

华为将于8月12日,在2025金融AI推理应用落地与发展论坛上,发布AI推理领域的突破性技术成果。

该技术通过将AI推理所需的矢量数据,从DRAM内存迁移至SSD闪存介质,优化计算效率。以存代算技术缓解先进制程限制,降低对HBM/GPU的依赖,实现存算一体系统创新。其本质是存储层扩展,而非DRAM的替代品。
SK海力士预计,2030年前AI内存市场将以每年30%的速度增长。日本铠侠、美光、英伟达等巨头,也在同步布局以存代算技术。由于美国制裁,国内企业无法突破先进制程,转向系统级创新,布局以存代算技术。
今天重点拆解下 存算一体技术(以存代算)。
存算一体技术概述
存算一体技术(Computing in Memory, CIM)是一种将数据存储与计算功能融合在同一芯片区域的新型架构。通过在存储器内部,直接进行数据处理或计算,该技术彻底解决了传统冯·诺依曼架构中的“存储墙”问题。
核心理念是打破存储与计算分离的传统局限,将计算能力叠加到存储器上,利用后摩尔时代的先进封装和新型存储器件等技术,实现计算能效的数量级提升。
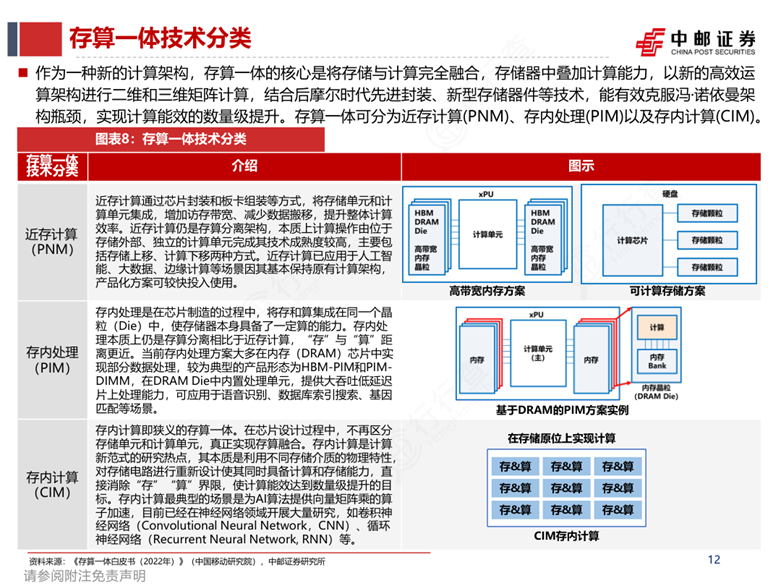
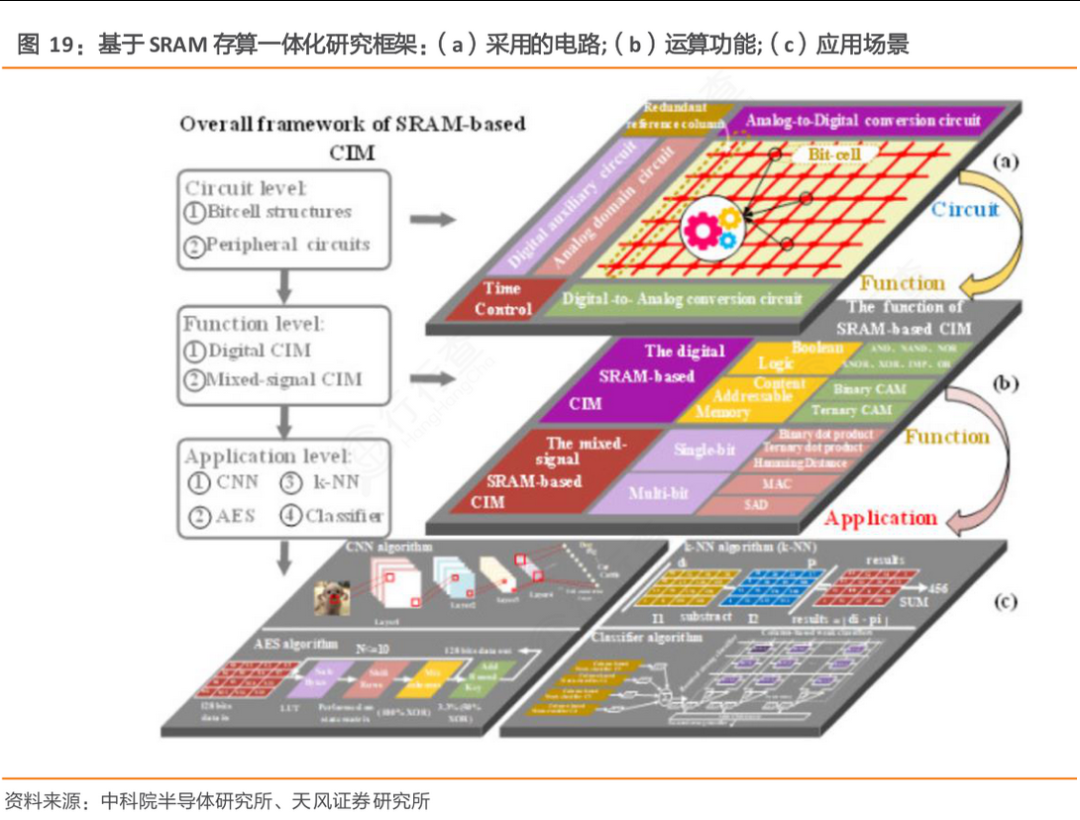
