


【新智元导读】OpenAI深夜突袭,GPT-5.4新王炸场!一夜之间,直接粉碎了Gemini 3.1 Pro和Claude Opus 4.6的神话。这也是头一次,ChatGPT拥有真正「原生电脑使用」能力,办公效率直接拉满。而真正恐怖的地方在于,每一个维度上它都没有短板。
被Gemini和Claude连续压了一个月后,OpenAI终于动手了。
就在刚刚,下一代旗舰GPT-5.4正式发布!
ChatGPT端:GPT-5.4 Thinking与GPT-5.4 Pro全面上线
开发者端:GPT-5.4接入API与Codex,并附带极速版GPT-5.4 fast


之所以直接跳到5.4,是因为这是一次「推理 编程」的合流式跨越
成绩单,直接炸裂。
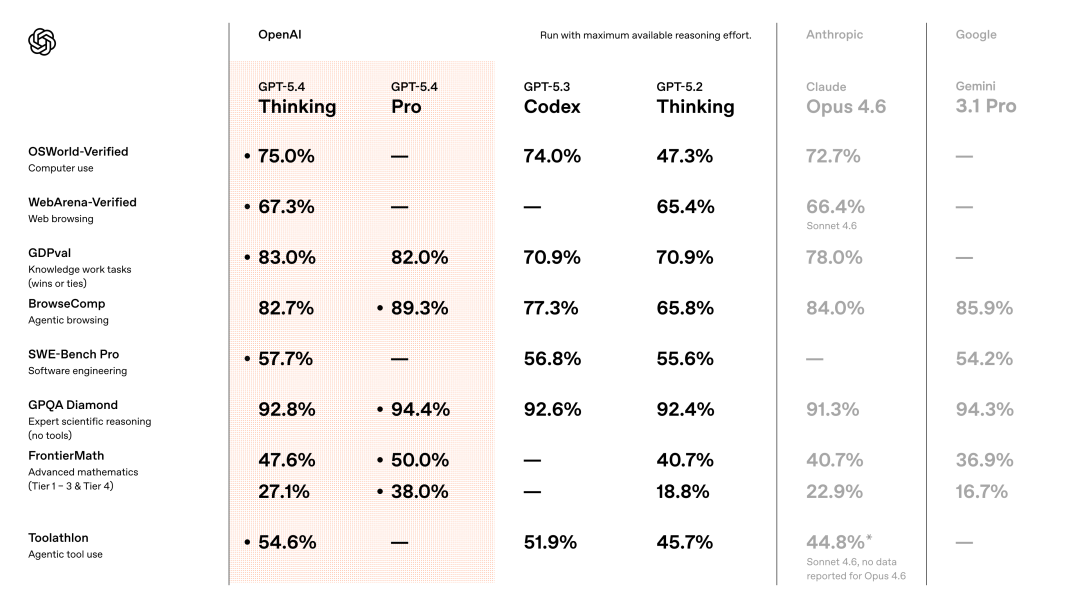
GDPval胜率83%,叫板顶尖人类专家;
SWE-Bench Pro编程第一,FrontierMath数学第一;
ARC-AGI-2抽象推理跑出83.3%新高,Gemini 3.1 Pro的77.1%、Opus 4.6的68.8%,全部踩在脚下。
OpenAI这次,是真的翻身了。
更炸的是,GPT-5.4还是首个拥有「原生电脑使用」能力的通用模型。
识别UI、操控键鼠、在软件和网页间穿梭自如,像人一样操作电脑。
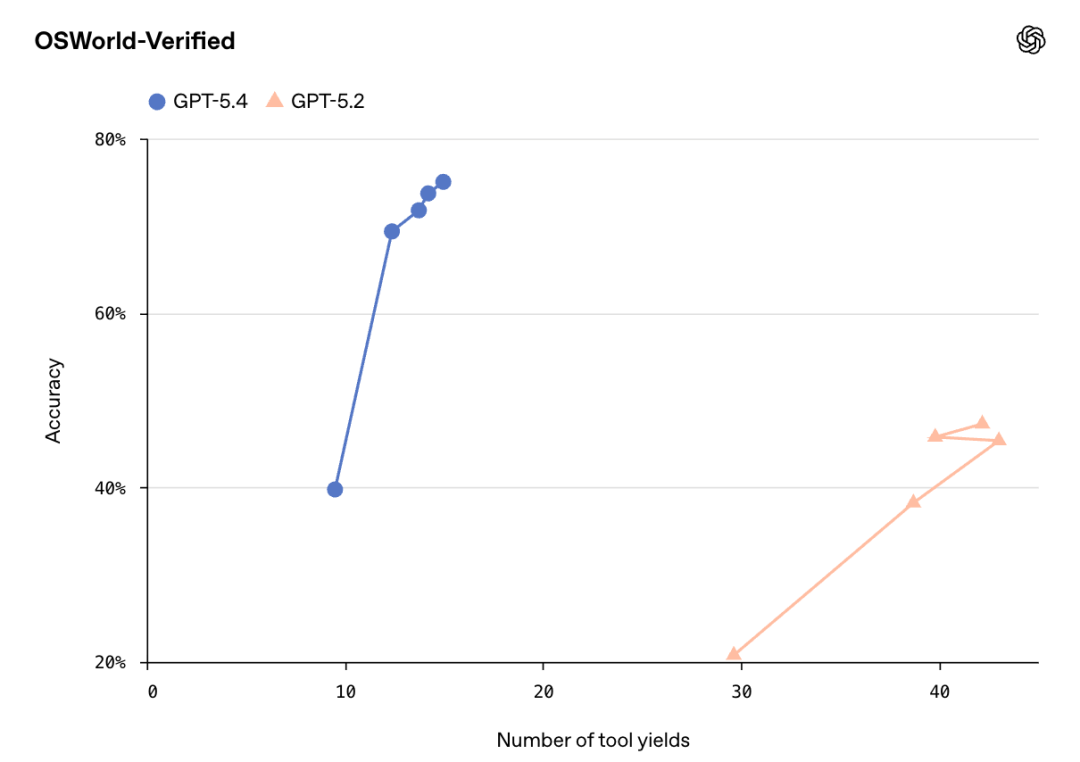
在OSWorld-Verified上,它直接拿下75%成功率,刷爆SOTA。
