

摘 要
2025年9月18日,2025华为全联接大会正式召开,继华为副董事长徐直军“以开创的超节点互联技术,引领AI基础设施新范式”演讲后,以昇腾芯片、超节点为代表的相关产品持续发布。
昇腾与超节点新品性能优异,未来产品迭代蓝图清晰。本次大会发布产品包括:1)昇腾芯片:保持“一年一代”迭代:2025Q1发布910C,2026-2028年逐步推出950PR/950DT、960、970。950系列低精度计算与自研HBM提升大模型训练效率,PR/DT面向推理与训练场景分工明确。960/970实现算力、带宽翻倍。2)华为超节点:通过灵衢协议和UB-Mesh架构,实现高可靠、高带宽、低时延的全光互联。
从AI标卡到超节点集群,华为算力产品覆盖多样化需求。具体超节点产品包括:1)超节点数据中心(Atlas 900/950/960 SuperPoD):面向超大规模AI训练,采用UB-Mesh互联与灵衢协议,整机算力EFLOPS级,互联带宽高、时延低、可靠性强,可灵活扩展至上万卡规模;2)超节点集群(Atlas 950/960 SuperCluster):在超节点基础上实现跨节点组网,总算力可达ZFLOPS级,网络性能与能效显著提升;3)企业级风冷超节点服务器(Atlas 850/860):面向企业级后训练与多场景推理,支持即插即用、高密度算力、风冷环境下高效散热,可按需扩展至千卡集群;4)标卡产品(Atlas 350):适配高并发推理与多模态生成任务,单卡算力高、内存与访存优化,可覆盖从10B到100B参数模型的训练与推理需求。
系统级创新弥补工艺短板,核心技术积累支撑算力跃升。过去,华为长期受美国制裁,在先进制程上受限,单颗芯片与英伟达等海外头部算力公司存在差距,但华为依靠多年“联人、联机器”的积累,在联接技术上投资,最终实现了万卡级超节点,以系统级思维优化产品与解决方案。今天,华为新品发布会给出了几大重要信号:1)HBM实现了自研突破,昇腾新品采用自研HBM HIBL 1.0(白鹭,带宽1.6 TB/s)与HIZQ 2.0(朱雀,带宽4 TB/s),分别对应HBM2e与HBM3水准;2)华为逐步从“一颗芯片覆盖端、边、云”的全场景设计,转向针对不同计算场景的需求特征进行优化;3)昇腾从传统SIMD向SIMD/SIMT架构演进(SIMT是NVIDIA GPU的典型模式)。华为算力产品在性能上逐步向行业龙头靠拢,先进制程工艺缺乏、单一ASIC架构等短板也逐一补齐,华为在系统性优化上厚积薄发、制定了极为清晰的未来产品路线图,我们看好华为算力链条继续快速迭代,为国产算力提供持续替代方案。
