



1、量化分析DeepSeek R1的数据表现和成本优势
2、量化2月1日、3日OpenAI推出的o3-mini和Deep Research两大模型的数据表现和成本优势
3、DeepSeek-R1对资本市场和相关标的的详细梳理
摘要
中国公司深度求索DeepSeek于2025年1月20日发布其最新开源模型DeepSeek-R1,用较低的成本达到了接近于OpenAI开发的GPT-o1的性能。我们认为,DeepSeek模型正在激发一波全球性的AI浪潮,推动AI继续进步。
DeepSeek-R1特点在于:强化学习技术、蒸馏技术、对用户开放思维链输出等。根据DeepSeek-R1的基准集表现,我们认为R1模型的综合性能已经能并肩OpenAI-o1-1217版本,综合能力:DeepSeek-R1≈OpenAI o1-1217>DeepSeek-V3。根据DeepSeek-R1蒸馏小模型表现,32B和70B模型在多项能力上实现了对标OpenAI o1-mini的效果,其中数学能力、多模态理解能力等测试中都一定程度上优于OpenAI o1-mini。
在性能并肩的情况下,DeepSeek-R1的成本优势尤为突出。DeepSeek-R1 API服务定价为每百万输入tokens 1元(缓存命中)/4元(缓存未命中),每百万输出tokens 16元。性价比完爆OpenAI o1以及其mini版本:
缓存命中的条件下,每百万输入tokens是OpenAI o1-mini成本的1/11,是o1成本的1/55。
缓存未命中的条件下,每百万输入tokens是OpenAI o1-mini成本的18%,是o1成本的3.6%。
输出API价格,每百万输出tokens是OpenAI o1-mini成本的18%,是o1成本的3.6%。
我们对OpenAI最新推出的o3-mini进行成本测算,相较DeepSeek-R1几无优势。OpenAI迅速应对DeepSeek挑战,相继推出两款重要的AI模型——北京时间2月1日凌晨推出o3-mini和2月3日晚上推出Deep Research智能体。但相较我们分析的DeepSeek-R1价格,o3-mini性价比相较DeepSeek-R1几无优势:
缓存命中的条件下,每百万输入tokens是DeepSeek-R1的4倍。
缓存未命中的条件下,每百万输入 tokens是DeepSeek-R1的2倍。
输出API价格,每百万输出 tokens是DeepSeek-R1的2倍。
