


新智元报道
新智元报道
【新智元导读】CES现场,苏姿丰投下震撼弹:四年内AI算力将提升1000倍! 面对英伟达的封锁,AMD不再隐忍,直接祭出Helios「太阳神」机架与MI455X芯片,以单代性能暴涨10倍的「暴力美学」正面硬刚。从Yotta级计算宏图到128GB统一内存的PC怪兽,AMD正用一场史无前例的算力狂飙,试图彻底重写AI世界的权力版图。
今日是美国拉斯维加斯举办的消费电子展(CES)主旨演讲日,更是全球科技产业权力版图剧烈震荡的一天。
几个小时前,身着标志性皮衣的英伟达CEO黄仁勋刚刚走下舞台,留下了令竞争对手窒息的Vera Rubin平台和Agentic AI的宏大愿景,仿佛一位刚刚巡视完疆土的帝王。
然而,聚光灯并未就此熄灭。
之后,所有的目光转向了AMD的掌门人苏姿丰(Lisa Su)。
这位总是身着干练西装、在男性主导的半导体世界中杀出重围的女性,正准备在发布会上,向那个看似不可战胜的「绿色帝国」发起这一代最猛烈的冲锋。
这是算力世界「双城记」的缩影。
一边是英伟达,试图通过封闭的生态、极致的垂直整合构建起不可逾越的「围墙花园」,将数据中心变成只属于它的黑色方尖碑;
另一边是AMD,试图通过结盟、开放标准和堆料极致的硬件,率领着包括OpenAI、微软、Meta在内的「复仇者联盟」,试图在铁幕上撕开一道口子。
这场发布会早已超越了摩尔定律的线性叙事。
AMD在今天发布的除了芯片本身,更是一整套试图打破英伟达垄断的蓝图。

在深入解读AMD的突围之前,我们必须先审视那道横亘在AMD心头的巨大阴影——英伟达刚刚发布的Vera Rubin平台。
了解对手的强大,才能理解AMD此次反击的悲壮与战略价值。

就在AMD发布会开始前,黄仁勋展示了英伟达的下一代核武:Vera Rubin。
这个名字本身就充满了隐喻——Vera Rubin是证实暗物质存在的著名天文学家,而英伟达正试图掌控AI宇宙中那些「看不见」但决定一切的力量:数据流动的引力。
根据现场披露的信息,Vera Rubin平台严丝合缝、甚至精密得令人窒息。
它由三个核心组件构成,每一个都直指AMD的要害:
(1) Rubin GPU:这是英伟达的皇冠明珠。
虽然具体工艺细节被严格保密,但其配备了下一代HBM4(高带宽内存)。这一事实,足以让整个行业颤抖。 HBM4不仅仅是速度的提升,更是容量的质变,直接解决了大模型训练中的「内存墙」问题。

(2) Vera CPU:这是英伟达基于Arm架构深度自研的怪兽。
它拥有88个自定义Arm核心和176个线程。 英伟达的意图或许是:通过超级芯片的设计,将Vera CPU与Rubin GPU在物理层面「焊死」在一起,逐步在高端AI服务器中剔除x86架构的CPU(也就是AMD和Intel的主阵地)。

(3) NVL144 机架:这是英伟达「数据中心即计算机」理念的终极形态。
单机架拥有144颗GPU,通过NVLink 6互联,带宽达到了惊人的260TB/s。 这是一台巨大的、单一的、吞噬电力的超级计算机。

英伟达传递的信息冷酷而明确:在未来的AI数据中心里,不需要插拔,不需要兼容,甚至不需要其他品牌的Logo。你买的不是芯片,而是英伟达定义的「算力单元」。
更令AMD感到压力的是英伟达在软件叙事上的升级。
黄仁勋在演讲中不再只谈论训练,而是大谈特谈Agentic AI。
当AI模型从单纯的聊天机器人进化为能自主规划、调用工具、解决复杂任务的智能体时,推理算力的需求将不再是线性的,而是指数级的。
一个Agent为了完成一个任务,可能需要在后台进行数千次的推理、反思和模拟。
英伟达声称,Rubin平台能将推理Token的成本降低10倍。
这种「降维打击」般的承诺,直击了OpenAI等客户的痛点——他们每天都在为天文数字般的电费和算力成本发愁。
英伟达试图告诉市场:只有我的软硬件一体化平台,才能承载这种能够「思考」的AI。
在这样的背景下,苏姿丰登场了。
她面对的是一个近乎完美的对手,一个不仅垄断了现在,还试图定义未来的帝国。
灯光渐暗,大屏幕上亮起了AMD标志性的橙红色光芒。
PPT的第一页是一句充满了防御性却又极具进攻意味的标语:「Solving the World's Most Important Challenges」(解决世界上最重要的挑战)。