相关标的:1)昇腾硬件合作伙伴;2)代工:国内相关晶圆厂;3)铜连接:华丰科技;4)光连接:华工科技;5)电源:泰嘉股份;6)PCB:方正科技,深南电路,南亚新材、生益电子、广合科技等;7)散热:飞荣达、英维克、申菱环境、中航光电等。
风险提示:新品研发不及预期、产品良率不及预期、竞争格局恶化

华为算力产品发布会:
昇腾超节点引领国产算力
昇腾产品一年一代,迭代路径清晰。2025华为全联接大会明确了2025-2028年的昇腾路线图:2025Q1发布910C;2026Q1推出950PR,2026Q4推出950DT;2027Q4升级至960;2028Q4再迭代到970,整体保持“一年一代”的节奏。
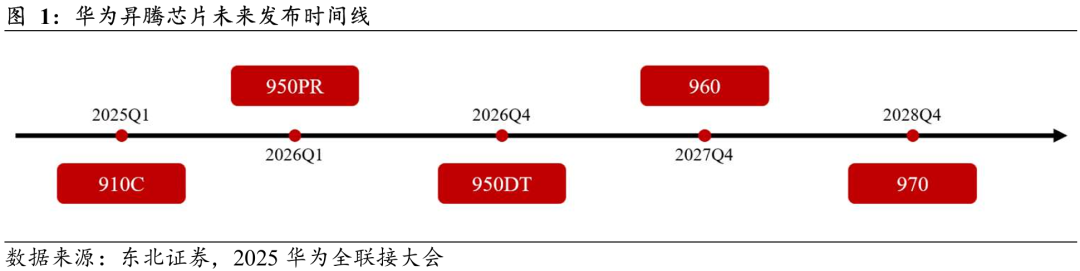
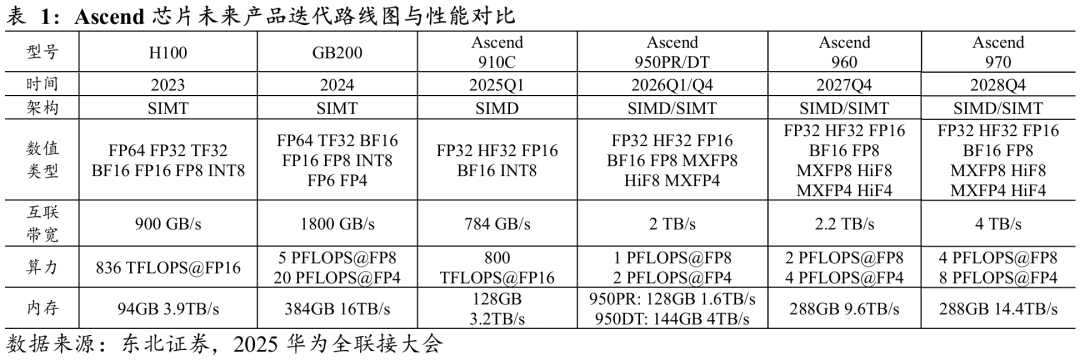
Ascend 950:低精度突破与内存自研。950芯片新增更低精度数据格式支持,包括FP8/MXFP8/HFP8(1 PFLOPS)与MXFP4(2 PFLOPS),更贴合大模型需求。架构方面提升向量算力配比,支持SIMD/SIMT,并具备更细粒度内存访问能力(从此前的512B到128B),提升带宽利用率。同时,950芯片首次引入自研HBM:HIBL 1.0(白鹭)与HIZQ 2.0(朱雀),强化自主可控。
Ascend 950PR & 950DT:场景化分工。950系列分为PR与DT两类:
1)950PR = 950 Die HIBL 1.0,PR代表Prefill & Recommendation,强化推理Prefill和推荐业务性能,面向搜索、广告、电商;
2)950DT = 950 Die HIZQ 2.0,DT代表Decode & Training,优化推理Decode与模型训练,适配生成式AI与大模型迭代。

