

9月19日,上交所官网披露,上市审核委员会将于9月26日召开会议,审议摩尔线程首发事项。若顺利过会,摩尔线程离“国产GPU第一股”就更近一步。

1、公司坐标: 北京
成立时间:2020年6月11日
2、创始人
张建中--中国GPU星辰大海破浪前行的孤勇者。
1966年张建中出生于江苏南京,毕业于南京理工大学,硕士学历。2005年加入英伟达,曾用15年将英伟达中国的市占率从不足50%,提升至80%以上。被誉为“帮助英伟达在中国取得成功的GPU生态和行业营销专家”。却在巅峰时刻毅然离职,誓言中国必须要有自己全功能的GPU。
2020年,时任英伟达全球副总裁,中国区总裁的张建中,做出惊人决定,放弃千万年薪,回国创业,抱着“赤子之心”投入“GPU国产化”的研发,走了一条艰难但极其伟大而正确的道路。
仅30天,他便吸引了众多GPU驱动、编译、AI芯片、软件算法以及系统设计等领域10年以上经验的资深工程师加入,并在国内搭建了最为完整的专业IC团队。
在第300天,他带领团队研发出中国首颗全功能GPU。
创业100天,公司估值超10亿美元,刷新全球独角兽最快成长记录。
2023年10月17日,美国商务部将摩尔线程列入实体清单,台积电等代工厂被迫断供。这一击几乎致命:芯片无法量产,前期投入可能付诸东流。张建中在内部信中写道:“1017事件让整个国产GPU/AI芯片行业遭受重创,但中国GPU不存在至暗时刻,只有星辰大海。”
面对制裁,他果断砍掉非核心业务,聚焦图像渲染 AI算力两大战略。同时,积极的与中芯国际、华虹集团等国内代工达成合作,通过工艺优化和设计调整,部分芯片实现量产。
如果,公司没有芯片这条“芯”,那活着也就没有意义,张建中深知,硬件易得,生态难建。英伟达CUDA用20年绑定500万开发者,摩尔线程要想活下去,必须打破这种垄断,于是,张建中的策略是“两条腿走路”:一方面,摩尔线程便自研MUSA架构,兼容CUDA等主流生态;另一方面,推出国产首个万卡大模型训练平台“KUAE夸娥”,构建万卡智算集群。
他说“AI工厂”的主战场,万卡是最低标配。
如今,摩尔线程IPO在即,作为国内全功能GPU的领头羊,虽然截止2025H1营收累积已突破12亿,但与255亿的估值存在较大差距,和英伟达24年的609亿美元营收相比,更是相差甚远。
这是一条荆棘丛生的险峻之路,张建中坦言:“全功能GPU是大芯片领域的珠穆朗玛峰,摩尔线程仍是一家年轻的创业公司,挑战很多,前路漫长。”
然而他的信念从未动摇---打造中国最好的全功能GPU,张建中会带领摩尔线程团队一直践行到底。

3、发展时间轴:
(1)产品轴
与国内多数采用GPGPU或AI算力芯片(ASIC)路线的企业不同,摩尔线程选择了全功能GPU技术路线,覆盖了多个应用领域。已成功推出四代GPU架构,分别命名为苏堤、春晓、曲院和平湖,形成了从芯片到显卡到集群的完整智算产品线。
摩尔线程以“一年迭代一颗芯片”的速度,展现了惊人的研发效率:
2021年:成立不到300天,首颗国产全功能GPU芯片“苏堤”研制成功,实现了从0到1的突破。
