

作为支撑大模型全生命周期的核心脊梁,AI Infra 已成为全球科技大国与企业博弈的战略高地。它不仅承载着巨大的算力洪流,更是决定AI应用能否落地生根的关键土壤。面对这一万亿级赛道,国际巨头加速跑马圈地,不断加码全球AI基础设施的布局;而中国科技力量也不遑多让,阿里、腾讯、百度等厂商正全力推进全栈自研战略,旨在打破技术壁垒,构建自主可控的AI生态闭环。随着全球数字化进程的深化,AI基础设施行业正处于爆发前夜,即将迎来新一轮的黄金增长期。
本报告旨在系统梳理AI Infra的全景图,我们将首先解读其核心内涵与必然性,接着分析市场现状与空间,继而深入产业链上下游,详细剖析硬件革新与软件进化的关键路径,并盘点国内外核心厂商的布局与能力。希望通过这份梳理,为理解AI时代的底层支撑力量提供清晰的框架。
01
行业概述
1、AI Infra概念
AI Infra(AI Infrastructure,AI基础设施)指的是专门为AI工作负载的设计、构建、管理和优化的底层硬件与软件系统。它的核心目标是高效、大规模地完成AI模型的训练和推理任务。如果将开发大模型比做是“造房子”,那AI Infra就是“工具箱”,包括构建、部署和维护人工智能系统所需的硬件、软件和服务的组合。一个完整的AI基础设施通常包含:
1)算力层:GPU、TPU、AI ASIC、推理芯片等;
2)存储层:高性能分布式存储、对象存储、NVMeSSD;
3)网络层:高带宽低延迟互连(InfiniBand、NVLink、RoCE);
4)软件与中间件层:分布式训练框架(PyTorch DDP、DeepSpeed、Horovod)、MLOps工具链(Kubeflow、MLflow);
5)运维与管理层:Kubernetes集群调度、资源监控、自动扩缩容。
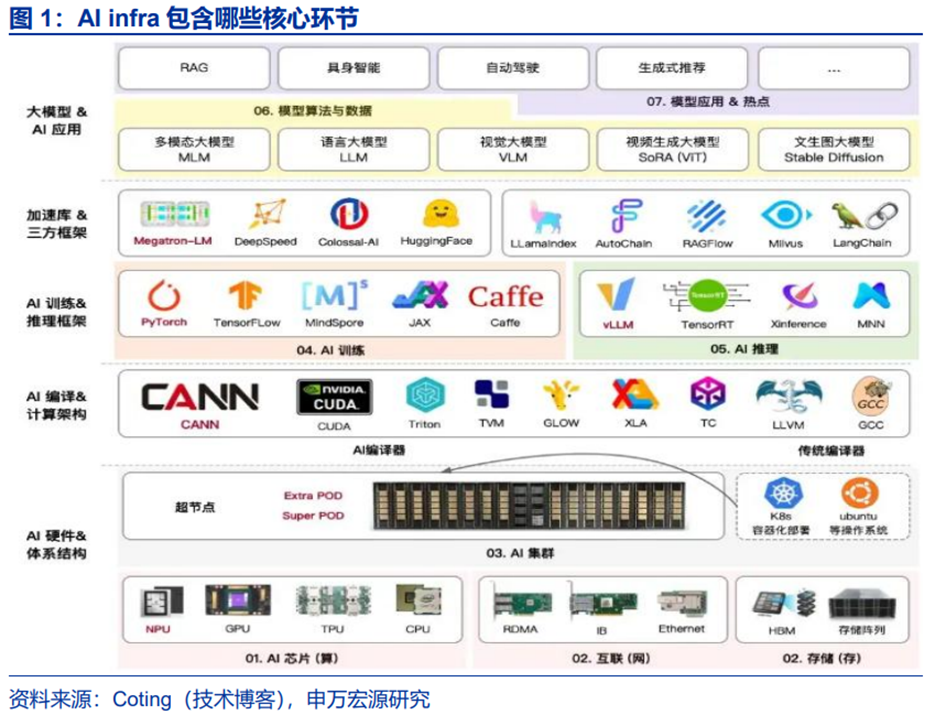
当前基础设施硬件层已经得到了充分的认知,包括算力芯片、服务器、交换机及网络设计以及存储等,AI编译和计算架构主要由底层硬件层厂商开发,AI训推框架玩家也已相对固定,包括Pytorch、Tensorflow、vLLM等,且常为开源。但再向上层,AI应用大规模渗透所需要的Infra软件,价值仍未被完全发掘。
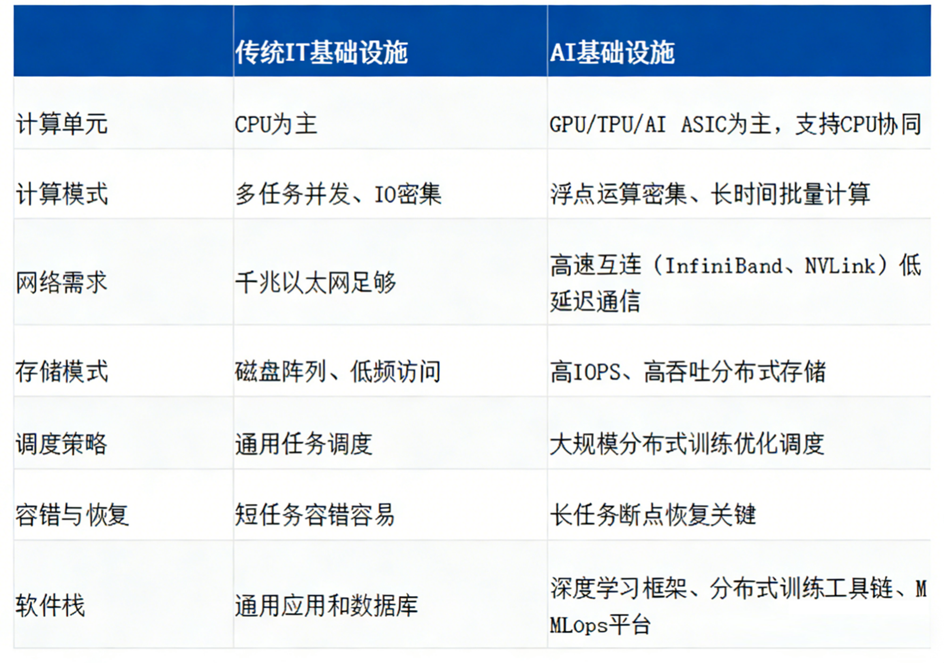
2、AI基础设施和传统IT基础设施的区别
以AI大模型训练为例,在资源占用模式上与传统IT任务存在根本性差异:
(1)计算密集与高并发:AI训练依赖庞大的浮点运算量,例如GPT-3的训练计算需求高达数百PetaFLOPs天。这要求多GPU能够进行高带宽、低延迟的协同,这区别于传统CPU服务器以IO为主的任务特性。
(2)海量数据吞吐:训练过程涉及TB至PB级数据集的加载,因此存储系统必须提供极高的IOPS和顺序吞吐能力,并支持高效的数据预取机制。
(3)调度复杂与弹性需求:AI训练任务通常耗时较长(可持续数天乃至数周),一旦中断将造成严重损失。此外,分布式训练对GPU、网络结构及节点位置高度敏感,必须采用针对性的调度策略。
(4)异构计算与优化需求:AI硬件不再是单一架构(GPU、TPU、FPGA、ASIC并存)。软件栈需要适配不同硬件的特性,最大化性能利用率。
总结来看,AI任务计算密集、数据吞吐巨大、调度复杂且依赖异构硬件,传统IT基础设施无法满足性能和稳定性要求。
3、AI Infra应具备六大核心能力
异构算力调度能力:针对当前算力多元化的发展趋势,AI Infra通过算力调度技术和平台,实现对异构算力芯片的深度适配和统一纳管,能够根据不同业务场景进行高效的算力选型、编排和分发。
智能应用支撑能力:基于云原生调度编排、微服务框架和高性能应用服务,AI Infra针对智能应用提供开发、部署、运维的全生命周期管理,具备支撑复杂多业务场景智能应用的能力。
全链路数据管理能力:基于湖仓一体对数据采集、清洗和预处理流程的支撑能力,以及向量数据库对向量数据检索的支撑能力,AI Infra具备针对AI模型开发和部署的全链路数据管理能力。
训推一体化和加速能力:AI训推平台针对AI模型训练/微调和推理框架的支撑能力,以及对于AI训推流程的加速能力,成为AI Infra在AI模型开发层面的核心技术平台。
安全体系构建能力:基于隐私计算和联邦学习的核心安全能力,AI Infra融合基础云安全能力,构建适配AI模型和应用的智算安全体系,保障AI模型和用户敏感数据的安全。
全流程场景化服务能力:针对智能体(Agent)在各行业领域加速应用的趋势,AI Infra具备支撑智能体开发与应用全流程的场景化服务能力,为MCP等智能体相关技术提供了稳定的运行环境。
02
行业现状及市场空间
1、AI基础设施正式步入稳定与革新并存的应用期
伴随着移动互联网和大数据技术的普及以及近年来AI能力的爆发式提升,AI技术在各行各业得到广泛应用,对高性能计算、大规模存储、高效算法库等基础设施需求不断增长。AI基础设施正式步入稳定与革新并存的应用期。
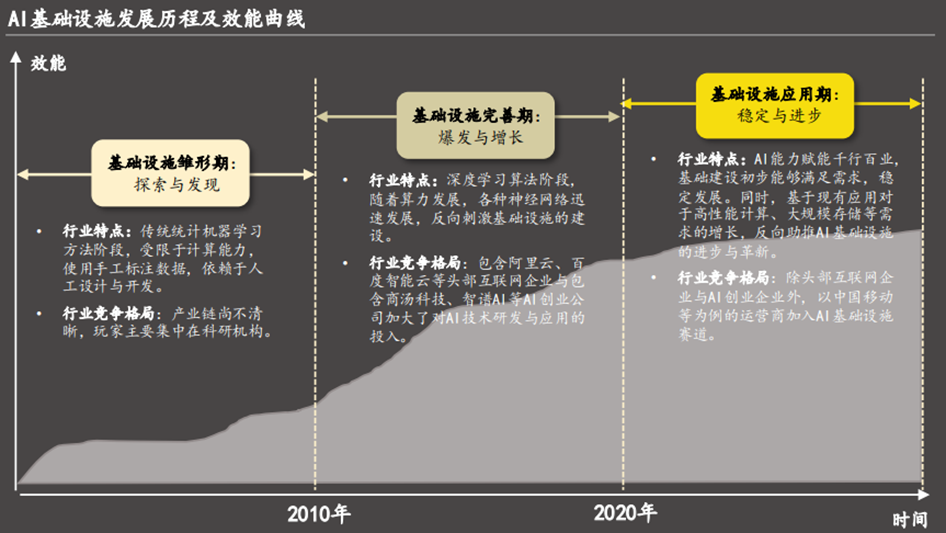
雏形期(2010年以前):该时期,AI基础设施处于探索与发现阶段,人工智能领域处于低谷时期,AI项目多数处于实验性阶段。因此,AI基础设施生态系统在该阶段尚不清晰,专业的人才与资源缺失,主导AI项目的玩家主要集中于科研机构。
完善期(2010-2019年):随着机器学习和深度学习等一系列AI技术的关键突破,AI基础设施行业开始迈入爆发与增长阶段。一方面,AI技术的进步,互联网发展带来的大数据时代以及AI开源社区的建立,均为AI技术的发展与传播提供了有力的支撑条件,进而对底层基础设施的技术发展产生积极性影响。另一方面,AI基础设施的商业模式逐渐清晰,头部互联网企业与部分AI创业企业逐步认知到AI的潜力,纷纷加入该赛道,加大了对AI基础设施的资源投入。
应用期(2020年-至今):2020年后,各行各业开始大规模应用深度学习技术实施创新应用,加快产业转型和升级。随着AI与各场景的深度融合与发展,计算能力、分布式系统和大规模数据处理能力等新能力反向助推了AI基础设施的创新与优化。此外,随着5G与AI的融合发展趋势,运营商也在该阶段进入赛道,开始积极布局包含AI基础设施新基建、平台能力新基建与云网新基建等。
2、AI焦点转向“推理”驱动,国内外厂商加码AI基建投入
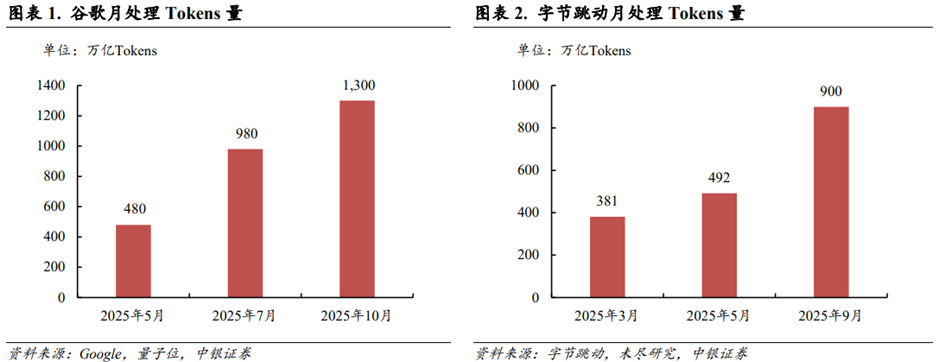
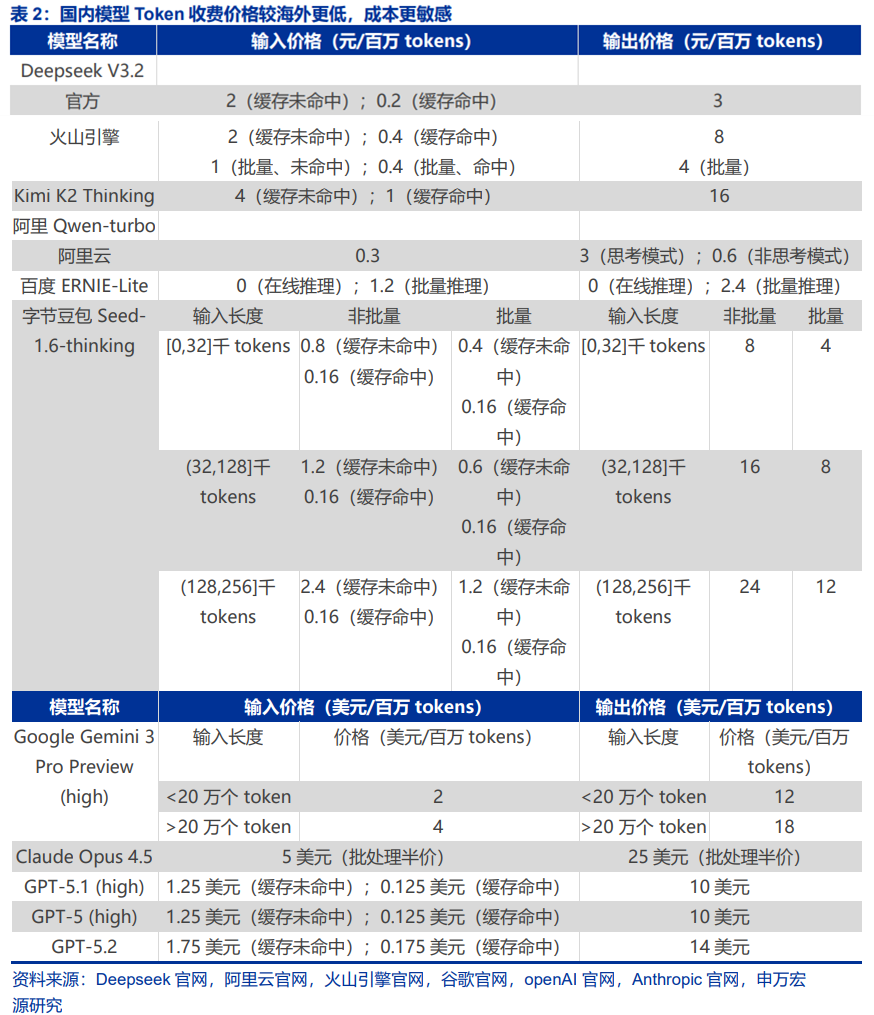
AI产业焦点从“训练”转向“推理”,带来AI Infra需求增量。在过去两年,AI产业聚焦于大模型的训练阶段,各大厂商着力于扩大大模型的参数规模,增加预训练的数据量。这是产业的“投入期”。目前,产业焦点已经逐步转向大模型的推理阶段。根据量子位援引谷歌数据,2025年10月谷歌月处理Tokens量达到1,300万亿,是2025年5月数据的2倍多。根据未尽研究援引字节跳动数据,2025年9月字节跳动月处理Tokens量达到900万亿,是2025年3月的2倍多。根据虎嗅网报道,黄仁勋在GTC2025大会上指出,AI正在从生成式向代理式(Agentic AI)和物理式(Physical AI)升级,预计2028年全球AI数据中心基础设施建设支出将达到1万亿美元。能够认为主流大模型的能力已经达到“可用性”门槛,可以满足大多数场景的商业化需求。随着大模型在商业场景的落地,推理对Tokens消耗量的需求快速增长,亦对AI基础设施建设(AI Infrastructure)提出了更高的要求。
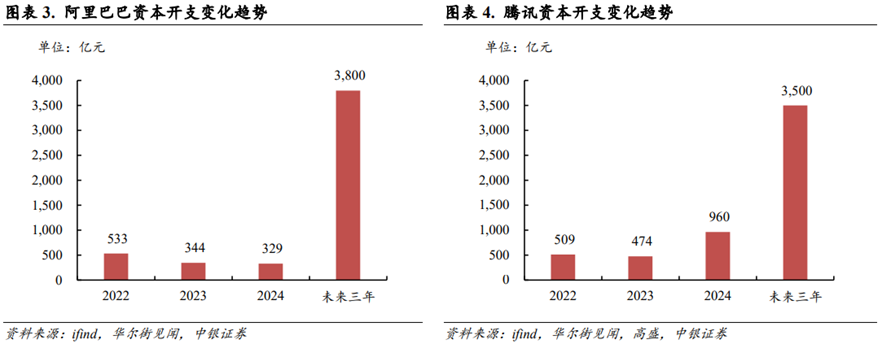
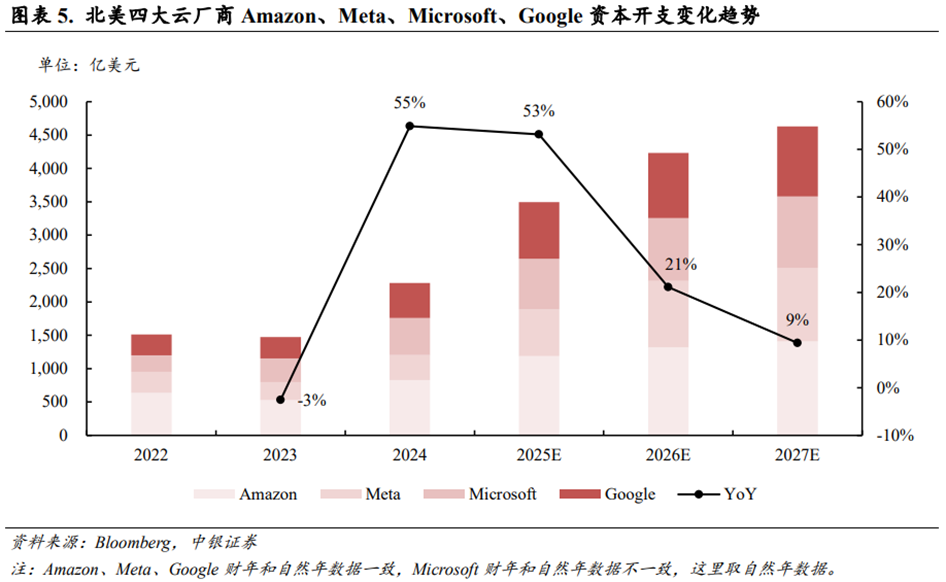
国内和海外云厂商积极提高资本开支以应对AI Infra扩张趋势。根据ifind数据,阿里巴巴2022~2024年资本开支合计达到1,206亿元;根据华尔街见闻报道,阿里预期未来三年资本开支合计达到3,800亿元。根据ifind数据,腾讯2022~2024年资本开支合计达到1,943亿元;根据华尔街见闻援引高盛数据,腾讯预期未来三年(2025~2027年)资本开支合计达到3,500亿元。根据Bloomberg数据,2025年北美四大云厂商Amazon、Meta、Microsoft、Google资本开支合计将达到3,496亿美元,YoY 53%;预计2026/2027年该资本开支数据将进一步增长至4,243/4,632亿美元。
3、全球AI基础设施市场规模预测
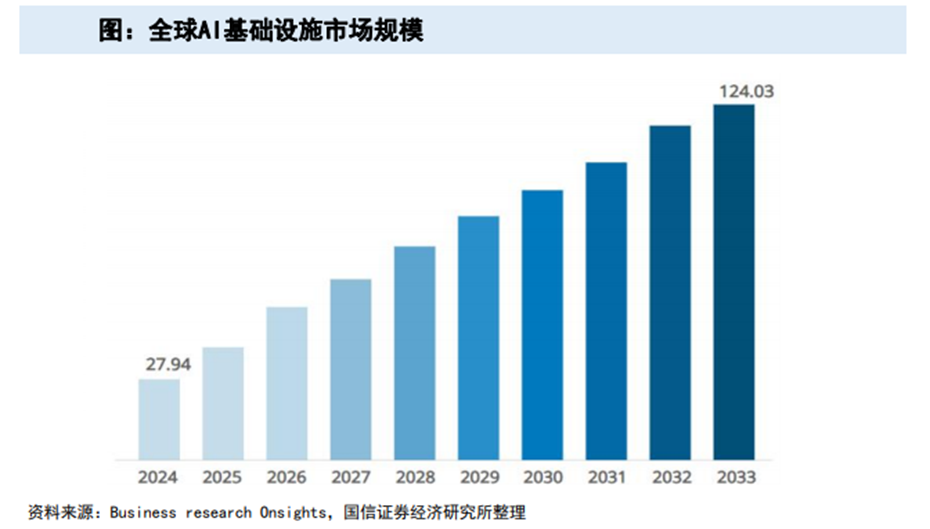
据Business Research Insights数据,全球AI基础设施市场规模在2024年为279.4亿美元,预计将在2025年上升至329.8亿美元,预计到2033年将达到12403亿美元,在2025-2033期间的复合年增长率为18.01%。
03
产业链分析
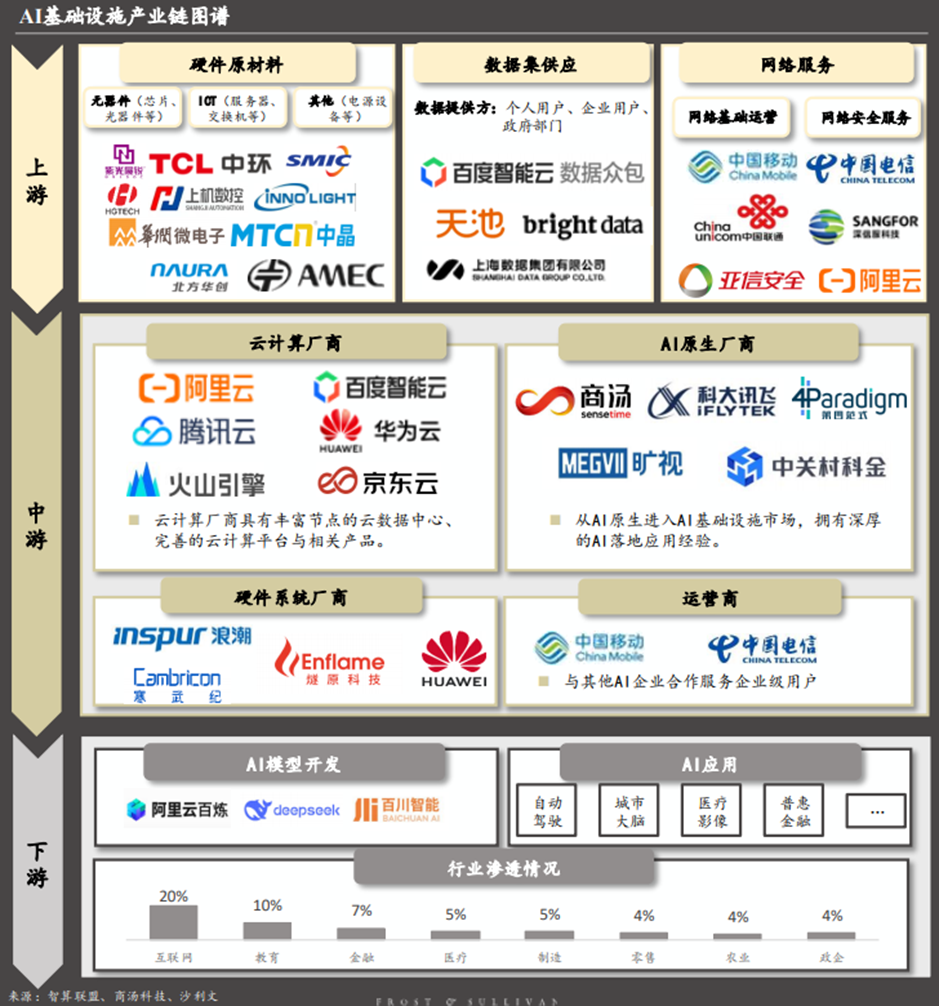
AI基础设施行业产业链上游为各类硬件原材料供应商、数据集供应商以及网络服务等;中游包括服务于各行业场景企业用户与消费级终端用户的云计算厂商、AI原生厂商、硬件系统厂商以及运营商;下游各行业应用中,互联网等数字原生行业为应用进展先行者。
1、产业链上游:AI芯片国产替代进程加速
AI芯片作为AI产业链的基础层,直接决定了AI系统的计算能力与效率,是上游的核心领域。随着2025年美国对于AI芯片限制的进一步加强与一系列国产芯片支持的政策推出,AI芯片国产替代进程加速,中国芯片自给率稳步提升,但仍亟待提高。
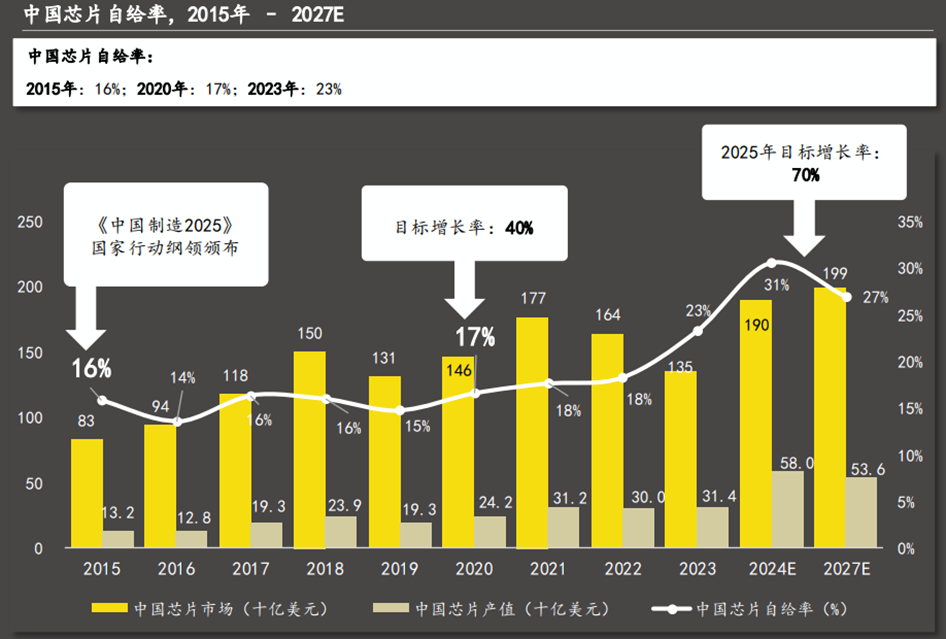
中美科技博弈持续演绎的背景下,作为核心基础层的AI芯片政策战略地位高,积极导向的政策颁布与有力的资金支持,助推芯片国产化率提升。长期看,一方面,中国企业将加大对芯片制造技术的研发投入,努力提升自身的制造能力和技术水平,减少对海外代工厂的依赖;另一方面,国内的芯片制造设备和材料供应商也将获得更多的发展机会,推动整个芯片制造产业链的国产化进程。根据Techsights数据,中国芯片自给率呈现稳定增长态势,从2015年的16%增长至2023年的23%。此外,在2020年国务院颁布的《新时期促进集成电路产业和软件产业高质量发展的若干政策》中,明确提出2025年芯片自给率目标为70%,国产芯片未来增长空间可观。
然而,高端芯片的技术壁垒急需攻破,英伟达等国外厂商在高端芯片技术上仍保持领先地位。将国产主流AI芯片与英伟达产品对比,可发现部分运算性能仍存在较大差距,例如H100芯片采用的4nm工艺国内尚未实现。国产芯片在运算性能、市场份额与生态建设仍需逐步提升。
2、产业链中游:AI基础设施厂商类型与商业模式
(1)厂商类型
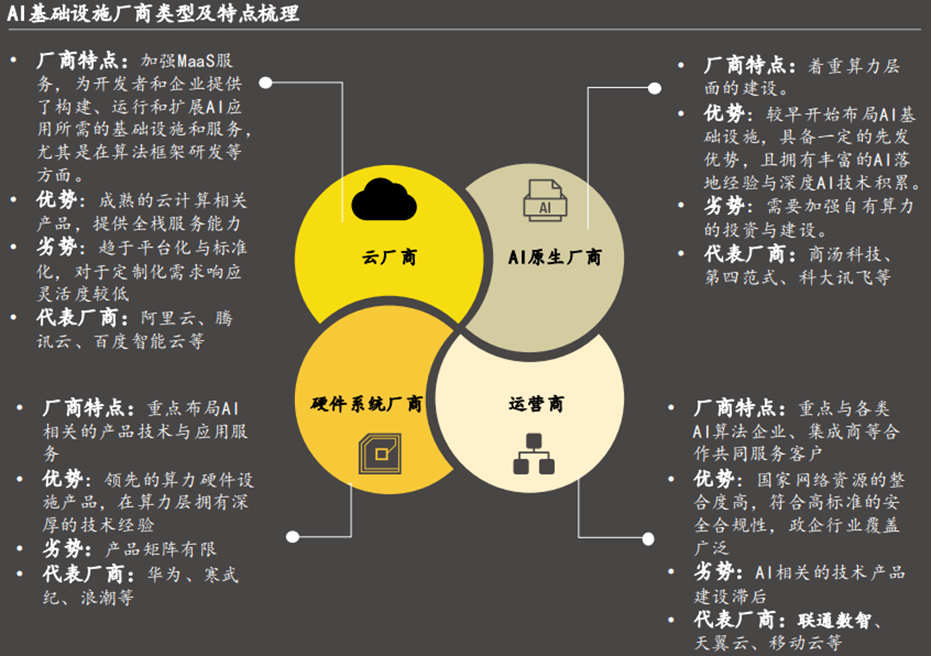
AI基础设施厂商指为AI技术开发、训练和部署等提供底层硬件、软件以及平台的企业,目前主流AI基础设施厂商可分为云厂商、AI原生、硬件系统厂商以及运营商。云计算、AI原生、硬件系统与运营商四类主要厂商塑造AI基础设施市场格局,提供全栈服务能力的云计算、提供垂直一体化解决方案的AI原生、提供高效硬件支持的硬件系统厂商与整合网络资源的运营商共同推动AI基础设施行业生态完善与技术演进。
云计算厂商:头部云厂商具备完善的全栈服务能力、庞大的开发者生态与客户基础以及丰富的C端产品经验与技术。以阿里云、腾讯云为例的该类厂商在技术创新、算法研发与平台支持层面起到关键作用。
AI原生厂商:较早开始布局AI技术与产品,具备深厚的AI算法沉淀。以商汤科技为例的该类厂商在端到端的垂直一体化解决方案以及长尾场景下的定制化能力具备优势。
硬件系统厂商:专注于开发和提供以GPU、服务器等处理AI任务的硬件设备以提升AI任务处理效率。以华为等为例的该类厂商具备领先的硬件设计能力,在为各类AI任务提供高效计算能力层面至关重要。
运营商:覆盖广泛的网络资源与政企相关渠道,提供符合最高标准的安全合规性产品。以中国移动等为例的该类厂商通过与AI产业链其他玩家合作共同服务企业客户,提供“AI DICT”解决方案。
(2)商业模式
AI基础设商业模式根据资产所有权与控制权可分为重资产、轻资产以及混合模式三种主要模式。其中混合模式凭借“核心自控 外部弹性扩展”的灵活性优势,符合大多数企业和场景的现实选择,愈发成为明显的未来趋势。
重资产:该模式的核心为规模化的硬件投入和基础设施建设,为企业客户提供稳定且高性能的算力资源。然后完全自建算力中心对多数企业而言经济负担大且具备较高的技术迭代风险和运维难度。
轻资产:该模式的核心在于通过软件、平台等自身不持有大量物理资产,更聚焦于软件的敏捷开发和生态构建。然而对于企业用户的数据控制和管理能力相对较弱且对厂商具备较高的依赖性。
混合模式:核心在于结合前两种模式的优势,既拥有部分核心资产以保证关键服务的可控性,又通过合作、租赁等轻量合作模式保持其灵活性,加强了企业用户对复杂场景需求的适应性。

