

前几天,总部设在巴黎的世界模型(World Models)公司AMI宣布完成10.3亿美元种子轮融资。成立才3个月,投前估值已达35亿美元,这三组数字,足以颠覆认知。
AMI总部有意设在巴黎,不是硅谷,不是北京。杨立昆明确表态,要将欧洲打造成为中美之外的AI第三极。
此前的2月18日,AI“教母”李飞飞创办的世界模型公司World Labs,也官宣完成10亿美元融资,市场预估投后估值达50亿美元。
作为AI领域两大泰斗---杨立昆与李飞飞,短期内相继押注世界模型、斩获巨额融资。其背后是顶级人物、顶级资本与顶级技术路线的三重联合,押注AI的下一个未来。
世界模型赛道正式爆发,将替代过渡的大语言模型(LLM),成为AI和算力的新战场!
今天我们来研究世界模型。下文从:① 世界模型-基础知识扫盲;② 主要流派&技术指标解析;③ 产业链&代表厂商;④ 总结&挑战,等四个维度来解析。

简单来说,世界模型就是给AI装上了一个“人类级别的大脑模拟器”:人类闭眼就能想象“扔球→落地→弹起”“开门→迈步→进门”的完整过程,预判动作的后果;世界模型就是让AI拥有这种能力——不是只会描述文本、生成画面,而是真正理解世界如何运转,在“脑内”预演未来、规划最优动作。
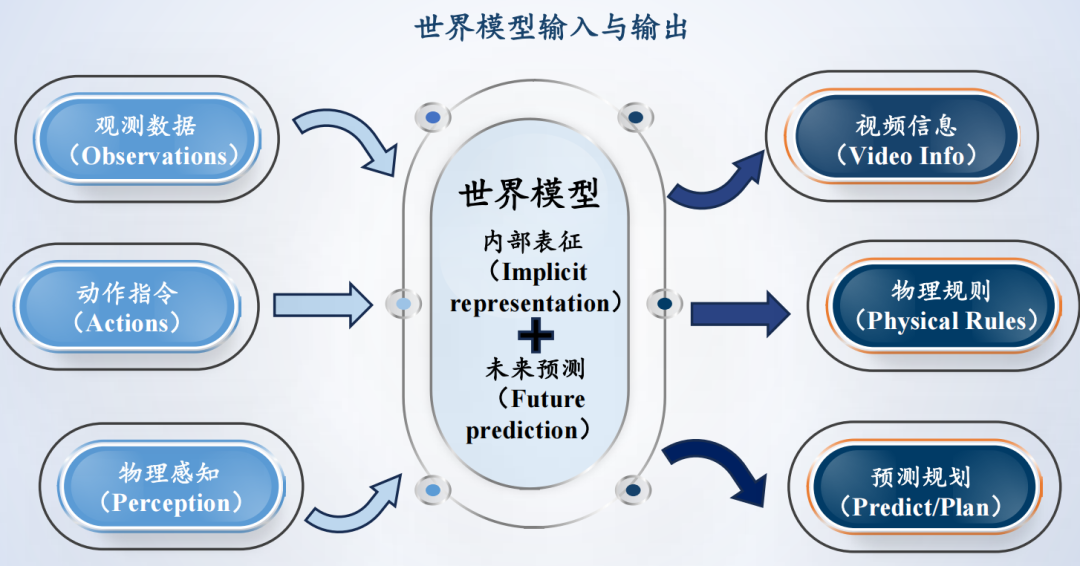
(1)高维压缩(懂归纳)
① 去伪存真:从复杂的视频像素中剔除树叶摆动、光影闪烁等冗余噪声。② 特征提取:将环境精炼为包含关键实体(如人、车、障碍物)的抽象状态。 ③ 认知建模:用最精简的数学向量代表当前世界,为 AI 的逻辑推理和决策提供高效的底层数据。
(2)前向预测(能预判)
① 时空推演:基于“当前状态 预定动作”,在脑内自动演算出未来的环境演变。② 多路径预判:能够意识到未来的不确定性,并给出多种可能发生的潜在场景。③ 消除延迟:通过预判未来走向,让 AI 能够克服传感器延迟,实现更具前瞻性的实时反应。
(3) 物理常识(守规律)
① 内化法则:自动领悟重力、碰撞、遮挡等物理规律,确保预测结果符合因果逻辑。② 维持恒常: 确保物体在运动或被遮挡时,其形状、位置和材质保持连续,不产生逻辑幻觉。③ 物理对齐:让 AI 从单纯的“像素模仿”进化到对物理世界客观真理的本质理解。
(4)内部仿真(可试错)
