

随着硬件架构迭代,卡单token的成本下降,能源价格在全球AI竞争中的重要性与日俱增。据我们测算,千万亿级全球日均token用量对中国电量和电力或有10%级别弹性,对绿证价格、容量电价甚至电量电价的拉动显著。推荐:1)低估值的绿电,有望充分受益于AIDC清洁能耗需求;2)推理时代电力瓶颈的出现大概率先于电量,容量电价市场化利好火电;3)重申我们1月报告《中美电价剪刀差——中国电力股何时见底I》的结论,2026年开始电力供给侧降速,电力板块步入配置窗口,token出海只是锦上添花。
训练时代,海外大模型由于数据管制不会布局核心算力在中国,国内大模型本土AIDC的需求增长又受制于国产芯片能力。推理时代,Anthropic/OpenAI等海外企业部署边缘算力在中国的探索逐步成熟,而国内大模型的规模效应与成本优势在token竞争中开始体现。我们测算常见参数的MoE推理模型每百万token的电耗在0.01-1度,若全球日均token调用量达到千万亿级别(目前百万亿级),对中美用电量的弹性在2%-12%。假设国产大模型1)30%-50%的市占率,2)70%-90%的本土算力部署, token需出海带来的用电需求对中国电量/电力的正向拉动可能达8%/18%。
硬件优化与架构创新带动单位算力GPU降本,电价占比快速提升
虽然中美电价自2025年底开始已经出现了明显的剪刀差,但我们测算电力在AIDC和token的单位成本中占比通常都不超过9%,芯片依然是当前算力竞争的决定因素。1)高配训练版AIDC中,电价占比仅5%;推理模型对峰值浮点算力的要求大幅降低,国产芯片适配度提升,硬件降维后电价占比翻倍达10%。2)token成本中,顶配海外芯片电价占比6%-8%,自研推理级芯片可能会推升电价占比上升至20%-30%。我们认为能源成本在AI竞赛中的重要性提升;至少中国宽松的电力供需不会成为算力扩张的瓶颈。
Token出海的电价弹性:绿证先于容量先于电量
根据我们的测算,国产token的全球竞争力有望增厚:1)我国2026-30年绿电需求4%-33%,利好本就折价的绿证价格;2)实现我国2026-30年容量电价增厚50-300元/千瓦有较大概率。中美两国在AI的需求爆发下缺电量的概率都不大,但是电力的紧张几乎都是确定性的。事实上,因为推理模型产能利用率显著低于训练,这意味着相同耗电量情况下,推理模型用电负荷更高;后训练和推理时代,AI对电力需求的弹性可能胜于电量的弹性。