2022年:发布第二代GPU芯片“春晓”,并推出首款国产游戏显卡MTT S80及数据中心产品MTT S3000,正式进入消费级和企业级市场。 2023年:推出第三代GPU芯片“曲院”,AI性能大幅提升,并基于此成功搭建“夸娥(KUAE)”千卡智算集群,标志着其具备了支持大模型训练的能力。
2024年:发布第四代GPU芯片“平湖”,增加FP8精度支持,片间互联速率达800GB/s,显存容量提升至80GB,进一步强化AI算力,并推出面向智能终端的“长江”SoC芯片,业务版图拓展至AI PC和智能汽车领域。
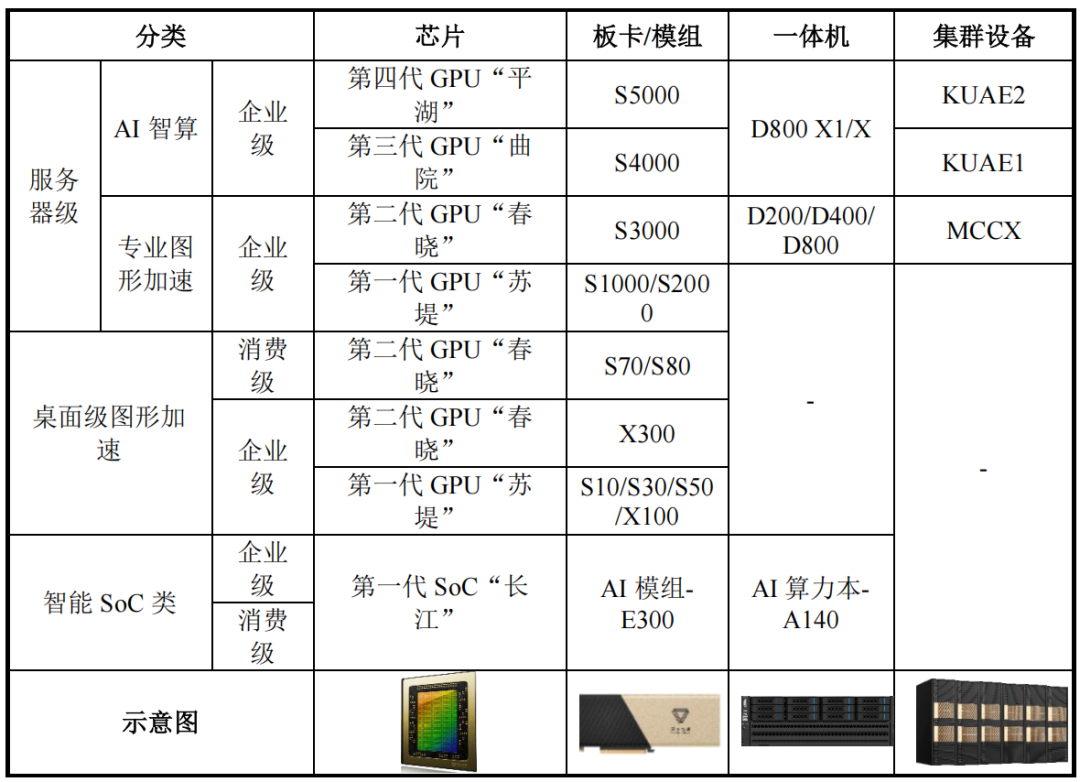
另外,为了对标英伟达CUDA的生态,其自主研发的MUSA架构可同时支持AI计算加速、图形渲染、物理仿真及超高清视频处理所需的计算能力,形成了从芯片到显卡到集群的完整智算产品线。
在专业图形加速产品方面,其S10/S30板卡产品在信创个人PC市场上与飞腾、海光、兆芯、龙芯等国产品牌CPU完成适配,已服务多家企事业单位客户。
在智能SoC领域,公司推出了"长江"SoC,INT8算力达50TOPS。据称,该产品在汽车智能座舱市场上的性能规格超越高通骁龙8295方案,预计2026年导入量产。
(2)融资时间轴
下图:融资历程,来自鲸准

摩尔线程自 2020 年成立以来已完成六轮融资,累计融资额超65亿元,超过70家头部投资机构和豪华股东:
既包含红杉中国、五源资本、GGV纪源资本等顶级基金公司,也有深创投、国盛资本等实力雄厚的国资平台,更是还汇聚了腾讯、字节跳动、中国移动等高科技产业巨头。
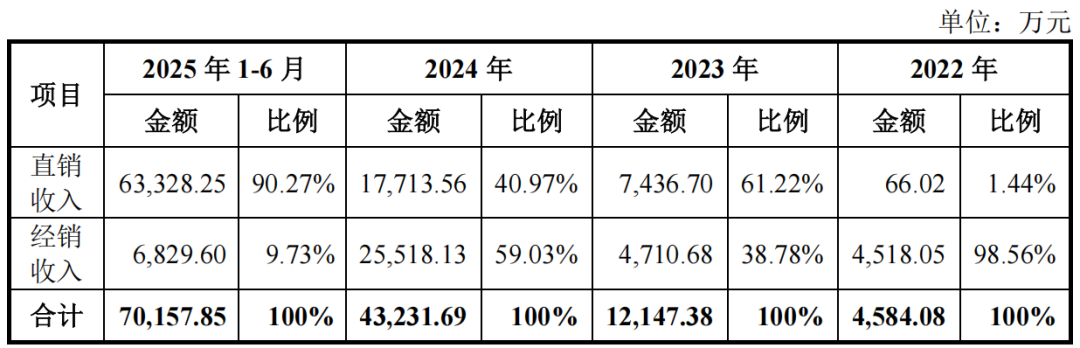
财务数据显示,摩尔线程营收呈现高速增长态势:
2022年至2024年,摩尔线程营业收入从0.46亿元增长至4.38亿元,年复合增长率高达208.44%,2025年上半年实现营收7.02亿元,超过了此前三年的营收总和。
但公司累计研发投入达93.76亿元,至今尚未盈利,累计亏损超过50亿元。这主要是由于,公司 GPU 产品迭代速度较快,属于技术密集型行业,业务复杂程度高芯片行业研发投入巨大,占最近三年累计营业收入的比例约为716.27%。
4、商业模式
(1)盈利模式
硬件销售为主:AI智算集群及板卡是主要收入来源,2025年上半年AI智算产品收入占比94.85%。
公司采取直销与经销并存的销售模式,内部设有专门的销售团队同客户进行及时接洽。在直销模式下,通常公司直接参与客户的商务谈判,达成意向后,公司直接与客户签订销售合同。除直销模式外,公司亦采用经销模式拓展市场。
二、核心技术--构建AI超级工厂
2025年7月25日,摩尔线程CEO张建中,创新的提出“AI工厂”概念,如同芯片晶圆厂的制程升级,是一个系统性、全方位的变革,需要实现从底层芯片架构创新、到集群整体架构的优化,再到软件算法调优和资源调度系统的全面升级。
这座“AI工厂”的智能“产能”,由五大核心要素共同决定,其效率公式可概括为:AI工厂生产效率 = 加速计算通用性 × 单芯片有效算力 × 单节点效率 × 集群效率 × 集群稳定性
摩尔线程以全功能GPU通用算力为基石,通过先进架构、芯片算力、单节点效率、集群效率优化与可靠性等协同跃升的深度技术创新,旨在将全功能GPU加速计算平台的强大潜能,转化为工程级的训练效率与可靠性保障。
