


近期全球算力持续迎来重磅催化。北美方面,上周英伟达将向英特尔注资50亿美元,双方联合开发PC与数据中心芯片;微软宣布在美建“最强AI数据中心”。
国内方面,美媒称中国要求科技公司停购英伟达AI芯片;上周华为发布昇腾芯片路线图,超节点性能比肩英伟达,有望成为明年国产算力增量重要来源;国产“GPU第一股”摩尔线程IPO将于9月26日上会。
端侧AI迎来强催化,OpenAI加注端侧硬件,将与国内厂商合作生产设备,首款预计2026年末推出;此外Meta年度Connect大会上发布三款革命性AI智能眼镜,有望加速端侧AI硬件设备迎来新一轮机遇。
当前北美AI加速算力指引乐观,国产算力全链加速国产替代突围。
本文重点解析国产算力芯片三大核心赛道。
01
算力芯片行业概览
算力芯片专门用于加速大规模数据计算和复杂算法处理的集成电路,核心目标是高效执行计算任务,如深度学习训练、科学仿真和图形渲染等。
按应用场景划分,算力芯片分为通用算力芯片和专用算力芯片。
根据技术架构,算力芯片可分为GPU、FPGA、ASIC三大类。
GPU通用性强但功耗高、FPGA灵活性好但成本较高、ASIC具备高专用性和高性价比的特征,每种芯片架构在功耗和性能上各有侧重,适用于不同场景需求。
算力芯片对比:
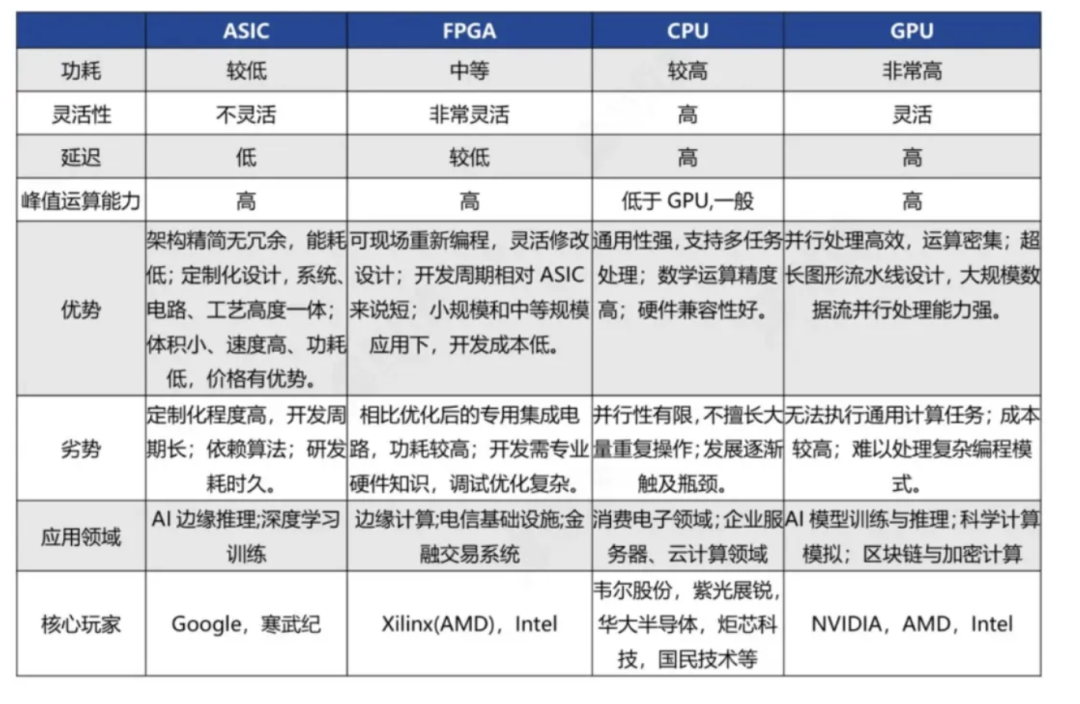
GPU
GPU是AI服务器中加速芯片的首选,具有高并行架构能够同时处理海量数据、高内存带宽通用性强且功耗较高。
