

摘要
GPT5发布在即,有望挑战多模态AI新高度。当前多模态AI正在向“多模态全才”发展,绝大多数多模态大模型仍然停留在L3级别(任务级协同),对于L4范式级协同及L5模态级协同仍然有较大差距,而据早前官方口径,GPT5有望将前期各类模型整合在一起,我们认为强大整合的GPT5有望集推理、多模态、Agent、编程、Deep research等功能于一身,冲击L5级别多模态AI。
全球科技巨头争先入局,多模态或是AI货币化的先锋。据快手官方,2025Q1可灵AI已经实现1亿美元ARR,展现出良好的AI货币化能力,科技巨头纷纷押注多模态AI,如:
1)腾讯发布混元3D世界模型,一键生成“我的世界”;
2)阿里通义万相是业界首个使用MoE架构的视频生成模型,总参数量为27B,激活参数14B,还支持电影美学控制系统;
3)字节在 Seed1.6 模型系列中探索了 Adaptive CoT 技术,让模型能够根据问题难度自动触发思考过程,取得了模型效果和推理性能的平衡等。
国内上市公司也在加大多模态AI应用的商业化进程:
1)美图:推出了RoboNeo,实现集图像编辑、视频生成、设计创作、网页建站于一体的智能AI Agent;
2)万兴科技:有望对标可灵的天幕2.0即将发布,叠加超媒AI Agent打造一站式AIGC体验;
3)快手:快手可灵2.0模型在动态质量、语义响应、画面美学等维度,保持全球领先,2025Q1就已经实现1亿美元ARR的亮眼表现;
4)合合信息:扫描全能王的能力范围在加速扩展,延伸至AI鉴真、AI Agent等前沿AI应用;
5)福昕软件:福昕智能文档解决方案以多模态解析技术和人工智能技术为基座,构建了从文档解析、知识索引到精准问答的全链条能力。
投资建议:当前全球多模态AI正在向“多模态通才”转变,智能化水平与能力范围不断扩大,美图、快手等多模态AI产品已经体现出较强的AI货币化能力,多模态AI应用或成为AI大模型商业化变现的前锋,建议关注多模态AI相关标的:美图、快手、万兴科技、合合信息、福昕软件等;同时建议关注受益于多模态AI发展的AI应用、AI算力等相关标的。
风险提示:多模态AI技术落地不及预期,行业竞争加剧。
1 GPT5发布在即,有望挑战多模态AI新高度
1.1 多模态AI的新基准:“多模态通才”
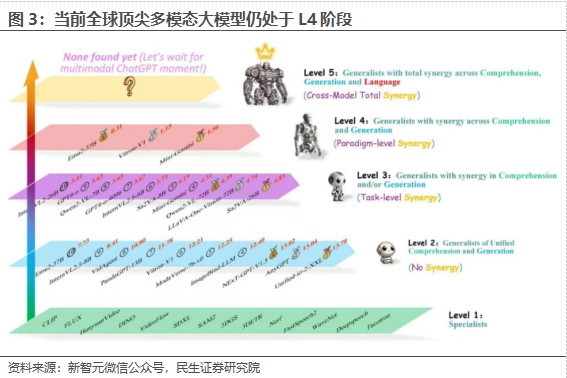
全新的General-Level提出全新理念:判断一个多模态通用模型是否更强大,不能简单地等同于在基准测试中获得更高的分数,或者与其他模型相比支持尽可能多的多模态任务。2025年5月,十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
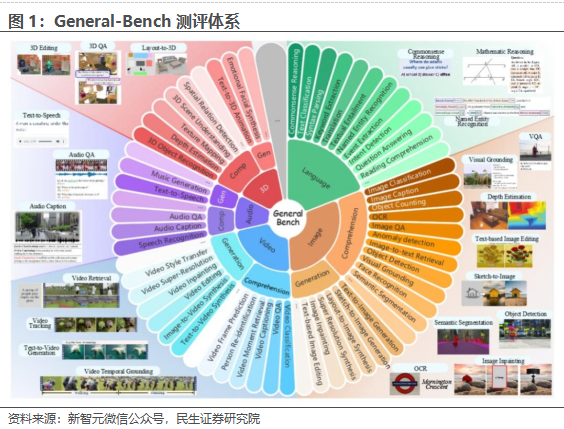
General-Level建立了五个层级的评价水平,当前全球范围内多模态模型仍然处于L4阶段。据新智元微信公众号,该评价体系将考察体系分为四个方向:
1)模态理解和同时进行多模态理解和生成:最初阶段,多模态大语言模型(MLLMs)的回复仅限于基于用户提供的多模态输入生成文本输出;后续的多模态大语言模型不仅具备多模态理解能力,还能在各种模态之间生成、编辑内容;
2)支持更广泛的模态:多模态通才需要广泛支持和处理多种模态数据,包括但不限于文本、图像、视频、音频,甚至是三维数据,支持的模态范围反映了一个人工智能系统能力的广度。到目前为止,多模态模型可以将图像与视频结合、视频与音频结合等,最先进的模型甚至可以处理任意模态;
3)支持各种任务和范式:多模态通才必须能够处理各种不同定义和要求的任务,来提高整体的多功能性。例如,早期的视觉多模态大语言模型只能进行粗粒度的图像理解,后续发布的模型能够实现细粒度、像素的图像/视频定位和编辑等。模型的解码组件也必须足够灵活,能够以各种任务格式生成输出,处理不同类型的任务,例如目标定位、像素级修改以及多模态内容创作;
4)多模态智能体与多模态基础模型:刚开始的多模态智能体,就是大语言模型通过调用外部工具和模块(通常是专用模型)来执行特定的多模态任务。后续的研究重点逐渐转向构建联合多模态大语言模型,其中大语言模型与其他模块(如多模态理解组件和多模态生成组件)通过共享嵌入空间紧密集成。
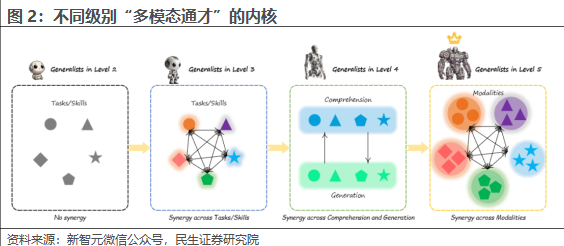
基于上述考察体系,L1-L5的评价分别要求:
1)L1专家型模型:针对特定任务或特定模态的数据集进行微调,可以看作是针对特定任务的专家模型,包括各种学习任务,例如语言或视觉识别、分类、生成、分割、定位、图像修复等,比如CLIP,Stable Diffusion等;
2)L2支持多任务的通才:模型从专用模型转变为通用模型,需要让系统能够适应各种任务建模方式,支持多种模态类型和输入格式,同时处理各种模型类型和输出格式(可用于理解或生成)。目前,最流行且广泛采用的做法是以大语言模型(LLM)作为核心/智能媒介,整合各种专业模型来构建通用模型,通过现有的编码和解码技术整合各种模型,从而实现多种模态和任务(比如理解和生成任务)的融合与统一;
3)L3出现任务级协同的通才:要从普通的通用模型提升到第3级,系统必须展现出跨任务的协同能力,使得至少两个任务(无论这两个任务是理解类的还是生成类的,都能够共享特征并实现相互性能提升;
4)L4范式级协同的通才:如果一个通用智能体能够达到第4级,也就意味着该系统不仅具备强大的理解能力,而且在进一步学习和训练生成能力时仍能保持基础性能,比如Morph-Token分离出视觉重建损失用于生成学习,以避免与理解学习损失相互干扰;
5)L5模态级全协同的通才:是通用智能体的最终目标,从某些模态的任务中学到的特征、知识甚至智能可以在一定程度上迁移到其他支持的模态任务中。目前,大多数多模态通用智能体受到架构发展的限制,主要通过语言智能来支持其他模态的智能,要想真正达到第5级,必须实现所有模态之间的协同。
1.2 科技巨头纷纷押注多模态AI
1.2.1 腾讯混元3D世界模型:一键构建“我的世界”
