

事件:
英伟达GTC 2025大会于3月17-21日举办,英伟达CEO黄仁勋于3月19日发表主题演讲,介绍AI加速计算新时代、AI加速计算的新品、CPO芯片及集成光子引擎、以及AI技术在自动驾驶、机器人等前沿领域的应用。综合演讲及材料信息,总结要点如下:
评论:
1、数据中心28年Capex望超万亿美元,训练推理带来100倍Tokens增长。
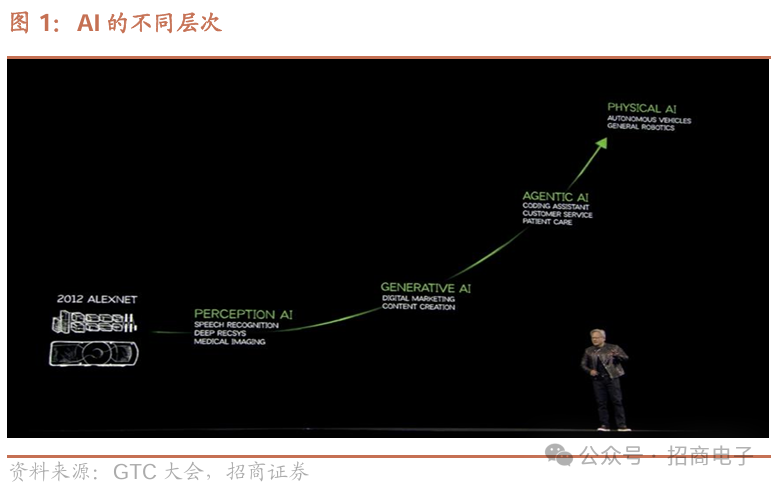
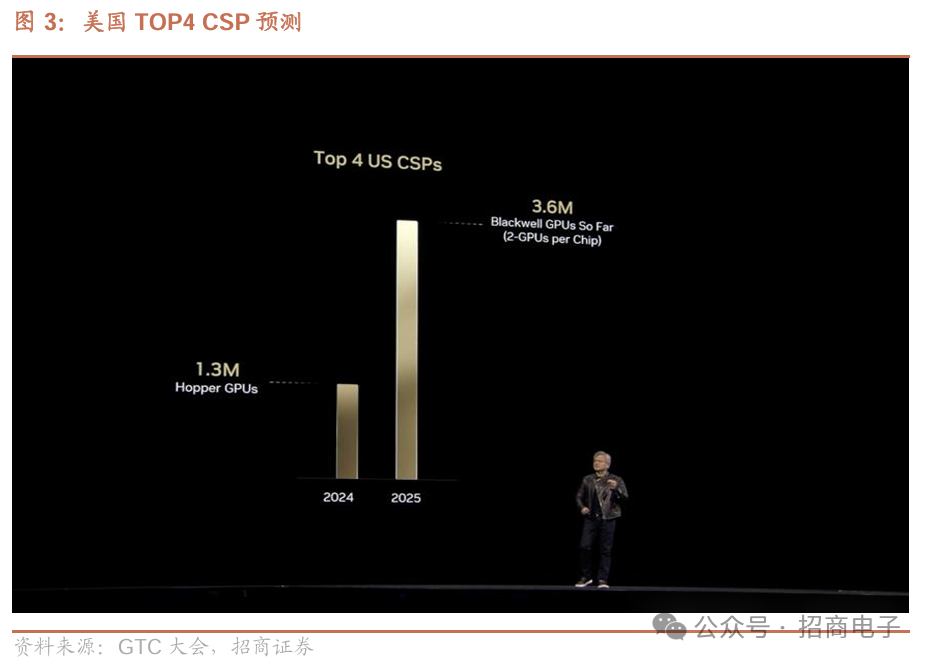
1)资本开支:数据中心、CSP和相关基础设施的资本开支将大幅增加,预计2028年数据中心建设将达到1万亿美元,绝大部分投资或将用于加速计算芯片。2024年公司向四大云服务商共交付130万颗Hopper GPU,预计2025年将出货360万颗Blackwell。英伟达认为,世界正在经历一场革命性转型,全球数据中心正在向人工智能工厂转型,计算机将为软件生成Tokens,处理分析并生成AI驱动的研究和应用。2)训练及推理:英伟达概述了三层次的AI,即Generative AI、Agentic AI以及Physical Al,从生成式到AI推理再到理解物理层面;由于训练和推理模型的计算量剧增,AI基础设施在短时间内增长惊人,如今所需计算量较去年预计增长100倍,当AI技术生成Tokens 时,会生成代表推理步骤的单词序列,致使Tokens数量大幅增加,为保持模型响应交互性,需将计算速度及Tokens速度提高10倍。
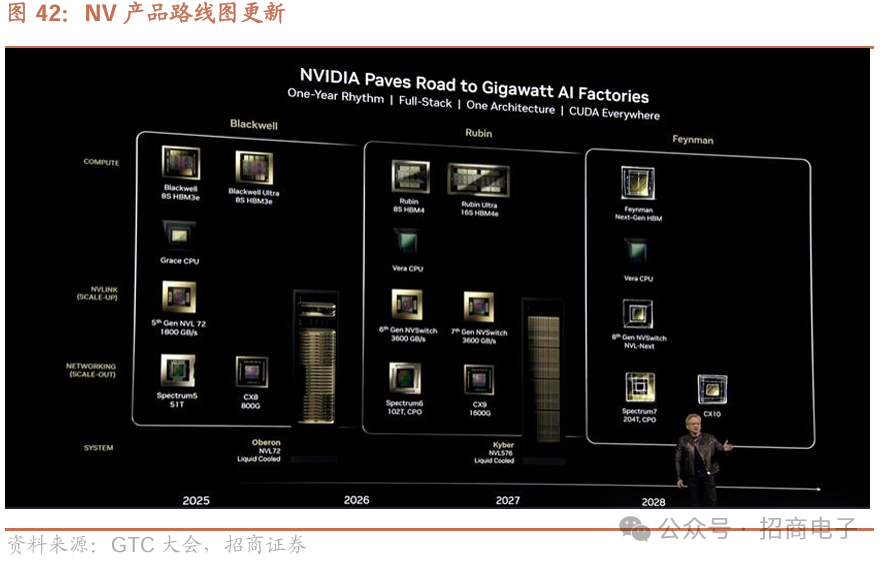
2、Blackwell全面投产且进展顺利,展示Rubin和Feynman等未来代际产品。
1)Blackwell:英伟达表示,Blackwell已全面投产且进展较快,客户需求量较大,Blackwell NVL72结合Dynamo推理性能提升了40倍,相当于一座Hopper AI工厂的性能;英伟达将于25H2发布Blackwell Ultra,算力较GB200 NVL72提升约50%(FP8精度算力达0.36EF),搭载HBM3E、内存从192GB提升到了288GB,搭载CX8链路并达到14.4TB/s的传输速率。2)Vera Rubin NVL144:预计26H2推出,包括VeraCPU RubinGPU,同时调用时Rubin能在推理时实现每秒50千万亿次浮点运算,Rubin内存将升级为288GB容量的HBM4,带宽也会从原来的8TB/s大幅提升至13TB/s,扩展NVLink后Rubin带宽翻倍至260TB/s,同时采用CX9链路并达到28.8TB/s传输速率;3)Rubin Ultra NVL576:预计27H2推出,FP4精度算力达15 EF、FP8精度算力达5 EF,相较于GB300 NVL72性能提升约14倍;Rubin Ultra NVL576搭载HBM4e内存、带宽达到4.6 PB/s ,并支持 1.5PB/S带宽的NVLink 7,与上一代相比提升约12倍,同时采用CX9链路及115.2 TB/s传输速率,较上一代提升约8倍。4)Feynman:预计2028年上市,Vera CPU、NVSwitch-NEXT、Spectrum7、CX10网卡等配套都将同步迭代,迎接千兆瓦AI工厂时代。
3、英伟达推出CPO交换机,预计2026年开始将随Rubin系列逐步推向市场。
1)Quantum-X CPO交换机:预计25H2推出,整体交换容量为115.2Tb/s,相比可插拔光模块方案能耗降低约3.5倍,并带来网络弹性提升10倍以及部署效率提升1.3倍;每个Quantum-X CPO交换机包含4个Switch模块,单Switch具备28.8Tb/s传输速率,采用台积电N4代工,具备3.6TFLOPS FP8精度的算力;Switch周围放置6个光学组件,组件内含3个1.6T可拆卸硅光引擎(共计18个),由324路光纤连接,其中包括36路光纤输入及288路光纤输出。硅光引擎采用200Gb/sDe微环调制器,光纤耦合采用台积电COUPE平台、N6工艺生产,用垂直耦合方式,与3D封装的EPIC进行光路耦合。交换机外部共有1152路单模光纤,即8×2(收发)×3(光引擎数)×6(光组件数)×4(芯片数),单个模块包括8个激光器用于自动温度跟踪、波长和功率调谐,整个Quantum-X交换机对外接口包括18个外置光源输入,144个MPO连接器、324根光连接,对应115太比特每秒的吞吐量。2)Spectrum-X CPO:预计26H2推出,分为两种型号,①SN6810包含128*800GB/S端口,背板带宽102.4TB/S,②SN6800包含512*800Gb/S端口,背板带宽409.6TB/S;3)MRM micro mirror技术:结构为1个小波导连接1个环形结构,当光信号在波导中传输时,环形结构能产生共振、控制波导反射率、通过吸收光阻断光信号,将直接连续激光束转化为0或1;由于英伟达选择这项技术,25H2硅光子交换机将顺利推出,未来英伟达将硅光子学与共封装技术相结合,无需收发器,可直接将光纤接入512接口的交换机中,扩展到数十万个甚至数百万个GPU规模的能力,采用CPO交换机可以帮助数据中心节省60MW的电力,相当于100个Rubin的耗电量。4)合作伙伴:波若威科技、Coherent、康宁、Fabrinet、富士康、Lumentum、SENKO、矽品SPIL、住友电工、天孚光通信TFC、台积电等。
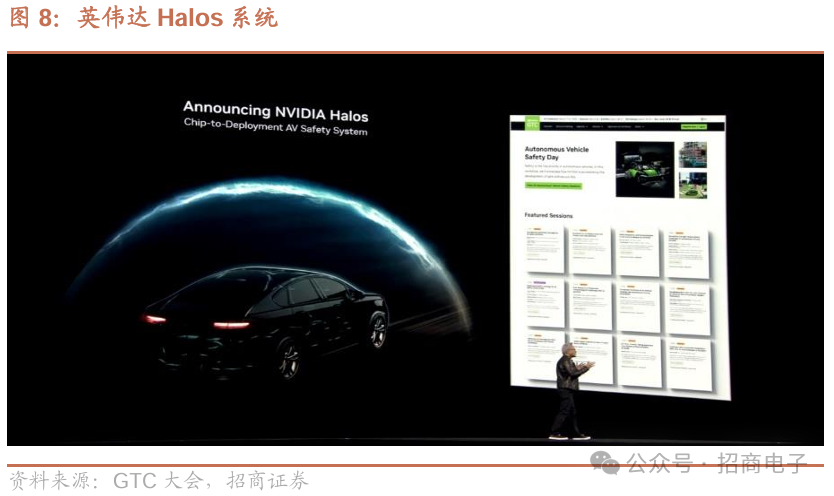
4、智驾推出Halos系统,机器人领域推出开源通用基础模型Isaac Groot N1。
①自动驾驶:英伟达认为自动驾驶时代已经来临,英伟达在汽车安全领域发布了Halos系统,通过Omniverse加速自动驾驶汽车开发,Cosmos的预测和推理能力支持AI优先的自动驾驶系统,该系统通过模型蒸馏、闭环训练和合成数据生成实现端到端可训练。②机器人:英伟达认为训练机器人需海量数据,借助基于英伟达Omniverse和Cosmos构建的方案可生成合成数据,英伟达推出并开源适用于类人机器人的通用基础模型Isaac Groot N1,具有快慢双系统架构,通用性强,开发者可利用相关流程对其进行后期训练。