Ascend 960:全面翻倍的跨代跃升。预计2027Q4发布的Ascend 960将在Ascend 950基础上实现全面翻倍:算力×2、内存容量×2、内存带宽×2、互联端口×2,并引入自研HiF4(最优4bit精度)。该代产品针对千亿—万亿参数规模训练优化,尤其适合大规模集群部署。

Ascend 970:算力翻倍 带宽优化。预计2028Q4发布的970延续960逻辑,在算力、内存容量、互联带宽均提升至2倍,内存带宽提升至1.5倍。
昇腾芯片发布释放三大信号,标志华为算力链短板逐步补齐:
Ø 在存储技术上,华为实现了HBM(高带宽存储器)自研突破。此前受制于禁令,国内AI芯片企业面临HBM采购困难,影响整体算力布局。昇腾新品采用自研HBM HIBL 1.0(白鹭,带宽1.6 TB/s)与HIZQ 2.0(朱雀,带宽4 TB/s),分别对应HBM2e与HBM3水准,显示国内在相关工艺上可能取得了一定进展。
Ø 在芯片战略上,华为逐步从“一颗芯片覆盖端、边、云”的全场景设计,转向针对不同场景的计算与通信需求进行优化。这不仅在昇腾芯片产品规格中有所体现,也在超节点数据中心和AI标卡等新品中得到延伸。
Ø 在架构设计上,昇腾芯片从传统SIMD向SIMD/SIMT混合架构演进,其中SIMT是NVIDIA GPU的典型模式。华为可能正尝试突破高度专用AI加速器的边界,为未来探索通用加速计算(GPGPU)铺路。
2025华为全联接大会发布《超节点发展报告》。报告指出,随着AI算力需求的爆发式增长,行业正从单纯的算力堆砌转向底层架构创新。“超节点”通过高带宽互联和系统协同,将成百上千处理器整合为一体,实现极致训练与高效推理。计算范式正在重塑产业格局与竞争力,超节点正成为AI时代的核心基础设施。
华为超节点具备高可靠性、全光互联、高带宽和低时延。超节点指的是物理上由多台机器组成,但在逻辑层面可视为一台机器进行学习、思考和推理,华为通过UB-Mesh架构实现这一设想。超节点技术既可靠又具备高性能:1)在可靠性方面,华为结合电信号稳定性与光传输优势,通过在每层协议中引入高可靠机制、为每条光路设计百纳秒级保护,并重新设计光器件、光模块及互联芯片,实现了可靠性提升约100倍,高可靠光互联距离超过200米;2)在互联性能方面,华为采用高密度封装与端口聚合,并通过对等架构消除CPU中转、协议归一化减少多协议转换,实现跨柜卡间带宽超过1TB/s、时延低于2.1微秒的高性能互联。