腾讯混元3D世界模型是业界首个开源可沉浸漫游、可交互、可仿真的世界生成模型,为游戏开发、VR、数字内容创作等领域带来了全新的可能性。据腾讯开源微信公众号,该模型核心是语意层次化3D场景表征及生成算法,该算法将复杂3D世界解构为不同语意层级,实现前景与背景、地面与天空的智能分离,不仅生成视觉效果逼真的整体场景,还能输出标准化的3D Mesh资产,兼容Unity、Unreal Engine、Blender等主流工具。用户可对场景内元素进行独立编辑或物理仿真,无缝衔接AIGC技术与传统CG工作流;能够实现只需输入简单指令,模型即可快速生成包含建筑、地形、植被的完整3D场景。输出的Mesh文件可用于游戏原型搭建或关卡设计,还能灵活调整前景物体、更换天空背景,满足个性化创作需求;此外,腾讯混元还披露了包括端侧混合推理语言模型、多模态理解模型、游戏视觉模型等在内的一系列开源计划。

1.2.2 通义万相:业界首个使用MoE架构的视频生成模型
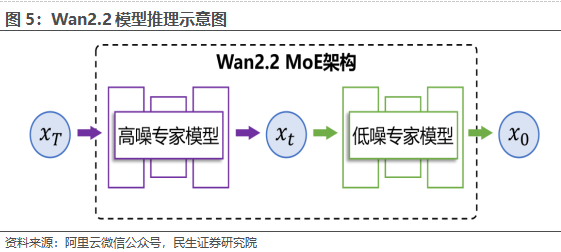
通义万相文生视频模型和图生视频模型均为业界首个使用MoE架构的视频生成模型,总参数量为27B,激活参数14B;同时,首创电影美学控制系统,光影、色彩、构图、微表情等能力媲美专业电影水平。据阿里云微信公众号,通义万相2.2率先在视频生成扩散模型中引入MoE架构,有效解决视频生成处理Token过长导致的计算资源消耗大问题;Wan2.2-T2V-A14B、Wan2.2-I2V-A14B两款模型均由高噪声专家模型和低噪专家模型组成,分别负责视频的整体布局和细节完善,在同参数规模下,可节省约50%的计算资源消耗。在模型能上,通义万相2.2在复杂运动生成、人物交互、美学表达、复杂运动等维度上也取得了显著提升。此外,较上一代万相2.1模型,万相2.2模型的训练数据实现了显著扩充与升级,并在训练中引入了专门的美学精调阶段,通过细粒度地训练,使得视频生成的美学属性能够与用户给定的prompt提示词相对应。万相2.2模型在美学精调阶段创新性提出了「电影级美学控制系统」,直接将光影、色彩、镜头语言三大电影美学元素装进模型。通义团队编码了60多个直观可控的参数,并且可以随意组合,大幅提升电影级画面的制作效率。
1.2.3 Figma:借力AI重写创意行业新格局
Figma服务的客户分散在银行、快消品、能源、制造、软件等各行各业,截至2025年3月31日,Figma在全球已有45万付费客户。据智东西微信公众号,全球数十亿人使用应用程序、网站和其他数字体验都是通过Figma制作的,包括谷歌地图、优步打车软件、奈飞流媒体节目、多邻国语言学习应用、领英职场社交媒体、大语言模型Claude等。Figma的访问权限以按年或按月订阅的形式出售。如下图所示,其根据特定用户的需求提供不同的档位,包括五个档位:Viewer、Collab、Content、Dev、Full,对应入门者、专业用户、组织用户和企业用户,不同档位对应不同的费用,截至2025年3月31日,Figma的总留存率为96%,净美元留存率达到132%,在Figma平台上年度付费超1万美元的付费客户达到11107家。