与市场观点不同之处
市场尚未意识到AI的全球竞赛已经从“训练时代”演化到“推理时代”,国产与海外算力的差距在缩小,Agent模式的token消耗将会呈现指数增长。市场可能认为中国大模型token出海的核心竞争优势是电价,但是我们测算发现电价占比目前仅10%,随着芯片推理经济性和效率的优化、电价在单位token的成本中占比有可能持续提升。
最利好绿电和火电,尤其推荐关注低估值港股
推荐:1)受益于AIDC可再生能源需求的绿电公司;2)受益于容量电价弹性的火电公司;3)电量和电价弹性下利润兼具弹性、估值兼具性价比港股火电;4)2026年开始中国基荷电源和新能源装机都会降速,板块已经步入配置窗口。
风险提示:单位token能耗下降,数据本地化的法规挑战(海外API调用中国的大模型的算力需要本地部署),中国供给增速能否如期下降。
与市场观点不同之处
市场尚未意识到AI的全球竞赛已经从“训练时代”演化到“推理时代”,国产与海外算力的差距在缩小,而能耗增长曲线斜率更高。2026年已经进入AI Agent加速落地期,与2023-25年以大模型能力跃迁为主线不同,下一阶段产业主线不再是模型参数或benchmark的线性提升,推理需求对芯片的峰值算力下降,海外大模型的GPU优势边际减弱,国产算力依靠更高的性价比在全球竞争中脱颖而出。Agent模式的token消耗不是“对话量”的线性函数,而是“任务复杂度×执行时长”的指数函数,推理才是未来AI能耗的大头。
市场可能认为中国大模型token出海的核心竞争优势是电价,但是我们测算发现电价占比目前仅10%。传统预训练要求下,数据中心对电价成本敏感性不足5%,折旧占比超过60%。后训练和推理环境下,数据中心对电价成本的敏感性翻倍。我们保持其他参数不变,将训练常用的英伟达芯片置换成华为昇腾310系列,总成本中电费占比约9%,边际成本中电费占比接近60%。对于单位token的边际成本:海外芯片配置下,电价占比通常在10%以内;自研芯片中电价成本占比可能已经提升至20%-30%。虽然目前中国低电价不是token成本优势的主要原因,但是我们认为,随着芯片推理经济性和效率的优化、电价在单位token的成本中占比有可能持续提升。