风险提示:竞争加剧风险、贸易摩擦风险、行业景气度变化风险、宏观经济及政策风险。
附录:英伟达GTC 2025主题演讲纪要
时间:2025年3月19日
主讲人:英伟达创始人黄仁勋
1、AI的三个层次
过去五年,重点转向生成式人工智能,实现图像、资产的翻译与转换,人工智能检索方法也大变。以往侧重存储、获取多版本数据,如今AI像主动助手,能理解请求上下文与含义,动态生成响应,这一转变近年对技术各层面影响重大。现在是生成计算模型,不像过去提前创建、存储多版本内容再取用,AI能理解我们提问并生成所知,必要时检索信息、加深理解并给出答案,不再是检索数据,而是生成答案,彻底改变计算方式,过去几年尤其是两三年内,计算的每一层都发生了变化。①生成式AI是教AI模式转换,如文本到图像、视频等,能多种方式生成内容,从根本上改变计算模式。②智能体AI意味着有AI代理机构,它能感知、理解环境背景,可推理如何回答或解决问题,能规划行动、使用工具,因理解多模态信息,可访问网站学习并利用新学知识工作,这是全新推理方式。③物理AI依托理解物理世界的物理人工智能驱动机器人技术,它懂摩擦、惯性、因果关系、物体永存性等,理解三维空间将开启人工智能新时代,让机器人成为可能,这些阶段都将带来新市场机会。
人工智能解决行业挑战的能力不断提升。今年重点聚焦两大核心问题:一是突破数据限制,数据作为AI的核心,打破其约束至关重要;二是优化训练流程,以此推动AI进一步发展。扩展AI意义重大,智能的扩展策略能提升AI系统的效率与弹性。过去一年,AI发展显著,模型性能达到全新高度。扩展AI并非仅提升计算容量,还涉及弹性、加速及推理。现代AI系统采用结构化决策,系统会选出最佳解决方案,不再是简单的“单次生成”,而是遵循结构化推理过程,保证响应的一致性与准确性。
2、推理模型带来的100倍Tokens增长
由于推理,如今所需计算量很可能是去年此时预计的100倍。从AI的能力说起,智能体AI具备推理能力,能逐步解决问题,比如用不同方式处理问题选最佳答案,或多种方式解决同一问题并检查一致性,还能将答案回代方程确认。现在AI借助思维链技术可逐步推理分解问题。
在AI基础技术中,生成下一个标记(Tokens)时,前一步生成结果会再次作为输入参与后续步骤,不是只生成单个标记,而是生成代表推理步骤的单词序列,导致生成的Tokens数量大增,可能达到原来的100倍,或因模型复杂达到10倍。为保证模型响应性和交互性,计算速度需提升10倍,计算量要容易100倍。但面临数据来源和局限性的挑战,数据及人类演示有限,系统需按步骤读取、批准数据来解决复杂问题,如何突破这一制约是关键。在科学领域,类似数独的谜题和基于限制的问题可作类比,AI能通过大量尝试逐步解决,生成数百万独特示例,基于产生的大量Tokens形成海量合成数据用于学习优化。
对比前四大公共云CSP(AWS、Azure、GCP和OCI)中Hopper GPU高峰年和Blackwell第一年,AI正处拐点,因更聪明、能推理而更有用,使用人数增多,如ChatGPT等待时间变长。训练和推理模型所需计算量急剧增长,短短一年,Blackwell刚发货,AI基础设施就呈现惊人增长。
3、数据中心的演变与人工智能加速计算的新时代
如今,我们似乎常常不得不等待技术的追赶。许多人渴望看到结果,但训练这些模型所需的计算能力是巨大的。随着最新硬件的进步,我们终于看到计算能力在实际应用中得到了体现。预测的紫色部分显示了数据中心投资的预计增长。分析师预测,用于数据中心、CSP 和相关基础设施的资本分配将大幅增加。正如我之前提到的,我预计在不久的将来,数据中心的建设将大幅扩张。这种动态转变已经开始,绝大部分投资可能会用于加速计算。我们早就明白,软件必须与硬件加速器紧密集成,而现在我们已经越过了一个临界点,这种集成正在成为一种必然。
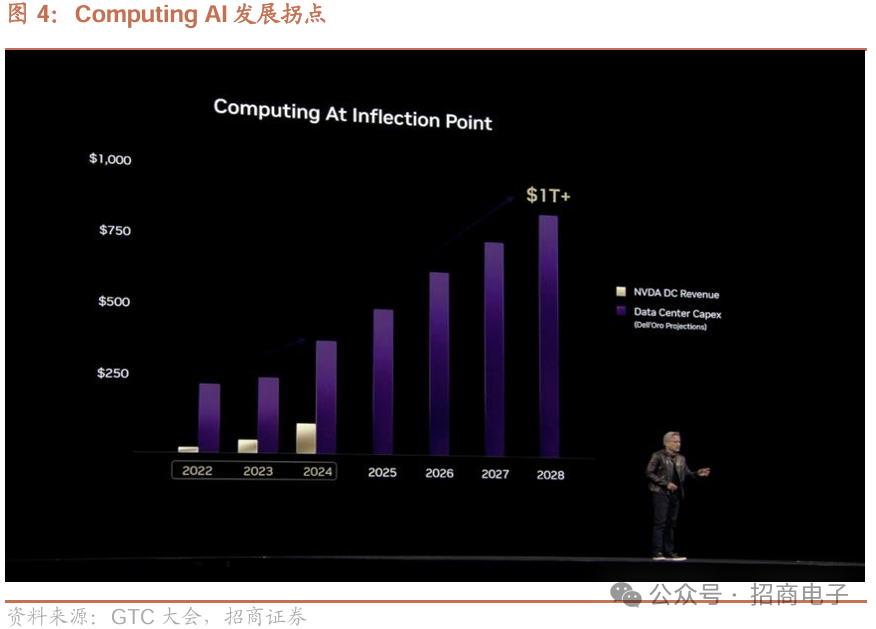
我们现在正在见证全球数据中心扩张所带来的切实影响。第一个关键转变是基础设施的转变。第二个重大发展是软件开发所需的资本投资不断增加。这是一个重要的概念:软件加速器现在将产生代币,驱动软件流程。从本质上讲,整个计算生态系统正在变得代币化,从而实现先进的人工智能驱动的检索和处理。
数据中心正在转变为我所说的 “人工智能工厂”。这些设施只有一个目的:处理、分析和生成人工智能驱动的研究和应用。世界正在经历一场根本性的转变--不仅是数据中心的扩张,还有如何在这些环境中部署和加速人工智能。
4、CUDA-X行业框架
我们需要AI框架来创建加速软件,就像加速AI框架一样,这需要物理、生物学、多物理学以及各类量子物理学的框架,还有各种各样的库和框架,我们称之为各科学领域的库加速框架。
CUPYNUMERIC:NumPy是全球下载量和使用量最大的Python库,去年下载达4亿次。若你在使用NumPy,不妨试试CUPYNUMERIC。
CULITHO:计算光刻库,历经四年,已涵盖光刻和计算光刻全过程。未来各行业有工厂的公司都将有两类工厂,一是实体建造工厂,一是制造AI的数学工厂。台积电、三星、阿斯麦都是我们的合作伙伴及导师,提供了支持。
AERIAL SIONNA:我们的5G库,可将GPU变为5G无线电,信号处理是我们的强项。在此基础上,能分层AI for Ran,下一代无线电网络将深度融入AI。
CUOPT:受信息理论局限,信息有限,但加入AI就能进行数学优化。几乎各行业在座位规划、航班库存管理以及客户、工人、工厂、司机和乘客等安排时都会用到,涉及多种限制和大量变量,旨在优化时间、利润和服务质量。
PARABRICKS:用于基因测序和分析的模块。
MONAI:全球领先的医学影像库。
EARTH-2:用于高分辨率本地天气分析。
CUQUANTUM & CUDA-Q:我们将在GTC举办首个量子日活动。正与生态系统中各方合作,助力研究量子架构、算法,或构建经典加速量子异构架构,在张量收缩的等方差和张量、量子化学等方面开展了令人兴奋的工作。