苏姿丰没有回避房间里的大象,而是直接切入正题:算力需求的爆炸。

AMD直接抛出了概念:Yotta Scale Compute(尧字节级计算)。
尧塔浮点运算(Yottaflop),代表每秒一亿亿亿次浮点运算(10²⁴ FLOPS)。
目前,最强的El Capitan还是百亿亿次浮点运算(1.742 Exaflops,即10¹⁸ FLOPS)
AMD的目标是未来5年,10万台El Capitan级超级计算机。

目前,世界最强超级计算机El Capitan,占地约697平方米,相当于两个网球场大小
根据AMD的内部数据,AI算力需求正在经历每年前所未有的暴涨。
PPT第8页赫然写着:「10,000x Increase in AI Compute」。

苏姿丰说:「不仅训练算力每年增长4倍,在过去两年里,推理Token的数量增加了100倍。」
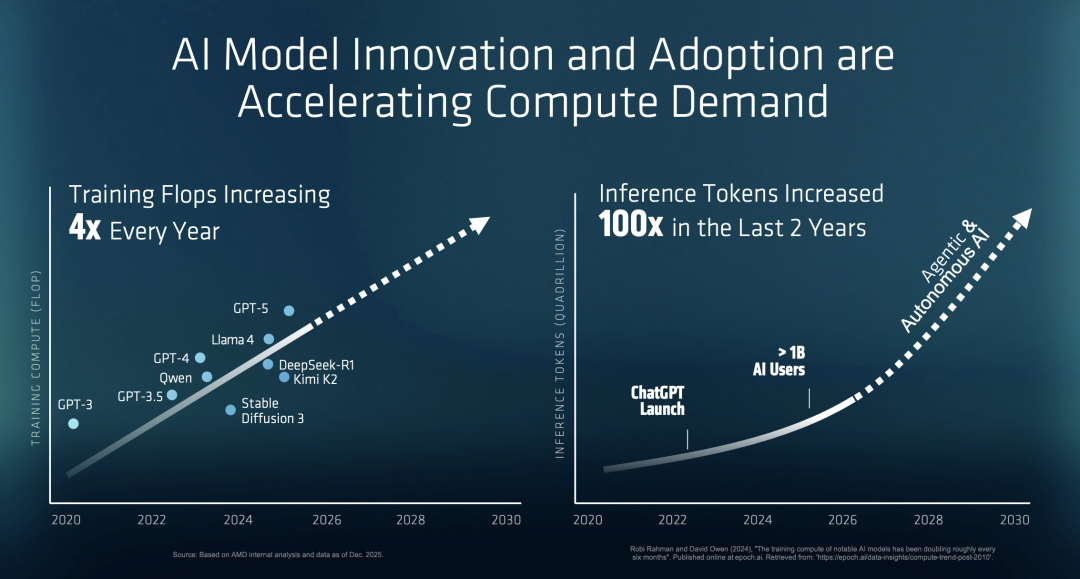
这一数据直接回击了英伟达关于「推理成本」的叙事——AMD同样看到了Agentic AI的未来,但他们的解决方案完全不同。
AMD试图用更开放、更巨大的规模来解决问题。
发布会的高潮是一个名为「Helios」的AI机架的揭幕。

