

9月26日,上交所官网显示,摩尔线程智能科技(北京)股份有限公司首发申请成功通过上交所上市审核委员会会议审议。

根据摩尔线程招股书披露,公司拟募资80亿元,主要用于“摩尔线程新一代自主可控AI训推一体芯片研发项目”“摩尔线程新一代自主可控图形芯片研发项目”“摩尔线程新一代自主可控AISoC芯片研发项目”及“补充流动资金”,前2个项目拟募资总额超过50亿元。
这些项目的实施,将有利于推动国内自主GPU芯片的创新应用发展,打破国外GPU芯片的市场垄断与出口管制,加速实现GPU芯片的国产替代。
本文重点解读:国产算力芯片核心赛道GPU 。
01
GPU行业概述
算力芯片分为多种类型,包括中央处理器(CPU)、图形处理器(GPU)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)等。
其中,GPU(图形处理器)是专门用于处理图形渲染和并行计算任务的可编程逻辑芯片。当前已成为人工智能训练推理、科学计算、数字孪生等关键领域的核心算力支撑。
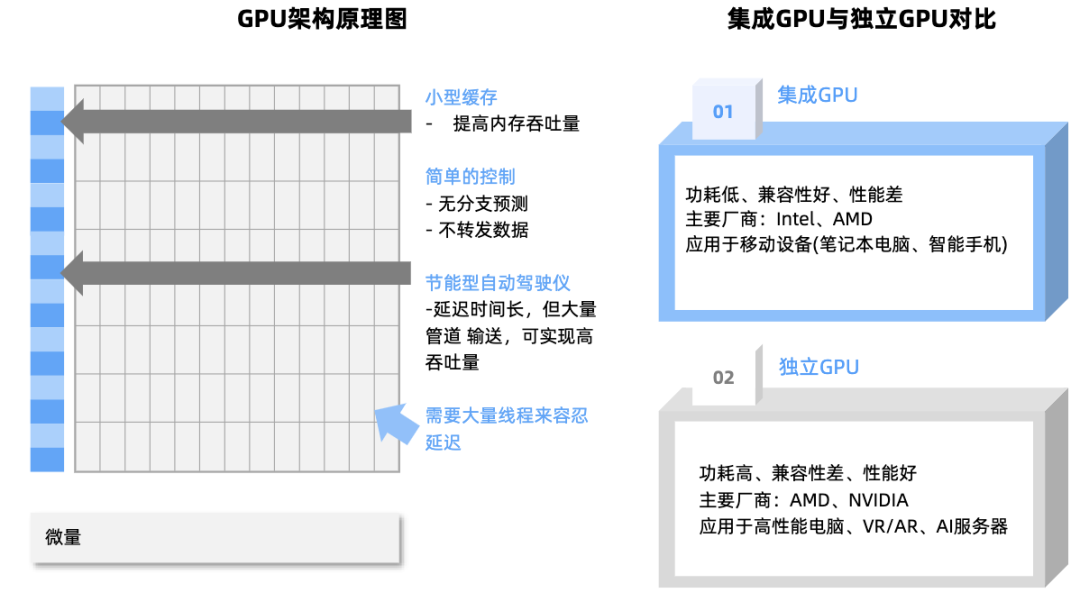
GPU与CPU的区别:与CPU的串行计算架构不同,GPU在矩阵运算、数据密集型处理等场景下效率可达CPU的数十倍至数百倍,构成算力基础设施的核心组件。
GPU的核心特征在于采用大规模并行计算架构,通过数千个计算单元同时执行多线程任务。
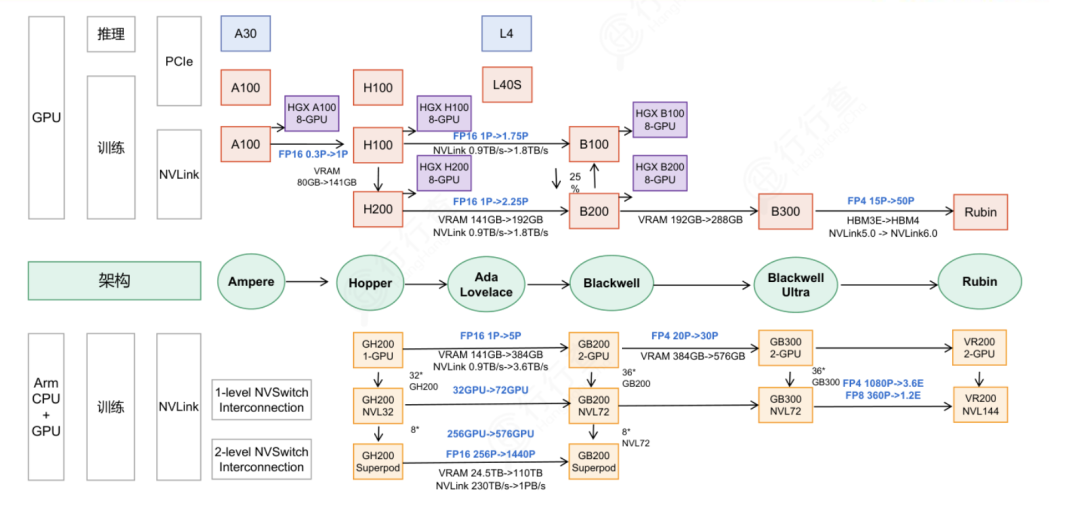
以英伟达为例,每一代GPU在计算能力、NVLink带宽和内存容量方面持续升级,推动AI训练与推理性能不断提升。
国产GPU应用领域
国产GPU的应用已全面覆盖数据中心AI、专业图形、边缘计算与物联网、高性能计算等核心场景。
数据中心AI场景:壁仞BR200、华为昇腾910C/920等芯片已构建大规模智算集群,支持千亿参数大模型训练、AI绘画及自然语言处理(NLP)任务。国内企业通过自研通信库构建多芯混合集群,GPU与国产芯片协同训练效率提升35%。
