


当前AI算力重心由训练端转向推理端,叠加海外资本开支向上,ASIC作为推理主要形式加速爆发。
全球各大CSP谷歌、亚马逊、META、微软等均加速自研ASIC。
ASIC受到科技巨头欢迎的本质是芯片设计可以更贴合自己的模型,提升讯推效率,以及降低成本并且保持技术路线独立性。
随着ASIC高度定制化和能效优势趋势逐渐清晰,有望重塑全球算力市场格局,国产ASIC产业链也将迎来新一轮机遇。
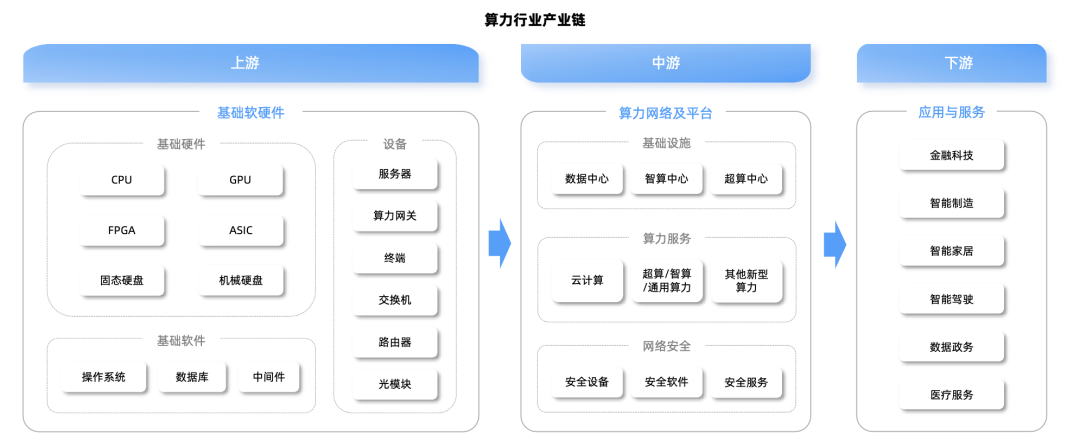
本文重点解析ASIC芯片产业链核心赛道以及竞争格局。
01
ASIC行业概览
算力芯片主要有CPU、GPU、FPGA和ASIC四种形式。
这几种架构在功耗、价格和性能上各有侧重,适用于不同场景的需求。
算力芯片四种形式对比:
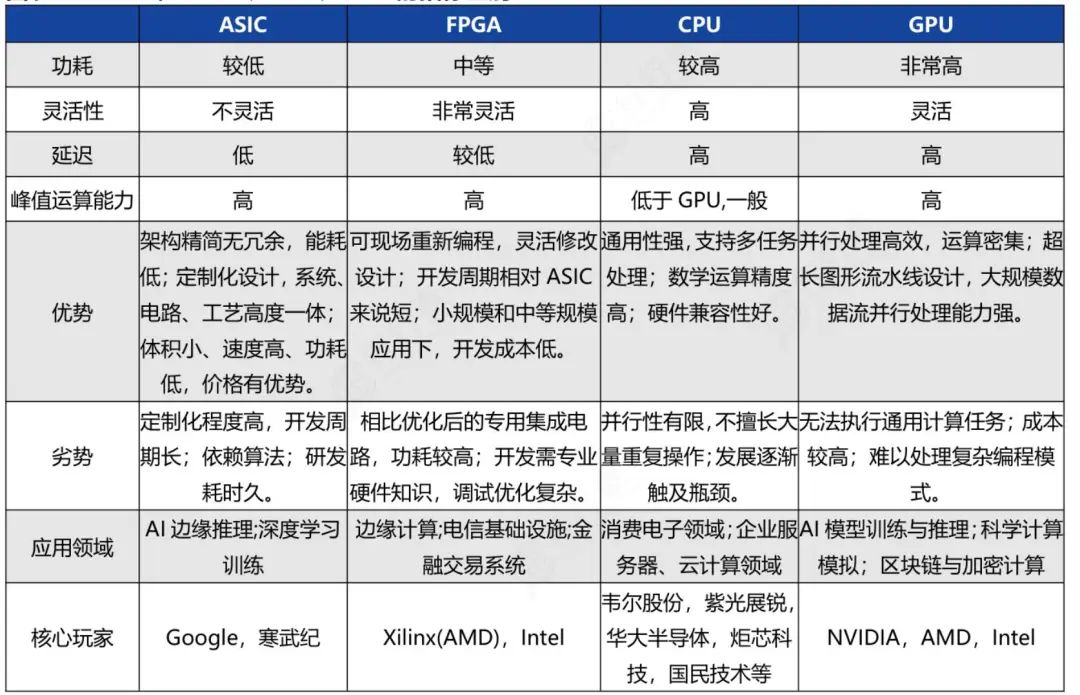
GPU:通用算力卡,是目前AI算力芯片的主流选择,英伟达是该领域的领导者,像国内的海光信息DCU也属于通用GPU。
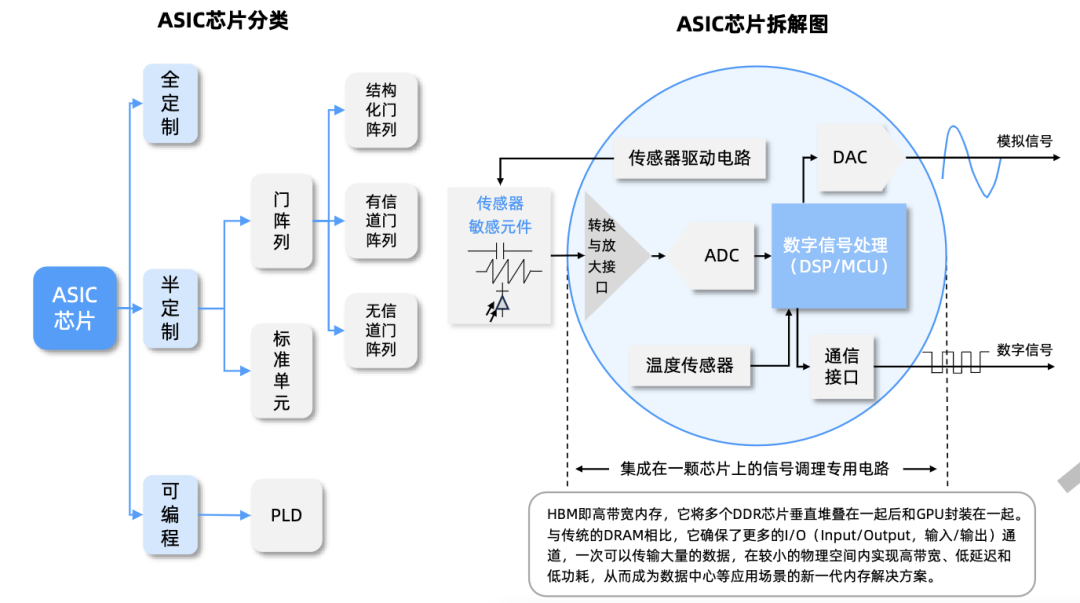
ASIC芯片:专用定制芯片,是针对特定用途定制的集成电。ASIC面对专项任务,主要应用于深度学习加速,在大模理推理侧相较其他AI芯片在效率和速度方面更具优势,且在量产成本、功耗和性能方面表现出色。海外科技巨头博通和MARVELL是ASIC领域的领先者,大型云服务厂商多与两者合作,比如谷歌的TPU就是与博通合作开发的,国内华为昇腾也属于ASIC路线。