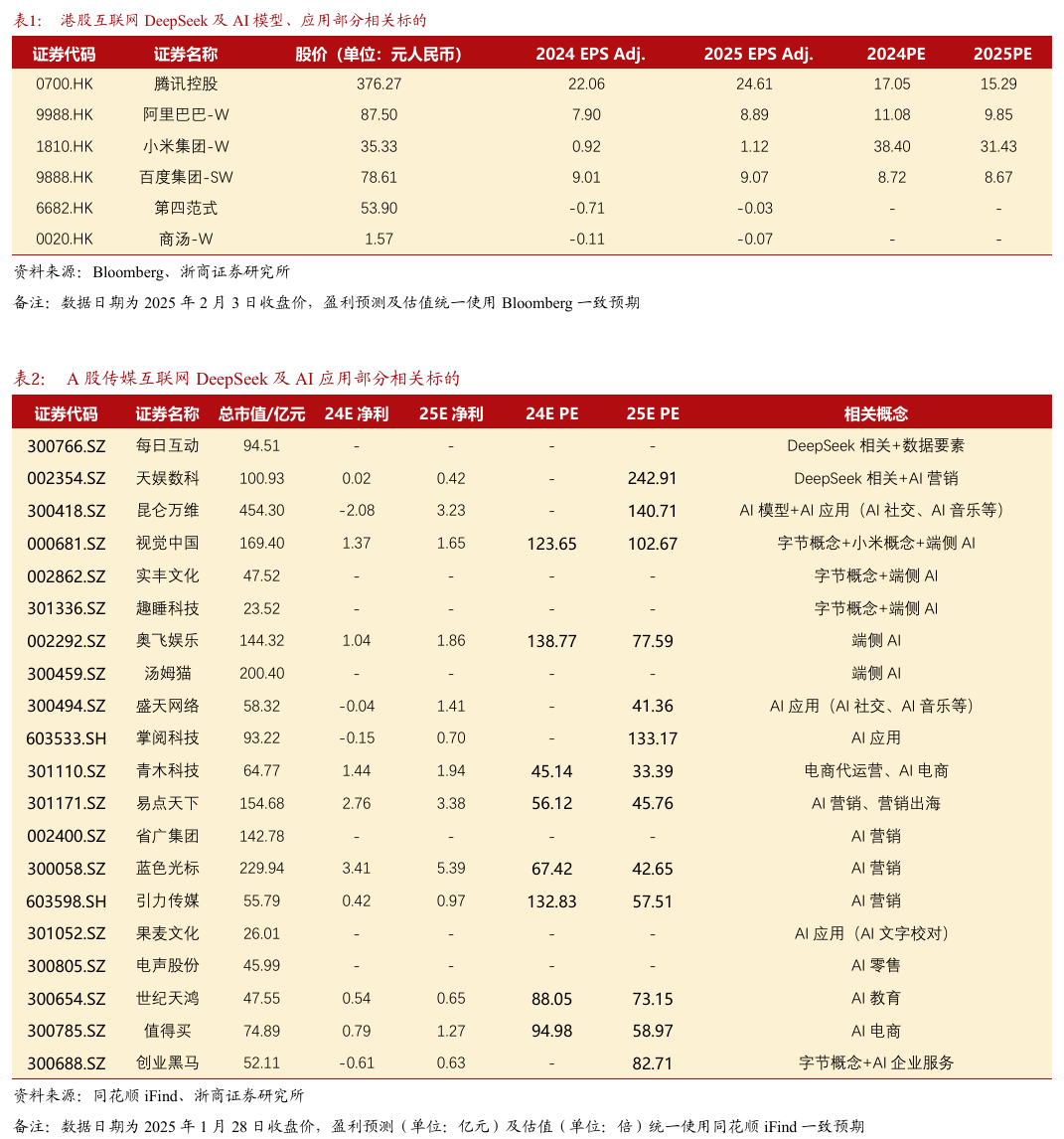
投资建议:DeepSeek-R1的颠覆性在于第一次实现中国模型对海外模型,尤其是代表全球领先AI水平的OpenAI模型的一次成功追赶,通过算法的优化实现AI平权,打破在算力和芯片上“大力出奇迹”的既定格局,将促使全球AI资产的价值重估,尤其是对中国互联网资产有显著的价值提升作用,前期中国互联网资产受中美芯片限售、模型发展略逊等影响估值承压,如港股互联网龙头【腾讯控股、阿里巴巴-W、小米集团-W】、以及其他港股AI核心标的【百度集团-SW、第四范式、商汤-W、美图、汇量科技】等。A股方面,除明确与DeepSeek有一定关系的【每日互动、天娱数科】,重点关注偏软的AI应用标的价值重估,关注【昆仑万维、视觉中国、盛天网络、掌阅科技、豆神教育】等的投资机会,同时继续重点提示端侧AI也有望受益于推理成本下降【实丰文化、趣睡科技、博士眼镜、英派斯】等。
正文
1 DeepSeek推出R1模型激发新一波全球性的AI浪潮
中国公司深度求索DeepSeek于2025年1月20日发布其最新开源模型DeepSeek-R1,用较低的成本达到了接近于OpenAI开发的GPT-o1的性能。这一进展破解了全球人工智能产业长期以来在算力上“大力出奇迹”的路径依赖,其影响波及资本市场。我们认为,DeepSeek模型正在激发一波全球性的AI浪潮,推动AI继续进步。
1.1 DeepSeek采用强化学习技术,基准表现并肩OpenAI-O1正式版
1月20日DeepSeek官网及APP同步上线、正式发布DeepSeek-R1,并同步开源模型权重。根据R1论文,该模型特点在于:强化学习技术、蒸馏技术、对用户开放思维链输出等,即:(1)DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。(2)DeepSeek-R1遵循MIT License,允许用户通过蒸馏技术借助R1训练其他模型。(3)DeepSeek-R1上线API,对用户开放思维链输出。

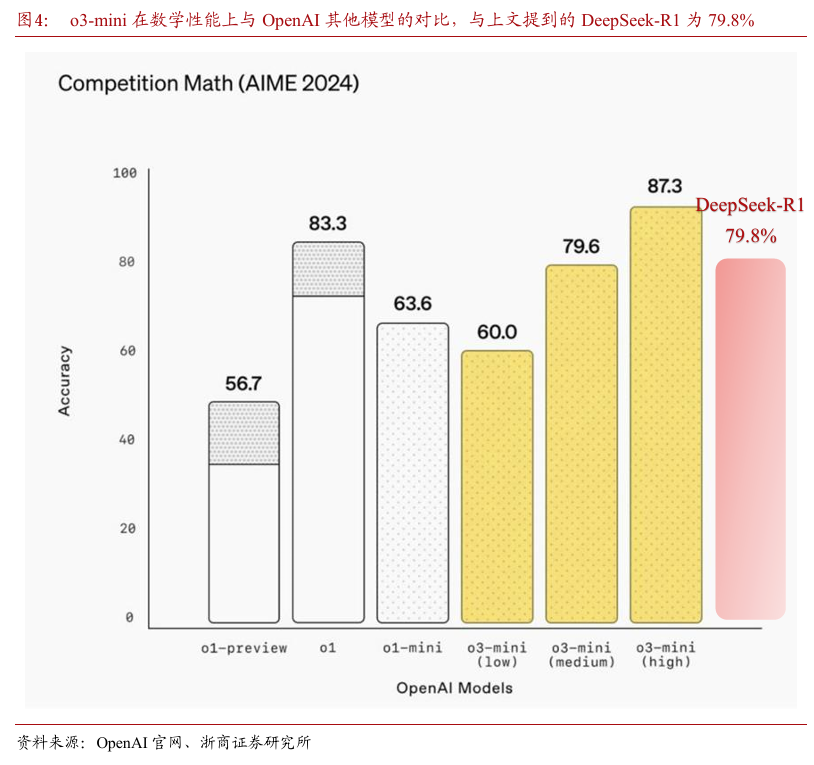
根据官网给出的基准集表现,我们认为R1模型的综合性能已经能并肩OpenAI-o1 1217版本,综合能力:DeepSeek-R1≈OpenAI o1-1217>DeepSeek-V3。