① 脑内梦境:允许智能体在虚拟的“内部模型”中进行千万次强化学习,无需在现实中付出事故代价。② 长程规划:在行动前先进行全流程沙盘推演,评估不同决策的后果,从而选出安全、最优的执行路径。③ 反事实优化:通过复盘“如果没有这样做会怎样”,让 AI 具备在虚拟思考中快速自我进化迭代的能力。
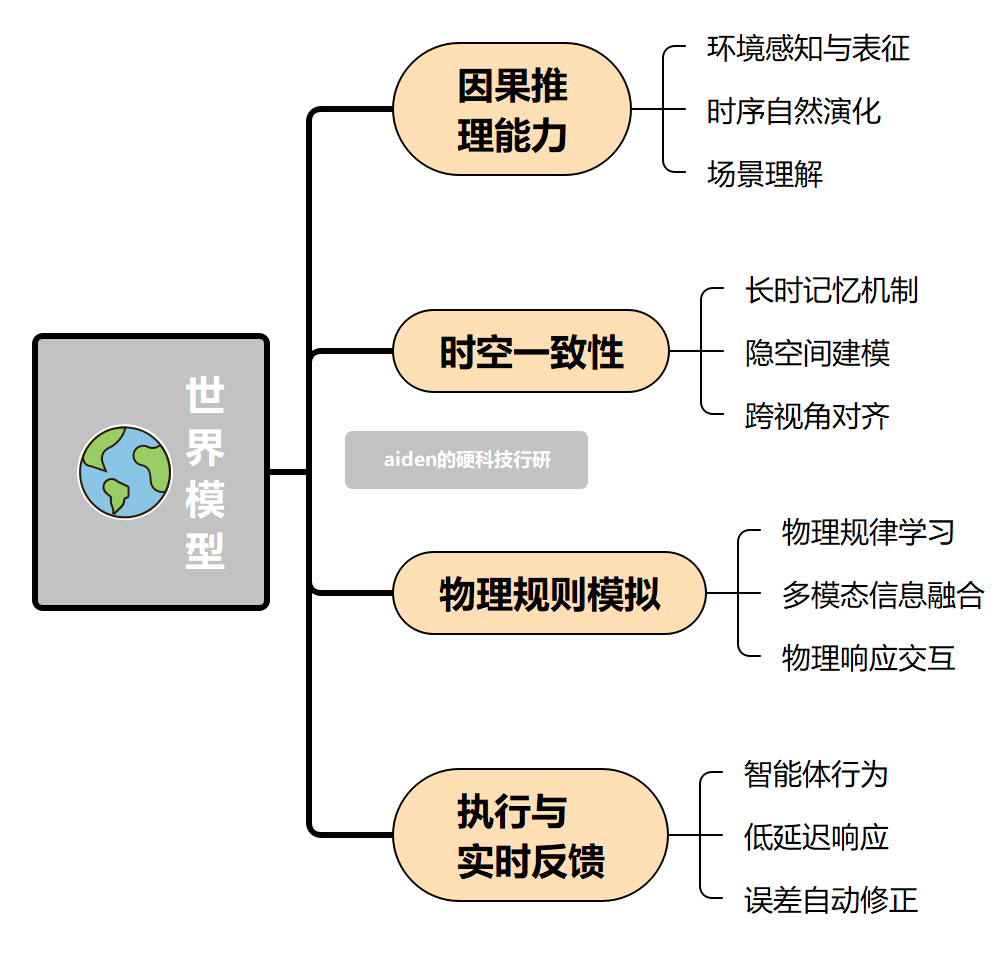
(1) 因果推理能力:不只是统计数据间的相关性,而是能判断事件之间的因果关系,能判断“做A会导致B”。它可以区分“先后发生”和“必然导致”,从而做出更可靠的决策与预测。
(2)时空一致能力:在生成长序列(如长视频、自动驾驶长轨迹)时,保持物体结构、光影和物理状态的一致性。在时间和空间上保持场景、物体状态的连续与稳定,不会出现位置突变、时序颠倒。让AI对世界的认知符合人类真实的时空规律。
(3)物理规划模拟:模拟复杂的物理规则仍然是一项极具挑战性的任务,现实世界中的流体运动、物体碰撞等物理现象涉及到大量的参数和变量,具有高度的非线性和不确定性。在模型内部构建3D场景下的重力、碰撞、受力、运动等物理规则,可在脑中预演动作与环境交互的过程。通过模拟规划出合理路径,避免现实中盲目试错。
(4)执行与实时反馈:在真实世界中,获取实时的交互数据面临诸多困难,难以获取足够丰富和多样化的数据。而世界模型通过结合强化学习,可根据感知到的真实环境变化,实时修正模型预测与动作指令。形成“感知—模拟—执行—调整”的闭环,适配动态、不确定的真实场景。
当下的AI大模型,如GPT、豆包大多是感知 统计拟合,只能复现数据里的模式,本质上是高级的“词汇接龙”游戏。它们懂“重力”、“碰撞”这些词在文本中的概率分布,但根本不理解这些概念在物理世界中的实际意义。没有对物理规则、因果关系、常识逻辑的内在建模,因此不会规划、不会推理、不会泛化到没见过的场景。
世界模型的核心是补齐物理建模、实时推理、泛化能力的短板,其成熟度直接决定产品能否商业化落地。这不仅是技术、更是商业、进化的问题。
(3) 突破人类文本数据的枯竭瓶颈
科学家预测,人类留在互联网上的高质量文本数据在未来几年内就会被大模型“吃干榨净”。如果仅仅依赖文本,AI 的智商提升将停滞。
而世界模型的价值在于, 真实世界的视觉、听觉和空间交互数据是无限的。世界模型通过观察海量无标注的视频、通过视觉、力觉、触觉等传感器采集真实数据,去自己领悟世界的物理运行规律和逻辑,做出正确的预测和判断。这被认为是通向人类级别智能(AGI)的下一座金矿。