以希腊神话中的太阳神命名,Helios承载了AMD照亮黑暗、打破垄断的隐喻。
如果说英伟达的NVL72是一座封闭的黑色方尖碑,那么Helios就是AMD试图构建的「巴别塔」——一座由全人类(除了英伟达)共同建造的高塔。
为了更直观地理解这场对决,我们将Helios与英伟达的NVL平台进行了详细对比:
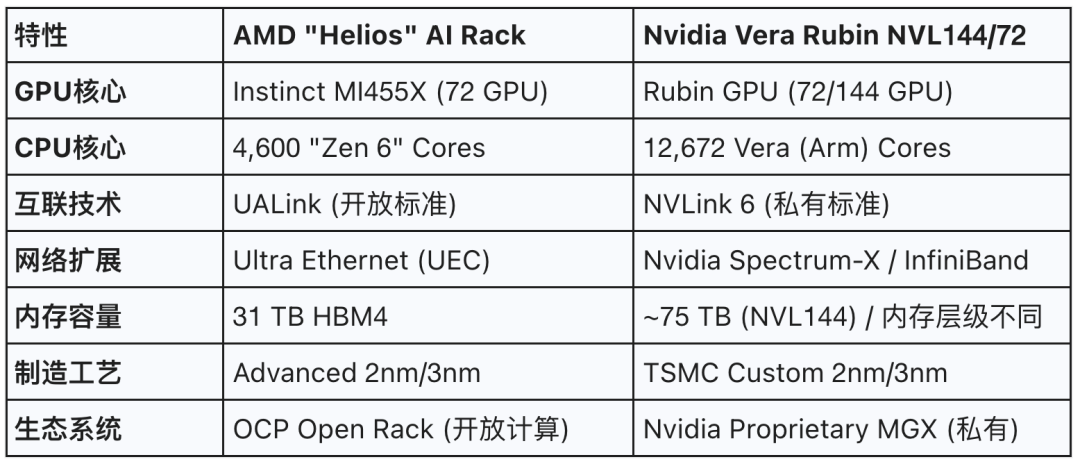

Helios机架不仅仅是硬件的堆叠,它是AMD战略的集大成者。
Zen 6的首次确认与x86的坚守:在PPT的参数列表中,赫然写着「4,600 'Zen 6' CPU Cores」。
这是一个巨大的彩蛋,也是AMD对英伟达Vera CPU最有力的回击。
当英伟达试图将世界推向Arm架构时,AMD坚守并升级了x86架构。
对于那些在这个星球上拥有数以亿计基于x86代码资产的企业来说,不需要为了AI重写所有的底层代码。
31TB HBM4内存的暴力美学:这是一个让现场发出惊呼的数字。
对于大模型训练而言,显存容量往往比计算速度更早成为瓶颈。
AMD继续沿用了「大显存」策略,试图用海量的HBM4来容纳更巨大的MoE模型,从而减少跨卡通信的频率。
这是一种简单粗暴但极为有效的策略:如果你的互联速度不如NVLink,那就把内存做大,减少互联的需求。
作为Helios的心脏,AMD Instinct MI455X被正式推向舞台中央。

10倍性能跃迁:相比于前代MI355X,MI455X实现了10倍的性能提升。
这是一个激进的数字,通常代际升级在2-3倍,10倍的宣称意味着架构级的重构。
这主要得益于新的CDNA架构和制程红利。

OAM模组化设计的坚持:不同于英伟达越来越倾向于将CPU和GPU焊死在一块主板上,AMD依然强调即插即用的灵活性。
这意味着客户可以保留原有的服务器机箱,只升级计算模组。
这对于成本敏感的云服务商来说,是极具诱惑力的「反锁定」策略。
他们不需要因为升级GPU而扔掉整个机柜的电源和散热系统。
AMD展示了直到2027年的路线图,这种透明度在瞬息万变的半导体行业极为罕见。

2026年:MI400系列(即今天的MI455X)。
2027年:MI500系列。这将基于CDNA 6架构,采用2nm工艺,配备HBM4E内存。
AMD承诺在4年内实现1000倍的AI性能提升。