主要应用在消费级游戏显卡和专业级AI训练与推理等领域。
GPU架构原理图:
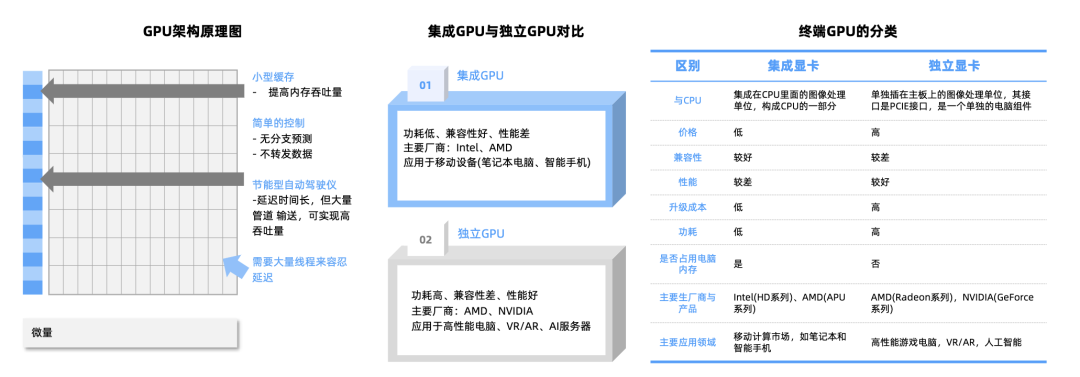
海外厂商英伟达、AMD、英特尔、高通、ARM等厂商主导GPU市场。
国产寒武纪、海思、景嘉微、海光信息、龙芯中科、摩尔线程、壁仞科技、燧原科技、沐曦集成、砺算科技(东芯股份)等高端AI芯片厂商全面提速。例如,海光信息的DCU产品在AI训练、推理等领域为国产GPU的发展提供有力支持;景嘉微自主研发的JM系列GPU芯片打破了国内GPU市场的技术空白;寒武纪思元系列AI芯片包含CPU、NPU和GPU,AI芯片产品布局对标英伟达的GPU业务,通过全栈产品满足不同场景的AI计算需求。
近期国产高端AI芯片企业陆续启动上市,摩尔线程和沐曦招股书均已披露。摩尔线程IPO将于9月26日上会。摩尔线程产品矩阵包括消费级显卡MTTS80、数据中心级MTTS4000、万卡级夸娥智算集群等。国产高端GPU全面提速有望未来对先进制程晶圆厂、材料、设备和先进封装等各环节需求拉动明确。
ASIC芯片
ASIC芯片即专用集成电路,是针对特定应用需求而设计和定制的芯片。
其算力密度高、能效比优,近年来AI推理等特定场景需求加速,ASIC方案在性价比上的优势日益凸显。
但是其缺点包括灵活性较低,且前期投入较高,一旦设计完成难以更改,这限制了其对于新算法、新任务的适用能力。
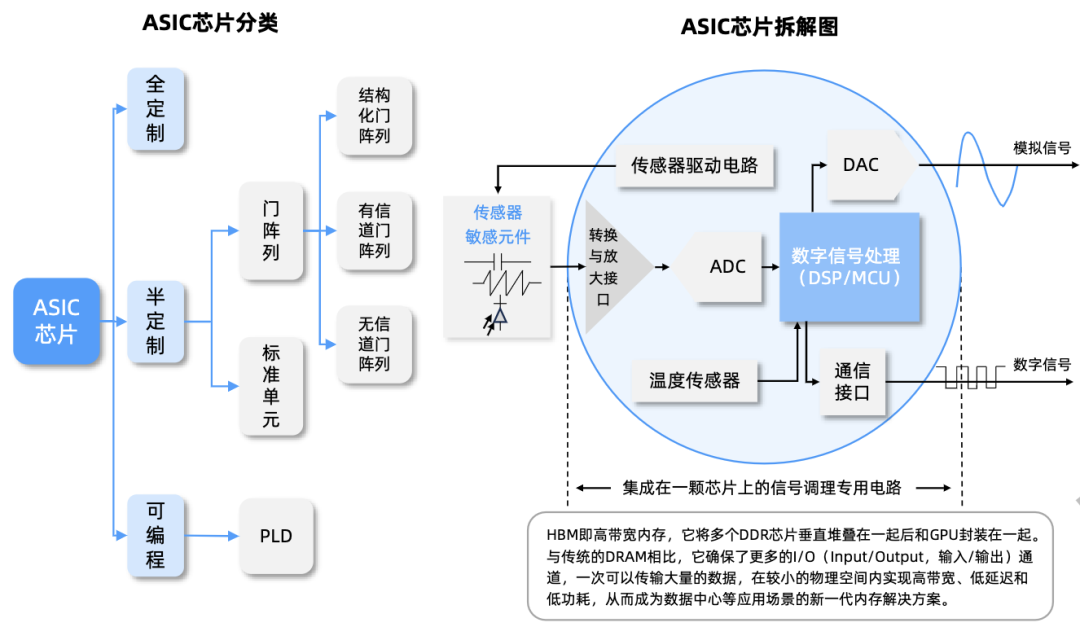