上一代GPT-5.2(47.3%),人类(72.4%),一个月前刚登顶的Opus 4.6(72.7%),通通都被超了。
没错,AI操作电脑,已经比人类更熟练了。
能力融合上,GPT-5.4继承了GPT-5.3-Codex的全部编程基因,并且新增了100万token上下文和原生工具搜索,一个模型打通推理、编程、操控全链路。
GPT-5.4 Thinking在思考时,你还能随时介入调整方向,不打断思路,一次对话直接交付结果。
看来,OpenClaw之父加入后,立马让ChatGPT原生「电脑操控」能力变强了!

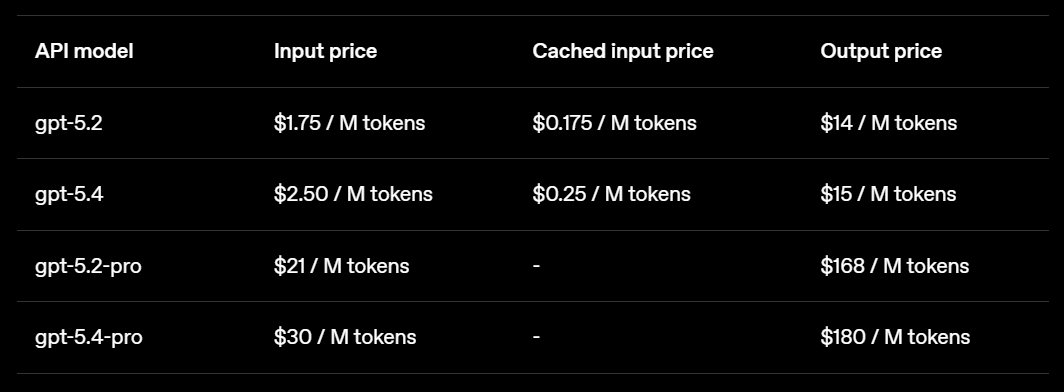
定价方面,GPT-5.4再创新高,输入价格2.5美元/百万token,输出价格15美元/百万token。
Pro版本就更夸张了,输入30美元/百万token,输出180美元/百万token。

先说最炸的部分。
GPT-5.4是OpenAI首个具备原生计算机使用能力的通用模型。
它能通过Playwright等库,编写代码来控制计算机,也能直接「看」屏幕截图动用鼠标和键盘。
发邮件、排日程、填表格、跑流程,这些以前需要你点来点去的活儿,现在GPT-5.4自己都能干。
在OSWorld-Verified中,GPT-5.4直接刷出了75.0%的成功率。
要知道,就在一个月前刚登顶的Claude Opus 4.6,成绩也不过72.7%。GPT-5.4一出手就把它甩开了2.3%。