专业图形领域:兼容主流API,满足国产化需求。景嘉微JM9系列、摩尔线程MTT S80显卡兼容OpenGL/Vulkan等API,广泛应用于CAD/BIM设计、GIS地理信息系统及国产化桌面终端,满足政务、军工等场景的图形渲染需求。摩尔线程驱动更新(如v310.120)优化OpenGL 4.4框架,支持Blender 4.x等软件工作流,提升专业图形处理效率。
边缘计算与物联网领域:高能效比支撑实时推理。寒武纪思元590、摩尔线程E300产品以高能效比优势,服务于智能驾驶、智慧城市的边缘推理任务。
高性能计算场景:海光深算1000 DCU与芯动科技GD2000 GPU通过与CPU协同优化,为高校和科研院所的科学计算、数值模拟提供稳定算力。例如,国家气象机构利用GPU集群模拟全球气候系统,预测精度提升至90%,计算速度较传统方法提升200倍。
高端GPU芯片的技术难点
高端GPU芯片的技术难点集中在架构设计、软件生态、先进制程和算力-带宽优化四大领域,且各环节相互制约,形成系统性技术壁垒。
架构设计的极致平衡:高端GPU芯片需在有限功耗下实现数千计算单元的高效并行调度,兼顾算力密度、内存带宽与数据流转效率,平衡图形渲染与通用计算双场景需求。
软件生态壁垒:高端GPU芯片需兼容CUDA等主流框架并构建自主工具链,解决应用适配成本高、生态覆盖不足的问题。
先进制程的突破:高性能芯片对7nm及以下先进制程、HBM显存封装等工艺要求严苛,国内制造环节仍存性能与产能瓶颈。
算力-带宽的优化:高算力需匹配高带宽显存与互联技术,避免数据传输成为性能瓶颈,同时需持续投入研发与顶尖人才储备,应对长周期、高投入的技术迭代挑战。
02
国产GPU产业链
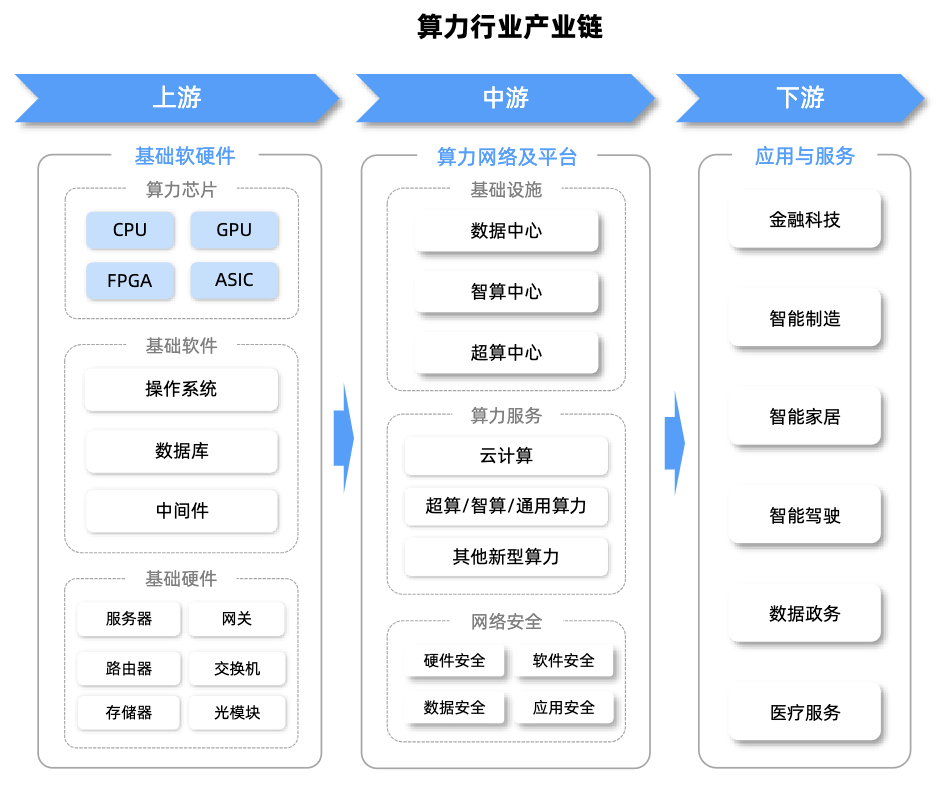
GPU产业链上游核心包括硅片、核心元器件、IP授权、制造设备与材料等核心环节。
