


英伟达今天凌晨发布的四季度业绩指引超预期,财报显示营收同比增长73%至681亿美元,超过市场预期的650亿美元。
另据Wccftech,英伟达主办的全球性技术大会GTC大会将于3月16日召开,GTC是AI领域的重要盛会和产业风向标。
黄仁勋早前表示,所有技术都已逼近极限,将有几款全新芯片在GTC大会上发布。
市场预计采用LPU方案的Feynman架构芯片有望在GTC发布,同时下方采用PCB板为高多层板。
英伟达早前与AI推理芯片先锋Groq达成约200亿美元技术授权合作,获得LPU架构非独家IP授权并整体吸纳创始人及核心团队。
LPU将大幅提升AI算力中的模型推理能力,全新增量将成为英伟达强化推理版图的重要补充。
本文重点聚焦LPU推理芯片产业链核心环节。
01
什么是LPU?
LPU(LanguageProcessingUnit,语言处理单元)是专为顺序处理的计算密集型任务设计新型芯片架构,其核心目标是通过架构创新优化语言模型的推理效率。
LPU舍弃了GPU中的大量冗余结构,仅专注于推理阶段(即基于预训练模型处理输入并生成输出),在推理任务中实现低延迟、高吞吐性能,进而大幅提升推理能力。
英伟达与Groq合作:2025年12月,英伟达与AI芯片初创公司Groq达成非独家许可协议,斥资200亿美元获其技术授权,并吸纳创始人JonathanRoss、总裁SunnyMadra等核心团队,共同推进授权技术的升级与Groq推理技术应用。
