

在具身智能领域,一个问题正变得越来越尖锐:当一个机器人站在厨房里,它究竟应该先“看懂”这个世界,还是先“想清”下一步动作?
过去,大量研究将这两件事割裂开来,要么专注让模型描述场景,要么埋头优化动作序列。但在真实世界中,感知与决策本就是一体的。当机器人抓起一只杯子,它必须同时理解杯子的位置、杯中的液体、倾倒的角度和此刻是否该停止。任何一刻的犹豫或误判,都意味着任务的失败。
北京大学副教授穆亚东及北京大学、星源智团队给出了一套完整的答案。在即将召开的计算机视觉顶会CVPR 2026上,一篇题为《Extending Embodied Question Answering from Perception to Decision》的论文,首次将具身问答从静态感知扩展到动态决策,提出了大规模数据集EQA-Decision与对应的RoboDecision训练框架。
该工作构建了覆盖四大推理模块、超过四百万问答对的超大规模数据引擎,并设计出从监督微调到思维链再到强化学习的三阶段训练方法,让模型真正学会“先想后做、看图决策”,为具身智能的评测和能力建设立下了一道全新的基准线。

论文链接:
01.
EQA-Decision:一个为决策而生的百万级数据引擎
具身问答(Embodied Question Answering, EQA)自提出以来,一直被视为连接视觉感知、语言推理和物理交互的关键任务。然而,现有数据集和评测基准长期处于“各自为战”的状态,几乎没有一个大规模框架能将空间理解、状态追踪、因果推理和即时行动决策放在同一语境下统一考量。
这种割裂带来的后果是,即便是目前最先进的多模态大模型,在面对动态交互场景时也常常表现得像个“纸上谈兵”的旁观者。它们可以准确告诉你“桌子上的红苹果在碗的左边”,却很难在机器人抓取苹果的过程中判断“此刻是否已经抓稳”,更不用说“如果苹果滑动了,下一步该调整什么动作”。
而为了填补上述空白,研究团队构建了EQA-Decision数据集,其体量超过四百万个多模态问答对,数据来源横跨模拟环境、图像问答、第一人称视频和真实机器人轨迹四大类型。
这些数据被系统性地组织成四大推理模块,即静态场景构建、空间理解、任务动态推理和即时决策,并在其下细分为九项子任务。
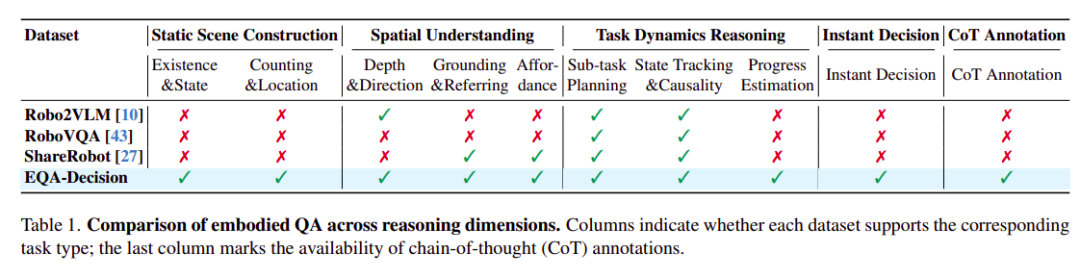
其中,静态场景构建模块关注物体存在性、状态、计数和位置等基本场景理解任务,为模型提供对环境的“第一眼认知”。
空间理解模块则从三个互补视角切入,包括深度与方向、定位与指代,以及行动可能性,帮助模型建立起“哪里是什么,哪里可以做什么”的空间直觉。
这两个模块更贴近传统意义上的感知能力,而真正让该数据集区别于以往工作的,是任务动态推理和即时决策两大模块。
任务动态推理包含了子任务规划、状态追踪与因果推理、以及进度估计三个子类,这种引入时间进程和因果链条的设计,促使模型去理解动作的先后逻辑和任务状态的演变。
而最前沿的即时决策模块,则将具身问答推向了真正的行动层面。该模块专注于建模机器人在动态具身环境中的实时决策过程,模型需要在任务执行中的某一瞬间,综合空间布局、子任务完成度和未来动作后果,完成一次从“看到”到“决定”的完整思维链路,给出此刻最合理的即时动作。
比如,在“刷洗水瓶”的任务中,机器人倾斜瓶身倒水,水流仍在流出,此时模型应当回答“等待,直到水流停止”,而非急躁地进入下一步。
正是任务动态推理和即时决策这两个新引入的模块,使 EQA-Decision 真正将具身问答从“静态体检”升级为“动态实战”。
02.
RoboDecision:三阶段训练打造“感知-决策”统一体
有了面向决策的数据集,还需要能真正消化这些数据的模型。团队以Qwen3-VL-8B-Instruct为基座,提出了RoboDecision训练框架,通过三阶段递进式训练,逐步将通用多模态模型塑造成擅长具身推理与决策的专家。