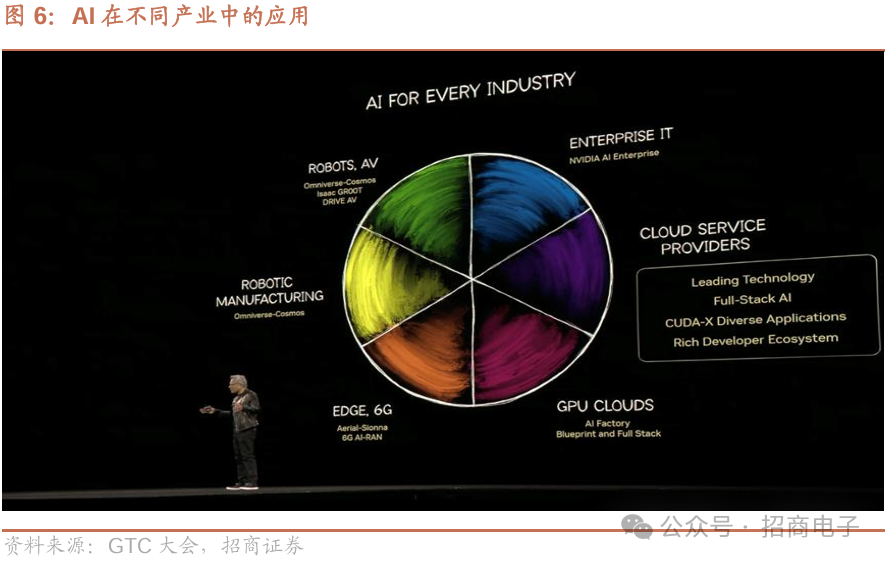
5、AI在行业中的应用
GPU云
AI始于云端,云服务提供商热衷于我们的领先技术,他们主要业务是托管GPU,称自己为GPU云。我们的重要合作伙伴CoreWeave正在筹备上市,我们深感自豪。
边缘计算与6G
边缘计算是令人激动的领域。英伟达携手T-Mobile、MITRE、思科、ODC和Booz Allen Hamilton,将在美国构建完整的无线电网络堆栈,把AI引入边缘计算。全球每年有1000亿美元资本投入未来无线电网络及所有数据中心通信配置,这将是融入AI的加速计算。AI借助强化学习,能更好地适配无线电信号(如大量mimos)以应对环境和流量变化,革新通信。
自动驾驶汽车
自动驾驶汽车是AI较早涉足的行业。我们开发的技术被几乎所有自主研发汽车的公司采用,相关技术可应用于数据中心(如特斯拉在数据中心用大量视频GPU),或同时用于数据中心与汽车(像Waymo和Wave),也有仅用于汽车的情况(较少见),有些公司还会使用我们所有软件。汽车行业期望与我们合作,我们打造了训练、模拟、自动驾驶汽车这三类计算机及相应软件堆栈、模型和算法。通用汽车(GM)已选择英伟达合作打造未来自动驾驶汽车车队。自动驾驶时代来临,我们期待在制造、设计模拟及车载AI这三个领域与GM开展合作。
计算光刻技术
过去四年,计算光刻技术取得显著进步,大幅提升处理效率,优化了在半导体制造中极为关键的光刻处理流水线。半导体行业由生产硅晶片和光刻元件这两类主要工厂驱动,这些工厂对AI计算、智能设备和自动驾驶汽车等行业意义重大 。台积电(TSMC)、三星(Samsung)、ASML、Synopsys 和 Mentor Graphics 等公司目前正处于光刻技术进步的临界点。
从光刻到AI驱动的射频设计,半导体制造各流程正经历重大创新,然而有限的数据带宽和频谱可用性带来限制,几乎所有行业(从电信到航空航天)都受影响,优化时间、资源分配和整体效率成为关键。
行业正在大规模采用开源解决方案,像BMC这样的大企业推动着基因测序、医学成像和多物理场仿真等领域的创新,研究生态系统发展迅速,经典计算和加速计算有新突破。等变性作为现代AI核心概念,成为先进计算模型关键特征,业界正开发集成软件堆栈,实现AI生态系统各部分无缝互动,基于DSS的计算机辅助工程稀疏求解器和高性能计算框架是两大重要突破,代表着各行业在仿真、设计和AI加速方面的重大转变。
过去许多公司依赖无AI加速优化的传统软件,如今专业AI软件和加速框架兴起,带来计算工作负载处理方式的革命,实现了AI加速大规模数据结构、基于Spark的计算框架以及科学研究尖端解决方案,AI和物理建模的混合加速将持续重塑各行业。相关库速度快、扩展性强且应用广泛,开发人员利用它们能创建出色软件。
加速计算使不可能变为可能,GTC旨在构建深度生态系统,CUDA就是愿景例证。自2006年创立,CUDA已有600万开发者,900多个加速库推动科学发现、塑造行业,让机器能精准感知世界,性能提升数千倍,缩小模拟与现实差距,未来社区还将有更多成就,其影响力深远,如帮助科学家完成毕生研究。
基于此,云计算成为下一个话题。机器学习需强大基础设施,数据中心推动AI研究和科学进步,云服务提供商作用关键,且AI不局限于云正拓展到各领域,云计算在AI推动下正带来开创性发展。
6、人工智能驱动的边缘计算与无线网络革命
这一转变的核心是庞大的软件生态系统,堆栈各层功能类似SQL,为不同应用提供专门库。AI基础设施复杂,CSP却深知其价值,英伟达与开发者、CSP客户紧密合作,优化AI基础设施以适配实际应用。开发者生态系统是AI融入全球各行业的基础,毕竟各行业系统配置、运行环境、领域库及使用案例差异巨大,如今AI已在企业、制造、机器人和自动驾驶等领域产生重大影响。
当下,越来越多公司投身基于GPU的云服务。英伟达发展历程中,约20家公司专注GPU云解决方案托管,重要合作伙伴CoreWeave在该领域举足轻重,我们为其进步深感自豪。这些GPU云提供商需求独特,我们全力支持。边缘计算则是最令人期待的发展方向之一。如今,我们宣布重大合作:思科、英伟达、T-Mobile和Servers ODC将在美国搭建全栈AI驱动的无线网络,这是推出的第二个AI网络堆栈,把AI功能带到边缘。每年,数十亿美元投入无线电网络,其构成全球通信骨干。无疑,未来AI驱动的加速计算将彻底革新该领域,大幅提升效率与性能。
在动态环境管理大规模MIMO系统的无线电信号,本质就是大型AI驱动的无线网络。强化学习在优化网络条件方面会如在其他复杂系统中一样,发挥关键作用,AI极有可能彻底变革通信。就像我们与熟悉之人交流那般轻松,打电话回家时,妻子因了解前情能无缝衔接对话,靠的是先验知识和语境理解。将AI与这些能力结合,就能改变机器处理通信的方式。如同AI改变视频处理和3D图形,也将重新定义边缘计算,这就是此次公告令人兴奋之处,T-Mobile、思科、英伟达和Servers ODC正在构建将AI融入电信基础设施的全栈解决方案。
7、英伟达自动驾驶汽车领域布局
英伟达投身自动驾驶汽车领域超十年,所开发技术几乎被所有自动驾驶汽车公司采用,像特斯拉会用英伟达GPU产品,可用于数据中心和汽车。Waymo和Wave在数据中心及汽车上都用英伟达计算机。此外,公司与汽车行业合作,能满足多样合作需求,打造了训练、模拟以及自动驾驶汽车的机器人控制这三类计算机,还有配套软件栈、模型和算法。英伟达宣布,通用汽车选择其作为打造未来自动驾驶汽车车队的合作伙伴。自动驾驶汽车时代已至,英伟达期待在三个领域与通用汽车人工智能团队合作:制造业AI,助力革新汽车制造方式;企业运营AI,实现工作、汽车设计与模拟等方面变革;汽车内部AI,为通用汽车构建AI基础设施,携手推动其AI技术发展。