从广义上看,存算一体包括近存计算(PNM)、存内处理(PIM)和存内计算(CIM)三种形式,其中狭义的存算一体特指存内计算,即晶体管同时具备存储和计算能力。
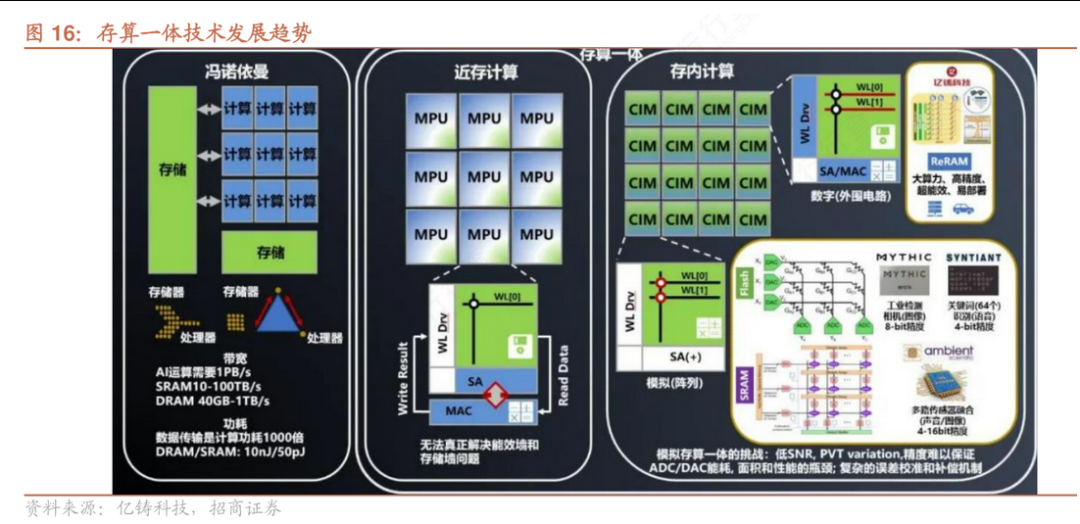
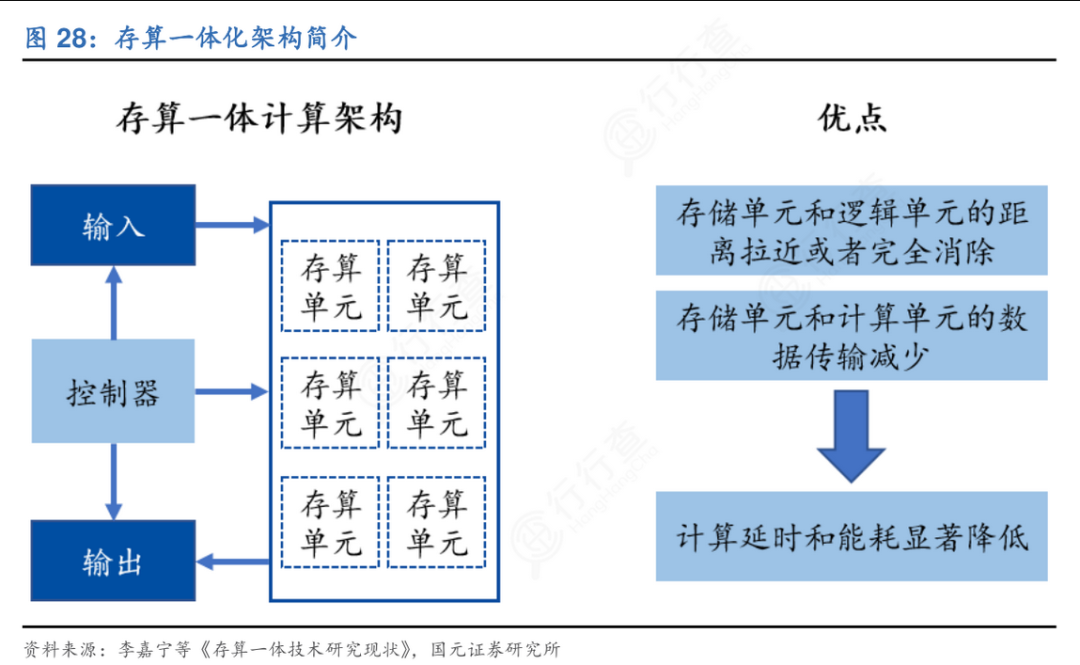
与传统冯·诺依曼架构相比,存算一体技术的根本区别在于数据流动方式和架构设计逻辑。传统架构中,处理器和存储器分别负责计算和存储,数据需频繁在两者间搬运:计算时,数据先从存储器读取到缓存,再由控制单元分配给计算单元运算,完成后写回存储器。这种分离式结构导致了“存储墙”问题——随着处理器性能不断提升,存储器带宽增长缓慢,两者之间的“剪刀差”日益扩大,造成访存带宽低、延迟高、功耗大等问题。
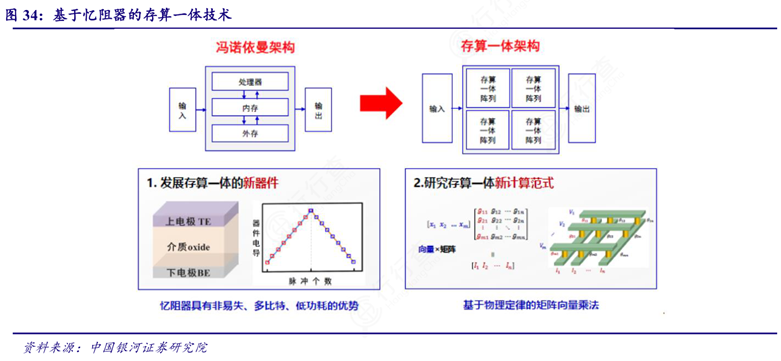
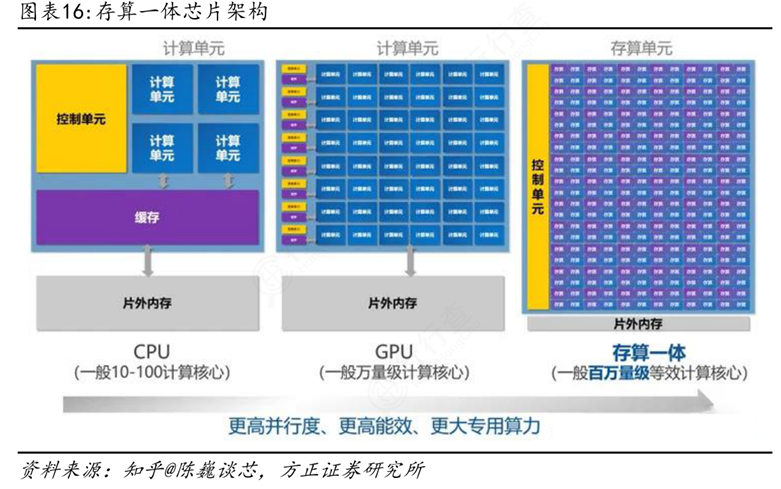
相比之下,存算一体架构通过将存储与计算单元集成在同一硬件单元内,实现了数据原位处理,即“计算发生在数据存储的位置”。