VLN:看图 文本,负责“导航指令理解”
VLA:看图 文本 动作,负责“直接动手”
World Models:懂物理 时空 因果,负责“脑内模拟、预判未来”。
(1) LLM(Large Language Model,大语言模型)
LLM的核心是文本token预测,语言理解、知识、推理、规划。可以完成写代码、聊天、逻辑推理、任务拆解。是AI的“语言中枢/逻辑中枢”。
但其短板是,没有物理常识、没有空间感、看不见世界,全靠文字脑补。代表:GPT、gemini、Deek Seek、豆包、阿里千问等。
(2)VLN(Vision-Language Navigation,视觉语言导航)
VLN其核心是图文对齐 路径导航,是早期具身智能的经典范式。特点是只解决“按指令走到目标点”,不建模完整世界,不做长期物理预测。VLN是VLA的前身,机器人导航专用模块。
VLN输入的是自然语言指令,如输入“走到客厅拿水杯”) 视觉图像。可输出导航动作(前进、左转、右转、停止)。 代表如 RxR、Env-Emb、DUET、谷歌/斯坦福早期机器人导航模型。
(3) VLA(Vision-Language-Action,视觉-语言-动作模型)
VLA输入的是文本指令 图像/视频 状态,可输出连续动作、轨迹、关节角、抓握指令。其核心是端到端“看-懂-做”,直接输出机器人关节/控制指令。
其特点是多模态映射,不强调内部建模世界, 泛化强,但偏“黑箱响应”,不懂物理因果。是机器人的“反射神经/执行层”。代表有 Google RT-2、Figure Helix、π0.6、银河通用AstraBrain、千寻智能 Spirit V1.5等。
(4)World Models(世界模型)
而世界模型的核心是对环境的时空、物理、因果结构建模 未来预测。其特点是内置物理规则、空间结构、时序演化,可“脑内预演”,是真正的认知与决策核心。是机器人的“大脑模拟器/世界认知内核”。
输入的是多模态观测(视觉、雷达、力觉); 输出的是内部状态表征、未来状态预测、规划结果。
(1)自动驾驶--最成熟,最先落地
自动驾驶是当前世界模型商业化成熟度最高的场景,也是唯一实现百万级设备规模化部署的赛道。
传统自动驾驶只会“看路”,不会预判、不会推理,极端场景如暴雨天鬼探头、无保护左转、加塞容易失效,无法适配复杂的开放道路环境,控制精度不足,训练成本极高。