当前AI由投资驱动转向应用拉动,推理需求成为AI云和端侧的主要成长动能,JPM预计2026年开始占比有望超过60%。
资料来源:行行查
02
ASIC芯片市场竞争格局
当前国内外厂商加速ASIC芯片布局。
海外科技巨头博通与Marvell分别以55-60%和15%的市占率主导ASIC赛道。
博通:在ASIC领域处于主导地位,特别是在数据中心和人工智能加速方面,是大型云服务厂商定制ASIC芯片的首选合作商,获得了谷歌、微软、Meta等科技巨头的青睐。
Marvell:正量产其首批AIASIC项目(Tranium2与AxionCPU),并将在2026年量产后续项目(Tranium3、Maia3nm),并且已获得亚马逊与微软2nmASIC设计订单。
科技巨头加速推出专门用于人工智能计算的ASIC芯片。
谷歌:2016年在GoogleI/O大会发布首款TPUASIC。今年4月,谷歌发布第七代TPUIronwood,也是谷歌第一代专为推理设计的AI加速芯片,FP8峰值算力4614TFLOPS,带宽192GB,整体性能直逼英伟达B200。
谷歌最新Ironwood与TPUv4、TPUv5p性能对比:
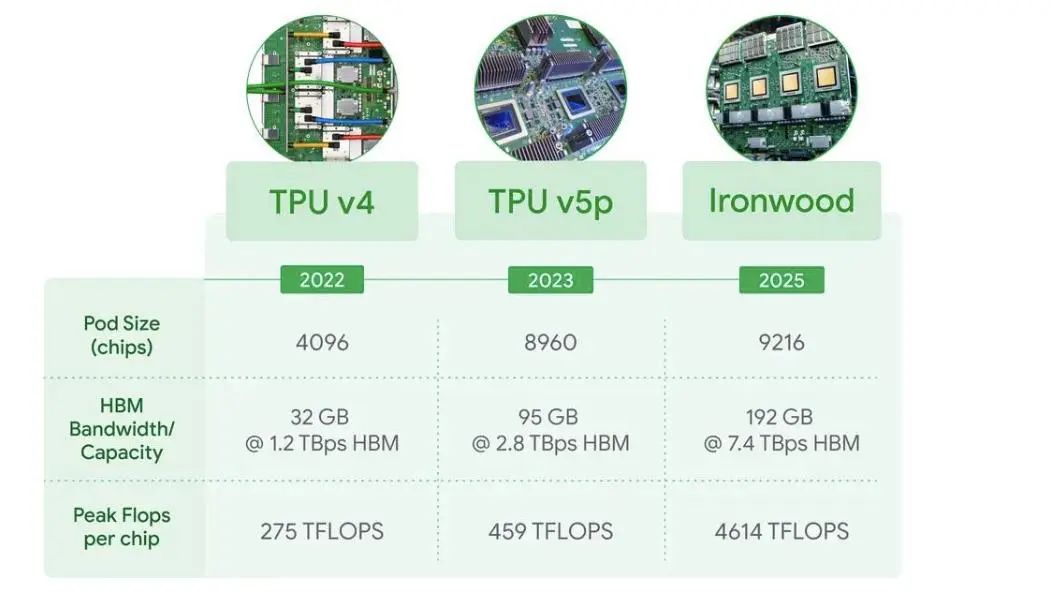 资料来源:谷歌官网
资料来源:谷歌官网
Meta:计划大规模部署其自研的AI加速芯片(MTIA),将是AI服务器市场格局演变的重要里程碑,将对相关供应链产生显著影响。
英伟达:今年5月,英伟达在COMPUTEX重磅发布NVLinkFusion,通过提供IP或接口,支持第三方ASIC加速芯片、CPU等接入英伟达计算体系。
NVLinkFusion支持ASIC融入英伟达计算体系:

国内百度、阿里和腾讯等互联网大厂自研AI芯片大多采用ASIC架构,主要应用于自身业务场景,典型的ASIC芯片例如:阿里平头哥推出含光800AI芯片;百度昆仑系列AI芯片。
华为昇腾、寒武纪、燧原科技、黑芝麻和地平线等厂商也基于ASIC架构设计芯片,在深度学习模型的训练和推理方面具有高性能和高效率。ASIC产业链各环节相关布局厂商还包括芯原股份、灿芯股份、澜起科技、全志科技、国科微、淳中科技、山石网科等。
03
光模块&CPO
当前AI驱动数据中心网络高速迭代,叠加ASIC需求高增,超大规模(百万卡)ASIC部署使得架构层数增加,带动光模块用量和相关新技术水涨船高。
800G/1.6T高速光模块26年需求上修,下一代互连技术产品CPO预计将在今年下半年交付。
海外方面,ASIC配套的网络架构变化,特别是META的高配比Back-End网络架构,使得光模块与AISC的比例提升。
国内方面,受益于AI算力基建加速,400G 高速光模块出货量快速增长,BBAT以及华为对于高速光模块的需求也有望快速提升,相关光模块和光芯片厂商加速布局。例如,网络架构变动最大的Meta链相关厂商旭创、新易盛、太辰光、源杰、仕佳光子;1.6T光模块26年上修相关厂商旭创、新易盛、天孚、汇绿生态等;国内厂商有望突破北美云厂商:联特、华工、光迅、剑桥;设备商/新云厂商需求的供应链剑桥、腾景、汇率生态等;CPO天孚通信、罗博特科、剑桥、太辰光以及上游光芯片和MPO相关厂商博创、太辰光、仕佳光子、光库科技、源杰科技等。
光模块技术演进趋势:光学部件与ASIC芯片集成度不断提升