这是在告诉资本市场和客户:「我们有长期的技术储备,不会在英伟达的快速迭代中掉队。我们是长跑选手,不是投机者。」
如果说GPU是跑车,那么互联技术就是高速公路。
英伟达之所以无敌,不仅仅是因为跑车快,更是因为他们修了私有的高速公路(NVLink),只允许自家的车跑,而且还要收昂贵的过路费。
本次发布会上,AMD最核心、也是最具破坏力的战略反击,就是联合全行业修建一条免费、通用的高速公路——UALink (Ultra Accelerator Link),以及升级原本的国道——Ultra Ethernet (超以太网)。
在技术圈,NVLink被视为英伟达最深的护城河,甚至超过了CUDA。
它允许GPU之间像大脑神经元一样共享内存,延迟极低。
没有NVLink,几千张GPU堆在一起只是一堆沙子;
有了NVLink,它们才是一颗超级大脑。
英伟达的策略是:如果你想用最高效的集群,就必须买全套英伟达方案。
NVLink不兼容任何其他厂商的芯片,它是一个封闭的物理层协议。
AMD在PPT中专门辟出一页介绍开放生态。
这背后是一个名为UALink Consortium的庞大联盟。
Scale Up(节点内扩展)的利剑:UALink。
这是直接对标NVLink的技术。
它由AMD、英特尔、微软、Meta、谷歌、博通等巨头共同制定。
UALink 1.0规范支持多达1024个加速器在一个POD内互联,这在规模上甚至超越了英伟达当前的NVSwitch能力。
内存一致性:UALink最关键的特性是支持显存池化。
这意味着AMD的GPU可以访问同一集群内其他GPU的内存,就像访问自己的一样。
这对于训练万亿参数模型至关重要,也是此前只有NVLink能做到的事情。
这是一个典型的「合纵连横」故事。
OpenAI、微软、Meta这些巨头最恐惧的不是技术瓶颈,而是供应商锁定。
如果未来的AI基础设施完全依赖英伟达的私有标准,这些科技巨头的议价权将归零。
因此,Helios机架不仅仅是AMD的产品,它是整个「反英伟达联盟」的意志体现。
除了UALink,发布会中多次提到Ultra Ethernet (UEC)。
这是另一场关乎生死的战争:节点间互联。
InfiniBand的统治:英伟达在收购Mellanox后,垄断了高性能网络InfiniBand。 它延迟极低,无损传输,是AI训练的黄金标准。
以太网的进化:AMD没有选择自研私有网络,而是押注以太网的进化。 UEC旨在解决传统以太网在AI负载下的丢包和拥塞问题。
成本的逻辑:InfiniBand昂贵且封闭,而以太网廉价且通用。 根据研究,UEC方案的每GFLOP成本比InfiniBand低27%。
如果UEC成功,意味着客户可以用便宜通用的以太网交换机(比如博通、思科的产品)来组建超级计算机,而不需要购买昂贵的英伟达Quantum InfiniBand交换机。
这正是Helios机架的杀手锏:更低的总拥有成本(TCO)。
对于那些要购买数万张显卡的客户来说,这节省下来的钱可能高达数十亿美元。
视线从云端的数据中心拉回,苏姿丰将展示重点转向了PC。
在AI时代,PC正在变成「私人AI助理」的物理载体。

AMD发布了震撼级的产品——Ryzen AIMax系列。

这款芯片看似只是笔记本处理器,但其参数却令人咋舌,尤其是那个恐怖的数字:128GB统一内存。

为什么这很重要?
在过去,x86处理器的内存和显存是分离的,且容量有限。
想在笔记本上运行一个像Llama 3 70B这样的大模型几乎是不可能的,因为显存不够。
苹果的M系列芯片(M3 Max/Ultra)之所以受开发者欢迎,就是因为统一内存架构允许大模型直接在本地运行。
AMD Ryzen AI Max直接对标苹果,成为首款能运行2350亿(235B)参数模型的x86处理器。
这意味着,开发者可以在一台Windows笔记本上,流畅运行企业级的超大模型,而无需联网。
现场的PPT充满了火药味,AMD几乎把市面上所有的竞争对手都拉出来打了一遍:

对比Intel Core Ultra 9:Ryzen AI 400系列在内容创作上快1.7倍,多任务处理快1.3倍。
这象征着x86阵营内部话语权的转移。
对比Apple M5:这是一个大胆的比较。
AMD声称Ryzen AI Max在AI Token生成速度上快1.4倍。
对于那些苦于苹果生态封闭、又羡慕其统一内存架构的开发者来说,这是唯一的替代品。
对比Nvidia DGX Spark:最令人意外的是,AMD将笔记本芯片与英伟达的工作站级别产品对比。
在每美元Token生成效率上,Ryzen AI Max是英伟达DGX Spark的1.7倍。
AMD描绘了一个诱人的未来:每一个开发者、每一个创作者,都能在自己的书桌上拥有一台「微型超算」。
不再需要昂贵的云端API,不再担心隐私泄露,你的Ryzen AI Max就是你的私有GPT。
这对于OpenAI等公司来说也是利好——如果端侧算力足够强,大量的推理任务可以从云端卸载到用户本地,从而节省天文数字般的云服务器成本。
除了硬件,AMD还发布了Ryzen AI Halo处理器,专为AI开发者设计。