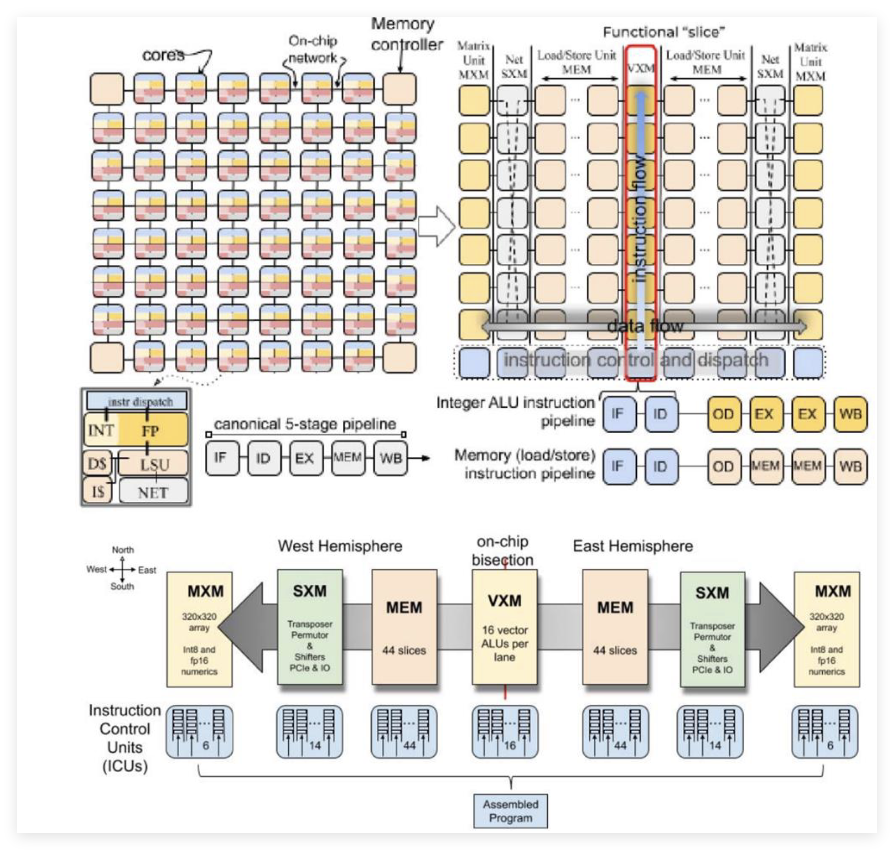
Groq是什么?Groq的核心产品正是LPU,是面向推理计算阶段专门设计的ASIC,其出发点并非追求更高的算力规模,而是解决通用GPU架构中长期存在的“时延-吞吐权衡”问题。Groq从设计开始即围绕实时、交互式推理场景进行设计,其核心价值主张在于Determinism(确定性)。
从技术层面来看,Groq第二代产品采用三星SF4X4nm工艺,能效比初代14nm产品提升15-20倍,单集群规模扩展至4,128颗芯片全互联。
从产业分工角度看,Groq与英伟达并非替代关系,而是高度互补。
英伟达将LPU架构中的确定性执行、低延迟通信等特性融入其Hopper/Blackwell架构GPU中,强化推理性能。此外,英伟达或计划将Groq的LPU硬件堆栈集成至Feynman芯片。
花旗分析师指出,LPU的引入将帮助英伟达应对推理需求爆发。
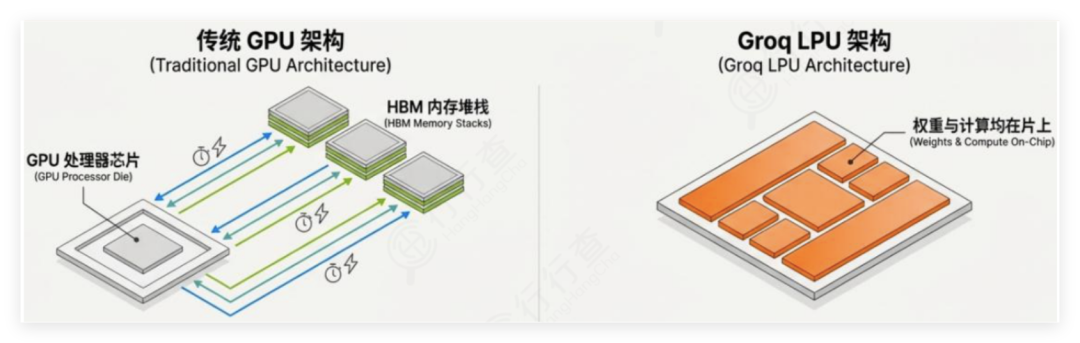
LPU的张量流处理器(TSP)的架构(右图)对比传统GPU采用多核布局(左图):
 资料来源:groq官网
资料来源:groq官网
LPU的积极影响
算力性价比提升,利好推理乃至整体AI产业:例如,Groq的LPU在MetaLlama2-70B推理任务中,相较于英伟达H100实现了10倍的性能提升,同时推理成本降低了80%。