其核心技术如下:
1、MUSA生态:"兼容 开源"策略
软件生态是摩尔线程的核心护城河,公司推出了Musify工具链,实现CUDA代码向MUSAC平台自动迁移,显著降低开发者转换成本。目前摩尔线程已完成与PyTorch、PaddlePaddle等主流框架适配,获得超150家行业软件兼容认证。
MUSA,Moore Threads Unified System Architecture,是摩尔线程自主研发的统一计算架构,是其技术体系的基石,对标英伟达的CUDA生态,采用的是“兼容 开源"策略。
它涵盖了统一的芯片架构、指令集、编程模型及软件驱动框架,旨在为AI计算、图形渲染、科学计算等各类并行任务提供统一的开发平台。
MUSA架构的“全功能”体现在单一GPU芯片内集成了四大引擎(AI计算、3D图形、视频编解码、物理仿真),并支持从FP64到INT8的完整数据精度,能够灵活应对多样化的工作负载。
另外,MUSA生态具有兼容性:为打破NVIDIA CUDA生态的壁垒,摩尔线程推出了关键工具MUSIFY,可将现有CUDA代码以较低成本自动迁移至MUSA平台,极大地降低了开发者的迁移门槛,加速了生态应用的适配。

2、“云-边-端”多元化产品
公司产品覆盖AI智算、图形加速、智能SOC三大领域,形成了从芯片、板卡、一体机到智算集群的多层次产品矩阵。
AI智算产品如MTT S5000板卡和夸娥千卡智算集群,算力密度和能效比领先,支持万卡级集群训练,效率超过同代国外产品;图形加速产品MTT S80显卡性能对标英伟达RTX 3060,支持千款游戏和应用;智能SOC产品“长江”集成CPU、GPU、NPU,瞄准智能座舱和边缘计算场景。
(1)AI 智算产品
公司 AI 智算产品线涵盖 AI 训练智算卡、AI 推理卡、AI 超节点服务器及夸娥(KUAE)智算集群等,为 AI 计算中心、云服务平台等打造,满足从大模型预训练及后训练、推理部署到GPU 云服务等场景应用需求。
其中,基础算力层面,AI 训练智算卡与 AI 推理卡作为核心计算单元,为 MoE 混合专家模型、多模态模型、世界模型等前沿模型预训练及集群化推理优化设计,具备良好的计算性能与能效比。
服务器层面,AI 超节点服务器,服务于大规模 AI训练与推理场景,通过高密度算力集成和创新散热设计,实现单节点多卡高效协同。
公司 AI 智算产品线通过层次化的算力架构与智能应用场景的深度融合优化,为 AI 产业规模化发展提供全面支持,赋能客户构建从传统 AI 到自主决策型自主 AI 代理的全栈解决方案,把握智能计算与 AI 垂直领域的市场先机。
(2) 专业 /桌面级 图形加速产品
专业 图形加速产品:主要应用于工业设计、高清视频编辑、数字孪生、AI 云电脑等高端场景的 GPU 及相关产品系列,涵盖 MTT S3000/S2000/S1000 等系列显卡,以及基于前述显卡打造的一体机等解决方案。
桌面级图形加速产品:主 要 应 用 于 AI PC 、 游 戏 PC 及 办 公 PC 等 场 景 的 GPU 及 相 关 产 品 , 包 括