3、产业链下游:应用情况
在面向行业的具体落地过程中,AI基础设施结合不同行业的业务特性,提供适配的部署模式、资源配置和技术能力,满足从算力管理到AI应用落地的全流程需求。AI基础设施基于行业性AI业务和应用需求视角,具备云边一体的算力池化、调度与管理能力,云原生的应用开发、运维,全链路的湖仓一体、向量数据检索能力,一体化的训推框架、训推加速能力,以及体系化的基础云安全、模型安全和数据安全。在交通出行行业,AI基础设施通过云边端协同架构,实现车路协同、多模态感知等关键能力,推动智能出行与交通管理革新;在工业制造领域,依托实时数据处理与分布式算力,优化生产全流程,实现柔性制造与供应链智能决策;教育行业则借助训练加速、向量数据库等技术,构建个性化学习与智能教学新范式;泛互联网与IT服务依赖其高并发支撑与敏捷扩展能力,保障业务快速迭代;具身智能通过多模态融合与云边端协同,赋予机器人精准感知与实时决策能力;而医疗行业则基于高性能算力与隐私计算,推动AI诊疗、精准药物研发等场景落地。
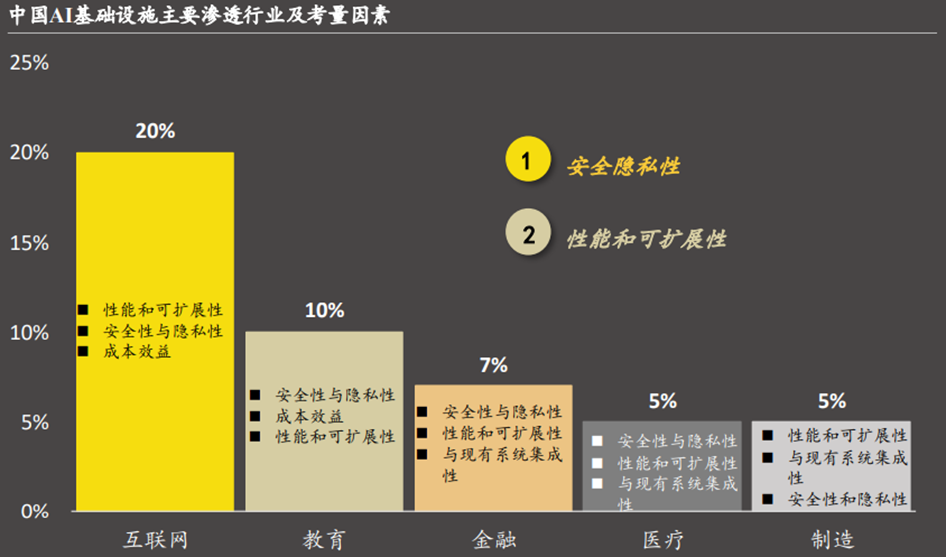
应用行业考量因素:在渗透率较高的行业中,安全隐私性成为了诸多用户的首要考虑条件,尤其在金融与医疗等监管严格的行业,大量的数据(包括交易数据、病患信息等)需得到妥善的保护,因此该类行业用户对于AI基础设施的风险实时监测等能力有较大需求。而互联网与制造业由于场景复杂,对于高性能与可扩展性有着迫切需求。此外,不同的解决方案部署方式以及AI应用成熟度也对各行业优先考量条件产生一定影响。
04
AI Infra硬件
1、计算效率和互联带宽是AI芯片升级的重要方向
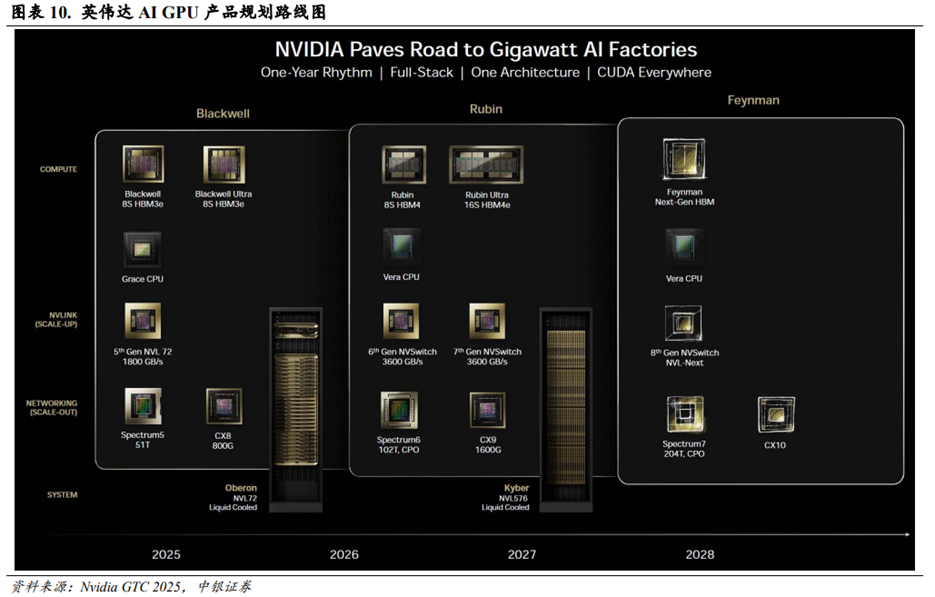
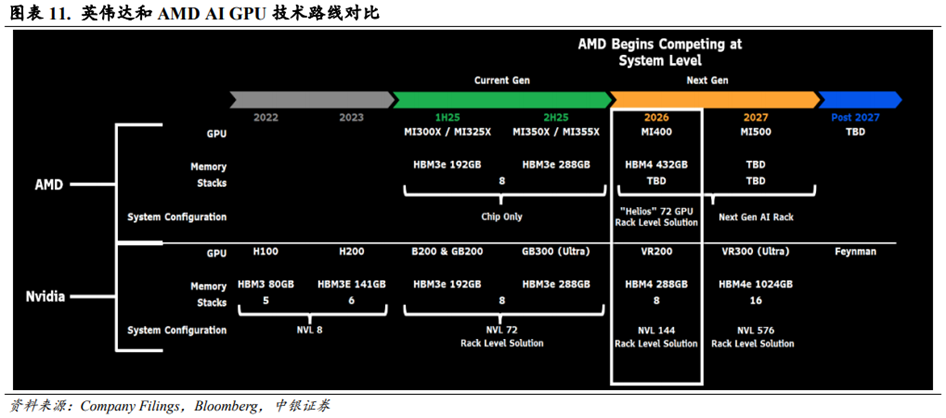
GPU/ASIC的计算效率和Switch的互联带宽是两大重要升级方向。根据英伟达在GTC2025大会上披露的产品规划,英伟达将在2025/2026/2027/2028年推出Blackwell Ultra 8S HBM3e/Rubin8S HBM4/Rubin Ultra 16S HBM4e/FeymanNext-Gen HBM解决方案。其中Blackwell Ultra NVL72算力达到1.1EFDenseFP4Inference/0.36EF FP8 Training,整体是GB200NVL72的1.5倍;Vera RubinNVL144算力达到3.6EFFP4Inference/1.2EF FP8 Training,整体是GB300NVL72的3.3倍;Rubin Ultra NVL576算力达到15EF FP4Inference/5EF FP8 Training,整体是GB300NVL72的14倍。同时6thGen NVSwitch和7thGenNVSwitch速率也将达到3,600GB/s,是5th Gen NVSwitch速率的2倍。随着链式推理(Chain of Thought)生成的Tokens快速增长,为了提高结果的准确性,英伟达积极推动GPU计算效率和Switch互联带宽的升级。