提升高速互联需求,促进PCB升规升级:LPU架构强调功耗比等特性,对上游供应链要求不同于传统AI服务器。其与CoWoP封装结合,推动PCB升规升级,主板或采用超高多层 M9的PCB设计以满足要求。
优化AI投入结构,提高PCB在AIBoM中的占比:作为AI硬件重要组成部分的PCB,其在AI物料清单(BoM)中的占比也将持续提升,预计从当前的3-5%提升至未来的5-10%。
LPU之间的芯片间直连:
02
LPU产业链
LPU芯片产业链核心环节覆盖芯片设计、存储芯片SRAM、PCB、先进封装、边缘计算、液冷等领域。
芯片设计
适配大模型推理的定制化芯片设计是LPU产业链的起点和关键环节。
海外核心企业Groq是LPU架构开创者,由谷歌TPU核心团队创立的Groq公司推出的LPU,在MetaLlama2-70B推理任务中实现10倍性能提升,推理成本降低80%,成为行业标杆。
英伟达通过技术授权合作吸纳Groq团队,将LPU融入自身生态,强化推理版图。
谷歌和AMD通过TPU、MI系列芯片布局语言处理市场,尚未推出专用LPU。
国内企业如寒武纪思元系列芯片覆盖云端推理场景;海光信息DCU芯片基于AMDGCN架构授权,兼容ROCm生态;无问芯穹“无穹LPU”是全球首个基于FPGA的大模型处理器;芯原股份提供NPUIP授权服务,通过IP核被多款AI芯片采用,适配LPU的协同计算需求,其VIP9000系列NPUIP支持Transformer加速;燧原科技、登临科技、云天励飞等均涉足LPU相关领域。