而世界模型可以:① 构建道路4D时空模型,预判车辆/行人5–10秒行为;② 支持虚拟仿真训练,不用海量路测就能练出强泛化能力;③ 实现「传感器输入→世界模型建模→控制指令输出」的端到端闭环,消除模块间的误差传递,大幅提升决策的稳定性与鲁棒性更安全、更像人类开车。
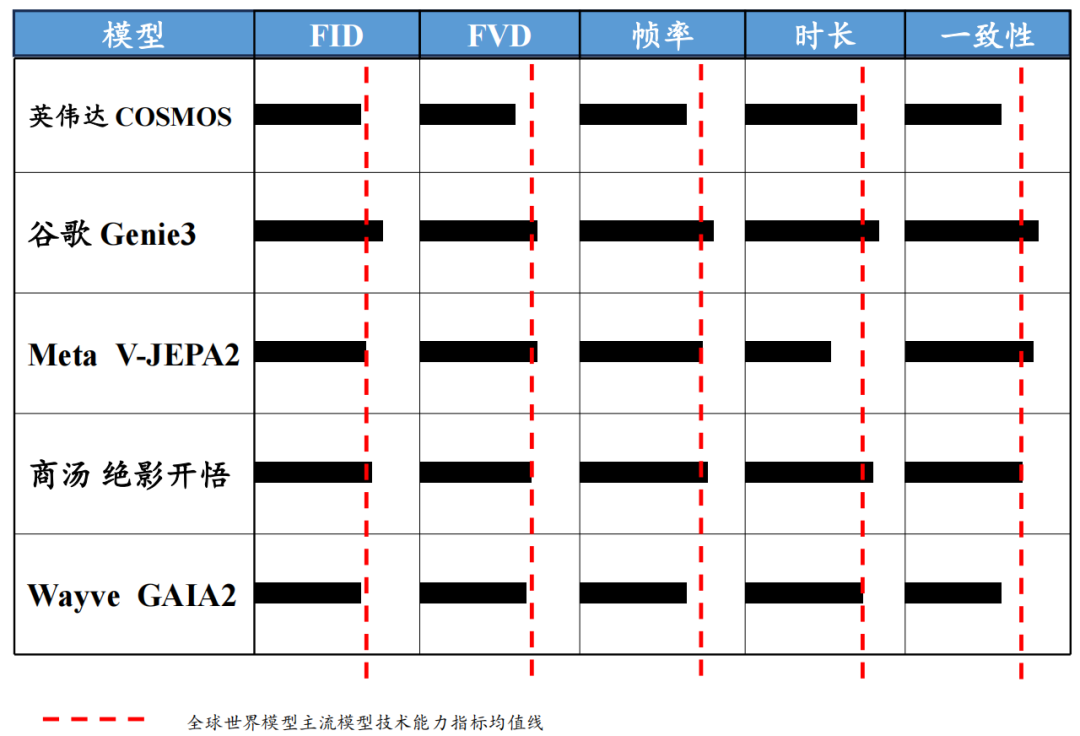
世界模型是高阶自动驾驶(L4/L5)的必选项。代表案例是谷歌的Genie 3、英伟达Cosmos、英国自驾公司Wayve 的GAIA-1 ;另外华为WEWA、蔚来的NWM、商汤“绝影开悟”世界模型等。
下图:深蓝S09搭载的乾崑智驾ADS 4采用全新WEWA世界模型架构:

(2)机器人&具身智能--终极战场,人形机器人必备
机器人是世界模型最具长期价值的场景,也是杨立昆、李飞飞等顶级科学家下场创业的核心目标 —— 世界模型是通用人形机器人从「专用设备」走向「通用智能体」的唯一路径。
传统机器人只会重复动作,环境一变就废,环境适配能力为零;且不会规划;无法理解物体的材质、重量、摩擦系数等物理属性,抓握鸡蛋要么捏碎、要么抓不住,拧瓶盖要么拧不开、要么拧变形,不会精细操作,泛化性极差。
世界模型可以:① 实时3D空间 物理建模,懂重量、材质、碰撞;② 支持脑内预演任务(倒水、做饭、收拾),长时序规划;③ 零样本适应新环境,不用重新编程。
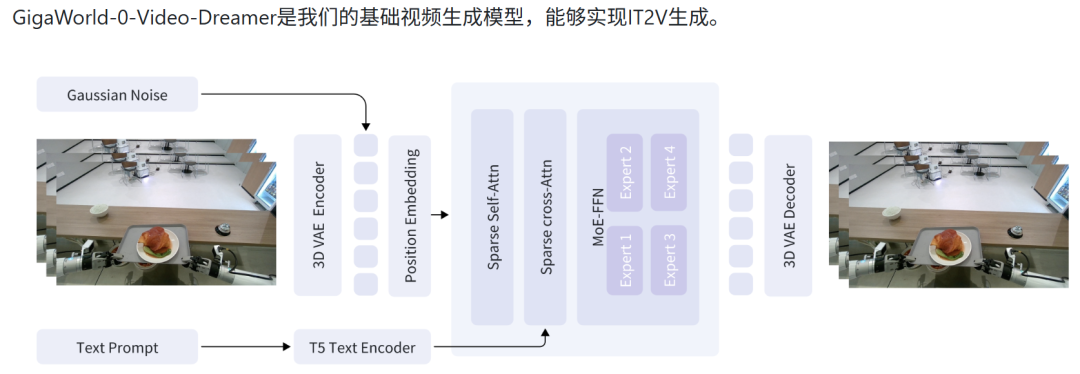
代表:李飞飞的World Labs3D空间智能世界模型、LeCun的JEPA系列模型、极佳视界的Giga-Brain、星动纪元的Ctrl-World、智澄AI、流形空间的Manifold AI、无界矩阵Evogen-verse等。
下图:GigaWorld-0-Video-Dreamer世界模型
(3)游戏与AR/VR--C端最快,体验革命
传统游戏与AR/VR内容贵、NPC死板、AR/VR穿模、延迟高易晕。
而世界模型在游戏与虚拟现实中扮演着核心角色。它用于构建虚拟环境的逻辑与物理规则,使玩家能与动态场景互动。通过世界模型,系统可模拟重力、碰撞、光照等真实效果,提升沉浸感。同时,它还支持AI角色的行为决策,推动剧情发展,而且文本一键生成无限开放物理世界,成本大降。
在AR/VR中,世界模型可实现真实物理交互,不穿模、不漂移,增强用户体验的真实性与连贯性。如苹果Vision Pro、Meta Quest、NVIDIA Omniverse等。