根据财联社2025年9月10日报道,英伟达宣布推出专为长上下文工作负载设计的专用GPU Rubin CPX,对应的AI服务器Vera Rubin NVL144CPX共集成36颗VeraCPU、144颗Rubin GPU和144颗Rubin CPX GPU。英伟达计划以两种形式提供Rubin CPX,第一种是和Vera Rubin装配在同一个Compute Tray上,第二种是独立以整个机架的CPX解决方案提供给客户,数量正好匹配Rubin机架。英伟达分析称,推理过程包括上下文阶段和生成阶段,Rubin CPX针对“数百万tokens”级别的长上下文性能进行优化,具备30PFlops的NVFP4算力和128GB GDDR7内存。Vera Rubin NVL144CPX机架处理长上下文的性能相较于GB300 NVL72高出最多6.5倍。

根据华尔街见闻和新浪财经报道,在2025年第二次GTC大会上,英伟达宣布Hopper芯片在其生命周期内共出货了400万颗,预计Blackwell芯片出货量将达到2,000万颗,预计Rubin GPU将在2026年10月量产。英伟达预计Blackwell和Rubin芯片将带来五个季度共计5,000亿美元的营收。
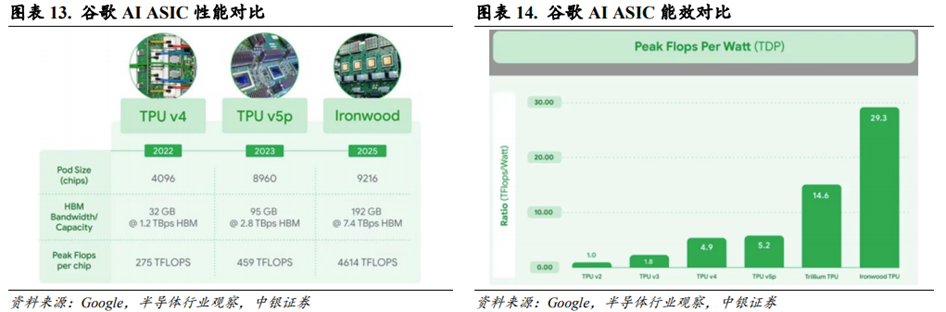
GPU/ASIC厂商均在积极提高芯片算力效率。根据IT之家报道,AMD在其2025年年度人工智能直播活动Advancing AI 2025上正式发布MI350X和MI355X的解决方案。根据Bloomberg信息,AMD预计将在2026年推出MI400及其相关的“Helios”72GPU Rack级解决方案,以应对英伟达的竞争。Amazon、Google、Microsoft、Meta、OpenAI等云厂商亦在积极联合第三方设计公司推出自研AI ASIC以应对英伟达的竞争。根据半导体行业观察报道,谷歌在Google Cloud Next25大会上推出第七代张量处理单元(TPU)Ironwood,Ironwood提供256颗芯片和9,216颗芯片两种配置,后者总算力达42.5EFlops,单芯片峰值算力4.614EFlops,功率效率是Trillium的1.5倍,每瓦性能翻倍,较首代TPU提升30倍。
ASIC厂商或迎来第三方市场加速发展机遇。根据智东西2025年10月24日报道,谷歌宣布将向Anthropic供应100多万颗TPU芯片以及附加的谷歌云服务,交易价值数百亿美元。谷歌在声明中称,这是Anthropic迄今为止规模最大的TPU扩容计划。至此,Anthropic已经和英伟达、谷歌、亚马逊三大芯片供应商达成合作。根据财联社2025年11月25日报道,Meta Platforms正在考虑斥资数十亿美元采购谷歌TPU芯片,包括用于Meta的数据中心建设。

机架级互连(Rack Level Interconnects)对AI性能有重要影响。根据Nilesh Shah Zero Point Technologies&Rohit Mittal Auradine《Optimizing Foundational Models:Hardware-Accelerated Memory Compression&Interconnects》数据分析,英伟达B200芯片性能是H100的2倍左右,而GB200 NVL72Rack性能是DGX H100 Rack的30倍左右。互联技术和纵向扩展网络(Scale-up Networking)是实现这种性能增益的关键因素。能够认为目前AI Infra升级方向不仅仅局限于AI芯片计算性能的提升,也对高带宽的互连技术提出了更高的要求。
综合来看,AI GPU和AI ASIC的发展趋势都是向更大的diesize、更高的计算效率、更大的互联带宽升级。这也对PCB及其相关材料提出了更高的要求。

2、PCB技术迭代对层数、线宽/线距、制造工艺提出了更高的要求
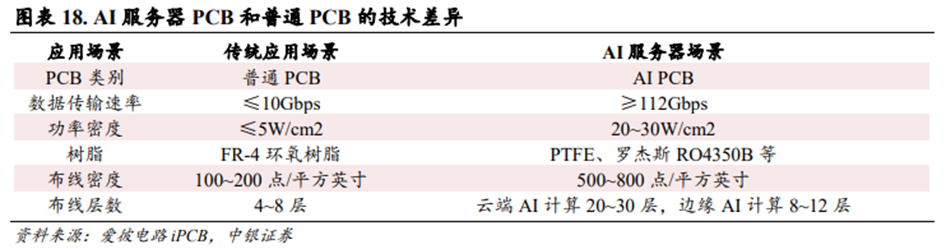
PCB(Printed Circuit Board,印制电路板)是为电子元器件提供机械支撑和电气连接的重要部件。随着行业对算力的极致追求,PCB也在向着更多的层数、更小的线宽/线距、更高的制造工艺升级。
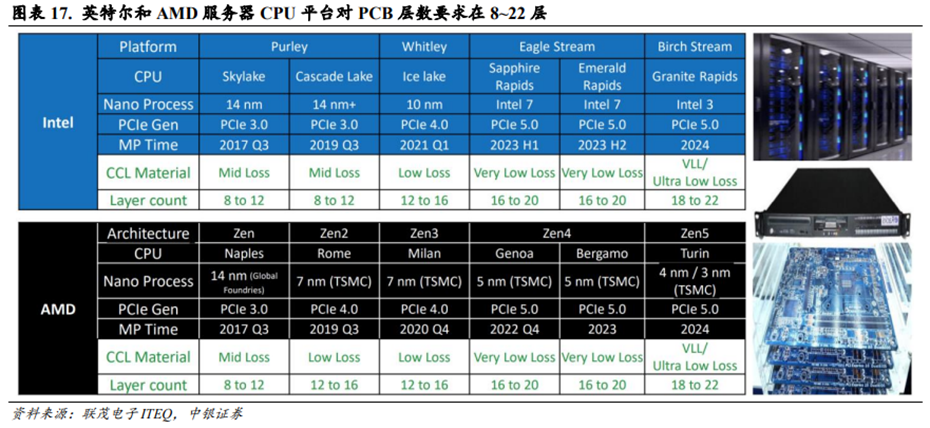
AI服务器的PCB层数相较于传统服务器有显著升级。相较于传统服务器,AI服务器新增了GPU板组,而GPU对连接带宽要求更高,进而对PCB提出了更高的要求。同时交换机所承载的总带宽大小也是影响PCB性能的关键。传统服务器CPU平台对PCB层数要求通常在8~22层。根据联茂电子ITEQ数据,英特尔服务器CPU平台从Skylake升级到Granite Rapids,其对应的PCB层数亦从8~12层升级到18~22层;AMD服务器CPU平台从Naples升级到Turin,其对应的PCB层数亦从8~12层升级到18~22层。根据爱彼电路数据,AI服务器在面向云端AI计算等场景对PCB层数要求通常在20~30层。
根据福邦投顾数据,OAI-OAM(主板)承担搭载GPU/ASIC模组的功能,通常采用四阶及以上的HDI,其PCB层数约为20~30层;OAI-UBB(主板)承担搭载8颗加速卡模组和连接网络拓扑的功能,通常采用多层板或一阶HDI,其PCB层数约为20~40层及以上;OAI-HIB(副板)承担连接GPU、CPU、DPU等芯片的功能,通常采用多层板,其PCB层数约为20~30层;MotherBoard(副板)承担搭载CPU、存储等元件的功能,通常采用多层板,其PCB层数约为16~26层。

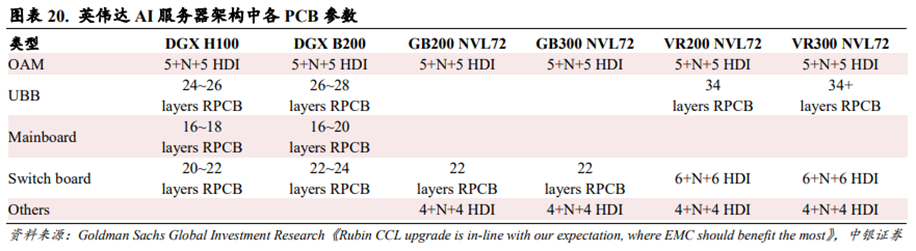
英伟达AI服务器PCB层数持续增长。根据Goldman Sachs Global Investment Researchs数据,英伟达AI服务器从Hopper向Balckwell再向Rubin架构升级的过程中,其OAM保持五阶HDI的参数配置,UBB从24~26层多层板向34层及以上多层板升级,Switch board从20~22层多层板向六阶HDI升级,整体PCB层数呈现增长趋势。
相较于标准PCB,AI服务器PCB线宽/线距更小。根据Kingbrother《AI Server PCB:How to Choose the Right Manufacturer for Data Centers》数据,标准PCB的线宽/线距通常在100μm及以上,AI服务器要求PCB的线宽/线距达到40μm及以下,需要以最小钻孔直径为0.06mm的激光钻孔为原型制作,通孔深宽比达到25:1。
英伟达RubinNVL576或采用正交背板。根据Serve The Home报道,英伟达在GTC2025大会上首次展示其Rubin NVL576机架(名为Kyber),其中计算节点和交换节点均采用竖插的方式,两者通过Midplane形成连接。根据福邦投顾数据,英伟达RubinNVL576后续有望采用正交背板(Midplane的变形)的解决方案,预计是78层(3×26L)或104层(4×26L)的设计 铜浆烧结或80 层的设计。
根据华为IP知识百科,正交架构是一种硬件结构。采用正交架构的设备背板无需走线,传输效率高,突破了传统背板架构的线路速率瓶颈。正交架构在可扩展性强、交换容量大的同时,保持了较小的信号衰减。