它是一个平台。
它预装了ROCm软件栈(AMD的CUDA替代品),优化了PyTorch、Hugging Face等框架,并且实现了Day-0支持主流模型(Llama, GPT-OSS, Flux等)。

AMD终于意识到,软硬结合才是王道。
他们试图用类似苹果的体验,将开发者从CUDA的引力场中拉出来,给他们一把「铲子」,让他们在AMD的土地上挖掘AI的金矿。
在发布会的后半程,PPT上出现了一张密密麻麻的Logo墙。
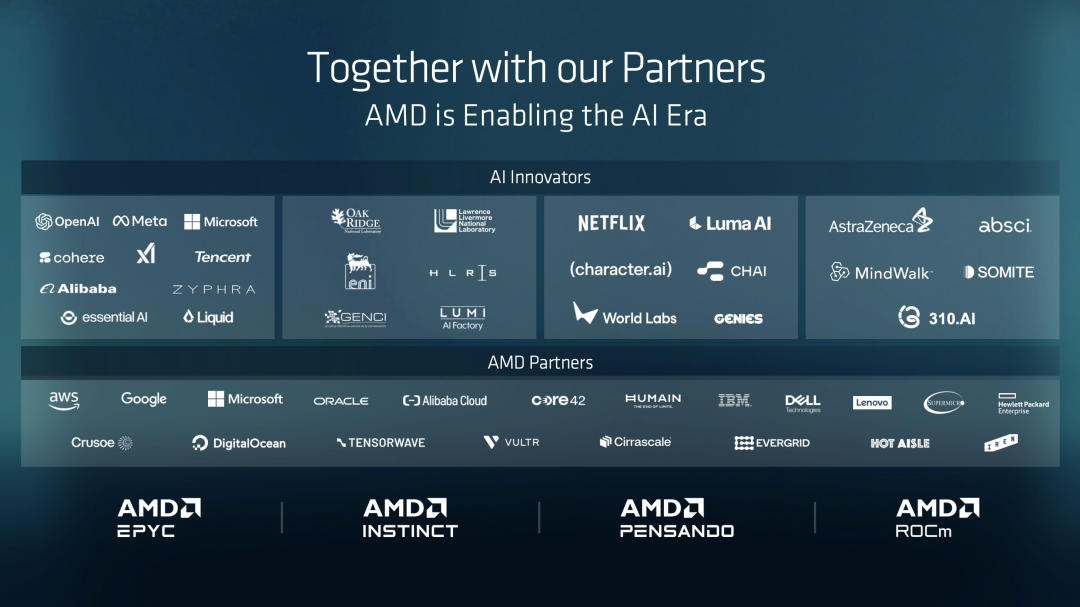
但其中最耀眼的,莫过于OpenAI。
虽然奥特曼没有亲自出场站台,而是OpenAI总裁Greg Brockman代为出席,但OpenAI作为核心合作伙伴出现在第一位,本身就是最强烈的信号。
这是一场关于生存的博弈。
为什么OpenAI需要AMD?
答案很简单:恐惧。
OpenAI对算力的饥渴已经到了病态的程度。
Brockman直接摊牌,在OpenAI内部,「算力一直在被争抢」。
对此,苏姿丰打趣道:「我每次见到你,你都会告诉我:你们还需要更多算力。」
随即,她抛出一个关键问题:「需求真的有这么大吗?」
Brockman的回答相当直接:
过去几年里,OpenAI的算力规模几乎每年都在翻倍甚至三倍增长,而且这种趋势不会放缓。
他甚至用ChatGPT,做了一页幻灯片,分析了OpenAI如何让推理更省算力,包括更高带宽、更强性能、更低的HBM内存占用。