8、英伟达 Halos系统保障汽车安全
英伟达指出汽车安全领域中安全性受关注不足,在会上发布了Halos系统。安全性需芯片、系统、系统软件、算法、方法论等多方面技术支撑,涉及确保多样性、监测多样性、保证透明度与可解释性等内容,这些理念要融入系统和软件开发各环节。英伟达自称是全球首家对每一行代码做安全性评估的公司,已评估700万行代码,涵盖芯片、系统软件及算法。其安全性由第三方评估,第三方逐行检查代码,确保设计合理,保障多样性、透明度和可解释性,英伟达为此申请了超1000项专利。
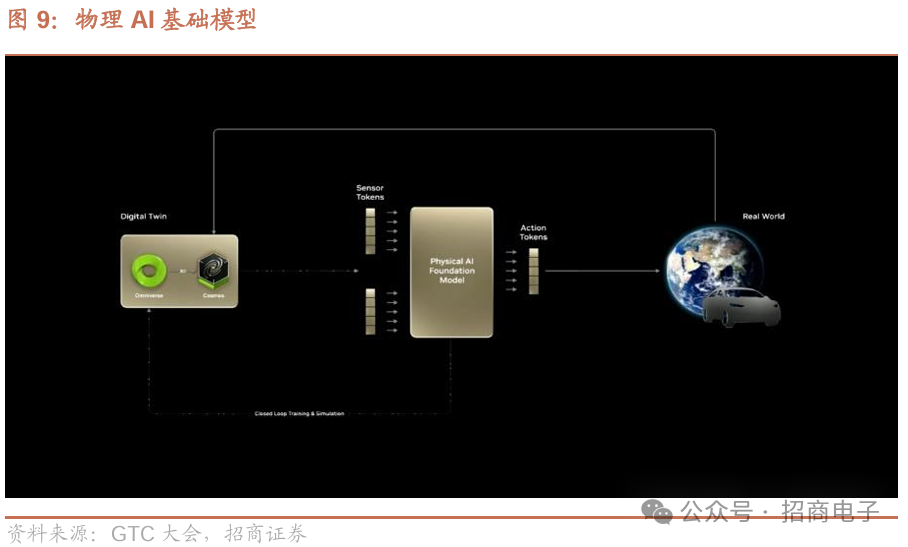
9、英伟达借助Omniverse与Cosmos加速自动驾驶AI开发
英伟达借助Omniverse加速自动驾驶汽车的AI开发,Cosmos的预测和推理能力支持AI优先的自动驾驶系统,该系统借新开发方法、模型蒸馏、闭环训练及合成数据生成,实现端到端可训练,过程如下:
模型蒸馏作为策略,Cosmos驾驶知识从慢但智能的“教师”模型,转移到小、快且能在车内运行的“学生”模型。“教师”展示最优轨迹,“学生”跟随学习,经迭代直至二者表现相近。蒸馏启动策略模型,复杂场景则需闭环训练进一步微调。借助Omniverse神经重建,日志数据转为基于物理模拟驾驶闭环的3D场景,创建场景变体测试模型轨迹生成能力,由Cosmos行为评估器评分,新场景及其评估结果形成大型数据集用于闭环训练,提升自动驾驶汽车应对复杂场景的稳健性。
最后,3D合成数据生成增强自动驾驶汽车对不同环境的适应力。Omniverse依日志数据,融合地图和图像构建4D驾驶环境,生成现实数字孪生体,引导Cosmos分割信息。Cosmos生成准确多样场景扩充训练数据,缩小模拟与现实差距。


10、英伟达数据中心技术变革与系统架构演进
数据中心方面,Blackwell已全面投产,公司实现计算机架构的根本性转变。三年前展示的Grace Hopper,其Ranger系统约为屏幕宽度一半,是首个使用NVLink 32的系统,当时虽体积大,但解决规模扩展问题的理念正确。分布式计算需大量计算机协同处理大问题,而在横向扩展前,纵向扩展不可或缺,只是纵向扩展难度大,不能像Hadoop那样随意扩展。Hadoop用商用计算机组网进行存储计算,这一理念让超大规模数据中心能利用现成设备解决难题,不过我们要解决的问题太复杂,Hadoop式扩展能耗过高,所以得先纵向扩展。
英伟达上一代系统架构HGX革新了计算和人工智能领域。一个Blackwell封装含两块GPU,八个这样的封装连到NVLink 8,再与有双CPU的CPU机架通过PCI Express相连,众多此类设备经InfiniBand组成人工智能超级计算机,这是横向扩展前的纵向扩展成果,但我们还想继续纵向扩展。Ranger采用该系统,横向扩展的同时将纵向扩展程度提升四倍,有了NVLink 32,可系统体积过大,于是重新设计NVLink工作方式和纵向扩展方式,首先是在系统主板嵌入交换器,拆分并取出NVLink系统。

NVLink交换机堪称世界上性能最强的交换机。借助它,每一块GPU都能在相同时间内以满带宽与其他GPU进行通信。我们把它从原来的位置移到了机箱中央。九个不同的交换机托盘里,总共装有18个这样的交换机。从计算能力来看,这相当于之前的两个组件。通过液冷技术,我们成功将所有计算节点压缩进了一个机架中。这无疑是整个行业的重大变革:从集成式的NVLink变为拆分式的NVLink,冷却方式从风冷转变为液冷,组件数量从每台计算机约6万个,增加到每个机架60万个,功率达到120千瓦,且完全采用液冷方式。
现在一个机架中就能容纳一台算力高达1exa次浮点运算的计算机。这台计算机里有3000到5000根电缆,总长度约两英里,包含60万个部件,数量相当于20辆汽车的零部件,并全部集成到了这台超级计算机中。公司期望打造出特定的芯片,然而目前无论是技术极限方面,还是制程工艺技术,都无法实现这一目标。该芯片预计有130万亿个晶体管,其中20万亿个用于计算。所以,解决办法是将其拆分,拆分成Grace Blackwell NVLink 72机架。最终,我们实现了世界上前所未有的极致纵向扩展,所达成的计算量和内存带宽达到了每秒570太字节,这台机器里的各项数据都以“太”为单位计量,而且其算力达到了exa次浮点运算级别,也就是每秒能进行一百万万亿次浮点运算。

