

2026年3月12日,小米联合清华大学、澳门大学发表论文《LaST-VLA: Thinking in Latent Spatio-Temporal Space for Vision-Language-Action in Autonomous Driving》,提出一种隐时空VLA,在难度最高的自动驾驶测试benchmark之NAVSIM v2上EPDMS得分高达87.1,NAVSIM v1上的PDMS得分91.3,在全球范围内都是第一。
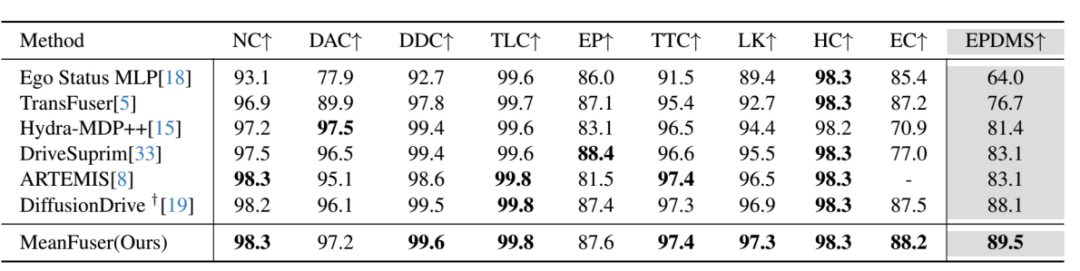
此外,小米还联合中科院发表论文《MeanFuser: Fast One-Step Multi-Modal Trajectory Generation and Adaptive Reconstruction via MeanFlow for End-to-End Autonomous Driving》,提出一种新颖的非VLA的传统分段式端到端算法,EPDMS得分高达89.5,整体参数还不到6千万,帧率可达59Hz,无论是性能还是效率均是全球第一。
今天我们主要来看小米的隐时空VLA。LaST-VLA论文共有13位作者,其中小米汽车11位,澳门大学1位,小米汽车同时也是清华大学的1位,小米汽车徐少清为项目领导。
图片来源:小米汽车
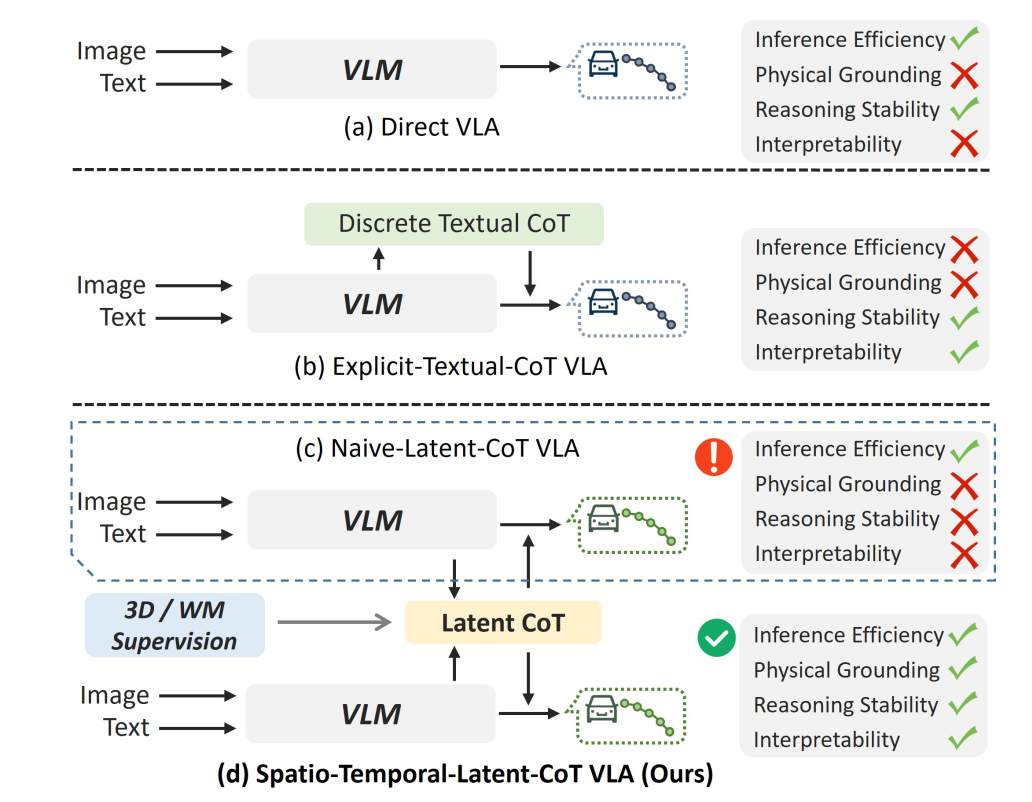
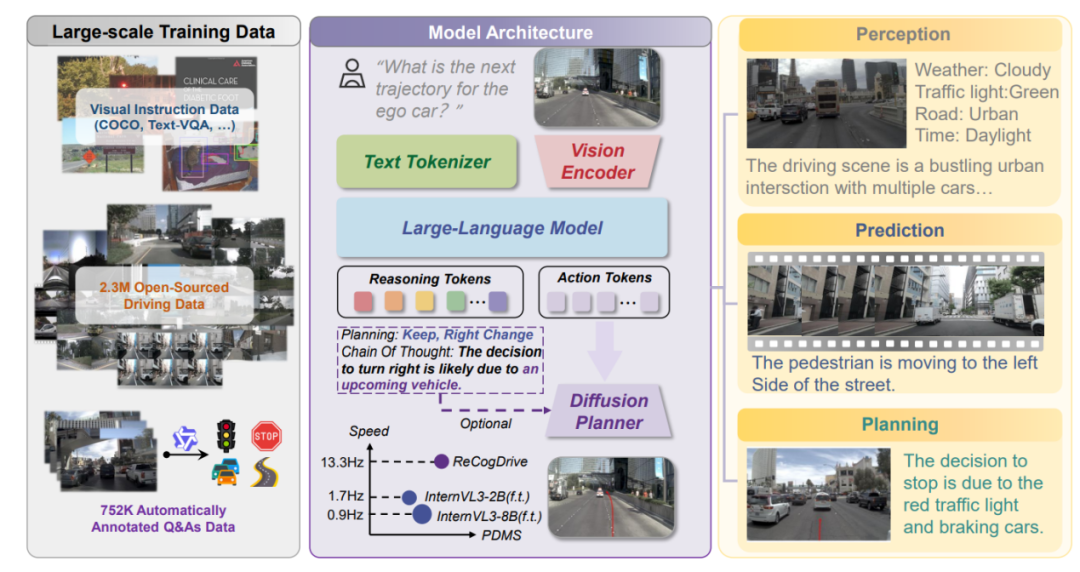