Token消耗量对电能量电价的弹性可能不如绿证与容量电价。考虑到中央政策对AIDC绿电消耗比例80%以上的要求,token带来的电量满足要求最容易的方式就是购买目前显著低估的绿证(2025年绿证全年均价4.2元/张,2026年以来均价5.5元/张,仅为同期碳价的8%)。同时考虑到推理模型的产能利用率显著低于训练模型,电量的弹性可能要低于电力弹性,对电能量电价的带动可能晚于容量电价。正如我们在2026年1月的报告《公用事业: 中美电价剪刀差:大国的相同与不同》中阐述的,两国电力供需紧张程度都远高于电量供需,美国“缺电”迄今为止也没有缺电量,PJM容量电价快速上涨,电量电价并没有出现相对气价的超额上涨。
中国的电价优势在全球AI算力竞争中扮演什么样的角色?
正如我们在2026年1月的报告《公用事业: 中美电价剪刀差:大国的相同与不同》中阐述的,两国工业电价自2025年底开始已经出现了明显的剪刀差;随着美国的气价和中国的煤价的差距进一步拉大,新能源渗透率在两国的提升,都会更确立甚至加速这一趋势(得益于中国风光储和电网制造业的绝对优势)。
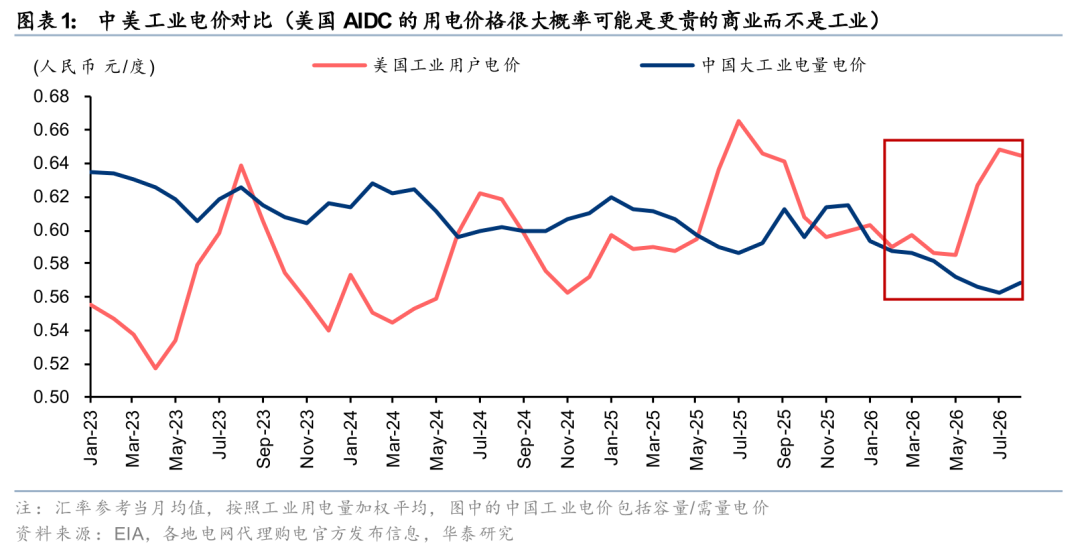
但是,我们认为低电价本身对数据中心的成本和token的成本都不是决定性因素,所以国产算力的优势更多体现在充足的电力供应上,产品迭代和产能扩张短期看不到能源瓶颈。
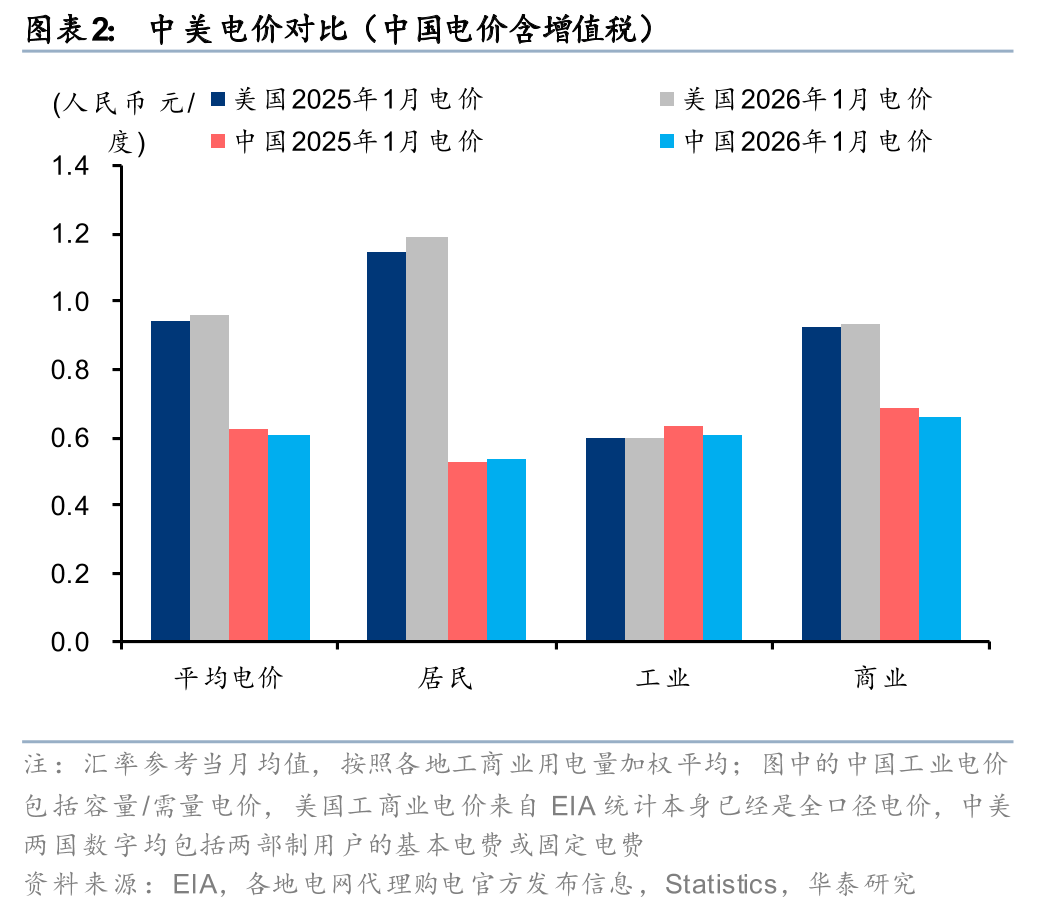
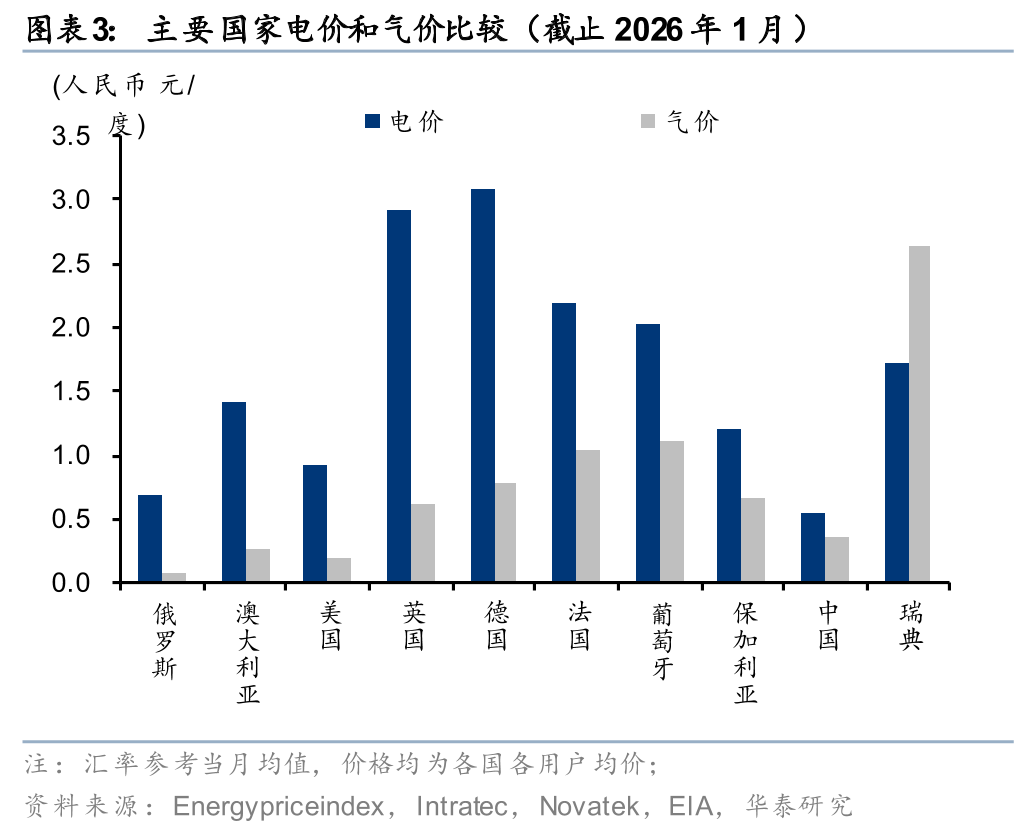
推理时代,电价对AIDC敏感性翻倍,更有可能吸引基建投资
早期Scaling Law聚焦预训练,对芯片的峰值算力要求较高,国产芯片存在一定差距。MoE之后推理模型成为主流选择,2024年9月开始以OpenAI的o系列为代表的“推理模型”在预训练后引入强化学习等后训练,后训练与推理对芯片的要求大幅下降。从目前海外模型的迭代进度来看,主流头部模型几乎全部是推理模型,后训练模型的算力需求还在进一步增加。国内在算力受限下更侧重架构与算法精修,Qwen、DeepSeek、Kimi 等以注意力优化、稀疏化与MoE 等提升训练推理效率与性价比。