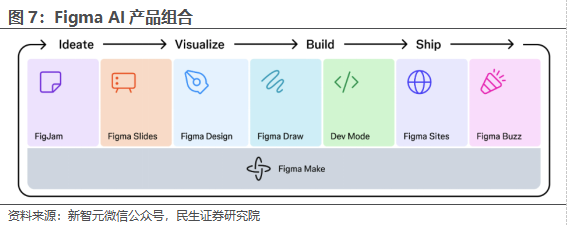
2025年,Figma有望推出四款全新AI产品。据智东西微信公众号,2025年Figma将推出四款新产品,使产品组合规模翻一番:Figma Make、Figma Draw、Figma Sites和Figma Buzz:
1)Figma Make:是一款AI驱动的可将提示词转化为功能的工具。用户可以直接从指令生成可运行的原型,并且立即验证想法;可以自由选择进一步输入指令、直接编辑代码,还是进行视觉化操作;
2)Figma Draw:是一款用于绘制精细的矢量编辑图像和产品插图的工具。Figma Draw支持AI自动完成繁琐的重复性任务,例如移除图像背景、重命名设计图层、在原型中填充逼真内容等,First Draft也是一项AI能力,用户只需输入简单指令,就能从空白画布生成可编辑的用户界面;
3)Figma Sites:可让用户设计网站并直接将其发布到网上;
4)Figma Buzz:可轻松创建数字广告等营销资产。
1.2.4 字节Seed1.6: Adaptive CoT技术的前沿探索
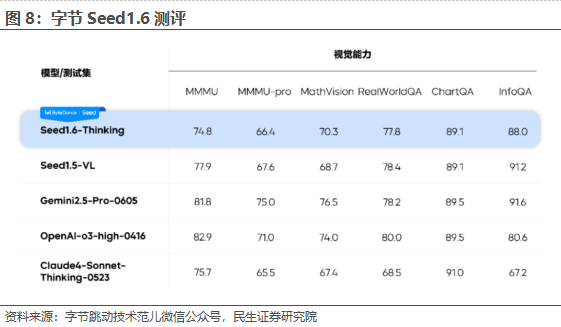
字节在Seed1.6 模型系列中探索了Adaptive CoT 技术,让模型能够根据问题难度自动触发思考过程,取得了模型效果和推理性能的平衡。据字节跳动技术范儿微信公众号,Seed1.6-Thinking 在 Seed1.5-Thinking 的基础上拓展了训练算力,加大了高质量训练数据规模(包括 Math、Code、Puzzle 和 Non-reasoning 等数据),提升了模型在复杂问题上的思考长度,并且在模型能力维度上深度融合了 VLM,给模型带来清晰的视觉理解能力。因此,对比 Seed1.5-Thinking,Seed1.6-Thinking 在复杂文本场景中的推理能力明显提升,同时也具备了较好的视觉推理能力。
2 重点公司多模态AI业务梳理
2.1 美图:RoboNeo定义AIGC Agent新范式
据AI启元社,美图最新推出了RoboNeo,这是一款集图像编辑、视频生成、设计创作、网页建站于一体的智能AI Agent,具备极强的美学审美能力与落地执行力,是一站式影像生产力工具的新标杆,且可免费使用。RoboNeo的slogan“一句话搞定影像生产力”,强调从修图、美学分析,到品牌设计、海报生成、网页建站、短视频创作,全流程自动化执行。
RoboNeo天然融合美图秀秀、美图设计室等系列产品的图像处理技术,具备图层智能拆分、插画风格保留元素一致性处理、风格转绘等高级图像功能。除了静态图像,其还具备文生视频、图生视频、视频转绘、视频动作合成等多项AI视频能力。RoboNeo覆盖了品牌设计 商业视觉内容生成的全流程需求,从企业初创视觉建设到日常电商物料输出均可应对;支持一站式网页搭建,主要针对中小企业或电商商家实现线上营销入口的快速落地。