视觉-语言-动作(VLA)模型通过统一感知和规划彻底改变了自动驾驶,但它们对显式文本思维链(CoT)的依赖导致了语义-感知解耦和感知-符号冲突,降低了效率,还容易出现脱离物理基础的幻觉。最近向隐式(潜在)推理的转变试图通过在连续的隐藏空间中思考来绕过这些瓶颈。然而,连续的隐性向量(Latent Vectors)本质上是高维空间中的黑盒数字,若不加物理显式约束,模型根本不会在这些向量中进行“物理思考”,而是会变成毫无意义的噪声。为此,小米为隐性思维链添加了两重约束,一层约束是3D几何约束,另一层是世界模型推理约束。同时小米还加入了基于GPRO的强化学习微调,最终取得了VLA领域第一名。
小米LaST-VLA算法框架
图片来源:小米汽车
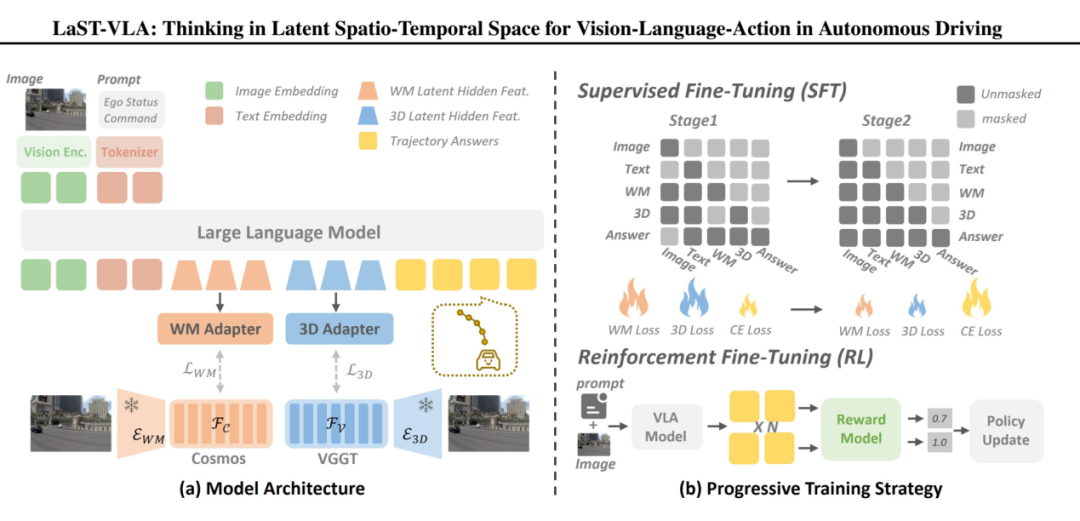
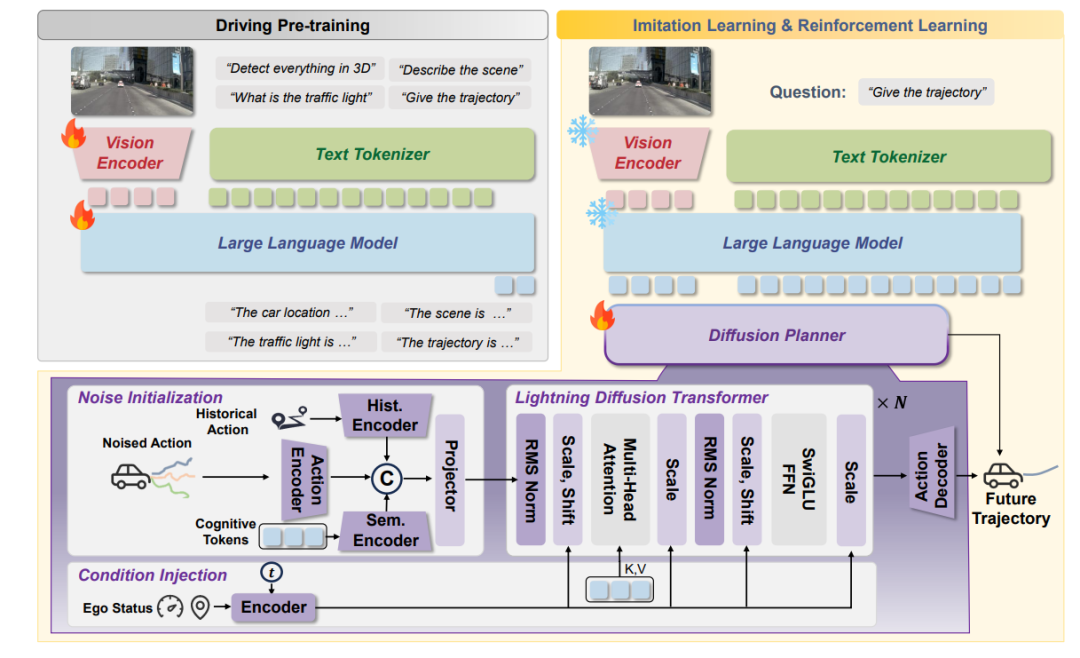
传统的端到端自动驾驶 VLM(视觉-语言-模型)通常直接将图像特征和文本提示映射为动作(轨迹),如果加入文本思维链(Textual CoT),则是先生成一段文字描述,再生成动作,这会导致极高的推理延迟。LaST-VLA 放弃了离散的文本Token,转而使用连续的隐变量向量(Latent Vectors)作为“思考”的载体。它将整个推理过程解耦为两个阶段:第一阶段是思考者,第二阶段是轨迹规划者。模型首先作为“思考者”生成连续的推理状态 ,然后作为“规划者”在这些物理先验的条件下预测轨迹路点waypoint。
Thinker (思考者阶段):模型首先生成一系列特殊的Latent Tokens,记为H。为了赋予这些向量明确的物理意义,作者将其强制划分为两部分,H1负责理解静态的3D空间结构(如车道线、可行驶区域、静态障碍物),H2 (时间动态思考向量):负责预测动态的时空演变(如周围车辆的未来轨迹、行人的意图)。