ASIC产业链上游主要包括底层算法设计企业、IP核授权企业、EDA工具供应商等;中游是ASIC芯片生产制造环节,涵盖ASIC芯片制造商、流片和封测等厂商;下游应用于通信、消费电子、汽车和工控等领域。
底层算法设计:遵循“算法-架构-硬件”协同优化原则。包括高通、ARM、谷歌(TPU架构)、英特尔(Xeon架构)等主导算法架构;寒武纪(思元系列)、阿里平头哥(含光系列)等国内企业加速突破。
ASIC供给侧:目前全球两家最大的ASIC半导体公司是博通和Marvell,目前两家公司占据了超过60%的份额。大型云服务厂商多与以上两者合作,比如谷歌的TPU就是与博通合作开发的,Marvell联手亚马逊。
国内百度、阿里和腾讯等互联网大厂自研AI芯片大多采用ASIC架构,主要应用于自身业务场景,典型的ASIC芯片例如:阿里平头哥推出含光800AI芯片;百度昆仑系列AI芯片。HW、寒武纪、燧原科技、黑芝麻和地平线等厂商也基于ASIC架构设计芯片,在深度学习模型的训练和推理方面具有高性能和高效率。ASIC产业链各环节相关布局厂商还包括如云天励飞、翱捷科技、全志科技、澜起科技、瑞芯微、灿芯股份、国科微、中昊芯英、北京君正、曲速科技(旋极信息)、淳中科技、山石网科等。
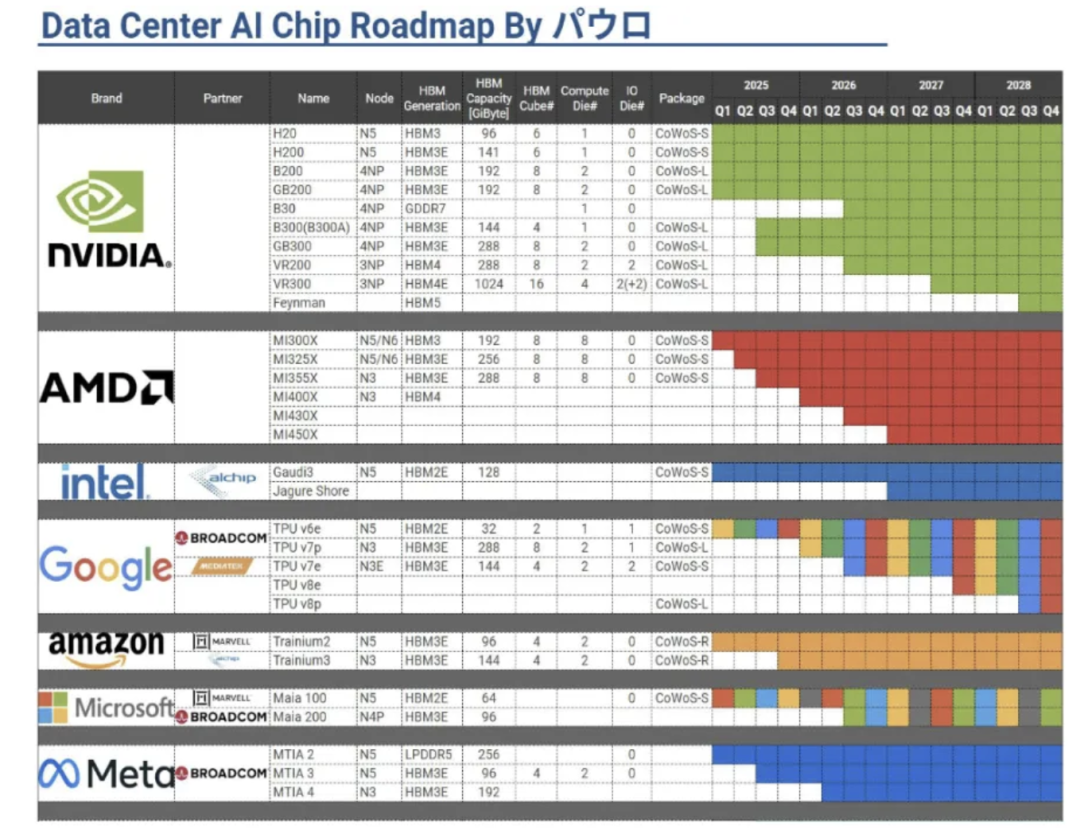
各家CSP厂商均在布局ASIC方案:
FPGA芯片
FPGA的核心特点是可动态重构硬件逻辑,兼顾灵活性与性能,适合中小规模AI任务和快速迭代场景。主要应用场景是通信加速和工业控制等。
