


长期以来,医院护理评估环节面临评估表种类众多、信息分散、流程冗长及易遗漏等挑战。针对这一问题,我们在上海市同济医院开展了基于医疗垂直领域大语言模型 WiNGPT 的 AI 辅助护理评估试点。
依托大语言模型在非结构化病历理解及跨文档因果推理方面的核心优势, 试点项目成功将传统的“人工检索填报”模式重构为 “AI 智能预填 人工复核” 的新模式。实测数据显示,新模式在复杂逻辑场景下的预填准确率已超过 95%,且系统响应速度与审核效率均显著提升。这不仅大幅降低了护士的文书工作负荷,更有力验证了 AI 技术在护理文书处理工作中的实战价值。
背景
在护理日常工作中,评估是保障患者安全和制定护理计划的关键环节。护理评估需整合患者检查报告、医嘱及病史等多源数据。传统模式下,信息分散于不同系统,规则引擎看不懂自由文本,护士只能自己跨系统查资料,费时还容易漏。
针对上述问题,我们采用“无感嵌入”策略,将 WiNGPT 融入现有护理系统,避免额外学习成本,同时构建了“自动感知 — 智能预填 — 人工复核”的三步工作流:
自动感知:护士打开表单时,模型后台自动阅读电子病历、检验及医嘱。
智能预填:基于语义分析输出判断结果,自动勾选建议选项并提供溯源依据。
人工复核:护士由录入员转变为审核者,仅需确认或微调。
该流程旨在在不改变现有操作习惯的前提下,实现智能化与安全性的平衡。