1)AIME 2024美国数学邀请赛2024
DeepSeek-R1: 79.8%
OpenAI-o1 1217: 79.2%
DeepSeek-V3: 39.2%
分析:在美国数学邀请赛2024测试中,DeepSeek-R1和OpenAI-o1 1217表现非常接近,显示出它们在处理类似任务时具有相似的准确率,但相较DeepSeek-V3有非常大的进步,迭代速度和效果非常显著。
2)Codeforces编程比赛
DeepSeek-R1: 96.3%
OpenAI-o1 1217: 96.6%
DeepSeek-V3: 58.7%
分析:在编程相关的任务上,DeepSeek-R1和OpenAI-o1 1217表现非常接近,显示出它们在处理类似任务时具有相似的准确率,但相较DeepSeek-V3有非常大的进步,迭代速度和效果非常显著。
3)GPQA Diamond多模态理解
DeepSeek-R1: 71.5%
OpenAI-o1 1217: 75.7%
DeepSeek-V3: 59.1%
分析:在多模态理解任务上,OpenAI-o1 1217表现最佳,其次是DeepSeek-R1,但相较DeepSeek-V3有非常大的进步,迭代速度和效果非常显著。
4)MATH-500数学专项
DeepSeek-R1: 97.3%
OpenAI-o1 1217: 96.4%
DeepSeek-V3: 90.2%
分析:在MATH-500数学专项测试上,三个模型的表现都非常出色,显示出它们在数学领域的强大能力,DeepSeek-V3略差一点。
5)MMLU自然语言理解
DeepSeek-R1: 90.8%
OpenAI-o1 1217: 91.8%
DeepSeek-V3: 88.5%
分析:在自然语言理解任务上,三个模型的表现都非常出色,显示出它们在数学领域的强大能力,DeepSeek-V3略差一点。
6)SWE-bench Verified软件工程
DeepSeek-R1: 49.2%
OpenAI-o1 1217: 48.9%
DeepSeek-V3: 42.0%
分析:在软件工程相关任务上,DeepSeek-R1表现最佳,其次是OpenAI-o1 1217,DeepSeek-V3的表现相对较低。
1.2 蒸馏小模型超越OpenAI o1-mini
DeepSeek-R1在开源DeepSeek-R1-Zero和DeepSeek-R1两个660B模型的同时,蒸馏了6个小模型开源给社区,其中32B和70B模型在多项能力上实现了对标OpenAI o1-mini的效果。