全球FPGA市场由赛灵思(现AMD旗下)和Altera(现英特尔旗下)主导,主要参考者还包手Lattice、Microchip等厂商。
国产替代属于早期阶段,高中低端产品分化明显。对于500K以上的高容量FPGA,国产替代仍然面临一定的挑战,需要本土公司在硬件架构、EDA软件、IP性能等方面进行深入研发和创新。
国内厂商复旦微电、安路科技、紫光同创(紫光国微子公司)引领FPGA国产替代,相关布局厂商还包括京微齐力、成都华微电子、智多晶、高云半导体等。

02
AI端侧芯片
算力芯片广泛应用于多个领域,包括数据中心、自动驾驶、端侧边缘计算、云计算、生物医药和消费电子等。
其中,边缘端芯片核心特点是针对边缘设备如消费电子、智能设备和机器人等优化,平衡算力与功耗,支持本地化AI推理,而非依赖云端服务器进行处理的技术架构。
端侧AI产业链涵盖“芯-模-智”三大层级的完整生态体系,覆盖硬件、算法到场景的端侧AI全景图谱。
端侧AI芯片层包括端侧SoC、存储芯片和传感芯片在内的核心硬件。
 资料来源:行行查
资料来源:行行查
端侧AI SoC芯片
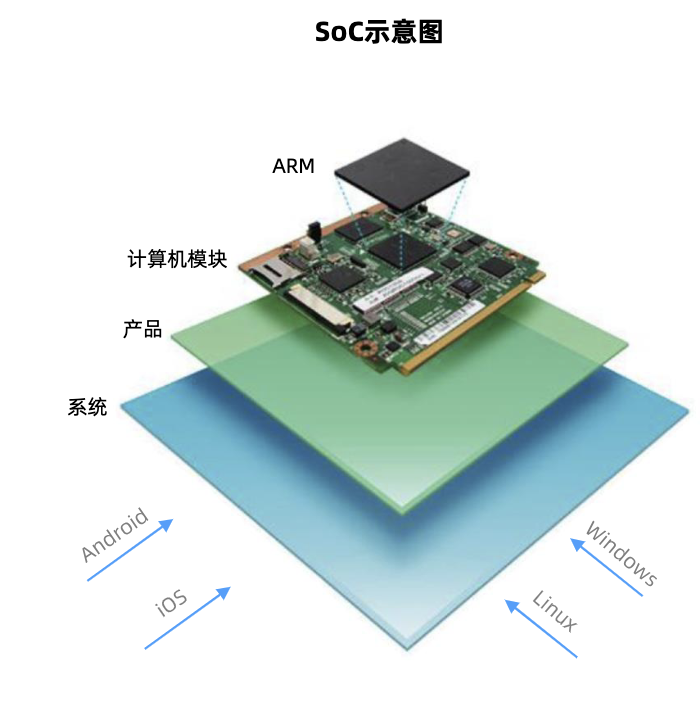
SoC芯片是高度集成的单芯片系统,也是智能终端设备的大脑和端侧AI边缘算力的核心。是在一块芯片上集成整个信息处理系统,称为片上系统或系统级芯片。
其具有高度集成性,且能够提供强大的计算能力,同时处理多种类型的数据,支持多模态交互。