在WebArena-Verified上,同时使用DOM和截图驱动交互时,GPT-5.4成功率达67.3%,领先GPT-5.2的65.4%。
在另一项Online-Mind2Web测试中,GPT-5.4仅靠截图观察就拿下了92.8%,而ChatGPT Atlas智能体模式只有70.9%,断崖级领先。
不过,GPT-5.4一切强大的执行能力,都是建立在更强的「通用视觉感知」能力之上。
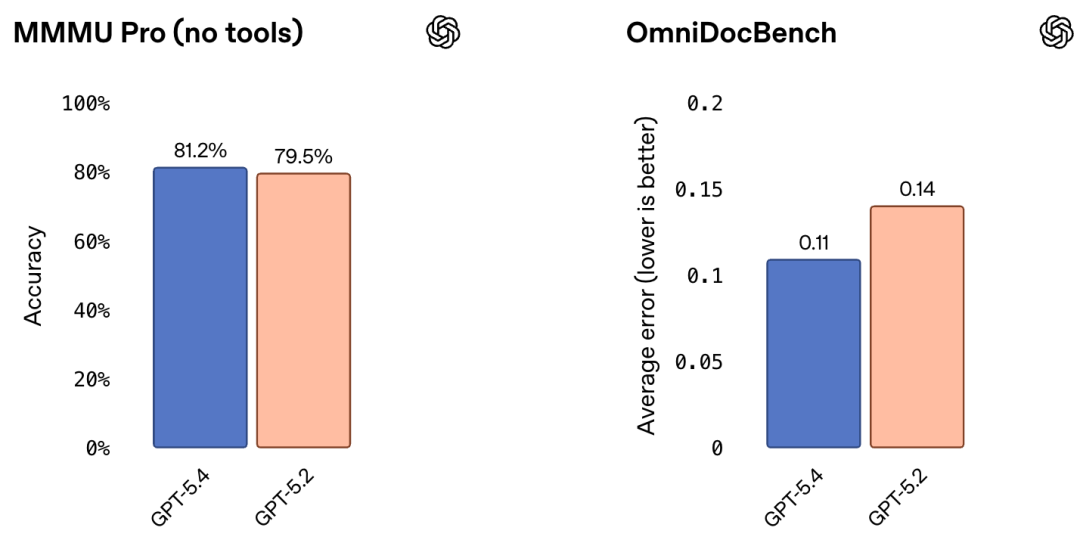
在MMMU-Pro上,GPT-5.4(不使用工具)的成功率81.2%,大幅优于GPT-5.2(79.5%)。
视觉感知的提升,也直接转化为更强的文档解析能力。
在OmniDocBench上,GPT-5.4(未开启推理强度)的平均误差为0.109,而GPT-5.2为0.140。
更重磅的是,GPT-5.4还首次引入「原始」(original)和「高」(high)图像输入细节级别。
前者支持最高1024万总像素,或最大单边6000像素(以较低者为准)的全保真度感知;后者支持最高256万总像素或最大单边2048像素。
在API早期测试中,GPT-5.4在定位能力、图像理解和点击准确性均有大幅提升。
如果说计算机使用是「硬功夫」,那知识工作就是GPT-5.4的「软实力」。

在GDPval基准测试中,GPT-5.4以83.0%的成绩,追平甚至超越了行业内的专业人士。
上一代GPT-5.2仅有70.9%,一个版本的差距,直接拉开了12个百分点。