(4)科学模拟--最有价值,人类科研加速器
在气象学、流体力学、分子生物学等自然科学领域,传统研究依赖求解极其复杂的偏微分方程,计算成本极其高昂。世界模型通过深度学习系统化地掌握了这些复杂系统的动力学演化规律。它可以直接在数据层面进行 AI 推理,以数万倍的速度替代传统的数值计算,同时保持高度的物理保真度,从而加速科学发现的进程,预测更快、更准,提升100-1000倍。
代表公司: Google DeepMind的气象大模型 GraphCast 能够在一分钟内预测未来 10 天的全球天气;AlphaFold 3 实现了对所有生命分子结构及其相互作用的预测。英伟达的Earth-2 气候数字孪生平台,结合 AI 与物理模拟进行全球气候预测;FourCastNet 天气预测模型。
总之,世界模型让AI拥有“物理常识 预判未来 脑内模拟”。
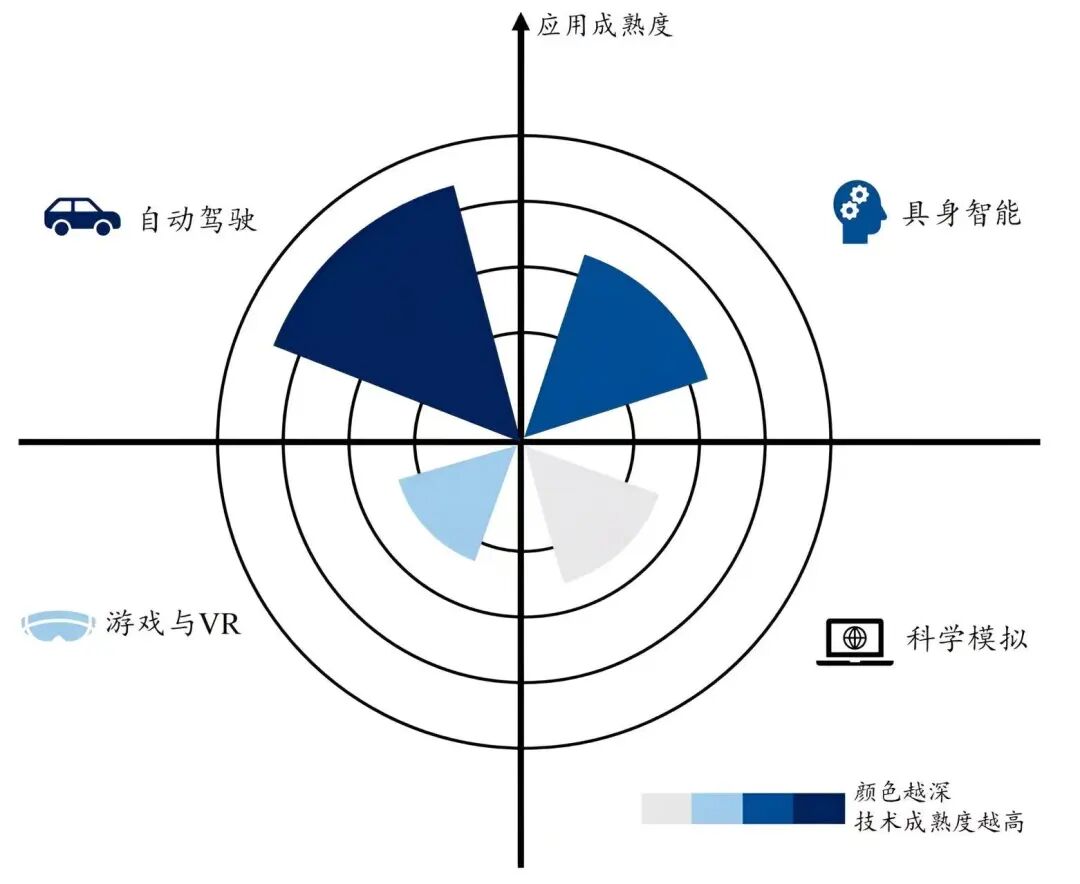
落地场景顺序预测:自动驾驶 → 游戏/AR/VR → 工业机器人 → 科学模拟 → 家用人形机器人。如下图:
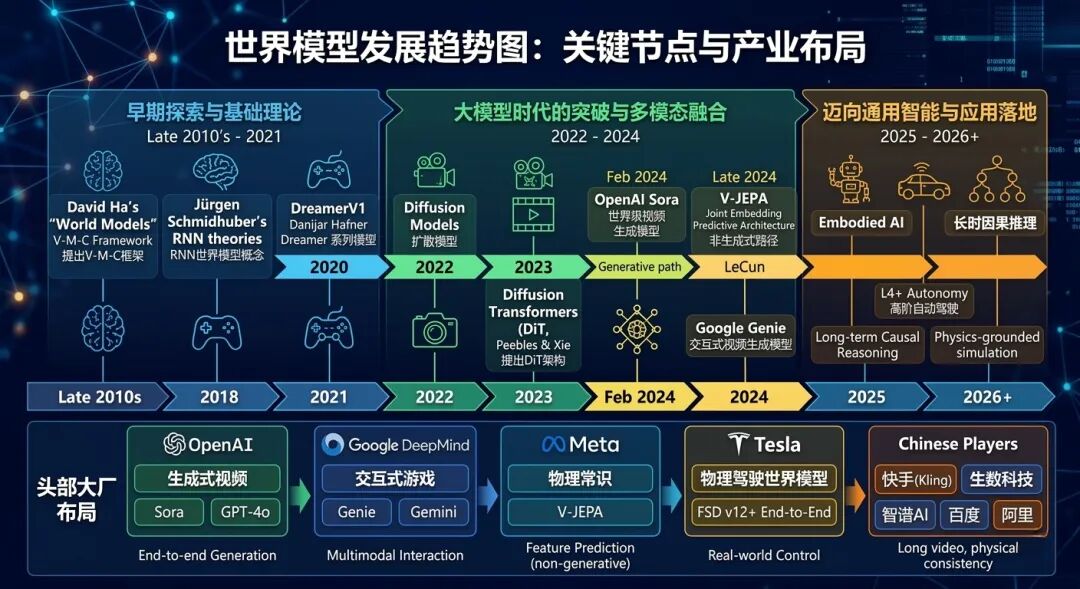
1、视频生成流派--OpenAI Sora、谷歌Genie为代表
视频生成应该是目前最具代表性的、也是最为大众所熟悉的世界模型路线。它的目标很直观,就是尝试让AI直接生成一个“能动起来的世界”,并让这个世界随着时间流动、演化、变化。
2)优势与局限性
优点是生成质量极高,内容逼真度高,擅长捕捉复杂时空关联,视觉效果震撼,而且它生成的结果“看得见”。我们肉眼能直接观察世界模型是否具备物理一致性、是否理解时空结构,并且它能快速商业化落地,影视、广告、教育、游戏都能立刻使用。
但局限性同样存在,逼真和高清的画面,训练与推理成本极高;基于数据驱动学习的视频生成不具备可解释性和鲁棒性,被批评为“只是在做像素级的插值拟合”,尚未真正理解物理因果逻辑。
3)案例代表
OpenAI在发布Sora之初,它们就将其定义为一个“世界模拟器”。Sora并不是简单地把一段视频用静态图像一张张“拼出来”,而是让画面里的事物能够随着时间连续地演化。
这些视频细节之所以令人震撼,是因为人们发现,模型似乎开始真的“理解”了事物变化的背后规律,它知道光线在材质上如何变化,知道一个物体在受到外力后该怎样移动。而目前与Sora类似的,还有Google的Genie 3 、字节Seedance、快手Kling等一系列视频生成模型。