护理评估创新
传统信息化手段依赖规则匹配,难以处理复杂逻辑和非结构化数据。WiNGPT 通过深度语义推理,解决了三类临床难题:
1.复杂时空逻辑:识别病程记录中的时间状语,自动计算事件与入院日间隔,支持如“住院前6个月内跌倒≥2次”等复合条件判断,而非简单关键词计数。
2. 药理知识归纳:内置药理知识库,自动识别并统计精神类、降糖类等高风险药物类别,无需人工逐一核对患者医嘱用药及其分类。
3. 跨文档线索整合:具备多源语义理解能力,自动关联分散在医嘱、药品知识、报告结果、电子病历等数据中的隐性线索,无需人工在不同文档与系统间反复跳转比对,如“TPN”。
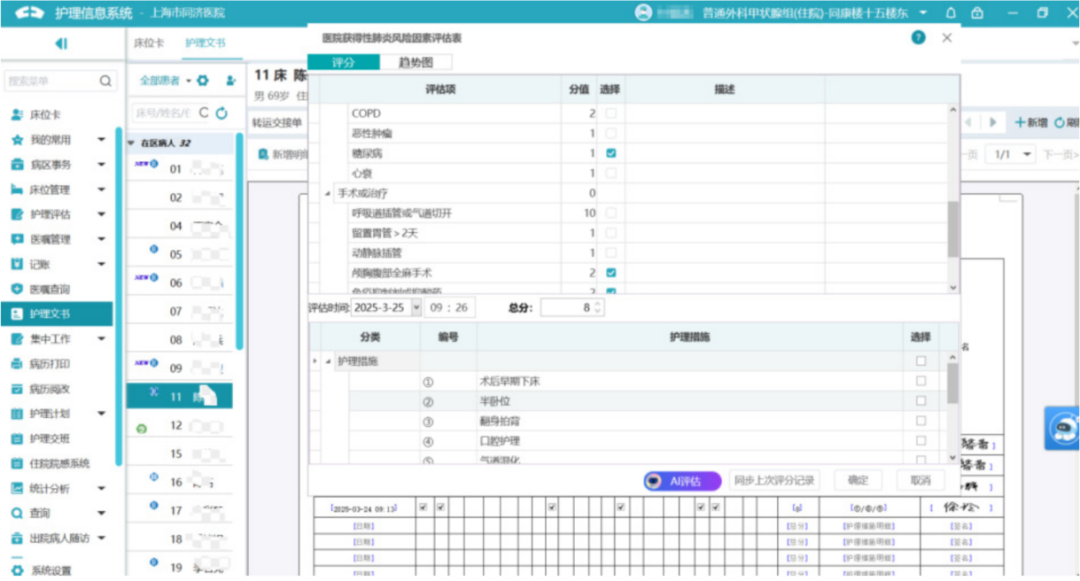
图1. 护理评估智能预填
上图展示了护理评估表单的智能预填功能,护士打开页面时,所有具有客观数据来源的选项已经被自动勾选,当护士点击某个被系统勾选的评估项时,系统会在旁边的原始病例文本中显示出具体的溯源依据。
结果与初步成效
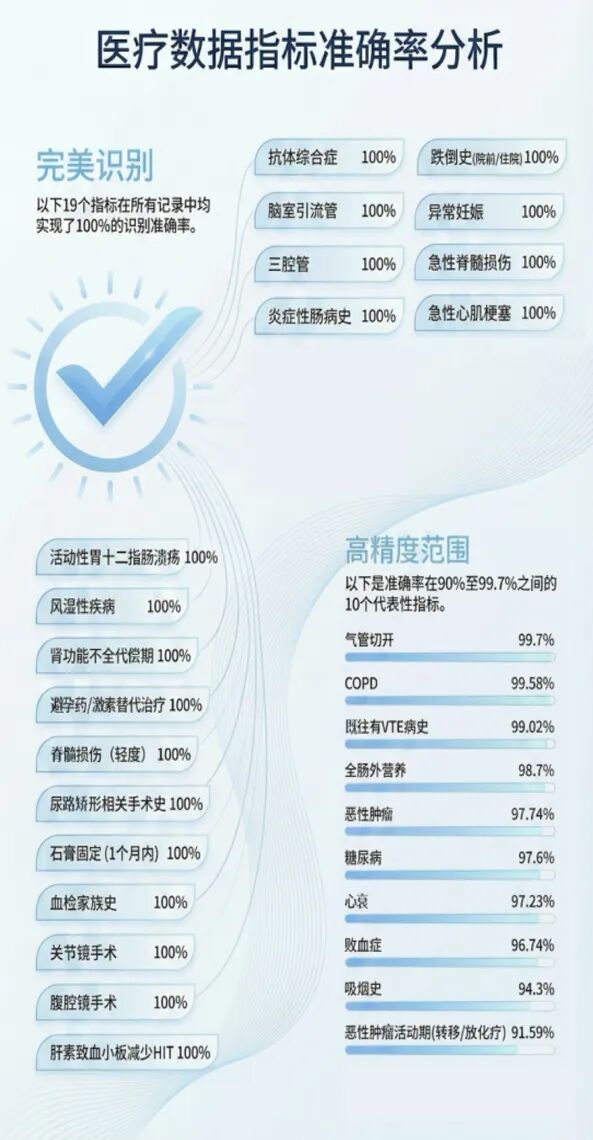
图2. 部分护理指标准确率一览
从上图可见,在不同类型的评估指标上,WiNGPT均保持了较高的准确性。
使用百分比
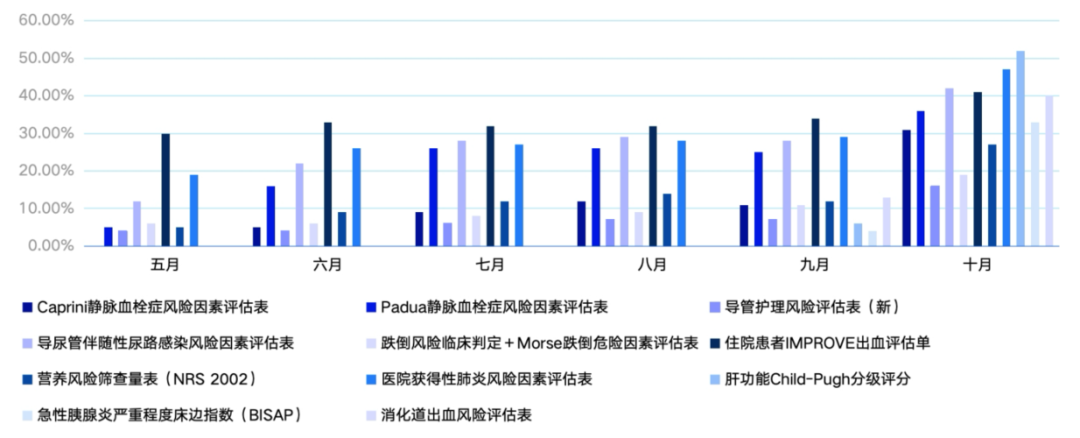