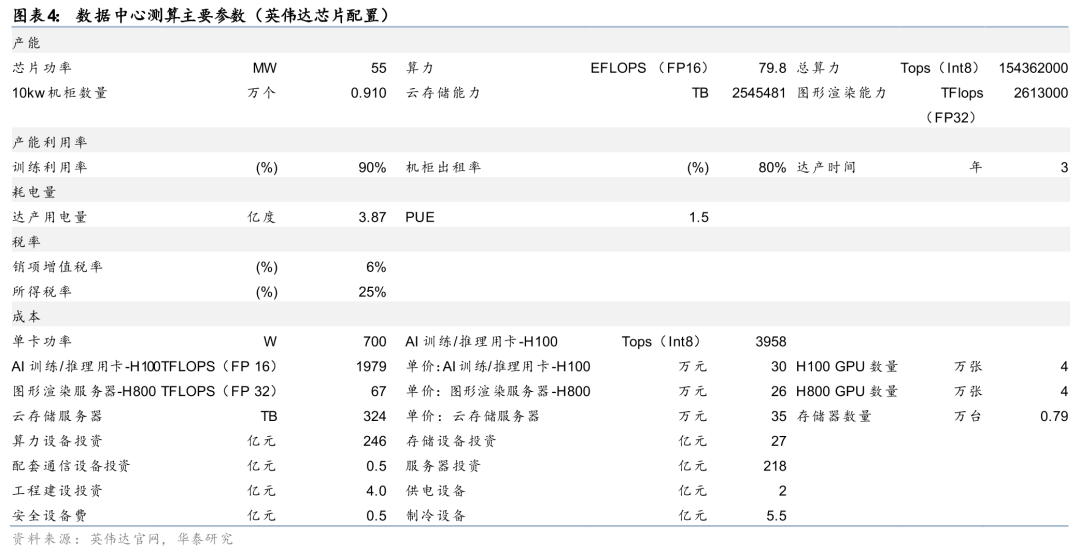
传统预训练要求下,数据中心对电价成本敏感性不足5%。根据我们的测算,一个典型80 EFLOPS(FP16)的大型智算AIDC,假设全部芯片采用英伟达产品(不考虑最新的Blackwell这类顶级训练卡,参考中国合规版H100/H800),服务器成本大概接近总投资的90%,总成本中电费只占5%,折旧占比超过60%。
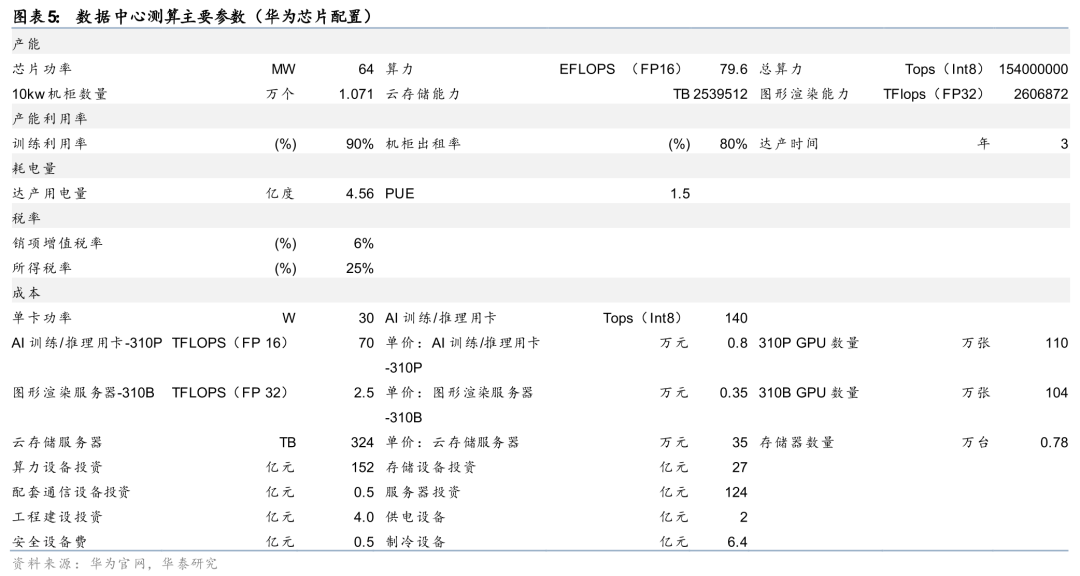
后训练和推理环境下,国产芯片配置的数据中心对电价成本的敏感性翻倍。我们保持其他参数不变,将芯片置换成华为昇腾310系列,总投资可以下降40%;在国产芯片版本的AIDC中,总成本中电费占比约9%,边际成本中电费占比接近60%。相较于海外主流训练模型而言,推理模型电价敏感性有显著提升,但总体来说影响幅度远不如芯片成本。根据2025年9月MIT Adam Zewe的研究,训练能耗的70%在大模型准确性上的提升不足2%-3%。
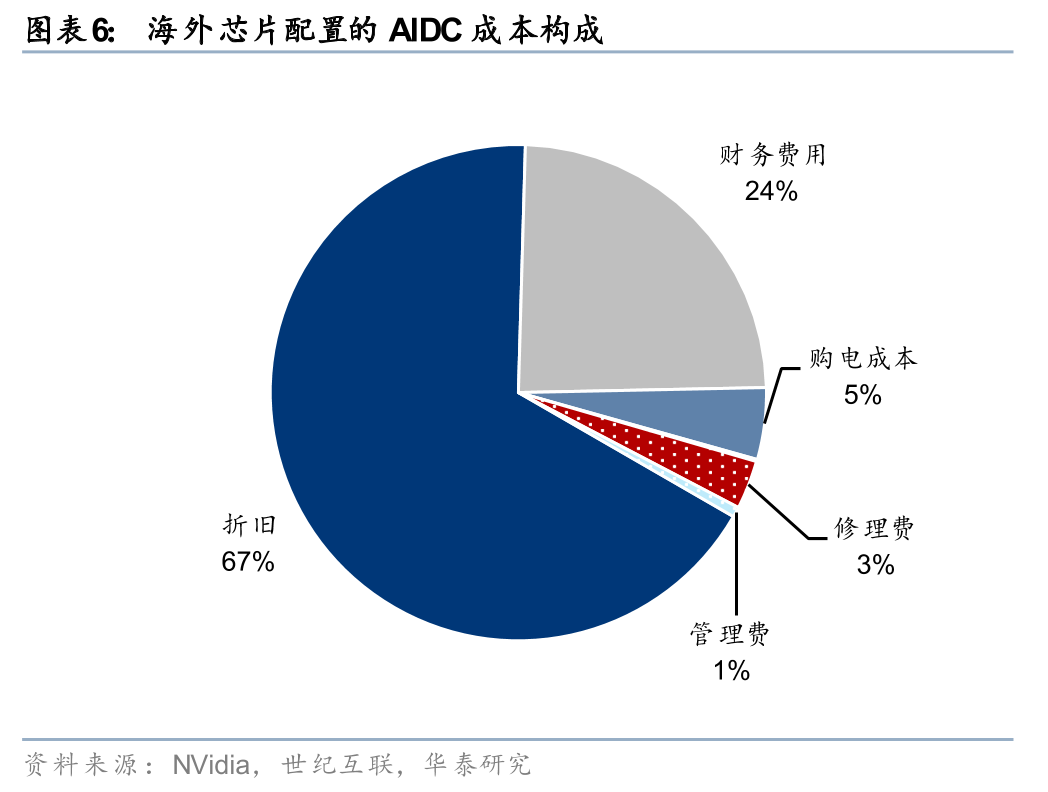
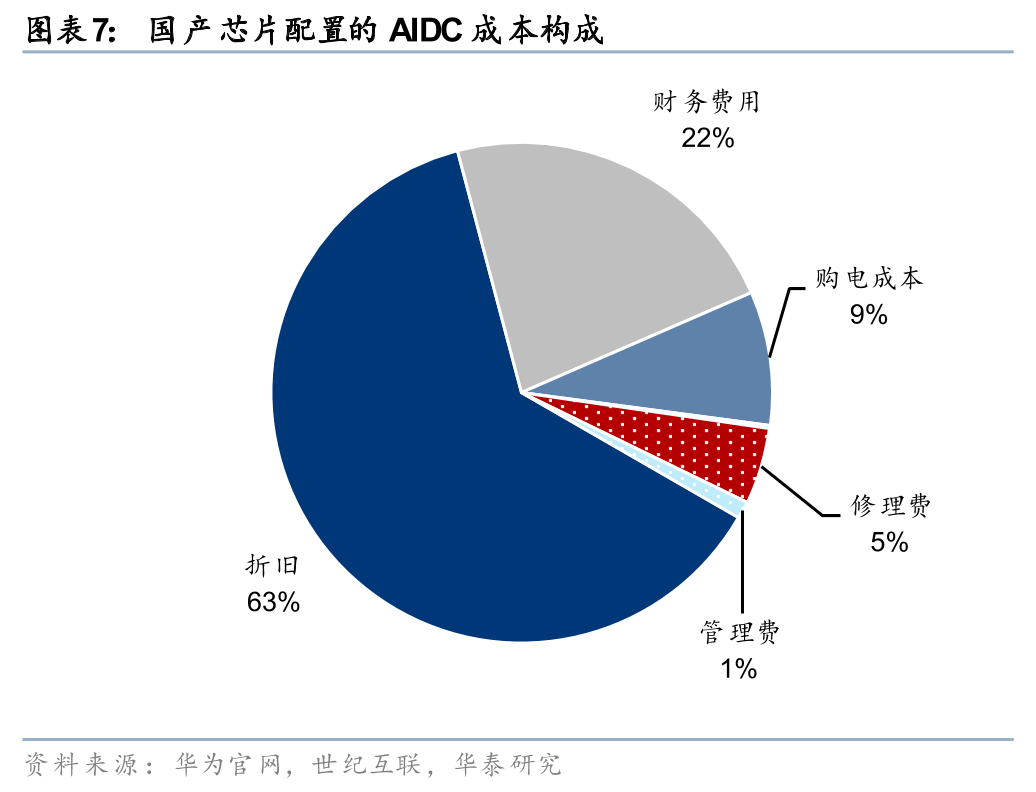
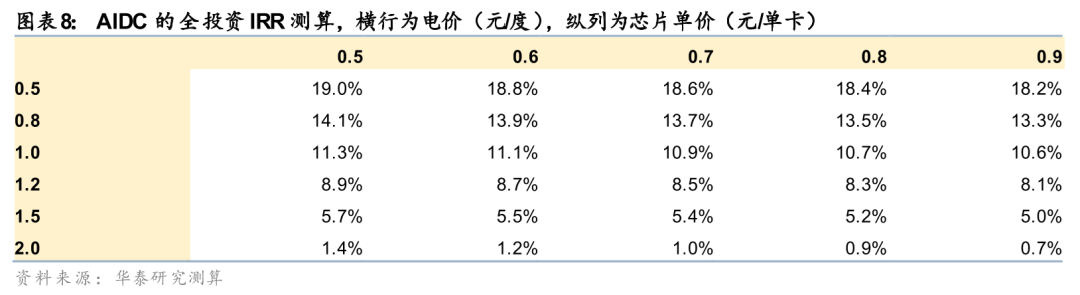
根据我们测算,电价0.1元/度的变化对AIDC的全投资IRR的影响仅0.2%,而芯片的可得性是核心瓶颈,且芯片的单价敏感性也远高于电价。所以,训练时代通过低电价吸引海外AIDC在电力供需宽松的中国本土的投资逻辑较弱,且受到我国对数据中心牌照的审批限制,外加《数据安全法》和《网络安全法》等法规制约,海外算力需求很难落实到中国基建投资。推理时代,海外大厂对非敏感数据的要求降低,更追求规模效应与交付成本,通过云服务合作、开源模型本地化部署、边缘计算轻量节点、有限合资试点等方式在中国可能有更多案例落地。
Agent开启token需求爆发,中国电力天花板高