这种方式大幅减少了数据在存储与计算之间的迁移,不再依赖统一的缓存系统,而是采用分布式、一体化设计,使每个存储单元都可能具备计算能力,从而形成百万量级的等效计算核心。例如,在AI推理任务中,尤其是神经网络的向量矩阵乘法运算,存算一体可以直接在存储阵列中完成乘加操作,避免频繁的数据读写过程。这不仅显著提升了计算效率,还大幅降低了功耗,能效比可达到10-100TOPS/W,算力可达1000TOPS以上,明显优于现有ASIC芯片。
此外,传统冯·诺依曼架构下的CPU通常只有10-100个计算核心,GPU虽拥有万量级核心,但仍依赖外部内存,数据传输仍是瓶颈。而存算一体架构通过控制单元直接管理存储与计算资源,实现更高并行度、更高能效和更大专用算力。特别是在AI、大数据、边缘计算等需要高吞吐量和低延迟的应用场景中,存算一体能够有效应对PB级数据处理需求,解决传统架构下“漏斗效应”带来的效率损失问题。
存算一体技术通过深度融合存储与计算,从根本上改变了数据处理流程,消除了传统架构中因数据搬运带来的延迟和能耗问题。它不仅是一种架构创新,更是面向AI时代高算力需求的系统级优化路径,能够在保持低成本的同时提供大算力和低功耗的综合优势。
存算一体技术(以存代算)的上游供应链主要包括芯片设计与制造、存储介质研发及相关核心元器件供应。
