

报告摘要
■云厂商资本开支预期持续提升,AI算力空间巨大。从底层原理看,摩尔定律的边际放缓和Scaling law共同打开了AI算力需求的上限,更强的模型需要更大的参数量、数据量进行训练,而支撑模型训练则需要更多的AI算力。从AI算力实际需求看,2024年前三季度北美四大云厂商资本开支同比增长59%;根据TrendForce,预计2024年AI服务器出货量同比增速将达到42%,2025年受云端业者及主权云等需求带动,出货量有望再增长约28%,推动AI服务器占整体服务器市场出货量比例提高至近15%。AI服务器出货量同比增速将达到42%,2025年受云端业者及主权云等需求带动,出货量有望再增长约28%,推动AI服务器占整体服务器市场出货量比例提高至近15%。AI服务器市场整体仍具有较大的增长潜力。
■高端AI服务器出货形态改变,产业链有望得到重塑。根据TrendForce,从AI服务器搭配AI芯片类型来看,预计2024年主流搭载GPU的AI服务器占比为71%,其中英伟达市占率近9成,预计2025年英伟达新一代Blackwell将取代Hopper平台成为市场主流。由于GB200机柜级产品在算力、连接、功耗方面均较传统8卡服务器更具性价比,因此Blackwell架构产品的主要出货形式也相应发生变化。根据鸿海发言人在法说会上的回应,预计2024年第四季度小量生产GB200服务器,2025年大量出货。产品形态和出货模式的变化也将影响产业链的分工。
■工业富联深度参与英伟达AI产业链,在产业链分工变化中有望获取更多份额。公司作为英伟达重要的联合研发合作伙伴以及云厂商的核心供应商,在AI爆发初期就占据了AI服务器供应的一席之地,业务涉及GPU模组、板卡和服务器多种形态。而在GB200机柜级产品系列中,公司深度参与了机柜级产品从板卡到计算托盘、交换托盘到整机的生产制造,单机价值量和机柜出货量均有望伴随GB200芯片的量产实现大幅增长,带动云计算业务收入以及整体业绩高增。
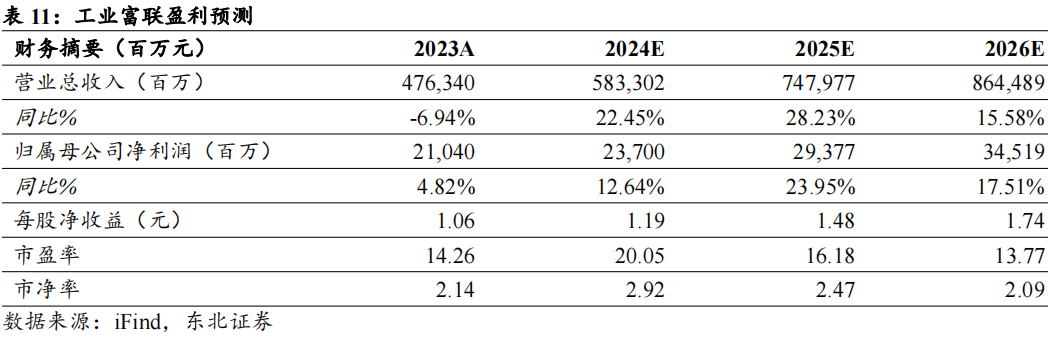
■投资建议:我们认为工业富联作为英伟达核心供应商,将成为AI 资本开支高速增长、算力投入持续提升的受益者。预计工业富联2024-2026 年分别实现收入5833/7480/8645亿元,同比增长22%/28%/16%;实现归母净利润237/294/345亿元,同比增长13%/24%/18%。对应PE分别为20x/16x/14x。给予“买入”评级。
■风险提示:技术迭代不及预期的风险;供应链稳定性下降的风险;GB200量产进度不及预期的风险;行业竞争加剧,毛利率下降的风险。

1 高性能AI服务器主导市场,白牌服务器厂商份额提升
1.1
供给:早期受CPU技术迭代影响,AI时代GPU成主导因素
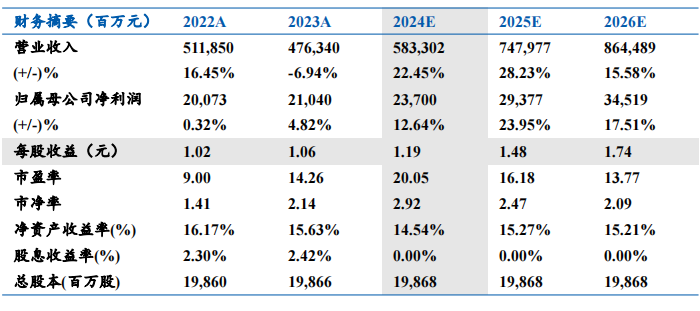
服务器CPU成本占大头,CPU迭代主导产品周期。服务器作为网络环境中提供计算能力以及运行应用程序的IT设备,其计算性能主要由CPU的核心数量、架构、频率决定。从成本角度看,根据IDC数据,通用服务器拆分中,CPU成本占比最高,达到32%。因此CPU的技术迭代是用户替换原有服务器的动力之一。
摩尔定律失效及数据处理需求增长为服务器市场规模扩大带来长期支撑。根据摩尔定律,IC上可容纳的晶体管数目约每隔18个月便会增加一倍,性能也将提升一倍,而价格下降一倍。伴随数据量增长,对大量数据处理需求的消化能够通过增加计算设施的数量和提高晶体管密度两种方式实现。而由于摩尔定律的失效,后者效果持续减弱,数据处理需求增长将成为服务器出货量及市场规模持续增长的主要支撑,服务器性能提升也将反映在单价提升上。
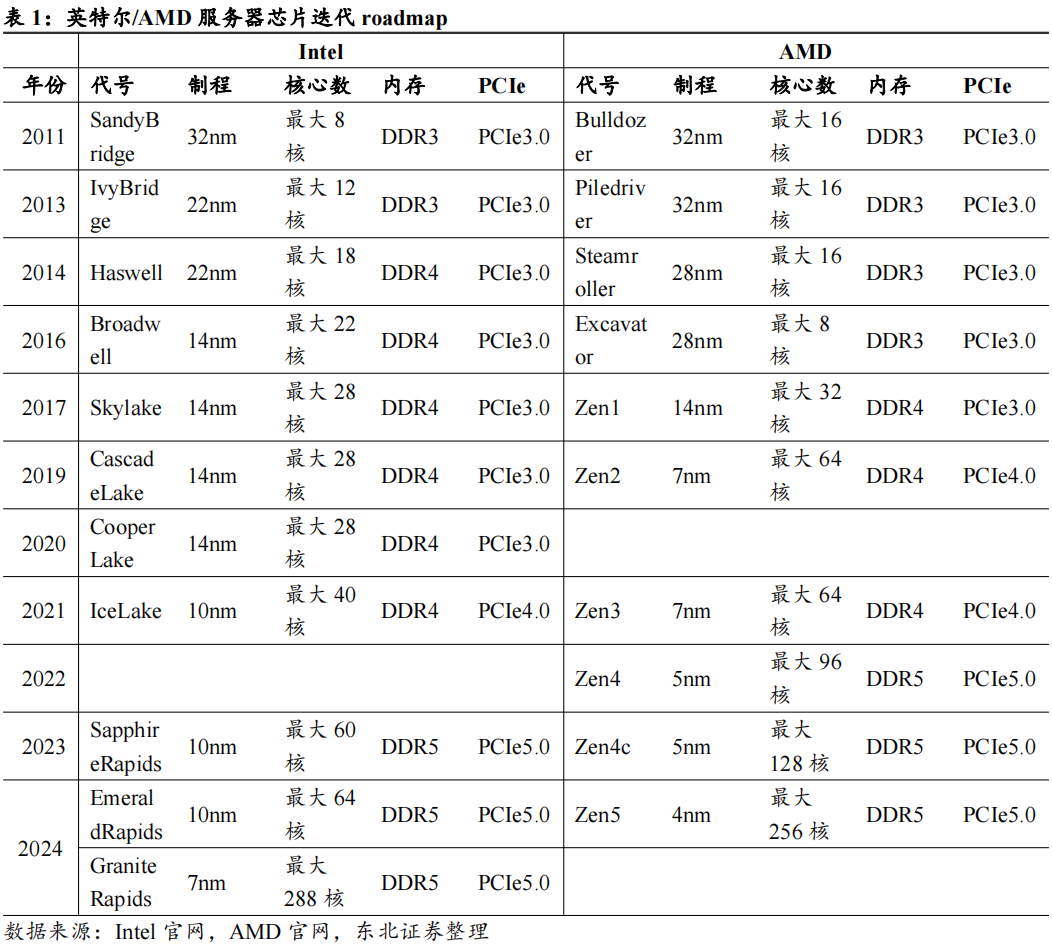
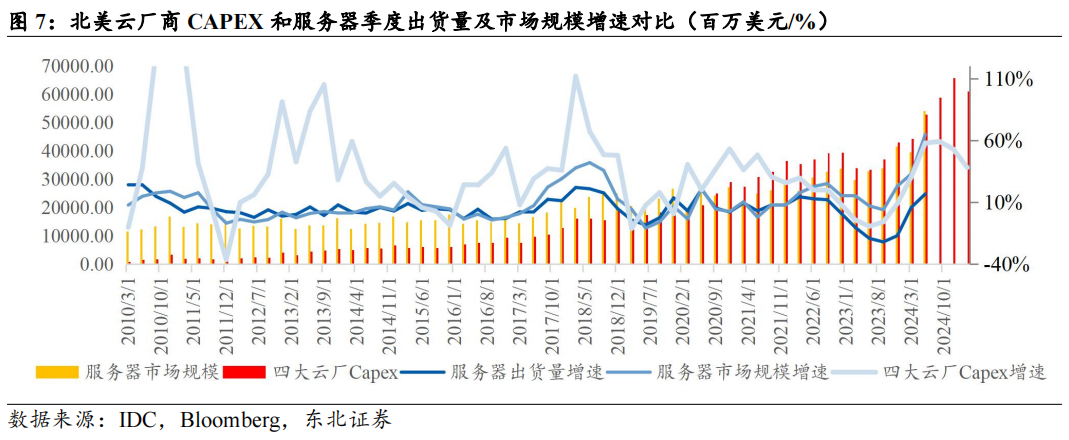