AI Agent需求增长的背后是大模型从Chatbot转化为新质生产力。正如我们华泰科技团队在2026年2月的报告《华泰科技/计算机: Agent叙事强化,算力与SaaS分化加剧》中所阐述的:2025年是AI Agent元年,2026年可能进入Agent加速落地期,主要体现在两方面:一是Agentic Coding的迭代速度会大幅加快;二是国内外大厂会激烈争夺个人Agent助手的超级入口,均会成为下一轮token加速的重要推手。2026年将成为AI Agent推理端从“能力验证”走向“Agent规模化应用”的关键拐点年。与2023-25年以大模型能力跃迁为主线不同,下一阶段产业主线不再是模型参数或benchmark的线性提升,而是Agent形态驱动的token使用方式结构性变化。
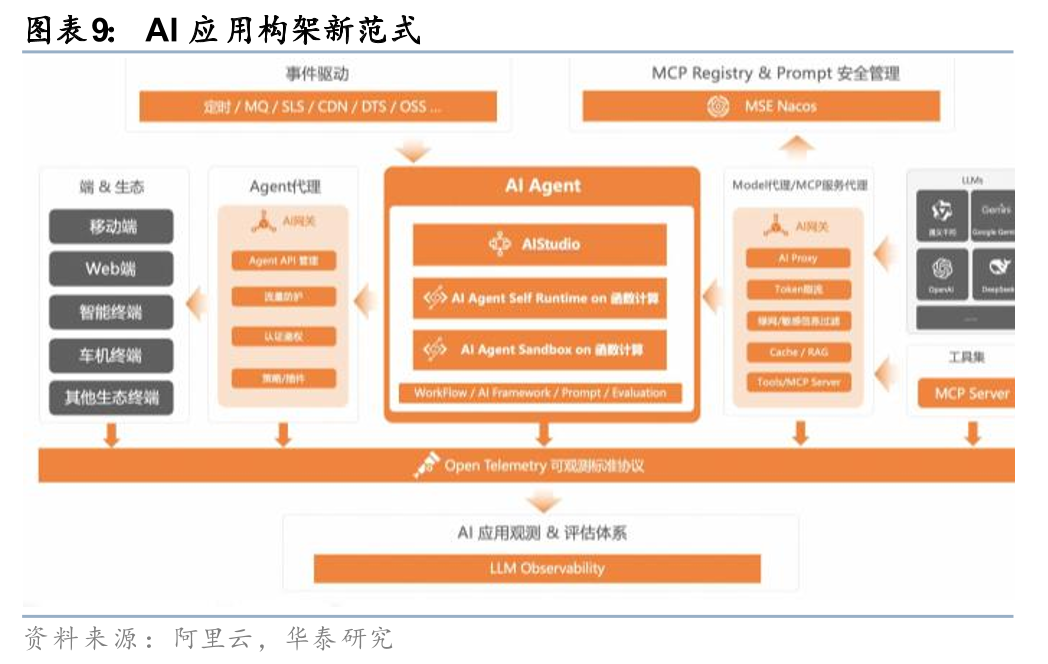
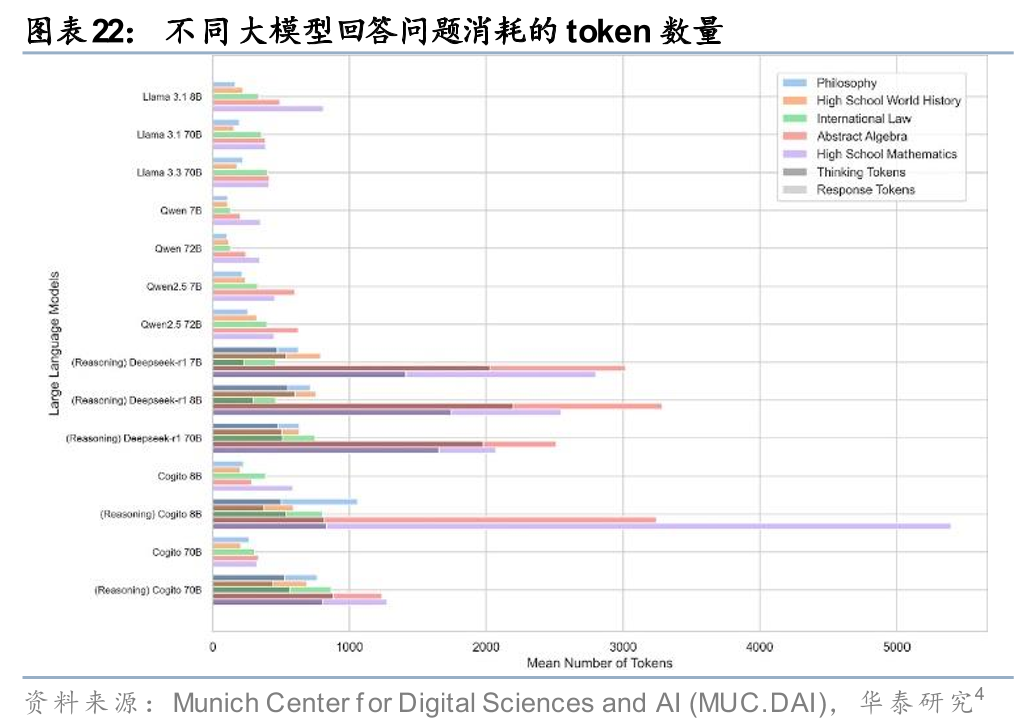
区别于传统Chat模式,Agent的推理范式算力消耗较大。多步规划、工具调用、长时间运行与状态保持这三点共同决定:Agent模式的token消耗不是“对话量”的线性函数,而是“任务复杂度×执行时长”的指数函数。以Claude Code为例,完成一个项目需要消耗百万级别 token(完成复杂项目的消耗会更大),这与chatbot单次交互消耗一千左右token相比,算力消耗提升3个数量级。从Claude Code技术文档来看,官方建议每名用户每分钟的token限制设置在20-30万token,算力消耗较大。
大模型Token的竞争中,电价的决定因素与日俱增
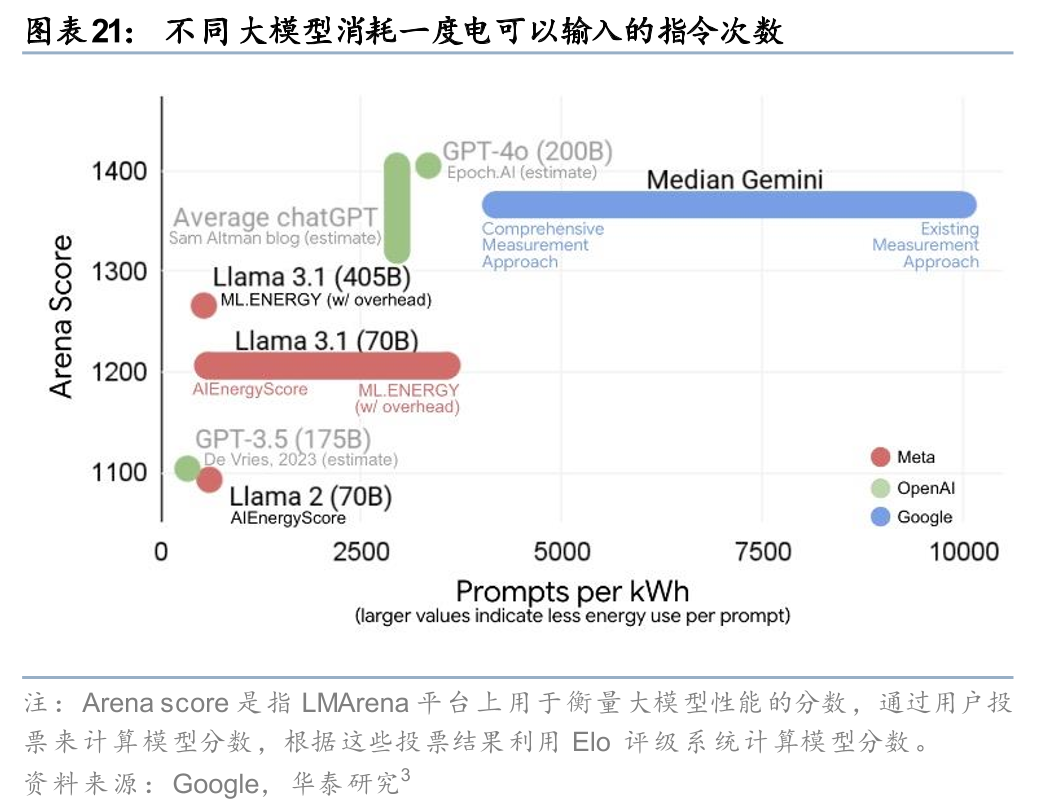
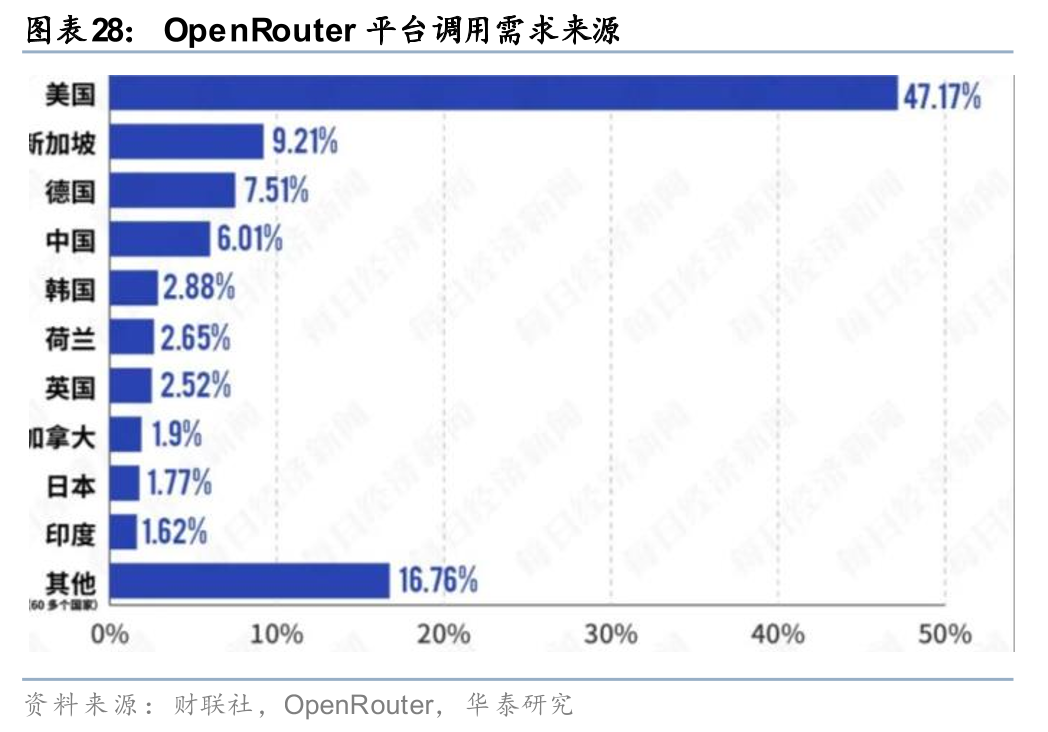
2026年2月26日,全球最大的API聚合平台OpenRouter公布的全球最新的Token用量榜单,9日~15日这周中国模型以4.12万亿Token的调用量,首次超过同期美国模型的2.94万亿Token。前五名中我国大模型独占四席(MiniMax M2.5、Kimi K2.5、GLM 5和DeepSeek V3.2),全球开发者对中国AI能力的认可逐渐显现。中国大模型的Token经济,是输出境内电力和算力的新范式,而且享受着1998年WTO电子传输不征关税的制度红利。