CoWoP技术有望成为AI服务器PCB的升级方向。根据SemiVision数据,英伟达在其最新的芯片封装技术路线图中引入CoWoP(Chip-on-Wafer-on-PCB,芯片-晶圆-印制电路板)概念。CoWoP技术去除了传统的ABF载板,将芯片和硅中介层模块直接贴装在高精度印制电路板(通常是类载板,即SLP,或Substrate-LikePCB)上,形成从芯片级到系统板级的直接连接。
CoWoP技术在降低信号传输损耗和热力学表现上有突出优势。CoWoP技术在理论上拥有两个关键优势:1)更短的信号路径和更低的插入损耗。这对于NVLink、PCIeGen6/7和HBM3/4等高速互联至关重要。2)更高的热学和力学灵活性。因为芯片裸片直接贴装在PCB上,这有助于直接接触式冷板或液冷解决方案的实施,尤其适合于解决千瓦级人工智能GPU的散热问题。
CoWoP技术对PCB的加工工艺提出了极高的要求。相较于现有的CoWoS和CoPoS技术,CoWoP面临的技术挑战包括:1)印制电路板精度要求较高。系统板必须承担封装载板的高密度布线功能,其线宽/线距(L/S)必须达到15~20μm甚至更低,同时保持严格的平整度和尺寸稳定性。2)热机械可靠性要求较高。由于热循环和热膨胀系数(CTE)不匹配,直接贴装在PCB表面的裸芯片和硅中介层可能面临更高的焊点疲劳和翘曲风险。3)制造和良率挑战。传统PCB工厂需升级至接近先进封装标准,配备ISO1~5级洁净室,且组装后的良率必须极高,缺陷容忍度极低。
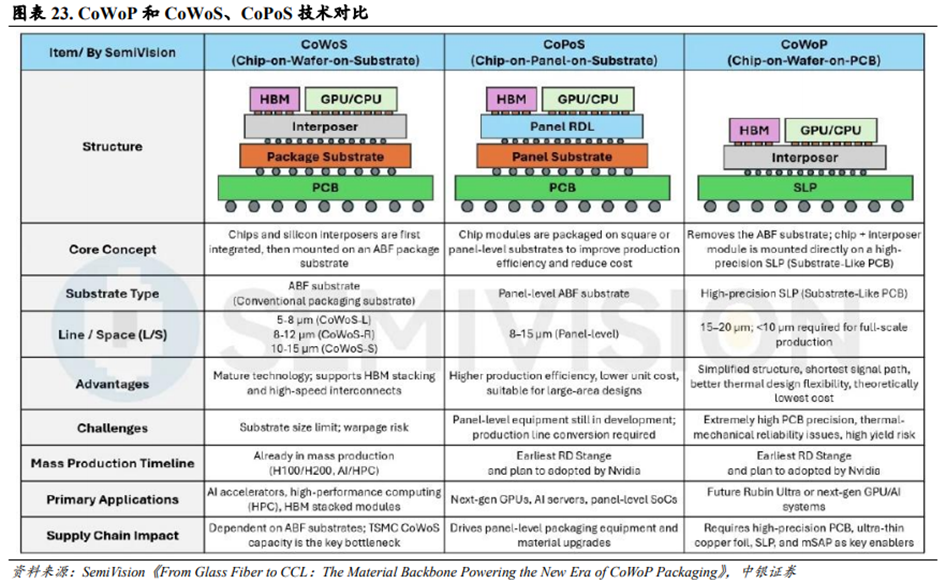
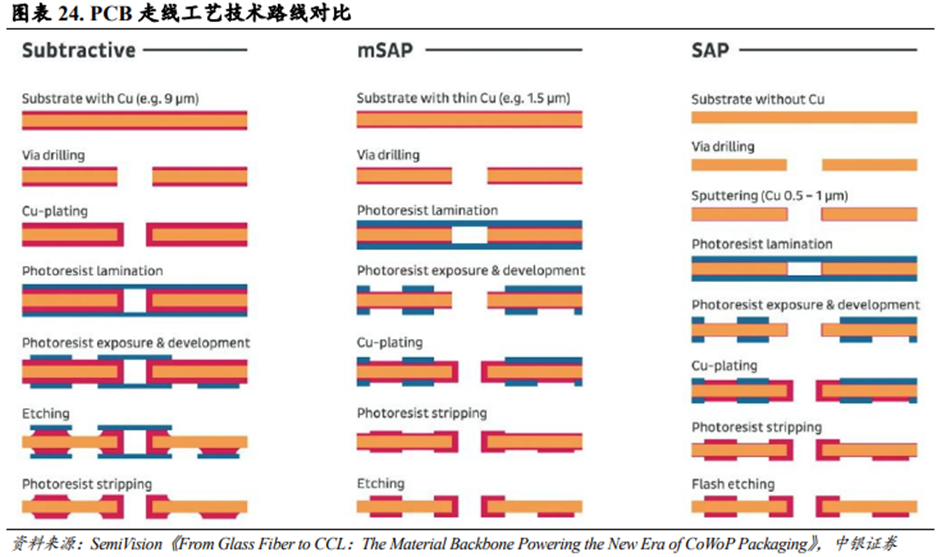
SAP和mSAP工艺可以实现较细的线宽/线距。类载板(SLP,Substrate-Like PCB)采用改良型半加成法(mSAP,Modified Semi-Additive Process),和传统减成蚀刻法相比,能够实现更细的线宽/线距。1)减成蚀刻法使用厚铜箔覆盖整个PCB表面,然后通过光刻胶、曝光和蚀刻等方式来制作线路。受蚀刻精度限制,该方法制作的PCB容易出现边缘粗糙问题。2)加成法是从PCB的绝缘基底开始,仅在需要的地方选择性镀铜或沉积铜。该方法制作的PCB可以实现极细的线路,但是生产成本较高,大规模生产效率较低。3)半加成法工艺(SAP/mSAP)从一层薄铜基底开始,确定图案,电镀线路,蚀刻掉多余的基底铜。该方法制作的PCB可以实现10μm级别的线宽/线距,且生产效率比全加成法更高。
SLP工艺在模块中已有成熟应用,但是CoWoP技术实现大规模商业化节点仍待观察。目前SLP工艺已经在英伟达的800G和1.6T光模块中有成熟应用,光模块的小尺寸外形和可控的翘曲度使SLP工艺落地切实可行。考虑到SLP工艺在大型GPU板卡的应用上面临显著的翘曲风险,CoWoP技术的成熟度还需要长期鉴定。从应用和时间线的角度来看,短期内CoWoP不太可能在人工智能加速器或图形处理器中实现大规模量产。虽然英伟达已经将CoWoP技术纳入Rubin Ultra平台的内部技术路线图中,以应对散热和翘曲问题,但是Rubin Ultra的大规模量产仍将依赖于CoPoS或其他成熟的过渡解决方案。CoPoS采用和CoWoS类似的工艺,但是方形面板级封装所需设备可能要到2026年底才能准备就绪。
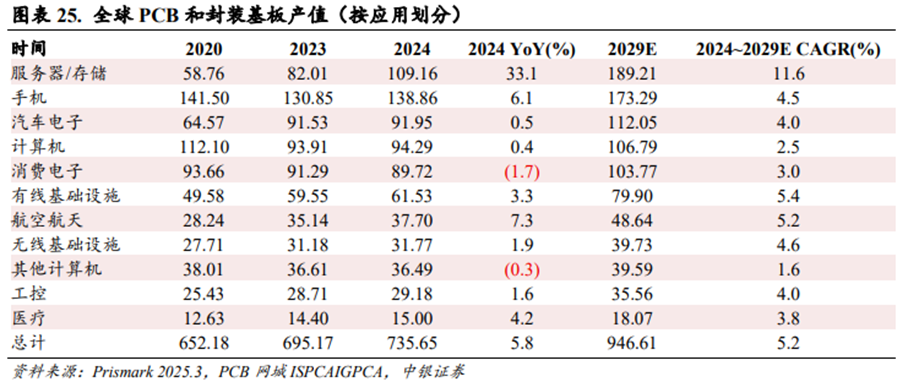
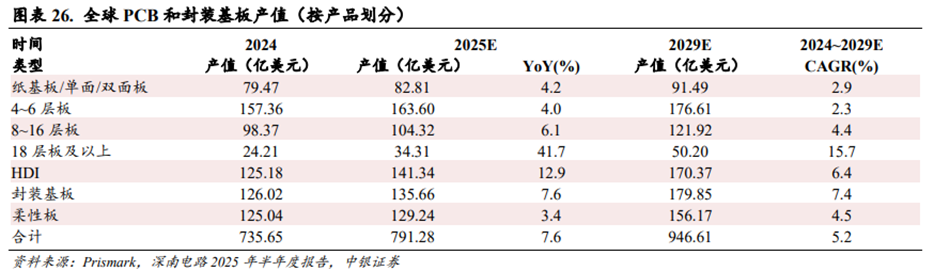
AI服务器PCB有望成为增长最快的子赛道。根据PCB网城ISPCAIGPCA援引Prismark数据,2024年全球电子产业增长略高于长期平均水平,预估整体规模达到2.54万亿美元,同比增长4.6%,这主要得益于服务器市场前所未有的强劲表现。由于AI服务器和相关的高速网络基础设施的需求攀升,2024年用于服务器和存储的PCB和封装基板产值达到109.16亿美元,同比增长33.1%。
18层及以上多层板、HDI、封装基板有望成为增长前三快的PCB细分板块。根据深南电路2025年半年报援引Prismark数据,2024~2029年PCB各细分产品预计将实现不同幅度的增长。2025年18层以上多层板产值预计将达到34.31亿美元,同比增长41.7%;2024~2029年18层及以上多层板产值预计将从24.21亿美元增长至50.20亿美元,CAGR达到约15.7%,是增长最快的PCB细分产品。2025年封装基板产值预计将达到135.66亿美元,同比增长7.6%;2024~2029年封装基板产值预计将从126.02亿美元增长至179.85亿美元,CAGR达到约7.4%,是增长第二快的PCB细分产品。2025年HDI板产值预计将达到141.34亿美元,同比增长12.9%;2024~2029年HDI板产值预计将从125.18亿美元增长至170.37亿美元,CAGR达到约6.4%,是增长第三快的PCB细分产品。
尽管18层及以上多层板市场规模绝对值在PCB细分产品中较小,但是AI服务器和数据中心网络对18层及以上多层板有较强需求,推动该领域市场规模增速较快。HDI面向智能手机领域的需求增长并不大,但是面向AI服务器、数据中心网络、卫星通信、汽车电子的需求增长较快,亦驱动HDI市场规模增速较快。封装基板市场主要受益于AI高阶算力和存储需求的增长。
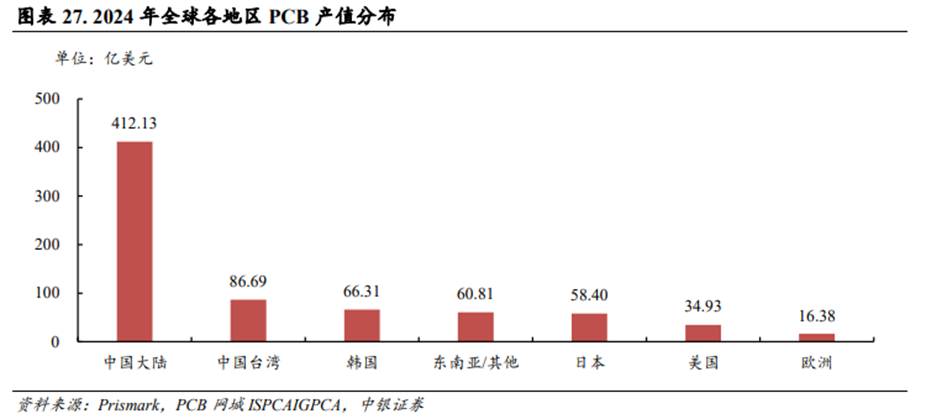
中国大陆深度参与全球PCB供应链,亦有望深度受益于AI Infra带动的PCB升级浪潮。根据PCB网城ISPCAIGPCA援引Prismark数据,2024年全球PCB产值预计达到735.65亿美元,其中中国大陆PCB产值达到412.13亿美元,占全球比例约56.0%;中国台湾PCB产值达到86.69亿美元,占全球比例约11.8%;韩国PCB产值达到66.31亿美元,占全球比例约9.0%;东南亚和亚洲其他地区PCB产值达到60.81亿美元,占全球比例约8.3%。综合来看,中国大陆贡献全球PCB产值超过一半以上,预计中国大陆的PCB厂商亦会深度受益于AI Infra带动的PCB升级浪潮。
3、AI INFRA聚焦低介电性能,PCB材料全面升级
Dk值和Df值是衡量PCB及相关材料电性能的关键指标。AI Infra通常需要配备高阶HDI和18层及以上的高多层PCB,通常这些PCB产品层数较多且单层厚度较薄、线宽线距较小。PCB层数厚度较薄且线宽线距较小会导致信号干扰、电气性能损失和散热性能下降等问题。在这种情况下,系统设计更强调选用具有低介电常数(Low-Dk)和低介电损耗(Low-Df)的PCB材料,这对于降低信道损耗和保持信号完整性至关重要。因为高速传输损耗的来源主要是介质损耗和导体损耗,所以基板材料的特性直接决定了数据能否在极高频率下可靠传输。
印制电路板产业链较长,上游主要为原材料环节,包括电解铜箔、电子级玻纤布、合成树脂、木浆纸等;中游为制造环节,包括覆铜板、半固化片、油墨、刻蚀液、镀铜液等原材料以及印制电路板PCB的生产制造;下游为应用环节,包括通信设备、半导体、消费电子、航空航空、计算机等各个领域的应用。
(1)覆铜板
覆铜板(Copper Clad Laminate,CCL)是电子工业中用于制造印制电路板的核心基材,其基本结构由铜箔和粘合剂构成,其中基板采用高分子合成树脂和增强材料(玻纤布)复合而成,表面覆盖有导电性能的铜箔。覆铜板是电子元器件安装焊接的载体,通过层压工艺将导电层和绝缘基材结合,广泛应用于通讯设备、计算机、汽车电子等领域。
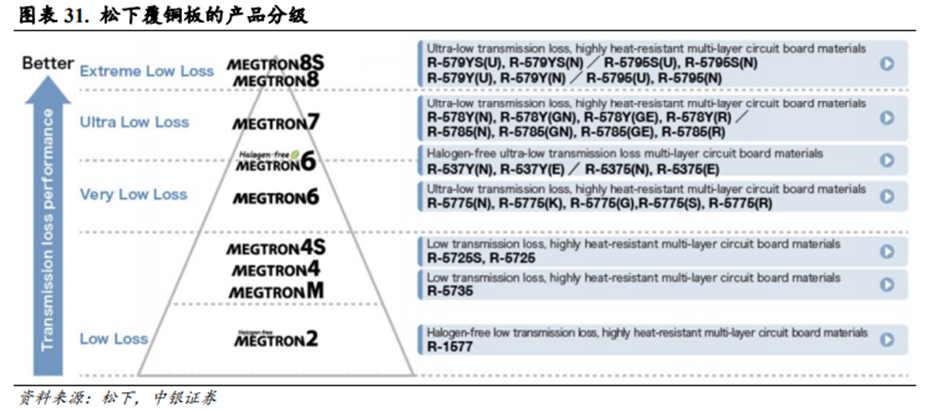
根据Df数值大小,覆铜板分为M1-M9等不同等级。M8及以上级别覆铜板更适合作为高性能芯片的基材。根据思瀚产业研究院信息,英伟达GB系列超级芯片拥有高速数据传输能力,这对覆铜板的电性能有较高要求。覆铜板必须具有极低的介电常数和介电损耗因子才能保证GB系列芯片的高性能使用。目前在覆铜板行业内,松下电工的MEGTRON系列是高频高速覆铜板领域的分级标杆。松下电工历年发布的不同代MEGTRON高速覆铜板都会成为覆铜板行业内其他厂商发布基本技术等级处于同一水平的对标产品。松下电工最新的覆铜板产品是MEGTRON8和MEGTRON8S,其介电损耗因子Df基本都小于0.002。其中MEGTRON8S系列覆铜板在28GHz的条件下,传输损耗相比于M7减少了30%,更适合作为高性能芯片的覆铜板硬件材料。
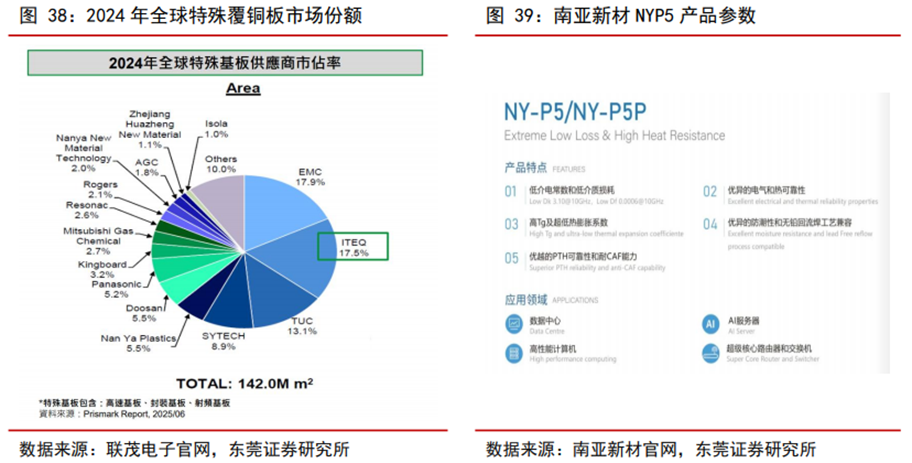
台系占据高端覆铜板主要份额,陆系企业积极突破有望迎发展机遇。2024年全球特殊覆铜板市场份额前三均为台系企业,分别为台光电子、联茂电子、台燿科技,市场份额约为17.9%、17.5%和13.1%。内资企业生益科技、南亚新材、华正新材则积极突破,市场份额分别为8.9%、2.0%和1.1%。其中生益科技方面,根据《生益科技:2025年半年度业绩说明会》,公司有全系列高速覆铜板,有不同等级高速覆铜板应用在不同传输速率的产品,可以满足服务器、数据中心、交换机、光模块等应用领域的需求,极低损耗产品已通过多家国内及海外终端客户的材料认证,并已有产品在批量供应。南亚新材方面,公司M8材料已获得国内多家重要终端认证,现已实现小订单批量生产,在高阶产品上如AI服务器、交换机、光模块等领域得到应用;M9材料目前正在多家PCB客户测试中,积极向多家国内外终端推广认证。
(2)铜箔
HVLP4需求有望快速释放,2026年供需缺口或加大。覆铜板主要由铜箔、树脂、玻纤等原材料构成,成本占比分别为42%、26%和19%,材料选择将直接影响覆铜板的性能。铜箔方面,按粗糙度不同,电子电路铜箔主要分为高温高延伸铜箔(HTE)、低轮廓铜箔(LP)、翻转铜箔(RTF)、超低轮廓铜箔(VLP)、高频超低轮廓铜箔(HVLP)。由于铜箔在信号传输中存在趋肤效应,若铜箔粗糙度过高,需要传输的路径越长,将会造成数据损耗增加,影响信号完整性。因此高速电路一般需要搭载粗糙度(Rz)更低的铜箔,如VLP、HVLP铜箔。HVLP按照粗糙度不同,又可以进一步分为HVLP1-HVLP5,其中HVLP4的Rz仅为0.5μm。随着AI算力硬件加大对更高等级覆铜板材料的应用,HVLP4需求有望快速释放。据SemiAnalysis测算,2026Q1全球HVLP4需求约为592吨/月,Q4将进一步增长至1,441吨/月,而2026Q1-Q4供应分别为600、600、950、950吨/月,供需缺口较大,产品价格有望进一步走高。
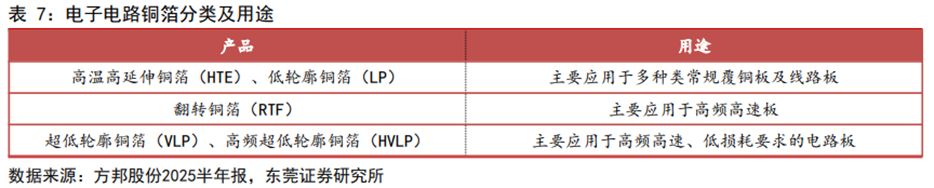
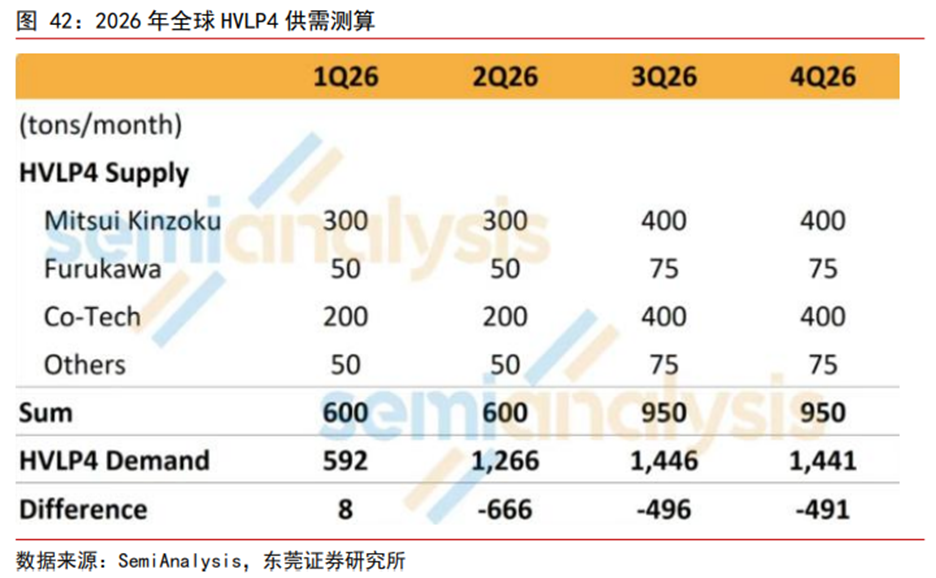
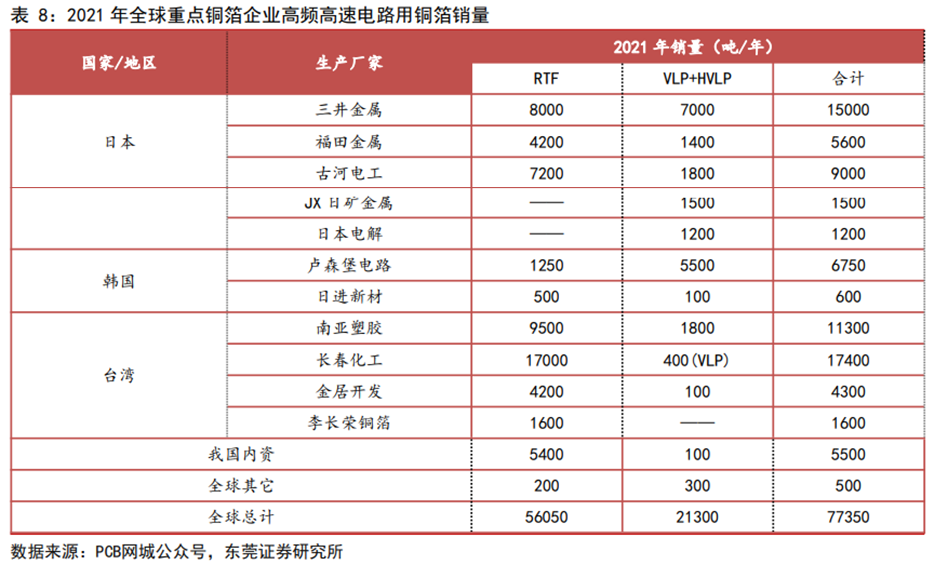
日系企业把握高端产能,内资企业进一步突破。2021年全球VLP及HVLP等高端铜箔销量约为2.13万吨,日系企业占据1.29万吨,占比高达60.56%,其中日本三井金属以7,000吨销量排第一。国内企业德福科技拟收购的卢森堡电路以5,500吨销量排名第二,卢森堡电路在2020年和2021年分别研发出HVLP4及HVLP5,技术实力领先,相关产品已经获得全球前四家覆铜板企业供货资质;此外公司本部HVLP1及HVLP2已经实现小批量供货,主要用于AI服务器、400G/800G光模块领域,HVLP3通过日系覆铜板企业认证,应用于国内算力板项目,下半年有望放量。此外,国内的铜冠铜箔HVLP1-3产品已向客户批量供货,HVLP4铜箔处于下游客户认证过程中。
(3)玻纤布
电子玻纤布是覆铜板的增强材料,是决定覆铜板介电性能的核心材料之一。电子布按玻璃纤维成分可以分为E玻纤(E-Glass)、D玻纤(D-Glass)、NE玻纤(NE-Glass)、L玻纤(L-Glass)和石英纤维布(Quartz Fiber)等。玻纤材料内部成分的构成决定了其介电性能的表现。
石英纤维是综合性能最优异的电子布增强材料之一。E玻纤是经典的传统电子玻璃纤维材料,在1MHz下的介电损耗(Df)为0.0060。D玻纤相较于E玻纤拥有更好的介电损耗(Df)和更低的热膨胀系数(CTE),但是存在可制造性问题和成品的性能缺陷问题。NE玻纤和L玻纤是基于D玻纤开发的产品,性能有进一步提升,但是同样存在可制造性问题。石英纤维布的二氧化硅含量达到99.999%,其在1MHz下的介电损耗仅为0.0001,其热膨胀系数(CTE)仅为0.54ppm/℃,两大关键性能指标均远低于E玻纤、D玻纤、NE玻纤和L玻纤。
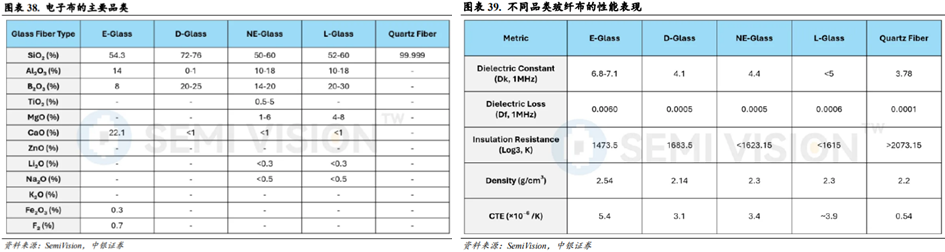
根据日东纺披露的产品路线规划图,其规划有NE、NER、NEZ、DXII、T、V玻纤,其中NE为第一代低介电常数电子布(Low-Dk一代布),NER为第二代低介电常数电子布(Low-Dk二代布),T为低热膨胀系数电子布(Low-CTE布)。在算力时代,AI服务器和AI终端产品均对芯片材料提出了更高的性能要求。低介电常数电子布(Low-DK一代布和二代布)主要应用于主板基板,低热膨胀系数电子布(Low-CTE布)主要应用于芯片封装基板。随着AI需求的快速增长,低介电常数电子布和低热膨胀系数电子布需求也快速增长。展望未来,5G millimeter wave、1.6T Switches、PCIe6.0、100Gbps及以上AI Server等应用领域均对电子布介电损耗性能要求更进一步。日东纺预计将在2026~2028年推出NEZ电子布(下一代超低介电常数电子布,Low-DK三代布)来满足未来技术发展的需求。石英纤维布有望凭借超低的介电常数和超低的热膨胀系数性能,成为下一代超低介电常数电子布的重要材料之一。
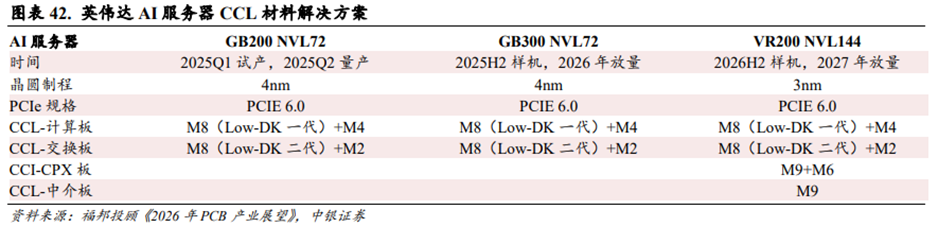
石英纤维布有望成为Rubin和Rubin Ultra服务器CPX/Midplane/正交背板的CCL材料核心解决方案之一。根据福邦投顾对供应链调研结果,AI服务器在进入224Gbps及以上的传输通道架构下,基于信号完整性考量,CCL基板需要从当前的M8规格升级至M8.5~M9规格。M8.5以Low-DK二代布 碳氢树脂解决方案为主,M9以石英纤维布解决方案为主。目前英伟达Rubin架构服务器中,CPX的基板和中介板(Midplane)基于信号传输距离因素会采用M9的石英纤维布解决方案,其余计算板(Compute Tray)和交换板(Switch Tray)会尽量考虑采用M8(Low-DK一代或二代)的解决方案。Rubin Ultra的正交背板预计会采用M9的石英纤维布解决方案。ASIC架构在成本效益和供给考量下会采用M8.5(Low-DK二代)的解决方案。
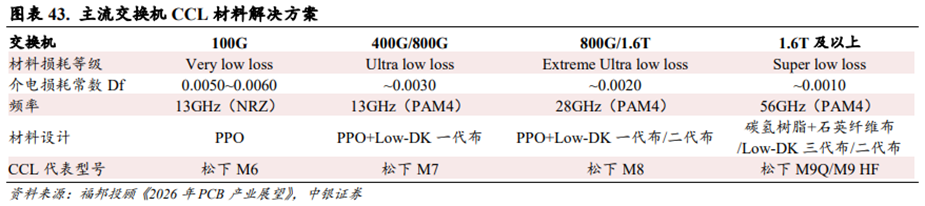
石英纤维布有望成为1.6T及以上交换机的CCL材料核心解决方案之一。根据福邦投顾对供应链调研结果,交换机在升级过程中,基于高速传输需求,其对信号传输损耗性能要求也愈高。预计1.6T及以上规格的交换机将会采用松下M9的CCL,并搭配石英纤维布解决方案。
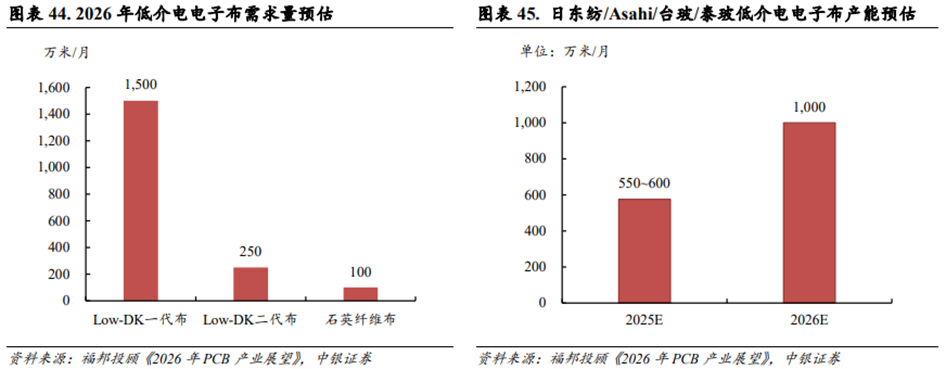
中国大陆的低介电电子布厂商有望参与到供应链中。根据福邦投顾对供应链调研结果,预计2026年全球Low-Dk一代布需求量约1,500万米/月;Low-Dk二代布需求量约250万米/月;Low-DK三代布(石英纤维布)需求量约100万米/月。从供应端来看,2025主要厂商(日东纺/Asahi/台玻/泰玻)低介电电子布总产能约550~600万米/月,预计2026年将增长至1,000万米/月。主要厂商的低介电电子布产能和需求相比存在缺口,如果考虑良率对交期的影响则供给缺口问题更甚。这也为中国大陆的低介电电子布厂商带来了机会。
(4)树脂
电子树脂是覆铜板材料中唯一具有可设计性的有机物。电子树脂是指能满足电子行业对纯度、性能和稳定性要求的合成树脂,主要用途包括制作覆铜板、半导体封装材料、印制电路板油墨、电子胶等,主要承担绝缘和粘接的功能。其中生产覆铜板是电子树脂最主要的应用领域之一。在覆铜板生产领域,电子树脂是覆铜板材料中唯一具有可设计性的有机物。应用于覆铜板生产的电子树脂一般是指通过选择特定骨架结构的有机化合物(如四溴双酚A)和有反应活性官能团的单体(如环氧氯丙烷),经化学反应得到特定分子量范围的热固性树脂,是能够满足不同覆铜板所需要的物理化学特性需求的一类有机树脂材料。这些物理化学特性一般是指阻燃性、耐热性、耐湿热性、尺寸稳定性、介电特性和环保特性等性能,符合下游电子行业的要求。由于终端应用领域广泛,加之覆铜板性能主要通过电子树脂的特性予以实现,覆铜板生产厂商需要根据具体应用场景和下游客户的要求,选择相应功能的电子树脂,调整其用量和比例,形成适配的胶液配方。
覆铜板厂商会综合考量电子树脂的配方、成本和性价比。胶液配方并非仅包含单一种类电子树脂,而是由多种不同品类、不同特性的电子树脂按一定比例组合而成。因为配方中涉及的化合物繁多,且特性各异,混合后各组分间存在各种交叉反应,各种性能之间既可能相互促进,又可能相互抑制,因此组分的种类及比例的微小调整,均可能影响配方的性能表达。覆铜板生产厂商需要寻找最佳反应配比,以实现产品的最佳综合表现,同时还需考虑成本和性价比等因素以满足量产需求。
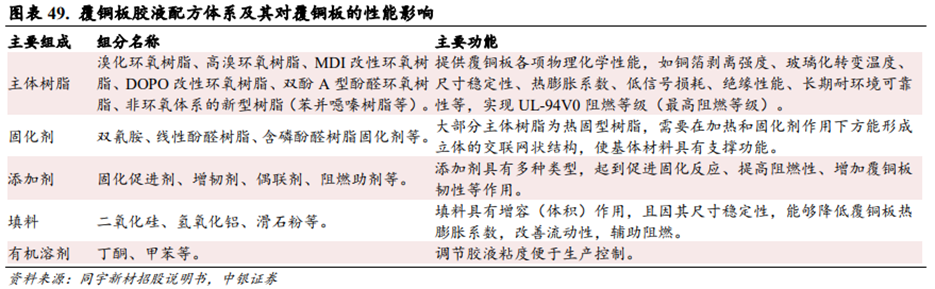
电子树脂特性对覆铜板CCL和印制电路板PCB的性能有关键影响。电子树脂的极性基团结构、固化方式影响覆铜板的铜箔剥离强度以及层间粘结力。电子树脂的高苯环密度以及高交联密度,有助于提升覆铜板的玻璃化转变温度、增强覆铜板尺寸稳定性、降低其热膨胀系数。电子树脂中溴类、磷类阻燃元素的含量越高,覆铜板的阻燃等级便越高。电子树脂的分子结构高度规整对称以及较低的极性基团含量,能有效降低覆铜板的电信号损耗,以适配高速高频通讯领域的应用场景。高纯度、低杂质的电子树脂能提升覆铜板的绝缘性能以及长期耐环境可靠性(如高温高湿)。