据报道,GPT-6及后续模型的训练需要数万张甚至数十万张B200。
如果只依赖英伟达,OpenAI的命运就完全掌握在黄仁勋手中。
英伟达可以决定谁先拿到芯片,谁能拿到多少,甚至以什么价格拿到。
议价权:引入AMD作为「二供」,是OpenAI乃至微软逼迫英伟达降价、或者至少不随意涨价的唯一手段。
哪怕AMD的芯片只能达到英伟达80%的性能,只要它存在,英伟达就不能肆无忌惮地垄断定价。
供应链安全:当台积电的CoWoS产能被英伟达订满时,AMD提供了一个备选项(尽管他们也争抢台积电产能,但AMD的Chiplet设计策略使其能利用不同的封装技术,增加了供应链的弹性)。
除了OpenAI,我们还看到了Hugging Face、PyTorch、Databricks等名字。
这是AMD对外界质疑最有力的回应。
多年来,关于AMD最大的诟病就是「硬件一流,软件三流」。
ROCm(Radeon Open Compute)一直被认为是CUDA的拙劣模仿者,Bug多、文档少。
但在这次发布会上,AMD展示了ROCm的广泛采用。

这一变化的幕后推手是PyTorch 2.0。
随着PyTorch等高层框架的普及,底层的CUDA依赖正在被剥离。
对于大多数开发者来说,只要PyTorch代码能跑,底下是A卡还是N卡已经越来越不重要了。
OpenAI的Triton语言更是加速了这一过程,它允许开发者编写的代码自动优化到不同的硬件后端。
这正是AMD「农村包围城市」战略的体现:既然无法在底层CUDA上击败你,那就把战场拉到上层的PyTorch和Triton上,在那里,大家是平等的。
苏姿丰抛出了一个让全场愣住的判断:「五年内,全球将有50亿人每天都在使用AI 。」

注意:是每天都在用!
这意味着算力需求将持续指数级增长。
2025年,全球AI用户已超过10亿!而且,这不是AI的终点:未来主动式和自动化AI还将指数级增长,引爆更多推理算力需求。
AMD的另一个关键判断是:AI正在从云端,走向个人电脑。

李飞飞直接描绘了未来的游戏体验。
她的公司World Labs旗下的产品Marble,只需要少量照片,就能让模型自动构建一个完整的3D世界。
现场演示中,只要用手机随手拍几张照片,AI就能自动生成3D场景。
游戏、虚拟世界、创作门槛,会被彻底打穿。
这深远影响PC的使用体验。
更激进的,是主动式智能体。
明年开始,你的电脑,可能真的会「替你打工」:

除了PC,AMD 还在同步押注物理AI等场景。
哪里需要AI算力,AMD就会出现在哪里。

这一次,AMD是真正的All in AI。
当苏姿丰在台上展示LUMI超级计算机(由AMD驱动的前欧洲最快超算)在气候模拟上的贡献时,更是进一步输出了价值观。

本次CES发布会,实质上是「反英伟达联盟」的一次誓师大会。
英伟达的路线:类似于早期的IBM或现在的苹果。
封闭、昂贵、体验极致、利润独吞。
Vera Rubin平台将这种封闭推向了极致,从CPU到GPU再到网卡和交换机,全部自研,全部私有。
AMD的路线:类似于安卓。
开放、混乱但充满活力、性价比高、利润共享。 它联合了博通(网络)、英特尔(CPU互联)、微软(软件)等所有被英伟达边缘化的巨头。
客户的选择:短期内,为了追求极致性能(如训练GPT-6),巨头们依然会咬牙购买英伟达的Rubin。
但在推理侧和中等规模训练中,Helios和MI455X提供了极具吸引力的替代方案。
发布会结束了,苏姿丰在一片掌声中退场,留下了身后大屏幕上那个巨大的「Together we advance_」的标语。

对于全球科技产业而言,2026年的这天意义非凡。
我们并不希望看到一个只有一个玩家的游戏。
当英伟达试图用Vera Rubin将整个AI产业封装进它的黑色机柜时,AMD用Helios在墙上凿出了一扇窗。
如果说英伟达是算力时代的「罗马帝国」,不仅修路(NVLink),还造车(GPU),甚至开始制定交通规则(Agentic AI),那么AMD就是那个试图维持贸易自由的「商业联邦」。
OpenAI需要这扇窗,微软需要这扇窗,在这个星球上每一个渴望低成本、普惠AI算力的开发者都需要这扇窗。
这场「AI算力战争」没有终点,Yotta Scale只是下一个开始。
正如沙漠中每一粒沙子都可能成为未来的芯片,算力的世界里,也绝不应该只有一种声音。

 VIP复盘网
VIP复盘网