为了给H1和H2有确定的显性约束,传统方法通常依赖密集的像素级重建(如预测深度图或未来视频帧)来学习物理规律,这会带来巨大的计算开销并引入大量无关的纹理细节 。LaST-VLA 引入了外部基础模型(Foundation Models)作为“教师”,进行特征级别的知识蒸馏。这种约束也可以理解为learning,也可以理解为对齐即Adapter。
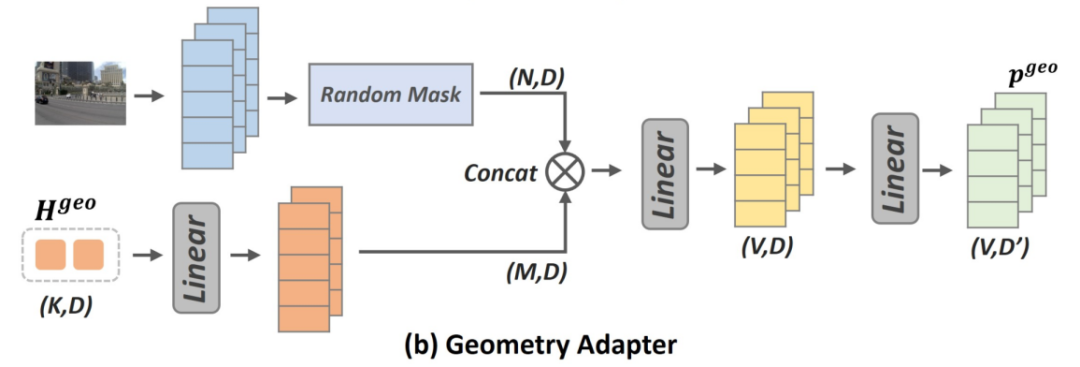
3D几何对齐
图片来源:小米汽车
3D几何对齐,赋予模型3D感知能力,使用预训练的3D视觉基础模型(如VGGT),提取当前图像的3D/BEV(鸟瞰图)特征表示设计一个轻量级的多层感知机(MLP)作为适配器。将模型生成的几何思考向量H1和原始图像特征输入适配器,预测出3D特征,使用均方误差(MSE)强迫预测的特征逼近真实的3D特征。
VGGT是META提出的一种感知框架,在3D视觉领域,不同任务之间往往被模型架构所隔离——估相机、做深度、建点云,各用各的网络,协同效率低下。Meta AI的研究打破了传统界限,提出了一个统一的几何感知框架 VGGT(View Generalizable Geometry Transformer),可以从任意数量的视图中直接推理出相机参数、点云、深度图、三维轨迹等全部关键3D属性。VGGT 不仅可用于标准几何任务,在作为特征骨干网络时,同样能大幅提升点跟踪与新视角合成等下游任务表现。因此荣获CVPR 2025最佳论文。
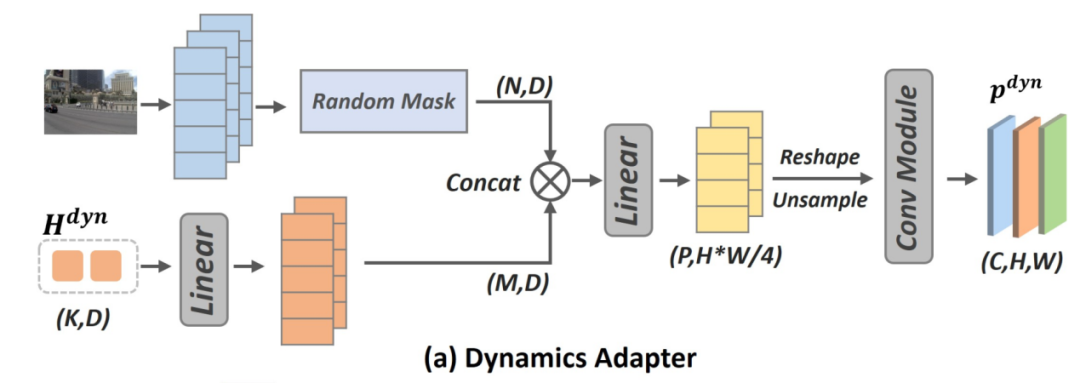
动态对齐
图片来源:小米汽车
教师模型:使用预训练的视频生成模型/世界模型(如 Cosmos),提取包含未来时空演变信息的特征。对齐过程:同样设计一个适配器 ,输入动态思考向量H2 和图像特征,预测世界模型特征。