半导体IC设计流程图:
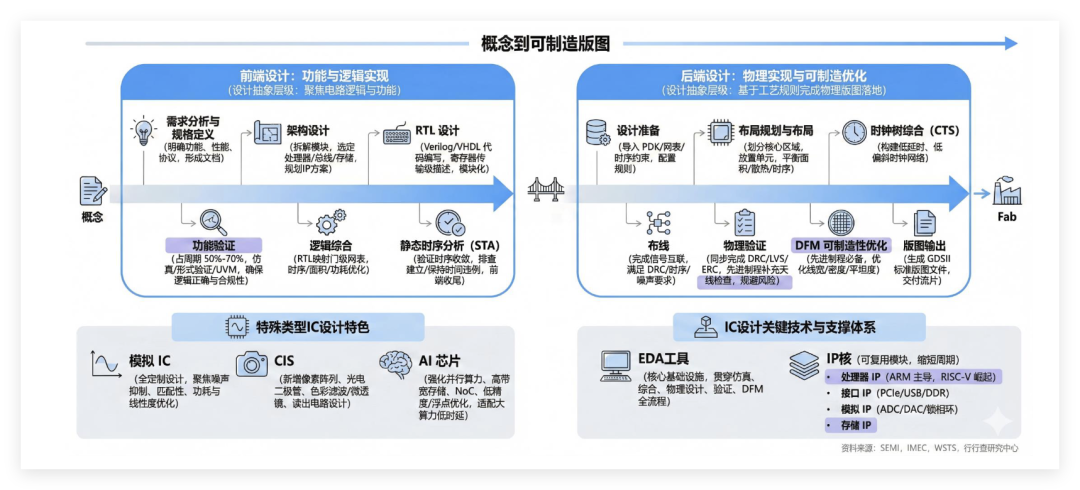 资料来源:行行查
资料来源:行行查
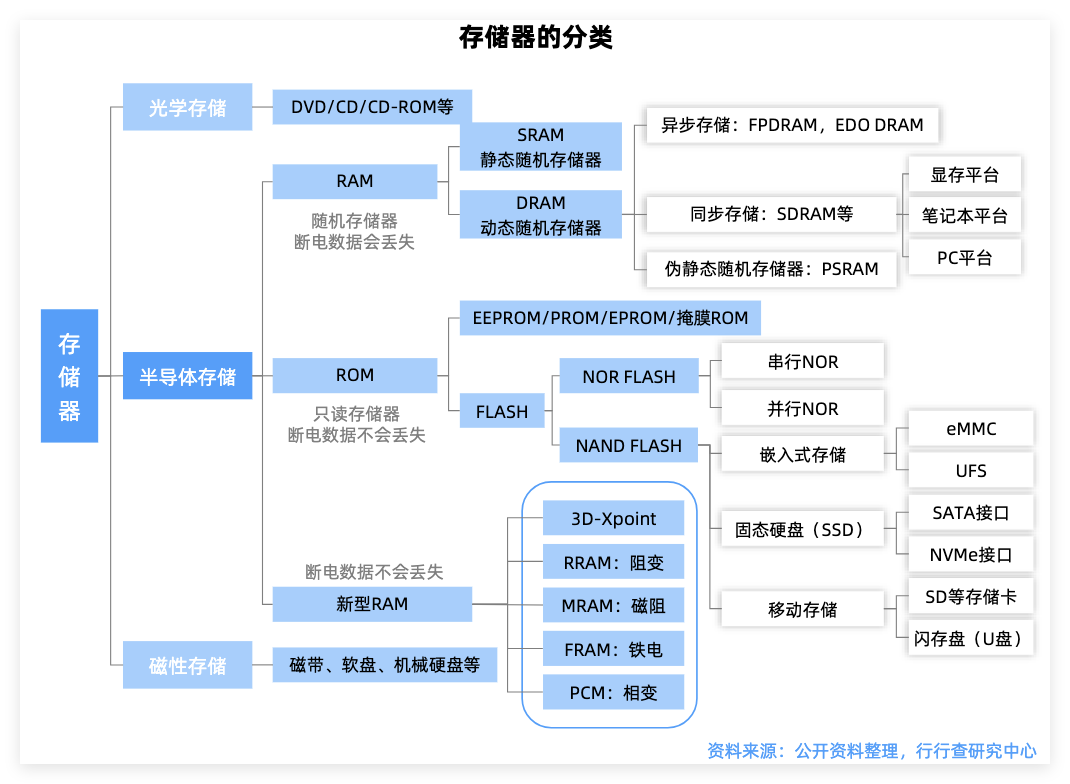
存储芯片SRAM
LPU核心在于采用SRAM作为主要内存,而非传统GPU与TPU依赖的HBM。
通过大面积SRAM的近存计算方案,LPU满足LLM愈发显著的Tokens需求。
GroqLPU搭载230MBSRAM:
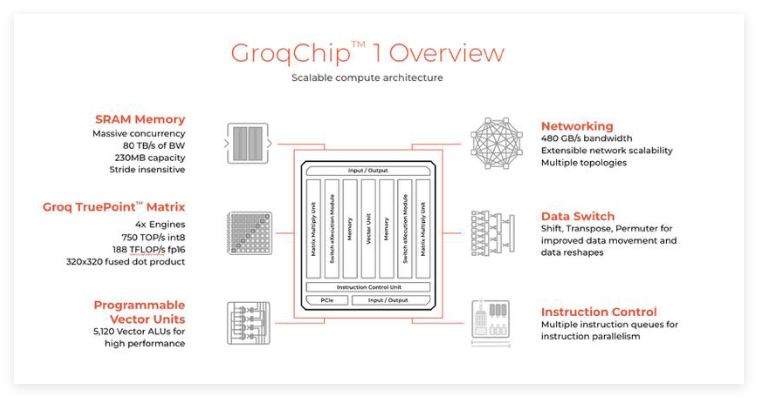 资料来源:Groq
资料来源:Groq
SRAM核心优势
SRAM带宽高达约80TB/s,且数据几乎都能在芯片内部完成访问与运算,大幅降低了数据迁移成本,使AI在推论阶段能以更低延迟、更高能效即时回应用户问题。
虽然容量小且成本高,但作为LPU关键存储介质,用于存储关键数据指令以支持高速推理。
例如,LPU处理大语言模型时,SRAM可实现每秒500个token的生成速度,比英伟达GPU快10倍。
据瑞银证券,LPU通过230MB片上SRAM和80TB/s带宽,解决了传统GPU因访问片外HBM导致的延迟问题,可实现推理吞吐量7.5倍以上的提升。
 资料来源:行行查
资料来源:行行查
SRAM竞争格局