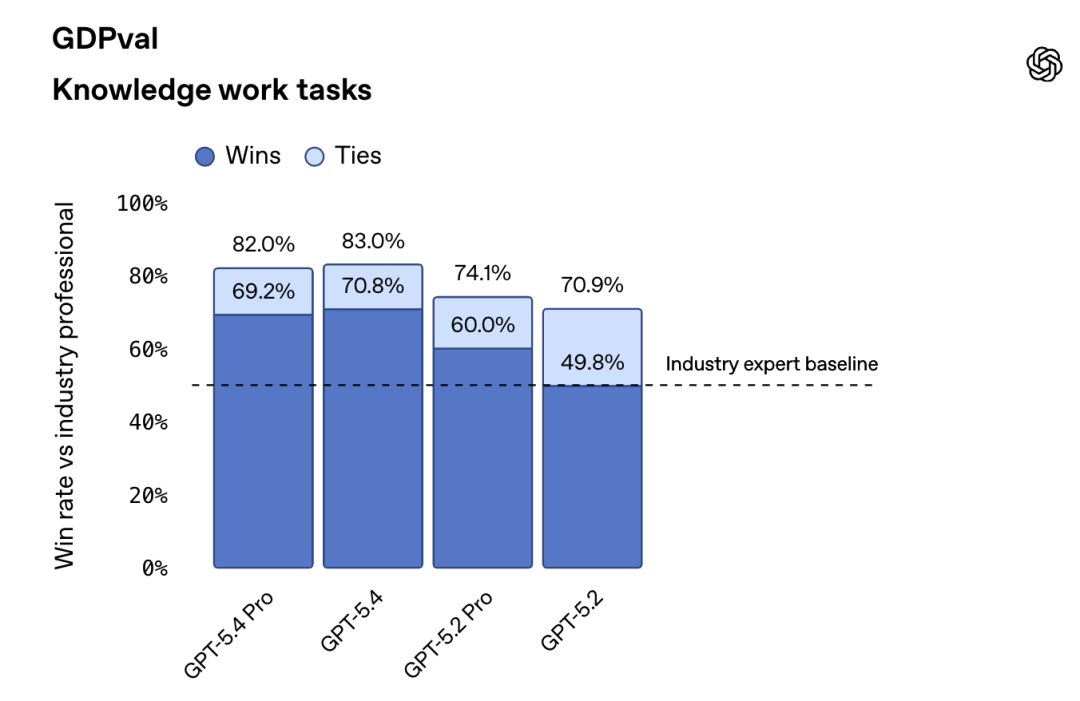
GDPval测试横跨美国GDP贡献最大的9个行业、44种职业,包括销售演示文稿、会计电子表格、急诊排班表、制造图表、短视频等,全部都是要求AI真刀真枪地交付工作产出。
GPT-5.4已经能做PPT、做Excel、排班表了,而且做得比大多数专业人士还好。
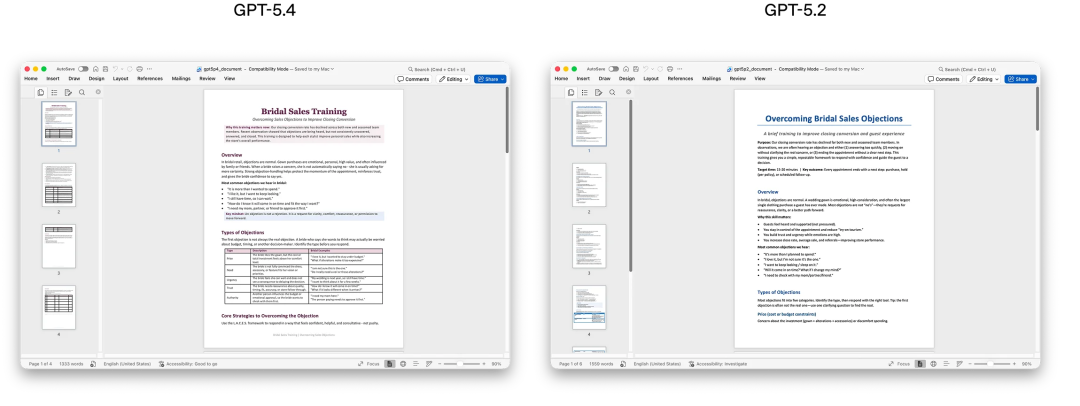
在一项模拟初级投资银行分析师的内部电子表格建模测试中,GPT-5.4平均得分87.3%,GPT-5.2只有68.4%。
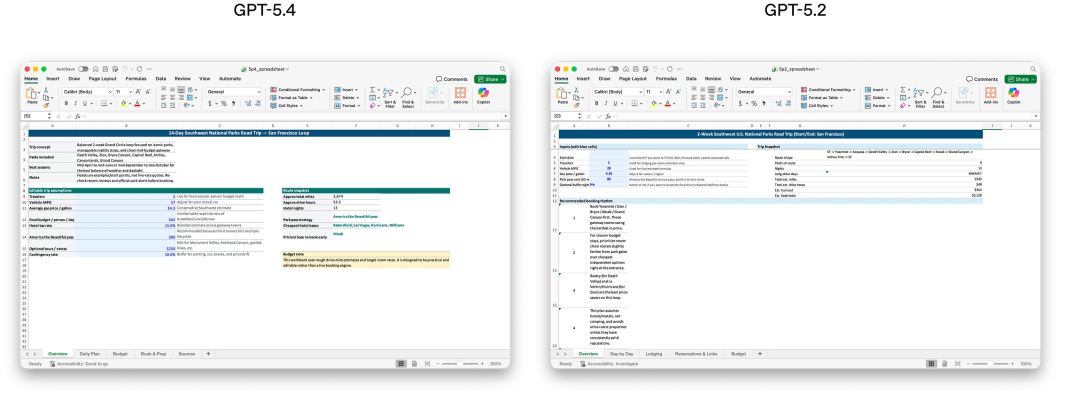
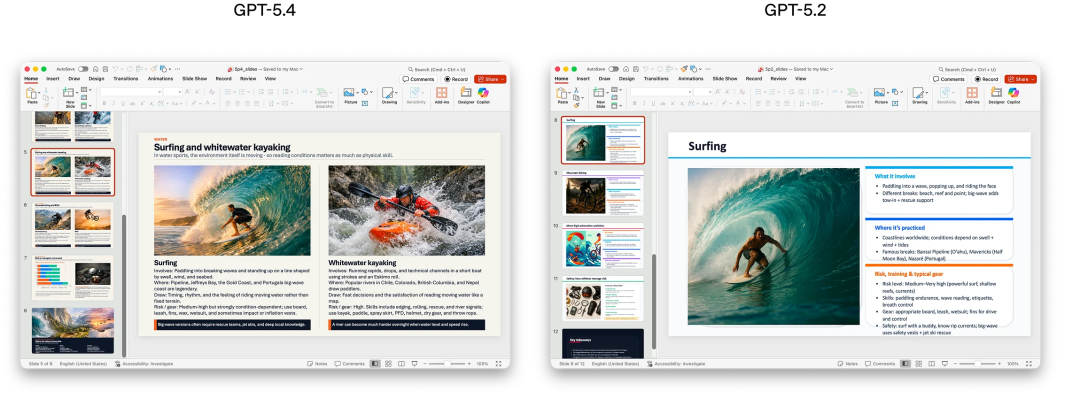
不仅如此,人类在68.0%的情况下,更偏好GPT-5.4生成的PPT,因其美感更强、视觉更丰富、图像使用更高效。

为了让GPT-5.4真正胜任实际工作,OpenAI在减少幻觉和事实错误上持续发力。
这么说吧,GPT-5.4是OpenAI迄今为止,最讲求事实的模型。
在一组去标识化的、包含用户标记事实错误的提示词集中,相对于GPT-5.2,GPT-5.4单独声明出错的概率降低了33%,整个回复包含任何错误的概率降低了18%。
GPT-5.4的另一个大招,完整继承了GPT-5.3-Codex的编程能力。
这意味着,不再需要在「聪明的模型」和「能写代码的模型」之间来回切换。一个模型,全部搞定。