这里小米应该是直接用了Cosmo,没错这就是英伟达的世界模型,Cosmos 世界基础模型是在 9,000 万亿个token(包括来自自动驾驶、机器人、合成环境和其他相关领域的2,000万小时数据)上训练而成的预训练大型生成式 AI 模型。这些模型能够创建逼真的环境和交互式合成视频,为训练复杂的系统(从执行高级动作的人形机器人仿真到端到端自动驾驶模型的开发)提供了一个扩展自如的基础。
如果仅仅上述的对齐损失,神经网络通常会“偷懒”或者说走捷径(Shortcut learning)。在预测最终动作时,模型可能会直接越过潜思考向量H1和H2,直接去关注(Attend to)原始的图像特征,导致H1和H2都白做了,变成摆设。为解决这个问题,LaST-VLA 在Transformer 的注意力机制中引入了结构化因果掩码:在计算 Self-Attention 时,强行切断动作Token对原始图像Token的注意力连接。动作Token只能看到系统提示词(Prompt)和潜思考向量H1和H2。这在网络中制造了一个信息瓶颈(Information Bottleneck)。模型如果想做出正确的驾驶动作,就必须把所有关键的视觉信息压缩、提取并转移到潜思考向量H1和H2 中。这从架构底层保证了Latent CoT的有效性。
SFT监督微调存在“协变量偏移”(Covariate Shift)问题,即微小的误差会随着时间累积导致灾难性后果。为了让模型学会在长时序下安全驾驶,LaST-VLA 引入了强化学习。
冻结与解冻:冻结用于特征对齐的适配器(保持其物理直觉),解冻VLM的主干网络。
算法选择:采用 GRPO (Group Relative Policy Optimization)。相比于传统的PPO,GRPO不需要训练一个与策略网络同等大小的价值网络(Value Network),极大地节省了显存,非常适合大语言模型的RL微调。