2.2 快手:可灵AI货币化进程亮眼
快手可灵2.0模型在动态质量、语义响应、画面美学等维度,保持全球领先。据快手科技微信公众号,可灵AI致力于提升模型基础质量和模型效果,并引入更多创新功能,以满足用户的多样化需求。在本次2.0模型的迭代中,可灵AI正式发布AI视频生成的全新交互理念Multi-modal Visual Language(MVL),让用户能够结合图像参考、视频片段等多模态信息,将脑海中包含身份、外观、风格、场景、动作、表情、运镜在内的多维度复杂创意,直接高效地传达给AI。
快手可灵在2025Q1已经实现1亿美元ARR,伴随AI功能持续上新,可灵AI货币化进度有望加速。据凤凰网财经,可灵在2025年3月(正式推出后的第10个月)实现年化经常性收入(ARR)超过1亿美元;我们认为,伴随新的AI功能上线,以及全球创作者计划,可灵AI有望迎来付费用户增长同时ARUP提升的“戴维斯双击”,加快AI货币化进度。
2.3 万兴科技:天幕2.0 超媒Agent切入蓝海市场
据万兴科技微信公众号,万兴天幕2.0大模型在华为云的强大算力与技术加持下,由千人团队联合创新打造。它依托百亿级数据沉淀与万兴科技15亿用户行为数据,实现了音视频垂类原子能力的全面跃升,在专业级运镜设计、多层次立体音效生成、首尾帧智能补齐与过渡内容创作等方面达到业界领先水平。该模型秉持“创意平权”理念,聚焦音视频创作垂类场景,助力创作者突破技术限制,以更低门槛、更高效率生成具备真实感与专业品质的音视频内容,加速推动人人皆是创作者时代的到来。

万兴超媒Agent依托万兴天幕音视频多媒体大模型2.0强大技术底座打造,通过高度智能化的技术架构,实现了用一个Agent全面包办从分镜规划到作品发布一系列创作任务,有效解决了传统创作模式下多软件切换、操作繁琐等问题,使普通用户也能轻松创作出具有大片质感的音视频作品。作为一款专为全球音视频创作者量身打造的AI Agent产品,万兴超媒Agent具备三大特点:全链路视频编辑能力、行业Know-How知识库沉淀、大模型与工具链深度耦合。

2.4 合合信息:扫描全能王的能力范围加速扩展
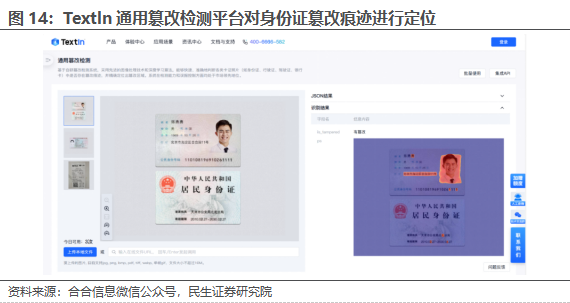
据合合信息微信公众号,合合信息“AI鉴伪”技术实现了从静态图像到多模态信息鉴伪的技术跨越,精准打击人脸视频、AIGC生成图像、证件票据等AI伪造“重灾区”。AI人脸鉴伪模型采用人脸视频篡改检测技术,可对人脸视频实现毫秒级实时鉴定,大幅提升篡改检测效率。AIGC图像鉴别技术用大模型分析“看不见”的图像信息,可实现毫秒级鉴伪,测试样本集鉴定准确率超90%,有效识别MidJourney、GPT 4O等主流模型AI生成图片。TextIn通用篡改检测平台采用自研深度神经网络技术,基于百万级数据训练,支持数十种常用票据及卡证篡改检测,有效解决企业及机构检测文档数量庞大、造假形式多样,版式复杂等痛点。