早期Intel主导服务器处理器市场,其技术研发周期是服务器厂商采购的重要参考。根据IDC数据,过去十余年,Intel一直是服务器处理器市场份额的绝对占有者,自2006年以来,Intel市场份额持续提升,到2017年达到顶峰98.1%。作为CPU市场的主导者,其技术迭代周期影响了服务器厂商的采购节奏,从制程更新角度看,Intel32nm、22nm、14nm制程处理器分别在2010Q1、2013Q3、2016Q3量产,而服务器出货量/市场规模增速的波峰则出现在2011Q2、2015Q1、2018Q1,间隔约5-6个季度(具体可参考图7)。
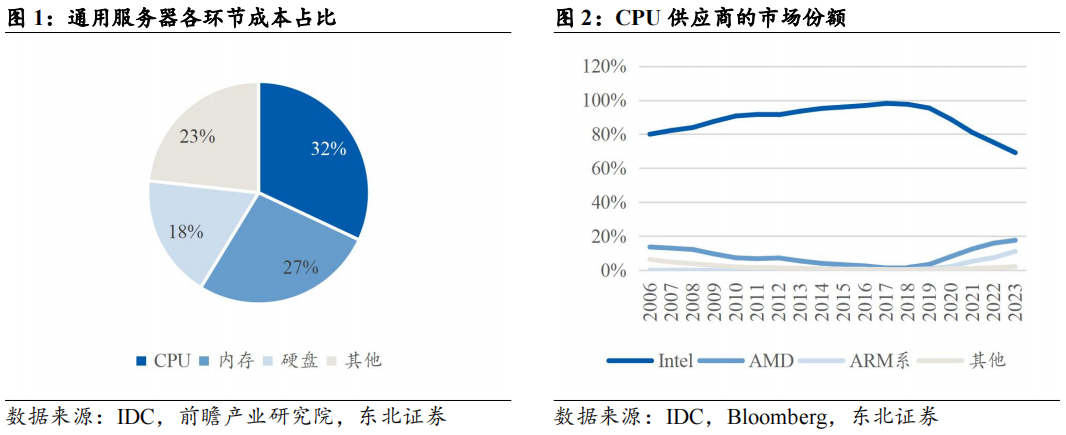
Intel迭代周期放缓,通用服务器采购周期受CPU技术迭代的影响正在减弱。2016年以前,Intel采取Tick-Tock研发周期,即两年一次工艺制程进步,中间一年更新架构。2016年开始,Intel研发瓶颈出现,2017年Intel推出14nm制程产品Skylake(可扩展处理器第一代)后,新制程推出持续跳票,直至2021Q1推出10nm制程的产品Icelake(第三代)。与此同时,竞争对手AMD发力,制程、核数反超Intel。2024年,Intel推出了第六代GraniteRapids,核心数追上AMD。由于Intel自身技术迭代周期放缓以及AMD的追赶,Intel市场份额有所下降,2023年Intel在全球服务器CPU市场占据了69.14%的份额;AMD份额提升至17.63%。市场份额变化导致了由技术迭代主导的服务器换机需求正在逐步减弱。
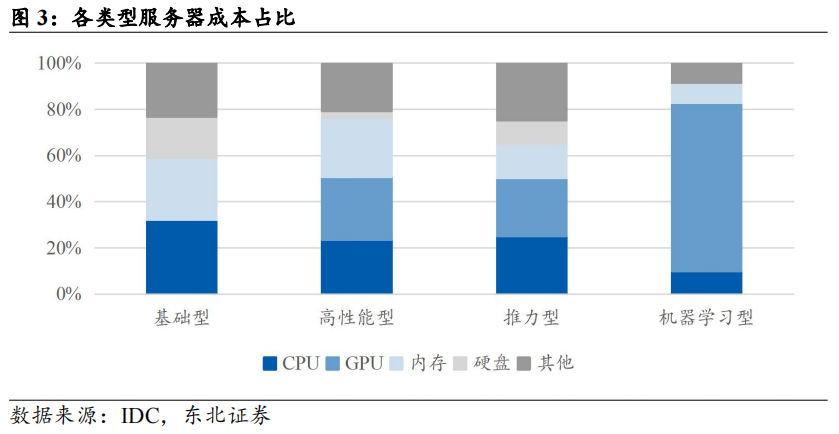
GPU接棒CPU成为下一个影响服务器技术迭代的主要因素。AI服务器与普通服务器的主要区别在于:1)硬件架构:AI服务器通常配备高效的中央处理器(CPU)和多块图形处理器(GPU)、张量处理器(TPU)或专用的AI加速器,普通服务器主要以CPU为算力提供者,适用于处理逻辑计算和浮点型计算等任务。AI服务器通常配备1-2个CPU 4/8/16个GPU,通用服务器则可以支持更多CPU插槽。2)计算能力:AI服务器通常采用并行计算模式,普通服务器的CPU在进行逻辑判断时需要大量的分支跳转处理,结构复杂,算力提升主要依靠增加核心数。此外,AI服务器对内存、网络能力具有更高的要求。2023年开始正式进入AI大模型时代,由于AI模型训练的特性,需要对大量数据样本进行并行处理,因此能够执行高强度并行计算任务的GPU更加符合大模型训练和推理的要求。根据IDC数据,机器学习型服务器GPU成本占比在73%,显著高于CPU成本占比。
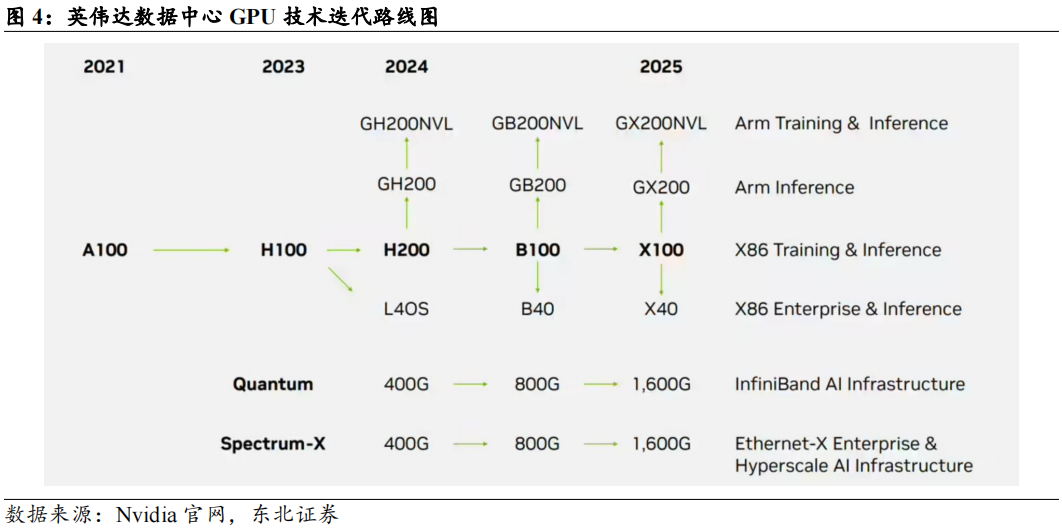
1.2
需求:资源向云厂商集中,AI发展导致Capex持续加码
互联网是服务器市场最大的下游客户,采购需求受到资本开支和折旧周期的共同影响。根据TrendForce,2024年服务器整机仍以美系云厂商为主要客户;在高端AI服务器方面,微软、谷歌、AWS、Meta四巨头占比分别达到20%/17%/16%/11%,国内互联网厂商BBAT的需求占比为8%。服务器的需求格局在过去10年也发生了较大变化,一方面,互联网厂商主业发展(如阿里、亚马逊的电商,腾讯的游戏,字节的短视频业务)驱动大厂部署更多的服务器,以应对高并发场景(如双十一);另一方面,云计算模式的兴起将企业市场的服务器需求转移至云厂商,需求格局向头部集中,因此国内外互联网厂商的资本开支变化能够作为服务器市场规模的一项前瞻指标。此外,海外互联网厂商的折旧政策普遍将服务器的折旧年限定为4年左右,折旧周期同样将影响下游对服务器的需求。
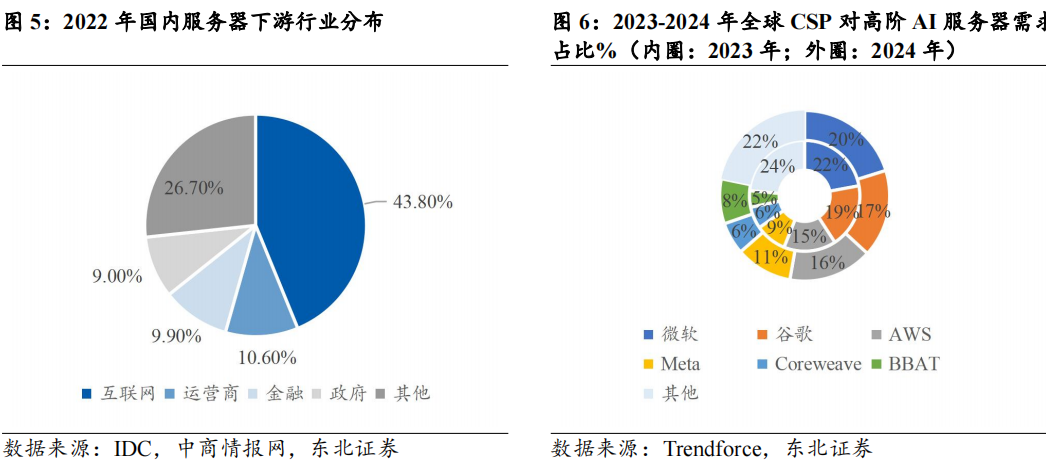
从服务器历史出货情况进行复盘,出货量与销售收入一轮周期大约持续3-4年,其中需求侧更多受到云厂商资本开支的影响,供给端更多关注服务器处理器技术迭代的情况。具体来看:
根据云厂商资本开支情况和服务器出货情况,我们将通用服务器按周期进行划分:
阶段1(2010—2015年):
2006年AWS成立,2010年前后,微软、谷歌分别推出Azure和GoogleCloud,大厂云计算业务起步。从需求格局上看,2010年前后,服务器的主要下游在于企业市场(约30-40%)、政府、金融、电信等行业,企业通过自建机房进行信息化建设,通常直接向服务器品牌厂商或渠道商采购,需求较为分散。伴随云计算模式的崛起,企业市场的服务器需求逐渐转移至云计算厂商,自建机房转换为公有云。