11、英伟达对推理难题的思考与解决方案
公司关注效率与性能,旨在解决推理难题。英伟达视推理为“工厂”生成Tokens的过程,此“工厂”要产生收入和利润,所以构建时必须兼顾极高的效率与性能,因为其各方面都直接关系到服务质量、收入和盈利能力。图中横轴代表每秒生成的Tokens数量,如在ChatGPT输入提示后输出的标记,会被重组成单词。公司认为,要让人工智能更聪明,需生成大量Tokens,包括用于推理、一致性检查以及产生众多创意以供筛选的Tokens,因人工智能会反复审视成果,生成Tokens越多,人工智能越聪明。
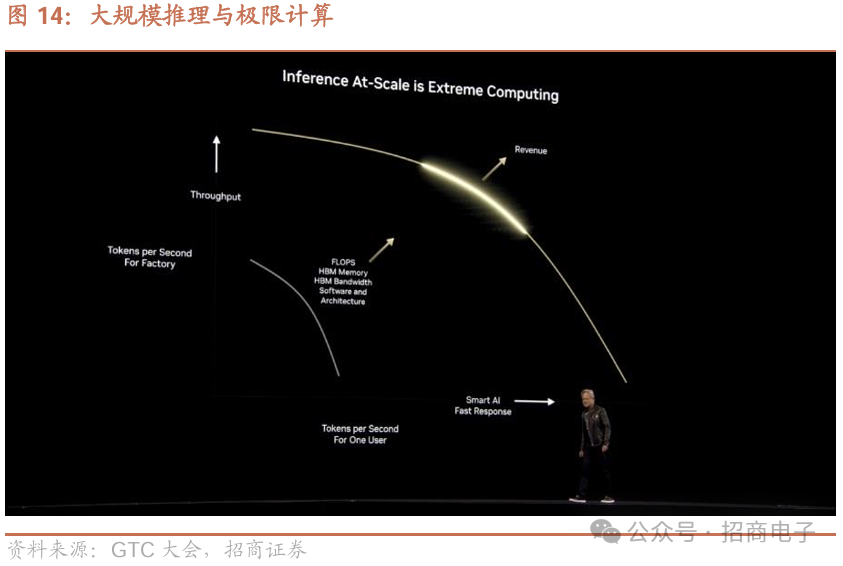
给出智能答案的耗时存在实际限度,需解决两方面问题:既要生成大量Tokens,又要尽可能快完成,Tokens生成速率很关键。但计算机科学和工厂生产中,响应时间与吞吐量存在根本矛盾,因批量处理到使用产品耗时久。一方面想给客户优质服务(即快速智能的AI),另一方面要让数据中心为更多人生成Tokens以实现收入最大化。理想状态是达到图表右上方,曲线呈正方形,能在产能限度内快速为每人生成Tokens,但难以实现,目标是让曲线下面积最大化,范围越大“工厂”越好。
每秒生成Tokens数量和每秒Tokens响应时间,一方面需大量计算浮点运算能力,另一方面需大量带宽和浮点运算能力。好的解决办法是具备大量浮点运算、带宽、内存、资源,以及良好架构、高能源效率,还得有编程模型在复杂条件下运行软件。
传统大语言模型(LLM)能获取基础知识,推理模型借助思维标记解决复杂问题。如安排宾客座位,传统大语言模型用不到500个标记快速作答但会出错,推理模型用超8000个标记思考得出正确答案。给模型推理问题后,R1推理尝试不同场景,给出并检验答案;上一代语言模型仅一次生成,用439个标记,速度快但答案错,标记浪费。增加难的变量,推理会变难,推理该问题用近9000个标记,且因模型复杂耗费更多计算量。
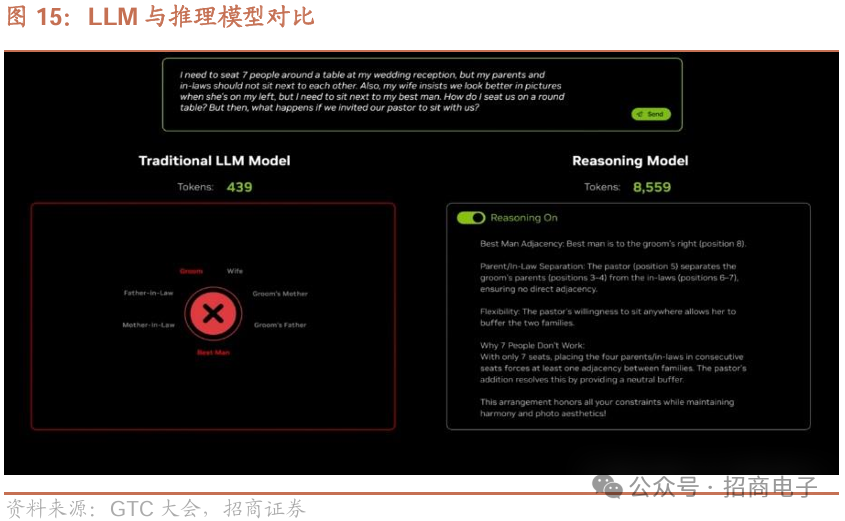
12、Blackwell 系统模型处理与复杂软件管理
对于经纵向扩展的Blackwell系统(即NV Link72系统),首要处理R1模型。R1模型虽看似规模不大,却有6080亿个参数,下一代模型参数可能达上万亿。解决办法是采用流水线并行、张量并行和专家并行计算的多种组合方式。而且依据不同模型、工作负载及情况,计算机配置需改变,要在针对极低延迟优化和针对吞吐量优化间权衡,这使得人工智能“工厂”的操作系统复杂至极。
在预填充和实时批处理中,聚合工作负载管理十分关键。比如KV缓存,能让GPU运行更佳。像读取数据后,访问约94个网站获取信息并生成报告。预填充阶段虽忙碌,但生成token不多;而与聊天机器人对话时,数百万用户同时操作,会大量消耗token生成和解码资源。根据工作负载,我们要动态决定分配更多GPU资源给解码还是预填充,这一动态操作极为复杂。上述还涉及流水线并行、专家并行、实时批处理以及聚合工作负载管理,还有将任务路由到正确GPU并通过内存层次结构管理器分配内存等操作,整个软件复杂程度超乎想象。
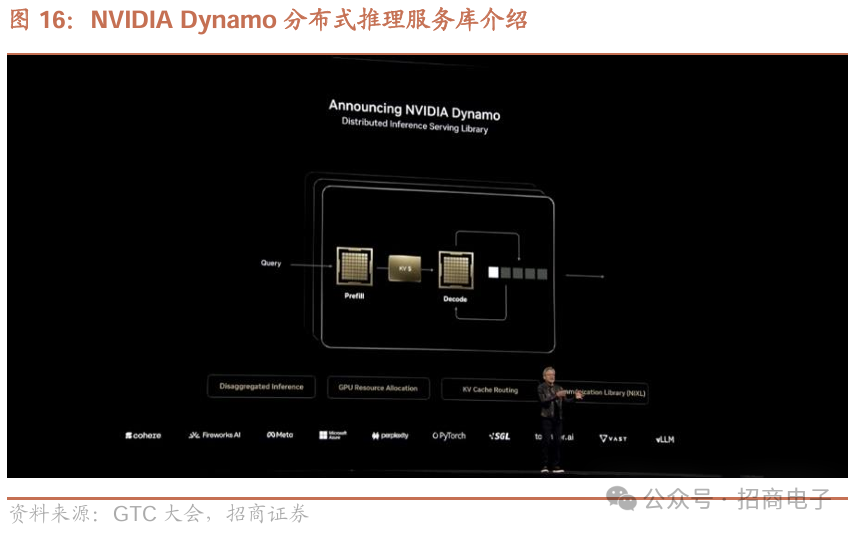
13、NVIDIA Dynamo:AI 工厂的操作系统
今天我们宣布英伟达Dynamo诞生,它本质上是人工智能工厂的操作系统。以往运营数据中心,用类似VMware的操作系统编排企业IT上的不同应用程序,如今依旧。但未来,应用程序从企业IT变为智能体,操作系统从VMware类变为Dynamo这类,它运行于人工智能工厂而非数据中心。
我们将其命名为Dynamo是有原因的。发电机(Dynamo)开启了上一次能源工业革命,原理神奇,水流入转化为电,80年前就如此,后续发展到自动化,一切都源于它。所以我们把这个复杂的软件操作系统命名为英伟达Dynamo,而且它是开源的,众多合作伙伴参与开发,我们非常欣喜。
现在,我们在等待完成所有基础设施扩展工作,同时已开展大量深入模拟,用超级计算机模拟自身的超级计算机。接下来展示上述内容的优势。大家记得工厂图表吧,Y轴是工厂每秒令牌吞吐量,X轴是用户体验每秒令牌数,大家都想要超级智能且能大量生产的人工智能,这就是Hopper。
14、Dynamo 带来的推理性能提升与收益分析
Hopper能为每个用户每秒生成约100个tokens,这里有8个通过无限带宽连接的GPU,且以每兆瓦每秒令牌数归一化,这是个1兆瓦规模的数据中心。在此数据中心里,每秒能为每个用户生成100个tokens,总计每秒生成10万个tokens。若进行超级批处理且客户愿长时间等待,该人工智能工厂每秒大约能生成250万个tokens。
以Hopper为例,已知ChatGPT每100万个tokens成本约10美元,按此计算,250万个tokens每秒成本25万美元。从另一角度,10万个tokens除以2,意味着每个工厂每秒产生2万美元价值。一年约3000万秒,这个1兆瓦的数据中心年收入约100万美元,可视为目标值。一方面,人们希望tokens生成越快越好,因为这样能拥有超级智能AI,且AI越智能人们越愿付费;另一方面,AI越智能,生产数量往往越少,这是合理的权衡关系。
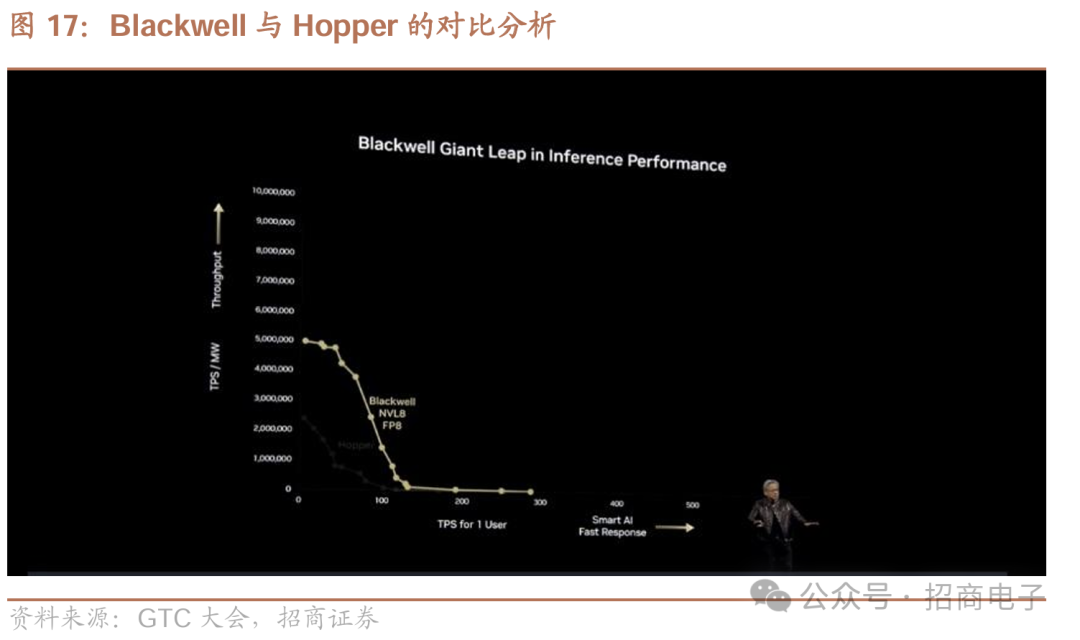
现在展示的Hopper是一款颠覆性的计算机。制造过程是这样的:先推出配备NV Link 8的Blackwell,也就是同一台Blackwell计算机,其采用FPA架构,性能更快,规模更大、晶体管更多,表现更优。
但我们不满足,寻求更多突破,引入新精度标准——简单的4位浮点运算,借此可量化模型,用更少能量完成相同任务,从而能开展更多工作。要知道,未来每个数据中心能源有限,收入受能源制约,可依可用能源量算收入,和很多行业一样,所以这是能源受限行业,收入与能源紧密相关,我们必须用节能计算机。之后,又通过NV Link 72技术对其扩展。
因架构紧密集成,现在引入Dynamo,它能进一步提升性能,对Hopper和Blackwell都很有帮助。当把两者优势结合,基本能达到最大性能点,这可能是工厂运营的最佳状态,需平衡以实现最大吞吐量,打造最智能AI,提供最高质量服务,X、Y轴交点就是优化目标。从数据对比看,在相同功耗(非相同芯片数量)下,Blackwell性能远超Hopper,这体现了摩尔定律追求,在相同功耗下,一代产品中Blackwell性能是Hopper的25倍。
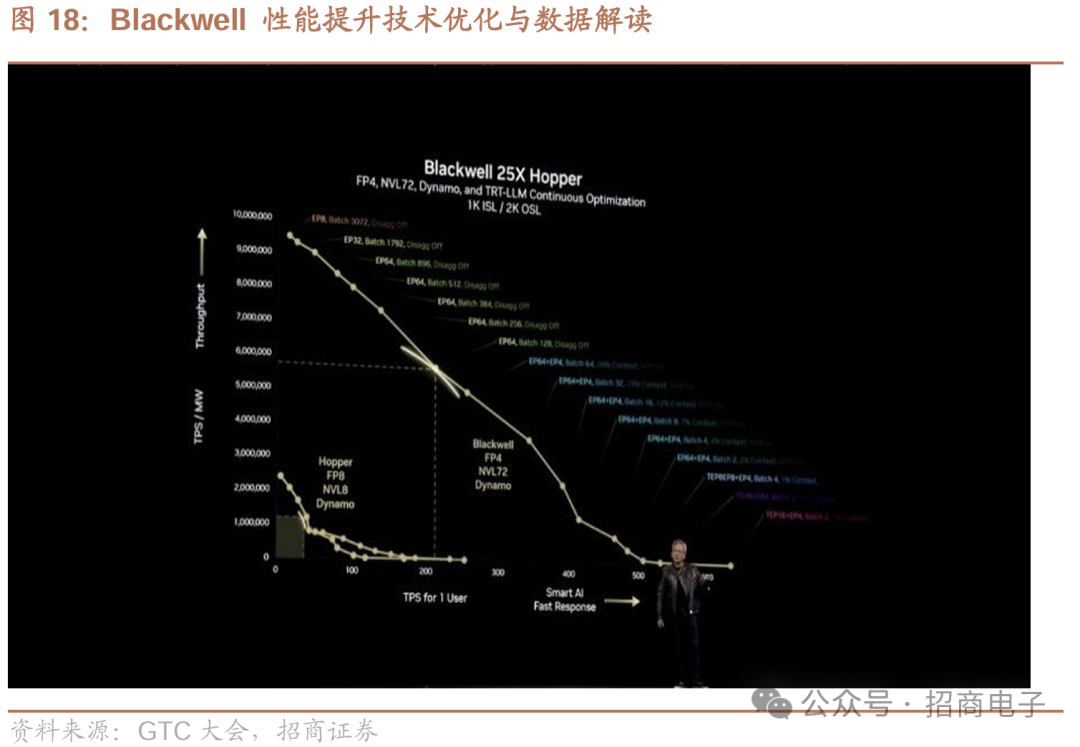
在帕累托前沿下方有上百万个不同配置点,原本可通过配置数据中心实现。我们能以多种方式并行处理和分配工作,并找到最优解——帕累托最优。图表上点的颜色显示相应配置,表明需要可编程、尽量同质化且可互换的架构,因为前沿区域工作负载变化大。例如,有专家并行8路、批处理3000、分解、Dynamo关闭的配置;中间部分有专家并行64路,26%用于上下文(Dynamo开启26%上下文),74%用于批处理64路和专家并行64路的配置;另一边是专家并行4路的配置。构建下一代计算机以适配下一代工作负载。以推理模型为例,Blackwell性能是Hopper的40倍。之前说过,Blackwell大量出货时,Hopper会失去竞争力。

