

今日,通义千问团队正式开源发布Qwen3.5系列中等规模模型,推出包括Qwen3.5-35B-A3B、Qwen3.5-122B-A10B、Qwen3.5-27B三个版本。沐曦股份旗下曦云C系列GPU已同步完成对上述模型的Day 0 适配工作,为用户提供即时可用的高性能AI算力支持。
这是曦云C系列GPU继Qwen3.5系列首款模型 Qwen3.5-397B-A17B 的开放权重版本后,再一次实现对Qwen 3.5系列模型的高效适配。
全栈软件生态支撑,实现无缝衔接
曦云C系列GPU所依托的MXMACA软件栈3.3.0.X版本,构建起连接底层硬件与上层应用的核心技术桥梁。该软件栈覆盖底层驱动、编译器、算子适配、训练及推理框架等全链路能力,为Qwen3.5系列模型提供完整的软件生态支撑。
深度适配主流框架,确保开箱即用
MXMACA套件已完成与vLLM、SGLang、Transformers、KTransformer等业界主流大模型推理框架的深度适配。这些框架是运行Qwen3.5-122B-A10B、Qwen3.5-35B-A3B和Qwen3.5-27B的关键基础设施,确保用户能够在曦云C系列GPU上实现模型的快速部署与高效运行。
Qwen3.5 亮点

Qwen3.5 代表了一次重大飞跃,融合了多模态学习、架构效率、强化学习规模以及全球可访问性等方面的突破,为开发者和企业带来前所未有的能力和效率。
统一的视觉-语言基础:在多模态 token 上进行早期融合训练,在推理、编码、智能体和视觉理解等基准测试中,跨代际地达到与 Qwen3 相当的水平,并超越 Qwen3-VL 模型。
高效混合架构:门控 Delta 网络与稀疏混合专家(Mixture-of-Experts)相结合,在保持极低延迟和成本开销的同时实现高吞吐推理。
可扩展的强化学习泛化能力:在百万级智能体环境中进行强化学习训练,任务分布逐步复杂化,从而实现强大的现实世界适应能力。
全球语言覆盖:支持扩展至 201 种语言和方言,支持包容性的全球部署,并具备细致入微的文化与区域理解能力。
下一代训练基础设施:相比纯文本训练,多模态训练效率接近 100%,并配备异步强化学习框架,支持大规模智能体脚手架和环境编排。
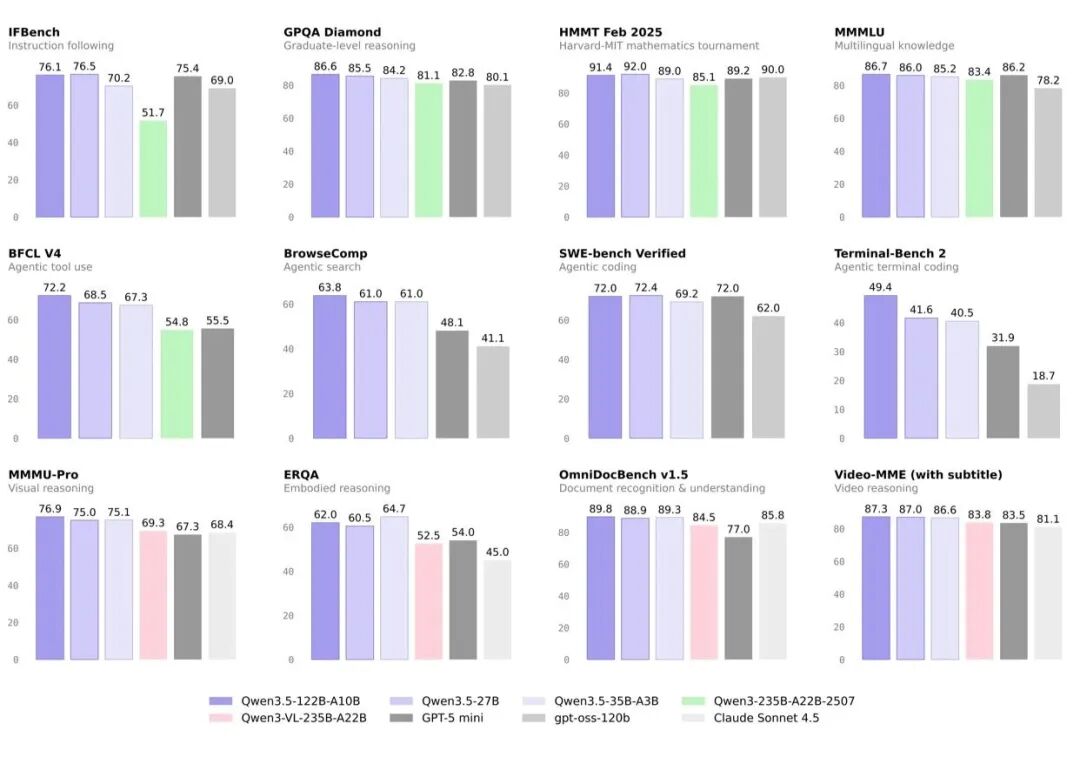
Qwen3.5 凭借高效的混合架构与原生多模态推理,为通用数字智能体奠定了坚实基础。下一阶段的重点将从模型规模转向系统整合:构建具备跨会话持久记忆的智能体、面向真实世界交互的具身接口、自我改进机制,目标是能够长期自主运行、逻辑一致的系统,将当前以任务为边界的助手升级为可持续、可信任的伙伴。

 VIP复盘网
VIP复盘网