下图:谷歌 Genie3 特点

2、JEPA 派:联合嵌入预测架构流派--不追求画面,追求物理逻辑
2025年,当全球AI行业几乎所有的头部公司——OpenAI、Google DeepMind、Anthropic、xAI——都在all in大语言模型。整个行业都在追逐更大的模型,追求Scaling Law、更多的算力、更长的上下文窗口。然后LeCun站出来说:你们全错了,一个人挑战整个行业。
JEPA 派就是Yann LeCun提出来的。
Yann LeCun,杨立昆,图灵奖得主,前Meta首席科学家。 自25年11月离开Meta后,于26年1月创立了Advanced Machine Intelligence Labs,简称AMI,助攻世界模型。
LeCun 认为的世界模型,不是预测下一个词,而是理解物理世界。不是从文本中学习,而是从视频、图像、传感器数据中学习。不是生成语言,而是构建对现实世界的抽象表征。
为此,LeCun提出了一个技术框架:JEPA,全程Joint Embedding Predictive Architecture,联合嵌入预测架构。他认为生成式模型(如 Sora)算力浪费严重且容易产生幻觉(Hallucination)。JEPA 更像人类大脑的运作方式,专注于更高维度的逻辑和常识。
JEPA 派的核心理念---放弃在像素层面生成画面,转而在抽象的特征空间中预测世界的变化。抛弃无关紧要的细节(如树叶的随机摆动),只关注核心变量的变化。
2)优劣势
优势是算力成本低、数据效率高、泛化性强、可更好地捕捉物理逻辑常识,因果推理能力突出;局限性是可视化能力弱,无法直接生成画面,不可解释,复杂场景几何一致性差,且产业落地的直观性不足,当前仍以实验室验证为主。

3、3D 空间智能派--李飞飞World Labs、英伟达 Cosmos
世界模型能够生成或预测的连续视频帧的数量或时间长度,衡量模型的长期预测能力。在相同帧率下,长时预测更难,易出现累积误差和模式崩溃。反映了模型对复杂场景长时间建模和推演的能力。
早期模型可能只能生成几秒的视频,而先进模型已能实现数分钟甚至更长时间的连续生成,如LongVIE-2模型可生成长达5分钟的高保真视频。期间模型需保持场景一致性、物理规律遵循和状态记忆。
(5)一致性
指生成视频在时间维度上的连贯性,包括运动平滑性、物体身份保持、场景逻辑合理等。