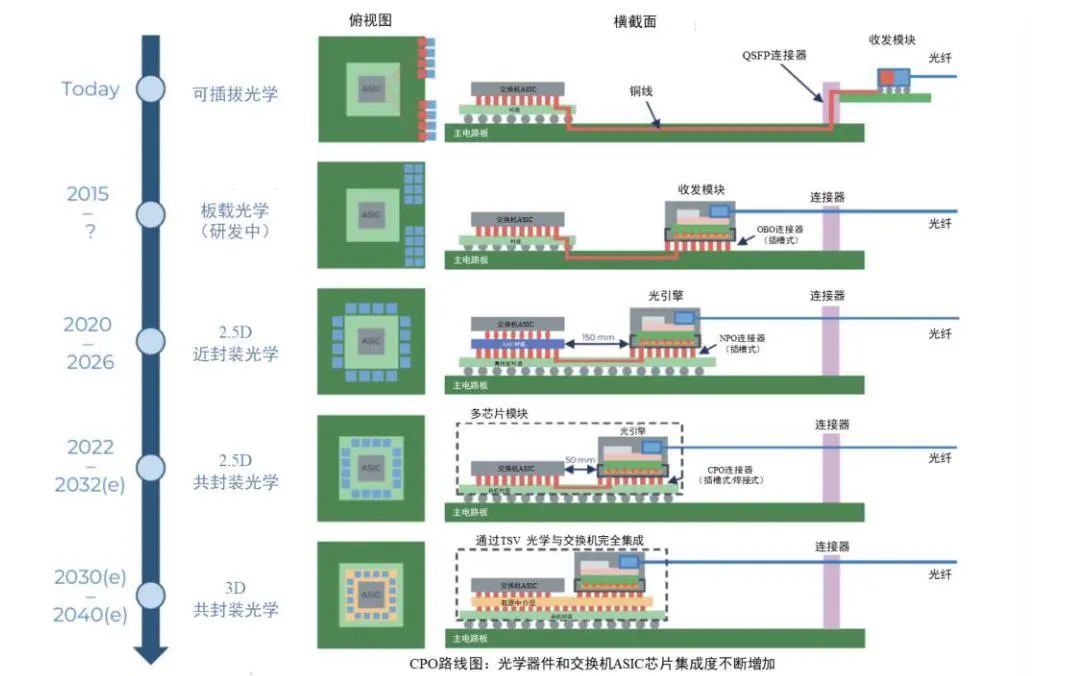 数据来源:Yole
数据来源:Yole
04
交换机
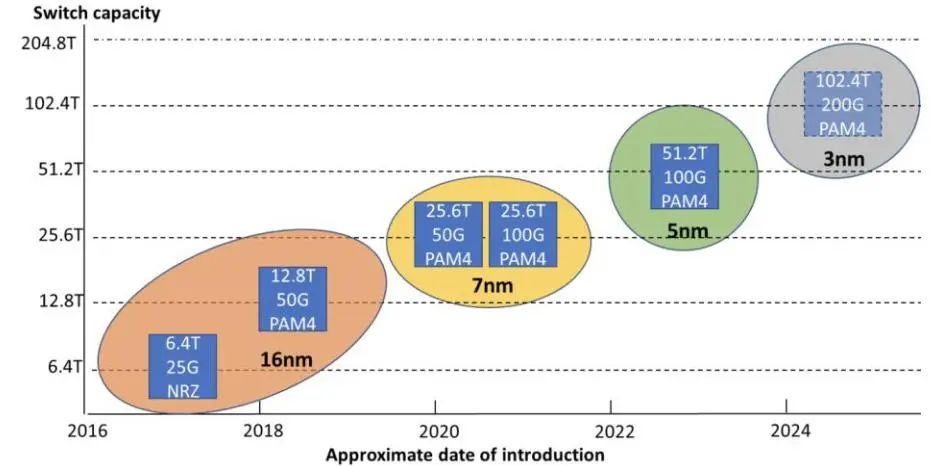
从2016年起至今,交换机容量经历了从6.4T到102.4T的巨大飞跃,同时工艺技术也从16nm逐步演进至3nm,数据传输效率也进一步增强。这些变化共同推动数据中心网络的高速智能化发展。
而当前以ASIC为核心的算力集群中交换机价值量占比进一步大幅提升。
Meta部分集群建设中网络投入占比持续加速,高速交换机赛道迎来新一轮机遇。
受益互联网厂商资本开支增长,数据中心交换机作为重要互联设备需求同步上行。
交换机市场格局行业集中度较高。华为、新华三(紫光旗下)和锐捷网络占据大部分的市场份额,思科和中兴通讯紧随其后。随着新华三在海宁的合作产业园区扩产,交换机代工厂商共进股份和菲菱科思等厂商有望协同发展。此外,盛科通信在商用以太网交换芯片国内排名第一,全球第四。
数据中心交换机ASIC发展:
 数据来源:Cisco《800GClientOptics in theDataCenter》,Earlswood Marketing
数据来源:Cisco《800GClientOptics in theDataCenter》,Earlswood Marketing
05
高速铜缆连接
随着ASIC在数据中心算力集群中的广泛应用,柜内连接器作为关键组件,需求显著增长。
ASIC芯片数量的增加以及光、铜、PCB等数通设备配比的提高,推动铜连接市场放量。