硅片领域:中国大陆硅片供应商加速追赶,形成梯队竞争态势,主要厂商包括沪硅产业、中环股份、立昂微、中欣晶圆、众合科技、中晶科技、扬杰科技、有研半导体、上海合晶、金瑞泓、西安奕斯伟和南京国盛等。例如沪硅产业的12英寸硅片缺陷密度控制在0.03个/cm²以内,达到信越化学水平,为国产GPU芯片提供了高质量的基底支撑。

核心元器件:国内高端GPUPCB核心供应商胜宏科技、鹏鼎控股、沪电股份、深南电路、景旺电子、东山精密、生益科技等加速布局。封装基板国产替代先锋兴森科技是国内少数具备20层及以下产品量产能力的企业,良率接近海外龙头(低层板90%、高层板85%以上),卡位Chiplet、CoWoS等先进封装工艺。
AI PCB 第二次技术迭代逻辑是 8 卡变为 Rack 架构:
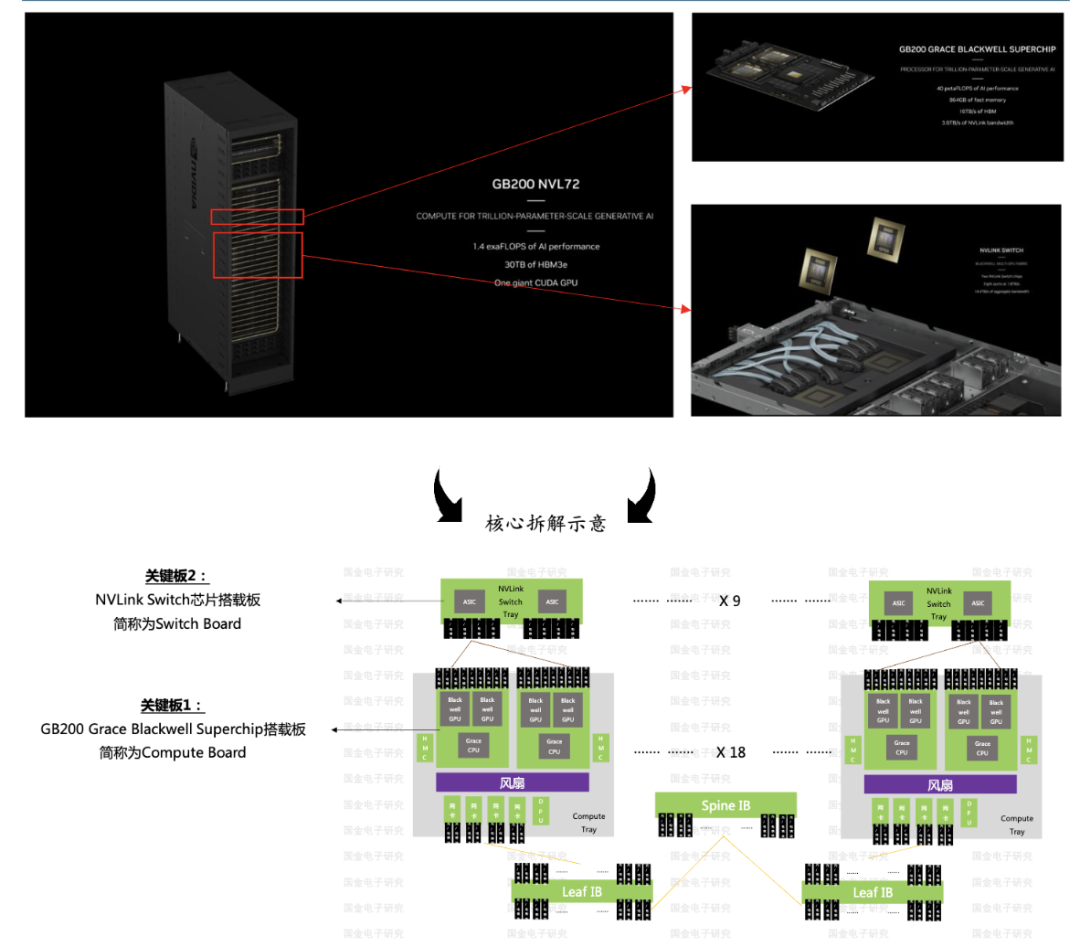
资料来源:英伟达官网
IP授权和EDA:芯原股份提供GPU IP及设计服务,深度绑定本土厂商。芯原科技拥有超过1400项半导体IP授权,其中处理器IP(如RISC-V架构的CPU IP、高性能DSP IP)可用于手机、汽车、AIoT等场景。EDA领域,国内厂商华大九天、概伦电子、广立微等加速国产替代。
制造设备:北方华创覆盖多类关键设备、中微公司刻蚀机突破亚埃级精度、华海清科、拓荆科技、盛美上海、上海微电子、屹唐半导体、长川科技、中科飞测、精测电子等厂商在各细赛道引领国产替代。
材料端:国内电子特气本土替代进程加快,以华特气体、金宏气体、雅克科技、中船特气、昊华科技、和远气体、南大光电、凯美特气为代表的企业在不同种类的细分气体领域皆有突破。半导体掩模版具有较高的进入门槛,主要厂商包括中芯国际光罩厂、迪思微、中微掩模、龙图光罩、清溢光电、路维光电等。光刻胶市场中,南大光电、彤程新材(北京科华)、华懋科技(徐州博康)、晶瑞电材(苏州瑞红)、上海新阳、容大感光、鼎龙股份,以及广信材料、飞凯材料、雅克科技等加速国产替代。