以AI眼镜为例,是具备第一视角信息输入和输出,是多模态AI大模型落地到端侧的最佳载体。
供应链最新消息称,OpenAI正从 AAPL 招募硬件/设计/供应链人才,目标在 26年底-27年初推出首批设备。OpenAI已经与国内厂商立讯精密达成协议,共同生产未来的OpenAI设备,首款预计2026年末推出,歌尔将供应扬声器等零组件。
此外Meta年度Connect大会上发布了三款革命性AI智能眼镜。
国内消费电子SoC环节主要参与厂商包括乐鑫科技、恒玄科技、星宸、炬芯、瑞芯微、晶晨、全志科技、中科蓝迅、润欣科技、泰凌微、富瀚微等。
端侧AI存储芯片
AI眼镜需要处理大量的数据,包括图像、视频、语音等,存储技术需要具备高性能的特点,此外AI眼镜需要长时间佩戴和使用,因此存储技术的低功耗特性也十分重要。
目前,AI眼镜采用的存储技术主要包括以下几种:
ePOP类存储产品:
ePOP是一种新型的封装技术,将多个芯片封装在一起,形成一个紧凑的存储模块。这类存储产品轻薄小巧、功耗低,非常适合用于AI眼镜等智能穿戴设备。
该技术以佰维存储为代表,佰维存储的ePOP系列产品已成功应用于Meta等公司开发的AI智能眼镜中。
eMCP类存储产品:
eMCP是将多个芯片(如DRAM和NANDFlash)封装在一起的存储产品,具有体积小、功耗低、性能稳定等特点。
该类型存储主要布局厂商以兆易创新、普冉股份、东芯股份等为代表。
 资料来源:行行查
资料来源:行行查
03
智能驾驶芯片