高频高速覆铜板驱动电子树脂向较少极性基团趋势发展。随着移动通信技术的发展,PCB行业对覆铜板的介电性能有着持续提升的要求。由于环氧树脂自身的分子构型和固化后含较多极性基团,对覆铜板的介电性能和信号损耗产生不利影响,因此,基于环氧树脂的覆铜板材料逐渐难以满足高频高速应用需求。经特殊设计,具有规整分子构型和固化后较少极性基团产生的苯并噁嗪树脂、马来酰亚胺树脂、官能化聚苯醚树脂等新型电子树脂应运而生,形成具备优异介电性能和PCB加工可靠性的材料体系。
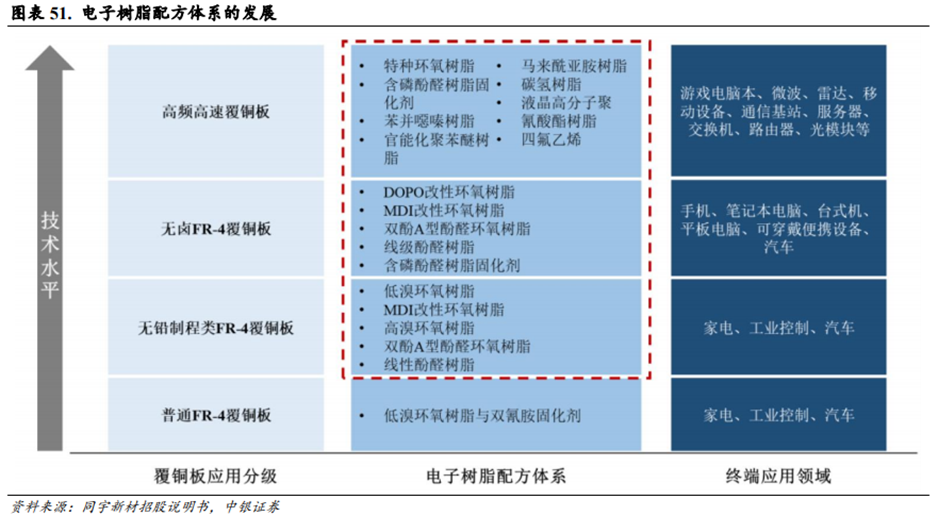
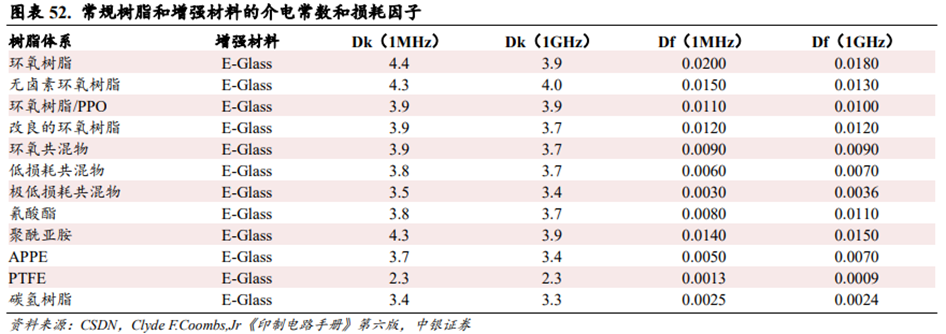
业内主流的电子树脂包括环氧树脂、聚苯醚树脂、双马来酰亚胺树脂、碳氢树脂、聚四氟乙烯树脂等,碳氢树脂和聚四氟乙烯树脂是高频高速树脂的热点发展方向。根据ClydeF.Coombs,Jr《印制电路手册》第六版数据,不同树脂搭配E-Glass在不同频段下呈现不同的介电性能表现,其中PCH树脂搭配E-Glass在1GHz频段下,介电常数Dk为3.3,介电损耗Df为0.0024;聚四氟乙烯树脂搭配E-Glass在1GHz频段下,介电常数Dk为2.3,介电损耗Df为0.0009。因此,碳氢树脂和聚四氟乙烯树脂均是目前在高频高速场景介电性能表现较为优异的材料。