图3. 各评估表单使用效果
响应时间
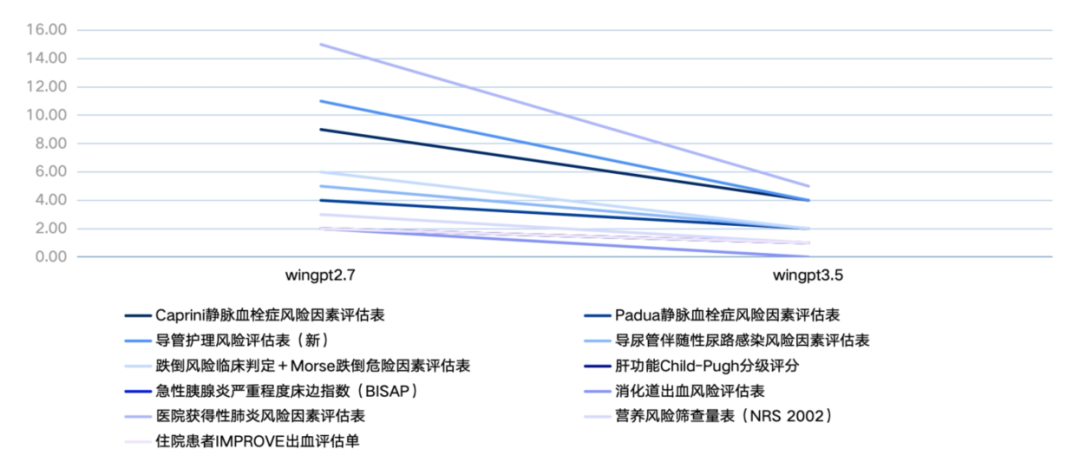
图4. 各评估表单使用响应时间
真实世界验证:准确性、效率与采纳率
基于上海市同济医院的真实运行数据,我们从三个维度对模型表现进行了评估:
1. 准确率:模型结论与资深护士评估高度一致,显著降低误报与漏报。
·COPD(慢性阻塞性肺疾病):样本量> 1190 例,准确率 99.58%。
·全肠外营养(TPN):跨文档推理场景,准确率 98.7%。
基础诊断类:在明确诊断指标上保持高位准确率。
2. 效率:模型升级后响应速度显著提升。
·医院获得性肺炎风险评估表:平均响应时间由 15 秒缩短至 5 秒。
·导管护理风险评估表:由 11 秒缩短至 4 秒。
3. 采纳率:随着速度与精度提升,AI 评估采纳率快速增长。如肝功能 Child-Pugh 分级与消化道出血风险在 5 个月内分别从 0 提升至 52% 和 40%。
小结
此次试点验证了两件事:一是 AI 的语义理解能力确实能补上规则引擎的短板,把非结构化文本变成可用数据;二是准确率高、响应快是护士愿意用的前提。这个案例也证明 AI 能有效减轻文书负担,这套做法可以复制到其他医院。下一步,我们计划把系统推广到更多病区。

 VIP复盘网
VIP复盘网