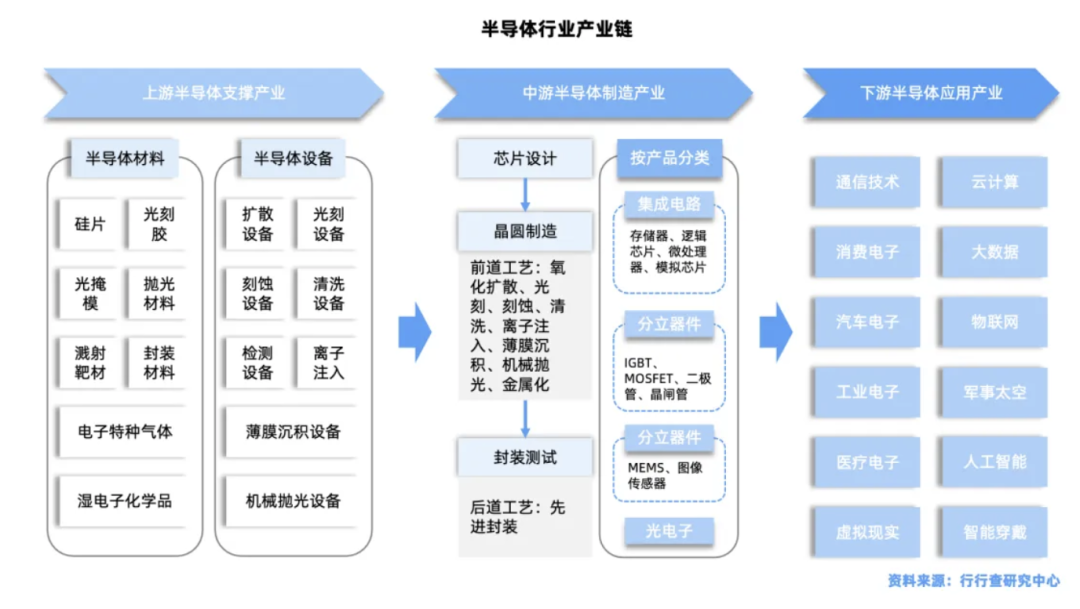
GPU产业链中游是核心设计与制造环节,主导技术与产品落地。
设计端形成差异化竞争梯队,华为、景嘉微为领军企业,具备全栈研发能力。砺算科技是图形渲染与AI融合的全自研突破者。
摩尔线程、壁仞科技聚焦高端市场突破。
除晶圆制造外,长电科技、通富微电、华天科技、甬矽电子、晶方科技等在封装测试领域提供专业服务,保障芯片量产质量。
下游是系统集成与应用拓展环节,连接产业与市场。
系统集成商以浪潮信息和中科曙光等为代表推出基于国产GPU的AI服务器。
应用端商汤科技、旷视科技基于国产芯片开发行业解决方案,科大讯飞等企业则将国产GPU应用于教育、医疗等场景,推动技术商业化落地。
04
GPU行业竞争格局
当前全球GPU芯片行业呈现“一超多强、多线竞争”的格局。
英伟达凭借技术生态和市场份额占据绝对主导地位,AMD与英特尔加速追赶;中国厂商在政策支持与国产替代需求推动下快速崛起,形成差异化竞争。
中国GPU市场中,华为昇腾系列芯片,在AI和数据中心领域具有强劲实力。摩尔线程以全功能GPU覆盖数据中心和消费级双市场,成为国产领军者。海光信息凭借DCU芯片在AI加速卡市场深度绑定运营商与超算中心;景嘉微在军用领域市占率领先,并拓展信创桌面市场。
壁仞科技、沐曦股份等聚焦高端AI训练;砺算科技7G106芯片采用6nm工艺,性能超越RTX4060,支持端侧大模型低延迟推理,展现国产GPU在消费级市场的潜力。芯动科技一站式IP授权和芯片定制及GPU赋能型领军企业,提供跨全球各大工艺厂从55纳米到5纳米的全套IP和芯片定制解决方案。
2024年全球数据中心GPU市场份额:
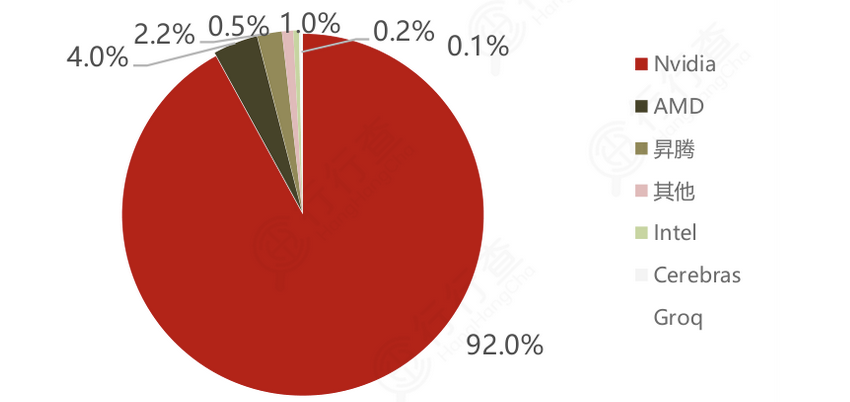
资料来源:IOT Analytics、民生证券、行行查
05
国内GPU代表厂商概览