阶段2(2016—2019年):
互联网大厂资本开支在2016年和2018年仍保持了较高增速,云厂商在服务器下游的占比逐渐提升。我们计算北美四大互联网厂商资本开支总和,其在服务器销售收入的占比由2011Q1的15%提升至2016Q4的54%。
这段时间,云计算业务规模持续扩大,伴随服务器下游客户中互联网厂商占比的提升,云厂商资本开支增速与服务器销售收入增长趋势逐渐统一,北美CSP资本开支变化对服务器采购周期的影响显著提升。
阶段3(2020—2023年):
2020年受疫情影响,线上数字化办公需求暴增,企业市场进一步向云厂商转移,其中2020H2开始至2021年,亚马逊资本开支出现几乎翻倍增长态势,拉动北美云厂商资本开支增速上升,并导致与服务器出货增速再次出现背离。剔除亚马逊2020年提前投入的影响,2021年-2022年,北美四大云厂商资本开支仍处于上行期,带动服务器需求大幅增长。到2023年,通用服务器投入放缓,且资本开支中AI服务器需求对通用服务器份额形成挤兑。
阶段4(2024年至今):
2023年云厂商资本开支增速出现收缩(Q2\Q3甚至负增速),一方面,云厂商经过21-22年的高速投入后,短期换机动力不强;另一方面,AI大模型军备竞赛,云厂商资本开支被AI服务器占用,由于AI服务器具有更高的单机价值量,2023年服务器销售收入正增长,但出货量下滑。2024年前三季度北美云厂商资本开支同比增长59%,增长主要由AI服务器贡献,带动服务器市场规模、出货量大幅回升。根据彭博一致预期,CY2024北美四大云厂资本开支同比增速有望达到50.42%。
云厂商开启大模型军备竞赛,AI服务器需求量大幅抬升。根据TrendForce,预估2023年AI服务器(包含搭载GPU、FPGA、ASIC等)出货量近120万台,年增38.4%,占整体服务器出货量近9%,预计2024年AI服务器出货量同比增速将达到42%,2025年受云端业者及主权云等需求带动,出货量有望再增长约28%,推动AI服务器占整体服务器市场出货量比例提高至近15%。从行业的角度看,互联网依然是最大的采购行业,占整体加速服务器市场近60%的份额,此外金融、电信、交通和医疗健康等多数行业均有超过一倍以上的增长。从互联网角度看,为了训练自己的AI大模型,在下一代技术变革中取得先发优势,各大厂对于AI投入的重视程度显著提升,并开启一轮AI算力储备:
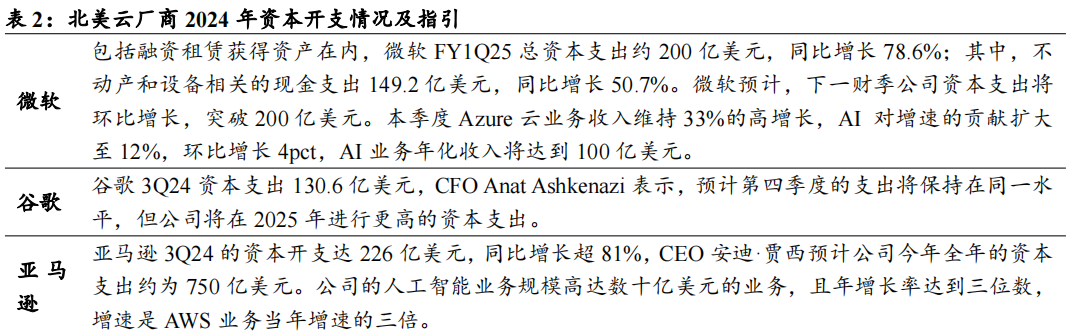
微软:未来几年的资本支出将逐年增加,以支持公司云产品的增长以及在人工智能基础设施和训练方面的投资。
谷歌:CFO在电话会议中表示资本支出的增加大部分将用于技术基础设施,包括支持云和AI产品的服务器和数据中心设备,如多模态AI助手Astra。公司侧重于效率,从而为AI的投入腾出资金。亚马逊:2025年的资本支出将在今年的基础上继续增加。公司大部分资本支出用于AWS,其增长主要是由人工智能技术方面的投入所驱动的。
Meta:预计2025年资本支出将显著增长,尤其是基础设施支出将加速增长,主要原因是基础设施增加带来更高的折旧和运营费用增长。公司表示,计划继续大力投资于AI,为了实现生成式AI的目标,可能需要投入数千亿美元的算力资本支出。

1.3
ScalingLaw打破算力需求天花板,AI服务器打开长期成长空间
我们认为,Scalinglaw的想象空间和Moore’slaw的限制同时拉高了AI服务器的需求上限。具体来看:
ScalingLaw在机器学习和深度学习中主要描述了模型规模、数据量、计算量等因素与模型性能之间的关系。最早提出ScalingLaws的关键论文是OpenAI在2020年发表的《ScalingLawsforNeuralLanguageModels》(Kaplanetal.,2020)。这篇论文系统性地研究了模型参数、数据量和计算量如何影响语言模型的性能表现,提出了以下几个主要结论:
模型参数数量:增加模型的参数数量可以有效提升模型的性能,特别是在较大规模数据集上训练时,较大的模型更具优势。
数据量:增大数据量同样有助于提升模型性能。但数据和模型参数规模的增长并不是独立的,而是有一个最佳的比例。
计算资源:给定相同的计算资源,通常存在一个最佳的模型参数与数据量的组合,使模型达到最佳性能。
边际收益递减:随着模型参数数量和数据量的增加,性能提升的边际效益会逐渐减小,表现为“幂律”关系。
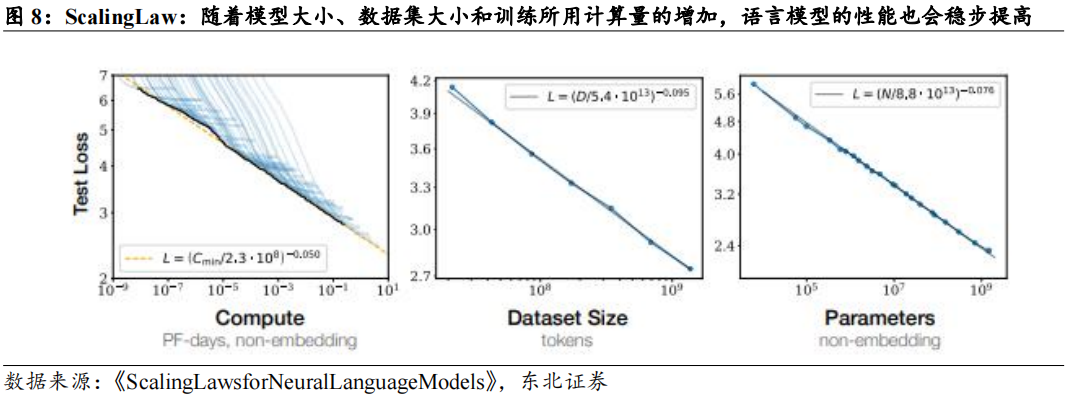
ScalingLaw反映了大语言模型的性能与参数量、数据量、计算资源量成正比,即更优质的模型需要由大参数、大数据量进行训练,同时需要计算速度更快的硬件进行支持。随着大语言模型进入万亿级参数量,AI算力需求同步提升。
单个芯片的计算速度或算力与晶体管的数量呈正相关,而晶体管数量由晶体管密度、面积、芯片架构设计共同影响。
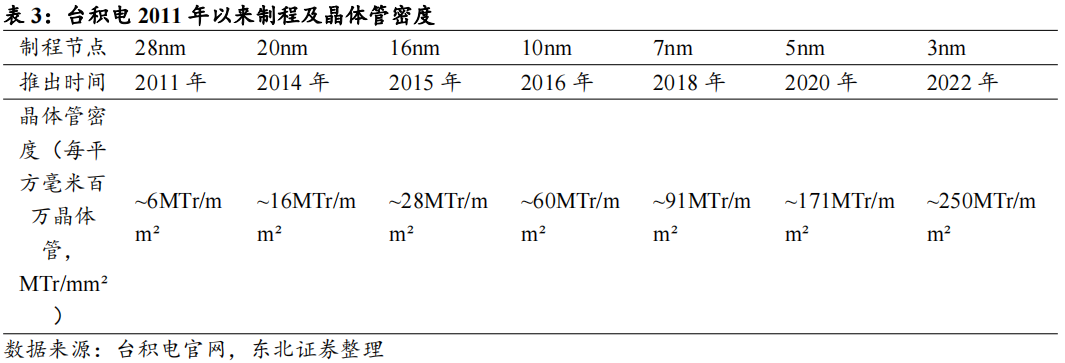
从晶体管密度角度看,Moore’sLaw的放缓限制了晶体管密度的增长,制程的迭代已无法大幅提升芯片的性能。参考台积电工艺,16nm/10nm制程晶体管密度分别为28M晶体管/平方毫米和60M晶体管/平方毫米,晶体管密度增长114%。对比之下,5nm制程晶体管密度为约171M晶体管/平方毫米,3nm工艺晶体管密度约为250M晶体管/平方毫米,密度增长约为46%。根据台积电公开发布的信息,N2(2nm)工艺将使晶体管的密度提升15%。由工艺制程带来的晶体管密度提升已经趋缓,摩尔定律逐步失效。
从芯片面积角度看,~800mm²被认为是芯片面积的上限。超过~800mm²后,制造、成本、良品率、封装、散热等方面的挑战会显著增加,导致生产变得极为困难和不经济。1)良率&制造成本:大面积芯片的缺陷概率更高,每个晶圆上的缺陷随机分布的,面积越大,受到缺陷影响的概率越高。2)封装:面积更大的芯片需要更复杂的封装,尤其在大功率的高性能芯片中,这会导致封装设计和制造成本上升。3)光刻设备限制:随着芯片面积的增大,光刻的曝光和对准精度需求也提高。
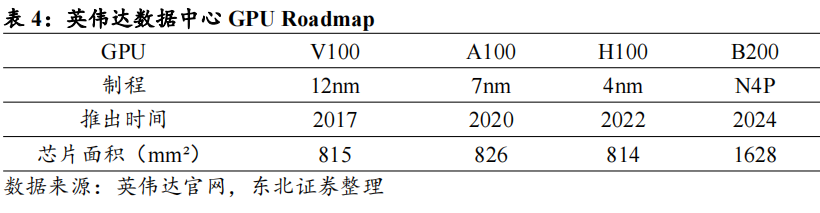
基于以上结论,单个芯片的算力存在瓶颈。尽管目前芯片公司采用Chiplet架构,将一个大面积芯片的功能拆分为多个较小的模块,通过高速互连技术组合在一起,但这种方式带来的算力增长依旧有限。由摩尔定律放缓带来的单芯片性能提升瓶颈越来越明显,万亿参数级别的大模型训练可能需要更多的AI服务器、更大规模的算力集群来实现。
模型发布进展迅猛,为AI算力投入增长带来持续性。进入大模型时代以来,模型架构经历了由传统千亿参数Transformer模型到万亿MoE大模型,到AI视频模型,再到推理模型(o1)的转变。所需的训练算力和推理算力的消耗也相应发生变化:
1.传统Transformer模型(如BERT、GPT系列)依赖于自注意力机制,参数规模巨大,通常达到数亿到数千亿级别。自注意力机制的计算复杂度随序列长度呈二次增长,导致训练大型模型时算力需求极高。
2.MixtureofExperts(MoE)模型在训练中需要管理多个专家的选择和优化,训练过程比传统Transformer更复杂。门控机制需要进行额外的学习,确保正确的专家被选中。此外,稀疏激活也可能导致负载不均衡问题,需要进行负载平衡优化。稀疏激活的特性使得其总体推理效率通常仍优于传统的大型Transformer。
3.AI视频生成模型(如Sora):视频数据的高维度(时间和空间)导致计算量呈指数增长。模型需要处理时空特征,模型通常包含3D卷积或时序建模机制。推理方面,如果需要实时视频生成,算力需求极高。
4.逻辑推理模型(如o1):在训练阶段算力需求类似于大语言模型。但因为需要调用思维链CoT,推理侧需求出现倍增。
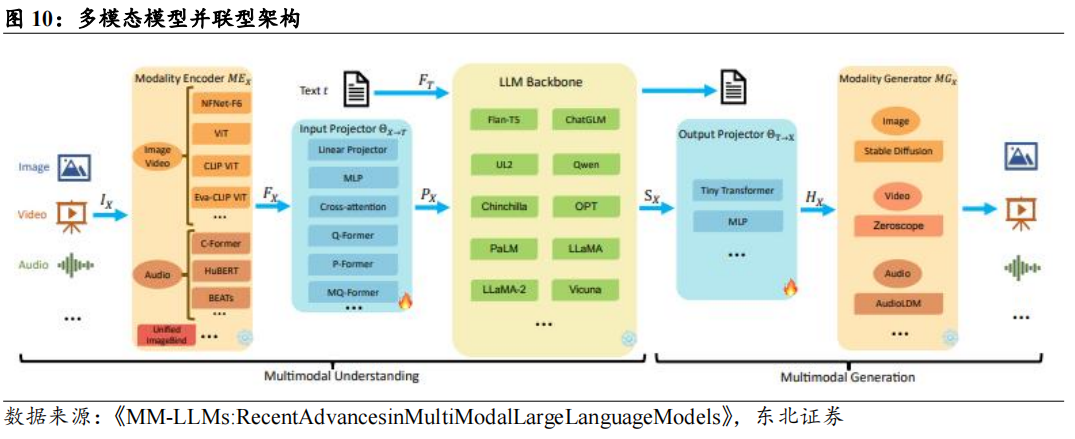