根据官网给出的DeepSeek-R1蒸馏小模型表现,32B和70B模型在多项能力上实现了对标OpenAI o1-mini的效果,其中数学能力、多模态理解能力等测试中都一定程度上优于OpenAI o1-mini,而OpenAI o1-mini的编程能力依然突出。
1.3 在性能并肩的情况下,DeepSeek-R1的成本优势尤为突出
DeepSeek此次推出的推理大模型DeepSeek-R1,其不仅性能比肩OpenAI-o1,并且其所需的训练成本可能只有后者的约1/20(仅用了2048个H800GPU,花了两个月的时间训练完成,仅花费了约558万美元),API的定价更是只有后者的约1/28,相当于使用成本降低了约97%。
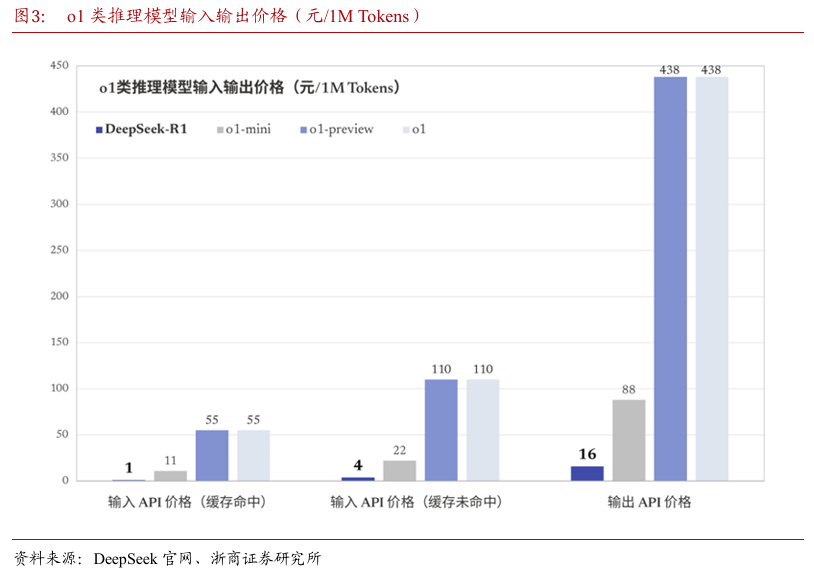
根据官网,DeepSeek-R1 API服务定价为每百万输入tokens 1元(缓存命中)/4元(缓存未命中),每百万输出tokens16元。性价比完爆OpenAI o1以及其mini版本。
缓存命中的条件下,每百万输入 tokens是OpenAI o1-mini成本的1/11,是o1成 本的1/55。
缓存未命中的条件下,每百万输入tokens是OpenAI o1-mini成本的18%,是o1成本的3.6%。
输出API价格,每百万输出tokens是OpenAI o1-mini成本的18%,是o1成本的3.6%。
DeepSeek官方公布的数据来看,其DeepSeek-V3的训练仅用了约2080张英伟达H800加速卡,这部分的芯片投资大约为4000万美元左右。而且,DeepSeek训练其AI模型也并不一定非要拥有庞大的自有的硬件基础设施,其完全可以通过租用第三方的硬件基础设施来对自己的大模型进行训练。也就是说,DeepSeek采用并不先进的AI芯片,以更低的算力要求和更低的成本,达到了OpenAI等美国AI技术厂商的顶级AI大模型的效果。这一成就被认为对美国的人工智能领导地位构成威胁,不仅引发了OpenAI、Meta、谷歌等众多大模型厂商恐慌,还引发了英伟达等AI芯片企业的价值重估和股价大跌。
2 OpenAI连续推出两款模型,应对DeepSeek挑战
OpenAI迅速响应市场变化、保持在AI领域的领先地位,推出了两款重要的AI模型——o3-mini和Deep Research智能体以应对DeepSeek的挑战。