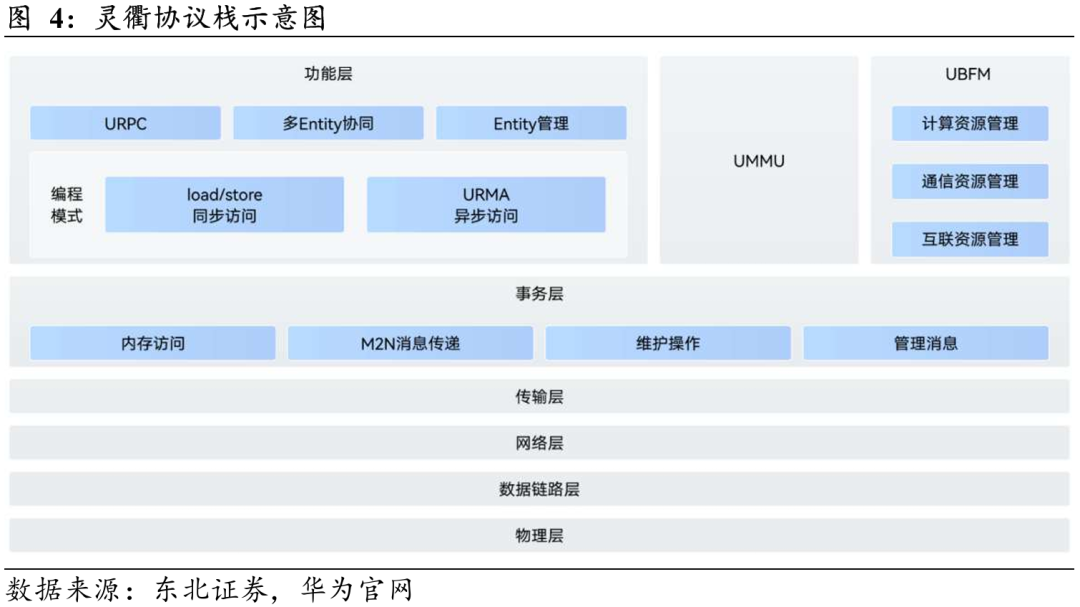
灵衢互联协议是超节点重要基石。灵衢协议(UnifiedBus)是支撑超节点结构的核心技术之一,自2019年开始研发,并在Atlas 900 A3 SuperPod上完成了灵衢1.0的商用验证。2025年华为全联接大会发布了灵衢2.0,同时推出《灵衢基础规范2.0》《灵衢固件规范2.0》和《灵衢使能操作系统参考设计2.0》等配套规范。该协议实现了总线级互联、节点平等协同、全量池化及协议归一,能够满足大规模AI计算和复杂组网需求,为超节点架构提供了核心互联支撑。
多款AI计算新品,覆盖超节点到企业级服务器。基于灵衢协议和超节点架构,华为在本次大会上推出了多款全新产品,包括全液冷数据中心AI超节点Atlas 950 SuperPoD、AI超节点集群Atlas SuperCluster系列、企业级风冷AI超节点服务器Atlas 850、AI新一代标卡Atlas 350、业界首个通算超节点Taishan 950 SuperPoD。这些产品以高带宽、低时延和超高可靠为设计核心,进一步强化了华为在AI计算及数据中心基础设施领域的市场竞争力,同时为各类规模的AI训练和推理提供了高性能、可扩展的计算解决方案。
1.2.1 超节点数据中心
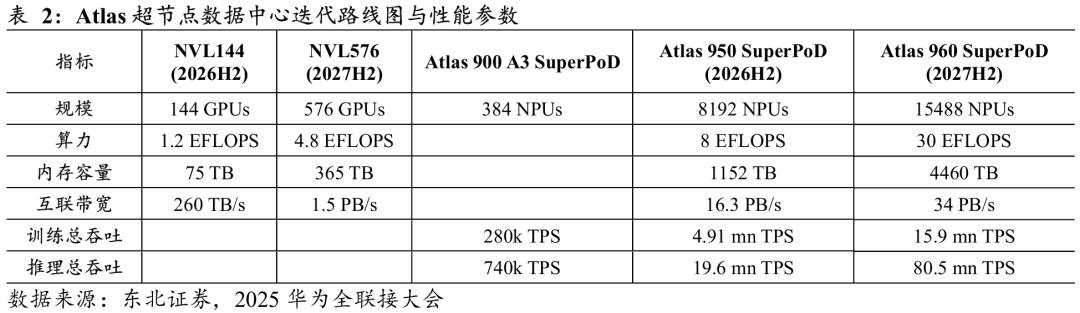
Atlas 900 A3 SuperPoD是华为当前的超节点数据中心产品,其搭载CloudMatrix384超节点,支持最多384卡互联,总算力规模达300 PFLOPS。该产品已累计部署超过300套,服务客户数量超过20家。

系统级创新重构AI算力平台,满足超大模型训练的极致算力与互联需求。本次发布的Atlas 950 SuperPoD面向超大型AI计算任务,在基础器件、协议算法及光电技术等领域进行系统级创新。首先,新算力平台通过正交架构实现零线缆电互联,并采用液冷接头浮动盲插设计确保零漏液,其独创材料与工艺使光模块液冷可靠性提升一倍。其次,在网络架构上,Atlas 950引入UB-Mesh递归直连拓扑,支持单板内、单板间及机架间的NPU全互联,可按64卡为步长灵活扩展,最大实现8192卡无收敛全互联。实际性能方面,整机算力可达8 EFLOPS@FP8或16 EFLOPS@FP4,互联带宽16.3 PB/s,支持Ascend 950DT芯片。