奖励设计(Reward Design):直接使用自动驾驶仿真器(如NAVSIM)的闭环评测指标作为奖励信号。奖励函数综合考虑了:轨迹跟踪:与专家轨迹的相似度。安全性如TTC(碰撞时间),距离障碍物越近惩罚越大。合规性:如DAC(可行驶区域合规性),压线或驶出道路给予惩罚。
在核心VLM选择上,小米汽车没有选择主流的Qwen-2.5-VL,而是选择不太常见的书生万象InternVL3,这是上海人工智能实验室在2025年4月推出的VLM大模型,InternVL3分监督微调SFT和强化学习RL两个版本,小米汽车选用了20亿参数和80亿参数两个版本做测试。
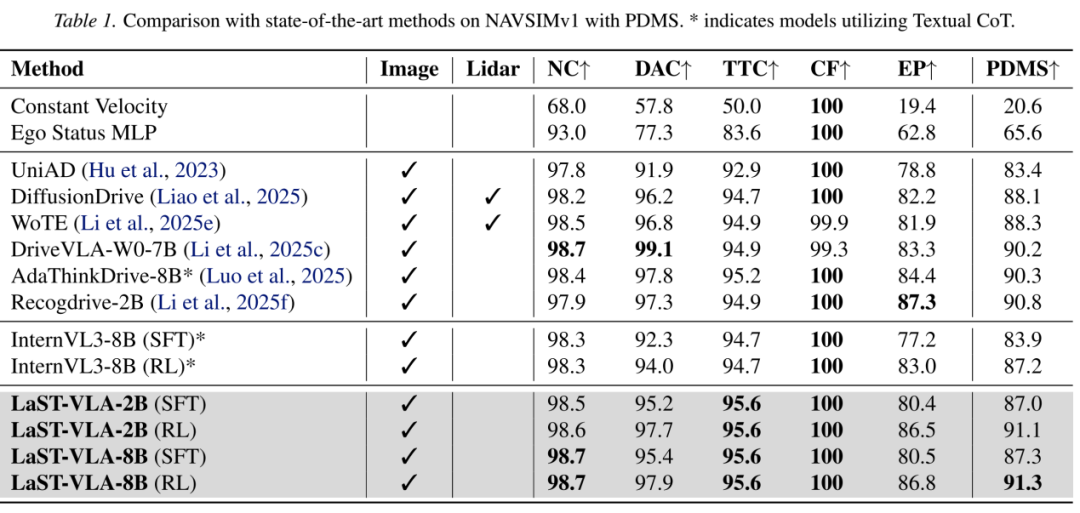
数据来源:小米汽车
NAVSIM v1上的测试成绩,LaST-VLA-8B (RL)的PDMS得分91.3,是目前已知最高得分,此外Recogdrive-2B的成绩也非常不错,与LaST-VLA相差无几,这个也是小米汽车的成果,也是基于InternVL3-2B,不过这个成果主要是和华中科技大学联合取得的。
Recogdrive概览
图片来源:小米汽车
Recogdrive在训练数据和路径规划者上下功夫。小米精心构建了一个包含310万条高质量驾驶问答对的数据集(包括处理开源的驾驶数据集以及通过搭建的自动标注流水线进行生成),用于对VLMs进行驾驶领域预训练,使其深度理解真实驾驶场景。LaST-VLA是否用了这个数据集做监督微调不得而知,如果用了的话,那么LaST-VLA的进步程度非常有限。
Recogdrive模型框架
图片来源:小米汽车
很明显采用了DiT扩散路径规划器,Recogdrive也是用了强化学习增强,至于LaST-VLA是否使用扩散路径规划器,论文里未明说,估计是没有,因为DiT扩散路径规划器差不多也要有3-5亿的参数,消耗运算资源较多。不过这也证明了DiT扩散路径规划器很强大,3D几何信息和世界模型知识蒸馏对性能的提升基本上和DiT扩散路径规划器差不多。