05
AI Infra软件
AI Infra包含三类核心软件:1)算力管理层:主要提供计算、存储、网络、安全等基础资源和服务;2)模型管理层:提供模型开发和应用所需的各种基础工具和组件,主要包括数据治理、模型部署、训练、推理、精调、集成管理等;3)应用管理层:主要提供资源管理、运营管理、运维管理等运营能力。目前算力管理层占主导地位,2024年市场份额达64.6%,但应用管理层占比持续提升,反映出AI应用正从探索走向深度集成。
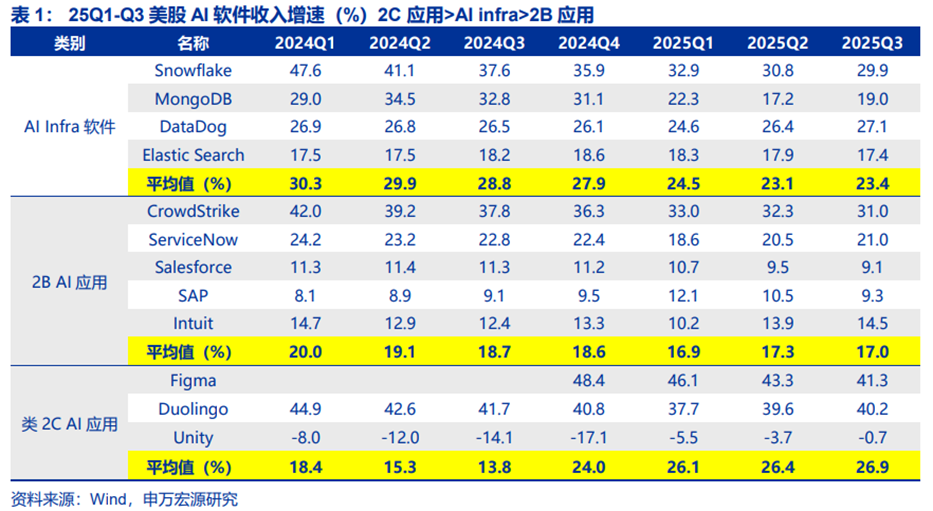
海外AI软件收入增速看,AI Infra软件公司收入增速平均值高于2B AI应用。因为AI投资遵循“算力-infra软件-应用”的顺序,Infra软件无论在模型训练、推理和AI应用部署中均有作用,但由于“Surrounded by Gs”,意为被巨头们(Google、GPT/openAI、GPU/Nvidia)包围,在训练占据主流时期,其商业机会暂未显现。2024H2模型推理量快速增加,部分领域AI应用也开始渗透,能够认为AI Infra软件的商业机会真正来临。
1、算力管理层:虚拟化与容器是核心技术
异构算力集群趋势下,算力管理和调度类的软件刚需性提升。当前国内模型厂商、云厂商等推理算力采用芯片较为多元,包括华为、寒武纪、海光信息等,一般会采用异构集群来支持。由于各芯片的底层指令集、硬件架构和软件栈均为自有,不互相兼容,在其上搭建一个软件隔绝硬件差异,就成为了推理服务和应用的刚需。
AI Infra算力管理层软件参与者主要为云厂商,如阿里云、华为云、火山引擎等自研,或者MaaS初创公司。
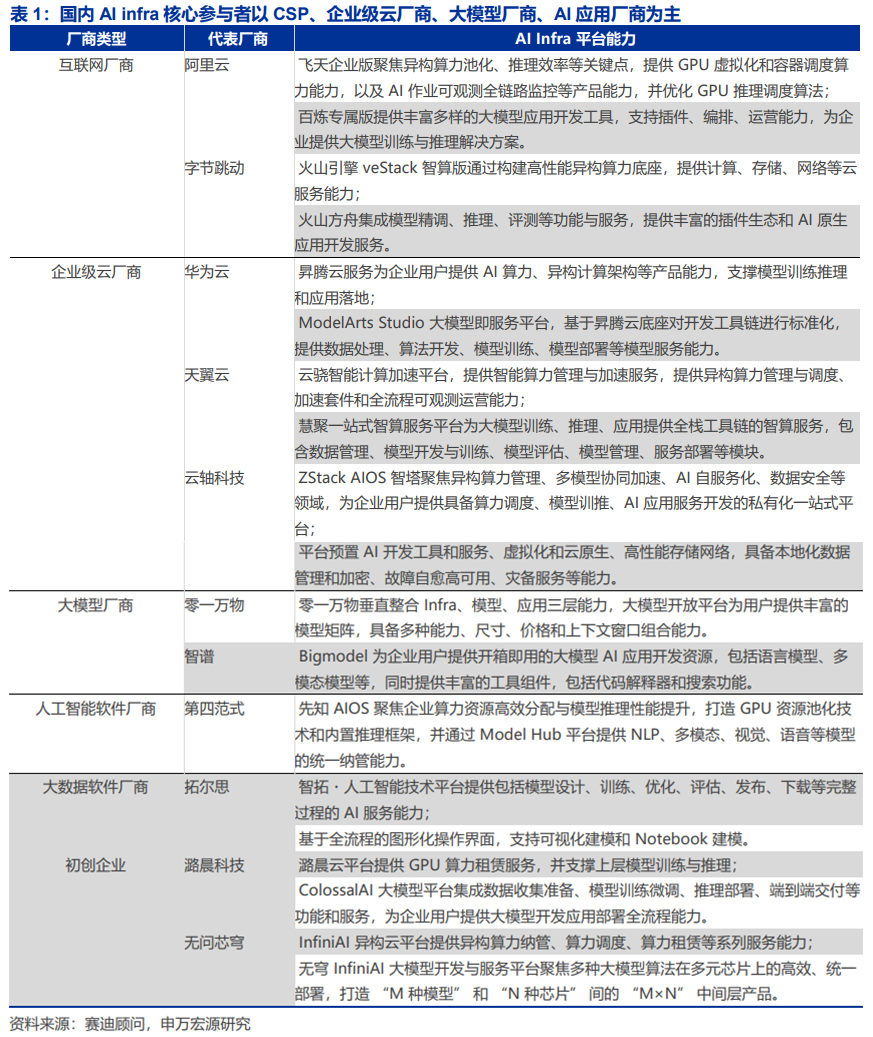
算力调度功能尤为重要。因为其影响着大模型厂商的成本,模型厂商需要投入百亿级美金资金规模在预训练算力上,1%的效率提升也意义显著。其次,大模型体系从芯片、云基础设施、框架到模型与应用之间存在极强的耦合度——不同厂商的芯片在设计模式、指令和调用方式上差异巨大,要想充分发挥性能,算子、框架乃至模型本身都必须深度感知底层拓扑。
Deepseek之后,性价比成为了国内模型的重要特性之一。在国内模型竞争背景下,Deepseek的较低定价,锚定了国内其他大模型的定价,使其始终存在降低成本的需求。因此在这种背景下,算力调度的能力成为大模型厂商、MaaS厂商盈利的关键。
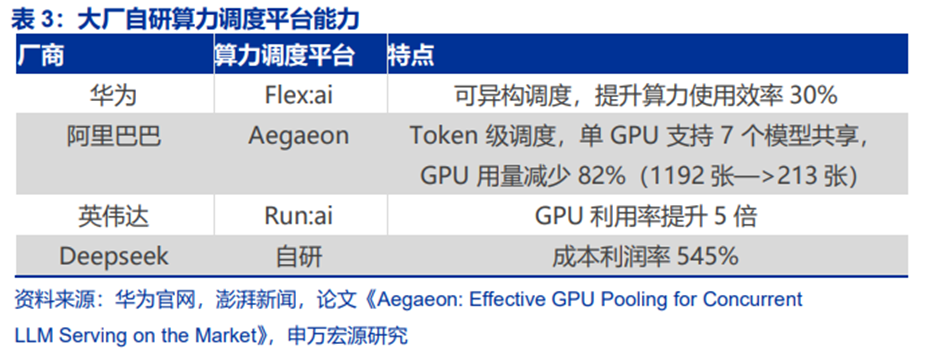
算力调度典型产品包括华为Flex:ai、阿里巴巴Aegaeon、字节跳动的Gödel资源管理和调度系统等。但不同厂商推出产品的目的有差异:
1)硬件厂如华为推出Flex:ai、英伟达推出Run:ai目的是强化自家硬件产品生态和粘性。
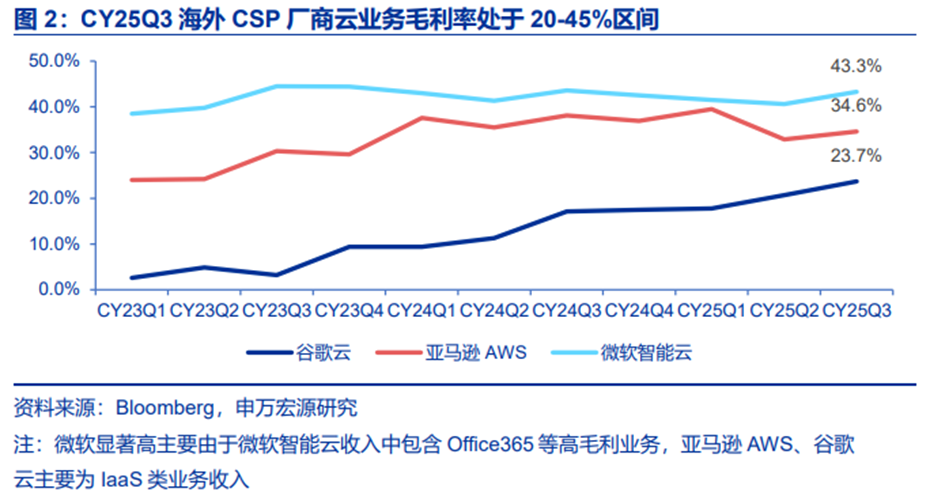
2)而阿里巴巴、字节跳动等则是①提升云用户体验;②降低成本,提升云业务利润率。
而实际上,海外大厂云业务的毛利率区间也较为宽泛,CY25Q3,微软、亚马逊、谷歌三大云厂云业务毛利率处于20%~45%区间。当前毛利率差异主要来自业务结构,但能够认为未来AI大模型云收入持续增加的过程中,硬件调度能力对其毛利率的影响至关重要。
25年11月华为正式发布并开源了创新AI容器技术Flex:ai,Flex:ai在发布后同步开源在魔擎社区中。华为Flex:ai是基于Kubernetes容器编排平台构建的XPU池化与调度软件。
Flex:ai能够实现异构算力的调度。英伟达、昇腾及其他第三方算力资源,Flex:ai都能够统一管理和高效利用,有效屏蔽不同算力硬件之间的差异。Flex:ai芯片级算力切分:华为Flex:ai将单张GPU/NPU算力卡切分为多份虚拟算力单元,切分粒度精准至10%,实现单卡同时承载多个AI工作负载,在无法充分利用整卡算力的AI工作负载场景下,算力资源平均利用率可提升30%。
阿里Aegaeon也是token级的“模型调度神器”。Aegaeon通过“token粒度的动态调度”,实现多模型共享GPU资源。传统多模型服务中,GPU资源要么被单个模型独占,要么在模型切换时产生巨大性能损耗。而Aegaeon创造性地将调度粒度从“模型级”下沉到“token级”(token是AI处理文本的基本单位),就像快递分拣系统从“按批次分拣”升级为“按单个包裹实时调度”。
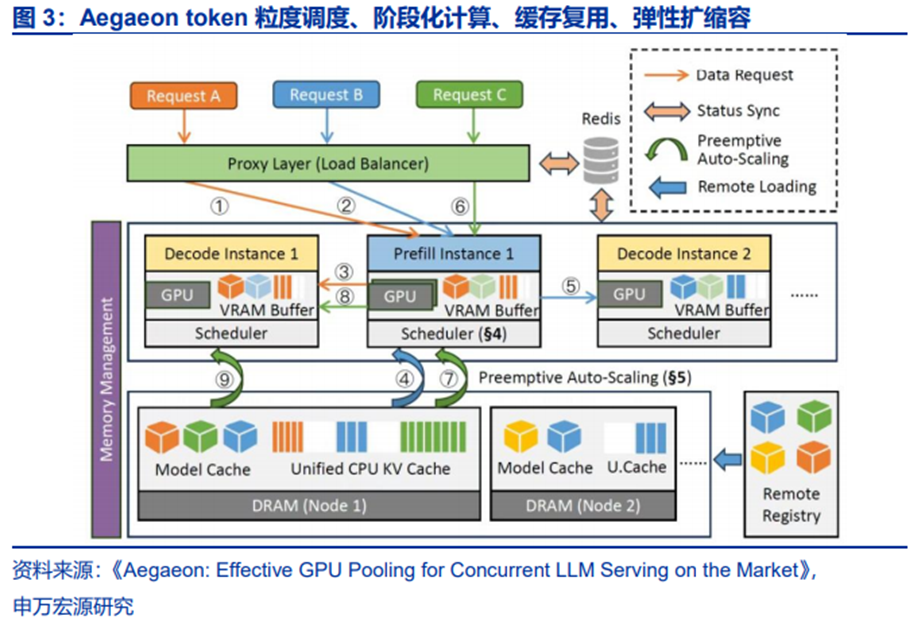
阿里Aegaeon将10个模型所需GPU数量从1192个锐减至213个,资源节约率高达82%。通过预加载模型参数、优化显存调度等技术,将模型切换开销降低,解决了精细调度带来的性能损耗问题。
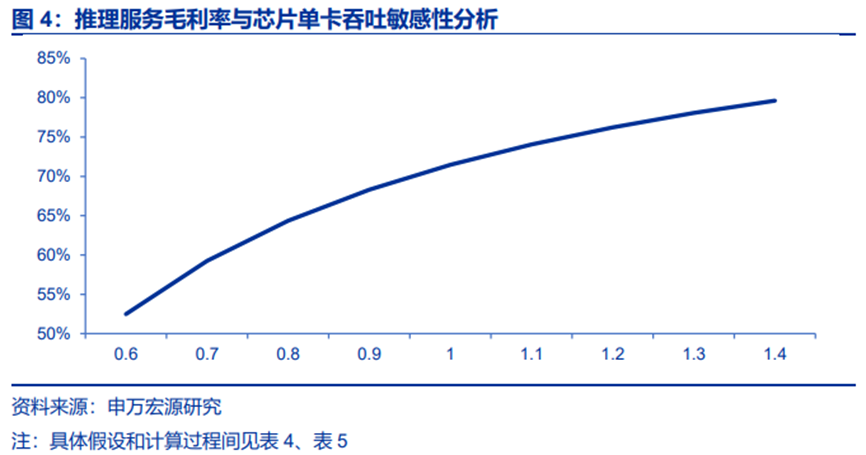
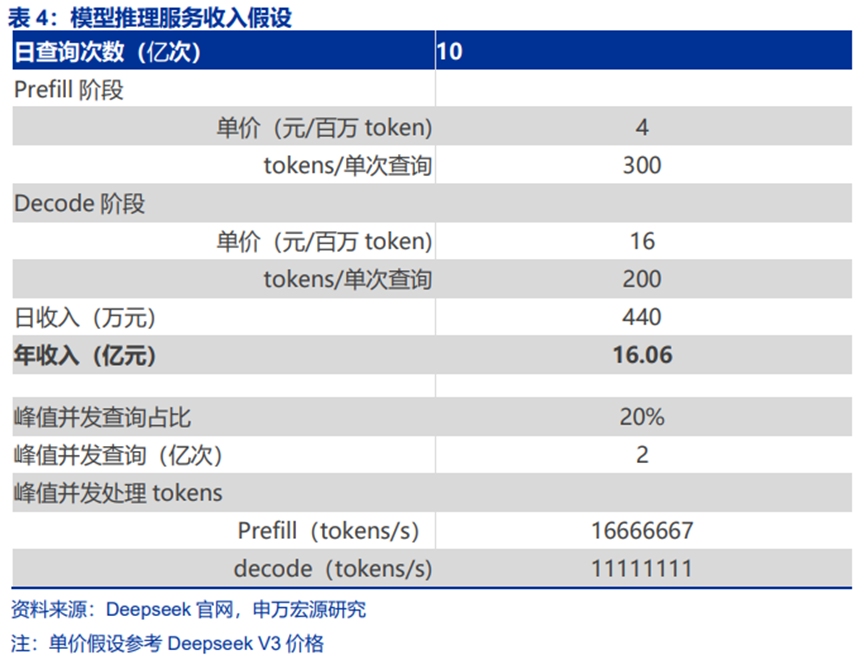
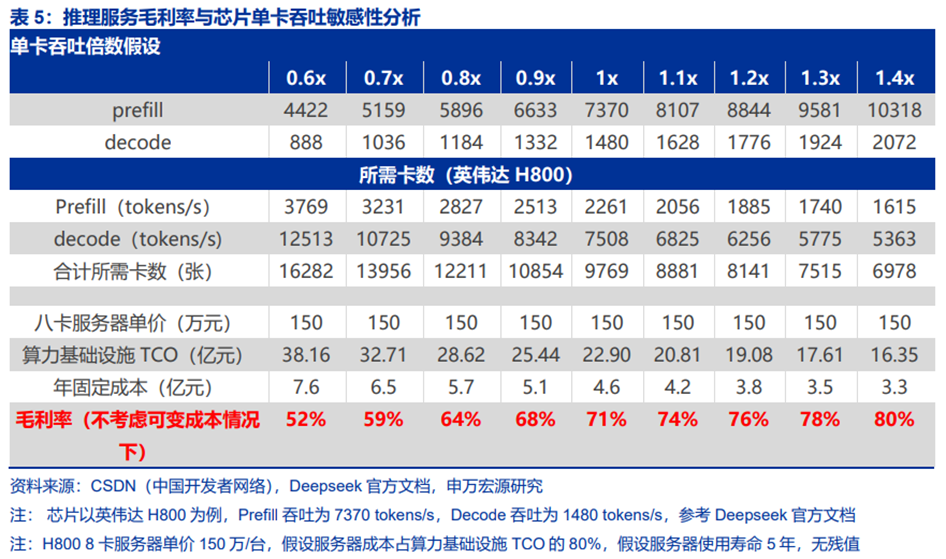
推理算力调度平台优化的核心指标是单卡吞吐,直接影响推理服务毛利率。单卡吞吐越高,硬件资源越能被充分使用。假设模型推理服务厂商使用等效。根据测算,在单日10亿查询量下,若使用H800芯片,单卡吞吐能力每提升10%,毛利率能够提升2-7个百分点。
2、模型及应用管理层:数据类Infra软件率先受益
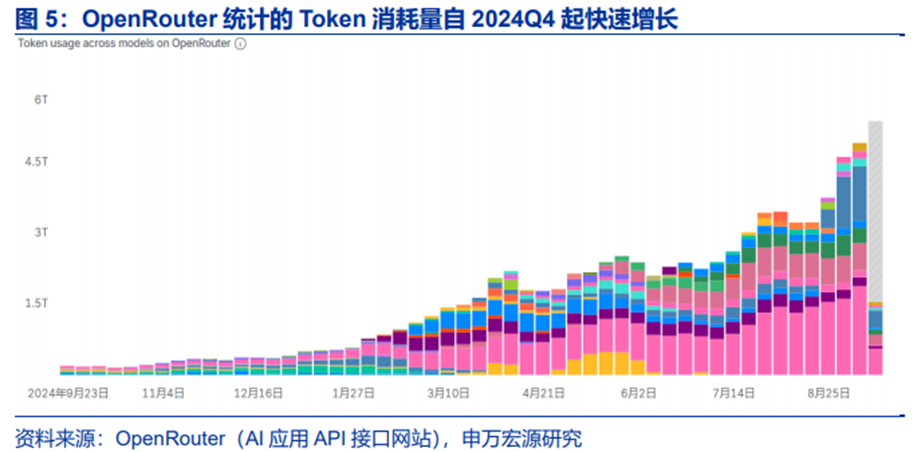
AI应用在快速渗透,推理AI Infra软件需求崛起。OpenRouter统计到的Token消耗量一年时间内翻了近10倍。Openrouter是一个开源路由工具,为2B端AI应用API接入各类大模型提供接口,从2024年Q4开始,从OpenRouter口径统计到的各类API接入大模型的Token消耗量持续增长。
AI应用部署的标准流程为:首先将训练好的模型与服务代码容器化;随后在K8s集群中部署,并配置扩缩容与负载均衡;通过API网关暴露服务;推理时,应用从特征库获取实时数据,由推理引擎处理并返回结果;最后通过监控体系保障服务稳定与模型效果。以RAG应用为例,请求会依次经过网关、检索向量数据库、拼接提示词、调用大模型服务并返回生成结果。其中所需软件工具主要包括:Docker用于将模型、环境及代码打包成容器;Kubernetes负责容器编排与资源调度;推理服务器(如TensorFlow Serving、Triton或vLLM)提供高性能推理接口;API网关(如Nginx)管理外部请求;监控工具(如Prometheus)追踪服务与模型性能;特征存储或向量数据库(用于RAG等场景)提供实时数据。
AI应用推理渗透的影响,率先作用在了数据层。观察到几个趋势:1)RAG风靡,向量数据库成为刚需;2)NoSQL OLTP厂商存储非结构化数据(语音、文本、图像、甚至向量索引等)、实时性高,需求正在反超,通过补充向量索引能力切入向量数据库市场;3)数据湖、数据仓库厂商(OLAP为主)通过并购、合作方式引入AI模型,向全栈工具迈进;4)数据IO控制权由CPU让渡到GPU,存储和向量数据库的技术需耦合升级。
(1)RAG类AI应用渗透,向量数据库需求提升
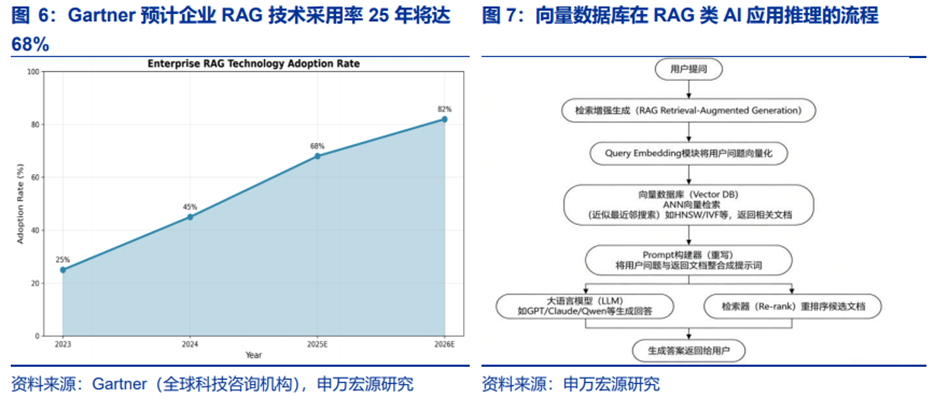
大模型幻觉问题下,2B端RAG类应用风靡。由于1)大模型不能直接记住大量企业私有知识:例如公司内部文档、产品手册、FAQ客户知识库。这些内容通常非常多,大模型无法全部放入Prompt,也不会长期记住;2)全文搜索不能满足语义需求:传统搜索如ES、关键词搜索只根据文本匹配,而包含某个关键词不等于语义最相关;3)大模型缺乏外部知识时,容易产生幻觉(hallucination),因此RAG(增强现实检索)成为企业部署AI应用的标配。根据Gartner,2024年全球已有45%的企业在智能客服、数据分析等场景中部署RAG系统,预计到2025年这一比例将突破68%。
向量数据库是RAG的“好帮手”,逐渐成为刚需。向量数据库本质上是一种专门用于存储向量化表示的系统。这些向量通常来源于图像、文本、音频等多模态数据,经过嵌入模型(embedding)处理后被映射到统一的高维向量空间并存储。
向量数据库的核心能力是,系统在接到查询向量时能快速返回最相似结果。这一能力源于层次图HNSW、量化IVF-PQ及DiskANN等近似最近邻算法对“快”和“准”的兼顾。在大模型时代前,向量检索就已支撑人脸识别、推荐排序、异常检测等场景;当前RAG推理需要用向量回溯长上下文或私有知识,进一步促进了向量数据库领域的发展。与传统键值库相比,这类系统不仅要管理嵌入生成、索引构建及查询调度,还必须在工程层面解决混合稠密-稀疏检索等复杂挑战,以确保在海量数据和持续写入下依旧保持高吞吐与一致性。
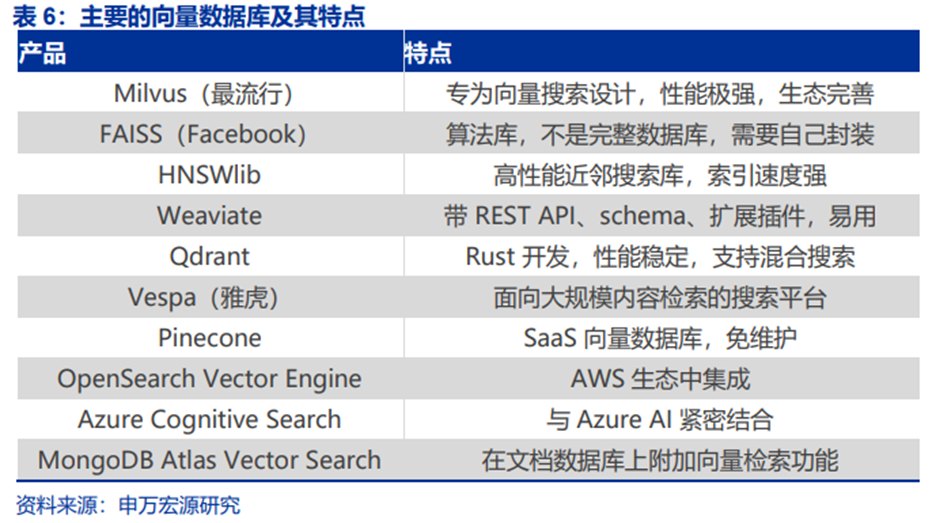
按照开源/商用,向量数据库可分为以下几类:1)主流开源向量数据库:Milvus、Weaviate、Qdrant等;2)商业SaaS/云厂商:Pinecone、Opensearch Vector Engine、AzureCognitiveSearch、MongoDB Atlas等;3)传统数据库的“向量扩展”功能:PostgreSQL pgvector、Elasticsearch vector search、MySQL HeatWave Vector,适合中小规模场景,不是专为大规模向量搜索设计。
向量数据库主要应对海量数据 高频查询,必须依赖高性能ANN搜索。当数据量达到百万到亿级,而查询需要维持毫秒级响应时,传统的精确相似度计算已经无法满足性能需求。只有通过高性能ANN索引(如HNSW、IVF、PQ等),才能在保证较高召回率的同时,实现高QPS的实时检索能力。
(2)OLTP NoSQL切入向量数据库,数据湖仓工具向应用层拓展
相比SaaS时代,AI给软件工具栈的最大影响是,数据结构从“分析优先”转向“实时运营 分析协同”。传统“分析优先”架构(数据仓库/湖仓一体为主)的设计目标是批量处理、事后洞察、报表输出,适配BI报表、历史趋势分析等场景,但在生成式AI、实时决策、智能交互等新需求下,趋势是:1)AI应用实时化:RAG、智能客服、实时推荐等场景要求毫秒级响应;2)数据价值即时化:LLM与智能体需要“数据即服务”,而非“数据即报表”,驱动业务自动决策;3)多模态数据爆发:文本、图像、音频等非结构化数据与向量嵌入成为核心数据结构。
Agent也强化了对高实时性数据的需求。Agent是具备感知-决策-执行闭环的智能系统,其运行依赖三个关键能力:1)实时感知环境变化:Agent需要持续获取外部动态数据(如用户实时指令、业务系统的状态变更、传感器的实时反馈),并快速响应;2)动态自主决策:基于实时数据和预设目标,Agent需在毫秒/秒级完成决策(如智能客服的意图识别、自动驾驶的路况判断、供应链Agent的库存调整)。3)交互性操作:Agent的决策结果需要直接作用于业务系统(如自动下单、修改订单状态、发送通知),涉及频繁的增删改查(CRUD)操作。
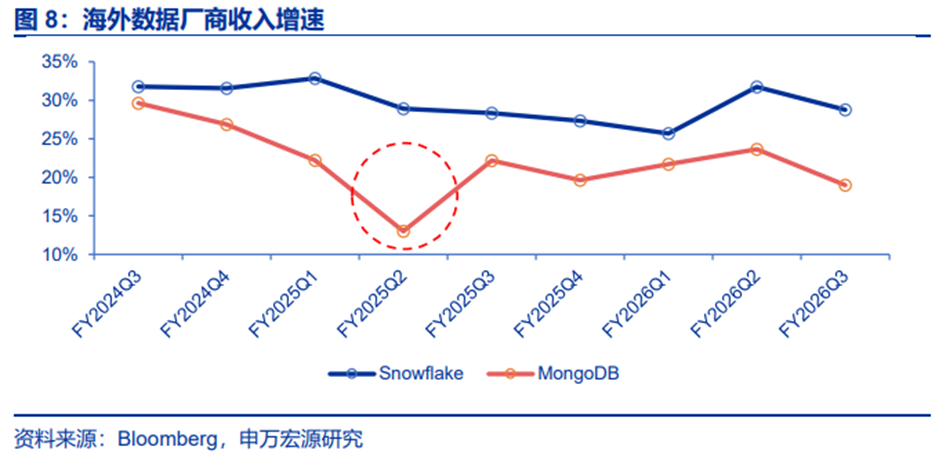
综合来看,这些需求的本质是高频、小批量、低延迟的实时事务处理,这正是OLTP的核心优势。以上趋势下,OLTP NoSQL再次风靡。海外Snowflake、MongoDB等厂商的收入增速FY2025Q2(对应2024Q2)出现拐点,印证这一逻辑。
MongoDB:构建企业级AI应用,向量数据库是刚需。
AI应用对数据结构提出前所未有的灵活性要求,传统关系型数据库因严格Schema限制难以应对语音识别等非结构化、半结构化数据场景。MongoDB凭借原生支持结构化、半结构化与完全非结构化数据的统一存储能力,成为AI应用的理想平台。
MongoDB凭借原生JSON数据模型,在AI时代具备显著技术壁垒。大语言模型(LLMs)原生输出与消费JSON格式,而MongoDB作为分布式文档数据库,天然适配非结构化、高动态数据场景。
除向量数据库外,MongoDB推出的AMP(Application Modernization Platform)平台也获得了客户高度认可,被视为帮助客户从传统关系型数据库迁移至现代文档模型的有效工具。管理层表示,AMP将在未来成为公司新的增长点之一。
MongoDB坚持“云中立”战略,其Atlas平台支持跨AWS、Azure、Google Cloud无缝部署,这一优势在近期多家云服务商出现服务中断后更显关键。客户对多云架构的依赖持续加深,MongoDB的跨云一致性与高可用性构成核心竞争力。
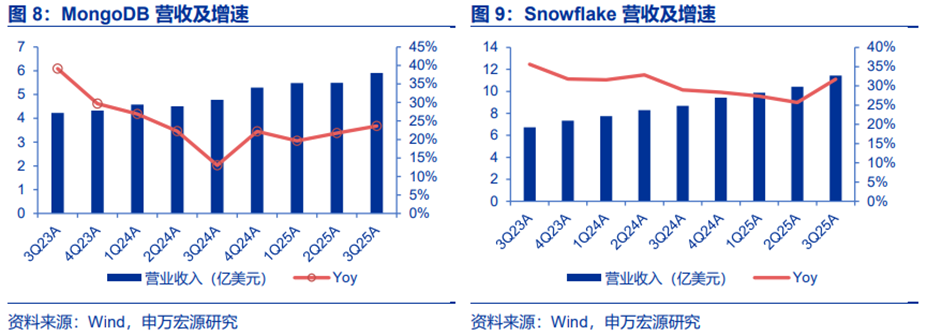
Snowflake:数据仓库核心玩家,更好发挥企业级AI应用效果。
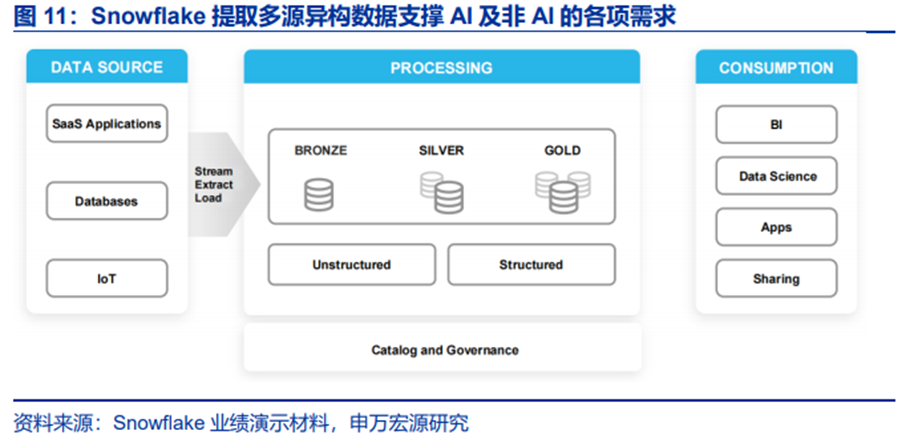
Snowflake Intelligence是一个针对AI模型和应用部署提供的数据平台,允许用户通过自然语言查询结构化和非结构化数据,并构建智能Agent以提升工作效率。
Snowflake Intelligence平台已进入公开预览阶段,目前已有超过6,100个账户每周使用Snowflake的AI功能,占部署用例的25%。此外,公司还推出了Cortex AI SQL,将AI原生集成到SQL中,使客户能够在不移动数据的情况下直接调用AI模型。
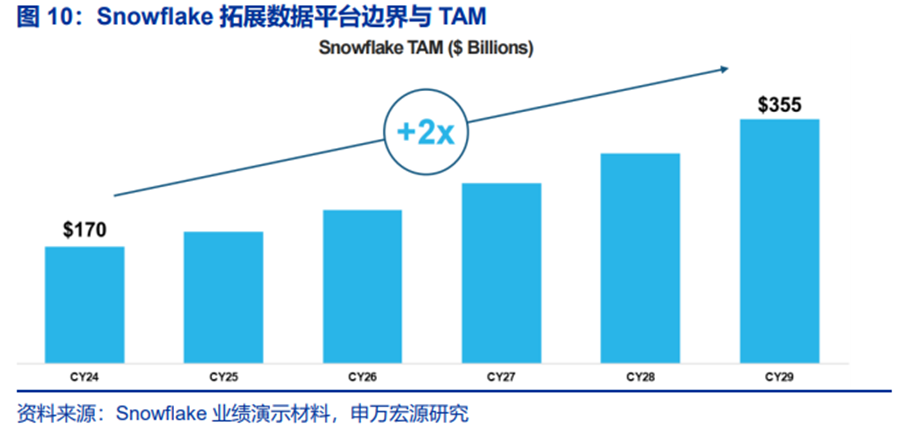
Snowflake的营收增长核心建立在“按使用付费”消费模型上,客户仅在实际使用产品并获得价值时才产生支出,该模式有效缓解客户对AI项目失败率高达95%的支出焦虑,确保投入与价值直接挂钩。根据Snowflake法说会,25%的已部署用例已整合AI功能,且新客户中50%的签约受AI驱动,表明AI正成为核心增长引擎。
AI将成为Snowflake推动自身从50亿美元营收迈向100亿美元的核心杠杆。根据CEO公开发言,未来Snowflake将覆盖数据从诞生、工程、分析到反馈优化的全生命周期。公司不再局限于“数据仓库”标签,而是通过持续迭代,将AI深度嵌入数据流,实现智能反馈闭环。其产品组合(Snowflake Intelligence、Openflow、Snowpark)协同作用,形成类似Kubernetes 云存储的平台级优势,支撑客户构建复杂AI应用。
(3)GPU成为数据控制中心,数据库 存储技术升级
AI推理迈入实时化、PB级数据访问的新阶段,存储IO正从“幕后支撑”变成“性能命脉”。LLM推理的KV缓存访问粒度仅8KB-4MB,向量数据库检索、推荐系统的特征读取更是低至64B-8KB,且需要支持数千条并行线程的并发请求。LLM推理的存储需求已突破10TB级,向量数据库和推荐系统的存储规模更是达到1TB-1PB,这种“小块高频”的访问模式,让传统存储架构性能落后。
NVIDIA最新提出了SCADA(Scaled Accelerated Data Access)方案,以GPU完全接管存储IO的控制路径与数据路径。SCADA是NVIDIA历经8年研究打造的完整解决方案,涵盖硬件适配、软件栈优化和协议创新。其中硬件平台为NVIDIA H3 Platform,具体架构:
1)算力层:最高支持4颗H100/L40S GPU,利用PCIe Gen5/6与存储直连,H100的并行处理能力可支撑数万条并发IO请求;
2)存储层:支持最多48块PCIe Gen6 SSD,单盘可提供5.4M随机读IOPS,44块集群可实现230MIOPS,接近理论峰值237.6MIOPS;
3)交换层:采用Broadcom Gen6 PCIe交换机,带宽利用率达96%,确保GPU与存储之间的低延迟通信。
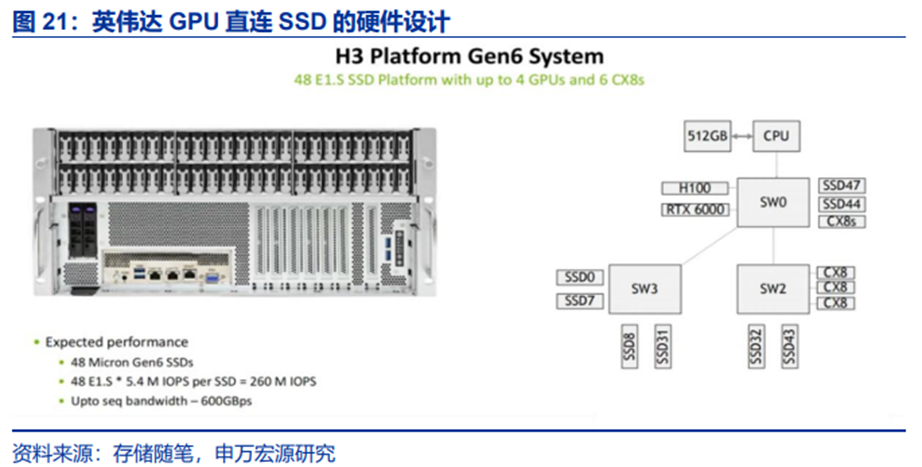
这种“GPU-交换机-SSD”的直连架构,彻底绕开了CPU的性能限制。测试数据显示,1颗H100GPU的IO调度效率是Gen5 Intel Xeon PlatinumCPU的2倍以上,即便入门级的L40S GPU(Gen4),其IO效率也达到同代CPU的98%,且成本更低。
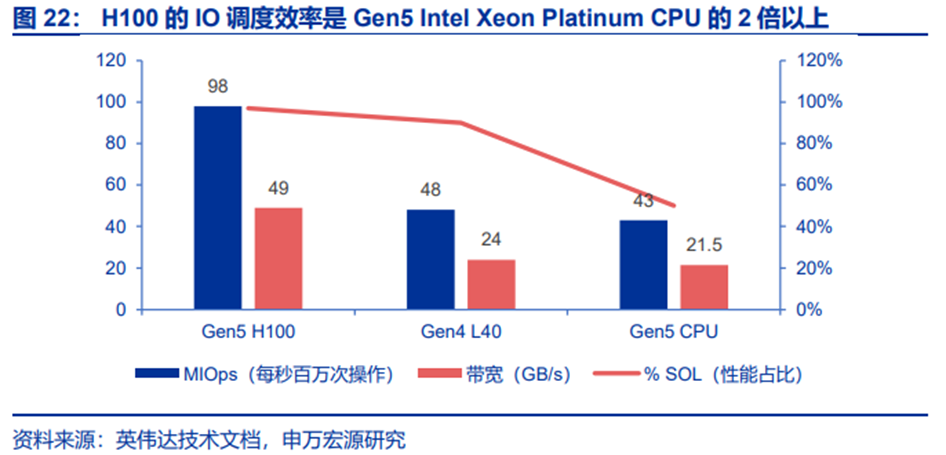
以LLM推理的KV缓存访问为例,SCADA的工作流程如下:
LLM模型在GPU上执行推理时,需要访问特定的KV缓存块(8KB-4MB);
GPU直接通过SCADA Client发起IO请求,无需CPU介入;
SCADA Server通过uNVMe驱动向目标SSD发送请求,利用PCIe Gen6交换机实现低延迟传输;数据通过DMA直接写入GPU的HBM缓存,供计算核心即时使用。整个过程中,CPU仅负责系统级的资源管理,不参与任何IO请求的发起与调度——这使得小数据块的IO延迟从毫秒级降至微秒级,完全匹配AI推理的实时性需求。
SCADA的成功离不开生态伙伴的支持,目前Marvell、Micron、三星、KIOXIA等头部存储厂商已深度参与SCADA的优化。
新的技术架构对向量数据库有什么影响?原本向量数据库分“三层存储”,核心靠硬盘 普通内存:1)核心工作区(CPU内存/DDR):像仓库的“工作台”,放高频访问的向量数据和索引,方便快速取用,但容量小、成本高。2)长期存储区(NVMe SSD/硬盘):像仓库的“货架”,存全量向量数据,容量大、成本低,但访问速度比内存慢,类似货架取货要走几步。3)备份区(云存储/异地硬盘):像仓库的“储物间”,存冷数据和备份,几乎不参与实时工作。
原本的工作流程是:CPU先接需求,从“货架”(SSD)把目标向量数据搬到“工作台”(CPU内存),CPU再把数据拷贝到GPU显存,让GPU做相似性计算(比如对比用户向量和商品向量),GPU算完后,把结果传回CPU,CPU再整理反馈给用户。
这种模式下,数据要“硬盘→CPU内存→GPU显存”三次拷贝,绕路又耗时;且CPU擅长串行任务系统级调度,但不擅长并行干活,面对亿级向量的批量计算,会成为瓶颈;其次内存墙问题凸显,内存容量小,超大规模向量数据放不下,只能频繁从硬盘调数据,越算越慢。
GPU直连之后,存储不发生变化,但数据从SSD直接提取到GPU显存中。为了适配这个新逻辑,向量数据库需要“升级改造”:
1)适配GPU”:把向量数据的存储方式改成GPU适配的列式存储,不用GPU再花时间转换;
2)索引和算法“适配GPU并行”:把原本给CPU设计的检索算法(比如HNSW),改成GPU能并行处理的版本,例如让GPU的多个计算核心同时对比不同向量,因此涉及算子重写;
3)自己管理GPU显存:向量数据库要学会分配GPU显存——哪些数据常驻显存、哪些数据用完放回SSD,避免显存不够用。
3、国内本地部署特色,涌现新需求
AI Infra层面,深信服凭借私有云能力切入全栈AI Infra领域;数据厂商层面,国内达梦数据、英方软件等开始发力AI。
达梦数据:核心能力在于OLTP,开始切入NoSQL。达梦数据是国产关系型数据库厂商翘楚与MongoDB类似,达梦数据近期也推出向量数据库,践行“智算多模”的技术理念与创新实践,其提出的原生多模存储引擎,实现了图、关系、键值、文档、向量等数据模型的统一存储。相比传统关系存储引擎,这一方案具有显著优势:消除了异构数据库间的迁移操作、冗余存储、兼容性问题及同步延迟,更借助图技术实现了性能的量级提升。
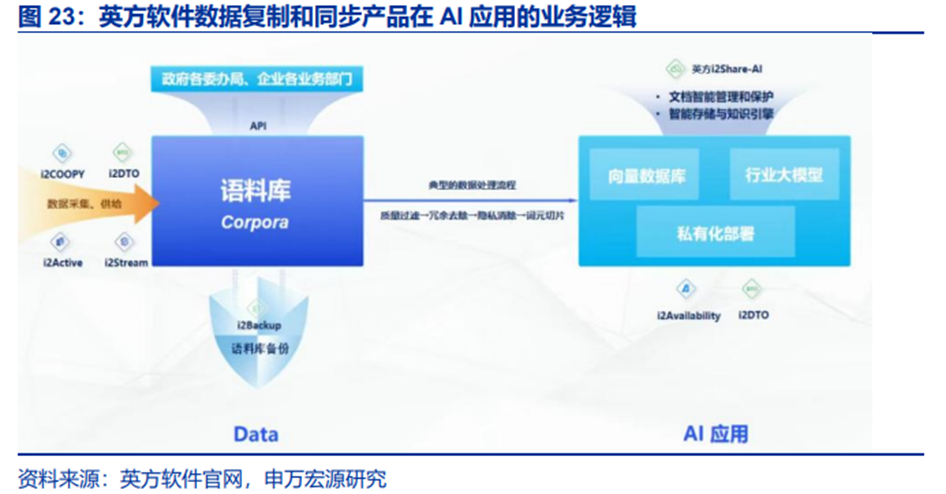
英方软件:数据复制及灾备厂商,OLAP服务生成AI的“好助手”。与Snowflake静态数据仓库的方式不同,英方软件推出i2Stream实时数据流处理平台,能够实现大规模数据流的实时同步,满足智能制造、智慧城市、AI大模型等领域对数据实时处理的需求。
06
AI基础设施厂商
1、阿里云:为企业级用户提供了全栈自研AI基础设施
阿里云是AI基础设施领域的领导者。阿里云以基于AI场景全面重构底层硬件、计算、存储、网络、数据库、大数据等AI基础设施层,已初步形成以通义为核心的操作系统和以AI云为核心的下一代计算机。平台层方面,阿里云百炼已集成两百多款大模型API,覆盖国内外主流开源和闭源模型。
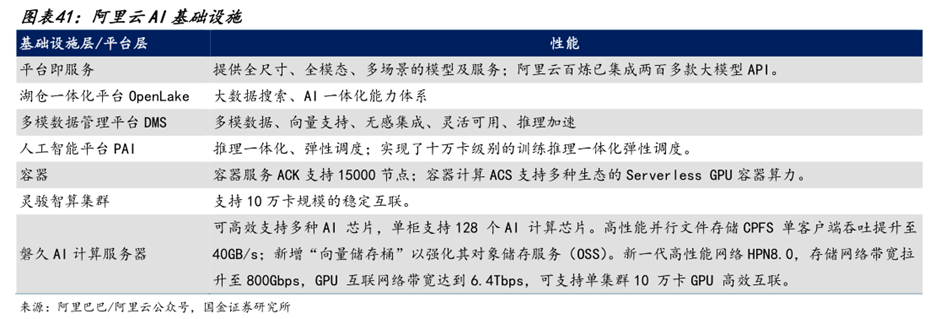
阿里云全栈自研AI基础设施具备完善的自有生态网络、大规模商用实践经验以及稳定安全的AI基础设施架构。1)全栈自研、积极创新:阿里云通过全栈自研构筑壁垒,从底层的算力到AI平台,始终坚持全栈技术创新。其自研产品及功能包含但不限于倚天等自研芯片、自研训推服务框架、自研HPN7.0网络架构等。2)完善的自有生态网络:阿里云拥有强大的生态系统,一方面阿里云拥有完善的产品服务生态;另一方面阿里云拥有12,000 家生态合作伙伴,与高校和科研机构保持紧密的合作关系,此外,阿里云还发起了全国最活跃的开源模型社区-魔搭社区。强大的生态优势进一步增强了阿里云的用户粘性与应用场景的深入。3)安全稳定的基础设施架构:阿里云为企业级用户提供了强大的安全防护体系与领先的网络架构。阿里云采取了DDoS高防、Web应用防火墙、云防火墙与数据安全中心等措施全面协助用户保护AI基础设施免受攻击。此外,阿里云提供了多种方式来监控和评估节点的健康状态,帮助用户快速定位问题并进行故障排查,满足用户对于产品安全稳定的要求。
阿里云在增长指数排名第一,在以下指标项得分最高。在安全合规与风险管理模块方面:阿里云在AI训推全流程提供数据存储、传输、处理安全保护,多租户环境下通过数据隔离、加密、全链路可信身份传递、合规审计强化数据安全;提供模型知识产权保护、防恶意操纵技术保障模型安全与完整性;通过AI伦理委员会、偏见检测工具、决策透明度技术践行AI伦理承诺;基础设施安全层面依托DDoS高防、WAF、云防火墙、数据安全中心及动环监控、物理接口加固,全面抵御网络攻击与物理安全风险。在生态系统与集成能力模块方面:阿里云PAI平台提供自研 第三方分布式训练框架、数据处理加速、推理优化工具提升训推效率;拥有超1.2万家覆盖渠道、ISV、SI、MSP全类型的生态合作伙伴,设AI基础设施专项伙伴;通过“云工开物”计划支持超150所国内外高校、超1000项合作项目;积极参与开源,是Apache基金会顶级赞助商,发起中国最大开源模型社区ModelScope,自研千问系列开源模型衍生数量超Llama。
阿里云在创新指数排名第二,在以下指标项得分最高:存储架构设计方面,提供对象存储OSS、高性能文件存储CPFS、文件存储NAS等丰富存储系统;AI特化存储优化方面,通过PAI-DLC平台EasyCkpt、AIMaster容错监控、SanityCheck健康检查提升容错,以支持AI模型检查点的高效存储和恢复。智能数据管理方面,覆盖数据版本控制、元数据管理、生命周期分层冷热数据分层存储等,支撑AI工作流。在架构可扩展性及多样化部署选项方面:阿里云PAI灵骏智算服务具备AIMaster自动容错弹性训练、训练任务弹性伸缩能力,保障扩展性能一致性;依托专有云与公共云技术同源,支持本地部署的专有云平台平滑同步公共云产品升级,满足用户扩展升级灵活性。
2、腾讯云:打造了算、存、网、数一体的高性能智算底座
腾讯云集结软硬自研产品能力,打造了算、存、网、数一体的高性能智算底座。凭借AI基础设施产品的智能性能与稳定性、积极创新的研发态度与各行业丰富的经验领先行业。1)智算性能和稳定性:腾讯云可实现集群千卡单日故障数低至0.16,为行业水平的1/3。此外,腾讯云的集群千卡1分钟能完成万卡checkpoint写入,数据读写效率为业界的10倍,通信时间更为业界的一半。2)积极创新:腾讯云集结软硬自研产品能力,打造了算、存、网、数一体的高性能智算底座,在AI高性能计算、AI高性能存储、AI高性能网络、向量数据库等方面均进行了系统性的优化与创新,打破了算存网的“木桶”效应。3)应用场景丰富:腾讯云产品应用场景丰富,其覆盖B端大客户、中小型企业与开发者等不同类型用户。覆盖包含互联网应用、出行与智能驾驶、大模型训练、广告搜索推荐、智能制造、医疗与教育等15 个行业,积累了丰富的行业实践经验。