15、AI 工厂建设与数字孪生优化
基于Hopper构建的100兆瓦工厂,有45000个芯片、1400个机架,每秒产生3亿个tokens。基于Blackwell构建工厂也不错,并非引导少买产品,实际购买越多,成本节省和盈利越多,一切基于人工智能工厂背景,讨论芯片要从大规模扩展角度出发。一个机架含60万个部件,价值3000英镑。
NVIDIA用Cadence Reality数字孪生,借CUDA和Omniverse库加速,模拟空气和液体冷却系统,Schneider Electric用ETAP应用程序模拟电源块效率和可靠性。实时模拟能让几秒内完成大规模“假设”场景迭代,而非几小时。用数字孪生向团队和供应商传达指令,减少错误、加快上线。规划改造升级时,可轻松测试模拟成本和停机时间,保障AI工厂未来可扩展性。
各国竞相建造先进大规模人工智能工厂,建一座人工智能千兆工厂是浩大工程,需数万名工人参与,完成近50亿个部件的建造、运输和组装,还要铺设超20万英里光纤。英伟达的人工智能工厂数字孪生体蓝图,能在建设前设计优化工厂。英伟达工程师用此蓝图规划1兆瓦人工智能工厂,整合最新英伟达DGX超级模块三维和布局数据、Virtue和施耐德电气的先进电力和冷却系统,以及经英伟达AIR优化的拓扑结构。以往工作各自开展,现在全方位蓝图让工程团队并行协作,探索配置,实现总体拥有成本和电力使用效率最大化。英伟达还用CUDA和全方位库加速的Cadence Reality数字孪生体模拟冷却系统,施耐德电气用E tap应用程序模拟电源模块,实时模拟优势显著,利用数字孪生体有诸多好处。