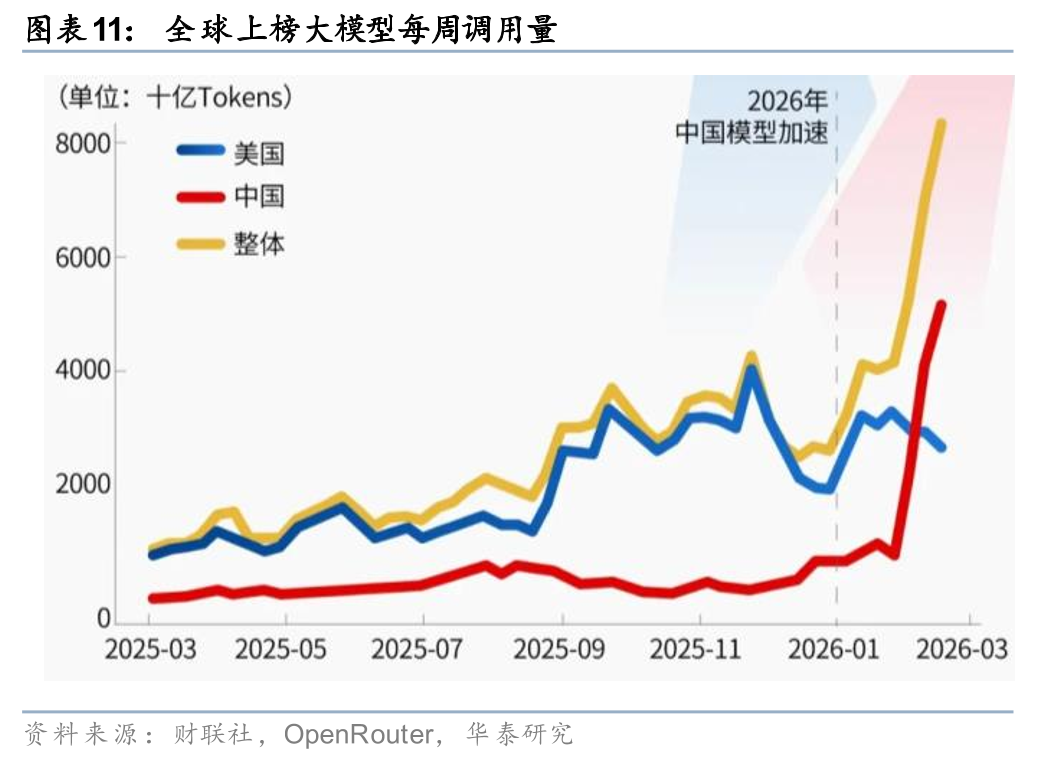
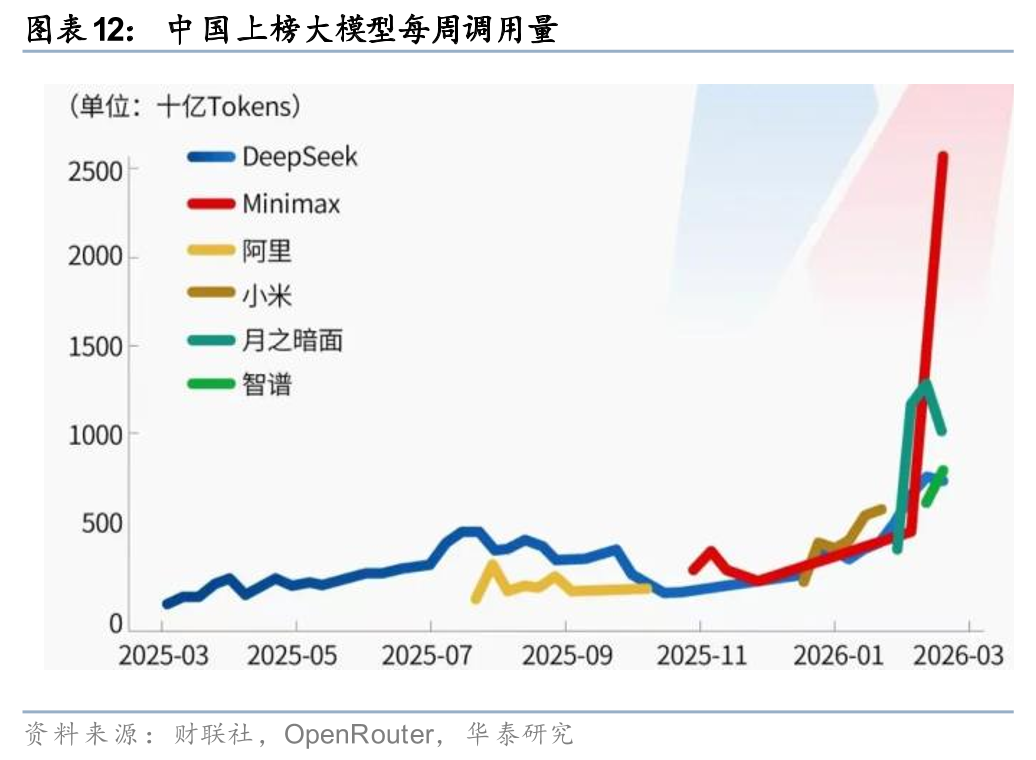
根据我们的测算,假设:
1) 推理模型中海外芯片的使用寿命为5年,国产3年;实际上推理LLM消耗GPU的速度未必这么快,而且大量推理模型是硬件复用的(使用的芯片是训练1-2年后的旧卡与新卡混配而成),芯片成本难以准确在训练和推理中分摊,但考虑到芯片技术迭代较快,使用者不可能真的以设计寿命来考虑回收成本;
2) 考虑50%的综合利用率,实际上长上下文的瓶颈还体现在显存等其他硬件,再额外考虑10%的冗余token备用;
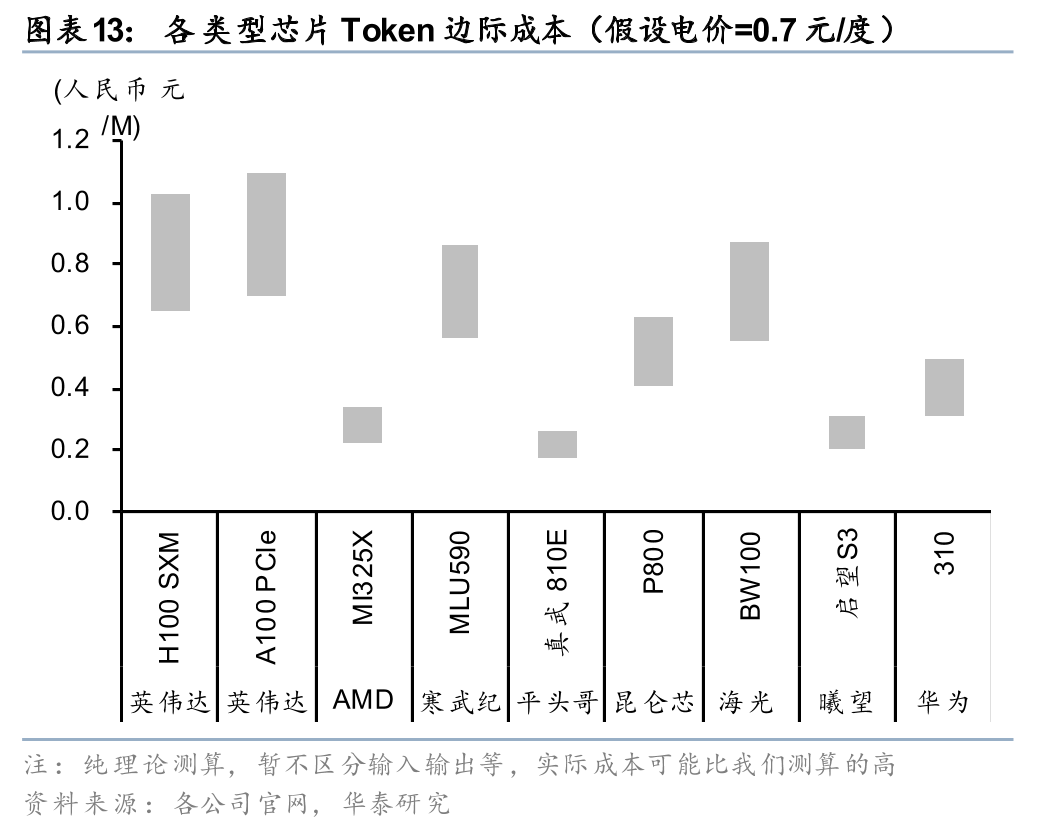
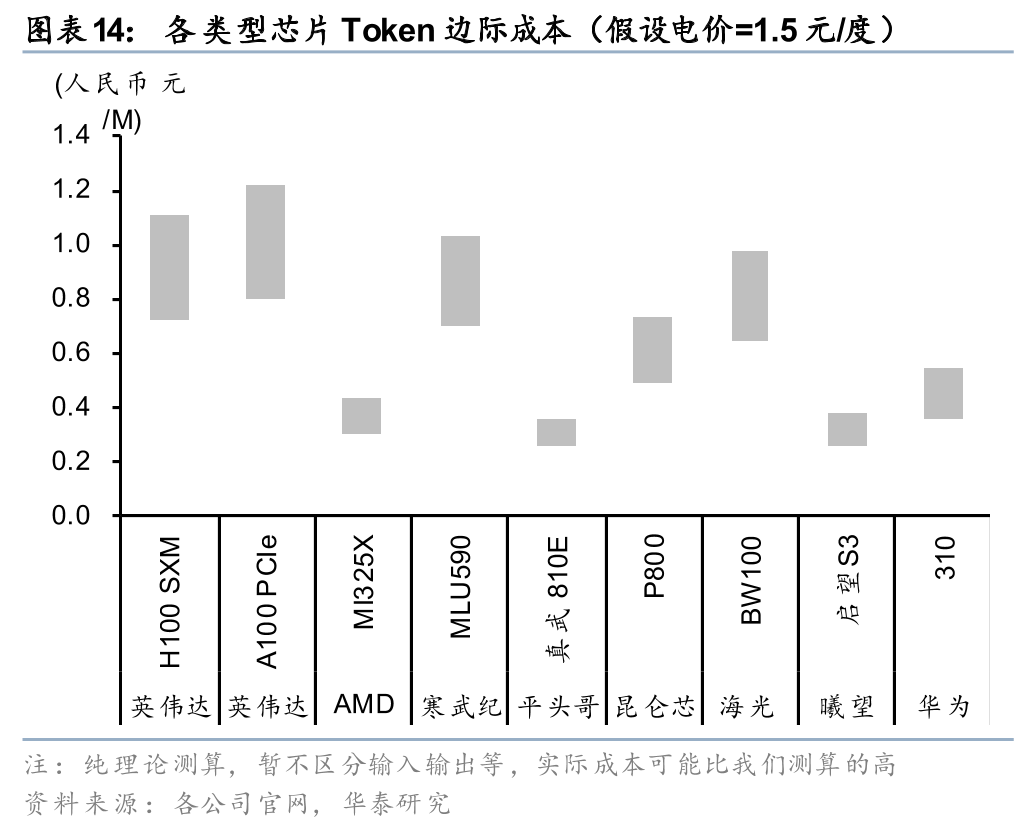
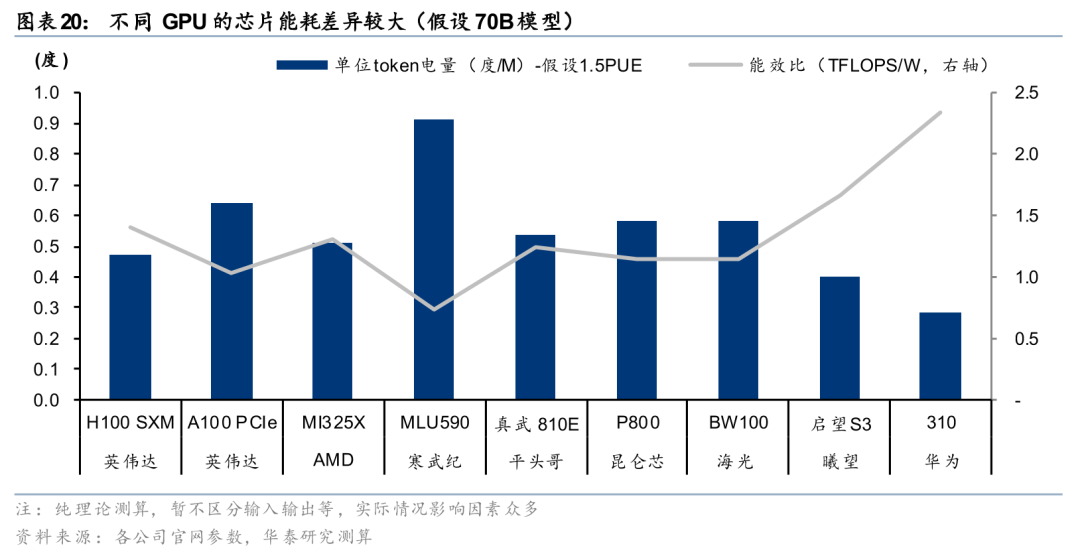
我们发现相同电价下不同GPU的token边际成本差异仍然高达2-3倍,可见芯片的差异对token的成本来说依然是决定性的;由于API调用时推理卡的峰值算力通常难以充分发挥,国产芯片和海外龙头的差距在LLM的应用上差距并不大,国内企业的优势很有可能不止是电价。根据我们的测算,英伟达芯片产生的token成本中,电价占比通常在10%以内;国产芯片中电价成本占比可能已经提升至20%-30%;所以我们认为虽然目前中国低电价不是token成本优势的主要原因,但是我们认为,随着芯片边际提升放缓、算法深度优化、规模效应放大,电价在单位token的成本中占比有可能持续提升。
事实上,考虑到响应速度和法规限制,海外API调用的token极有可能来自本地部署的AIDC(类似千问global模式和文心一言的海外版,推理资源在全球除中国大陆外的区域调用)。不过,除视频、对话能对响应速度要求极高的需求外,光缆传输百毫秒的延时、协议开销白毫秒级别的耗时和端口排队等拥塞,相比单个token本身就需要的百毫秒推理时长,并不一定是大部分需求的核心瓶颈。但至少我国电力的供应充足性与安全性是算力供给大幅扩张、短期看不到天花板的前提。
Token出海,对中国电力需求的影响
如何评估百万token的耗电量?