训练侧:大模型支持更多模态,参数规模扩展增加算力需求。随着多模态模型GPT-4(Vision)和Gemini的首次亮相,多模态模型的研究从早期的多模态理解主机按过渡到多模态内容生成。当前多模态大语言模型采用并联式框架,多模态数据送到各自模态的编码器后转换为大语言模型的文本编码,再由大语言模型处理后,经过特定模态的转换器后输出。未来的多模态模型可能会促进多模态融合,即在不同数据模态之间实现无缝的信息共享和转换,构建通用表征空间,使文本、图像、音频等模态的信息在共享空间中自由传递和相互影响,从而增强理解和生成能力。整合不同模态信息的复杂结构可能会导致参数量、模型的层数、计算单元显著增加,多模态也将带来数据量需求的提升,从而导致训练侧算力需求扩大。

推理侧:视频生成、推理优化模型带动推理侧算力需求指数级增长。目前最新发布的视频生成模型大多数为DiT模型,相较于前一代Video Diffusion Model和大语言模型,除本身参数量增长外,模型不仅要按帧生成图片,还需要引入时间这一维度,捕捉帧间关系,从而增加了推理的计算量。而OpenAI在2024年9月发布的o1模型则将Scaling Law扩展至推理,在推理过程中引入思维链(CoT,Chain of Thought),将输入问题拆解为多个逻辑步骤,每增加一个步骤,推理计算量成倍增加。参考OpenAI对于o1模型的定价,逻辑推理类模型的推理算力消耗至少为同等参数量大语言模型的3-4倍。
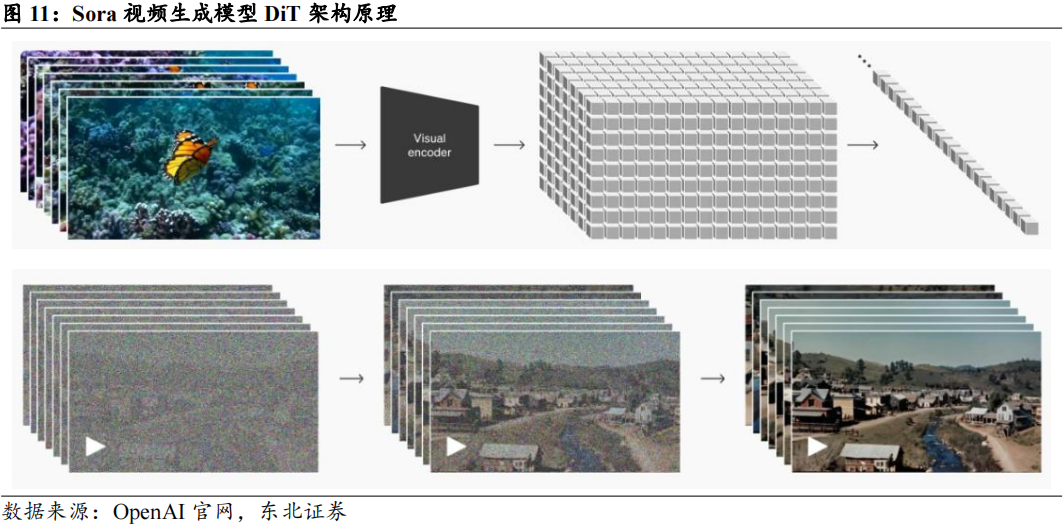

1.3
高端AI服务器形态发生变化,产业链得到重塑
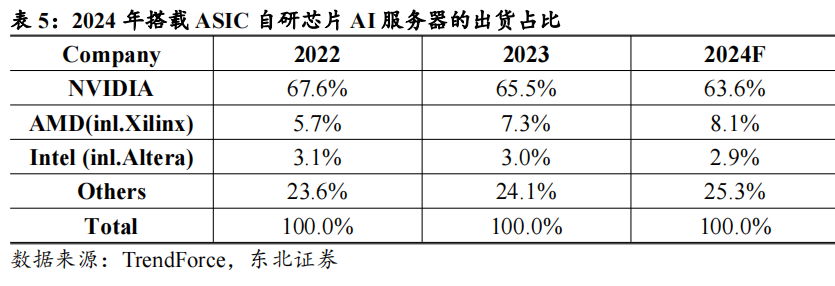
AI服务器综述:训练端产业链由英伟达主导,推理端百花齐放。根据TrendForce,从AI服务器搭配AI芯片类型来看,预计2024年主流搭载GPU的AI服务器占比为71%,其中英伟达凭借H200产品,市占率逼近9成,AMD市占率约为8%;CSPs自研ASIC服务器出货量占整体AI服务器的比重有望达到26%。而展望2025年,市场对于高阶AI服务器需求仍强,尤其以英伟达新一代Blackwell将取代Hopper平台成为市场主流,且出货形式有望从8卡HGX服务器向机柜转移。
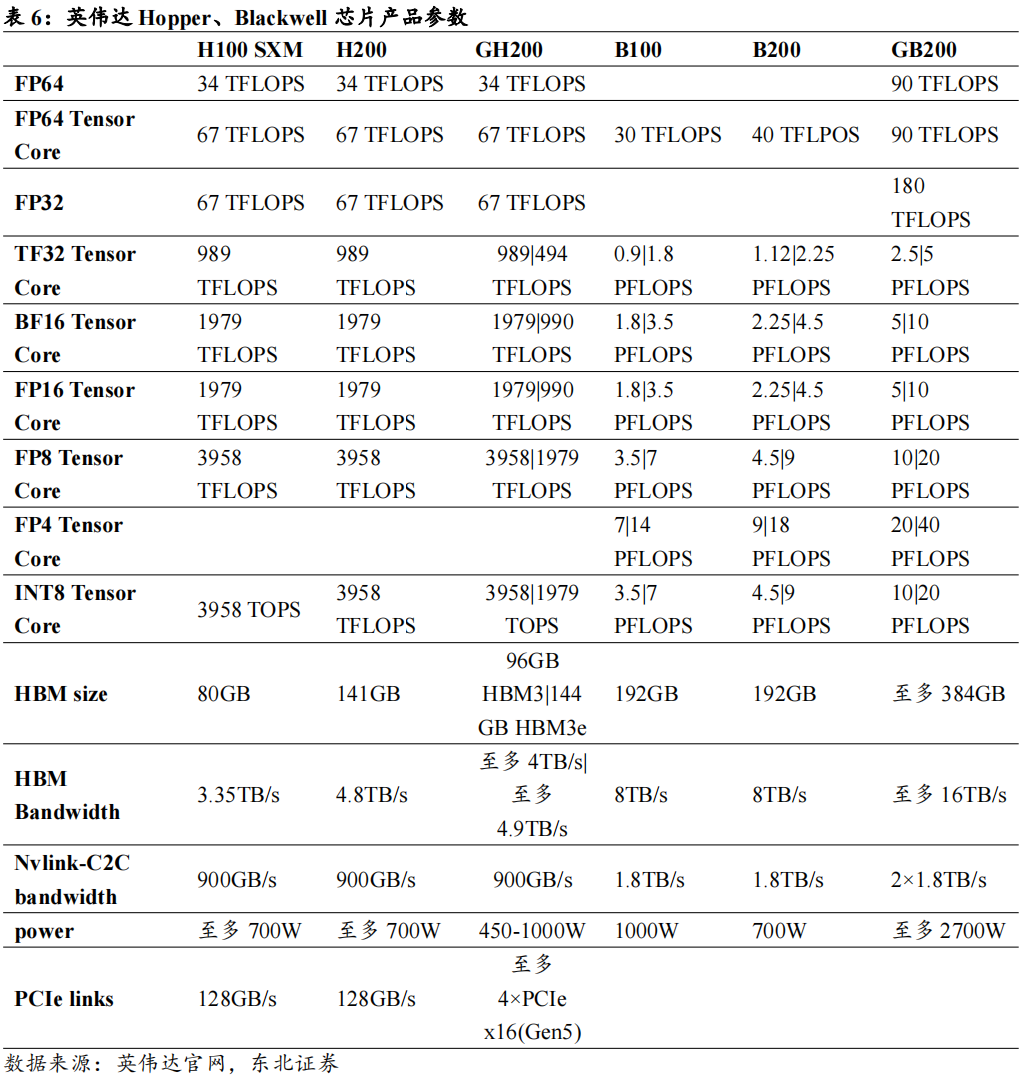
英伟达下一代Blackwell架构的服务器出货形态较Hopper发生较大变化。从产品体系来看,目前Blackwell系列产品包括超级芯片GB200对应的机柜级产品、高性能HGX系统HGXB100/B200等。Blackwell拥有2080亿个晶体管,是NVIDIA Hopper GPU晶体管数量的2.5倍以上,并使用台积电(TSMC)为NVIDIA量身定制的4NP工艺制造,单芯片算力高达20petaFLOPS。B200将两个晶片合并为一个GPU,显著提升了计算能力,并通过单一的、速度为10TB/s的高带宽接口NV-HBI连接。GB200超级芯片由2颗Blackwell GPU和1颗Grace CPU组成,并通过NVlink-C2C进行连接,提供900GB/s双向带宽。在GB200超级芯片的基础上,还设计了GB200 NVL72集群,在一个机柜级设计中连接了36个GB200超级芯片。Hopper系列产品则包括HGXH200/H100系统和GH200。
HGXH200/H100为配置了8个GPU的服务器产品;GH200超级芯片由1颗Hopper GPU和1颗Grace CPU组成,通过NVlink-C2C进行连接。
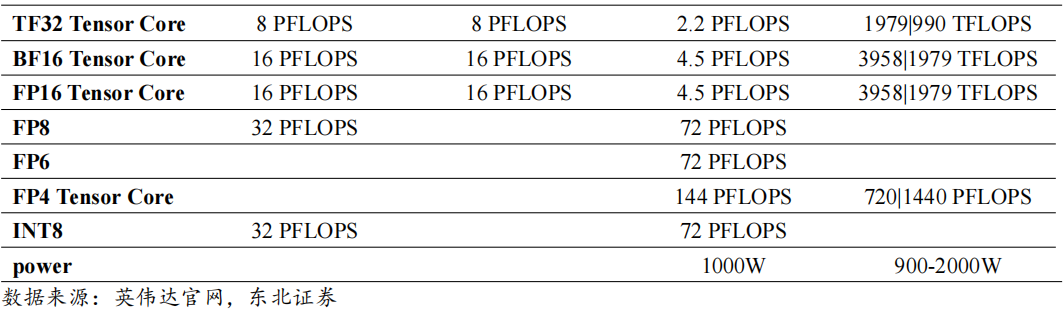
预计机柜级产品将成为明年Blackwell架构产品出货的主要形式。鸿海发言人曾在法说会上回应,预计今年第四季度小量生产GB200服务器,2025年大量出货;鸿海年度科技日上,董事长刘扬伟表示市场对Blackwell芯片的需求达到“疯狂程度”,计划到2025年产能达到20000台英伟达NVL72机柜。
GB200超级芯片将CPU和GPU都位于同一块PCB板上,降低了插入损耗,提升了CPU和GPU之间的通讯能力;GB200NVL72引入了尖端功能和第二代Transformer引擎,支持FP4AI,与第五代NVIDIA NVLink结合使用时,可为万亿参数语言模型提供30倍的实时LLM推理性能;与NVIDIAH100风冷基础设施相比,GB200在相同功率下可以提供25倍的性能。因此对于Blackwell架构,GB200机柜级产品在算力、连接、功耗方面较8GPUHGX服务器更具有性价比,将成为未来的主要出货形式。