目前Blackwell已全面投产,全球计算机公司都在大规模制造这款出色机器。我们十分感谢大家为过渡到新架构所做的努力。今年下半年,我们将顺利升级到Blackwell Ultra 。它有72个单元,性能提升1.5倍,具备新的注意力指令,内存增加1.5倍(新增内存可用于KB缓存等应用),带宽增加2倍。

在网络带宽上,因架构相同,今年下半年能顺利过渡到Blackwell Ultra版本。我们提前这么久预告产品,这在公司里极为少见。构建人工智能工厂和基础设施需多年规划,和买笔记本电脑不同,不是随意支出,而是大额投入,得规划土地、电力资源,准备资本支出,组建专业工程团队,提前两三年布局。


一个月后,我们将推出新系统Vera Rubin。它采用全新CPU,性能是Grace的两倍,内存、带宽更大,功耗仅50瓦。鲁宾版还配备全新GPU CX9、网络、智能网卡、NV Link 6、NV Link以及内存HBM4,除机箱外部件全新。如此设计能在一方面合理承担风险,避免基础设施相关其他方面过度冒险。Vera Rubin NV Link144将于明年下半年推出。NV Link144表示连接144个GPU芯片。
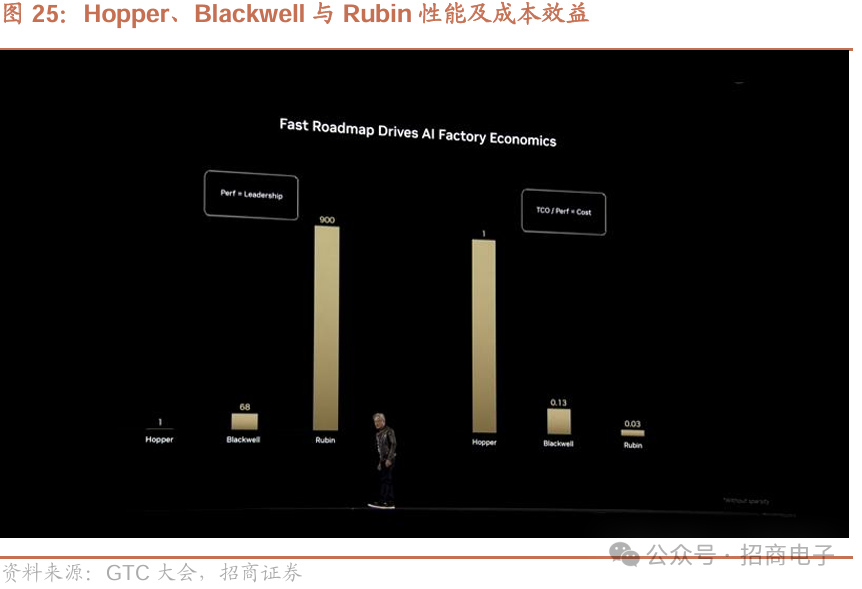
2027年下半年将推出Rubin Ultra,其NV Link达576,实现极致大规模扩展。每个机架功率600千瓦,含250万个部件,配备大量GPU。各方面显著提升,浮点运算能力从提升1倍变为15倍(达304.6 PetaFLOPS),带宽提升到4600字节每秒。全新NV Link和CX9众多,每个封装有16个位置,每个位置4个GPU,NV Link规模庞大。目前大家可能正在大规模生产Grace Blackwell 。我们先纵向扩展,再进行横向扩展,纵向扩展方面,Hopper浮点运算能力提升1倍,Blackwell提升68倍,Rubin提升900倍。
若将其转化为TCO,用这些数字计算,能直观判断人工智能工厂进展,Rubin将大幅降低成本。
16、以太网与光子学技术突破
这是英伟达快速发展的路线图,如同时钟般每年都有新进展。我们借NV Link实现纵向扩展,同时准备利用无限带宽和Spectrum-X进行横向扩展。很多人对我们进入以太网领域感到意外。我们之所以决定涉足以太网领域,是因为若能让以太网拥有无限带宽的特性,网络使用和管理对所有人而言都将变得更便捷。
我们决定投资Spectrum-X,将拥塞控制、极低延迟等特性及大量软件融入其中,使其成为计算架构的一部分,最终Spectrum-X性能卓越。我们用它构建了史上最大的单个GPU集群——Colossus集群,还有诸多成功案例,Spectrum-X无疑大获成功。我对其中一个领域格外期待,尤其是它采用了我们与台积电合作研发的出色制程技术。我们与庞大的技术供应商生态系统合作,创造出接下来要展示的成果,这是一项极具创新性的技术。


这是个光学设备,光信号从黄色部分进入,插入交换机后变为电信号连接。设备一侧有收发器、激光器及Mock Xander技术。比如,信号借此从GPU传至交换机,再经多个交换机传至另一GPU。若有10万个GPU,一侧需10万个此类设备,连接交换机间还需10万个,另一侧连接其他网络接口卡(NIC)也需相应数量。若有25万个GPU,还得增加一层交换机。
这25万个GPU中,每个GPU配备六个收发器,即有六个接口插头,这使每个GPU额外耗电180瓦,成本增加6000美元。若扩展到100万个GPU,乘以6个收发器,就有600万个收发器,每个收发器耗电30瓦,仅收发器就耗电180兆瓦,且它们只传输信号不运算。能源是关键资源,这180兆瓦耗电会削减客户收益,限制客户收入,进而影响我们自身收入。
为此,我们发明了世界首个MRM micro mirror。它有个小波导,上面连接环形结构。环形结构会共振,能控制光信号在波导中的反射率,限制、调制能量和光量,通过吸收光阻断或让光信号传播,将连续激光束转化为二进制的“1”和“0” 。

然后,这项技术所涉及的光子集成电路会与电子集成电路堆叠在一起,而电子集成电路又会与一整套微透镜堆叠在一起,微透镜再与一种叫做光纤阵列的部件堆叠在一起。所有这些部件都是使用台积电的一项技术制造的,他们称之为“cowos封装”,采用的是3D共封装技术,与众多的技术供应商合作完成,就是我之前给你们展示过名字的那些供应商,最终将它们组合成了这台令人惊叹的设备。

光子学封装、专用集成电路、6 个光子组件、18 个硅光子引擎

光子学交换机、太比特每秒(图31);专用集成电路、28.8太比特每秒的吞吐量、用于网络计算的 10.5 万亿次每秒半精度浮点运算(FP16)的SHARP性能


硅光子引擎、200吉比特每秒微环调制器、1.6 太比特每秒的吞吐量、3.5 倍的功耗节省、光纤连接器、光纤;硅光子引擎、200 吉比特每秒微环调制器、1.6 太比特每秒的吞吐量、3.5 倍的功耗节省、光纤阵列连接器、三维堆叠电子元件和光子集成电路、基板:

硅光子引擎、台积电 N6 工艺下的 2.2 亿个晶体管、1000 个集成光子器件、COUPE硅、电子集成电路、光子集成电路;多层数据光连接器、1152 根单模光纤:

外部激光源(ELS)、8 个集成激光器、自动温度跟踪、波长和功率调谐;光子学、18 个外部激光源、144 根多芯光纤连接器(MPO)光缆、324 个光连接、115 太比特每秒的吞吐量:

这一技术堪称奇迹,最终应用于我们的无限带宽交换机。硅基技术成效显著,今年下半年将推出硅光子交换机Quantum-X,明年下半年推出Spectrum-X交换机。这源于我们采用MRM技术,以及过去五年攻克的高难度技术风险,我们为此申请了数百项专利并授权给合作伙伴,助力相关产品制造。
我们能把硅光子学与共封装技术结合,无需收发器,可将光纤直接接入512端口的交换机,这是其他方式无法做到的,使我们具备扩展到数十万甚至数百万个GPU规模的能力,其带来的好处极为惊人,在数据中心可节省大量电力,保守估计能省60兆瓦,6兆瓦相当于10个Rubin超算机柜的耗电量,60兆瓦则相当于100个,节省的电力可用于Rubin部署。
我们的规划路线为每年更新路线图,每两年更新架构,每年推出新的产品线。持续提升关键因素,分阶段承担硅基、网络或系统机箱技术风险,在追求前沿技术的同时推动行业进步。