汽车芯片被定义为“质量标准达到车规级,可应用于汽车控制的芯片”,这也是其区别于消费级和工业级芯片的难点和技术门槛所在。
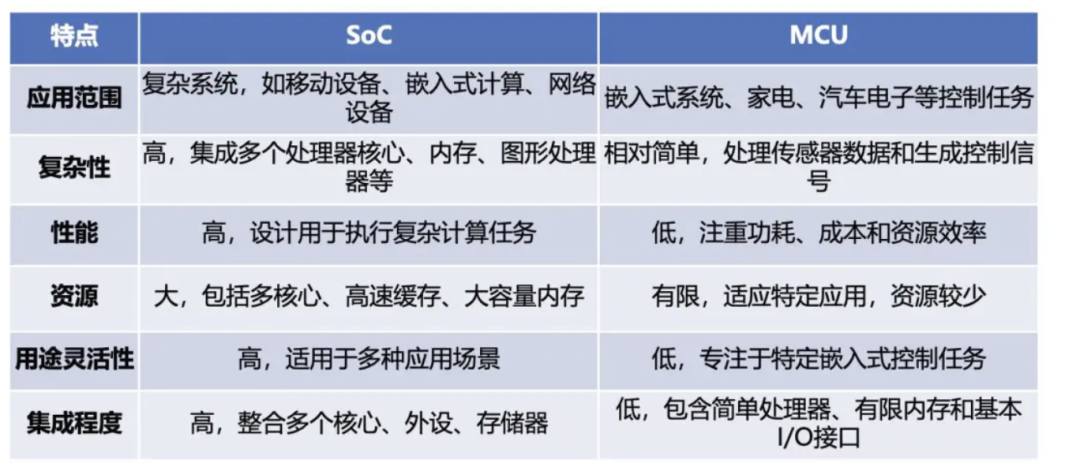
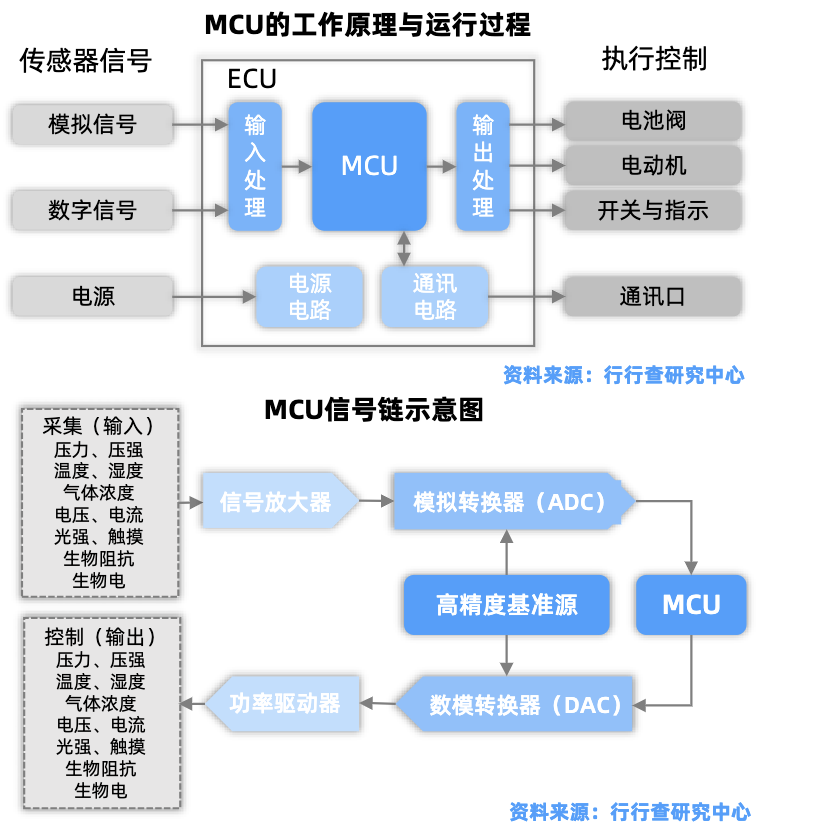
在汽车主控芯片中,MCU负责底层控制,SoC负责高层计算,两者共同构成智能汽车的“大脑 神经”。
SoC芯片:高阶智能辅助驾驶领域所应用的SoC芯片(也称智驾芯片、自动驾驶芯片等),是让车辆能够实现智能驾驶辅助及自动驾驶功能的计算单元,是AI芯片的一部分。
MCU芯片与SoC芯片对比:
伴随今年年初开始的智驾军备竞赛,算力智驾芯片需求大幅提升。
智驾芯片作为智能辅助驾驶功能实现的核心部件,成为产业链价值高地。
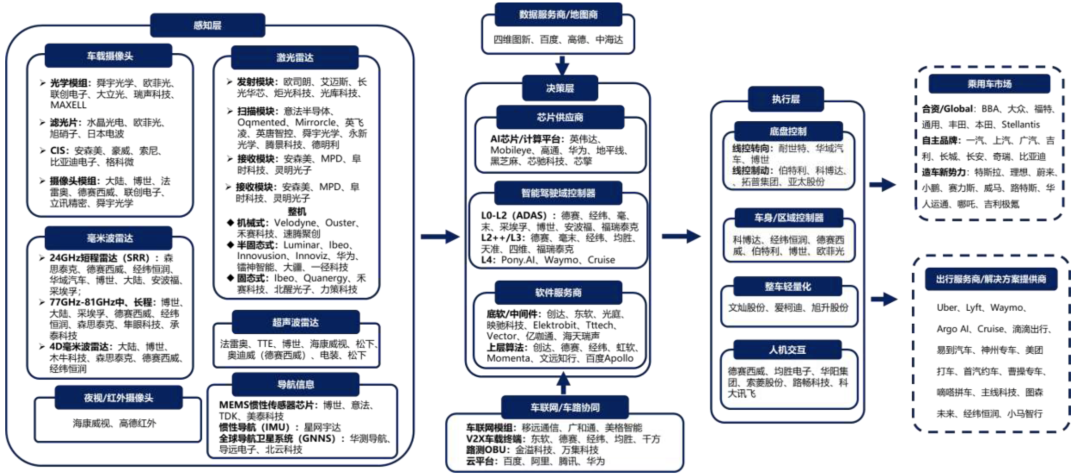
智能驾驶产业链:
 资料来源:方正证券、行行查
资料来源:方正证券、行行查
SoC芯片市场主要参与者分为四类:传统汽车芯片厂商、通用型AI芯片厂商、专业型智驾芯片厂商和全栈自研主机厂。
传统汽车芯片厂商:包括海外瑞萨、德州仪器和恩智浦等传统汽车芯片龙头厂商。
通用型AI芯片厂商:多为国际巨头,如英伟达、高通、国内HW海思等。这类厂商技术实力雄厚,在AI芯片领域具备先发优势。
此外,专业型智驾芯片厂商深耕产业新赛道,产品性能通常高于传统芯片厂。例如,地平线J6M大规模适配比亚迪/理想/吉利/奇瑞等车企,地平线J6首批Tie1合作伙伴代表主要包括博世、立讯、天准、华勤、金脉(英恒)等;黑芝麻A1000配套吉利/东风/一汽等车企,国产芯片均证明了良好的大规模上车能力。