海外SRAM市场中,英飞凌、瑞萨电子、赛普拉斯和微芯科技都是该领域的头部玩家。国内相关厂商中北京君正产品覆盖计算机、嵌入式设备及高性能芯片领域,市场占有率居全球前列;兆易创新覆盖SRAM到NAND全系列为LPU提供存储支持;恒烁股份研发存算一体AI芯片基于SRAM技术降本增效;后摩智能采用近存计算/统一内存架构,将片上SRAM与计算核心紧密集成。此外,昆仑万维和炬芯科技等厂商在创新型芯片fabless SRAM与3DDRAM堆叠有相关布局。
PCB
PCB承载CPU、GPU、LPU、存储芯片等所有电子元器件,提供物理支撑和电气连接。
LPU对PCB的技术要求远高于传统服务器,单块LPU平台PCB价值是传统服务器的5-7倍。
LPU3D堆叠封装大容量SRAM与GPU,对PCB互联要求更高,使用高多层PCB,目前多方案并行,包括30层 与50层 方案,进一步扩展PCB需求。此外或采用背面供电技术,带动嵌埋PCB需求,将用52层M9 Q增强方案。
新技术方向往往是PCB发展核心驱动力,如正交背板和CoWoP等技术都曾带动PCB产业提速。LPU作为英伟达推理端的重要布局,有望接力成为PCB新催化。
国内包括沪电股份、胜宏科技、景旺电子、深南电路以及广合科技、生益科技、鹏鼎控股、东山精密、兴森科技、崇达技术、中京电子等众多厂商在PCB相关业务上有所布局。
 资料来源:行行查
资料来源:行行查
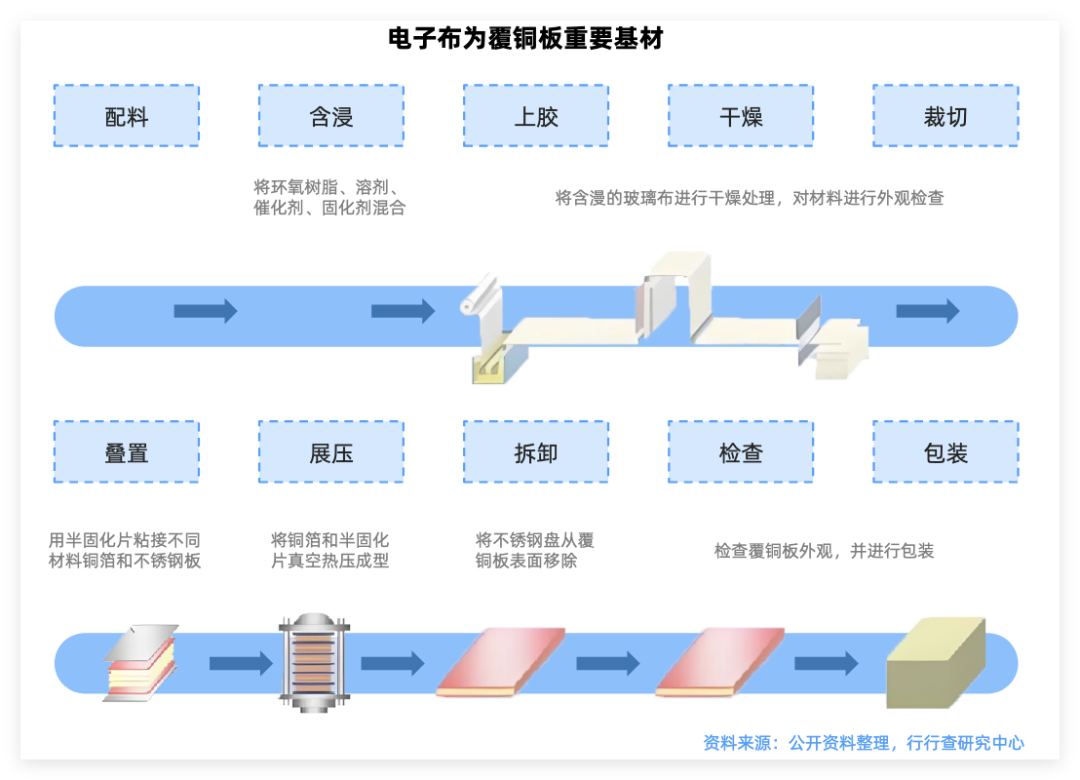