17、企业计算变革与Feynman发布
我们的下一代产品将以Feynman命名。为了能够将人工智能引入全球的企业领域,首先,我们得关注英伟达公司的Cosmos的优势。人工智能和机器学习已经彻底革新了整个计算架构体系。处理器不同了,操作系统不同了,上层的应用程序也不同了。应用程序的形态不同了,对它们进行编排管理的方式不同了,运行它们的方式同样也不同了。
未来人们访问数据方式将与过去截然不同,不再是精确检索后读取理解,而是像“Perplexity”那样,直接提问获取答案,企业处理数据也将如此。人工智能代理将成为数字化劳动力,全球10亿知识型工作者,未来或有100亿数字化工作者。如今约3000万软件工程师,未来所有软件工程师都将获人工智能辅助,今年底英伟达软件工程师也将如此。
人工智能代理将无处不在,其运行、企业运营及管理方式都将巨变,因此我们要推出全新计算机产品。即将发布全新计算机产品线,有一款新型个人计算机兼工作站,如Blackwell,采用液冷散热,运算能力达20千万亿次每秒,有72个CPU核心、芯片到芯片接口、高性能存储内存,还设PCI Express插槽装英伟达GeForce显卡,这款产品叫DGX工作站,DGX系列(含DGX Park和DGX Station)将通过惠普、戴尔、联想、华硕等OEM推出,专为数据科学家和研究人员打造,代表人工智能时代计算机及其运行模式。
目前已拥有面向企业的完整产品系列,从小型设备到工作站、服务器及超级计算机,所有合作伙伴都能提供。计算领域三大支柱,一是计算(如现有产品),二是网络(如应用于企业的人工智能网络Spectrum-X,三是存储,存储必须革新,从基于检索转变为基于语义,在后台持续嵌入信息,将原始数据转化为知识。未来企业都将拥有类似超级智能存储系统,我们正与DDN、戴尔、惠普企业、日立、IBM、网域存储、Newtonics、Peer Storage、Vast、Wecca等几乎整个存储行业优秀伙伴合作,首次推出由GPU加速的存储架构体系 。

18、英伟达开源模型及企业合作生态
戴尔公司将推出一整套英伟达企业人工智能基础设施系统,以及运行在这套系统之上的所有软件。

我们正致力于革新全球企业领域。今天将发布一个人人能运行的惊人模型。此前展示过推理模型R1及非推理模型Llama 3,R1更智能,作为Nims系统一部分完全开源。
大家可下载该模型,在DGX Spark、DGX工作站、OEM服务器、云端或智能代理人工智能框架中运行。我们正与众多公司合作,特别感谢埃森哲,朱莉·斯威德团队打造人工智能工厂和框架;奥多比系统公司,作为大型电信软件公司;AT&T的约翰·斯坦金团队构建其智能代理系统;贝莱德集团的拉里·芬克团队也在构建相关系统。
未来我们不仅招聘ASIC设计师,还会从楷登电子招聘数字异步设计师协助芯片设计,楷登电子也在构建人工智能框架。在这些合作中,均集成英伟达模型、Nims系统及各种库,可在本地数据中心或任何云平台运行。凯鹏华盈、德勤、安永、纳斯达克、思爱普(克里斯蒂安团队)、赛富等公司,都在将英伟达技术集成到自身人工智能框架中。
19、机器人技术发展与产业机遇
当下,机器人发挥作用的时代已至,其优势在于能与现实物理世界交互,完成仅靠数字信息无法做到之事。如今世界面临严重劳动力短缺,到本十年末,全球至少短缺5000万名工人。未来或许每年要给机器人支付5万美元让其工作,这将是个规模巨大的产业。
如今有各类机器人系统,基础设施也将机器人化,仓库、工厂里会有大量摄像头,全球约有1000万到2000万家工厂,汽车也可看作机器人,我们还在打造通用型机器人。
英伟达制造的三台计算机,可让机器人人工智能实现模拟、训练、测试及积累真实世界经验的循环。训练机器人需海量数据,互联网数据能提供常识和推理能力,但机器人还需行动和控制方面的数据,获取这类数据成本高昂。借助基于英伟达Omniverse(模拟平台)和Cosmos(数据平台)构建的方案,开发者能生成大量多样的合成数据训练机器人行为策略。在Omniverse中,开发者整合现实世界传感器或演示数据,调校Cosmos将原始数据转化为逼真多样的数据,再用Isaac Lab对机器人策略后期训练,让机器人通过模仿学习或强化学习掌握新技能。
实验室训练和现实操作不同,新策略需实地测试。开发者用Omniverse进行软件和硬件闭环测试,在数字孪生模型中模拟策略。现实操作需多机器人协同,Mega和Omniverse Blueprint让开发者能大规模测试后期训练的策略组合,如在虚拟生产设施中测试不同机器人。
许多成果源于模拟。今天推出英伟达Isaac Groot N1,这是适用于类人机器人的通用基础模型,基于合成数据生成、学习和模拟构建,具有快慢双系统架构,慢系统让机器人感知、理解环境和指令并规划行动,快系统将规划转化为精确动作。Groot N1的通用性使机器人能操作常见物体、协同执行多步骤任务序列,类人机器人开发者可在不同环境下对其后期训练。各行业开发者都用英伟达的三台计算机构建下一代实体人工智能。
实体人工智能和机器人技术发展迅猛,值得关注,有望成为最大规模的行业之一。从核心看,面临同样挑战,即数据获取、模型架构以及扩展法则(如何扩展数据、计算能力或两者同时扩展让人工智能更智能)这三个系统性问题,在机器人技术领域同样存在 。
20、英伟达机器人技术相关技术与模型发布
在机器人技术方面,我们构建了一个名为Omniverse的系统,它是我们实体人工智能的操作系统。大家听我谈论Omniverse已经很久了。今天,我们为它增添两项技术,给大家展示两样东西。
其一,为借助有生成能力且能理解现实物理世界的生成模型来拓展人工智能,我们推出Cosmos。利用Omniverse调校Cosmos,再由Cosmos生成无穷无尽的环境,如此便能创建基于现实、受我们掌控且在系统层面无限的数据。看Omniverse,我们用色彩鲜明的示例,展示在场景中对机器人的完美控制,而Cosmos能创建所有这些虚拟环境。
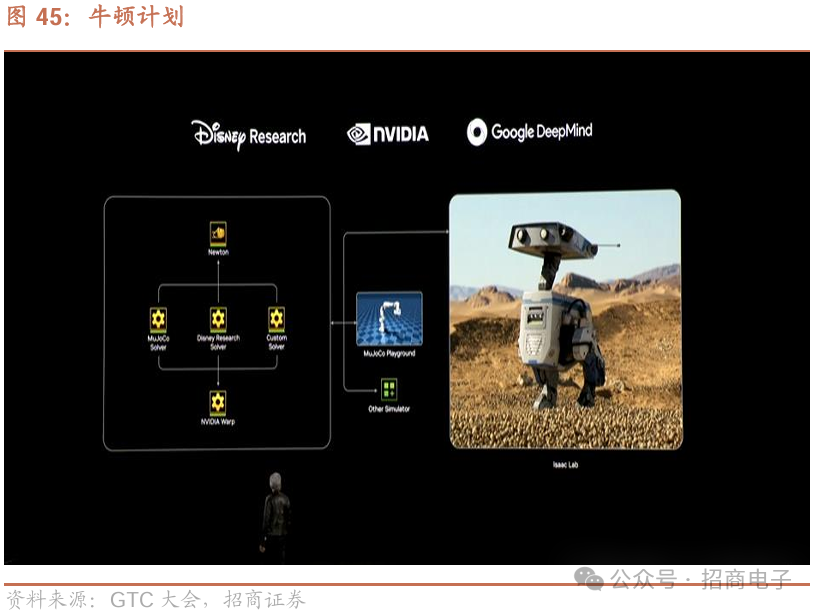
其二,如之前所说,如今语言模型令人惊叹的扩展能力之一是可验证奖励的强化学习。但在机器人领域,可验证的奖励是什么呢?显然是物理学定律带来的可验证物理奖励。所以,我们需要强大的物理引擎。多数物理引擎因不同目的设计,像用于大型机械,或服务虚拟世界、电子游戏等。但我们需要专门处理精细刚性和柔性物体的物理引擎,它要能用于训练抓握操作、处理反馈,实现精细运动技能和执行器控制。同时,它需能由图形处理器(GPU)加速,让虚拟世界以超线性时间、超实时速度运行,快速训练人工智能模型,还得能和谐集成到全球机器人专家常用的框架——MuJoCo中。
所以今天,我们宣布一个特别项目。这是深度思维(Deep Mind)、迪士尼研究院(Disney Research)和英伟达(Nvidia)三家公司的合作项目,我们称其为“牛顿计划(Newton)”。下面一起来看看“牛顿计划”的相关内容。
我们在机器人技术方面取得巨大进展。今天宣布,Groot N1将开源。
感谢大家参加GTC。总结一下:一是Blackwell已全面投产,产量提升迅猛,客户需求旺盛,因为人工智能领域处于转折点,推理人工智能及相关系统训练使计算量大幅增加;二是配备Dynamo的Blackwell NVLink72性能是Hopper在人工智能工厂性能方面的40倍,随着人工智能扩展,推理将成未来十年最重要的工作负载之一;三是我们制定了年度路线规划节奏,方便大家规划人工智能基础设施,且正构建用于云端、企业、机器人的三种人工智能基础设施。

 VIP复盘网
VIP复盘网