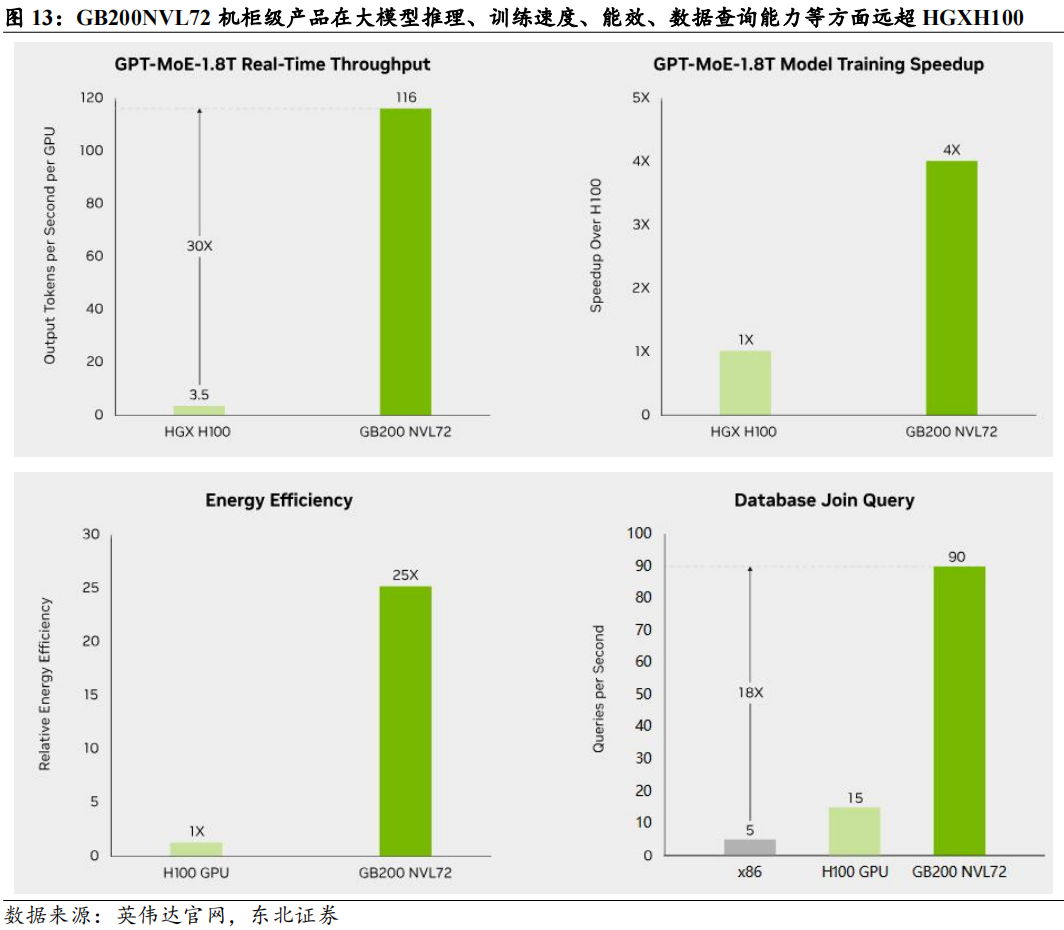
英伟达GB200机柜预计将推出4种外形尺寸。除GB200NVL72形式的机柜外,根据semianalysis,英伟达还推出了GB200NVL36*2,GB200NVL36x2(Ariel)和x86B200NVL72/NVL36x2形态,为客户提供更多选择。具体来看:
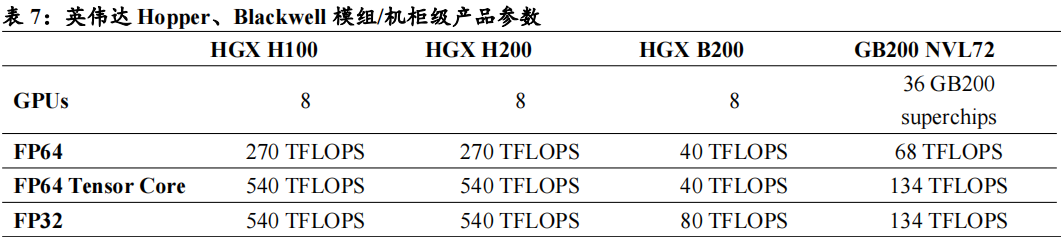
GB200NVL72:每个机架大约120kW功率,由18个1U计算托盘和9个NVSwitch托盘组成。每个计算托盘高度为1U,包含2个Bianca板。每个Bianca板由1个Grace CPU和2个Blackwell GPU组成。NVSwitch托盘包含两个28.8Tb/sNVSwitch5ASIC。
GB200NVL36*2:是两个并排互连的机架,每个机架包含18个Grace CPU和36个Blackwell GPU。每个计算托盘高2U,包含2个Bianca板。每个NVSwitch托盘都有两个28.8Tb/sNVSwitch5ASIC芯片。每个NVSwitch托架都有18个1.6T双端口OSFP壳体,可水平连接到一对NVL36机架。每个机架的功率和冷却密度为每机架66kW,总共为132kW。NVL36版本预计将成为无法支持机架密度120kW数据中心的首选。
GB200NVL36*2(Ariel):在NVL36x2的基础上,将计算托盘中的Bianca板替换为Ariel板,包含1个Grace CPU和1个Blackwell GPU。这一机架主要由Meta用于推荐系统训练和推理工作负载,这类任务对CPU内核要求更高。
x86B200NVL72/NVL36x2:或将于2025年二季度推出,用x86CPU替代原本GB200中的Grace CPU。
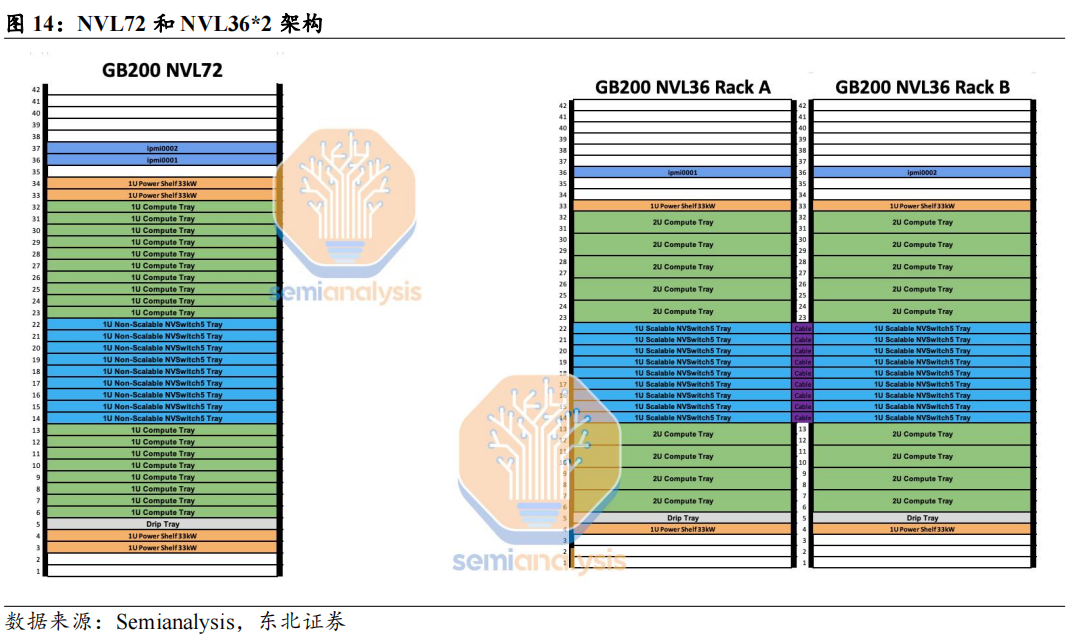
在HGX、DGX平台基础上,面向GB200机柜,英伟达预计还将推出MGX版本,给予CSP厂商定制空间,扩大用户的选择面。DGX为英伟达标准化平台,不支持定制,DGX GB200机柜预计将由英伟达直接向客户销售,主要客户群体包括中小数据中心、主权数据中心等。MGX提供模块化参考设计,OEM和ODM合作伙伴可以用不同的用例构建定制的解决方案,允许GPU、CPU、DPU的不同配置,包括Grace、x86或其他Arm CPU。MGX的主要客户群体为大型CSPs。HGX/DGX/MGX三种模式在产业链分工上也略有差异。HGX模式下,GPU模组、板卡、服务器的制造环节几乎全部由ODM厂商进行,最终交付给品牌服务器厂商出货给不同客户;对于DGX GB200机柜,芯片制造、封装环节完成后,由ODM厂商代工,将其组装为Compute Board、Switch Board等,再根据英伟达提供的标准,组装为机柜,并交付给英伟达,由英伟达出货给终端客户;对于MGXGB200机柜,ODM完成Compute Board、Switch Board等环节的组装后即交付英伟达,再由英伟达将标准的模块化组件出货给服务器ODM厂商,根据CSP的设计要求组装为机柜并交付。对于GB200机柜级产品,ODM厂商的分工均较HGX模式发生了变化,由于机柜本身价值量提升,技术难度相应增长,ODM厂商贡献的价值也将随之提升。
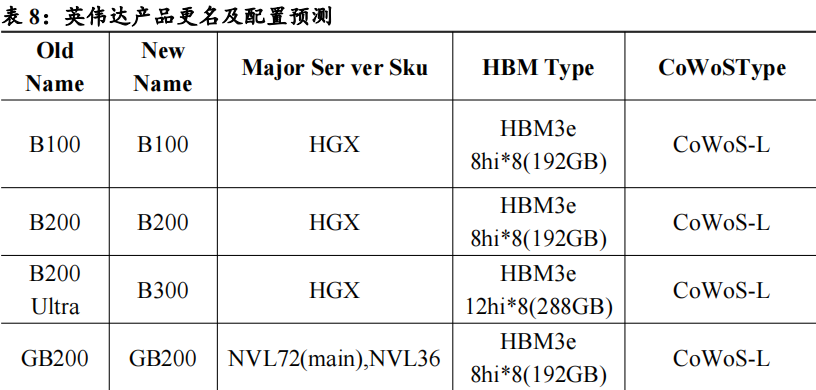