真正的通用世界模型,必须同时满足“三重一致性”(Trinity of Consistency),也就是模态一致性、空间一致性和时间一致性。
模态一致性 —— 语义接口:把文本、图像、音频映射到同一个语义空间。你说“红色的猫在蓝色的车上”,模型得把颜色绑对物体,而不是张冠李戴。
空间一致性 —— 几何基石:构建稳定的3D几何认知。同一把椅子从正面看和侧面看,结构不能变形,也不能转个角度就长出第三条腿。
时间一致性—— 因果引擎:遵循物理定律和因果链条。杯子必须先掉落再碎裂,蜡烛必须越烧越短,而不是反过来。
下图:主流世界模型技术指标对比:
世界模型产业链类似于大语言模型。但对算力和多模态数据要求更高,更苛刻。 其中,上游为基础设施,核心壁垒最高;中游技术层,为核心模型研发 ;下游为场景应用。
1、 上游:基础设施层--赛道卖水人,壁垒最高
上游是世界模型的算力、数据、工具底座,决定了模型的能力上限,核心分为三大板块:
(1)算力硬件
1)核心技术:为AI 训练芯片、AI 推理芯片、智算集群、超算中心、高速互联网络。
2)代表厂商:
(2)数据服务与仿真平台
1)核心技术:3D 物理仿真引擎,降低模型开发门槛;多模态数据采集与标注、4D 时空数据集、虚实迁移工具,涵盖数据采集、清洗、标注、存储等环节,由专业数据服务商提供高质量训练数据。
2)代表厂商:
2、中游:核心模型层--技术层
中游是世界模型的技术核心,分为基础模型、开发框架、MaaS 平台三大板块:
(1)基础世界模型
1)通用世界模型:
海外:Meta V-JEPA、OpenAI Sora、Google DeepMind Genie、NVIDIA Cosmos、World Labs Marvel、AMI Labs 通用世界模型。 国内:华为盘古世界模型、百度文心世界模型、腾讯混元世界模型、字节跳动豆包世界模型。 2)专用世界模型:
① 自动驾驶:华为WEWA架构、蔚来的NIO World Model、特斯拉World Simulator、Waymo Driver 世界模型、Momenta R6、商汤的绝影开悟等。 注意区分VLA端到端大模型:理想汽车Mind VLA、小鹏汽车VLA2.0、元戎启行等。
② 机器人:星动纪元Ctrl-World、极佳视界的GigaWorld等。
(3)MaaS 服务平台
3、 下游:场景应用层
下游是世界模型的商业化出口,未来市场空间最大。