电子布
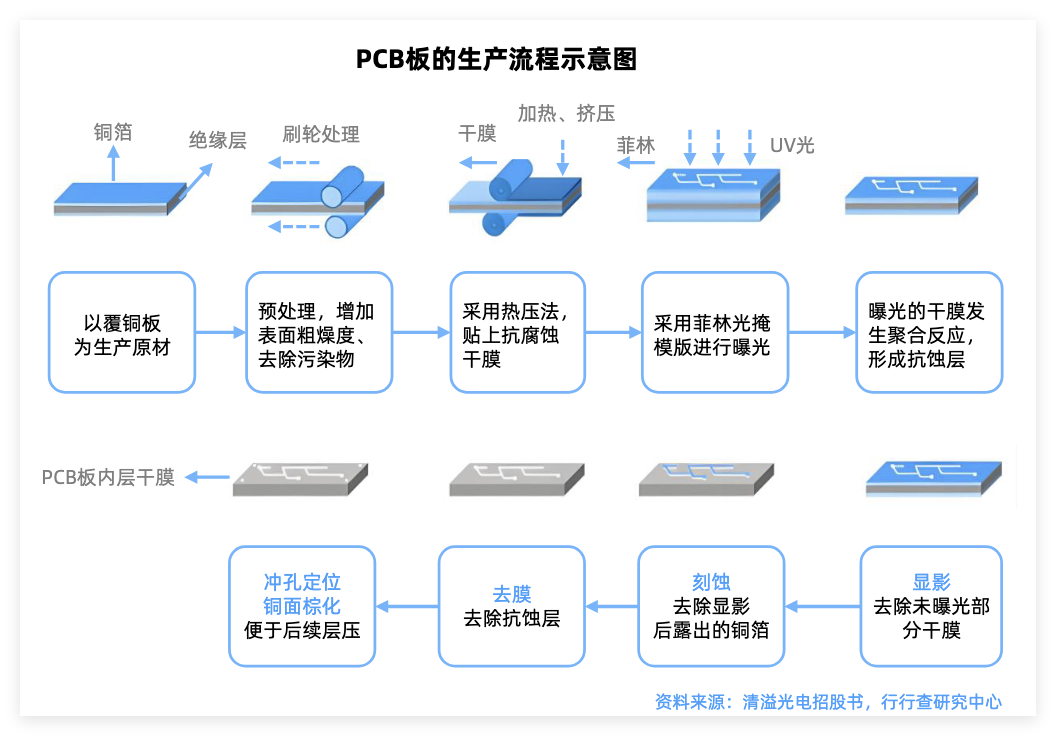
电子布是PCB的核心基材,由超细电子级玻璃纤维纱织造而成,与树脂复合后形成覆铜板(CCL),再通过蚀刻、钻孔等工艺制成PCB。
随着PCB层数的增加和面积的扩大,单片AI服务器对Q布的消耗量呈现出数倍的增长态势。
当前技术发展的主流方向是将PCB材料升级至M9,并配套使用超低轮廓铜箔以及低介电石英布。
 资料来源:行行查
资料来源:行行查
第三代(Q布/石英电子布):介电常数低至2.2-2.3,专为高频高速应用如AI服务器设计,同时Q布也是M9覆铜板的关键增强材料。
在算力硬件需求持续放量的背景下,Q布成为产业链中供应最为紧张的关键材料。
目前全球第三代电子布(Q布)产能高度集中,技术壁垒极高。全球Q布产能高度集中于日东纺、AGC、菲利华、中材科技等少数厂商,供给长期紧平衡。日东纺、AGC二者通过专利和客户绑定形成绝对优势;菲利华提供低介电常数(Dk<3.0)、低介电损耗(Df≤0.0007)的第三代石英布;中材科技旗下泰山玻纤提供低介电石英布;国际复材通过突破超细纱线生产技术,实现Q布的规模化量产;宏和科技是国内少数具备Low CTE(低热膨胀系数)电子布量产能力的企业之一。此外,海外旭化成和信越主要生产低介电玻纤(二代布原材料)。
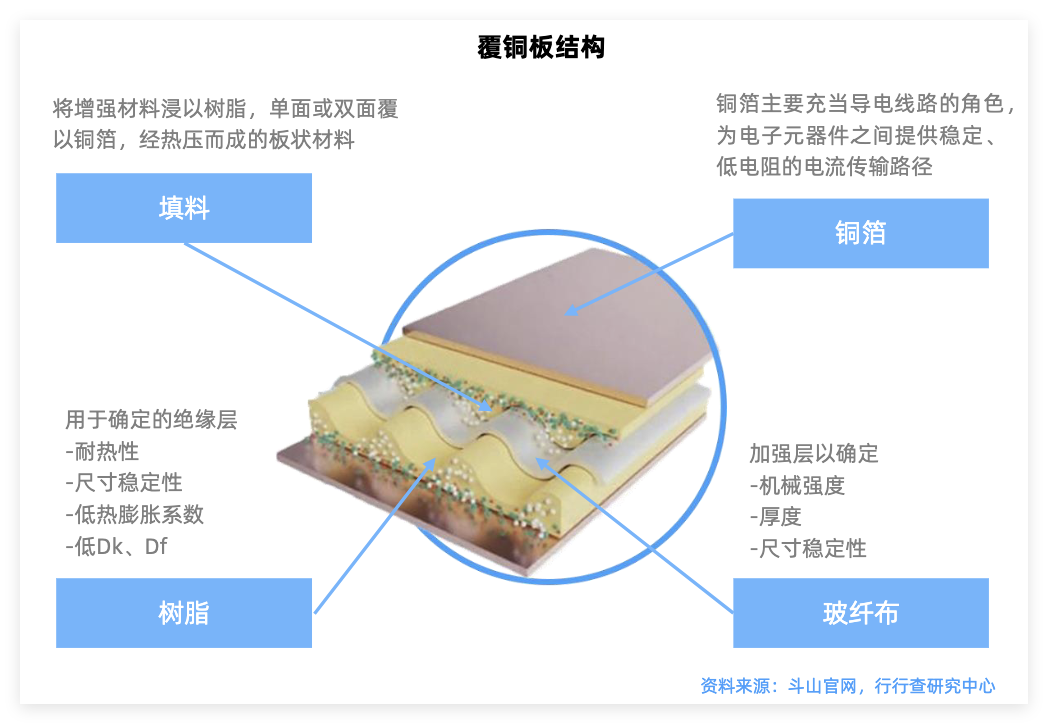