MTTS80/S70/S50/S30/S10/X300/X100 等系列显卡,以及基于前述显卡打造的工作站等。该类产品支持 Windows、麒麟 KylinOS、统信 UOS、openEuler 等多款国内外主流操作系统,以及Intel、AMD、海光、飞腾、鲲鹏等多款国内外主流 CPU 平台。
(3)智能 SoC 类产品--边缘与端侧AI
主要应用于 AI PC、边缘智能、具身智能、智能汽车和低空经济等众多场景,包括基于 SoC芯片的 AI 算力本-A140、AI 模组-E300 等产品。
该类产品可以广泛服务于 C 端和 B 端客户,满足上述行业对于端侧和边缘类 AI 场景的需求,同时可与公司的 AI 智算产品结合,形成云-边-端一体化解决方案,赋能客户实现 AI 的训练-推理需求。
3、自研KUAE大规模集群,优化集群效率
为了突破单节点效率的限制,摩尔线程自研KUAE(夸娥)计算集群,通过5D大规模分布式并行计算技术,实现千卡级别甚至万卡规模的集群协同计算,为大模型训练和推理等提供了强大的算力支持,推动AI基础设施从单点优化迈向系统工程级突破。
创新5D并行训练:摩尔线程整合数据、模型、张量、流水线和专家并行技术,全面支持Transformer等主流架构,显著提升大规模集群训练效率。
性能仿真与优化:自主研发的Simumax工具面向超大规模集群自动搜索最优并行策略,精准模拟FP8混合精度训练与算子融合,为DeepSeek等模型缩短训练周期提供科学依据。
秒级备份恢复:针对大模型稳定性难题,创新CheckPoint加速方案利用RDMA技术,将百GB级备份恢复时间从数分钟压缩至1秒,提升GPU有效算力利用率。

三、市场空间&竞争对手
1、市场格局
在全球范围内,欧美等发达国家及地区在 AI 领域的研发起步较早,早期资本投入较大。尤其是以英伟达为代表的 GPU 产品,因其成熟的开发者生态以及优秀的算力性能,使得 GPU 市场规模在过去五年迎来了爆发式增长,2024 年达到 10515.37 亿元。
未来,随着中国国产 AI 技术,如 DeepSeek 大模型、具身智能、智能驾驶等技术的持续突破,中国 AI 技术水平已经逐步达到国际领先水平,全球 AI 市场亦随之进入了一个多元发展的新时期。
根据弗若斯特沙利文预测,全球 GPU 市场规模预计在 2029 年将达到 36119.74 亿元,其中,中国 GPU 市场规模在 2029 年将达到 13635.78 亿元,在全球市场中的市场占比预计将从 2024 年的 15.6%提升至 2029 年的 37.8%。
2、国内外龙头对比
全球来看:英伟达是全球GPU绝对的霸主,全球GPU市场约88%份额,数据中心GPU领域占92%,独立GPU市场占94%。其最大的护城河--CUDA生态全球开发者超600万,覆盖AI训练、图形渲染、科学计算等全场景,技术迭代快,如Blackwell架构支持10万亿参数大模型训练。
AMD全球GPU市占率第二,全球GPU市场约6%,数据中心GPU份额不足5%,主要集中在游戏领域。其优势体系RDNA架构在游戏和AI推理场景能效比提升,与微软合作推出Azure专用AI芯片上。
国内GPU市场:华为昇腾、寒武纪、海光信息、景嘉微、还有国内GPU“四小龙”(其他三家为沐曦、壁仞、燧原)等形成了多元化竞争。