(1)行业垂直应用:涵盖金融(智能风控、智能投顾)、医疗(影像诊断、辅助诊疗)、教育(智能辅导、个性化学习)、制造业(智能制造、质检预测)、交通(自动驾驶、交通管理)等领域。
总之,世界模型已成为通向通用人工智能(AGI)的核心路径。它改变了传统 AI 仅能处理文本或静态图像的局限,赋予了智能体抽象表征、前向预测、物理常识与内部仿真四大核心能力。
通过将大语言模型(LLM)的逻辑推理与视觉-语言-动作模型(VLA)的执行力相结合,世界模型正驱动着机器人、自动驾驶及短视频创作等领域发生范式革命。
当前,世界模型正处于“从实验室走向早期商业化,从局部视觉模拟走向通用物理规律理解”的突破期。类似于 ChatGPT 在 2022 年底爆发的前夜。
1、挑战
世界模型,当前面临的核心挑战如下:
首先是技术瓶颈,物理建模与长时一致性仍是核心难题。当前世界模型对真实世界物理规律的理解仍较为表面,部分模型仍比较依赖数据驱动的模式识别,难以准确模拟复杂的动态交互过程,生成的动作偶有不符合现实中力学常识等情况,而且画面失真或行为混乱,难以长时间保持稳定和连贯。
其次是成本制约,数据、算力与能耗构成高昂壁垒。训练和运行世界模型需要强大的计算资源和海量高质量物理世界场景数据,成本压力巨大。
最后是应用评估,缺乏统一标准,难以衡量真实能力。现有模型能力评估大多关注生成画面的清晰度或短期预测的准确性,无法有效反映模型对物理规律的理解深度、超长时间运行的稳定性、因果推理能力以及在复杂任务中的规划效能。
2、迭代方向
尽管困难重重,世界模型依然会快速朝着以下方向迭代:
其一,未来世界模型的核心竞争将聚焦于 3D 空间与物理精度,显式建模将成为主流路线,隐式生成式模型将逐步向 3D 方向升级。
其二,从专用场景模型走向跨场景通用世界模型:未来 3-5 年,将出现首个真正意义上的通用世界模型,能够适配机器人、自动驾驶、工业仿真等多个场景,成为下一代 AI 的基础底座。
其三,与强化学习等多方案融合,形成 “世界模型 LLM VLA” 的完整 AGI 闭环。当前的世界模型的主流方案各有有优势和劣势,未来的世界模型,应该是融合空间智能与物理规律嵌入和强化学习的混合架构。打通LLM 负责语言与知识、世界模型负责认知与预测、VLA 负责动作与执行” 的完整闭环,实现 “感知 - 认知 - 预测 - 规划 - 执行” 的全链路自主智能。

 VIP复盘网
VIP复盘网