2.1 2月1日推出o3-mini,但性价比相较DeepSeek-R1几无优势
北京时间2月1日凌晨,为应对DeepSeek-R1所带来的竞争,OpenAI正式发布了o3mini型,这也是OpenAI推理系列中最新、最具成本效益的模型,并且已在ChatGPT和API中开放使用。
o3-mini是一款轻量级版本的o3模型,专注于提供高效能的同时大幅降低使用成本。这款模型特别适合需要频繁调用且对计算资源有限制的应用场景。此外,o3-mini在多项基准测试中表现优异,尤其是在编码、逻辑处理等任务上,显示出了其优于原来版本o1-mini及o3模型的性价比优势。
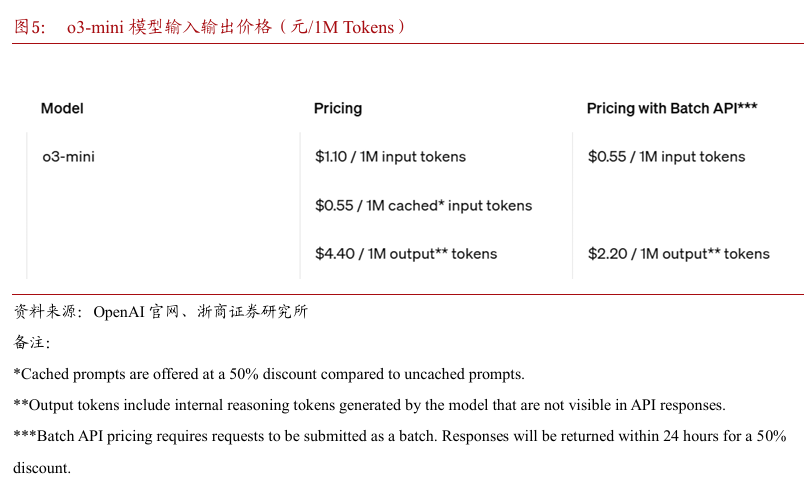
据OpenAI官网介绍,o3-mini的价格比OpenAI o1-mini便宜63%,比正式版o1便宜 93%。开发者可根据需求选择高、中、低三种推理强度,让o3-mini在处理复杂问题时进行 深度思考,平衡速度和准确性。
具体来说,目前ChatGPT免费用户首次可以体验一个有限速率的o3-mini版本,速率限制与现有的GPT-4o限制类似;Plus用户可选择o3-mini-high更高智能版本;每月支付200美元的Pro用户可无限使用o3-mini和o3-mini-high;API层面,o3-mini输入1.10美元/百万token、输出4.40美元/百万token,价格比o1-mini便宜63%,比正式版o1便宜93%,但仍是GPT-4omini的7倍左右。
但相较我们上文分析的DeepSeek-R1价格,性价比相较DeepSeek-R1几无优势。我们以2月4日美元兑人民币汇率1美元=7.25元人民币进行测算:
缓存命中的条件下,每百万输入tokens是DeepSeek-R1的4倍。
缓存未命中的条件下,每百万输入tokens是DeepSeek-R1的2倍。
输出API价格,每百万输出tokens是DeepSeek-R1的2倍。
2.2 2月3日再推出Deep Research,专注深度学习和专业信息处理
2月3日晚上,OpenAI再推出Deep Research模型,这是一个使用推理来综合大量在线信息并为用户完成多步骤研究任务的智能体,旨在帮助用户进行深入、复杂的信息查询与分析。目前,Pro用户现已可用,接下来还将开放给Plus和Team用户使用。
