、成本控制等方面具备优势。随着资本持续注入,国产企业有望在细分场景实现突破,逐步扩大市场份额。1)算力指标上:国内多数头部企业主流在售产品的 FP16/BF16 在 100-300 TFLOPS 左右,处于英伟达 A100 产品阶段,少数厂商通过先进封装等方式实现接近英伟达H100 产品的算力,为国内最先进水平;2)显存方面:国内企业结合自身产品特点,分别选择 HBM2e、HBM2、GDDR 等显存类型,显存带宽在 0.5-2 TB/s 左右。
供给侧:中芯国际作为中国集成电路领导者,产能/利用率持续提升。11 月 13 日,中芯国际披露 2025 年第三季度财报,2025Q3 中芯国际营收 171.62 亿元,环比增长 6.9%,毛利率25.5%;月产能为 102.28 万片(折合 8 英寸),同比增加产能约 13.85 万片(折合 8 英寸);产能利用率达 95.8%,环比增长 3.3 个百分点。中芯国际产能全球第三,约为台积电的三分之一。公司资本支出维持高位,未来产能或将继续增加。

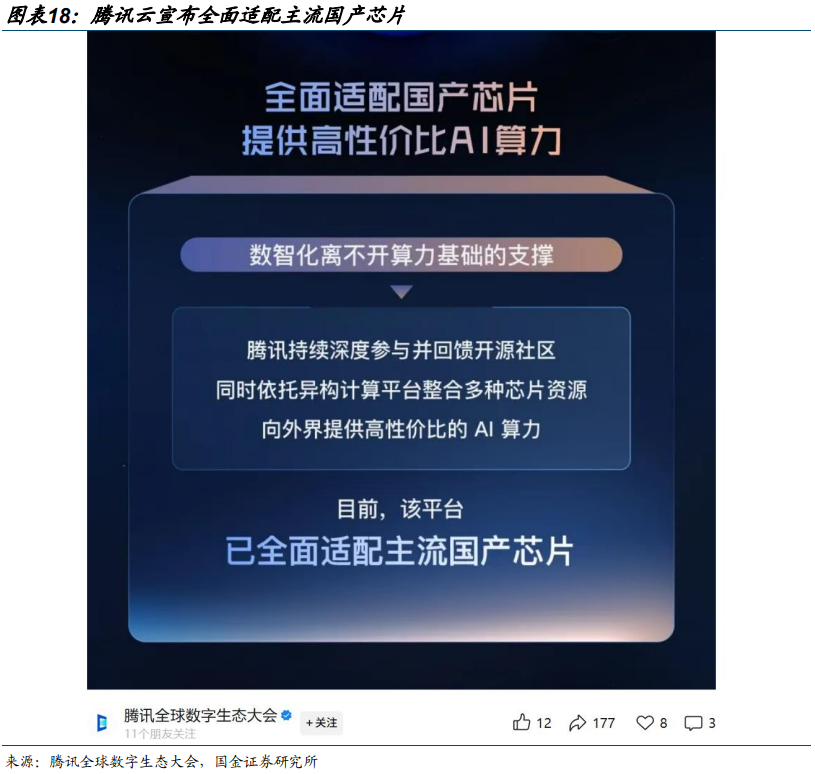
CSP 厂商加速适配,助力国产芯片生态建设。英特尔的 X86 生态、英伟达的 CUDA 生态之所以难以撼动,核心在于形成了“芯片 -软件-应用”的闭环。而当前国产阵营中,华为昇腾、阿里平头哥、壁仞科技等芯片厂商各有技术路线,生态分散问题显著。腾讯集团高级执行副总裁汤道生在交流中坦言,不同参数规模的 AI 模型需要适配不同芯片配置,当前只能通过与多家厂商合作实现场景覆盖。百度、阿里等企业加速适配国产芯片,推动“芯片-模型-应用”闭环形成。
03 供需双高,国内算力斜率陡峭
供需双高,国内算力斜率陡峭。
1)需求侧:①下游推理需求伴随 AI 手机等终端 AI 进入落地放量临界点确定性增强;②大模型 Scaling Law 仍然有效,模型迭代持续加速提升训练需求的确定性。
2)供给侧:①国产 GPU 性能持续提升;②国内 CSP 厂商加速适配国产 GPU。
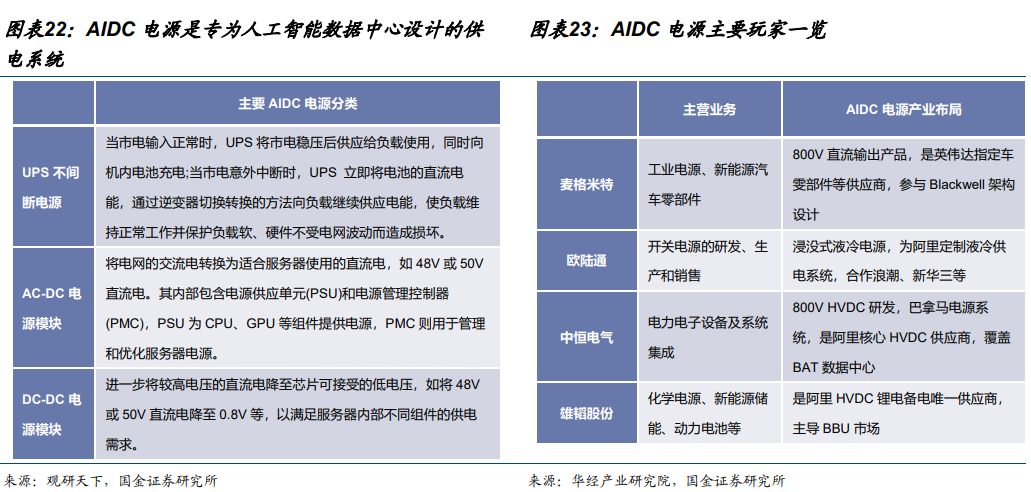
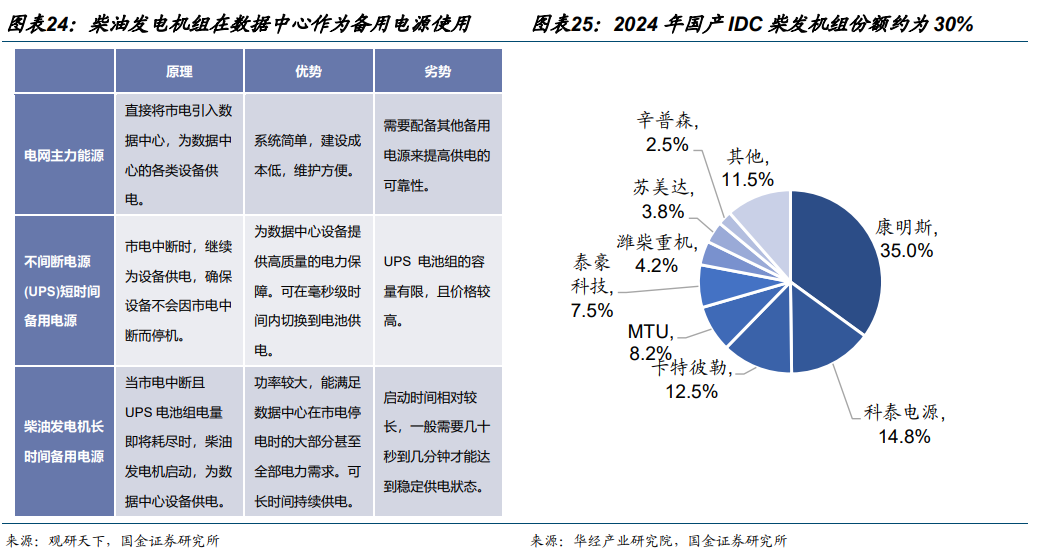
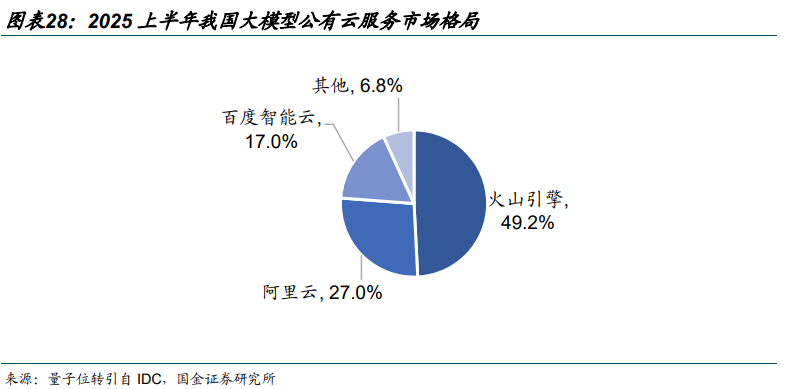
上述背景下,GPU、服务器、柴发、电源、IDC、云 6 大产业环节供需两高,其中,AI 服务器整合 GPU、存储等直接影响模型效果的硬件基础;AIDC 承载算力与数据;AIDC 电源是 AIDC 的主要供电系统;柴油发电机是 AIDC 不可或缺的备用电力来源;大模型公有云本质上是算力的共享化与弹性化。