在SWE-Bench Pro测试中,GPT-5.4拿下了57.7%准确率,媲美甚至超越了GPT-5.3-Codex(56.8%)。
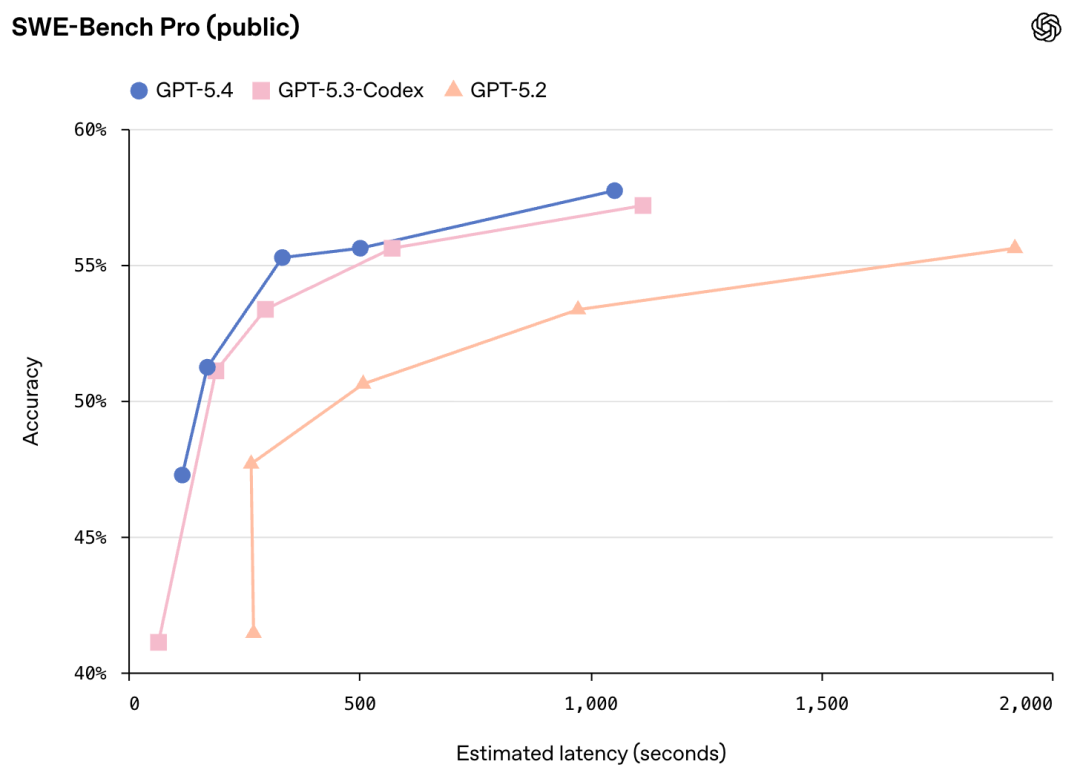
但真正的杀手锏不是分数,而是效率。
GPT-5.4是OpenAI迄今Token效率最高的推理模型,解决相同问题所需的Token大幅减少,成本更低,速度更快。
而且在各种推理强度设置下,GPT-5.4的延迟都低于GPT-5.3-Codex。
在Codex的/fast模式下,其Token生成速度最高可提升1.5倍。同样的智力,同样的能力,只是快了50%。
通过API,开发者也可以使用「优先处理」(Priority Processing)获得同样飞快的速度。
内部测试中,OpenAI还发现,GPT-5.4在复杂的前端任务上表现卓越。
生成的界面不仅美观,而且功能完备程度,远超此前任何模型。
为此,他们甚至还搞了个花活,发布了实验性的「Playwright Interactive」技能,让Codex能一边构建Web应用、一边在浏览器中可视化调试测试。
主题公园模拟游戏
仅凭一段提示词,GPT-5.4就徒手搓出一个完整的经营类游戏。
这一个全自动运行的微观世界,瓦片路网、设施建造、景观美化一应俱全。
而且,资金、客流、幸福感与评分系统环环相扣。
其中,Playwright充当了最严苛的质检员:从疯狂扩建到设施拆除,从镜头导航到 UI 数据验证,经过数轮自动化高压测试才最终交付。
传送门:https://developers.openai.com/showcase/theme-park-builder