我们查询了海内外权威资料和研究,各方对单位token电耗量的数据相差不小,我们认为一方面是表述口径的差异(比方说计算的只是GPU的能耗,还是数据中心的热设计功耗),另一方面是不同类型的模型在不同架构下处理不同任务本身能耗相差几个数量级。
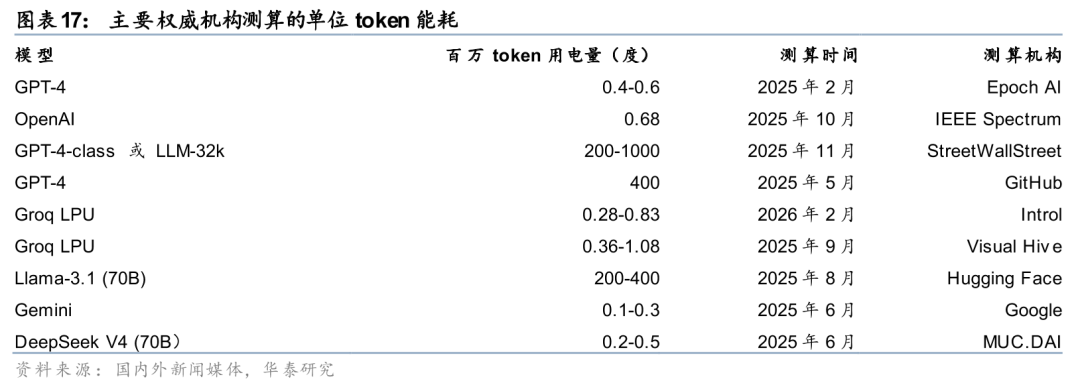
决定单位token能耗量的几个主要因素包括:
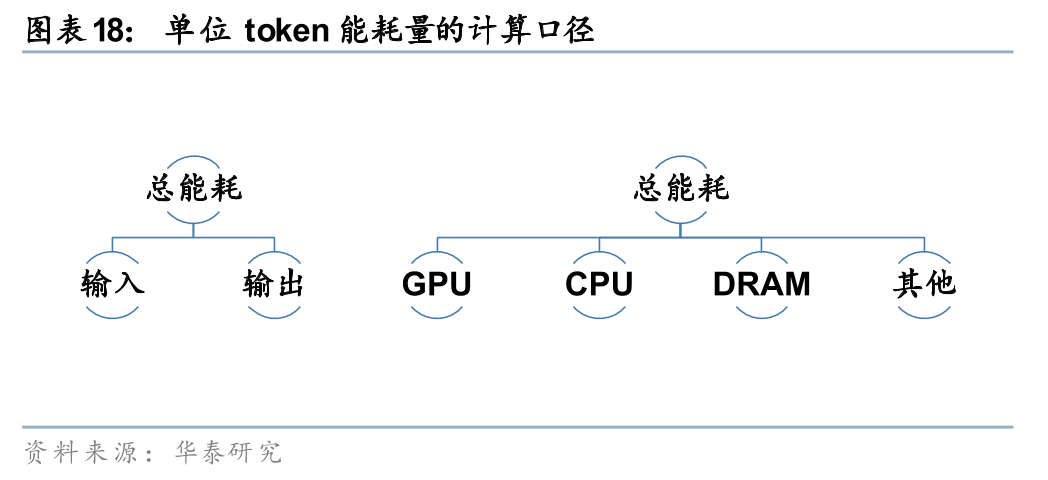
1. 硬件配置:使用不同芯片的能效比不同,专用ASIC/LPU比通用GPU能效高10倍以上,显存、缓存和模型的架构优化、冷却方式、电源效率等也影响总体能耗。
2. 模型类型:模型参数影响至关重要,7B模型比70B模型能耗低5-10倍,参数越多计算量越大,同理也适用于模型精度(FP16/32等);不同的模型种类例如vLLM/Transformer等注意力机制和激活比例也差异较大。
3. 推理方式:缓存命中率、批处理大小(批量推理 vs 单个推理),量化/蒸馏等优化技术,不同的并发策略,都会影响单位用电量指标。
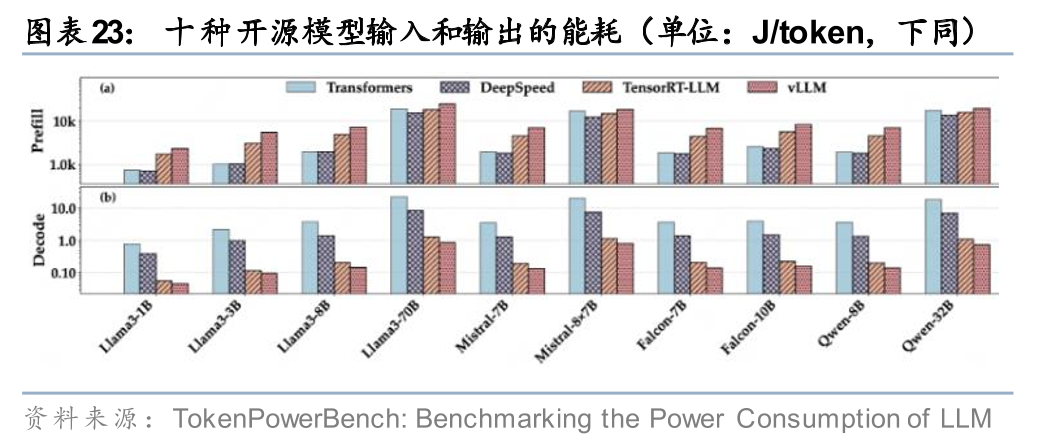
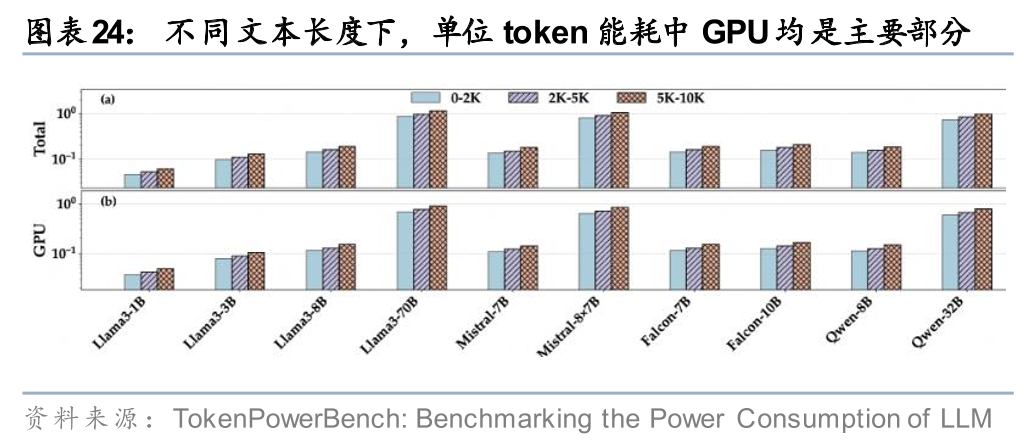
4. 任务类型:文本长度,标准Transformer模型化的注意力机制计算量通常随序列长度呈平方级别增长;低浮点精度可以大幅度降低计算和带宽需求。
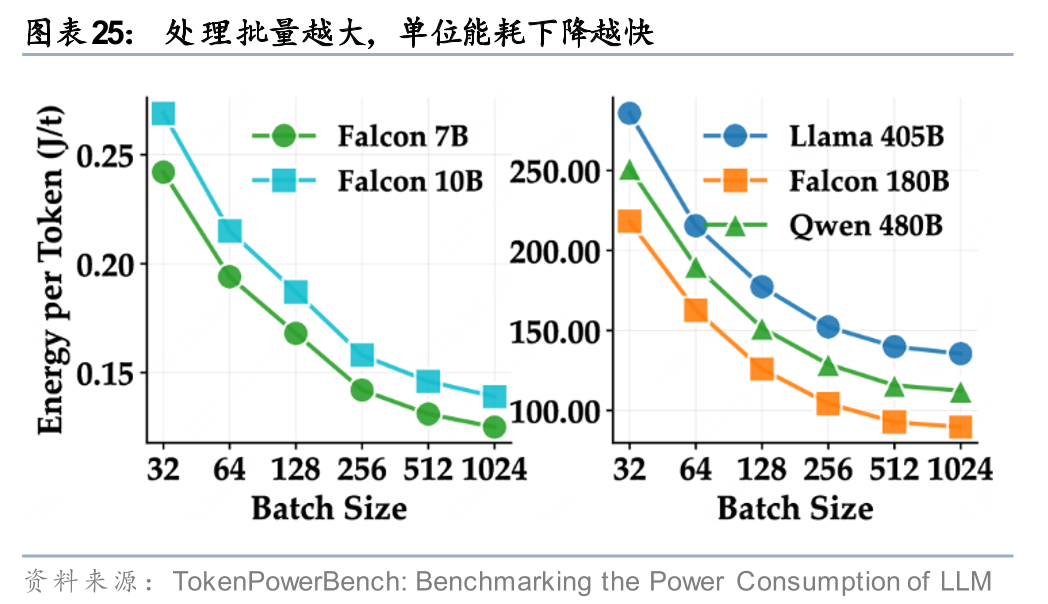
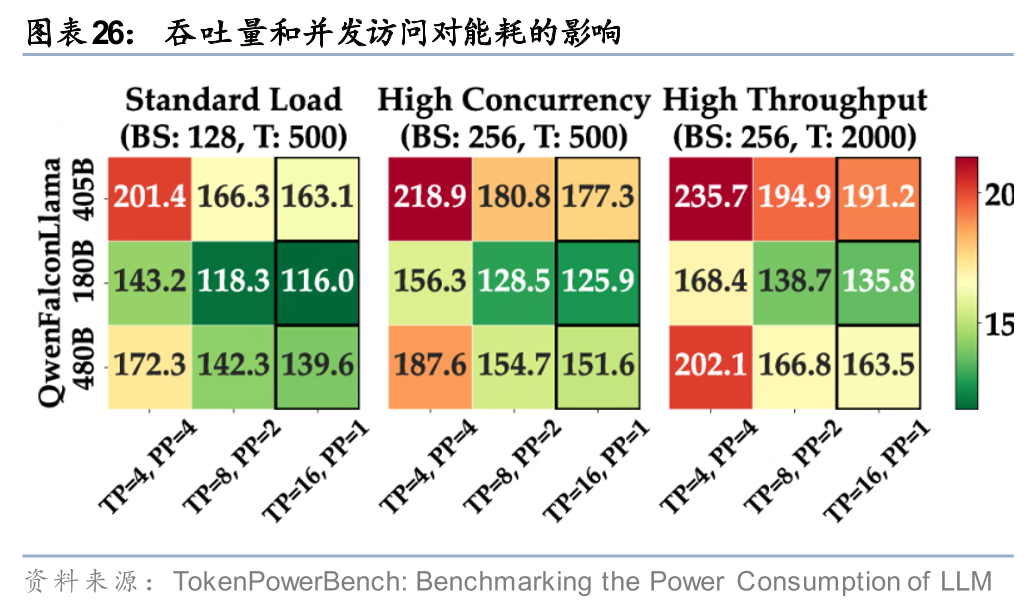
由于单位token的电量消耗影响的边界因素较多,我们也很难用情景分析的方法来涵盖所有可能性,这里我们主要考虑模型的参数。当前模型参数范围较为宽泛,小到0.3-0.5B的腾讯混元HY -1.8B-2Bit和千问3小模型,大到万亿级别的科学大模型(例如上海AI实验室发布的“书生”),我们这里以常规的7B-400B做测算。单位token耗电量计算结果,请见研报原文。
中国电力行业:日均千万亿token调用量有望带来10%级别的弹性
OpenRouter使用者主要是很多海外的开发者,其调用量大多来自非中国大陆的访问者,考虑到推理对延时的敏感性要求和大陆数据法规的限制,我们认为中国大模型调用量至少有部分来自海外算力部署,对中国电量可能没有直接的拉动作用。但是考虑到中国企业在海外AIDC的产能面临严重瓶颈,大量个人非敏感信息的处理需求完全可以选择国内算力 标准合规实现。

由于对全球或中国本土token消费量缺乏权威机构预测,我们参考部分信息用电量和电力的敏感性进行测算:
2025年10月Google在业绩会上宣布,全平台月Token消耗量由7月980万亿增至1300万亿;
2025年12月火山引擎总裁谭待在Force大会宣布截至当年12月,豆包大模型日均token使用量突破50万亿,较去年同期增长超过10倍;