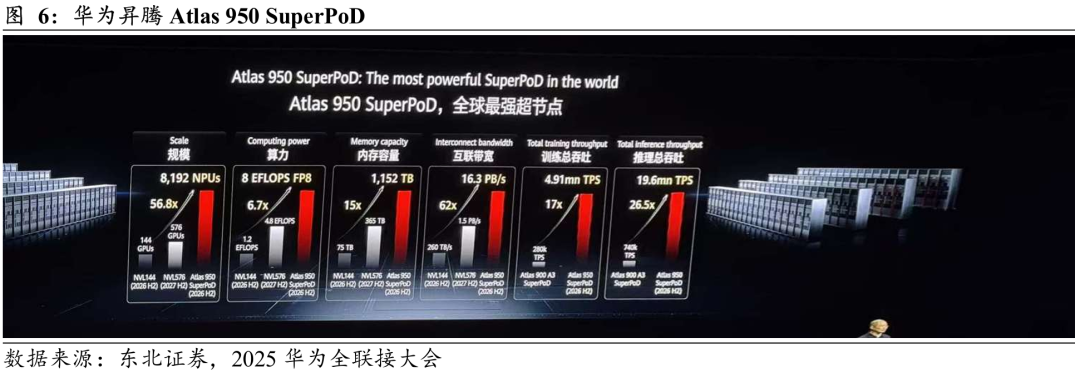
当前全球最强超节点,未来迭代路径明确。Atlas 950 SuperPoD是当前全球最强超节点,在规模、算力、内存容量、互联带宽上达到了英伟达预计2026H2发布的NVL144的56.8倍、6.7倍、15倍和62倍,在训练/推理总吞吐能力上达到了前代产品Atlas 900 A3 SuperPoD的17倍和26.5倍。未来,华为预计在2027H2发布Atlas 960 SuperPoD,该产品可支持多达15488卡互联,算力规模扩展至30 EFLOPS@FP8或60 EFLOPS@FP4,互联带宽提升至34 PB/s,支持Ascend 950DT或960芯片。

1.2.2 超节点集群
在超节点架构的基础上,华为进一步推出面向更大规模AI训练的Atlas 950 SuperCluster与Atlas 960 SuperCluster两款产品。
UB互联能够实现跨超节点的集群组网,提供更高性能且显著降低成本。以Atlas 950 SuperCluster为例,其由64个Atlas 950 SuperPod组成,总计搭载524,288颗NPU,整机算力达到524 EFLOPS@FP8或1 ZFLOPS@FP4。得益于UB互联技术,集群在性能与能效上实现了显著提升:静态时延降低23%,网络无故障运行时间增加28%,同时交换机数量减少14%、光模块数量减少26%,整体网络架构更加高效稳健。这种在算力与成本间取得平衡的设计,使得Atlas 950 SuperCluster成为面向超大模型训练与推理的高性价比选择。
1.2.3 企业级风冷AI超节点服务器
华为在企业级AI算力领域再度拓展边界,正式发布业界首个风冷AI超节点服务器Atlas 850。该产品内部搭载8颗昇腾NPU,定位于企业级模型后训练与多场景推理,旨在为用户提供即插即用的高性能AI基础设施。
设计层面,Atlas 850充分考虑了企业机房的普遍条件。单机功耗14kW,可兼容90%以上的现有风冷机房环境,无需额外改造,显著降低了部署与运维的复杂性。同时,系统支持按需扩展,用户可从8卡起步逐步扩展至上千卡集群,实现全量资源池化与统一调度。这种灵活的架构设计,使其既适配企业常规的后训练工作负载,又能支撑科研、互联网等对算力弹性要求较高的场景。