但每家技术各有侧重点,其中,摩尔线程主打“全功能GPU”,覆盖AI与图形;沐曦专注高性能计算;壁仞科技聚焦GPGPU;燧原科技则深耕云端AI训练与推理。主要竞对如下:
盈利模式 | ||||
基于 GPU 云端和边缘端AI芯片 | 销售芯片、加速卡以及整机系统 | 主要面向云端和边 缘 端 AI、游戏、专业图形、汽车 | 生态竞争能力全球领先,CUDA 生态 引领国际市场 | |
IDC、客户端、游戏及嵌入式四大业务板块,包括CPU/GPU、FPGA/DPU/SoC等芯片 | 销售芯片、加速卡以及整机系统 | IDC、客户 端、游戏及嵌入式等多领域 | 生 态 竞 争 能 力 较强,ROCm 生态在专业计算等领域表现优异 | |
x86 指令框架的海光 CPU基于 GPGPU 架构DCU 芯片 | 销售CPU和DCU产品 | 电信、金融、互联网等领域 | 积 极 参 与 开 源 社区,与众多厂商合作,构建软硬件生态 | |
云端、边缘端、终端通用智能芯片和 IP | 销售 IP 授权、芯片、加速卡以及智能计算集群系统 | 云边端的视觉、语音、自然语言、搜索推荐等 | 具备云边端一体化开发环境,支持统一的软件生态 | |
GPU 芯片、图形显控模块和加固类产品、小型专用化雷达等 | 销售 GPU 芯片、图形显控模块和加固类产品、小型 专用化雷达等 | 图形渲染 等领域,产品在图形处理和可视化等场景中广泛 | 产品以图形渲染为主,应用场景明确 | |
云端、边缘端和终端人工智能芯片 | 销售芯片、加速卡及整机 | 云边端的视觉、语音、自然语言、搜索推荐等 | 依托于 华为整体 生态优势 | |
销售 GPU 板卡、一体机和集群设备 | AI 智算集群、专业图形加速、桌面级图形加速,以及端侧智能设备 | 依托自研 MUSA 架构搭建国产计算加速生态 |
四、产业链
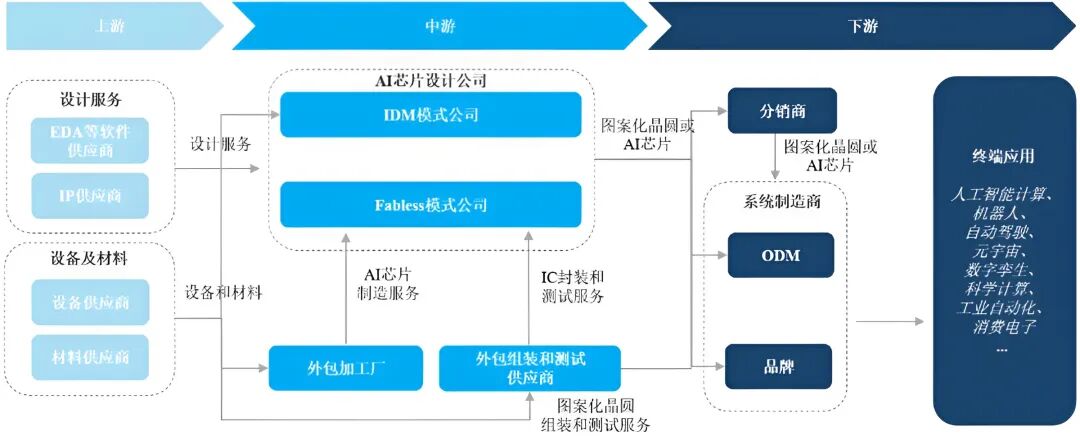
摩尔线程芯片产业链可分为上游为:EDA 软件、IP 模块等,以及制造所需的设备和材料;中游为:GPU 芯片设计、晶圆制造、封装和测试环节;下游为:GPU的分销服务与终端应用。
1、上游: EDA 软件、IP 等
上游环节提供芯片设计所需的 EDA 软件、IP 模块等,以及制造所需的半导体和封装材料。EDA 软件和 IP 供应商为芯片设计提供工具支持,而硅片材料、光刻胶、溅射靶材和封装材料供应商则为芯片制造、封装和测试提供关键资源。
中游环节,除 AI 计算加速芯片设计公司,还包括晶圆制造、封装和测试环节。晶圆制造部分通常由外部晶圆代工厂提供,而封装和测试环节则由封测厂商完成,包括 IC 封装、组装及测试工作,以确保芯片具备出色的性能和可靠性。
3、下游:GPU的分销服务与终端应用
GPU芯片的分销商主要负责销售图案化晶圆或 AI 计算加速芯片,最终应用下游包括 AI 计算加速、机器人、自动驾驶、元宇宙、数字孪生、科学计算、工业自动化、消费电子等众多行业。
(1)EDA/IP设计
① 华大九天:国内EDA工具龙头,为摩尔线程提供全流程芯片设计工具