腾讯云在增长指数排名第二,在以下指标项得分最高。资源配置与成本模型方面:提供丰富工具协助成本预估与优化,通过费用中心实时监控识别浪费,开源Crane项目利用预测算法提前触发弹性伸缩,避免滞后。能源效率与可持续性方面:采用先进技术架构,第四代数据中心通过模块化预制设计降低碳排放,运营阶段年均PUE达1.2,节能效果显著。安全运营与响应方面:构建“感知-决策-响应”一体化体系,智能监控风险,通过“三步应急”机制最小化事件影响并优化防护策略。
腾讯云在创新指数排名第一,在以下指标项得分最高。资源利用率优化管理方面:集成TACO-DiT和TACO-LLM等推理加速工具,大幅提升吞吐性能并降低营运成本;提供多样化调度与优化工具,通过TCCL、星脉网络等优化,显著提升负载性能、通信效率及训练效率。网络性能优化方面:提供基于RoCEv2的智能高性能网络IHN(星脉);针对AI高带宽需求,通过构建全局拓扑与动态感知调度实现流量规划,相比传统方式显著提升通信性能与全网吞吐。
3、百度智能云:中国AI领域首个基于产业深度实践的基础设施
百度智能云AI大底座作为中国AI领域首个基于产业深度实践的基础设施,为广泛行业用户提供了一站式自主创新的解决方案,支撑企业在智能算力基础设施建设上实现集约化建设、高性能应用与持续性增强。
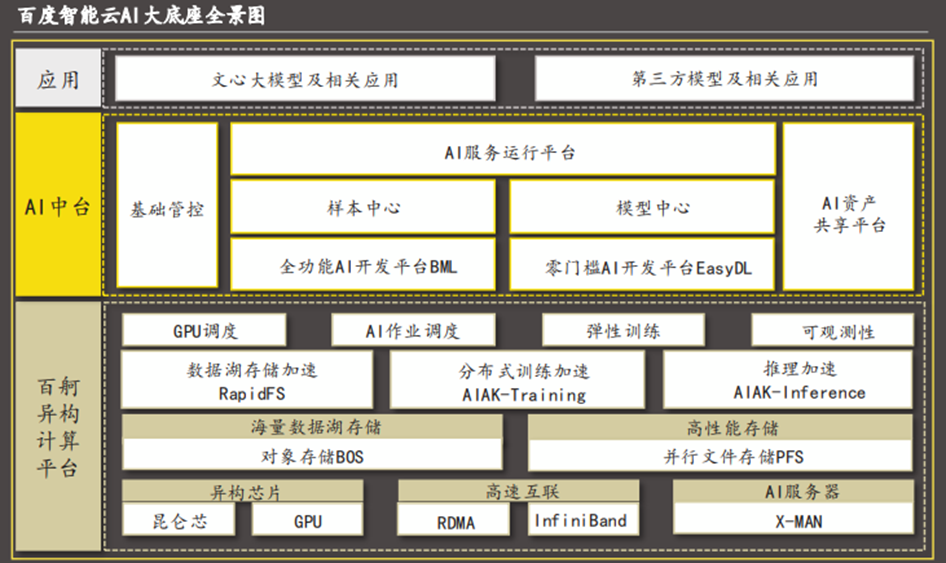
百度智能云坚持将自研技术贯穿完整架构,以构筑自主可控的核心产品与技术。其自研的AI大底座为各行业客户提供了从IaaS到PaaS的自主可控、自我进化的解决方案。1)广泛的行业覆盖:百度智能云的AI基础设施解决方案已覆盖互联网、制造、能源、金融、交通物流等多个领域。此外,百度智能云拥有庞大的开发者社区和合作伙伴生态,为企业提供全方位支持,以确保客户建立长期合作关系。2)领先的自主创新能力:百度智能云自研的“AI大底座”由百度百舸计算平台与百度AI中台解决方案两大平台构成,为企业用户提供了从IaaS到PaaS的全栈自研、自主可控、自我进化的解决方案,支撑企业在智能算力基础设施建设上实现集约化建设、高性能应用与持续性增强。3)高性能“云智一体”架构:百度智能云坚持“云智一体”架构,以各行各业的核心场景为切入点,构建更低成本的异构算力和更高效的开发运营能力,为各行业用户提供极致能效。
百度智能云在增长指数排名第三,在以下指标项得分最高。性能与成本平衡:通过算子融合、显存优化提升算力效率,并行与自适应调度提高利用率,多芯策略降低成本;针对不同规模任务提供差异化方案,大规模场景优化训练效率,小模型场景通过GPU切分共享降低生产成本。行业客户与场景应用方案:凭借AIAK加速框架、昆仑芯片等领先技术及完善服务体系,沉淀可观客户规模;应用场景全面覆盖金融、互联网、汽车等行业,与头部厂商密切合作,形成核心优势。
百度智能云在AI特化存储优化模块得分最高。PFS采用内存缓存元数据管理 客户端缓存机制,减少网络与磁盘访问开销;通过PageCache缓存小文件,适配AI训练场景;依托NVMe SSD存储、元数据服务器扩展等完善方案,提升GPU与存储吞吐量、降低访问延迟;高性能checkpoint保存框架,单次保存耗时较开源方案最高减少93%-99%。
4、星环科技:AI Infra全栈解决方案供应商
从Data Infra延伸至AI Infra。公司以大数据技术起家,AI数据工程基因纯粹,具有大数据基础平台、分布式数据库、数据开发与智能分析工具、数据云平台等完整产品矩阵,覆盖大数据全生命周期管理。基于数据工程基因,大模型时代浪潮下公司业务定位由数字基础设施提供商进一步延伸至AI基础设施企业,通过整合大数据、人工智能等技术,推出知识平台TKH,完善了AI从基础设施到应用的产业链条。
据星环科技公众号,5月27日,星环科技主办“AI×Data:新一代AI Infra”2025年度产品发布会,星环科技正式发布AI-Ready Data Platform概念,并全面展示其构建新一代AI基础设施的核心能力。星环科技在此次发布会上重点介绍了Sophon LLMOps 1.6平台的四维进化,作为企业级AI基础设施,Sophon LLMOps统一支撑空间管理、模型、算力管理、数据管理、通用工具,实现智能体驱动的AI全流程运营,实现了从数据到智能、从模型到应用的闭环升级,全面催化AI×Data的深度融合。