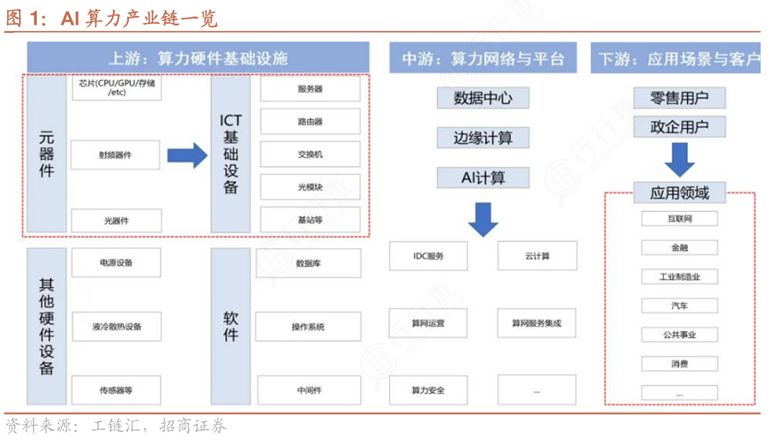
上游企业聚焦于新型存储器的研发,例如基于SRAM、DRAM或新兴非易失性存储技术(如ReRAM、MRAM)的存算一体芯片设计。代表性探索包括英特尔基于SRAM的可配置存储器方案和三星在DRAM上的DRISA架构布局。国内初创企业如知存科技、亿铸科技、智芯科、九天睿芯等,致力于“存”与“算”深度融合的技术路线,在无需依赖先进制程的情况下实现高效能计算。同时,东芯股份、兆易创新、北京君正、澜起科技等存储芯片厂商提供关键支持,而中科曙光、浪潮信息、寒武纪等算力厂商则为存算一体技术的系统级协同奠定基础。
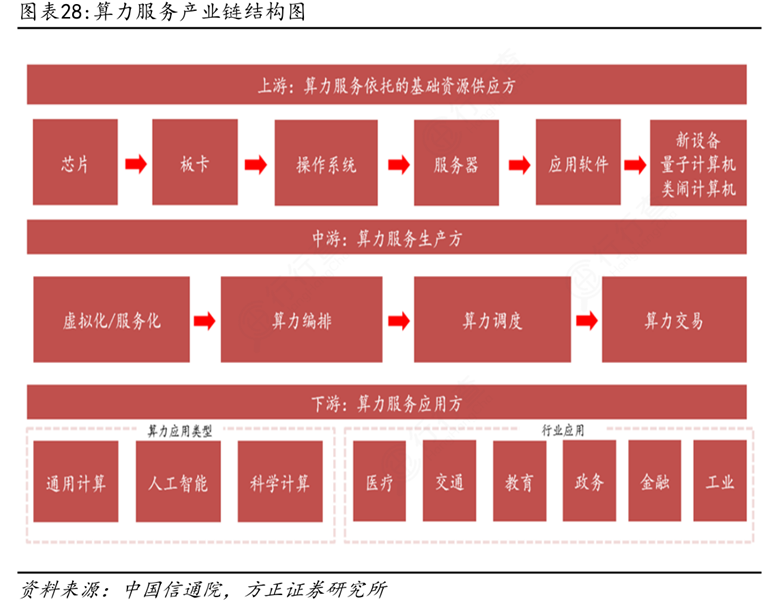
中游供应链涉及存算一体芯片的集成、封装测试、软件工具链开发及系统级解决方案构建。该环节需将底层硬件与上层应用适配,开发专用编译器、量化算法、驱动程序和操作系统支持模块,以确保存算一体架构能够高效运行AI模型和类脑计算任务。
不过,当前存算一体生态尚不完善,中游面临从芯片到应用的“断层”问题,亟需软件工具厂商、系统集成商和算法开发者共同构建完整的开发生态。