M9材料:是英伟达针对下一代Rubin架构AI服务器开发的革命性高频高速覆铜板(CCL)材料。其其核心构成主要包括特种树脂、石英布(Q布)和高端铜箔(HVLP4/HVLP5)。
东材科技通过英伟达M9级碳氢树脂认证,提供超低介电损耗(Df≤0.0005)的封装树脂;菲利华实现“高纯石英砂-石英纤维-石英布”全链条自主可控;生益科技提供M9级覆铜板;德福科技、铜冠铜箔量产HVLP4铜箔;联瑞新材提供M9材料关键填料球形硅微粉。此外,鼎泰高科、大族数控、宏昌电子等提供配套材料及相关设备。
液冷技术
LPU等高性能芯片将使用数据中心功耗大幅增加,液冷技术成为关键。
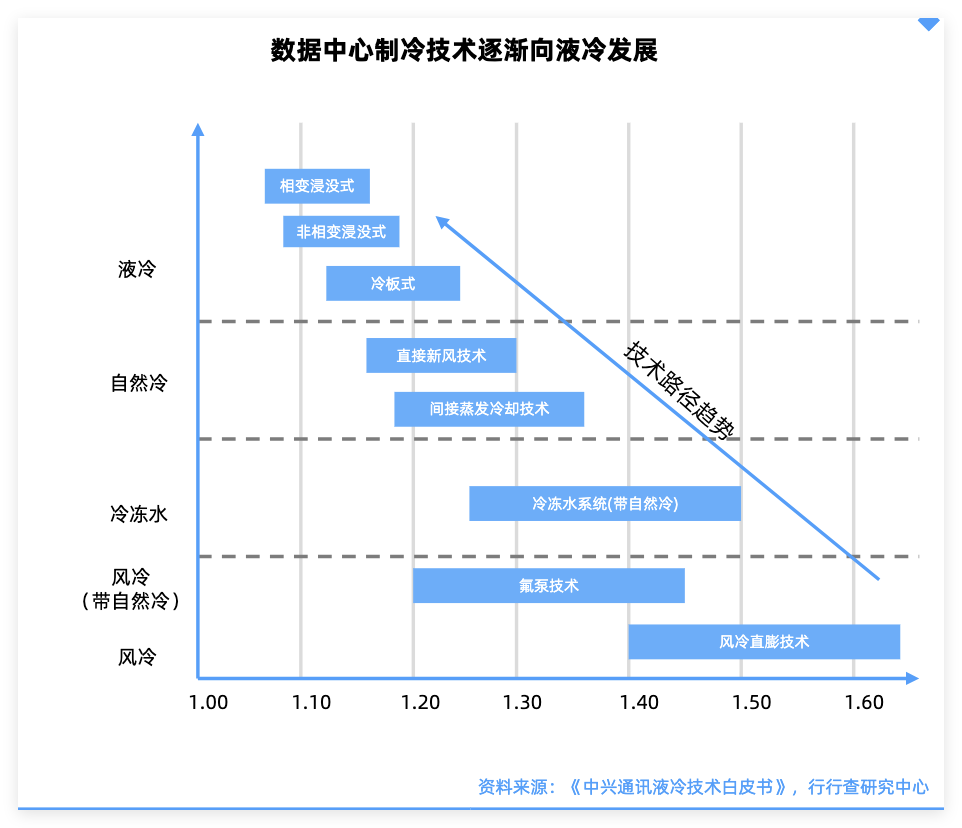
从全球头部厂商液冷技术布局路线来看,目前冷板式液冷和浸没式液冷为数据中心两大主流液冷方案。当前正从冷板式到浸没式渐进式过渡,并探索混合方案。

海外Vicor与Groq深度绑定,Groq的LPU架构为追求极致推理速度,需芯片在0.7V-0.8V极低电压下承载极高瞬时电流,其是最早采用Vicor分比式电源架构(FPA)的芯片公司之一。
国内液冷相关英维克、高澜股份、浪潮信息、同飞股份、中科曙光、曙光数创、申菱环境、依米康、佳力图、科华数据、飞荣达、思泉新材等厂商在各大核心领域均有所布局。其中,部分企业提供全链条液冷解决方案,覆盖冷板、CDU、工质等核心环节,技术适配高功耗芯片需求,能将数据中心PUE降至1.1以内,远超国家1.25的标准。