第一阶段是SFT(监督微调),在EQA-Decision四大模块上均匀采样数据,对语言模型和跨模态融合层进行训练,注入具身领域的先验知识,从而提升基础的空间、时间和决策推理能力。
第二阶段是CoT-SFT(思维链监督微调),团队从各模块均匀采样约10%的数据,用Gemini生成包含推理依据和最终答案的结构化思维链标注,再进一步微调模型。这一步教会模型“先想后答”,形成显式的多步推理和因果理解能力,也让后续强化学习阶段的奖励信号更加稳定。
第三阶段则是GRPO(强化学习微调),这是RoboDecision框架真正将“感知”与“决策”焊死的环节。许多经过监督微调的模型会过度依赖文本先验,导致即使视觉输入发生变化,输出依然相似,这在要求实时动作调整的具身任务中是致命的。
为此,团队设计了一种混合奖励函数,综合考察推理质量、答案正确性和视觉一致性三个维度。
其中,推理奖励用E5-large计算模型生成的推理链与参考思维链的相似度,鼓励因果一致的空间和时间推理;答案奖励则对自由文本回答采用语义相似度,对结构化输出(如坐标、深度)则采用基于规则的评分函数;
最具创新性的是视觉一致性奖励,它用OpenCLIP对齐生成的推理与视觉观察,确保模型的思考内容真正反映画面中的视觉证据,而非靠文本先验“瞎猜”。这迫使模型不再做一个“脱离画面的空想家”,而是成为一个紧盯场景变化、根据视觉线索即时调整推理的“实干派”。
这种将视觉对齐明确纳入优化目标的思路,在具身模型训练中尚属前沿。它相当于在模型的决策回路里植入了一个持续的感官校验机制,为构建可靠的动作生成系统提供了新的方法论。
03.
全面领先的评测结果:RoboDecision-8B超越GPT-5
为了检验成果,团队建立了一套统一的EQA-Decision Benchmark,涵盖静态场景理解、空间-深度推理、视觉指代、时间推理、规划推理和即时决策六大维度,总计2118个精心筛选的评测样本,且与训练集严格隔离。
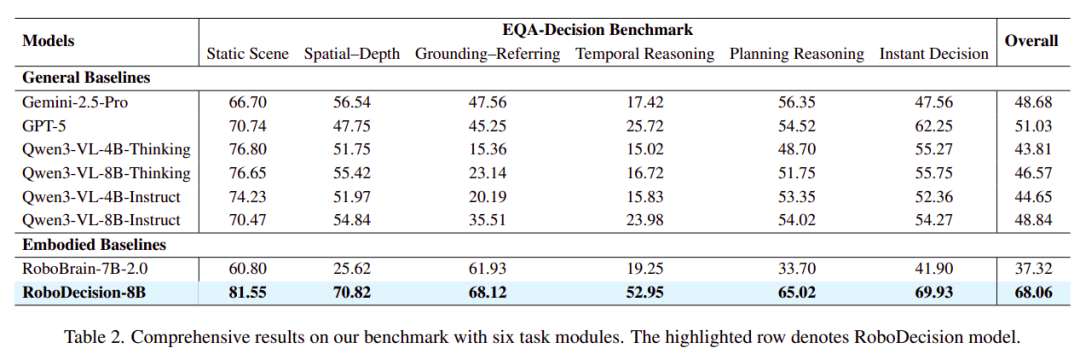
结果显示,RoboDecision-8B在整体得分上达到68.06,以显著优势超越了包括GPT-5(51.03)、Gemini-2.5-Pro(48.68)、Qwen3-VL-8B-Instruct(48.84)等在内的所有通用基线和具身基线模型。
尤其值得关注的是两个高难度维度的飞跃。在视觉指代定位任务上,RoboDecision得分 68.12,而Qwen3-VL-8B-Thinking仅23.14,差距悬殊的核心原因正是视觉一致性奖励强制模型把推理锚定在图像像素上。
在即时决策任务上,RoboDecision得分 69.93,比最强基线GPT-5的62.25高出7.7个点,充分证明了“感知-决策”一体化训练的有效性。
此外,在RoboVQA、ERQA等域外具身基准测试上,RoboDecision-8B同样展现出领先的泛化能力,证实了这套训练框架的有效性并非局限于自家数据集。
04.
结语与未来
具身智能的真正挑战,是在动态世界中做出正确决策。此次星源智与北京大学团队联合提出的EQA-Decision与RoboDecision,正是从感知智能迈向决策智能的关键一步,为后续的科研合作、产业交流和高端人才聚集搭建了一座极具吸引力的技术灯塔。
作为该工作的重要合作方,星源智为研究提供了宝贵的资源支持。CVPR 2026的录用,不仅是学术层面的突破,更彰显出公司在具身智能核心算法能力上的深厚积淀。
未来,随着这类“从感知到决策”的数据集与模型被更广泛地应用于具身智能研究与机器人学习等领域,或许将看到,机器人不仅能够理解世界,更学会如何做出正确的行动

 VIP复盘网
VIP复盘网