部分头部企业如阿里巴巴达摩院、华为、百度昆仑芯等正在推进软硬协同优化,推动技术从实验室走向工程化落地。此外,封装测试环节可能采用3D堆叠、Chiplet等先进封装技术,以提升存储与计算单元之间的互联密度和带宽效率。
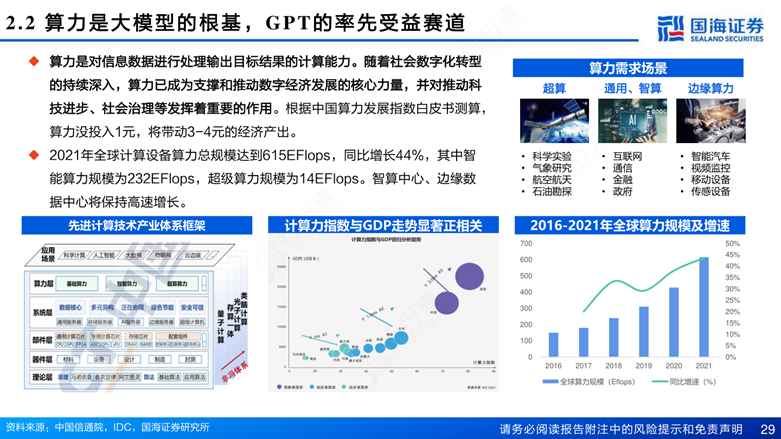
下游供应链涵盖存算一体技术的实际应用场景与终端用户,包括边缘计算设备、可穿戴设备、智能家居、自动驾驶、数据中心和类脑计算平台等。在边缘侧,闪易、新忆科技、苹芯科技、知存科技等企业专注于物联网、可穿戴设备等小算力、低功耗场景的应用落地;而在大算力场景中,亿铸科技、千芯科技、阿里达摩院等则聚焦于大模型训练与推理、自动驾驶感知决策系统等高能效需求领域。随着大型AI模型参数规模突破亿级甚至万亿级,传统冯·诺依曼架构面临的“存储墙”和“功耗墙”问题日益突出,存算一体有望成为继CPU和GPU之后的第三种主流算力架构,支撑未来AI系统的能效革命。

存算一体技术对算力产业链的重要影响,也体现在多个方面。
首先,它颠覆了传统冯·诺依曼架构中计算与存储分离的设计范式,通过将数据处理直接嵌入存储单元内部,大幅降低数据搬运带来的延迟和能耗。这种架构创新使得单位功耗下的算力提升可达10-100倍,能效比显著提高,据测算可实现超过1000 TOPS的算力输出和10-100TOPS/W的能效表现。