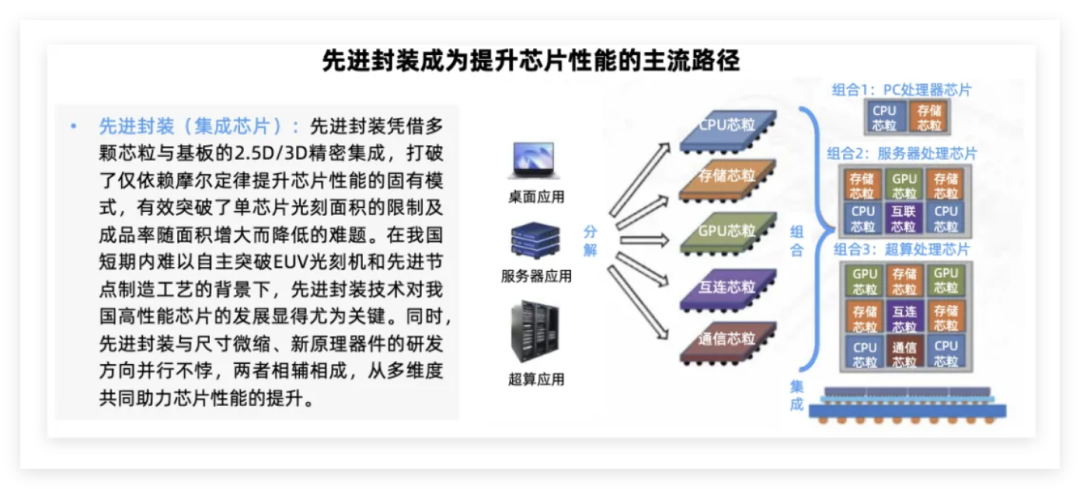
先进封装
LPU芯片通过SRAM替代传统HBM,解决了内存带宽瓶颈问题,但其单芯片SRAM容量有限(如GroqLPU集成230MBSRAM)。
先进封装使LPU集群在处理超大规模模型时,能通过多芯片协同弥补SRAM容量不足,同时保持低延迟优势。
Chiplet和2.5D/3D封装等技术通过多芯片互联,扩展内存容量和带宽。
据Wcctech,英伟达Feynman架构芯片预计将采用3D封装的方式将LPU堆叠在主芯片上,将专为推理任务优化的LPU芯片直接集成在GPU计算核心之上,从而实现通用计算与专用计算在物理层面的深度融合。
全球先进封装厂商阵容庞大,包括中国台湾厂商台积电,海外英特尔和三星等国际巨头,以及中国大陆封测厂商长电科技、通富微电、华天科技、智路封测、盛合晶微、甬矽电子、深科技、晶方科技、佰维存储以及精测电子、键合设备拓荆科技、百傲化学等众多厂商。
 资料来源:行行查
资料来源:行行查
短期来看,随着英伟达GTC大会临近,LPU新架构将带来算力形态新变化。而随着全球AI应用广泛落地,AI推理对低延时的需求不断增强,GPU LPU的异构架构有望进一步大幅降低推理成本,从高端场景向消费级市场渗透并加速大规模商业化。

 VIP复盘网
VIP复盘网