国产GPU厂商主要采用“全自研IP”与“混合IP”两种技术路线。全自研路径以华为昇腾为代表,从指令集到计算单元完全自主设计;混合路径则是通过授权外部IP进行二次开发优化。
摩尔线程:全功能GPU的国产化突破
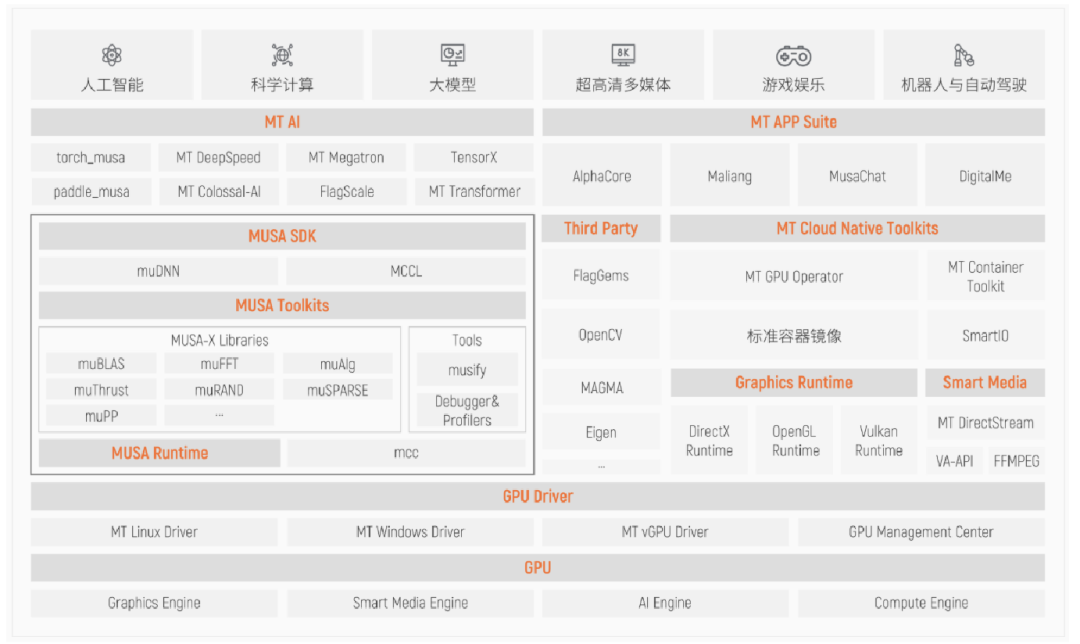
摩尔线程公司由前英伟达全球副总裁张建中于2020年10月创立,采用全自研路径,聚焦“全功能GPU”赛道,是国内少数对标英伟达的企业。其核心是自研的MUSA架构,实现从指令集到计算单元的完全自主设计,是国内首个支持AI智算、图形加速、物理仿真协同的全功能架构,已迭代至第四代。
摩尔线程的产品线
摩尔线程第三代 MUSA 软件栈:
华为昇腾:AI算力的规模化引领
华为昇腾芯片以达芬奇架构为核心,专注AI训练与推理芯片,构建“芯片-集群-生态”的全栈解决方案,具有算力密度高、集群扩展能力强的特点。
昇腾910:华为首款商用AI训练处理器,2019年发布,面向数据中心级大规模训练。7nm增强版EUV工艺,FP16算力256TFLOPS,最大功耗350W(后优化至310W),支持混合精度计算,应用在华为Atlas800训练服务器等,支撑千亿参数模型训练。
昇腾910C:昇腾910的升级版,采用中芯国际7nm(N 2)工艺,国产化率超90%。采用中芯国际7nm(N 2)工艺,晶体管数量达530亿,通过双die封装设计实现性能提升,FP16精度下单卡算力约800TFLOPS。
华为昇腾920: 第三代AI处理器,采用用6nm工艺,集成达芬奇架构AICore,旨在提供高性能的AI算力支持。FP16算力超900TFLOPS,BF16算力较H20高37%,支持千亿参数大模型预训练。配套推出的CloudMatrix384算力集群,支持384片昇腾920互联,可为千亿参数大模型预训练提供稳定算力。
寒武纪:AI加速芯片的专精之路