明年预计将推出B300等新产品形态,进一步提升显存,为CSPs、OEM厂商提供更多选择。根据Trendforce10月报告,NVIDIA最近将其所有Blackwell Ultra产品更名为B300系列:B200Ultra更名为B300,GB200Ultra更名为GB300,B200AUltra和GB200AUltra分别更新为B300A和GB300A。B300系列预计将于2025年第二季度和第三季度之间推出;B300A专门针对OEM客户,预计在2025年第二季度开始量产。Nvidia的B100、B200和GB200配备192GBHBM3E内存,使用8-HiHBM3E内存堆栈,B300和GB300将配备288GB的HBM3E,使用8个12-Hi堆栈;B300A和GB300A将配备144GB内存,使用四个12HiHBM3E堆栈。机柜级GB300NVL72产品预计将采用类似GB200NVL72的架构,一个计算托盘内包含2个CPU和4个GPU;GB300ANVL36则减少了CPU的比例,CPU:GPU=1:4,为客户提供更多CPU/GPU配比选择。

2 工业富联:GB200产业链的重要一环
2.1
服务器ODM核心参与者,受益于CSP定制化需求增长
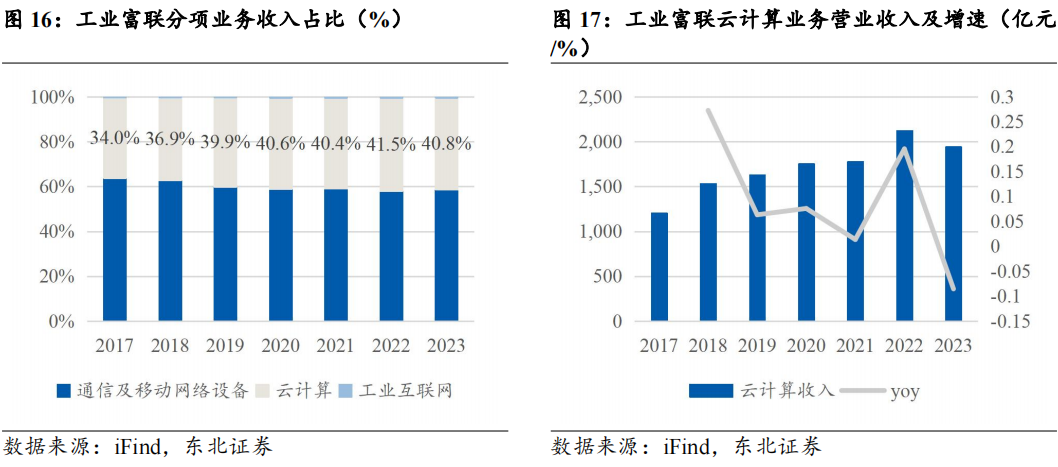
公司云计算业务受AI拉动已呈现出高速增长态势,占整体收入比例提升。工业富联的主要业务包括通信及移动网络设备、云计算、工业互联网。本篇我们将着重分析公司的云计算业务。2023年公司云计算实现营业收入1943.07亿元,占整体营收的比重为40.79%,为公司第二大业务。2024年前三季度,云计算收入同比增长71%,其中云服务商收入同比增长76%,占比46%;AI服务器占整体服务器营收比重提升至45%,收入同比增长228%。2024Q3,公司AI服务器占整体服务器营业收入比重提升至48%,占比逐季提升。通用服务器板块也持续回温,2024年前三季度营业收入同比增长22%。
工业富联云计算业务包含服务器、存储设备、云服务设备高精密结构件。公司服务器领域已实现前端到后端的全产业链覆盖,服务器业务的主要客户为品牌服务器厂商(如Dell、HPE)和云服务提供商(CSP,如Amazon),品牌服务商提供服务器及相关解决方案给到终端企业及政府单位、电信运营商、有线电视运营商等。
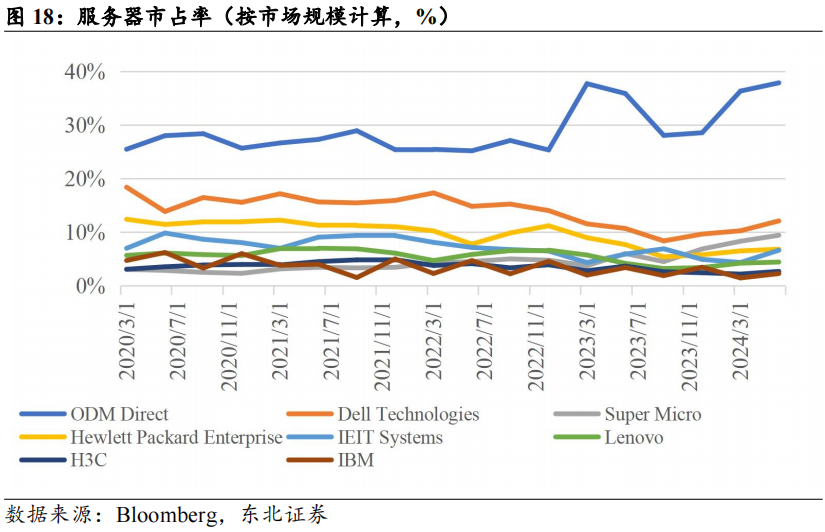
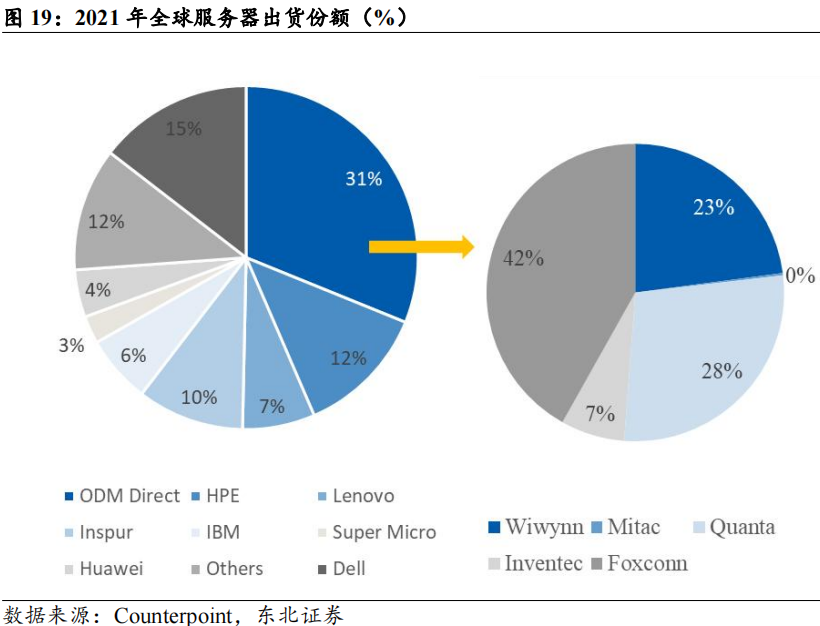
ODM Direct服务器市场份额持续提升,云计算为白牌服务器带来发展机遇。根据Bloomberg数据,截至2024Q2,全球服务器市场规模达到542亿美元,其中ODM direct市占率连年提升,由2020年初的25.5%提升至38%;根据Counterpoint,2021年ODM Direct实现收入302亿美元,其中富士康实现收入126亿美元,占比达到41.8%。云计算产业的发展使得服务器采购向头部云厂商集中,而云厂商为了体现技术、服务的差异,普遍采购定制化服务器,直接向ODM厂商下单,由ODM根据要求提供代工、组装服务后出货给云厂商。工业富联涉及服务器生产的L1-L12所有环节,同时公司以往积累的供应链基础使公司具备较强成本控制能力和交付能力,能够更好地满足CSP的定制化需求,提升CSP客户的性价比。
2.2
与英伟达密切合作,有望提升机柜级方案中的价值量
富联在AI服务器业务中保持了与英伟达的密切合作。富联与英伟达的合作可追溯至2017年,深度参与了英伟达首台AI服务器的前期研发和产品设计。在英伟达近期推出的AI服务器供应链中,工业富联是A100/H100/B100/B200板卡的独家代工供应商;在GPU基板方面,公司也占据了较高的市场份额。公司还参与了HGX服务器的母版、服务器整机、机柜等制造环节,并出货给品牌服务商和云厂商。
在GB200机柜的生产制造环节中,富联参与的环节显著增加,份额有所提升。首先,GB200相比传统的HGX服务器,增加了计算托盘和交换托盘的制造环节,富联深度参与了托盘的代工生产环节,价值量较板卡、基板有显著提升;其次,GB200作为机柜级方案,涉及服务器制造L12等级,较整机L10等级的难度更高,对ODM厂商的技术能力也随之提升,而富联作为L1-L12等级全覆盖的龙头ODM厂商,其生产制造的技术能力更能够获得英伟达及头部客户的认可。