AI 服务器是指专为 AI 应用设计的高性能计算机设备,能够支持大规模数据处理、模型训练、推理计算等复杂任务。与传统服务器相比,AI 服务器通常配备强大的处理器(如 CPU、GPU、FPGA、ASIC 等)、高速内存、大容量且高速的存储系统以及高效的散热系统,以满足人工智能算法对计算资源的高需求。据 IDC,目前 AI 服务器市场中 57.33%为训练型服务器,推理型服务器占比达 42.67%,预计未来推理型服务器将逐渐成为市场主流。2024年,我国 x86 服务器市场 CR6 分别为浪潮信息/超聚变/新华三/联想/宁畅/中兴,2024 年我国 x86 服务器市场规模约为 393 亿美元,同比增长 49.7%。

相关标的
国内算力:寒武纪、东阳光、海光信息、协创数据、星环科技、神州数码、百度集团、大位科技、润建股份、华丰科技、中芯国际、华虹半导体、兆易创新、大普微、中微公司、兴森科技、中科曙光、禾盛新材、润泽科技、浪潮信息、东山精密、亿田智能、奥飞数据、云赛智联、瑞晟智能、科华数据、潍柴重机、金山云、欧陆通、杰创智能。
海外算力/存储:中际旭创、新易盛、天孚通信、源杰科技、胜宏科技、景旺电子、英维克等;闪迪、铠侠、美光、SK 海力士、中微公司、北方华创、拓荆科技、长川科技。
风险提示
§ 行业竞争加剧的风险:
在信创等政策持续加码支持计算机行业发展的背景下,众多新兴玩家参与到市场竞争之中,若市场竞争进一步加剧,竞争优势偏弱的企业或面临出清,某些中低端品类的毛利率或受到一定程度影响。
§ 技术研发进度不及预期的风险:
计算机行业技术开发需投入大量资源,如果相关厂商新品研发进程不及预期,表观层面将呈现出投入产出在较长时期的滞后特征。
§ 特定行业下游资本开支周期性波动的风险:
部分计算机公司系顺周期行业,下游资本开支波动与行业周期性相关性较强,或在个别年份对于上游软件厂商的营收表现产生扰动。

 VIP复盘网
VIP复盘网