寒武纪成立于2016年3月15日,总部位于北京。公司产品线涵盖了云端、边缘端和终端设备中的人工智能核心芯片。采用自研的思元(Cambricon)架构,主打AI推理与训练加速,特点是能效比高、硬件可编程性强,适配多类AI框架。
云端线代表产品有思元100、思元270、思元290和思元370等。思元370系列采用7nm制程工艺,是首款采用Chiplet技术的AI芯片,支持LPDDR5内存,内存带宽是上一代产品的3倍。
景嘉微:图形GPU的国产化标杆
景嘉微以自主可控的图形处理为核心,长期深耕军用及国产化桌面GPU市场,侧重硬件架构优化与国产操作系统生态适配,是国内唯一具备军工资质的GPU研发企业,军用领域市占率领先。
JM9系列GPU延续了高性能图形渲染优势,支持OpenGL、Vulkan等主流图形API,适配银河麒麟、统信UOS等国产操作系统。该系列在CAD/BIM设计、GIS地理信息等专业领域表现突出,可满足政务、军工等场景的安全需求。
战略动向方面,新一代JM11系列进入流片阶段,算力密度较前代提升3倍。与龙芯中科、统信软件完成全国产化平台适配,拓展信创桌面市场。
海光信息:CPU-GPU协同的计算方案
海光信息的技术路线依托x86架构优势,侧重CPU与GPU(DCU)的协同计算,打造异构计算平台,核心是通过软硬件协同优化提升数据中心计算效率。
最新产品为深算系列DCU,如深算1000,FP64双精度算力达20 TFLOPS,可与海光x86 CPU无缝协同。该产品主要面向科学计算、数值模拟等高性能计算场景,已在高校、科研院所实现规模化部署。
战略动向方面,海光与中科曙光换股吸收合并,形成“芯片-服务器-云计算-算力服务”全产业链。目标通过RCEP东盟出口增长45%,将全球AI加速器份额从3%提升至10%。

龙芯中科:CPU-GPU协同的自主创新
龙芯中科技术路线以自主可控为核心,走CPU与GPU协同发展道路,通过自研GPUIP核实现硬件级整合,重点突破国产化图形渲染与AI推理能力。