同时,英伟达在GB200中的参与度提升,DGX模式的标准化机柜实际客户为英伟达,而MGX模式也需要将计算托盘、交换托盘制造好后交付英伟达,CSP客户于英伟达方面采购这些模块后,加入定制化设计,并交由ODM厂商生产。基于英伟达和富联持续的密切合作关系,富联能够深入参与到DGX模式和MGX模式的代工中,份额及ASP均显著提升。此外,10月8日,富士康母公司鸿海宣称公司正在墨西哥建设全球最大的英伟达GB200制造厂,以帮助缓解外界对英伟达Blackwell平台的巨大需求;董事长刘扬伟强调,鸿海的供应链已经准备好,包括垂直整合的制造能力、还包括支持GB200服务器基础设施所需的先进冷液和散热技术。新工厂的设立有望持续扩大GB200产能,强化供应链稳定性。
富联布局液冷业务,有望大批量供应于GB200机柜。在英伟达2024 GTC 大会上,工业富联旗下子公司鸿佰科技(Ingrasys)出席展出了与英伟达合作开发的新一代 AI 服务器与液冷机柜等多项技术和解决方案。展出的 AI 服务器产品包括 Ingrasys NVIDIA MGX 服务器,提供市场上最多样化的1U/2U/4U NVIDIA MGX 服务器产品组合,采用模块化设计架构,实现高灵活、高扩展的 GPU、DPU 及 CPU 组合,用符合成本效益的方式打造多种服务器配置,同时缩短上市时间,满足客户不同加速运算需求;搭配液冷解决方案的 AI 加速器GB6181,具备高效散热能力,搭载八个 NVIDIA H100 Tensor Core GPU,适用于高效能的AI 训练,提供每秒32千兆次浮点运算(PFLOPS)的高性能算力,同时可轻松集成到客户数据中心部署的 OCP ORv3 架构中支持下一代强大 GPU,为高性能人工智能数据中心提供强大算力支持。此前,工业富联还推出了针对PCIe GPU的采用液冷技术的模组化服务器,为客户提供适配多种服务器的液冷方案。对于下一代GB200产品,单超级芯片功率或达到2700W,NVL72总功率或将超过120kW,使用液冷或成为发挥Blackwell最大潜力的必备。
3 盈利预测及投资建议
3.1
主营业务收入拆分及预测
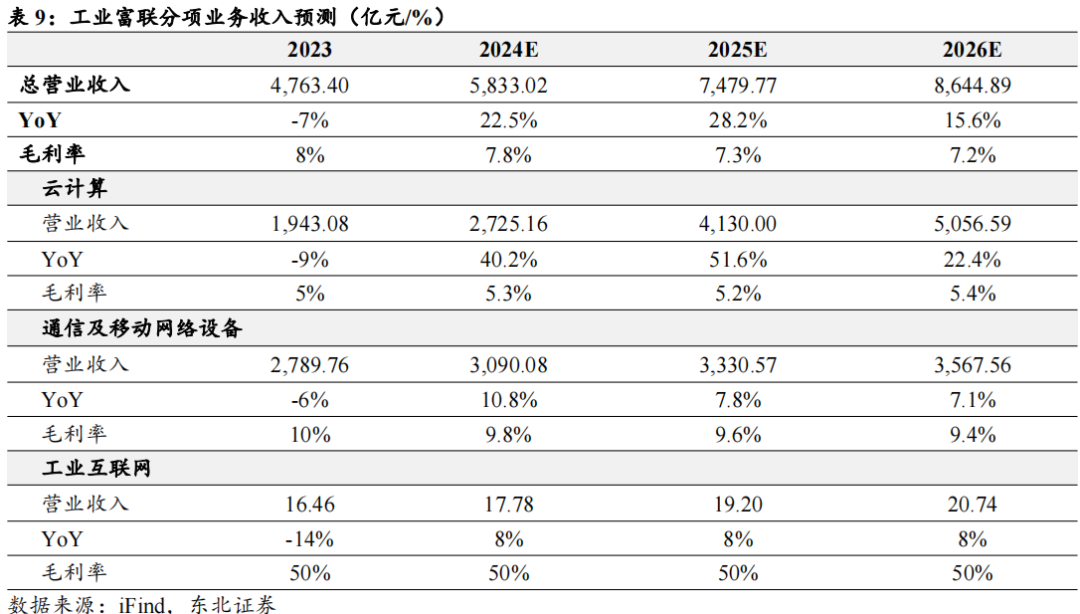
云计算业务是公司收入增长的重要驱动因素,因此我们对该业务进行了详细的拆分和测算,并作出如下假设:
1)云计算:包括AI服务器及通用服务器。受益于北美云厂商资本开支增长、供给侧产能提升等因素,我们预计2024-2026年,公司云计算业务收入有望达到2725/4130/5057亿元,同比增长40%/52%/22%;预计2024-2026年云计算业务毛利率为5.3%/5.2%/5.4%。
2)通信及移动网络设备:包括网络设备、电信设备、精密结构件等业务。预计AI将拉动高速交换机需求放量,iPhone新机型出货也将拉动精密结构件业务收入稳健增长。预计2024-2026年通信及移动网络设备业务收入有望达到3090/3331/3568亿元,同比增长10.8%/7.8%/7.1%。3)工业互联网:预计2024-2026年收入分别为17.8/19.2/20.7亿元,同比增长8%/8%/8%。
3.2
投资建议
我们认为工业富联作为英伟达核心供应商,将成为AI 资本开支高速增长、算力投入持续提升的受益者。具体来看:1)北美云厂商仍将保持高额资本开支和AI算力开支;2)英伟达机柜级产品出货在即,公司在该产品或将拥有更高的市场份额;3)公司在液冷等方面的储备有望增强公司的核心竞争力,并提升单台价值量。
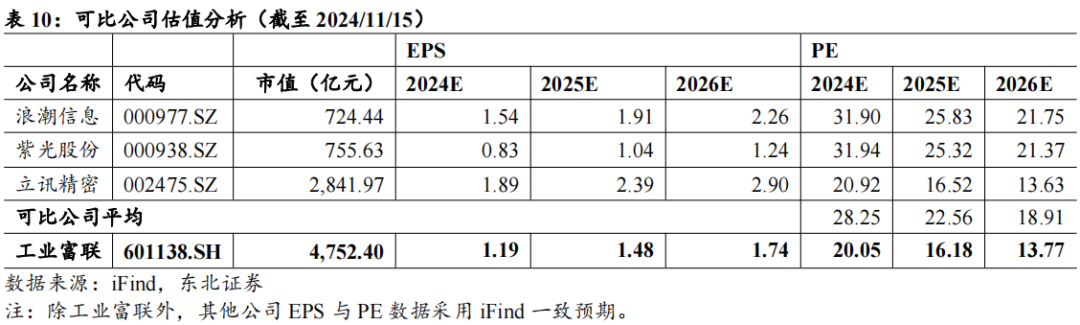
公司云计算业务、通信网络设备、精密结构件业务分别与浪潮信息、紫光股份、立讯精密的主营业务较为类似,因此我们选取这三家公司进行对比。可比公司2024-2026年对应的平均市盈率为28x/23x/19x。我们预计公司将实现归母净利润237/294/345亿元,同比增长13%/24%/18%。对应PE分别为20x/16x/14x。给予“买入”评级。
4 风险提示
1、技术迭代不及预期的风险;
2、供应链稳定性下降的风险;
3、GB200量产进度不及预期的风险;
4、行业竞争加剧,毛利率下降的风险。

 VIP复盘网
VIP复盘网