性能方面,Atlas 850在吞吐与时延指标上均较传统集群实现大幅优化。后训练吞吐量提升3倍,能够显著缩短模型迭代周期;推理时延则降低至仅10毫秒,比传统集群改善5倍,满足实时交互类AI应用的苛刻要求。在路线图上,华为还同步规划了Atlas 860,预计于2027年推出,单机FP8与FP4算力较850翻倍,显存容量亦提升至2,304 GB,进一步释放超节点架构的潜能。

值得关注的是,Atlas 850突破了风冷环境下高密度算力的散热瓶颈。其采用全方位风冷设计,从芯片到单板均配备针对性方案。在芯片散热层面,冰川冷板技术通过相变材料实现35摄氏度恒温散热,并结合针状鳍片结构提升热交换效率;在单板散热层面,免热级联架构避免了多NPU模块风路互扰,确保散热路径独立顺畅。得益于上述创新,Atlas 850整体散热能力提升超过40%。

1.2.4 Atlas 350标卡
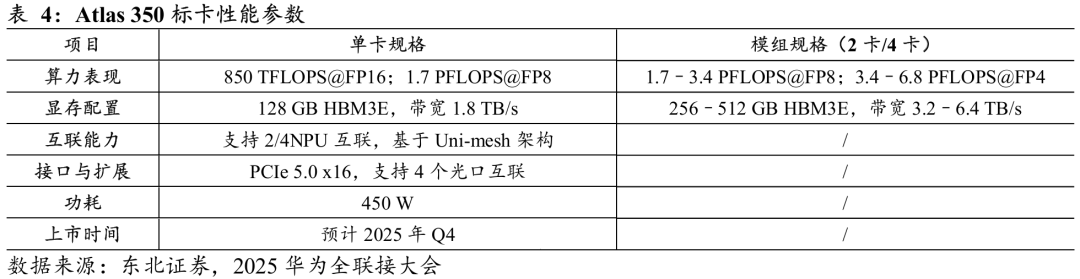
在单卡与模组架构之外,华为还针对特定业务场景推出了 Atlas 350,进一步丰富昇腾AI算力的产品层次。该产品强调多卡互联与业务灵活适配,旨在覆盖从高并发推理到大模型生成的多样化需求。
Ø 在推理场景中:Atlas 350尤其适合对延迟与并发要求较高的应用,其面向小于1B规模的模型,优化了向量计算能力与访存颗粒度,相较上一代Atlas 300I A2实现了向量算力翻倍、Cacheline访存精度提升4倍,从而有效支撑高并发低延迟的服务部署。
Ø 在多模态生成场景中:对不同模型规模具备弹性适配能力,从10B级参数的Stable Diffusion到100B级参数的DiT模型均可支持。凭借1.8倍性能提升、256GB内存和850 TFLOPS@FP16算力,Atlas 350能够满足生成类应用对迭代计算与算力弹性的双重要求。
1.2.5 鲲鹏芯片与TaiShan SuperPoD系列