这一突破对于缓解当前AI算力发展中“算力增长远超存储能力”的瓶颈具有决定性意义,尤其在数据中心、智能驾驶和移动终端等对能效敏感的应用场景中展现出巨大潜力。

存算一体技术推动了算力产业链从“以算为中心”向“以数据为中心”的范式转变。传统算力链中,数据需频繁在CPU/GPU与内存之间传输,导致带宽受限和功耗激增。而存算一体通过融合存储与计算功能,减少了对外部总线的依赖,有效缓解了“内存墙”问题。这不仅提升了整体系统的计算效率,也为未来异构计算、边缘智能和类脑计算提供了新的技术路径。
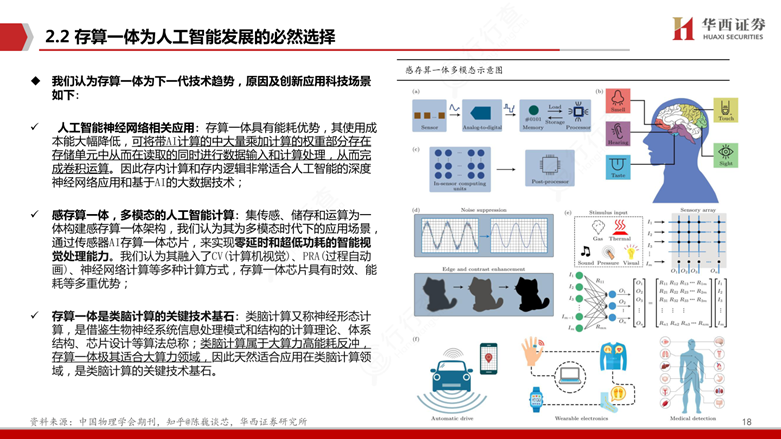
未来五年内,存算一体技术将朝着更高精度、更高算力和更高能效的方向快速发展,并通过与Chiplet技术、新型存储介质及多模态感知技术的深度融合,加速其在人工智能和类脑计算领域的落地应用。
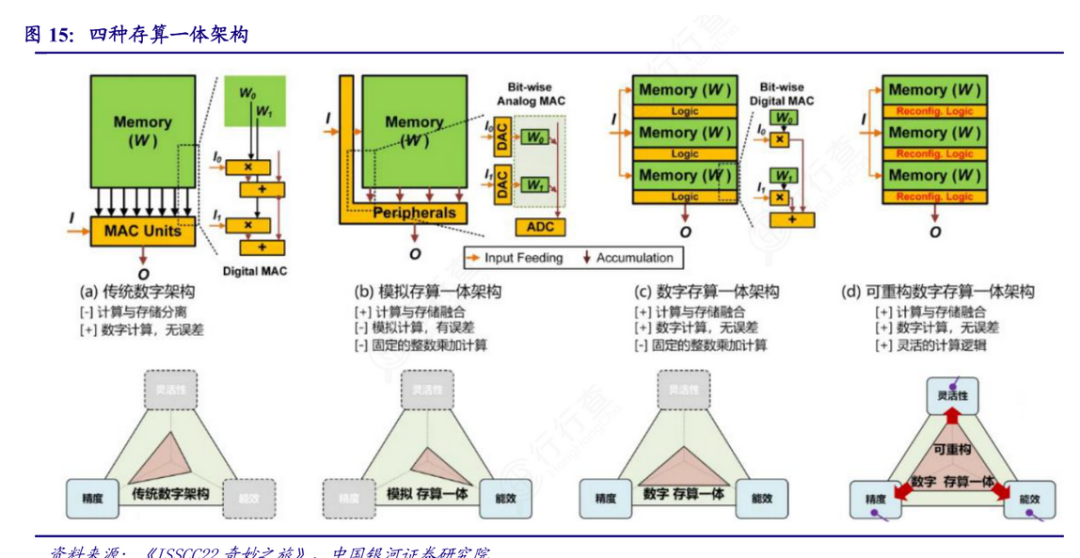
随着技术成熟度的提升以及产业生态的逐步完善,存算一体有望成为继CPU和GPU之后的第三种主流算力架构,为AI产业的可持续发展注入强大动力。

 VIP复盘网
VIP复盘网