2025年最新产品包括2K3000处理器和首款独立GPGPU芯片9A1000,图形性能对标RX550,提供数十TOPS算力,主打低成本场景。
芯原股份:GPU IP的专业化赋能
芯原股份技术路线聚焦图形GPUIP核研发,专注为终端设备提供超低功耗、高性价比的图形处理解决方案,核心优势在于硬件架构优化与多场景适配能力,服务于消费电子、物联网等领域。
2025年4月推出的GCNano3DVG是其最新GPUIP产品,支持3D与2.5D混合渲染,专为智能手表、AI/AR眼镜等可穿戴设备设计,能满足紧凑型电池供电设备的动态图形渲染需求。
芯动科技:高性能计算的硬核突破
芯动科技主打高性能通用计算GPU,采用先进制程工艺与创新架构设计,注重软硬件协同优化,目标对标国际高端GPU产品。
其主力产品为“风华”系列GPU,代表型号GD2000采用多核心并行架构,支持光线追踪与AI超分技术,FP32算力达15 TFLOPS,已应用于专业图形工作站、数据中心加速等场景,性能接近国际同代中端产品水平。
壁仞科技:高端AI算力的领军者
壁仞科技2019年成立,专注通用GPU及AI加速器研发,GPU产品已在国内部分云厂商落地试用。年成立
2025年初,公司完成新一轮15亿元融资,投前估值约140亿元。联合创始人包括前商汤科技总裁张文、前高通及华为工程师焦国方等。2022年,壁仞推出旗舰通用GPU芯片BR100及精简版BR104,核心性能对标英伟达A100/H100。2024年销售收入约4亿元,GPU产品已在国内部分云厂商落地试用。
壁仞科技技术路线以自研BR架构为核心,专注高性能AI训练与推理GPU,特点是算力密度高、内存带宽大、集群扩展能力强。
旗舰产品BR200智能芯片采用先进制程,FP16算力超500TFLOPS,支持千亿参数大模型训练与推理,配套的BR200-X加速卡已批量应用于国内头部智算中心,与英伟达A100形成竞争,在AI绘画、自然语言处理等场景中表现突出。

沐曦股份:全栈GPU后起之秀