战棋RPG
经过多轮迭代,GPT-5.4打造出一款回合制网格战斗游戏,包含移动、行动、站位和遭遇战等完整系统。
图像生成负责角色和美术风格,Playwright在每一轮迭代中验证界面交互、检查并微调UI行为和着色器效果,直到战斗手感、视觉表现和整体体验全部调优到位。
传送门:https://developers.openai.com/showcase/turn-based-rpg
金门大桥飞行体验
同样一段提示词起步,GPT-5.4生成了一个可以自由飞行的超写实3D场景——
逼真的光照、水面、雾气、悬索、桥上行驶的车流、周围的海岸线和城市背景,支持近距离结构穿越和远景风光俯瞰。
这里,Playwright化身「王牌飞行员」,开启多角度全自动巡航测试。
它不仅验证渲染视口的稳定性,还通过截图反馈协助 AI 持续校准构图与光影分布。 ,历经一小时的高频迭代。
传送门:https://developers.openai.com/showcase/golden-gate-flight-experience
在工具使用上,GPT-5.4的进化是多层次的。
工具搜索
GPT-5.4引入了「工具搜索」功能,彻底解决了MCP工具太多,上下文爆炸的问题。
只需要一个轻量级的可用工具列表,真正需要某个工具时,它会自动查找定义并即时加载。
在Scale的MCP Atlas基准测试(250个任务,开启全部36个MCP服务器)中,工具搜索配置在保持相同准确率的同时,将总Token使用量减少了47%。