② 澜起科技:GPU内存接口芯片IP龙头,高带宽需求爆发
③ 芯原股份:GPU IP储备丰富,一站式设计服务绑定大客户
(2)芯片材料等
① 安集科技:GPU用抛光液国产替代,客户验证完成
② 雅克科技:前驱体材料供应国际GPU大厂,订单饱满
③ 晶瑞电材:高纯试剂 光刻胶配套GPU先进制程
(3)制造/封测
① 中芯国际:国产GPU流片主力,先进制程产能满载
② 中微公司:GPU芯片国产刻蚀设备龙头
⑤ 华峰测控:模拟及混合信号测试机龙头
⑦ 通富微电:AMD核心封测伙伴,国产GPU订单爆发
(4)服务器/终端
①中科曙光:国产AI服务器龙头,GPU加速卡批量集采
②浪潮信息:全球服务器出货量第一,AI服务器占比提升
③紫光股份:新华三GPU服务器放量,政企订单饱满
④中国长城:飞腾CPU 国产GPU整机,信创份额领先
⑤同方股份:GPU服务器 云计算双业务,算力基建核心
(5)参股
①和而泰:目前持有摩尔线程1.244%股份
②联美控股:子公司拉萨联虹1亿元初始投资
③盈趣科技:基于战略布局和多元化发展的考虑投资摩尔线程
④圣元环保:通过认购中原前海基金份额3亿元间接参与摩尔线程
⑤初灵信息:通过中移数字基金间接持股
(6)代理商/供货
①浙大网新:控股子公司浙江网新图灵,为摩尔线程的浙江省总代
②麦捷科技:一体电感和绕线组合电感批量供货摩尔线程
⑥青云科技、⑦弘信电子、⑧ 平治信息、⑨拓尔思、⑩ 当虹科技
⑪麒麟信安、⑫深信服、⑬利和兴、⑭奥飞数据、⑮ 润欣科技等。
六、总结与展望
2025年9月26日,摩尔线程将迎来科创板IPO上会审议,从获受理到上会仅用不足三个月,创下“闪电速度”。这家被誉为“中国英伟达”的GPU企业,拟募资80亿元,用于新一代AI训推一体芯片、图形芯片和AI SoC芯片研发。
摩尔线程IPO之路,本质是国产GPU的破晓时刻。一家成立仅五年的公司正以冲刺速度奔向科创板,此次IPO不仅是一场融资,更是中国自主可控GPU发展的关键一役。
首先,摩尔线程的营收呈现爆发式增长:从2022年的4608万元增至2024年的4.38亿元,2025年上半年更是达到7.02亿元,超过前三年总和。其次,公司毛利率从2022年的-70.08%大幅提升至2025年上半年的69.14%,显示其产品商业化能力显著增强。
尽管收入增长迅猛,摩尔线程却尚未盈利,近三年半累计亏损超50亿元。这种“高增长、高亏损”的状况在芯片设计行业并不罕见,却真实反映了国产GPU突围的艰难。
如今,摩尔线程已推出四代GPU架构,构建了从芯片到集群的智算产品线。然而公司坦承,其产品在高端市场性能及生态支持上仍与国际龙头企业存在差距。

都说资本对硬科技的耐心,决定了国产芯片能走多远。然而, 摩尔线程IPO进程的超常规速度,相当于给我们发了“明牌”,国产GPU自主可控,是我们必须完成的生死突围。
正如摩尔线程的CEO张建中,给了我们验证:真正的强者不是选择捷径,而是走窄门,在无人区修路;真正的领导力不是规避风险,而是在至暗时刻点燃团队心中的光!
国产GPU的星辰大海,已经起航。而摩尔线程不会是踽踽独行,接下来,壁仞、燧原、沐曦,还有更多的国产GPU企业,已经在路上,砥砺奋进。。。

 VIP复盘网
VIP复盘网