亚马逊、Meta、微软等科技巨头在ASIC柜内铜连接用量上较高。据测算,柜内连接器的ASIC需求占比或由2025年的18%提升至2026年的38%,显示出强劲的增长势头。
高速铜缆用于服务器和存储设备之间的高速数据传输,满足数据中心对高带宽和低延迟的需求,是柜内连接的核心趋势。国内主要参与厂商包括兆龙互联、博创科技、沃尔核材、瑞可达、神宇股份、立讯精密、鼎通科技等;高速背板连接器主要参与厂商包括华丰科技、意华股份、庆虹电子、中航光电、陕西华达、神宇股份、鸿腾精密等。
06 PCB
ASIC芯片在算力密度上通常低于GPU,为弥补这一差距,需通过更高层数的PCB走线实现信号完整性和高速传输。
例如,AI服务器用PCB层数已从12-16层向20-28层演进,部分高端场景甚至要求32层以上,直接推高单卡PCB价值量。
ASIC算力集群需要通过Chiplet技术或2.5D/3D封装实现多芯片协同,这对PCB的布线密度、阻抗控制提出更高要求。例如,博通Tomahawk 5交换机芯片采用7nm制程,其配套PCB需支持56Tbps带宽,层数较上一代增加40%。
从需求端来看,算力升级对PCB制程升级趋势十分明确。
近年来国内算力PCB份额持续提升,国产化进程全面提速。头部厂商沪电股份、胜宏科技、生益科技、景旺电子、深南电路、广合科技、南亚新材等在产业链各环节加速布局。
在英伟达股东大会上,黄仁勋强调AI需求持续强劲,重申英伟达处于为期十年的AI基础设施建设浪潮的起点,明确“一年一更新”产品路线图,锁定算力产业链的升级节奏。网络架构和ASIC的发展有望呈现出新一轮高增长态势。

 VIP复盘网
VIP复盘网