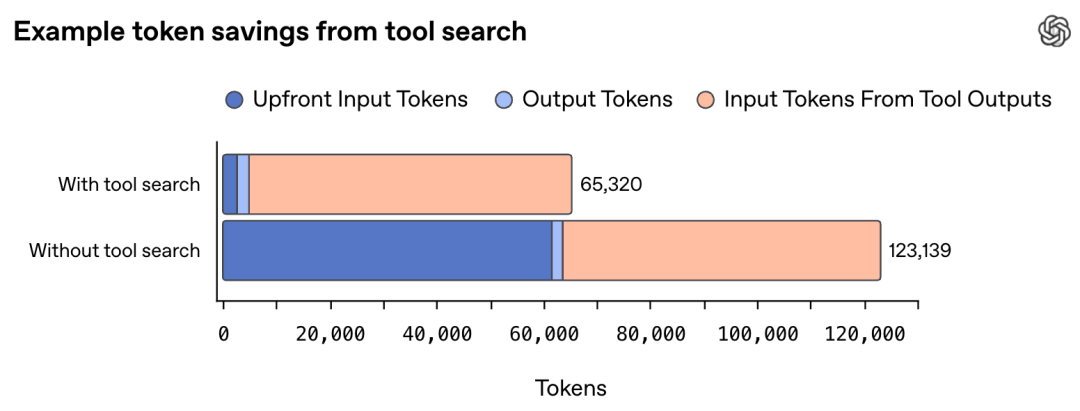
这对于工具定义动辄数万Token的MCP服务器来说,效率提升堪称恐怖。
智能体工具调用
在推理过程中,GPT-5.4决定「何时」以及「如何」使用工具时,更加精准。
在Toolathlon上,GPT-5.4以54.6%准确率,大幅领先GPT-5.3-Codex(51.9%)、GPT-5.2(45.7%),而且用的轮次更少。
智能体现在能顺畅完成「全套流程」——
阅读电子邮件→提取作业附件→上传附件→对作业评分→将结果记录到电子表格
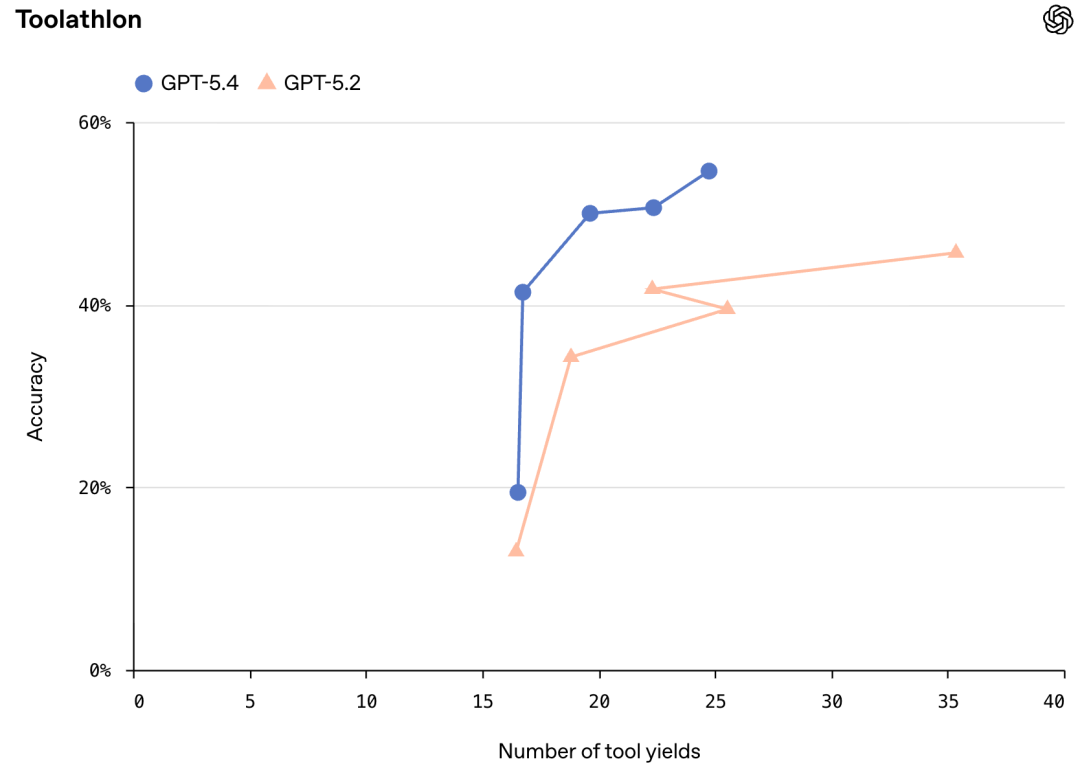
Toolathlon:评估多步任务中现实世界工具和API使用能力
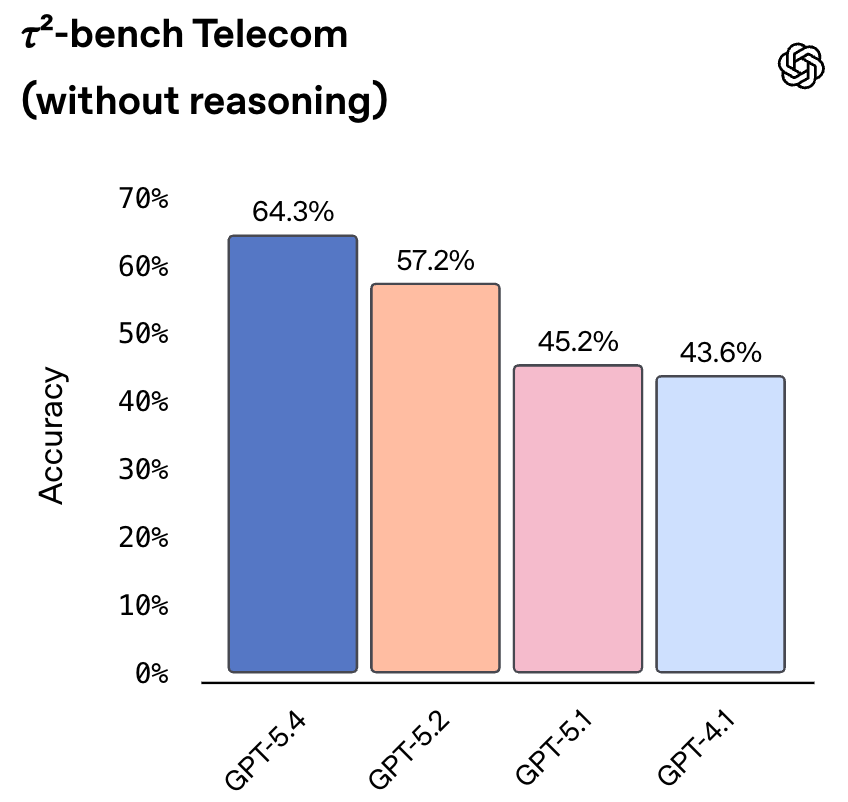
对于延迟敏感的场景(推理强度设为None),GPT-5.4在τ²-bench电信客服任务上也大幅领先。
而在开启推理强度(xhigh)的情况下,GPT-5.4在τ²-bench上更是达到了98.9%,几乎完美。
此外,GPT-5.4的智能体网络搜索能力迎来了大幅升级。
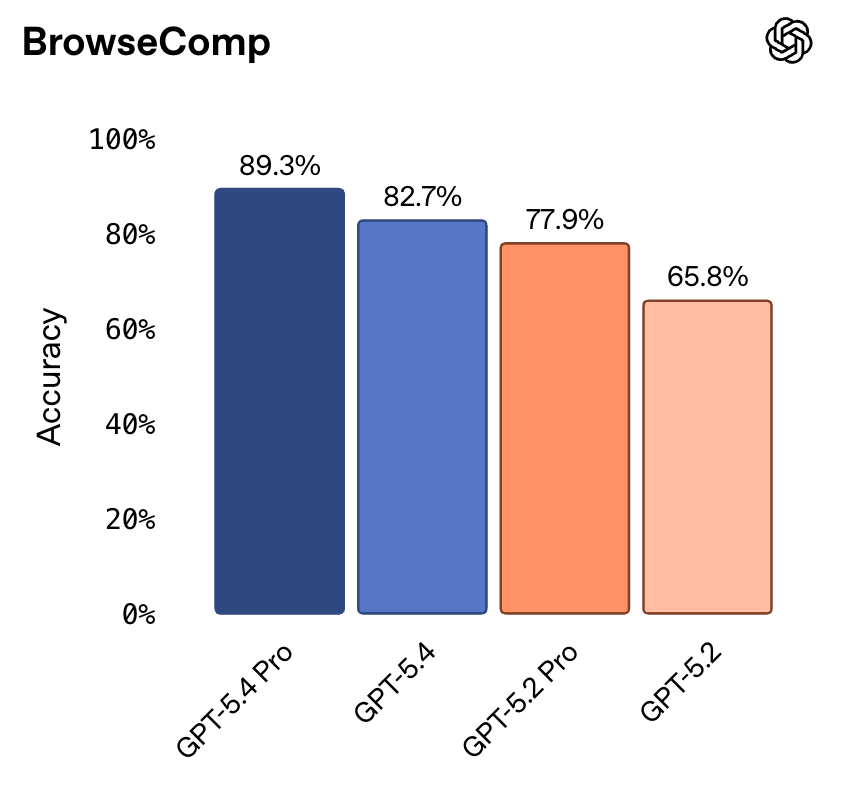
上一次,在BrowseComp测试中,Claude Opus 4.6凭借84.0%的成绩一骑绝尘,远超GPT-5.2 Pro(77.9%)。