2026年2月,弗若斯特沙利文(Frost & Sullivan)联合头豹研究院发布《中国GenAI市场洞察:企业级大模型调用全景研究,2025H2》,报告显示2025年下半年,中国企业级大模型日均调用量提升至37万亿tokens,较2025H1的10.19万亿tokens增长263%,实现阶段性跃迁。
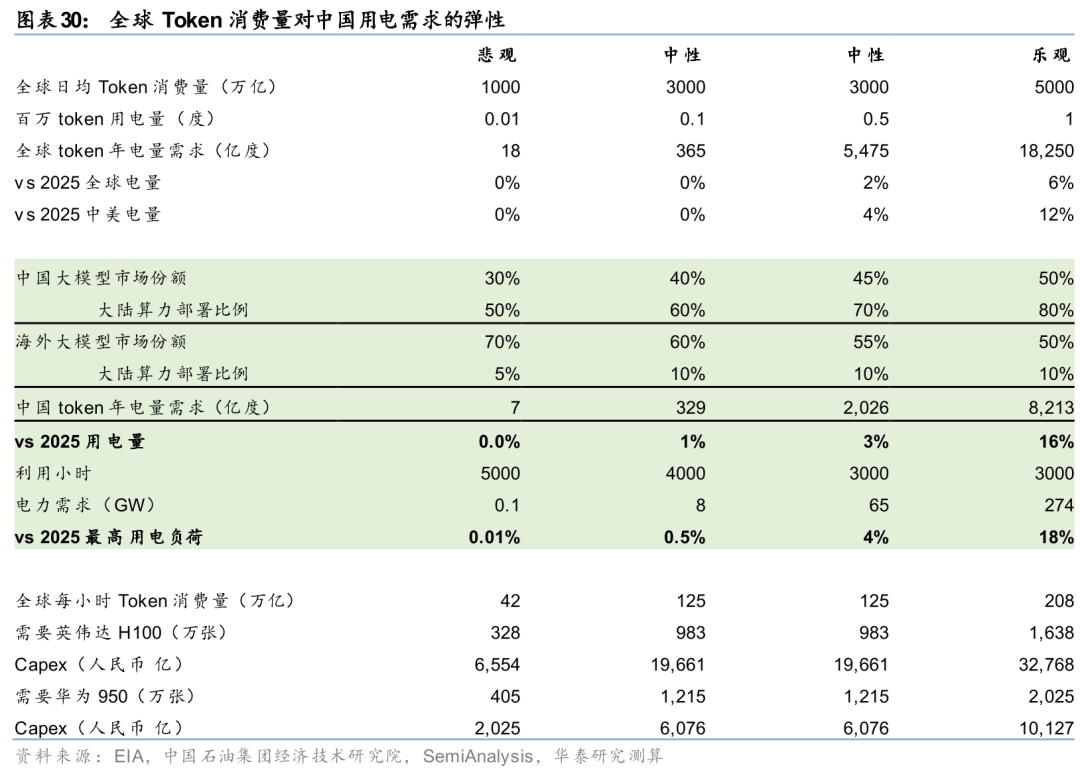
考虑到目前海外大模型可能短期不大可能在中国大规模部署算力(假设5%-10%的比例),那么推理时代对中国的电力行业产生需求的弹性主要来自调用中国大模型在中国的AIDC算力。假设全球token使用量日均千万亿的水平(按照已知信息2025年就已经达到了百万亿水平,仅Google和豆包两家就接近100万亿token使用量),对我国用电量和尖峰用电负荷的影响均会达到5-10%。届时,全球所需要的推理级别芯片约400-2000万张,与目前龙头厂商包括英伟达、华为等公司的产能相匹配;芯片所需capex约3000-17000亿元人民币左右,与目前国内外龙头企业如亚马逊、谷歌、Meta、微软、字节、阿里年均千亿级别的capex的支出也并不矛盾。
量化测算token需求对电力股的影响
电量电价利好:港股绿电/火电/绿发弹性
正如我们在2026年1月的报告《公用事业: 中美电价剪刀差:大国的相同与不同》中阐述的,我们认为2026年后电量电价大幅下降的可能性较低,考虑到AIDC用电量可能最利好绿电(2025年国家发展改革委等五部门联合发布《关于促进可再生能源绿色电力证书市场高质量发展的意见》要求国家枢纽节点新建数据中心绿色电力消费比例在80%基础上进一步提升),且新能源运营商的盈利能力目前也处于历史偏低水平。根据我们的测算,倘若中国绿电用电量增长329/2026/8213亿度,会增厚我国2026-30年绿电需求4%-33%。

假设这部分新增绿电需求会体现在绿证的价格上。参照我们2026年1月的报告《公用事业/环保: 碳价与绿证市场预期升温》,2025年绿证全年均价4.2元/张,2026年以来均价5.5元/张,仅为同期碳价的8%。当前绿证价格能为绿电带来0.55分/kWh的溢价,假设绿证涨价,我们测算对可再生能源发电企业的正向弹性,结果请见研报原文。
容量电价利好:港股火电 浙能/京能/建投等纯火电公司弹性较大
正如我们在2025年9月的报告《公用事业:电价:“电量”向左,“容量 调节”向右》中阐述的,容量电价引入供需系数概率较大。根据我们的测算,倘若中国尖峰负荷增长8/65/274GW,会增厚我国2026-30年有效容量的供需系数,在165/330元/kw的容量补偿标准下,意味着容量电价增厚如下:
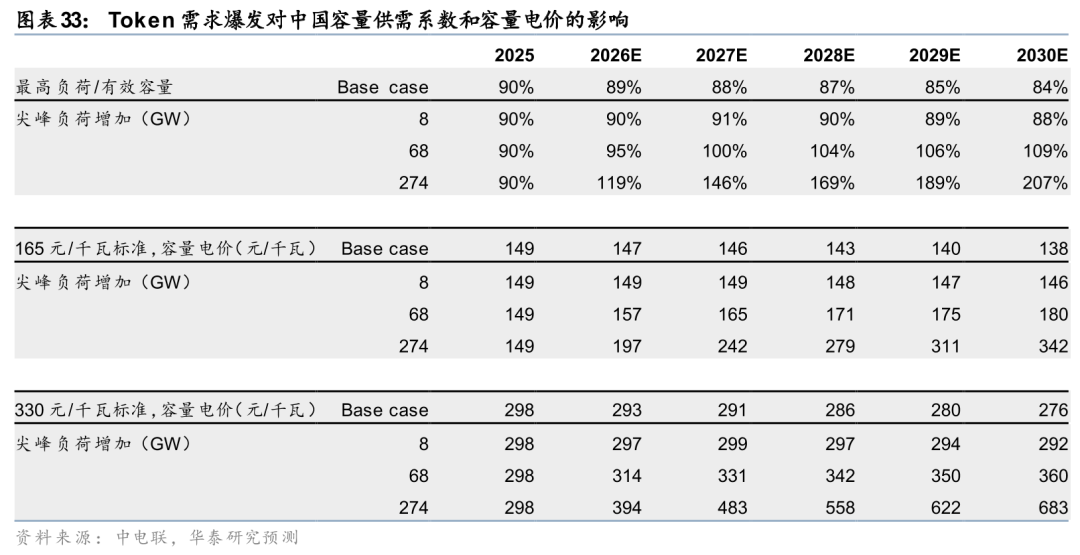
据此,我们测算对火电公司盈利的弹性如下。这里我们考虑主要公司的火电权益装机和2025年净利润,考虑容量电价上涨对净利润的上涨弹性,计算当前数值下PE的变化幅度。具体结果,请见研报原文。

 VIP复盘网
VIP复盘网