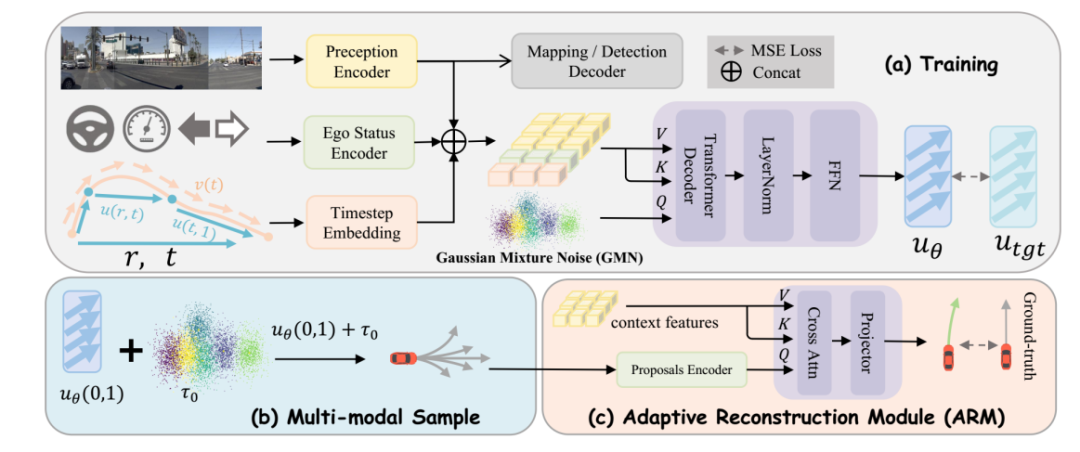
小米汽车与中科院自动化研究所的MeanFuser模型框架
图片来源:小米汽车
小米这里引入了MeanFlow概念,这是华人AI大神何凯明的作品,是继扩散模型生成式AI之后的更加先进效率更高的模型,基于扩散模型(Diffusion Models)或流匹配(Flow Matching)的生成模型虽然效果好,但在采样(生成图片)时通常需要执行数百甚至上千步迭代,速度较慢。近期的研究致力于减少采样步数,甚至实现一步生成。
MeanFlow 的核心思想是引入并建模平均速度(average velocity)的概念,这与Flow Matching中通常建模的瞬时速度(instantaneous velocity)不同。平均速度表示在一段时间间隔内的总位移除以时间间隔。从平均速度的定义出发,推导出了一个关键的「MeanFlow 恒等式」(MeanFlow Identity),它描述了平均速度与瞬时速度及其时间导数之间的关系。训练一个神经网络来直接预测这个平均速度场,并使用 MeanFlow 恒等式作为训练的指导目标。与之前的一步生成模型(如 Consistency Models)相比,MeanFlow 基于一个由底层真实场(瞬时速度场)导出的原理性恒等式进行训练,而非依赖于对神经网络输出施加启发式的一致性约束。这使得训练更稳定,并且无需预训练、知识蒸馏或课程学习。
MeanFuser网络架构主要由以下三个关键模块构成:
高斯混合噪声(GMN)引导的连续采样,为了消除对固定离散词表的依赖,并解决标准高斯噪声采样引起的模式崩溃问题,MeanFuser引入了高斯混合噪声来引导生成式采样。GMN实现了轨迹空间的连续表示。每个高斯分量捕捉一种独特的驾驶模式,有效增强了模型表达多模态行为的能力,同时保留子模式下的局部不确定性建模能力。
引入MeanFlow Identity实现单步极速生成,传统的流匹配技术通常依赖瞬时速度场,在推理时极易受到常微分方程(ODE)求解器数值误差的干扰,导致轨迹质量下降且耗时较长。MeanFuser突破性地将MeanFlow Identity引入规划任务。直接建模GMN与真实轨迹分布之间的平均速度场,从数学根源上消除了ODE求解带来的数值误差。大幅提升生成轨迹的平滑度与质量,更实现Fast One-Step(单步)生成,将推理延迟降至最低。
为了在多模态输出中确保最终执行轨迹的安全性,MeanFuser设计了一个轻量级的自适应重构模块(Adaptive Reconstruction Module, ARM)。在常规情况下,ARM通过注意力权重隐式地从所有单步采样的候选轨迹中评估并挑选出最优解;而在所有采样候选均存在风险的极端长尾场景下,ARM能够自适应地重构出一条全新的安全轨迹。
数据来源:小米
MeanFuser的EPDMS成绩高达89.5,这也说明现阶段传统基于规则的分段端到端还是比VLA要强。
数据来源:小米
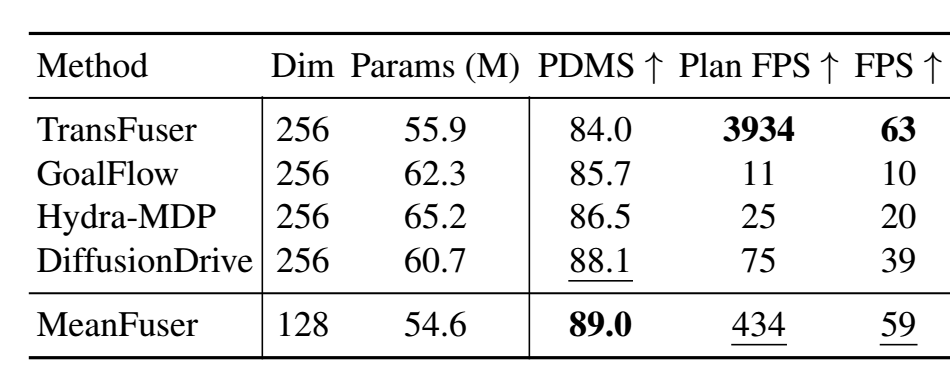
MeanFuser的参数仅仅只有5460万,而VLA模型最少都要20亿,VLA消耗的运算资源至少是MeanFuser的20倍以上。然而致命缺点是不太方便宣传,普通人乃至部分业内人士都认为VLA理论上更高大上。
小米汽车的研发能力非常出众,连续有高质量的论文输出,在新兴车企中表现十分亮眼

 VIP复盘网
VIP复盘网