在AI算力与企业级服务器持续升级的背景下,华为的鲲鹏系列芯片也在稳步演进,为超节点和高性能计算提供坚实基础。鲲鹏产品规划明确:2024年第一季度推出的Kunpeng 920提供64C、80C/160T规格,并支持HCCS;2026年第四季度的Kunpeng 950提供96C/192T及192C/384T规格,支持通算超节点并采用双线程灵犀核;2028年第一季度的Kunpeng 960高性能版本单核性能提升超过50%,面向AI主机与数据库场景,高密版本(≥256C/512T)面向虚拟化和容器场景,实现更高吞吐与并发能力。
基于鲲鹏芯片构建的全球首个通算超节点TaiShan 950 SuperPoD将于2026Q1发布,可支持最大16节点(32P)、最大内存48TB,并实现内存、SSD及DPU的资源池化。与前代产品TaiShan 200 V2相比,TaiShan 950 SuperPoD在数据库处理能力与资源利用率上均有显著提升:OLTP数据库每分钟处理事务量(tpmC)由1.85百万提升至5.4百万,性能提升约2.9倍;内存利用率由75%提升至95%;实时数据处理(TPC-DS)时间由3580秒缩短至2557秒,速度提升30%。

相关标的
此次华为发布昇腾芯片、企业级超节点服务器、超节点数据中心、超节点集群等一系列产品,这些产品在性能上逐步向行业领先水平靠拢,华为算力链此前的潜在不足也逐步解决(例如HBM、单一ASIC架构),同时我们也看到了华为在全局系统性优化上的厚积薄发。展望未来,我们看好华为算力链将继续快速迭代,为国产算力提供了持续的替代方案。在这一背景下,我们整理了以华为为核心的昇腾上游产业链标的:1)代工:国内相关晶圆厂;2)铜连接:华丰科技;3)光连接:华工科技;4)电源:泰嘉股份;5)PCB:方正科技,深南电路,南亚新材、生益电子、广合科技等;6)散热:飞荣达、英维克、申菱环境、中航光电等。
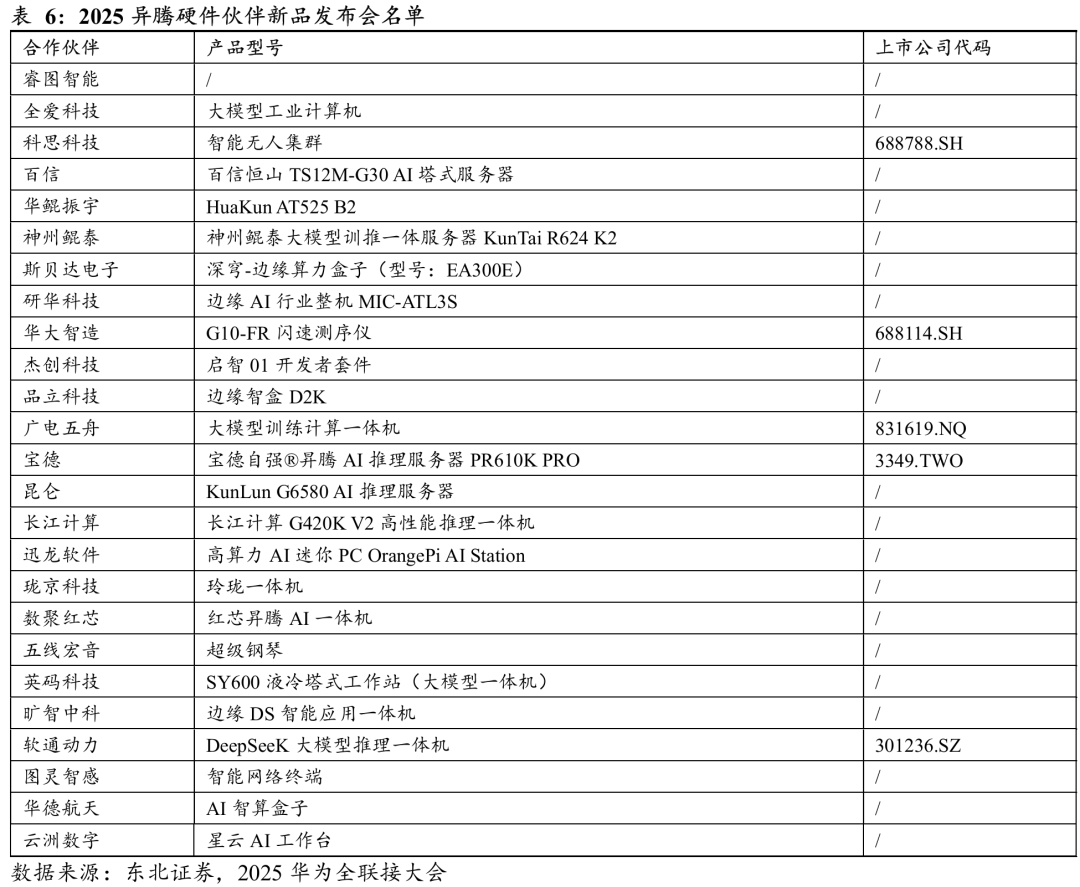
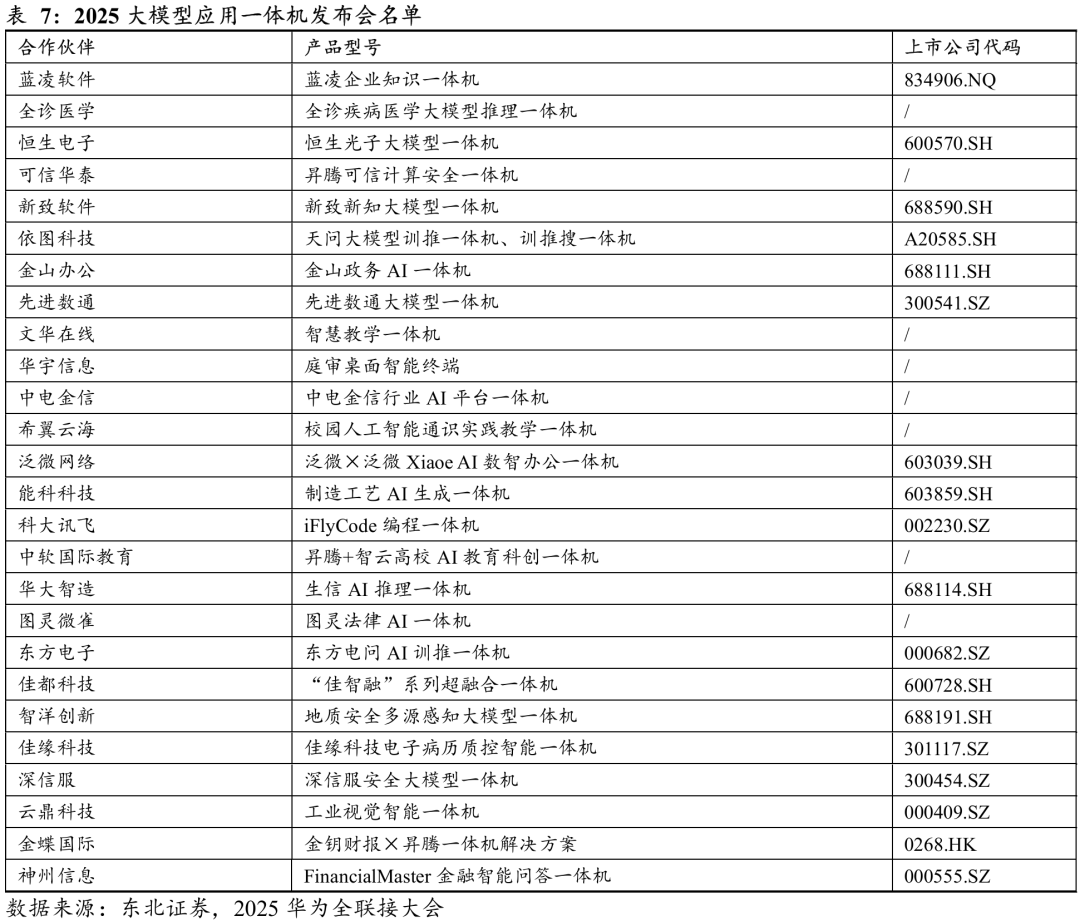
为进一步观察华为生态在AI计算和应用层面的布局,本次大会中多款硬件与大模型应用产品的发布值得重点关注。下表列出了2025年异腾系列硬件新品及大模型应用一体机的发布情况。相关标的包括科思科技、华大智造、广电五舟、软通动力、蓝凌软件、恒生电子、新致软件、依图科技、金山办公、先进数通、泛微网络、能科科技、科大讯飞、华大智造、东方电子、佳都科技、智洋创新、佳缘科技、深信服、云鼎科技、金蝶国际、神州信息。


 VIP复盘网
VIP复盘网