主机厂全栈自研:以特斯拉的FSD芯片为典型代表,蔚来和小鹏也先后发布了自研的神玑和图灵芯片。
此外,国内包括全志科技、晶晨股份,瑞芯微、兆易创新、华阳集团等在产业链细分赛道加速布局,以及芯驰、诸新芯航途、辉羲、芯擎、后摩智能、爱芯元智等独立高阶智驾芯片厂商也在积极布局算力或高算力的高阶智驾芯片。
各主机厂自动驾驶芯片量产时间线梳理:
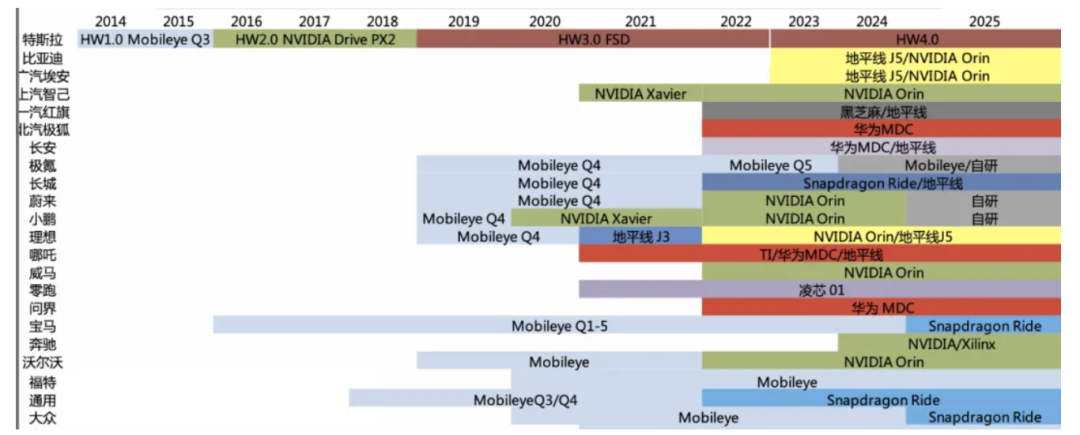 数据来源:各车企官网,车东西,九章智驾
数据来源:各车企官网,车东西,九章智驾
MCU芯片:全球车载MCU市场CR5超过90%,基本由欧美日厂商瑞萨电子、恩智浦半导体、意法半导体、英飞凌、微芯科技和德州仪器主导,国产替代空间十分广阔。MCU芯片各应用场景布局厂商众多,北京君正、成都华微、国芯科技、比亚迪半导体、景嘉微、上海贝岭、士兰微、中微半导、富满微、紫光国微、博通集成、国民技术、华岭技术、中颖电子、四维图新等厂商都在不同中细分领域有所布局。
受高阶智驾1-N催化,国产智驾芯片及解决方案厂商有望加速国产替代。
整体来看,当前国产AI生态全方面闭环,从国产AI芯片到国产开源模型,以及下游应用,将对国产算力产业链各环节带来积极正面影响。在此趋势下,国内算力芯片产业链各环节国产化有望进一步增强。

 VIP复盘网
VIP复盘网