沐曦集成电路(上海)股份有限公司成立于2020年9月,由原AMD全球GPU研发团队核心成员领衔创办,团队平均拥有15年以上GPU设计经验,涵盖架构、芯片、软件、系统全链条。
已在北京、南京、成都、杭州等地建成研发中心,形成“长三角 京津冀 成渝”的全国研发网络,支撑全栈产品自主研发。
聚焦AI训练与通用计算GPU,采用自研GPGPU架构,兼容CUDA生态,打造“芯片-软件栈-计算平台”的全栈产品体系。
2024年中国数据中心加速芯片市场出货量位居前三,成为国内少数实现千卡集群大规模商业化应用的GPU供应商。

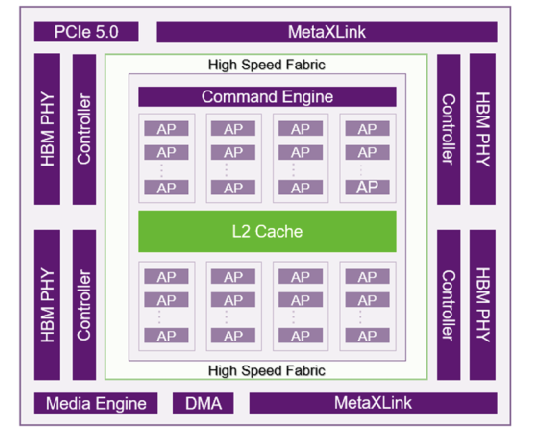
曦云C系列:面向AI训练与通用计算,如曦云C600(全自研GPU IP,集成大容量存储与多精度混合算力,支持MetaXLink超节点扩展技术)。
曦思N系列:面向推理场景,优化能效比。
曦锐D系列:面向图形渲染,支持专业设计软件。
核心产品MXC500AI训练芯片采用7nm制程工艺,对标英伟达A100/A800,支持PyTorch、TensorFlow等主流框架,已完成芯片功能测试与基础平台验证;公司正推进该产品规模化落地,主要面向智能驾驶、工业AI等领域,2025年已启动科创板IPO进程。
沐曦典型 GPU 基本组成架构:
砺算科技
砺算科技是国内图形渲染与AI融合的全自研突破者。

在中国AI智算GPU市场中,数据中心GPU产品是过去增速较快的细分市场。
参考摩尔线程招股书、弗若斯特沙利文数据,2020年至2024年全球GPU市场规模展现出显著的增长趋势,年均复合增长率高达62.4%。预计2025年全球GPU市场规模将达到15,000亿元;中国GPU市场规模将接近3,000亿元。
整体来看,在算力基础设施自主可控的国家战略背景下,发展国产GPU不仅是技术突破的需要,更是保障数字经济安全、推动产业转型升级的关键支撑。

 VIP复盘网
VIP复盘网