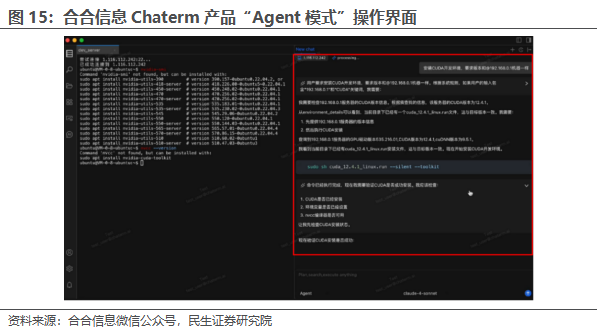
合合信息推出业内首个AI Agent跨平台云资源智能管理终端Chaterm,率先将AI Agent能力应用于云资源管理终端,通过自然语言,在操作界面对话或输入指令,就能实现工作的自动化,极大提高了开发、运维人员的工作效率。目前,Chaterm核心代码已全面开源,开发者可以直接观察算法底层运行逻辑,并根据实际需求进行定制化修改,做到云资源管理领域“透明可控,安全可信”。
2.5 福昕软件:智能文档解决方案加速落地
据福昕软件微信公众号,福昕创新性提出“大模型 领域知识 工程方法”的融合路径,构建了低成本、高效率的“人工智能 政法”应用范式。福昕智能文档技术通过将海量非结构化文档转化为结构化、可理解、可检索的数据资产,让检察官从“搜索与搬运”的低效工作中解放出来,真正聚焦于“思考与判断”的核心价值环节。

福昕智能文档解决方案以多模态解析技术和人工智能技术为基座,构建了从文档解析、知识索引到精准问答的全链条能力,使法律条文、案件卷宗等海量数据转化为可计算、可追溯的结构化知识资产,为检察机关提供了强大的数据治理能力。基于核心技术优势,福昕软件研发了“索迹智见"、“枫控智检”、“民声检应”三大核心产品,并与北京市人民检察院深度合作,共同打造了《“数智枫桥·数治北京”解决方案》。
2.6 其他多模态AI应用
北森AI 面试官得到众多企业认可。产品依靠北森20余年人才评估与面试方法论沉淀,与 AI技术深度融合形成 “专业评估逻辑 大模型能力” 双重优势,让 “面得准” 成为标配。岗位胜任力模型上,依托20年 People Science 积累及近200名心理学专家经验,为不同行业、岗位定制精准评估维度,从底层保障专业性与准确性;AI技术与场景结合方面,通过独创 “倒叙式三层追问面试法” 进行立体化追问,模拟资深面试官逻辑,结合 RAG 技术调用企业私有知识库,让评估更贴合业务场景。
粉笔AI面试点评有效提升用户面试表现。精品AI面试点评是粉笔打造的融合AI技术的智能化面试学习工具,借助虚拟面试老师,提供沉浸式模拟训练、精准智能点评及个性化答题优化,助力用户高效提升面试表现。
3 投资建议
当前全球多模态AI正在向“多模态通才”转变,智能化水平与能力范围不断扩大,美图、快手等多模态AI产品已经体现出较强的AI货币化能力,多模态AI应用或成为AI大模型商业化变现的前锋,建议关注多模态AI相关标的:美图、快手、万兴科技、合合信息、福昕软件等;同时建议关注受益于多模态AI发展的AI应用、AI算力等相关标的。
4 风险提示
1)多模态AI落地不及预期。当前多模态AI技术路径尚不清晰,或导致多模态AI技术研发不及预期,进而导致相关应用商业化落地不及预期。
2)行业竞争加剧。多模态AI应用市场较为广阔,当前互联网巨头悉数入局,传统垂类AI应用领军者若无法构建深厚护城河或面临市场份额流失风险。

 VIP复盘网
VIP复盘网