但GPT-5.4 Pro直接以89.3%实现了反超,标准版的82.7%也和Opus 4.6咬得很紧。
在实际使用中,这意味着GPT-5.4 Thinking更擅长回答需要从网络多源头整合信息的问题。
它能更持久地进行多轮搜索以筛选最相关的来源,尤其是「大海捞针」式的问题,并将信息综合成条理清晰、推理严密的答案。
GPT-5.4 Thinking同时还改进了深度网络研究能力。
特别是,针对极其具体的查询,并且在处理需要长时间思考的问题时能更好地保持上下文。
GPT-5.4 Thinking在思考时,还可以随意介入,也不会打断思路。
此功能现已在网页和Android应用上线,iOS版即将推出
针对复杂冗长的查询,它会在回复前通过一段前言来梳理工作计划。
更关键的是,你可以在它运行中途直接调整方向、补充说明,而不需要等它全部做完再推翻重来。
一次对话就能拿到想要的结果,省掉了来回拉扯的多轮沟通成本。
同时,模型在处理困难任务时能进行更深入的思考,对对话的历史步骤保持更强的记忆感知。
GPT-5.4的发布,是OpenAI对Gemini 3.1 Pro和Claude Opus 4.6的一次全面反击。
GPT-5.4的恐怖之处在于,它没有短板。
推理、编程、视觉、工具使用、计算机操作、网络搜索、知识工作,每一条线都拉到了顶尖水平。
这不是某个维度的突破,这是全维度的碾压。
OpenAI用GPT-5.4告诉所有人:在通往AGI的路上,它依然是最不能被忽视的那个玩家。
最后,附上GPT-5.4最全面的成绩单。


 VIP复盘网
VIP复盘网