据星环科技公众号,星环科技在此次发布会上推出的新一代AI Infra,不仅是一套完整的人工智能基础设施技术架构,更是一次关于未来企业智能化如何落地的系统性思考。新一代AI Infra旨在解决企业在AI落地过程中面临的数据和应用挑战。这一架构包含四大核心平台:Knowledge Platform(知识平台)、AI Platform(AI平台)、AI-Ready Data Platform(AI就绪数据平台)和Resources Platform(资源平台)。

5、达梦数据:全栈数据产品赋能AI落地
据达梦数据公众号,达梦数据聚焦数据管理、多模型训练、智能体生成,为用户解决智能客服、运维故障分析等场景问题。技术融合催生了新的增长极,达梦数据不仅深耕关系型数据库领域,还积极推动图数据库、缓存数据库、时序数据库、文档数据库等非关系型数据库和云数据库方面的全面布局,为AI时代筑基。
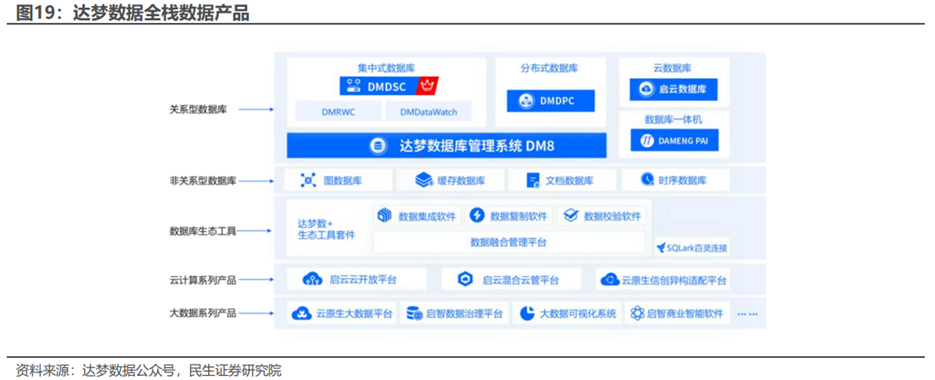
据达梦数据公众号,在基础资源层面,平台集计算、网络、算力、存储,构建了高度集成的硬件基础设施;模型底座集成DeepSeek、Meta LLAMA3、Qwen3等主流大模型,通过vLLM实现模型托管与推理加速。平台核心处理则实现多模型管理与智能体编排,支持模型接入、部署与启停的全流程管控。达梦启云数据库智能运维平台就是基于LLaMA3.x、QWen2.5等通用大模型做模型微调,能实现参数优化、SQL生成与优化、数据探查、AI自动优化数据库参数,解决人工调参效率低、难度高的问题。

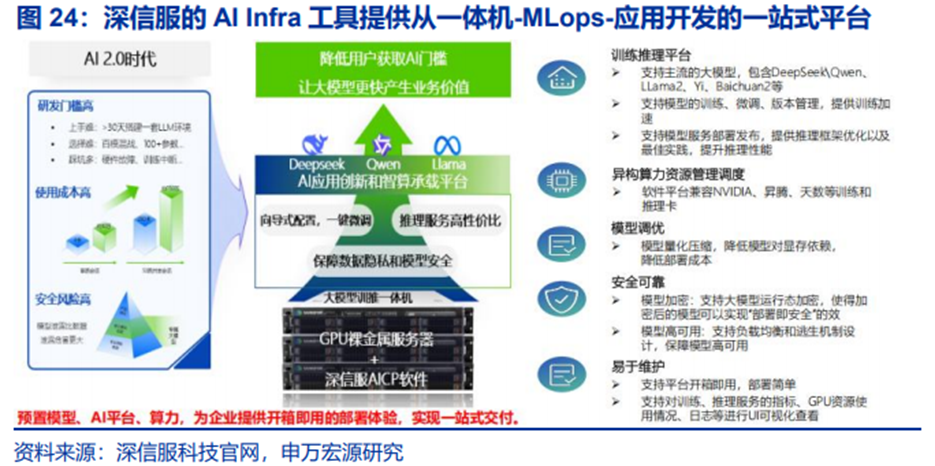
6、深信服:AI 超融合持续渗透
深信服提供包括虚拟化、超融合、轻量云等不同的基础设施产品和解决方案。深信服私有化部署的方案适合中国国情特点,通过一体机硬件搭载模型部署、同意纳管、微调、模型加密、应用开发等软件工具,通过硬件打市场、软件提供能力溢价的方式,能够认为未来在大型企业客户加速部署AI应用的进程中将受益。
国际数据公司(IDC)最新发布的《中国软件定义存储以及超融合系统市场追踪报告,2025Q1》显示,深信服超融合在2025年第一季度,以25.1%的市场占有率位居中国全栈超融合市场第一。
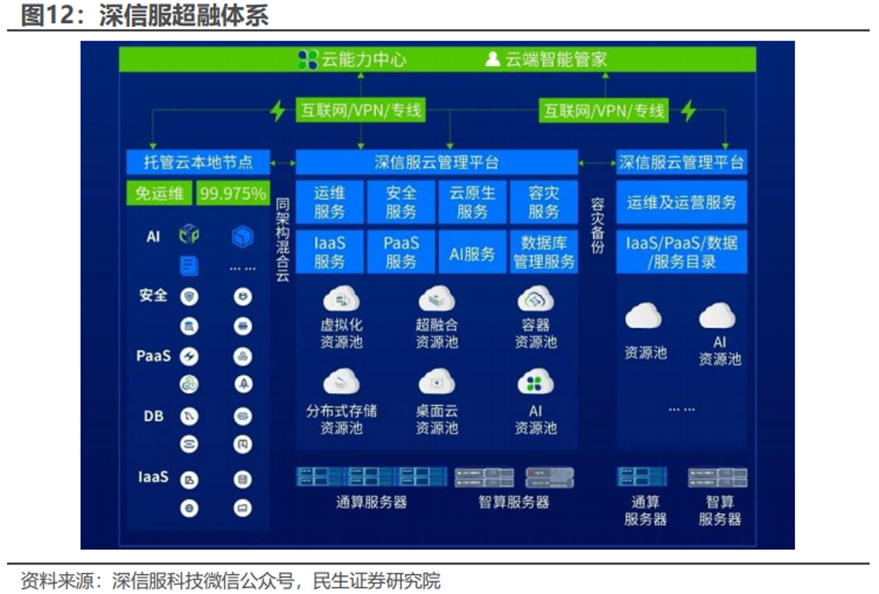
AI时代,超融合作为数字化转型的重要基础设施,用户对其的期待已不仅是单一的承载应用能力,而是可以促进业务创新和高效运营的、真正面向未来的数字化底座。据深信服科技微信公众号,用户“未来化”的需求,需要数字化底座具备这些特性:可演进:从技术到架构可以持续演进;混合云:云上与云下协同构建混合云;通算智算融合:在通算基础上快速融入智算化能力。因此,深信服超融合再次升级,将以轻量云实现用户的全栈需求。
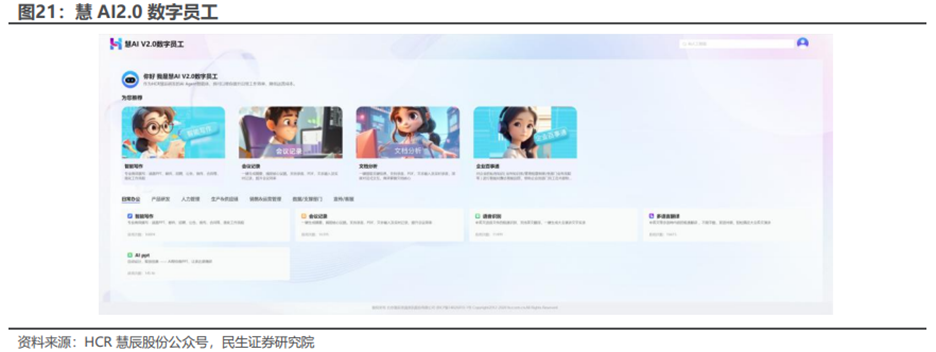
7、慧辰股份:实现从AI Infra到AI应用的全面打通
据慧辰股份公众号,2025年,在AI软硬件融合方面,公司联合行业智算硬件合作方,基于DeepSeek、Qwen等大模型与慧AI数字员工产品,构建数字员工一体机解决方案。提供从“底层算力、大模型部署、推理训练、数字员工应用”的全栈解决方案,助力各领域用户完成“硬件 大模型 智能应用”的一站式部署,在知识检索、日常办公、知识库问答、数字客服等多个场景中,帮助用户形成覆盖“业务-服务-运营-决策”的智能应用能力。
据慧辰股份公众号,为推动算力普惠化,慧辰股份参与共建技术-资源-市场协同的“智算云产业生态”,签署“AI公共算力平台软件”项目等,合作模式逐步由技术层面不断向产业生态深度延伸,与合作伙伴们从技术共建迈入商业化联合运营的新阶段,为千行百业提供高效、可信、便捷的智能算力服务。

07
参考研报
1.申万宏源-计算机行业GenAI系列报告之65:AIInfra,应用渗透下的又一卖铲人
2.申万宏源-计算机行业周报:AI Infra梳理!物理AI—数字孪生、具身智能实现基石!
3.申万宏源-计算机行业周报:AI Infra,重点关注数据层软件及MaaS
4.东莞证券-电子行业2026上半年投资策略:AI Infra市场有望高增,端侧创新在路上
5.东莞证券-电子行业东莞AI产业系列报告之一:AI Infra规模高增,PCB产业链有望受益
6.民生证券-计算机行业周报:国产AI Infra崛起,从算力到云与数据库
7.沙利文&头豹研究院-2025年中国AI基础设施行业市场报告
8.国金证券-阿里巴巴~W-9988.HK-重启新篇章:聚焦、增长、重估
9.中银国际-AI算力行业产业链更新报告:需求闭环 供给放量,AI infra供应链加速迭代
10.中银国际-电子行业:AI Infra升级浪潮中的材料革命,电子布、铜箔、树脂构筑AI PCB介电性能核心壁垒

 VIP复盘网
VIP复盘网