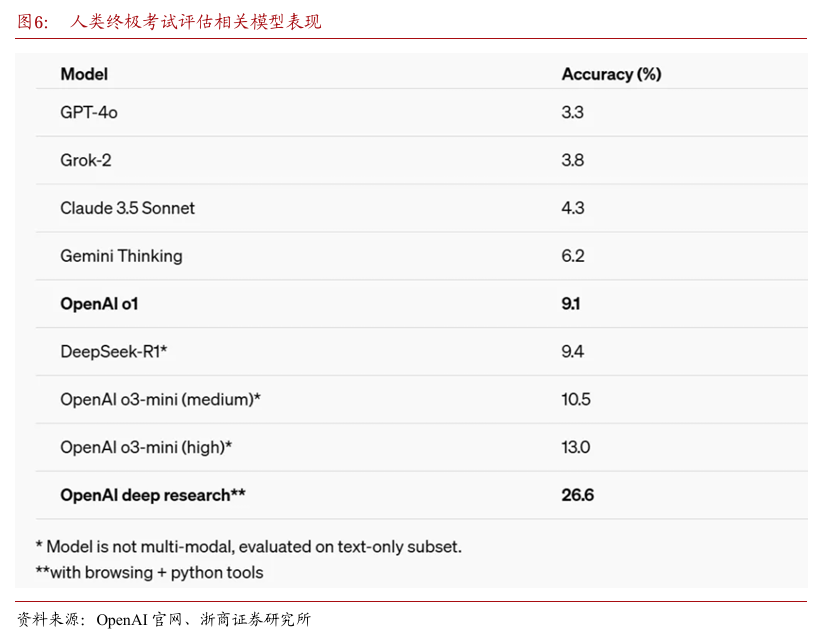
对于最近发布的「人类终极考试」评估,在专家级问题上对广泛学科的人工智能进行了测试,支持DeepResearch的模型以26.6%的准确率创下了新高。
这项测试包括3000多个多项选择题和简答题,涵盖了从语言学到火箭科学、古典文学到生态学的100多个学科。与o1相比,进步最大的是化学、人文和社会科学以及数学。支持DeepResearch的模型展示了一种类人方法,可以在必要时有效地寻找专业信息。
3 DeepSeek-R1颠覆性在于实现AI平权,重估资产价值
DeepSeek-R1的最大价值在于第一次实现中国模型对海外模型,尤其是代表全球领先AI水平的OpenAI模型的一次成功追赶,通过算法的优化实现AI平权。面对越来越大的模型,训练模型所需的AI算力不断飙升,“大力出奇迹”这一算力霸权开始左右人工智能的发展。英伟达创始人兼首席执行官黄仁勋就据此提出过“黄氏定律”:在计算架构改进的推动下,人工智能芯片的性能每年可提升1倍,速度远超摩尔定律。
我们上文的分析,DeepSeek-R1已经实现性能上的追赶和性价比上的超越,同时从两个维度极大地推进了AI发展的进程:
一是从算力到应用,继续大幅降低模型的使用成本,使AI应用的爆发加快落地。
二是盘活了整个国产AI市场,从国产芯片到国产大模型,再到国产AI应用,大幅提升了市场对整个国产AI产业链的信心。
DeepSeek-R1打破在算力和芯片上“大力出奇迹”的既定格局,将促使全球AI资产的价值重估,尤其是对中国互联网资产有显著的价值提升作用,因为前期中国互联网资产受中美芯片限售、模型发展略逊等影响估值承压,例如港股互联网龙头【腾讯控股、阿里巴巴-W、小米集团-W】、以及其他港股AI核心标的【百度集团-SW、第四范式、商汤-W、美图、汇量科技】等。A股方面,除明确与DeepSeek有一定相关性的【每日互动(幻方量化的创始合伙人之 一徐进是每日互动的联合创始人之一)、天娱数科(为DeepSeek提供投放业务)】,重点关注偏软的AI应用标的价值重估,关注【昆仑万维、视觉中国、盛天网络、掌阅科技、豆神教育】等的投资机会,同时继续重点提示端侧AI也有望受益于推理成本下降【实丰文化、趣睡科技、博士眼镜、英派斯】等。
风险提示
风险提示:AI技术迭代不及预期、AI应用落地不及预期、政策不确定性、中美关系不确定性等的风险。

 VIP复盘网
VIP复盘网
